
La notion de chaîne de caractères a déjà été superficiellement présentée au chapitre C2‑VII . En effet, bien que complexe, c'est un élément de langage indispensable pour mettre en œuvre des interactions avec un utilisateur – notamment afficher des messages – dans un programme s'exécutant sur un terminal de commandes en ligne.
Mais dès lors que les notions de pointeur (chap. C5‑I et chap. C5‑II ) et de tableau (chap. C5‑III et chap. C5‑IV ) ont été abordées, il est possible d'entamer une étude approfondie des chaînes de caractères.
Pour bien commencer cette étude, il importe de prendre conscience de ce qui fait intrinsèquement la complexité de la notion de chaîne de caractères. Dans un programme, une variable de ce type doit en principe pouvoir mémoriser un nombre de caractères potentiellement très grand, mais aussi éventuellement très petit. Il est donc impossible de déterminer une taille fixe par défaut qui serait satisfaisante dans tous les cas de figure.
C'est pourquoi, en matière d'implémentation des chaînes de caractères, la plupart des langages de programmation utilisent des mécanismes d'allocation dynamique de mémoire W (aspect qui sera abordé seulement dans la partie C6 de ce module). Une telle solution est adoptée dans la bibliothèque standard du langage C++ avec la classe string, mais pas en langage C.
En effet, la « philosophie » du langage C privilégie l'emploi d'objets les plus simples possibles. Dans le noyau du langage, il n'y a pas de notion de chaîne de caractères de taille dynamique. À la place, on recourt à un tableau de caractères à taille fixe surdimensionnée et à l'usage du caractère NUL comme marque de fin de chaîne (cf. l'exemple en figure ci‑dessous).

On parle de chaîne de style C – en anglais, C(‑style) string ou null‑terminated string W.


Même si la notion de chaîne de style C pourraient sembler constituer aujourd'hui un concept trop « rudimentaire » voire « archaïque » par rapport à ceux utilisés dans des langages de programmation plus récents (C++, Python, JavaScript, etc.), elle reste un élément de langage incontournable, car encore pour longtemps massivement utilisé pour la programmation des entrées‑sorties textuelles (typiquement, dans un terminal de commandes en ligne) et des systèmes à mémoire limitée (typiquement, sur cartes à microcontrôleur).
L'étude approfondie des chaînes de style C constitue donc l'objectif principal du présent chapitre, dans lequel on abordera les points suivants :
- On verra d'abord les constantes littérales de « type » chaîne de style C. Outre leur syntaxe de codage, on abordera la question de leur type et de leur représentation en mémoire.
- On pourra alors examiner le cas général des données déclarées de « type » chaîne de style C, soit comme un tableau de caractères, soit comme un pointeur sur une constante littérale de type chaîne de style C. On verra la syntaxe de déclaration et les manipulations élémentaires que l'on peut faire sur un tel objet (affectation, passage d'argument d'une fonction).
- Et puis on passera en revue les fonctions les plus usuelles de la bibliothèque standard sur les chaînes de style C, qui permettent de coder toutes sortes d'analyses et de manipulations complexes sur ces chaînes.


Pour finir, dans une perspective d'acquérir une connaissance plus experte et polyvalente de la notion de chaîne de caractères, la dernière section du chapitre propose une introduction aux chaînes de caractères dynamiques en langage C++. On y présente :
- d'une part la classe
stringde la bibliothèque standard, - d'autre part son implémentation plus limitée nommée
String(bien noter la majuscule initiale «S») dans le framework Arduino.
Tous ces aspects sont évidemment essentiels pour pouvoir développer des programmes avancés, tant sur terminal que sur systèmes embarqués.
Les constantes littérales de type chaîne de caractères
Notion mathématique de chaîne de caractère
Le préambule qui suit à pour vocation de simplement faire découvrir à un public de techniciens en informatique en quête d'expertise les aspects mathématiques que sous‑tend le concept de chaîne de caractères. En effet, ces aspects sont essentiels pour mieux comprendre les notions de chaîne nulle et de concaténation.
La notion de chaîne de caractères en programmation correspond en mathématiques à celle de séquence de symboles – on parle aussi de mot – dans ce qu'on appelle un monoïde libre W, c'est‑à‑dire un ensemble muni d'une loi de composition lui conférant une structure algébrique particulière (cf. ci‑après).
Attention ! La notion de mot d'un monoïde est fondamentalement différente de la notion familière de mot en langage naturel. En effet, dans le monoïde libre engendré par les caractères imprimables usuels, n'importe quelle séquence de caractères, aussi longue ou bizarre soit‑elle – par exemple, « !& mK », est un mot au sens mathématique.
Un monoïde libre est une structure algébrique dont la définition rigoureuse est assez complexe mais qu'on peut simplifier ainsi. On se donne :
- un alphabet noté A, c'est‑à‑dire un ensemble fini d'éléments qu'on appelle des symboles ;
- un opérateur de concaténation qui permet de composer des séquences de symboles, qu'on appelle aussi mots ; cet opérateur est noté « * » par nécessité mais, le plus souvent, il est omis dans l'écriture des séquences – de la même manière que l'opérateur de multiplication « × » est souvent omis en calcul littéral, par exemple lorsqu'on écrit « ab » plutôt que « a × b ».
La génération des séquences de symboles est assez intuitive :
- On peut déjà concevoir la séquence vide, de longueur 0. Bien que n'ayant usuellement pas de représentation, elle est absolument essentielle car elle constitue l'élément neutre pour l'opération de concaténation. En effet, « ajouter » la séquence vide à une séquence quelconque ne change en rien cette dernière.
- Ensuite, chaque symbole de A forme une à lui seul séquence de longueur 1.
- À partir de là, toute concaténation de deux séquences s1 et s2, respectivement de longueurs l1 et l2 forme une séquence s3 de longueur l3 = l1 + l2.

L'ensemble de toutes les séquences finies possibles ainsi engendrées est noté A*, pour lequel l'opérateur de concaténation est une loi interne, associative et dotée d'un élément neutre, la séquence vide. Il s'agit donc d'un monoïde W qu'on appelle, du fait de son principe de génération par libre concaténation de séquences, le monoïde libre construit sur l'alphabet A.
Attention ! Sur la figure ci‑contre, seule une minuscule partie des éléments de A* est représentée (les séquences de longueur inférieure ou égale à 2).
- L'ensemble des chaînes numériques composables en base 10 est le monoïde libre qu'on peut noter C* en le construisant sur l'alphabet des chiffres dits « arabes » :
C = {'0', '1', '2', … , '9'} - C* contient des éléments qui n'existent pas dans ℕ, par exemple "
00" ; - C* ne possède a priori aucune propriété arithmétique sur ses éléments (il faudrait pour cela commencer par définition la notion d'addition).
- Dans un plan pixelisé, l'ensemble des chemins axiaux continus possibles à partir d'un pixel d'origine peut être modélisé par le monoïde libre noté F* construit sur l'alphabet des déplacements axiaux unitaires :
F = {'←', '↑', '→', '↓'}
"→→→↑↑↑←←←↓↓↓" est un élément de F* qui trace un carré de 3 pixels de côté. Voyons maintenant quelques propriétés très générales qu'on peut établir sur un monoïde libre.
Le nombre d'éléments d'un monoïde libre est infini puisque, même si chaque chaîne possède une longueur finie, cette longueur n'est pas pour autant limitée (c'est exactement le même principe qui préside à l'infinité de l'ensemble ℕ des entiers naturels, qui sont composés avec un nombre fini mais illimités de chiffres).
De plus, même si l'on impose une longueur maximale m aux mots, le nombre d'éléments est potentiellement très grand. Ainsi, pour un alphabet de cardinal n (son nombre de symboles), on a nm séquences possibles.
unsigned long long (cf. chap. C3‑II ; on peut donc le qualifier d'astronomique ! Si l'alphabet A d'un monoïde libre est totalement ordonné par une relation d'ordre donnée, alors on peut aussi définir plusieurs relations d'ordre total sur son monoïde libre A*. On parle d'ordres lexicographiques. En particulier :
- On peut privilégier la position des symboles. C'est le choix qui est fait pour l'ordre alphabétique usuel, notamment dans les dictionnaires.
- On peut aussi privilégier la longueur des chaînes. C'est le choix qui est fait pour l'ordre numérique usuel dans les ensembles mathématiques.
Notion de chaîne de caractères en programmation
En programmation, une chaîne de caractères W – en anglais, character string – est un objet d'usage très fréquent, qui est constitué d'une suite finie de caractères. Un tel objet possède deux caractéristiques remarquables :
Dans tous les langages de programmation, il est possible de coder des constantes littérales de type chaîne de caractères – typiquement en utilisant les guillemets simples ou doubles comme délimiteurs afin de créer une distinction syntaxique avec les constantes littérales des autres types de données.
Par exemple :
-
"123"code une constante littérale de type chaîne de caractère, - alors que
123code une constante littérale de type entier.
Dans de nombreux langages de programmation (Python, JavaScript, Bash…), le fait d'accepter deux délimiteurs différents " " ou ' ' permet, dans les cas simples, d'encapsuler une chaîne de caractère dans une autre.
Exemple :
-
'Le smiley "visage souriant" a pour glyphe 😀.' - ou encore
"Le smiley 'visage souriant' a pour glyphe 😀.".
Mais attention, ce n'est pas le cas en langages C/C++ pour qui les guillemets doubles sont obligatoires, les guillemets simples étant réservés aux constantes littérales de type caractère. Ainsi, seule la 2e forme ci‑dessus est compilable, mais on va très vite voir que la 1e forme peut être adaptée avec des séquences d'échappement.
Et par ailleurs, il est facile d'imaginer des cas plus complexes où l'une des chaînes de caractères contient elle‑même un ou plusieurs guillemets.
Exemple.
"L'émoticône smiley 'visage clin d'œil' a pour glyphe 😉."
Dans un tel cas, la 1re forme de l'exemple précédent devient problématique, comme le met en évidence la coloration syntaxique de l'éditeur de code (ici, Google Prettify) :
'L'émoticône smiley "visage clin d'œil" a pour glyphe 😉.'
Le recours à des occurrences de la séquences d'échappement \' est alors indispensable :
'L\'émoticône smiley "visage clin d\'œil" a pour glyphe 😉.'
Un autre aspect essentiel à prendre en compte est le fait que la taille en mémoire d'une chaîne de caractères peut être grande, voire très grande – par exemple quand il s'agit de manipuler un fichier de texte dans sa totalité. Presque toujours, cette taille dépasse les capacités de stockage des registres de la machine sur laquelle s'exécute le programme. C'est pourquoi il n'est pas possible de manipuler informatiquement une chaîne de caractères comme une donnée élémentaire.
On verra donc qu'en langages C/C++, les constantes littérales de type chaîne de caractère sont fondamentalement gérées comme des objets indicés et accédées via des pointeurs.
Syntaxe de codage d'une constante littérale chaîne de caractères en langage C
En langage C, une constante littérale de « type » chaîne de caractères W – en anglais, string literal – se code via la forme syntaxique ci‑dessous :
préfixe d'encodage
"suite de val. de car. et de séq. d'échapp."
De plus, tout chaîne de caractère codée dans un programme peut être décomposée en plusieurs sous chaînes les unes à la suite des autres, chacune délimitée par des guillemets doubles "", et éventuellement pourvue du même préfixe, c'est‑à‑dire :
préfixe
"sous‑chaîne 1" préfixe
"sous‑chaîne 2"
Le compilateur se charge alors leur concaténation.
Dans cette syntaxe C, on peut apporter les précisions suivantes.
- Le préfixe d'encodage est optionnel et reprend la même syntaxe que celle des valeurs de caractères étendus (cf. chap. C3‑IX ). Il peut donc prendre les codes :
u8,uouU
pour spécifier que les caractères de la chaînes sont respectivement encodées dans le format :
UTF‑8, UTF‑16 ou UTF‑32. - UTF‑8 avec la chaîne de compilation GCC sous Linux ;
- ASCII restreint avec la chaîne de compilation Mingw‑w64 sous Windows.
- La suite de valeurs de caractères et de séquences d'échappement codée entre guillemets doubles
""doit respecter principalement deux limitations : - être codée sur une seule ligne du fichier source ;
- ne pas contenir le caractère
", puisque ce dernier marquerait la fin du codage de la chaîne – mais il suffit d'employer la séquence d'échappement\"pour remédier à cette limitation. - les valeurs de caractères peuvent être directement saisies dans le code source tant que la syntaxe automorphe est possible (cf. chap. C3‑IX ) ;
- les séquences d'échappement doivent être codées conformément à leur syntaxe spécifique avec le symbole
\comme préfixe (cf. chap. C2‑VII ) ; les plus courantes sont : -
\n,\t,\bou\apour intégrer respectivement un saut de ligne (LF), un saut de tabulation horizontale (HT), un saut arrière (BS) du curseur ou l'émission d'avertissement sonore (BEL) ; -
\\,\"ou\'pour intégrer respectivement les symboles «\», «"» ou «'» sans qu'ils soient interprétés comme des caractères de contrôle ; -
\xxx,\uxxxxou\Uxxxxxxxxpour intégrer un caractère par son point de code si ce dernier comporte respectivement 2, 4 ou 8 digits hexadécimaux, sachant que tous les digits du point de code doivent être saisis, y compris les zéros initiaux.
L pour imposer aux caractères de la chaîne le type obsolète wchar_t. Son usage n'est pas recommandé. \ en fin de ligne. Mais on peut aussi la décomposer en sous‑chaînes codées les unes à la suite des autres, séparées selon les règles du format libre – cf. chap. C2‑II ) Le programme académique ci‑dessous affiche constante littérale de type chaîne de caractères saisie à la ligne n° 5 comme seul argument de la fonction printf :
#include <stdio.h>
int main(void)
{
printf("Le \"visage clin d'œil\" \U0001F609 se code :\t\\U0001F609.");
return 0;
}
Il peut être testé directement avec dans l'environnement OnlineGDB, dont la chaîne de compilation est GCC (laquelle opère par défaut en UTF‑8). On obtient la sortie standard conforme aux attentes :
Le "visage clin d'œil" 😉 se code : \U0001F609.
Dans cet exemple, on peut remarquer :
- le caractère non ASCII
œdirectement saisi (syntaxe automorphe) ; - les séquences d'échappement
\",\tet\\; - la séquence d'échappement
\U0001F609– sachant qu'elle aurait aussi pu être remplacée par sa valeur de caractère 😉 saisie en syntaxe automorphe (cf. chap. C3‑VIII ) avec un simple copier‑coller depuis la table des caractères du système d'exploitation ou d'une page web comme celle‑ci .
De plus, comme cette chaîne de caractères est un peu longue, elle peut aussi être codée sur deux lignes comme ci‑dessous, pour faciliter la lecture du code dans une fenêtre d'édition étroite :
printf("Le \"visage clin d'œil\" \U0001F609 "
"se code :\t\\U0001F609.");
Cette possibilité est plus avantageuse que celle ci‑dessous (mal colorisée par le script Code Prettify – cf. chap. C2‑X ) consistant à utiliser des sauts de ligne fictifs, qui rompt l'indentation du programme (si on essaye d'ajouter des espaces au début de la ligne n° 6, ils sont intégrés à la chaîne affichée, ce qui n'est pas souhaitable) :
printf("Le \"visage clin d'œil\" \U0001F609 \
se code :\t\\U0001F609.");
Dans tous les cas, on obtient exactement le même affichage que ci‑dessus, les deux sous‑chaînes ayant été concaténées par le compilateur.
La notion de chaîne de caractères « brute »
Pour s'affranchir de toute contrainte de saisie, le langage C++ (depuis la norme C++11) et une extension du langage C – portée notamment par la chaîne de compilation GCC – introduisent la notion de chaîne de caractères brute – en anglais, raw string literal C++ §(6).
Sa syntaxe de codage est la suivante :
préfixe d'encodageR"motif(chaîne brute)motif "
Le motif joue le rôle de délimiteur (bilatéral), il peut être codé par n'importe quelle séquence (éventuellement vide) de caractères imprimables ASCII à l'exception du caractère SP (espace), de la contre‑oblique « \ » ainsi que des parenthèses « ( » et « ) » qui sont tous interdits.
Dans une chaîne de caractères brute, averti par le préfixe R, le compilateur ne traite aucune séquence d'échappement. Il se contente de rechercher les séquences "motif( et )motif" pour délimiter le début et la fin de la chaîne. Le choix du motif délimiteur dépend donc du contenu de la chaîne, le codeur devant s'assurer qu'il n'y ait aucun conflit possible avec une éventuelle occurrence de cette séquence dans le contenu de la chaîne. Typiquement, on prend une répétition de symboles symétriques comme par exemple ======.
Tous les caractères saisis dans une chaîne brute sont donc inclus tels quels dedans, y compris les sauts de lignes générés par la touche « entrée » du clavier. Cette propriété est particulièrement bienvenue dans un programme pour incorporer des lignes de code source d'un autre langage, qui peuvent alors être indentées conformément aux règles de bonnes pratiques de l'édition de code, et sans encapsuler chaque ligne entre des guillemets comme on a dû le faire dans l'exemple précédent.
- Le programme académique ci‑dessous (encore une fois, mal colorisé ici par le script Code Prettify – cf. chap. C2‑X ) comporte une chaîne de caractères brute codée sur deux lignes (n° 4 & 5) comme premier argument de la fonction
printf. Arbitrairement, le motif délimiteur choisi est!!!, mais tout autre aurait pu convenir. - Au chapitre R2‑IV , on a montré comment embarquer un serveur web sur une carte Arduino équipée d'un shield Ethernet – donc, programmée en C++. Dans l'extrait ci‑dessous, le code HTML/CSS de la page d'accueil du serveur est incorporé en plusieurs parties sous la forme des chaînes de caractère brutes
PAGE_HEAD(lignes nº 10 à 17) etPAGE_TAIL(lignes nº 19 à 26) :
#include <stdio.h>
int main(void)
{
printf(R"!!!(foo
bar)!!!");
return 0;
}
foo
bar

const char PAGE_HEAD[] = R"=====(
<!DOCTYPE html>
<html lang='fr'>
<head>
<meta charset='utf-8'>
<title>Dynamic page Arduino</title>
</head>
)=====";
const char PAGE_TAIL[] = R"=====(
<h1> Dynamic page example embedded on Arduino board </h1>
<p><a href='./?bgcolor=white'>White</a>
<!-- 2 non‑break spaces here as inter-margin -->
<a href='./?bgcolor=yellow'>Yellow</a></p>
</body>
</html>
)=====";
// ...
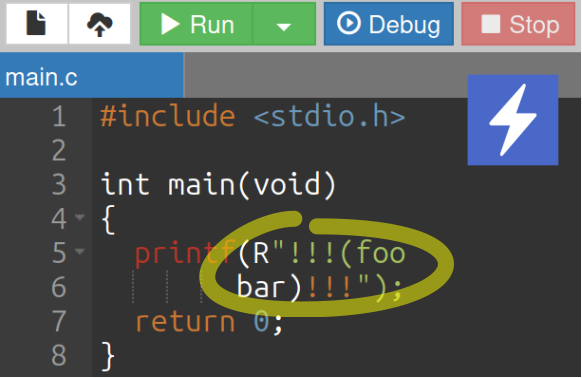
Avec certains éditeurs de code, la coloration syntaxique des chaînes de caractères brutes est défectueuse. C'est notamment le cas du script Code Prettify (cf. chap. C2‑X ) utilisé pour la mise en forme du présent site web, mais aussi avec OnlineGDB, comme le montre la capture d'écran ci‑contre ou la chaîne brute et ses délimiteurs ne sont pas syntaxiquement reconnus, et donc colorisés de façon « anarchique ».
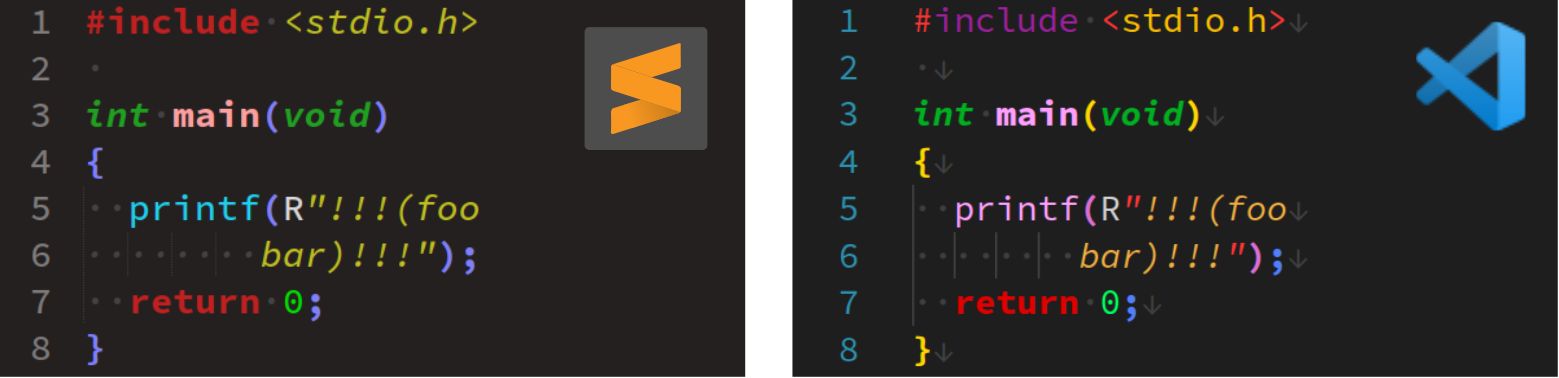
En principe, on devrait voir la chaîne de caractère brute rendue avec une seule couleur, ainsi que le font très bien les éditeurs de code comme Sublime Text ou VS Code – cf. les captures d'écran ci‑dessous.
Type d'une constante littérale chaîne de caractères
Comme toute constante littérale, une constante littérale chaîne de caractère possède un type implicitement déterminé par sa valeur. Dans tous les cas, en langages C/C++, il s'agit d'un tableau dont :
- le type d'élément est directement lié au format d'encodage des caractères ;
- le nombre d'élément dépend du nombre d'unités d'encodage nécessaires pour représenter tous les caractères de la chaîne (en rappelant que ce nombre est, pour certains formats, variable d'un caractère à l'autre – c'est notamment le cas en UTF‑8, cf. chap. C3‑IX ).
Plus précisément, si l'on note N le nombre d'unités d'encodage pour représenter tous les caractères d'une chaîne codée dans le programme sous la forme d'une constante littérale, cette dernière aura pour nom de type implicite (cf. chap. C5‑III ) :
-
const char[N + 1]en l'absence de préfixe d'encodage ou avec le préfixeu8en langage C ; -
const char16_t[N + 1]avec le préfixeu; -
const char32_t[N + 1]avec le préfixeU.
char8_t[N + 1] avec le préfixe u8 en langage C++ depuis la norme C++20) sachant qu'une unité supplémentaire (d'où le + 1 dans les expressions ci‑dessus) est toujours requise pour encoder le caractère de fin de chaîne NUL W – codé 0x0 dans tous les formats (et également, par la séquence d'échappement octale '\0', cf. chap. C3‑VIII ).
NB : le caractère NUL n'a pas besoin d'être saisi en fin de chaîne par le codeur, il est automatiquement ajouté par le compilateur (cf. chap. C2‑VII ).
Pour chacun des quatre exemples académiques à suivre, on donne le nom de type implicite d'une constante littérale chaîne de caractère donnée. Ce type est valable pour une compilation en langage C sur une machine Linux.

On fournit pour le premier exemple un programme de scan mémoire qui permet de vérifier le type implicite de la chaîne de caractères. Ce programme peut être compilé et exécuté sur OnlineGDB. Pour les exemples suivants, il suffit de procéder à quelques copier/coller pour l'adapter.
- La constante littérale
"Good bye."(9 caractères) a pour nom de type impliciteconst char[10](9 + 1 éléments) car elle est composée exclusivement dans le jeu ASCII restreint (chaque caractère ne nécessite qu'une seule unité d'encodage). - la constante littérale chaîne de caractère étudiée est ciblée par un premier pointeur de caractères
str(cf. la ligne n° 7) ; - pour la parcourir, on déclare un deuxième pointeur
pinitialisé surstr, donc sur le premier octet de la chaîne étudiée (cf. la ligne n° 8) ; - une boucle de répétition
do whileassure le parcours octet par octet destrviapjusqu'à atteindre le caractère de fin de chaîne0x0(cf. la condition de répétition qui combine aussi l'incrémentation préalable depavant son déréférencement, à la ligne n° 15) ; - son adresse, obtenue par la valeur de
pconverti en pointeur génériquevoid *(cf. chap. C5‑I ) ; - son indice (entre crochets
[]) dans le tableau, obtenu par la différencep - str(cf. chap. C5‑I ) ; - puis, par déréférencement de
pet en ayant préalablement testé la valeur de l'octet scanné par la fonctionisprint(cf. la ligne n° 10 et le chap. C3‑VIII : - soit la valeur de caractère de l'octet si ce dernier correspond à un caractère imprimable du jeu ASCII restreint (cf. la ligne n° 11) ;
- soit le code hexadécimal de l'octet, obtenu par conversion dans le type
unsigned char, dans le cas contraire (cf. la ligne n° 13). - La constante littérale
"À bientôt"(9 caractères également) a pour nom de type impliciteconst char[12](11 + 1 éléments) car elle comporte deux caractères (« À » et « ô ») qui sont hors du jeu ASCII restreint, donc non reconnus comme caractères imprimables par la fonctionisprint. L'un et l'autre nécessitent deux octets d'encodage en UTF‑8 (qui est le format par défaut des chaînes de caractères avec GCC), ce que l'on peut observer sur la sortie standard obtenue avec le même programme qu'à l'exemple précédent : - La constante littérale
u"Good bye."(toujours 9 caractères) a pour nom de type impliciteconst char16_t[10](9 + 1 éléments) car le préfixeuimpose le typechar16_t– de taille 2 octets – comme unité d'encodage de ses caractères. Et ici, chaque caractère ne nécessite qu'une seule unité d'encodage. - On pourrait faire une expérience similaire avec la chaîne
U"Good bye."et conclure qu'elle a pour nom de type impliciteconst char32_t[10]en constatant que les adresses de ses éléments consécutifs s'échelonnent de 4 en 4 octets.
#include <stdio.h>
#include <ctype.h>
#include <uchar.h> // only for further examples
int main(void)
{
char * str = "Good bye.";
char * p = str; // mem-scan pointer
do {
if (isprint(*p))
printf("%p\t[%2ld]\t%c\n", (void *) p, p - str, *p);
else // non printable character
printf("%p\t[%2ld]\t0x%X\n", (void *) p, p - str, (unsigned char) *p);
}
while (*p++ != 0x0);
return 0;
}
0x55c25dde6004 [ 0] G
0x55c25dde6005 [ 1] o
0x55c25dde6006 [ 2] o
0x55c25dde6007 [ 3] d
0x55c25dde6008 [ 4]
0x55c25dde6009 [ 5] b
0x55c25dde600a [ 6] y
0x55c25dde600b [ 7] e
0x55c25dde600c [ 8] .
0x55c25dde600d [ 9] 0x0
0x565528590004 [ 0] 0xC3 0x565528590005 [ 1] 0x80 0x565528590006 [ 2] 0x565528590007 [ 3] b 0x565528590008 [ 4] i 0x565528590009 [ 5] e 0x56552859000a [ 6] n 0x56552859000b [ 7] t 0x56552859000c [ 8] 0xC3 0x56552859000d [ 9] 0xB4 0x56552859000e [10] t 0x56552859000f [11] 0x0
char16_t * str = u"Good bye."; char16_t * p = str;
0x5651c71c5004 [ 0] G 0x5651c71c5006 [ 1] o 0x5651c71c5008 [ 2] o 0x5651c71c500a [ 3] d 0x5651c71c500c [ 4] 0x5651c71c500e [ 5] b 0x5651c71c5010 [ 6] y 0x5651c71c5012 [ 7] e 0x5651c71c5014 [ 8] . 0x5651c71c5016 [ 9] 0x0
Le caractère NUL est parfois désigné NULL mais il faut surtout ne pas le confondre avec le pointeur nul (cf. chap. C5‑II ) dont le code en langages C/C++ est NULL.
Allocation mémoire d'une constante littérale chaîne de caractères

Dans le cas d'un programme s'exécutant sur une machine dotée d'un système d'exploitation (typiquement, un PC), sauf lorsqu'elle constitue la valeur d'initialisation dans la déclaration d'une chaîne de caractères codée comme un tableau (ce cas particulier sera étudié infra ), toute constante littérale chaîne de caractères codée dans un programme (quelle que soit sa position dans le code) est a priori stockée dans le segment rodata de la zone statique allouée au programme lors de son exécution — autrement dit, le segment réservé pour les constantes statiques (cf. chap. C4‑2 ).

Dans le cas d'un programme s'exécutant sur une carte à microcontrôleur, du fait de l'absence de segment rodata, elles sont stockées dans le segment data, bien qu'il s'agisse de constantes. Comme cela a été souligné au chapitre C4‑2 ), elles sont donc vulnérables à d'éventuelles modifications par pointeur.
En principe, lorsque le programme comporte plusieurs occurrences de la même constante littérale chaîne de caractères, le compilateur est en général capable d'optimiser la taille du code exécutable en s'efforçant d'implémenter un seul stockage de cet chaîne de caractères.
Toutefois, le codage d'un saut de ligne final par une séquence d'échappement \n dans une chaîne de caractères peut engendrer des traitements différents du compilateur selon qu'elle figure comme argument effectif dans un appel d'une fonction d'affichage comme printf ou comme valeur d'initialisation d'une déclaration de donnée de type chaîne de caractères.
Considérons le programme académique suivant, codé dans un fichier nommé hello2x, qui consiste seulement à afficher deux fois la même chaîne de caractères "Hello", à l'aide de la fonction printf mais de deux manières différentes :
- d'abord directement comme chaîne de format (cf. la ligne n° 5) ;
- puis indirectement via la spécification de conversion
%set un pointeur (cf. la ligne n° 7).
#include <stdio.h>
int main(void)
{
printf("Hello");
char * str = "Hello";
printf("%s", str);
return 0;
}
Pour révéler la façon dont le stockage en mémoire est implémenté, on peut bien entendu procéder en scannant la mémoire comme on l'a fait dans les exemples précédents . Mais on peut aussi plus simplement, dans un terminal de commandes en ligne sous Linux, recourir aux outils de désassemblage du code exécutable du programme présentés au chapitre C4‑IV . En particulier, juste après la production du code exécutable, on peut appliquer la commande readelf avec l'option -x à la section .rodata du programme qui formera le segment rodata lors de l'exécution du programme :
gcc hello2x.c -o hello2xreadelf -x .rodata hello2xHex dump of section '.rodata': 0x00002000 01000200 48656c6c 6f002573 00 ....Hello.%s.
On voit donc que la section .rodata contient une seule occurrence de la constante littérale "Hello", et non pas deux. Le compilateur a donc effectivement optimisé le code exécutable.
Toutefois, le simple ajout d'un saut de ligne codé sous la forme de la séquence d'échappement \n dans la chaîne de caractères peut compromettre l'optimisation, comme on va le voir ci‑dessous avec la nouvelle version du programme.
#include <stdio.h>
int main(void)
{
printf("Hello\n");
char * str = "Hello\n";
printf("%s", str);
return 0;
}
Après les mêmes commandes de compilation et de désassemblage que supra, on obtient :
Hex dump of section '.rodata': 0x00002000 01000200 48656c6c 6f004865 6c6c6f0a ....Hello.Hello. 0x00002010 00257300 .%s.
Ici, il y a bel et bien 2 occurrences de ce qui semble être la même chaîne de caractères "Hello". Mais si l'on regarde attentivement, on s'aperçoit que la 2e comporte un saut de ligne (code 0a) mais pas la 1re. En fait, son saut de ligne a été intégré dans le code exécutable de la fonction d'affichage. Et donc, comme les deux constantes littérales sont différentes, elles sont stockées distinctement.
Remarques.
- Le cas de l'initialisation d'une donnée de type tableau par une constante littérale chaîne de caractères est traité infra .
- De plus, un exemple de modification indésirable d'une constante littérale chaîne de caractères est donné encore plus loin .
Particularité pour le framework Arduino
Dans le cadre de la programmation des cartes à microcontrôleur, le stockage des constantes littérales chaînes de caractères dans le segment data peut conduire à un encombrement significatif de l'espace mémoire réservé aux données (RAM). En effet :
- cet espace est souvent très limité – par exemple, seulement 2 ko de RAM sur dans le microcontrôleur Atmel ATmega328P qui équipe les cartes Arduino Uno et Nano (cf. chap. C1‑3 ) ;
- tout message textuel généré par le programme, qu'il soit envoyé sur le moniteur série ou un autre périphérique de sortie (écran LCD…) nécessite a priori le codage d'une constante littérale chaîne de caractères spécifique.
Même sans saturation de la RAM lors de la compilation, il est indispensable qu'il y reste suffisamment d'octets libres pour la pile et le tas lors de l'exécution du programme (cf. chap. C4‑2 ).
Pour remédier aux problèmes potentiels d'encombrement de la RAM, le framework Arduino met à disposition du codeur diverses macro‑définitions spéciales, notamment PROGMEM et F, détaillées ci‑dessous. Elles permettent de localiser des données dans la mémoire flash du microcontrôleur.
- La macro‑définition
PROGMEMA (pour program memory) est utilisable comme un mot‑clef modificateur dans le descripteur de type de la déclaration d'une donnée statique constante, typiquement un tableau de caractères. - La pseudo‑fonction
F(pour flash), quant à elle, s'appliquer à toute occurrence d'une constante littérale chaîne de caractères codée dans un argument effectif d'appel de fonction.
Pour les microcontrôleurs Atmel à cœur AVR, ces éléments de langages sont définis dans le fichier d'en‑tête avr/pgmspace.h G.
Rappelons qu'en plus de sa RAM, un microcontrôleur est doté d'un volume de mémoire flash (non volatile) notamment dédié au stockage du code exécutable du programme utilisateur – le segment text. Étant beaucoup plus grand que la RAM – par exemple, 32 ko dans le microcontrôleur Atmel ATmega328P – ce volume peut aussi être exploité pour y stocker des données.
Mais, outre le fait qu'elle complique le codage, l'exploitation de la mémoire flash pour les données présente un inconvénient : elle ralentit les opérations de lecture des données, puisque son temps d'accès est toujours très supérieur à celui d'une RAM. Elle est donc à employer seulement lorsqu'elle est vraiment nécessaire, c'est‑à‑dire pour stocker des données volumineuses qui risqueraient sinon de saturer la RAM du microcontrôleur.
Reprenons le programme déjà mentionné supra de démonstration d'un serveur web embarqué sur une carte Arduino équipée d'un shield Ethernet. Tel qu'il est donné au chap. R2‑IV , c'est‑à‑dire sans précautions particulières, le bilan de la compilation par le logiciel Arduino IDE sur un modèle de carte Uno est le suivant :
Le croquis utilise 16274 octets (50%) de l'espace de stockage de programmes. Le maximum est de 32256 octets. Les variables globales utilisent 961 octets (46%) de mémoire dynamique, ce qui laisse 1087 octets pour les variables locales. Le maximum est de 2048 octets.
Certes, lors de l'exécution, on n'observe aucun dysfonctionnement, parce que l'espace restant pour la pile et le tas (les variables locales) est suffisant au peu de données que les fonctions appelées manipulent. Mais on peut néanmoins observer que même avec une page web de taille extrêmement réduite, ce programme mobilise déjà 46 % de la RAM. Il suffirait donc que le code de la page web soit un peu plus long pour causer une saturation…
Pour montrer l'intérêt du stockage dans la mémoire flash, dans le programme ci‑dessous, appliquons les macro‑définition PROGMEM et F aux principales chaînes de caractères employées.
- On invoque la macro‑définition
PROGMENdans le descripteur de type de chacune des deux constantes déclarées chaînes de caractèresPAGE_HEADetPAGE_TAIL– cf. les lignes n° 10 & 19. - On applique la pseudo‑fonction
Faux constantes littérales chaînes de caractères constituant l'argument effectif des appels de fonctionsclient.printouclient.println– cf. les lignes n° 51, 52, 56 & 59.
reinterpret_cast C++) – cf. les lignes n° 54 & 61.
#include <SPI.h>
#include <Ethernet.h>
const int SPI_ETHERNET_PIN = 10; // pin number on board
byte mac[] = {0x90, 0xA2, 0xDA, 0x0D, 0x15, 0x43};
EthernetServer server(80);
const char PAGE_HEAD[] PROGMEM = R"=====(
<!DOCTYPE html>
<html lang='fr'>
<head>
<meta charset='utf-8'>
<title>Dynamic page Arduino</title>
</head>
)=====";
const char PAGE_TAIL[] PROGMEM = R"=====(
<h1> Dynamic page example embedded on Arduino board </h1>
<p><a href='./?bgcolor=white'>White</a>
<!-- 2 non‑break spaces here as inter-margin -->
<a href='./?bgcolor=yellow'>Yellow</a></p>
</body>
</html>
)=====";
void setup()
{
Ethernet.init(SPI_ETHERNET_PIN);
Ethernet.begin(mac);
// Serial.begin(115200); // only for debug
}
void loop()
{
EthernetClient client = server.available();
if (client) {
String clientRequest = "";
bool currentLineIsBlank = true;
while (client.connected()) {
if (client.available()) {
char c = client.read();
if (clientRequest.length() < 25) {
clientRequest += c;
// Serial.write(c); // only for debug
}
if (c == '\n' && currentLineIsBlank) {
client.println(F("HTTP/1.1 200 OK"));
client.println(F("Content-Type: text/html"));
client.println(); // blank line, start of response body
client.println(reinterpret_cast <const __FlashStringHelper*> (PAGE_HEAD));
if (clientRequest.indexOf("bgcolor=yellow") > 0) {
client.print(F("<body style='background: yellow'>"));
}
else {
client.print(F("<body style='background: white'>"));
}
client.println(reinterpret_cast <const __FlashStringHelper*> (PAGE_TAIL));
break;
}
if (c == '\n') {
currentLineIsBlank = true;
}
else if (c != '\r') {
currentLineIsBlank = false;
}
}
}
delay(1); // give the web browser time to receive the data
client.stop();
}
}
Le bilan de la compilation par le logiciel Arduino IDE est alors le suivant :
Le croquis utilise 16332 octets (50%) de l'espace de stockage de programmes. Le maximum est de 32256 octets. Les variables globales utilisent 561 octets (27%) de mémoire dynamique, ce qui laisse 1487 octets pour les variables locales. Le maximum est de 2048 octets.
On voit donc que la RAM n'est maintenant occupée qu'à seulement 27 % (contre 46 % avant), et ce sans que la mémoire flash ait été significativement impactée (toujours environ 50 %).
Pour aller plus loin…
Les données de type chaîne de caractères en langage C
Comme cela a été brièvement expliqué au chapitre C2‑VII et rappelé en introduction du présent chapitre, en langage C, il n'existe pas de type de donnée chaîne de caractères à proprement parler, c'est‑à‑dire qui permettrait de stocker en mémoire une séquence de caractères pouvant librement varier en longueur durant l'exécution du programme.
Dans un programme codé C, pour déclarer une donnée de type « chaîne de caractères », on est donc contraint d'employer :
- soit un tableau de caractères qui peut être initialisé de façon globale avec une syntaxe similaire à celle d'une constante littérale chaîne de caractères, mais qui n'en est pas une ; c'est le type recommandé pour une variable ;
- soit un pointeur sur caractères, dont la valeur initiale est l'adresse ciblant une constante littérale chaîne de caractères ; c'est une alternative acceptable lorsque l'on veut déclarer une constante ;
Dans tous les cas, on parle de chaîne de « style C » – C‑style string en anglais W.
Pour fixer dores et déjà les idées, les deux façons de déclarer une chaîne de caractères de style C peuvent être illustrées respectivement par les exemples académiques suivants :
- Comme un tableau de caractères :
char str[] = "Hello, World\n";
char * str = "Hello, World\n";

Il est primordial de ne pas confondre ces deux syntaxes char id[] et char * id. En effet, comme on va le voir, les données ainsi déclarées ont des propriétés fondamentalement différentes.
En langage C++, même s'il existe d'autres solutions plus évoluées (typiquement, la classe string – cf. infra ), il est toujours possible d'employer des chaînes de style C.
Déclaration d'une donnée de type tableau de caractères
Dans un programme en langage C ou C++, la déclaration d'une variable de type chaîne de style C se code préférentiellement via la même syntaxe que pour un tableau unidimensionnel (cf. chap. C5‑III ), avec les particularités suivantes :
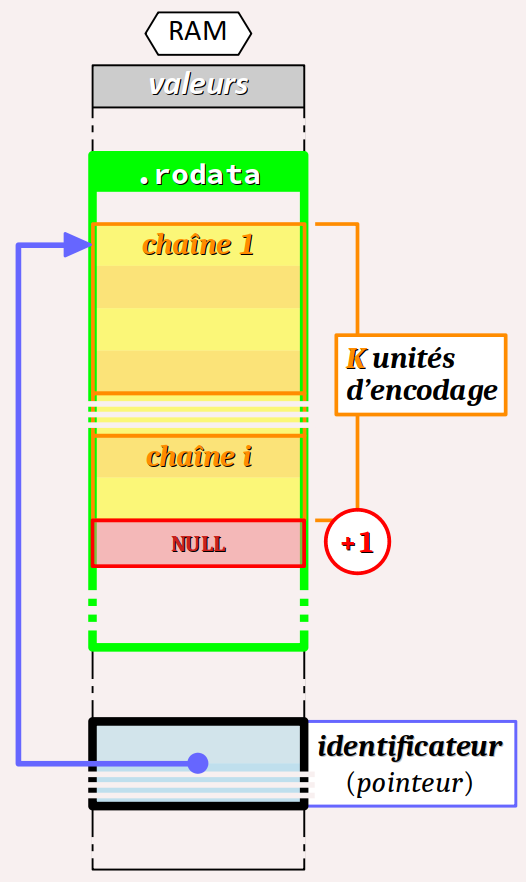
type de caractère identificateur[N] = chaîne 1 chaîne 2 ;
Dans cette syntaxe particulière, on peut apporter les précisions suivantes.
- Comme dans toute déclaration, on peut intégrer des mots‑clefs modificateurs comme
const(cf. chap. C2‑III ) et/oustatic(cf. chap. C4‑II et C4‑VI ). En revanche, le codage du mot‑clefregistern'a aucun effet, puisqu'une chaîne est potentiellement un objet trop gros pour être stockée en registre. - Le type de caractère codé peut éventuellement nécessiter le codage préalable d'une directive d'inclusion de fichier d'en‑tête de bibliothèque – par exemple,
uchar.hpour les typeschar16_tetchar32_t. - L'identificateur est le nom de la donnée. Comme pour tout identificateur de tableau, une occurrence ultérieure de cet identificateur dans le code est, sauf exceptions, dégradée en un pointeur (cf. chap. C5‑III ). On peut donc lui appliquer l'opérateur d'indexation
[]pour cibler les éléments du tableau. - Comme pour toute déclaration de tableau, le nombre d'éléments N est une expression optionnelle si l'initialisation est codée. Il doit s'agir une expression constante entière (cf. chap. C2‑II ) – en C++, simplement une expression constante ou une expression évaluable, selon la classe d'allocation.
- Les expressions optionnelles d'initialisation chaîne 1, chaîne 2… chaîne i doivent être codées conformément à la syntaxe des constantes littérales chaînes de caractères décrite supra , sachant que :
- leur éventuel préfixe d'encodage doit être compatible avec le type de caractère déclaré ;
- ces chaînes sont assemblées l'un après l'autre par concaténation pour constituer une liste unique de caractères formant les valeurs initiales des éléments ordonnés du tableau déclaré. Au total, le nombre K d'unités d'encodage nécessaires pour tous ces caractères doit être inférieur ou égal à la valeur de N − 1 si le nombre d'éléments du tableau N est codé. En son absence, la taille du tableau est automatiquement fixée à la valeur K + 1 pour inclure automatiquement le caractère de fin de chaîne NUL.
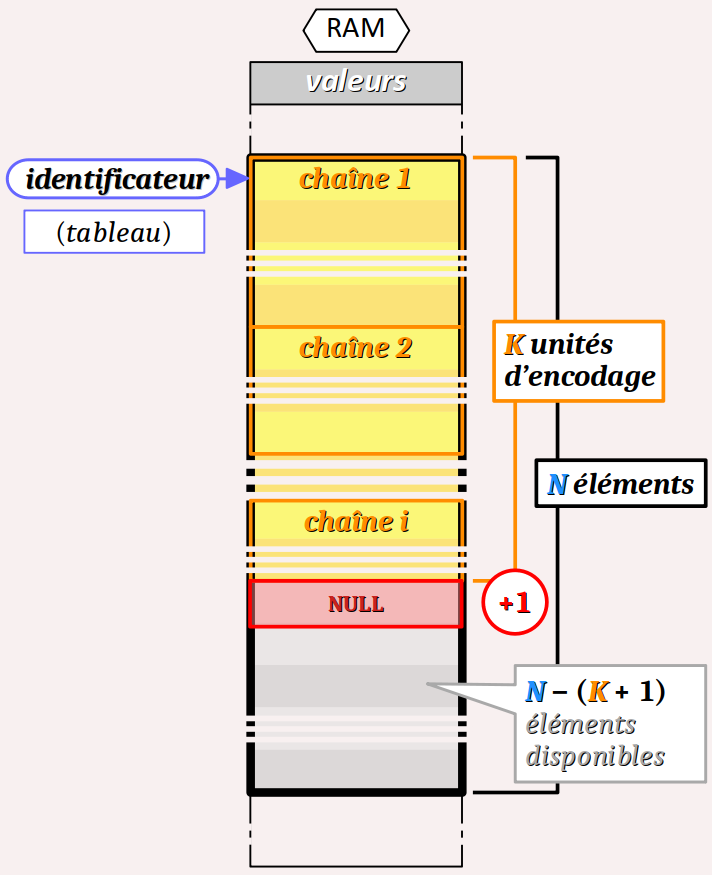
Le fait de pouvoir coder la valeur initiale de la variable de caractères en plusieurs parties chaîne 1, chaîne 2… est utile pour coder une longue chaîne sur plusieurs lignes dans le fichier source. En effet, cela n'est pas possible avec une seule chaîne – cf. supra – sauf si on code une chaîne brute ou si l'on code à la fin de chaque ligne un saut de ligne fictif via le caractère de contrôle \).
Il est également possible, comme pour tout tableau, de coder l'initialisation de la chaîne sous la forme d'une liste d'éléments, chacun constituant un caractère de la chaîne, comme ci‑dessous :
= {c0, c1, c2, };
Dans ce cas, il faut ne pas oublier de coder en dernier le caractère de fin de chaîne NUL (0x0) car, via cette syntaxe, il n'est pas automatiquement ajouté par le compilateur.
La déclaration académique ci‑dessous :
static char str[] = "Foo" "Bar";
crée dans le segment data de la mémoire allouée au programme une variable nommée str de type tableau de 7 caractères ASCII ou 7 unités d'encodage UTF‑8 (selon l'implémentation) initialisés respectivement dans leur ordre d'indexation avec les valeurs de la liste ci‑dessous :
{'F', 'o', 'o', 'B', 'a', 'r', 0x0}
On peut le vérifier grâce au programme ci‑dessous, codé dans un fichier nommé arraystr.c qui exploite une technique de scan mémoire similaire à celle développée dans les exemples précédent .
- La seule différence est que, comme la chaîne de caractères
strest déclarée comme un tableau, il n'est pas nécessaire de déclarer un pointeur pour la parcourir. On peut procéder par indexation directestr[i]oùiest la variable d'itération d'une bouclefor(cf. la ligne nº 10). - Par ailleurs, pour fixer la condition de répétition de cette boucle, on utilise tout simplement le nombre d'éléments
ndu tableaustr, obtenu grâce à l'opérateursizeof(cf. la ligne nº 7).
#include <stdio.h>
#include <ctype.h>
int main(void)
{
static char str[] = "Foo" "Bar";
size_t n = sizeof(str);
printf("%s\t\t%zu bytes\n", str, n);
for (unsigned i = 0; i < n; i++) {
if (isprint(str[i]))
printf("%p\t[%d]\t%c\n", (void *) &str[i], i, str[i]);
else // non printable character
printf("%p\t[%d]\t0x%X\n", (void *) &str[i], i, (unsigned char) str[i]);
}
return 0;
}
Compilé et exécuté dans un terminal de commandes en lignes, ce programme produit en sortie standard l'affichage attendu suivant :
gcc arraystr.c -o arraystr && ./arraystrFooBar 7 bytes 0x5829815b3010 [0] F 0x5829815b3011 [1] o 0x5829815b3012 [2] o 0x5829815b3013 [3] B 0x5829815b3014 [4] a 0x5829815b3015 [5] r 0x5829815b3016 [6] 0x0
Et grâce à la commande readelf mise en œuvre comme dans les exemples précédents (cf. supra ), on peut facilement vérifier que :
- aucune constante littérale
"FooBar"n'est inscrite dans la section.rodatadu programme exécutable (en revanche, on y retrouve les 3 chaînes de format codées dans chacun des 3 appels respectifs deprintfdu programme source – cf. les lignes nº 8, 12 & 14) :
readelf -x .rodata arraystrHex dump of section '.rodata': 0x00002000 01000200 25730909 257a7520 62797465 ....%s..%zu byte 0x00002010 730a0025 70095b25 645d0925 630a0025 s..%p.[%d].%c..% 0x00002020 70095b25 645d0930 7825580a 00 p.[%d].0x%X..
0x0 sont bien dans la section .data : readelf -x .data arraystrHex dump of section '.data': 0x00004000 00000000 00000000 08400000 00000000 .........@...... 0x00004010 466f6f42 617200 FooBar.
Par ailleurs, si on remplace la ligne n° 6 du programme précédent par la déclaration ci‑dessous où le nombre d'éléments de str est codé avec une valeur surdimensionné 10 :
static char str[10] = "Foo" "Bar";
alors on obtient évidemment une sortie plus longue puisque la boucle for parcourt maintenant 10 éléments et non plus seulement 7 :
FooBar 10 bytes 0x58a919d2c010 [0] F 0x58a919d2c011 [1] o 0x58a919d2c012 [2] o 0x58a919d2c013 [3] B 0x58a919d2c014 [4] a 0x58a919d2c015 [5] r 0x58a919d2c016 [6] 0x0 0x58a919d2c017 [7] 0x0 0x58a919d2c018 [8] 0x0 0x58a919d2c019 [9] 0x0
On voit alors apparaître les 3 éléments vacants du tableau situés après le caractère de fin de chaîne 0x0, qui sont tous nuls également puisque la variable est stockée dans la zone statique de l'espace mémoire attribué au programme. Ces éléments ne sont pas forcément perdus : ils pourraient éventuellement être utilisés dans la suite du programme.
Mais si on code plutôt un nombre d'éléments sous‑dimensionné dans la déclaration du tableau str, par exemple :
static char str[5] = "Foo" "Bar";
alors, même sans options spécifiques, on obtient un avertissement du compilateur et, dans les éléments du tableau str, une chaîne ayant un contenu tronqué par rapport à la valeur initiale codée :
gcc arraystr.c -o arraystr && ./arraystrarraystr.c: In function 'main': arraystr.c:6:24: warning: initializer-string for array of 'char' is too long 6 | static char str[5] = "Foo" "Bar"; | ^~~~~ FooBa 5 bytes 0x64f75c3d0010 [0] F 0x64f75c3d0011 [1] o 0x64f75c3d0012 [2] o 0x64f75c3d0013 [3] B 0x64f75c3d0014 [4] a
Et en particulier, le dernier caractère de la chaîne n'est pas le caractère de fin de chaîne NUL. C'est un défaut majeur qui la rend inapte aux fonctions de la bibliothèque standard de traitement des chaînes de caractères (cf. infra ).
Déclaration d'une donnée de type pointeur de caractères
Dans un programme en langage C ou C++, on peut aussi déclarer une donnée de type chaîne de style C comme un pointeur de caractère (cf. chap. C5‑I ), avec les particularités suivantes :
type de caractère * identificateur = chaîne 1 chaîne 2 ;
En ce qui concerne :
- le type de caractère ;
- les expressions chaîne 1, chaîne 2 … chaîne i ;
- et même l'identificateur – puisqu'il s'agit d'un pointeur on peut donc aussi lui appliquer l'opérateur d'indexation
[](cf. chap. C5‑III ) ;
on peut apporter les mêmes précisions que pour la déclaration d'une chaîne de caractères de type tableau (cf. supra ).
En revanche, on doit prendre conscience des différences cruciales suivantes.
- La variable ainsi déclarée n'est pas véritablement une chaîne de caractères mais un pointeur sur une constante littérale chaîne de caractères. Donc :
- Sa taille est invariablement celle d'un pointeur – typiquement, 8 octets sur une machine à architecture x86‑64 bits.
- Rien n'interdit de coder une affectation ultérieure à cette variable pointeur une autre adresse de donnée d'un type compatible (éventuellement via une conversion explicite), en particulier une autre constante littérale chaîne de caractères.
- La position d'un éventuel mot‑clef
constajouté dans le descripteur de type n'est pas indifférente – cf. la distinction exposée au chap. C5‑I entre : - un pointeur constant, dont la déclaration commence par
char * const, et interdit toute affectation ultérieure au pointeur après son initialisation ; - et un pointeur en « lecture seule », dont la déclaration commence par
const char *, et qui interdit toute modification de la donnée pointée (sachant que c'est déjà impossible puisque cette donnée est une constante littérale de type chaîne de caractères).
sizeof.) La déclaration académique ci‑dessous :
static char * str = "Foo" "Bar";
crée dans le segment .data de la mémoire allouée au programme une variable nommée str de type pointeur de caractère ASCII ou UTF‑8 (selon l'implémentation). La valeur de ce pointeur est l'adresse de la constante littérale "FooBar" stockée dans le segment .rodata.
En employant une méthode de scan mémoire similaire à celle des exemples supra , le résultat de cette déclaration peut être observé à l'aide du programme ci‑dessous :
#include <stdio.h>
#include <ctype.h>
const char RODATA_START = '#';
char data_start = '$';
int main(void)
{
static char * str = "Foo" "Bar";
printf("%s\t\t%zu bytes\n", str, sizeof(str));
printf("%p\t%c\t.data\n", &data_start, data_start);
printf("%p\t%p\tstr\n", &str, str);
printf("%p\t%c\t.rodata\n", &RODATA_START, RODATA_START);
char * p = str;
do {
if (isprint(*p))
printf("%p\t[%2ld]\t%c\n", p, p - str, *p);
else // non printable character
printf("%p\t[%2ld]\t0x%X\n", p, p - str, (unsigned char) *p);
}
while (*p++ != 0x0);
return 0;
}
Exécuté sur OnlineGDB, ce programme produit en sortie standard l'affichage suivant :
FooBar 8 bytes 0x5588dbce4010 $ .data 0x5588dbce4018 0x5588dbce2059 str 0x5588dbce2004 # .rodata 0x5588dbce2059 [ 0] F 0x5588dbce205a [ 1] o 0x5588dbce205b [ 2] o 0x5588dbce205c [ 3] B 0x5588dbce205d [ 4] a 0x5588dbce205e [ 5] r 0x5588dbce205f [ 6] 0x0
On peut ainsi vérifier que la variable str :
- a une taille de 8 octets, ce qui est bien celle d'un pointeur (ce n'est pas du tout la taille de la chaîne qu'elle pointe) ;
- est stockée dans le segment
.data; - prend pour valeur l'adresse
0x5588dbce2059qui est celle du premier octet de la constante littérale"FooBar"– laquelle est bien dans le segment.rodata.
Lecture et écriture des chaînes de caractères de style C
Cas d'une chaîne de caractères déclarée comme un tableau
Dans son espace de visibilité, une variable chaîne de caractères déclarée comme un tableau (cf. supra et le chap. C5‑IV ) :
- est accessible en lecture et en écriture, élément par élément, par exemple via une expression de la forme :
identificateur[i] = expression - mais ne peut pas faire l'objet d'une affectation globale par exemple via une expression de la forme :
identificateur = autre chaîne // build error
Dans le programme académique ci‑dessous, après avoir déclaré une chaîne de caractère de type tableau, on peut coder une modification de sa valeur élément par élément (cf. la ligne n° 8) :
#include <stdio.h>
int main(void)
{
char str[] = "Foo";
printf("%s\t(%p)\n", str, str);
str[0] = 'B', str[1] = 'a', str[2] = 'r'; // assignment char by char
printf("%s\t(%p)\n", str, str);
return 0;
}
Exécuté sur OnlineGDB, on obtient un affichage conforme au changement de valeur attendu :
Foo (0x7ffff813f354) Bar (0x7ffff813f354)
et l'on peut constater que l'adresse de str ne change pas.
En revanche, si l'on tente de coder une affectation globale, par exemple :
str = "Bar"; // global assignment: won't work here!
alors, comme prévu, le compilateur signale une erreur :
main.c:8:7: error: assignment to expression with array type
8 | str = "Bar"; // global assignment: won't work here!
| ^
Cas d'une chaîne de caractères déclarée comme un pointeur
Dans son espace de visibilité, une variable chaîne de caractères déclarée comme un pointeur (cf. supra et le chap. C5‑I ) :
- permet d'accéder élément par élément à la constante littérale qu'elle pointe en lecture, mais pas en écriture via une expression de la forme :
identificateur[i] = expression // segment fault
puisqu'il s'agit d'une constante ; - mais peut faire l'objet d'une « affectation globale » pour pointer sur une autre constante littérale, par exemple via une expression de la forme :
identificateur = autre chaîne
sauf bien entendu si la donnée a été déclarée comme un pointeur constant (cf. chap. C5‑I ).
Ici, il est essentiel comprendre que toute « affectation « globale » sur une chaîne de caractères déclarée comme un pointeur ne modifie pas la constante littérale pointée. En effet :
- cette dernière reste stockée telle quelle dans le segment
.rodata; - simplement la valeur du pointeur change d'adresse pour pointer sur la constante littérale autre chaîne qui constitue la r‑value de l'affectation, et qui est stockée ailleurs dans le segment
.rodata.
Dans le programme académique ci‑dessous, après avoir déclaré la chaîne de caractère de type pointeur str (cf. la ligne n° 5), on peut coder une affectation « globale » (cf. la ligne n° 8) qui consiste en fait à faire pointer str sur une autre constante littérale de type chaîne de caractères :
#include <stdio.h>
int main(void)
{
char * str = "Foo";
printf("%s\t(%p)\n", str, str);
str = "Bar"; // global assignment (OK)
printf("%s\t(%p)\n", str, str);
return 0;
}
Exécuté sur OnlineGDB, on obtient un affichage conforme à celui attendu :
Foo (0x5631624e2004) Bar (0x5631624e2013)
sachant que ce n'est pas la constante littérale Foo qui a été modifiée, mais simplement la valeur de str qui pointe sur une autre constante littérale – Bar.
En revanche, si l'on tente de coder une affectation sur un des éléments de la constante littérale sur laquelle str pointe, par exemple :
str[0] = 'B'; // assignment on elements: won't work here…
alors le programme semble s'exécuter, mais avec un affichage non conforme à ce qui est attendu :
Foo (0x562c9bde9004)
Il n'y pas de 2e ligne ! En fait, si on effectue la même expérience avec GCC sur un PC Linux, on constate directement une erreur de segmentation :
Segmentation fault (core dumped)
Transmission d'une chaîne de caractères de style C comme argument de fonction
Rappelons qu'en langage C (cf. chap. C5‑IV ), la transmission d'un tableau comme argument de fonction peut être codée seulement par adresse – ou, éventuellement, par référence en C++.
Lorsqu'on procède par adresse, dans l'en‑tête de la fonction, un tel argument formel est donc un pointeur. L'usage fait qu'il est le plus souvent codé comme tel, c'est‑à‑dire via la syntaxe :
descripteur de type * identificateur
surtout si l'argument est manipulé comme un pointeur dans le corps de définition de la fonction.
Bien entendu, il est toujours possible d'employer la syntaxe alternative équivalente :
descripteur de type identificateur[]
ce qui est plus plus lisible, surtout si l'argument est manipulé via l'opérateur d'indexation.
Cette équivalence des deux syntaxes possible pour coder un argument formel dans l'en‑tête d'une fonction est sans doute une grande source de confusion pour un codeur débutant à qui l'on vient juste d'expliquer qu'il ne faut surtout pas confondre ces deux syntaxes pour la déclaration d'une donnée de type chaîne de caractères (cf. supra ).
Rappelons (cf. chap. C5‑IV ) également que la transmission d'un tableau sous la forme d'un argument formel de type pointeur présente deux difficultés.
- On subit la perte d'information du nombre d'éléments du tableau.
- On a la possibilité inhérente de modification de l'argument effectif.
const avant le descripteur de type de l'argument formel lorsqu'on souhaite s'assurer que la fonction ne puisse opérer aucune modification sur l'argument effectif. Au regard de ces considérations, dans le cas particulier des arguments de fonction de type chaîne de caractères de style C, on peut retenir donc les deux règles suivantes :
- Si une fonction modifie un argument formel, alors dans toute expression d'appel, l'argument effectif correspondant doit obligatoirement être une variable déclarée comme un tableau.
- Si une fonction ne modifie pas un argument formel, alors dans toute expression d'appel, l'argument effectif correspondant peut être indifféremment déclaré comme un tableau, un pointeur, ou même simplement être une constante littérale.
- Dans le programme ci‑dessous, on code une fonction
toupperStringdont le but est de mettre en lettres majuscules toute une chaîne de caractères ASCII prise comme argument formel unique. Cet argument est donc modifié par la fonction. - la fonction
islowerpour déterminer si un caractère est une lettre minuscule (lowercase) ; - la fonction
toupperqui retourne la majuscule (uppercase) correspondant à une minuscule. - Dans le programme ci‑dessous, on code une fonction
wordCountqui compte le nombre de mots dans une chaîne de caractères ASCII prise comme argument formel en lecture seule.
ctype.h, cf. chap. C3‑VIII ) :
#include <stdio.h>
#include <ctype.h>
void toupperString(char * str)
{
do {
if (islower(*str)) *str = toupper(*str);
}
while (*++str);
}
int main(void)
{
char fbs[] = "Foo bar.";
printf("%s\n", fbs);
toupperString(fbs);
printf("%s\n", fbs);
return 0;
}
toupperString ne peut être appelée qu'avec pour argument effectif une chaîne de caractère déclarée comme un tableau. Et c'est bien le cas dans la fonction main du programme ci‑dessus (cf. la ligne n° 15). Foo Bar. FOO BAR.
fbs était déclarée comme un pointeur – c'est‑à‑dire, pourtant exactement comme dans l'en‑tête de la fonction : char * fbs = "Foo bar."; // will cause a segment fault!
Foo Bar.
Erreur de segmentation (core dumped)
isalnum déclarée dans le fichier d'en‑tête ctype.h de la bibliothèque standard du langage C (cf. chap. C3‑VIII ). Elle détecte les caractères alphanumériques, ce qui permet de les distinguer des autres catégories de caractères (espace, signes de ponctuation) qui ne constituent pas les mots.
#include <stdio.h>
#include <ctype.h>
size_t wordCount(const char * str)
{
size_t count = 0;
int isWord = 0; // bool value
do {
if (isalnum(*str)) {
if (!isWord) isWord = 1, count++;
}
else isWord = 0;
}
while (*++str);
return count;
}
int main(void)
{
char * fbs = "Foo bar.";
printf("\"%s\" contains %zu words\n", fbs, wordCount(fbs));
return 0;
}
wordCount peut être appelée avec n'importe quel argument effectif de type chaîne de style C, qu'il soit déclaré comme un tableau, un pointeur (cf. la ligne n° 21), ou même qu'il soit une constante littérale. "Foo bar." contains 2 words
Remarque. Dans les deux programmes ci‑dessus, la clause qui détermine la fin de boucle :
while (*++str);
teste :
Retour d'une chaîne de caractères de style C comme valeur de fonction
Rappelons qu'en langages C et C++ (cf. chap. C5‑IV ), à quelques exceptions près, il n'est pas possible de former une expression dont la valeur est un tableau.
Par conséquent, une fonction ne peut pas retourner une telle valeur, seulement un pointeur sur une variable préalablement déclarée de type tableau, qui doit également être transmise comme argument de la fonction.
Ces considérations restent valables pour les chaînes de caractères de style C, quel que soit leur type de déclaration. Elles ne sont pas commodes à retourner comme valeur de fonction.
Et c'est pourquoi en langage C++, on se tourne de préférence vers des objets de la classe string.
Longueur, capacité et taille en mémoire d'une chaîne de caractères de style C
Notion de longueur
En langages C et C++, on considère que la longueur d'une chaîne de caractères est le nombre d'unités d'encodage – on parle usuellement de nombre d'éléments – nécessaires pour représenter ses caractères en mémoire.
Dans le cas d'une chaîne de style C, le caractère de fin de chaîne NUL est exclus du compte pour déterminer sa longueur.
La longueur d'une chaîne de caractères est donc :
- égale à son nombre de caractères, si son format d'encodage est à taille fixe – typiquement, ASCII et UTF‑32 ;
- plus grande que son nombre de caractères si son format d'encodage est à taille variable – typiquement, UTF‑8 et UTF‑16.
On peut facilement coder une fonction qui retourne la longueur d'une chaîne, comme par exemple la solution très classique ci‑dessous pour les chaînes ASCII et UTF‑8 :
size_t stringLength(const char * str)
{
size_t length = 0;
while (*str++) length++;
return length;
}
Remarque. Il existe des solutions plus optimisées et robustes déjà codées dans la bibliothèque standard du langage C (cf. infra ).
Par ailleurs, pour compter le nombre de caractères d'une chaîne encodée en UTF‑8, on peut coder comme ci‑dessous une variante de la fonction ci‑dessus à peine plus complexe :
size_t u8stringLength(const char * str)
{
size_t length = 0;
do { // does not count trailing bytes
length += (*str & 0b11000000) != 0b10000000;
}
while (*++str);
return length;
}
dans laquelle, pour chaque caractère, on ne compte pas les octets de suite (trailing bytes), c'est‑à‑dire ceux qui présentent le motif initial binaire 10 (cf. chap. C3‑IX ).
Notion de capacité
En complément de la notion de longueur, la capacité d'une chaîne de caractères est tout simplement le nombre maximal d'unités d'encodage qu'elle peut accepter, au regard de l'espace mémoire qui lui est alloué.
Dans le cas d'une chaîne de style C, cette notion n'a de sens que si elle est déclarée comme un tableau. Sa capacité est alors N − 1 où N est le nombre d'éléments du tableau.
En rappel des connaissances acquises sur les tableaux au chapitre C5‑IV, pour déterminer la capacité d'une chaîne de stype C, on peut :
Taille en mémoire
Quant à la taille en mémoire d'une chaîne de caractères – qu'on peut obtenir directement avec l'opérateur sizeof – elle est égale au produit (×) de la taille du type d'encodage des caractères par :
- le nombre total d'éléments du tableau dans le cas d'une donnée déclarée comme tel ;
- le nombre total d'unités d'encodage – caractère de fin de chaîne NUL inclus – dans le cas d'une constante littérale.
Le programme académique ci‑dessous permet de tester les fonctions de calcul codées ci‑dessus avec la chaîne de style C donnée en exemple dans l'introduction du chapitre (cf. supra ).
#include <stdio.h>
#define nbOfElements(tab) (sizeof(tab)/sizeof(tab[0]))
size_t stringLength(const char * str)
{
size_t length = 0;
while (*str++) length++;
return length;
}
size_t u8stringLength(const char * str)
{
size_t length = 0;
do { // does not count trailing bytes
length += (*str & 0b11000000) != 0b10000000;
}
while (*++str);
return length;
}
int main(void)
{
char str[15] = "I ♥ GCC\n";
printf("%s", str);
printf("%2zu encoding units (length)\n", stringLength(str));
printf("%2zu UTF-8 characters\n", u8stringLength(str));
printf("%2zu bytes (size)\n", nbOfElements(str));
printf("%2zu bytes (capacity)\n", nbOfElements(str) - 1);
return 0;
}
Exécuté sur OnlineGDB, il produit sans surprise en sortie standard l'affichage attendu :
I ♥ GCC 10 encoding units (length) 8 UTF-8 characters 15 bytes (size) 14 bytes (capacity)
Fonctions de la bibliothèque standard sur les chaînes de style C
Généralités
Les chaînes de caractères étant des objets complexes et néanmoins très utilisés en langages C, il existe une plusieurs dizaines de fonctions dans la bibliothèque standard afin d'analyser et de manipuler facilement les chaînes de style C.
En particulier, pour les chaînes dont les unités d'encodage sont de type char, c'est‑à‑dire au format ASCII ou UTF‑8 C :
- Le fichier d'en‑tête
string.h(cstringen C++) regroupe la grande majorité des prototypes des fonctions d'analyse et de manipulation (détermination de la longueur, recherche de caractères et de motifs, recopie, concaténation, etc.). - Le fichier d'en‑tête
stdlib.hcontient les prototypes des fonctions d'interprétation numérique de valeurs codées dans une chaîne de caractères selon les différents types standards du langage (int,long,double, etc.).
Par ailleurs, il existe d'autres fonctions plus spécialisées pour le traitement :
- Dans le fichier d'en‑tête
stdlib.h, on trouve des fonctions sur les chaînes de caractères dites « multibyte » C, c'est‑à‑dire dont les unités d'encodage sont de typecharmais potentiellement multiples pour un caractère donné – typiquement, au format UTF‑8. Ces fonctions comportent le motif «mb» (pour multibyte) dans leur identificateur. - Dans le fichier d'en‑tête
wchar.h, on trouve des fonctions sur les chaînes de caractères dites « wide » C, c'est‑à‑dire dont les unités d'encodage sont de typewchar_t.
Enfin, les fonctions ayant un nom qui commence par mem (et non pas str) sont particulièrement polyvalentes :
- Leurs arguments formels principaux sont de type pointeur générique
void *(cf. chap. C5‑II ). - Il en résulte que dans une expression d'appel, les arguments effectifs correspondant peuvent être déclarés indifféremment de type
char[]ouunsigned char[].
Ces fonctions peuvent donc agir sur des suites d'octets et non pas seulement sur des chaînes de caractères.
Dans le cadre de ce chapitre, une présentation exhaustive de ces fonctions n'est pas envisageable. L'objectif est d'apporter un mode d'emploi basique des fonctions les plus usuelles, chacune dans sa variante la plus simple.
Quant aux fonctions spécialisées mentionnées ci‑dessus, elles ne seront pas abordées, là encore pour des questions de volume de documentation.
Systématiquement, des liens vers des pages de référence sont données pour accéder à plus de détails si nécessaire.
Chaque fonction possède plusieurs variantes, dont certaines sont dites sécurisées – elles sont reconnaissables au suffixe « _s » à la fin de leur identificateur.
En règle générale, ces variantes sécurisées imposent des restrictions de typage des arguments et produisent des codes d'erreurs pour faciliter le diagnostic des scénarios de fonctionnement. Dans un premier temps, il n'est pas forcément utile d'y recourir.
Fonctions d'analyse d'une chaîne de caractères
Détermination de la longueur d'une chaîne de caractères
Il n'existe qu'une seule fonction pour déterminer la longueur d'une chaîne de caractères de style C C :
// string length size_t strlen(const char * str);
La valeur retournée par la fonction strlen est le nombre d'unités d'encodage – c'est‑à‑dire d'octets – de l'argument str, sachant que le caractère de fin de chaîne NUL est exclu du compte (cf. supra ).
Dans l'environnement OnlineGDB, on teste les appels de la fonction strlen suivants.
- Après la déclaration
char s[8] = "abc";l'appelstrlen(s)retourne la valeur3qui est, de façon évidente, la longueur de la chaînes. - Après la déclaration
char s[8] = "a\0bc";l'appelstrlen(s)retourne la valeur1. Ici, la séquence d'échappement'\0'– le caractère NUL – explicitement codé marque la fin desdonc raccourcit sa longueur. - Après la déclaration
char s[8] = "😉";l'appelstrlen(s)retourne la valeur4. Rappelons en effet que la longueur d'une chaîne composée en UTF‑8 avec des caractères non ASCII est forcément plus grande que son nombre apparent de caractères : c'est son nombre d'unités d'encodage .
str (ici, 8) et le caractère de fin de chaîne NUL ne sont pas pris en compte dans la valeur retournée par la fonction strlen. Recherche d'un caractère ou d'un motif dans une chaîne
Les trois fonctions de recherche présentées ci‑après sont les plus usuelles. Elles admettent deux arguments formels non modifiés :
- le premier, nommé
str, est la chaîne de style C dans laquelle la recherche s'effectue ; - le deuxième est le motif cherché ; il peut s'agir d'un caractère (
ch) ou d'une sous‑chaîne (substr).
Systématiquement, la valeur retournée, de type char *, est un pointeur dans str.
Première occurrence d'un caractère dans une chaîne C
// string character char * strchr(const char * str, int ch);
Attention. L'argument formel ch, bien que déclaré de type int dans l'en‑tête de la fonction, est converti dans le type char dans le corps de définition de la fonction.
C'est pourquoi, dans l'appel de la fonction strchr, son argument effectif correspondant ne doit donc prendre qu'une valeur d'encodage comprise entre 0x00 et 0xFF. Ce faisant, il peut éventuellement être codé comme une valeur de caractère entre guillemets simples '' ou comme une séquence d'échappement.
La valeur retournée par la fonction strchr est :
Dans le programme ci‑dessous, la fonction htmlWordCount effectue un comptage des mots de texte d'une page web (partielle) codée en HTML/CSS, ici intégrée sous la forme d'une chaîne de caractères brute (cf. supra ).
Or en langage HTML, les mots de texte sont codés hors des balises. C'est pourquoi il faut repérer :
- les fins de balise
'>'pour commencer ou reprendre le comptage ; - les débuts de balise
'<'suspendre le comptage.
Pour aller à une fin de balise, on appelle la fonction strchr (cf. la ligne n° 11). Ensuite, on scanne le texte caractère par caractère en incrémentant le nombre de mot à chaque caractère non alphanumérique rencontré, jusqu'à atteindre le début de la balise suivante.
#include <stdio.h>
#include <ctype.h>
#include <string.h>
int htmlWordCount(const char * str)
{
int count = 0;
int isWord = 0; // bool value
do {
// end of HTML tag means (re)start of text
str = strchr(str, '>');
if (str == NULL) break;
do {
// symbols in the text are not considered as words
if (isalnum(*str)) {
if (!isWord) isWord = 1, count++; // start of a new word
}
else isWord = 0;
str++;
}
while (*str != '<' && *str != 0);
// beginning of HTML tag means end of text
}
while (*str != 0);
return count;
}
const char PAGE_TAIL[] = R"=====(
<h1> Dynamic page example embedded on Arduino board </h1>
<p><a href='./?bgcolor=white'>White</a>
<!-- 2 non‑break spaces here as inter-margin -->
<a href='./?bgcolor=yellow'>Yellow</a></p>
</body>
</html>
)=====";
int main(void)
{
printf("%d words\n", htmlWordCount(PAGE_TAIL));
return 0;
}
Exécuté sur OnlineGDB, ce programme produit en sortie standard l'affichage attendu :
9 words
puisque le code HTML de la chaîne de caractères traitée ne compte que les 9 mots ci‑dessous :
Dynamic page example embedded on Arduino board White Yellow
Dernière occurrence d'un caractère dans une chaîne C
// string reverse character char * strrchr(const char * str, int ch);
La fonction strrchr opère comme strchr (cf. supra ) mais dans l'ordre inverse des caractères de la chaîne str – donc en partant de la fin.
Une telle fonction est particulièrement utile pour des chaînes de caractères où les données les plus récentes sont concaténées à la fin (fichiers de log, relevés de mesure, etc.).
Première occurrence d'un motif dans une chaîne C
// string (sub)string char * strstr(const char * str, const char * substr);
La fonction strstr opère comme strchr (cf. supra ) mais en recherchant dans str la première occurrence de la sous‑chaîne substr. Si cette dernière est la chaîne vide "", la valeur retournée est celle du pointeur str.
La fonction strstr permet notamment de rechercher dans une chaîne de caractères encodée en UTF‑8 n'importe quel caractère hors du jeu ASCII restreint (donc encodé sur plusieurs octets).
Dans le programme académique ci‑dessous, on recherche dans la chaîne mess la première occurrence du caractère UTF‑8 « ô » (cf. la ligne n° 7).
#include <stdio.h>
#include <string.h>
int main(void)
{
char * mess = "À bientôt !";
printf("%s", strstr(mess, "ô"));
return 0;
}
Comme prévu, avec OnlineGDB, on obtient en sortie standard l'affichage :
ôt !
Fonctions avancées d'analyse
Les trois fonctions avancées d'analyse présentées ci‑après admettent, comme les fonctions de recherche deux arguments formels non modifiés :
Recherche d'un segment initial composé dans un alphabet dans une chaîne C
// string span size_t * strspn(const char * dest, const char * src);
La fonction strspn retourne la longueur du segment initial de la chaîne dest qui est composé exclusivement avec les éléments listés dans la chaîne src.
Attention ! La valeur retournée n'est pas un pointeur ni un indice mais une longueur de segment – la valeur 0 signifiant l'absence de segment identifié.
En complément avec strcspn (cf. infra ), la fonction strspn est particulièrement utile pour délimiter une chaîne numérique au sein d'un texte.
Dans l'environnement OnlineGDB, on teste les appels de la fonction strspn suivants ou l'argument formel scr prend la valeur "0123456789" pour lister tous les chiffres décimaux.
- L'expression
strspn("123abc", "0123456789")prend la valeur3qui est, de façon évidente, la longueur du segment initial numérique123dans l'argument effectif correspondant à la chaînedest. - L'expression
strspn("abc123", "0123456789")prend la valeur0car l'argument effectif correspondant à la chaînedestne commence pas par un chiffre (le segment123qui y figure n'est pas initial).
Remarque. Il n'est malheureusement pas toujours possible d'utiliser la fonction strspn pour détecter une chaîne numérique signée et/ou décimale simplement en ajoutant les symboles « - » et « . » dans la chaîne src. En effet, dans un texte général, des confusions potentielles seraient à craindre avec :
- des segments exprimant des soustractions, comme par exemple
12-34; - des segments exprimant des adresses IPv4, comme par exemple
192.168.10.1;
Recherche d'un segment initial composé hors d'un alphabet dans une chaîne C
// string complementary span size_t strcspn(const char * dest, const char * src);
La fonction strspn retourne la longueur du segment initial de la chaîne dest qui n'est composée d'aucun élément listé dans la chaîne src.
Attention ! La valeur retournée n'est pas un pointeur ni un indice mais une longueur de segment – la valeur 0 signifiant l'absence de segment identifié.
En complément avec strspn (cf. supra ), la fonction strspn est particulièrement utile pour délimiter une chaîne numérique au sein d'un texte.
Dans l'environnement OnlineGDB, on teste les appels de la fonction strcspn suivants ou l'argument formel scr prend la valeur "0123456789" pour lister tous les chiffres décimaux.
- L'expression
strcspn("abc123", "0123456789")prend la valeur3qui est, de façon évidente, la longueur du segment initial non numériqueabcdans l'argument effectif correspondant à la chaînedest. - L'expression
strcspn("123abc", "0123456789")prend la valeur0car l'argument effectif correspondant à la chaînedestcommence par un chiffre.
Première occurrence d'un élément d'alphabet dans une chaîne C
// string point break char * strpbrk(const char * dest, const char * breakset);
La fonction strpbrk retourne l'adresse du premier élément de la chaîne dest qui figure dans la chaîne src.
En complément avec strspn (cf. supra ) et strcspn (cf. supra ), la fonction strpbrk permet notamment d'analyser un texte parsemé de symboles séparateurs.
Le programme académique ci‑dessous permet de compter les mots dans texte composés en caractères exclusivement pris dans le jeu ASCII restreint (cf. chap. C3‑VIII ).
Il liste les séparateurs usuels de la langue anglaise (y compris l'espace) dans la chaîne SEP, qui joue le rôle d'argument effectif pour l'argument formel src dans les appels respectifs des fonctions strspn (cf. les lignes nº 12 et 15) et strbrk (cf. la ligne nº 14).
#include <stdio.h>
#include <string.h>
const char SEP[] = " ,.;:!?'\"()-[]";
const char TEXT[] = "C makes it easy to shoot yourself in the foot; C++ makes it harder, but when you do it blows your whole leg off! - Bjarne Stroustrup (in 1986).";
int wordCount(const char * str)
{
int count = 0;
str += strspn(str, SEP); // skip eventual initial separators without counting
do {
str = strpbrk(str, SEP); // find separator
if (str) str += strspn(str, SEP); // skip separator
count++;
}
while (*str != 0 && str != NULL);
return count;
}
int main(void)
{
printf("%d words\n", wordCount(TEXT));
return 0;
}
Exécuté dans l'environnement OnlineGDB, on obtient en sortie standard l'affichage :
28 words
Les fonctions d'analyse avancées ne sont pas opérationnelles sur les chaînes de caractères encodées en UTF‑8. En effet, ces fonctions n'opèrent pas sur les caractères mais individuellement sur les octets qui les composent.
Exemple. L'expression strspn("à", "ù") prend la valeur inattendue 1 alors que la chaîne "à" ne contient aucun caractère de la chaîne "ù". En effet, dans le format UTF‑8 :
-
àest encodé0x C3 A0; -
ùest encodé0x C3 B9.
Ces deux caractères partagent donc un même octet de valeur 0xC3. Ce dernier étant en tête dans la chaîne correspondant à l'argument dest, la fonction strspn retourne logiquement la valeur 1.
Fonctions d'interprétation numérique
Ces fonctions permettent d'interpréter – c'est‑à‑dire, en quelque sorte, « convertir » – dans un type numérique standard (int, long, double, etc.) une valeur codée dans une chaîne de caractères avec la syntaxe usuelle des constantes littérales (cf. chap. C3‑II et C3‑V ).
Ces fonctions sont déclarées dans le fichier d'en‑tête stdlib.h de la bibliothèque standard du langage C (cstdlib pour le C++).
Interprétation par une valeur entière
Interprétation en base 10 dans le type int C
// ascii to int int atoi(const char * str);
La chaîne str est supposée contenir une suite de chiffres, éventuellement précédée de caractères d'espacement, de zéros non significatifs et d'un signe « - » ou « + ».
La valeur retournée par la fonction atoi est la valeur numérique entière positive ou négative interprétant la chaîne de chiffres en base 10 détectée au début de l'argument str. Toutefois :
- Les éventuels caractères d'espacement ainsi que les zéros non significatifs codés au début de
strsont ignorés. - En cas de débordement de l'intervalle d'encodage du type
int, la valeur retournée dépend de l'implémentation. - En cas d'échec d'interprétation – en particulier si, après d'éventuelles caractères d'espacement et un signe «
+» ou «−», le premier caractère rencontré n'est pas un chiffre – alors la valeur retournée est0.
Dans l'environnement OnlineGDB, on teste les appels de la fonction atoi suivants.
-
atoi(" \t \n -0123.45foo")retourne la valeur attendue-123. -
atoi("foo123")retourne la valeur0(échec d'interprétation). -
atoi("12345678900")retourne la valeur-539222988(débordement). -
atoi("123456789012345678900")retourne la valeur-1(débordement).
'-' un '0' non significatif ignoré. Après le premier chiffre trouvé, tout caractère qui n'est pas un chiffre (ici, '.') marque la fin de la chaîne numérique. + ou -, ni un caractère d'espacement. "123456789012345678900" représente une valeur supérieure à LLONG_MAX. Interprétation en base 10 dans les types long et long long C
// ascii to long / long long long atol(const char * str); long long atoll(const char * str);
Les fonctions atol et atoll opèrent comme atoi mais avec un type d'interprétation de la valeur numérique plus large – respectivement long et long long.
Interprétation enchaînable en base n dans le type long
// string to long long strtol(const char * str, char ** str_end, int base);
La fonction strtol opère comme atol mais possède deux arguments supplémentaires.
- L'argument
str_endest un pointeur de caractère transmis par adresse pour pouvoir être modifié par la fonction ; c'est donc un pointeur de pointeur d'où le codechar **. - L'argument
basepermet de coder n'importe quelle base n = 2 à n = 36 dans laquelle interpréter la chaîne numérique identifiée.
str comporte plusieurs valeurs successives). strtol, on peut également coder pour l'argument base la valeur 0. La fonction opère alors par auto‑détection en recherchant un préfixe à la chaîne numérique – 0 pour la base 8 et 0x ou 0X pour la base 16 (malheureusement, il n'y a pas de préfixe pour la base 2). Le programme académique ci‑dessous montre comment enregistrer dans un tableau d'entiers nommé tab une série de 6 valeurs numériques codées en base 16 dans une chaîne de caractère nommée val (typiquement, une adresse MAC), où le préfixe "0x" est codé avant chaque valeur.
La fonction strtol est appelée dans une boucle for (cf. la ligne n° 8) :
- dont la variable d'itération principale
iest incrémentée autant de fois que le nombre de valeurs recherchées ; - dont les variables secondaires
petesont des pointeurs qui permettent de scanner la chaînevalvaleur par valeur.
Dans l'appel de strtol (cf. la ligne n° 9), le 3e argument est codé 0, autrement dit la base numérique d'expression des valeurs est détectée automatiquement par préfixe.
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
char * val = "0xAA 0xAB 0xAC 0xAD 0xAE 0xAF";
long tab[6] = {0};
for (char * p = val, * e = NULL, i = 0; i < 6 ; p = e, i++) {
tab[i] = strtol(p, &e, 0); // 0 => auto base detection
printf("%lX%s", tab[i], i < 5 ? ", " : ".\n");
}
return 0;
}
Exécuté avec OnlineGDB, ce programme produit en sortie standard l'affichage attendu :
AA, AB, AC, AD, AE, AF.
Il existe aussi la fonction strtoll qui est une variante similaire à strtol mais retournant une valeur dans le type long long.
Interprétation par une valeur décimale flottante
Interprétation dans le type double C
// ascii to floating-point decimal double atof(const char * str);
La chaîne str est supposée contenir une suite de chiffres et de symboles numériques conforme à la syntaxe de codage des constantes littérales décimales (cf. C3‑V ), éventuellement précédée de caractères d'espacement et de zéros non significatifs.
La valeur retournée par la fonction atof est la valeur numérique décimale interprétant la séquence de chiffres et de symboles. Toutefois, comme pour la fonction atoi :
- Les éventuels caractères d'espacement ainsi que les zéros non significatifs codés au début de
strsont ignorés. - En cas de débordement par le haut (overflow) ou par le bas (underflow) des intervalles encodables dans le type
double, la valeur retournée est un élément absorbant, respectivementinfou0.0(cf. chap. C3‑V ). - En cas d'échec d'interprétation – en particulier si, après les éventuelles caractères d'espacement, le premier caractère rencontré n'est pas un chiffre – la valeur retournée est
0.0.
Dans l'environnement OnlineGDB, on teste les appels de la fonction atof suivants.
-
atof(" \t \n -0123.45e+02foo")retourne la valeur attendue-12345.0. -
atof("0xA.1p3")retourne la valeur80.5. -
atof("foo12.3")retourne la valeur0.0(échec d'interprétation). -
atof("1e400")retourne la valeurinf(overflow). -
atof("1e-400")retourne la valeur0.0(undeflow).
'-' un '0' non significatif ignoré. Ici, c'est la lettre 'f' qui marque la fin de la chaîne décimale à interpréter. + ou -, ni un caractère d'espacement. Interprétation enchaînable dans le type double C
// string to double double strtod(const char * str, char ** str_end);
La fonction strtod opère comme atof mais, à l'instar de strtol, elle possède aussi un argument str_end qui est un pointeur de caractère transmis par adresse pour pouvoir être modifié par la fonction (c'est donc un pointeur de pointeur). Ce dernier donne le caractère immédiatement consécutif à la chaîne numérique interprétée pour permettre un enchaînement d'interprétation (si la chaîne str comporte plusieurs valeurs successives).
Le programme académique ci‑dessous montre comment enregistrer dans un tableau de décimaux nommé tab une série de 5 valeurs numériques codées au format csv (comma‑separated values W) dans une chaîne de caractères nommé val .
Comme dans l'exemple supra servant à illustrer la fonction strtol , la fonction strtod est appelée dans une boucle for (cf. la ligne n° 9) :
- dont la variable d'itération principale
iest incrémentée autant de fois que le nombre de valeurs recherchées ; - dont les variables secondaires
petesont des pointeurs qui permettent de scanner la chaînevalvaleur par valeur.
Le seul aspect supplémentaire est la ligne n° 12 qui code le traitement des virgules séparatrices des valeurs dans la chaîne : il exploite la fonction strchr (cf. supra ) pour chercher le caractère ',' et passer au caractère suivant.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void)
{
char * val = " 0.1 , 0.2 , 0.3 , 0.4 , 0.5 ";
double tab[5] = {0};
for (char * p = val, * e = NULL, i = 0; i < 5; p = e, i++) {
tab[i] = strtod(p, &e);
printf("%g ", tab[i]);
e = strchr(e, ',') + 1;
}
printf("\n");
return 0;
}
Exécuté avec OnlineGDB, ce programme produit en sortie standard l'affichage attendu :
0.1 0.2 0.3 0.4 0.5
Il existe aussi les fonctions strtof et strtold qui sont des variantes similaires à strtod mais retournant une valeur respectivement dans les types float et long double.
Fonctions de comparaison
Toute fonction de comparaison entre deux chaînes de caractères est basée sur un ordre lexicographique W défini – à l'instar de celui pour classer les mots dans un dictionnaire. Par défaut, cet ordre est basé sur la valeur ordinale des codes des caractères, quel que soit le format d'encodage (ASCII, UTF‑8, etc.).
Sous un système Linux, l'ordre lexicographique dépend aussi de la valeur de variable d'environnement LC_COLLATE durant l'exécution du programme. Par défaut, la valeur dans la locale C qui est sélectionnée.
Sur les chaînes de style C, la comparaison est opérée respectivement entre les deux chaînes octet par octet dans l'ordre de leur position dans les chaînes – de façon semblable au sens de lecture des mots.
Dans l'en‑tête des fonctions de comparaison, les identificateurs des arguments formels désignant les deux chaînes de caractères à comparer sont :
-
lhspour left‑hand string ; -
rhspour right‑hand string.
Remarque : ce genre d'identificateurs abrégés est classique (cf. chap. C5‑V ).
Comparaison complète de deux chaînes dans l'ordre lexicographique C
// string compare int strcmp(const char * lhs, const char * rhs);
La valeur retournée par la fonction strcmp est un entier :
- positif – typiquement
1– silhs > rhs, autrement dit silhssuccède àrhsdans l'ordre lexicographique. - nul –
0– silhs = rhs, autrement dit si les deux chaînes sont égales ; - négatif – typiquement
-1– silhs < rhs, autrement dit silhsprécède àrhsdans l'ordre lexicographique.
Dans l'environnement OnlineGDB, on teste les appels de la fonction strcmp suivants.
-
strcmp("abd", "abce")retourne la valeur1. -
strcmp("&abc", "#abc")retourne la valeur1. -
strcmp("è", "é")retourne la valeur-1. -
strcmp("e", "é")retourne la valeur-1.
"abd" succède à "abce" dans l'ordre lexicographique. '&' (0x26) succède à '#' (0x23) en termes de codes ASCII ou UTF‑8. 'è' (code 0xC3A8) précède à 'é' (code 0xC3A9) en termes de codes UTF‑8. 'e' (0x65) précède à 'é' (0xC3A9) car pour le premier octet, on a bien 0x65 < 0xC3. Comparaison des n premiers octets de deux chaînes de caractères dans l'ordre lexicographique C
// string n‑bytes compare int strncmp(const char * lhs, const char * rhs, size_t count);
La fonction strncmp opère comme strcmp mais seulement sur les n premiers octets respectifs des deux chaînes – ce nombre étant codé par la valeur de l'argument count.
Toutefois, le nombre d'octets réellement comparés ne dépasse pas la longueur de la plus grande des deux chaînes, même si la valeur de l'argument effectif codé pour n est supérieur cette longueur.
Si l'on souhaite une comparaison sur n octets quelles que soient la longueur des chaînes, il faut employer la fonction memcmp C. Elle admet un prototype similaire à celui de strncmp, mais plus polyvalent, car applicable à des suites d'octets (cf. supra ).
Dans l'environnement OnlineGDB, on teste les appels de la fonction strncmp suivants.
-
strncmp("abd", "abce", 2)retourne la valeur0. -
strncmp("ab\0a", "ab\0z", 4)retourne la valeur0. -
strncmp("Ù", "é", 1)retourne la valeur0. -
strncmp("Ù", "é", 2)retourne la valeur-16.
"abd" et "abce" ont leurs deux premiers caractères "ab" respectivement égaux. '\0' codés dans l'une et l'autre en 3e position (elles sont interprétées comme des chaînes de longueur 2). memcmp("ab\0a", "ab\0z", 4) retourne la valeur -1. 'Ù' (0xC399) et 'é' (0xC3A9) ont un premier octet 0xC3 identique dans leur code UTF‑8. 'Ù' et 'é' sont encodés l'un comme l'autre sur deux octets en UTF‑8 et au regard de leurs codes respectifs, 'Ù' précède 'é'. -1. Il en va de même pour les valeurs positives : elles ne sont pas forcément égales à 1. Fonctions de manipulation
En programmation, parmi les manipulations usuelles des chaînes de caractères, on a typiquement la recopie, la concaténation, l'affectation uniforme…
Dans l'en‑tête des fonctions de manipulation des chaînes de style C, les arguments formels sont usuellement désignés par :
-
destpour destination – son argument effectif correspondant dans l'expression d'appel est modifié ; ce dernier doit obligatoirement être déclaré comme un tableau de caractères ; -
srcpour source – c'est la chaîne dont l'argument effectif correspondant dans l'expression d'appel n'est pas modifié mais seulement lu, donc codé avec le mot‑clefconst; il peut s'agir d'une chaîne déclarée comme un tableau ou un pointeur de caractères, voire d'une constante littérale.
Recopie d'une chaîne dans une autre
Recopie complète de src dans dest C
// string copy char * strcpy(char * dest, const char * src);
Dans une expression d'appel de la fonction strcpy, l'argument effectif correspondant à dest est censé être déclarée avec un nombre d'éléments suffisant pour enregistrer tous les caractères de l'argument effectif correspondant à src – caractère de fin de chaîne NUL inclus. Sinon, le résultat est indéfini.
De plus, les arguments effectifs correspondant respectivement à dest et src ne doivent pas se chevaucher (no overlapping) sur le même espace mémoire – sinon, le résultat est également indéfini.
La fonction strcpy permet de coder une affectation groupée des octets de la chaîne dest, pour qu'ils prennent respectivement par ordre de position les octets de la chaîne src jusqu'à son caractère de fin de chaîne NUL inclus.
Il en résulte que les octets suivants de la chaîne dest ne sont pas affectés par cette manipulation.
Quant à la valeur retournée par la fonction, il s'agit simplement d'un pointeur sur la chaîne dest.
Le programme académique ci‑dessous code un appel de la fonction strcpy (cf. la ligne n° 14) sur deux chaînes de caractères déclarées homonymes à ses arguments dest et src, comme des tableaux de même taille mais initialisées avec des contenus différents.
Pour inspecter le contenu de dest avant et après cette manipulation de copie, on code une fonction de scan nommée scanString (cf. les lignes n° 19 à 26). Sans valeur de retour, elle prend comme arguments une chaîne str et une taille count.
- Avec
printf, elle affiche d'abordstrvia la spécification de conversion usuelle%s. - Puis elle effectue un affichage espacé de chaque caractère de
strou son code en hexadécimal s'il n'est pas imprimable, en comptant jusqu'àcount.
#include <stdio.h>
#include <ctype.h>
#include <string.h>
void scanString(const char * str, size_t count);
char dest[8] = "Hello";
char src[8] = "hi";
int main(void)
{
scanString(dest, 8);
strcpy(dest, src);
scanString(dest, 8);
return 0;
}
void scanString(const char * str, size_t count)
{
printf("%s\n", str);
for (const char * c = str; c < str + count; c++) {
printf(isprint(*c) ? "%3c " : "0x%X ", *c);
}
printf("\n");
}
Exécuté sur OnlineGDB, ce programme produit en sortie standard l'affichage attendu :
Hello H e l l o 0x0 0x0 0x0 hi h i 0x0 l o 0x0 0x0 0x0
En effet, après l'appel de strcpy :
- les trois premiers octets de
destsont bien ceux descr, caractère NUL inclus, qui met un terme à la copie. - les 5 derniers octets de
destn'ont pas changé mais sont en principe illisibles, puisque placés après un caractère NUL.
Examinons maintenant ce que se produit en cas de chevauchement entre les deux chaînes passées comme arguments effectifs dans l'appel de strcpy. Dans le programme supra, remplaçons la ligne n° 14 par :
strcpy(dest, dest + 1); // Bad coding! Result won't be OK.
Rappelons qu'une expression comme dest + 1 est interprétée par le compilateur comme un pointeur sur le 2e caractère de la chaîne dest. Une telle manipulation reviendrait donc à supprimer le premier caractère de dest. Malheureusement, le résultat obtenu n'est pas satisfaisant :
Hello H e l l o 0x0 0x0 0x0 eloo e l o o 0x0 0x0 0x0 0x0
puisqu'on observe une recopie erronée à partir du 3e caractère (on devrait normalement obtenir ello). On verra infra comment résoudre ce problème avec la fonction memcpy.
Recopie de n octets de src dans dest C
// string n‑bytes copy char * strncpy(char * dest, const char * src, size_t count);
La fonction strncpy opère comme strcpy mais exactement sur les n premiers octets respectifs des deux chaînes – ce nombre étant codé par la valeur de l'argument count.
Et le nombre d'octets réellement copiés n'est pas limité par la longueur de la chaîne src, ni par son nombre d'éléments déclarés ; mais bien évidemment, il est vivement déconseillé de dépasser cette limite puisqu'on serait sinon amené à déborder de la zone de mémoire allouée à src.
En revanche, on est toujours limité par le fait que les chaînes dest et src ne doivent pas se chevaucher sur le même espace mémoire.
Si l'on souhaite recopier une partie d'une chaîne dans elle‑même, il faut employer la fonction memcpy C. Elle admet un prototype similaire à celui de strncpy, mais plus polyvalent, car applicable à des suites d'octets (cf. supra ).
Pour tester la fonction strncpy, reprenons le même exemple académique proposé supra pour illustrer l'usage de la fonction strcpy.
Dans le programme, si l'on remplace la ligne n° 14 par :
strncpy(dest, src, 8);
on obtient dans dest une copie intégrale des 8 octets de scr, comme le montre l'affichage obtenu en sortie standard :
Hello H e l l o 0x0 0x0 0x0 hi h i 0x0 0x0 0x0 0x0 0x0 0x0
Examinons maintenant ce que se produit avec un chevauchement entre les deux chaînes passées comme arguments effectifs. C'est typiquement le cas si on remplace dans le programme la ligne n° 14 par :
strncpy(dest, dest + 1, 7); // Bad coding! Result won't be OK.
pour supprimer le premier caractère de dest. Comme supra avec la fonction strcpy, on obtient une copie erronée, comme le montre l'affichage obtenu (on devrait obtenir ello) :
Hello H e l l o 0x0 0x0 0x0 eloo e l o o 0x0 0x0 0x0 0x0
En revanche, si on utilise à la place la fonction memcpy comme ci‑dessous :
memcpy(dest, dest + 1, 7); // This is OK.
alors on obtient dans dest une copie correcte de ses octets décalés de 1 rang vers la gauche (d'où la suppression du premier caractère de la chaîne), comme le montre l'affichage obtenu :
Hello H e l l o 0x0 0x0 0x0 ello e l l o 0x0 0x0 0x0 0x0
Concaténation d'une chaîne au bout d'une autre
Concaténation complète de src au bout de dest C
// string concatenation char * strcat(char * dest, const char * src);
Dans une expression d'appel de la fonction strcpy, l'argument effectif correspondant à dest est censé être déclarée avec un nombre d'éléments suffisant pour enregistrer, en plus de tous les caractères qu'elle contient déjà, tous ceux de l'argument effectif correspondant à src – caractère de fin de chaîne NUL inclus. Sinon, le résultat est indéfini.
En principe, les argument effectif correspondant à dest et src ne doivent pas se chevaucher (no overlapping) sur le même espace mémoire – sinon, le résultat est également indéfini.
La fonction strcat code une affectation groupée des octets du tableau sur lequel dest pointe à partir du caractère de fin de chaîne NUL inclus, pour qu'il prennent respectivement par ordre de position les octets pointés par src jusqu'à son caractère de fin de chaîne NUL inclus.
Les éventuels octets suivants dans le tableau pointé par dest – donc, situés après le caractère NUL – ne sont pas affectés.
La valeur retournée est simplement un pointeur sur la chaîne dest.
Le programme académique ci‑dessous, similaire à celui pour illustrer l'usage de la fonction strcpy , code un appel de la fonction strcat (cf. la ligne n° 14) sur deux chaînes de caractères déclarées homonymes à ses arguments dest et src.
Pour inspecter le contenu de dest avant et après cette concaténation, on utilise la même fonction de scan scanString.
#include <stdio.h>
#include <ctype.h>
#include <string.h>
void scanString(const char * str, size_t count);
char dest[8] = "Foo";
char src[8] = "Bar";
int main(void)
{
scanString(dest, 8);
strcat(dest, src);
scanString(dest, 8);
return 0;
}
void scanString(const char * str, size_t count)
{
printf("%s\n", str);
for (const char * c = str; c < str + count; c++) {
printf(isprint(*c) ? "%3c " : "0x%X ", *c);
}
printf("\n");
}
Exécuté sur OnlineGDB, ce programme produit en sortie standard l'affichage attendu :
Foo F o o 0x0 0x0 0x0 0x0 0x0 FooBar F o o B a r 0x0 0x0
Dans le programme précédent, si on ajoute au début de la fonction main l'instruction :
dest[7] = '*';
pour rendre non nul un caractère situé après le premier caractère NUL, alors on obtient en sortie standard l'affichage :
Foo F o o 0x0 0x0 0x0 0x0 * FooBar F o o B a r 0x0 *
On voit donc que, comme prévu, la concaténation n'a pas modifié le dernier élément de dest.
Concaténation de n octets de src au bout de dest C
// string n‑bytes concatenation char * strncat(char * dest, const char * src, size_t count);
La fonction strncat opère comme strcat mais en copiant au bout de dest les n premiers octets de src – ce nombre étant codé par la valeur de l'argument count. De plus, un caractère de fin de chaîne NUL est ajouté juste après les caractères concaténés.
Attention, le nombre d'octets réellement concaténés est limité par la longueur de la chaîne src.
Si l'on souhaite s'affranchir de cette limite, il faut employer la fonction memmove C. Elle admet un prototype similaire à celui de strncat mais plus polyvalent car applicable à des suites d'octets (cf. supra ).
Pour tester la fonction strncat, reprenons le même exemple académique proposé supra pour illustrer l'usage de la fonction strcat.
Dans le programme, si l'on remplace la ligne n° 7 par :
char dest[8] = "Foo\0****";
et la ligne n° 14 par :
strncat(dest, src, 2);
on opère au bout de dest la concaténation des 2 premiers octets seulement de scr. Sur OnlineGDB, l'affichage obtenu en sortie standard est conforme à ce qui est attendu :
Foo F o o 0x0 * * * * FooBa F o o B a 0x0 * *
Et si l'on code pour l'argument countla valeur 5 dans l'appel de strncat, on obtient l'affichage :
Foo F o o 0x0 * * * * FooBar F o o B a r 0x0 *
où l'on voit que le dernier octet de dest n'a pas été écrasé par la concaténation, qui s'est arrêtée au caractère de fin de chaîne de src (4e caractère, juste après "Bar").
Pour effectuer une concaténation complète, c'est‑à‑dire dimensionnée exactement par la valeur de l'argument count et indépendamment de tout caractère NUL, il faut employer la fonction memmove. Ainsi, en remplaçant la ligne n° 14 par :
memmove(dest + 3, src, 5);
alors on obtient un écrasement complet des 5 derniers octets de dest, comme le montre l'affichage obtenu en sortie standard :
Foo F o o 0x0 * * * * FooBar F o o B a r 0x0 0x0
Affectation répétitive d'un caractère
Il existe une fonction, nommée memset pour coder l'affectation répétitive de n occurrences du même caractère ASCII dans une chaîne C :
// memory set void * memset(void * dest, int ch, size_t count);
Il s'agit d'une fonction polyvalente qui peut opérer sur des suites d'octets et non pas simplement sur des chaînes de caractères (cf. supra ).
Dans une expression d'appel de la fonction memset, l'argument effectif correspondant à dest doit être déclaré avec un nombre d'éléments supérieur ou égal à la valeur n prise par l'argument count.
Par ailleurs, comme pour la fonction strchr (cf. supra ), l'argument formel ch, bien que déclaré de type int dans l'en‑tête de la fonction, est converti dans le type char dans le corps de définition de la fonction.
C'est pourquoi, dans un appel de la fonction memset, l'argument effectif correspondant à count doit donc prendre une valeur d'encodage comprise entre 0x00 et 0xFF. Ce faisant, il peut éventuellement être codé comme une valeur de caractère entre guillemets simples '' ou une séquence d'échappement.
La fonction memset opère l'affectation groupée à la valeur de ch des n premiers octets du tableau sur lequel dest pointe.
Les octets suivants du tableau ne sont pas affectés. En particulier, il n'y pas d'ajout automatique d'un caractère de fin de chaîne NUL à l'octet de position n + 1.
La valeur retournée est simplement un pointeur sur l'argument dest.
Dans l'environnement OnlineGDB, on teste les appels de la fonction memset suivants.
- Après la déclaration
char str[8] = {0x0};l'instruction :
printf("%s\n", (char*) memset(str, '=', 4));
affiche====en sortie standard. - Après la déclaration
char str[8] = "0123456";l'instruction :
printf("%s\n", (char*) memset(str, '=', 4));
affiche====456en sortie standard. - Le tableau
strcontient donc 8 caractères'='et sans y prendre garde, on vient d'écraser le caractère de fin de chaîne que contenaitstr[7]. - En sortie standard, la fonction
printfpeut afficher seulement ces 8 caractères si, dans la mémoire, l'octet consécutif àstr[7]vaut par « chance »0, de sorte qu'il est interprété comme caractère de fin de chaîne. - Mais si on compile et exécute le programme ci‑dessous, où l'on déclare juste après
strune autre chaîne de 8 caractèresnxt(cf. la ligne n° 7):
str a été initialisé avec tous ses éléments valant NUL. Le premier de ces éléments constitue donc le caractère de fin de chaîne. printf("%s\n", (char*) memset(str, '=', 8));
peut afficher
======== en sortie standard.
#include <stdio.h>
#include <string.h>
void scanString(const char * str, size_t count);
char str[8] = "0123456";
char nxt[8] = "789...";
int main(void)
{
memset(str, '=', 8);
printf("%s\n", str);
return 0;
}
str et nxt : ========789...
str seulement). str et nxt ayant l'un et l'autre une taille de 8 octets, ils sont stockés l'un après l'autre dans la mémoire sans octets de padding (leur contrainte d'alignement est précisément de 8 octets). Le tableau str n'ayant pas de caractère de fin de chaîne, c'est donc celui de nxt qui joue ce rôle et termine l'affichage. Fonctions de composition et d'analyse polyvalentes
Dans le fichier d'en‑tête stdio.h de la bibliothèque standard du langage C sont déclarées les fonctions sprintf C et sscanf C.
int sprintf(char * buffer, const char * format, ... ); int sscanf(const char * buffer, const char * format, ... );
Les fonctions sprintf et sscanf constituent respectivement des variantes des fonctions printf et scanf. Elles opèrent sur une chaîne de caractère – d'où le préfixe « s » de leur nom – au lieu des périphériques d'entrées‑sorties standards (écran et clavier).
Dans leur en‑tête (cf. ci‑dessus), la chaîne de caractère sur laquelle ces fonctions opèrent est nommée buffer et constitue le premier argument formel avant la chaîne de format (nommée format).
L'argument buffer :
- est composé par
sprintf– donc son argument effectif correspondant doit être déclaré comme un tableau de caractères avec un nombre d'élément suffisant pour stocker ceux codés dans la chaîne de format – sans oublier de compter le caractère de fin de chaîne NUL automatiquement ajouté ; - est analysé par
sscanf– donc son argument effectif correspondant peut être déclaré indifféremment comme un pointeur ou un tableau de caractères ; il peut également s'agir d'une constante littérale.


Par ailleurs, la très complexe syntaxe de codage des autres arguments des fonctions sprintf et sscanf est la même que pour printf et scanf. Succinctement abordée aux chap. C2‑VII et C3‑V , cette syntaxe est approfondie au chap. C5‑VIII .

Reprenons des exemples académiques qui ont été proposés au chap. C2‑VII pour illustrer respectivement les fonctions printf et scanf .
- Après la déclaration
char date[11];l'instruction :
sprintf(date, "%02u/%02u/%u", 1, 9, 2019);
compose la chaîne de caractères"01/09/2019"dans la variabledate. - Réciproquement, après la déclaration groupée :
unsigned day, month, year;
l'instruction :
sscanf("01/09/2019", "%02u/%02u/%u", &day, &month, &year);
affecte aux trois variablesday,monthetyearrespectivement les valeurs1,9et2019.
Introduction aux chaînes de caractères dynamiques en langage C++
Généralités
En langage C++, il est bien évidemment possible d'employer les chaînes de style C, et c'est d'ailleurs incontournable pour certaines fonctionnalités, notamment lorsque l'on code des arguments à la fonction main (cf. chap. C5‑VII ).
Néanmoins, les concepts de la programmation orientée objet (cf. les chap. C1‑I et C2‑VI ) permettent d'implémenter efficacement des chaînes de caractères dynamiques. Dans cette perspective, la bibliothèque standard du C++ comporte un module dont le fichier d'en‑tête principal string C++ qui définit notamment la classe string.
Par rapport aux types char * et char[], la classe string :
- apporte au codeur une grande souplesse d'utilisation du fait de son caractère dynamique et des méthodes puissantes de manipulation ou d'analyse qui sont intégrées à la classe ;
- requiert en contre‑partie une occupation mémoire plus lourde, qui est négligeable pour les longues chaînes de caractères, mais qui peut devenir pénalisante lorsqu'un programme utilise une grand nombre de petites chaînes.
Plus généralement, le fichier d'en‑tête string – avec ses fichiers annexes, via des directives d'inclusion, notamment basic_string.h – déclare un grand nombre d'éléments génériques qui permettent de mettre en œuvre des objets conçus sur mesure pour répondre à toutes sortes de problématiques, typiquement des manipulations fines de contenu de fichiers de texte avec telle ou telle contrainte d'encodage des caractères.
Au regard de cette généricité et de la multitude des éléments déclarés, il ne serait pas réaliste d'en faire ici une présentation exhaustive (il faudrait y consacrer un chapitre entier, et en ayant préalablement explosé certains aspects essentiels de la programmation orientée objet). On ne donnera donc ci‑après que des descriptions partielles et parfois superficielles, dans l'esprit d'une simple introduction.
Le fichier d'en‑tête string est bien évidemment à ne pas confondre avec les fichiers string.h et cstring qui déclarent les fonctions de manipulation des chaînes de style C (cf. supra ).
Déclaration directe d'un objet de classe string
Le module string de la bibliothèque standard du C++ ne définit pas seulement une classe mais une famille de classes qui sont toutes basées sur le même patron – en anglais, template W – nommé basic_string.
Le polymorphisme du C++ permet ainsi de décliner efficacement la définition de chacune des classes de cette famille en fonction du type des unités d'encodage qu'elle utilise pour les caractères. En particulier :
- la classe
stringemploie le typechar; - la classe
u8stringemploie le typechar8_t; - la classe
u16stringemploie le typechar16_t; - la classe
u32stringemploie le typechar32_t;
sachant qu'avec certaines implémentations – notamment GCC sous Linux – la classe string est compatible avec le format d'encodage UTF‑8.
En règle générale, toutes les explications données ci‑après sur la classe string, ses opérateurs et ses méthodes, est valable aussi pour toutes les classes issues du patron basic_string, moyennant parfois quelques adaptations.
Dans un programme en C++, la déclaration d'une objet variable de classe string se code via la syntaxe suivante :
std::string identificateur = chaîne 1 chaîne 2 ;
où les constantes littérales chaîne 1, chaîne 2… adoptent la même syntaxe qu'en langage C (préfixe d'encodage facultatif et saisie entre guillemets doubles – cf. supra ).
Dans cette syntaxe, on peut simplifier le descripteur de classe avec juste string en codant préalablement l'instruction :
using namespace std;
c'est‑à‑dire en précisant que le programme utilise l'espace de nom standard W, nommé std.
Comme la déclaration d'une chaîne de style C, celle d'un objet de classe string peut être assortie de modificateurs comme const et/ou static (cf. chap. C4‑II ).
De plus, il également possible d'adopter les syntaxes alternatives du C++ pour l'initialisation des données, via des constructeurs (cf. infra ).
Le programme académique ci‑dessous donne un exemple de déclaration directe en C++ d'une variable de classe string nommée mess et initialisée avec des caractères accentués (cf. la ligne n° 7).
#include <cstdio>
#include <string>
using namespace std;
int main()
{
string mess = "À bientôt.";
printf("%s\n", mess.c_str());
return 0;
}
Testé dans l'environnement OnlineGDB, il produit l'affichage attendu À bientôt..
Remarque. L'affichage en sortie standard avec la fonction printf d'une chaîne de classe string nécessite un recours à la méthode c_str (détaillée infra ), car la spécification de conversion %s attend une valeur de type char *.
Une telle manipulation n'est pas nécessaire si l'on utilise le module d'entrées‑sorties iostream spécificique au C++, comme illustré ci‑dessous dans la variante du programme précédent.
#include <iostream>
#include <string>
using namespace std;
int main()
{
string mess = "À bientôt.";
cout << mess << endl;
return 0;
}
Il produit exactement le même affichage.
C'est donc avec iostream que seront illustrés tous les exemples à suivre dans le reste du chapitre.
Plus généralement, le patron de classe basic_string permet de déclarer des types de chaînes « sur‑mesures », c'est‑à‑dire dont les caractères font l'objet de spécifications particulières. Sans entrer dans les détails :
- Le module
stringmet à la disposition du codeur le patron de classechar_traitsC++. Avec, on peut déclarer un nouveau type de caractères (basé un encodage existant) et redéfinir des opérateurs et des méthodes, spéficiquement pour ce type. Par exemple, on peut jouer sur les opérateurs de comparaison pour modifier l'ordre lexicographique usuel et ainsi obtenir une relation d'ordre insensible à la casse. - Sur la base de ce nouveau type de caractères, on peut alors déclarer un nouveau type de chaîne.
Le type size_type
Dans le patron de classe basic_string est aussi défini le type size_type pour déclarer des données qui expriment une position ou une longueur dans une chaîne de caractères. Ce type vient ici spécifiquement en remplacement du type size_t de la bibliothèque standard du langage C (cf. chap. C3‑I ).
Attention ! Comme le type size_type est défini au sein d'une classe, son identificateur n'est pas utilisable directement comme descripteur de type pour une déclaration.
Mais il suffit de le préfixer par le nom de la classe utilisée via l'opérateur de résolution de portée :: W (scope resolution operator) dont on a vu un cas d'usage au chap. C2‑VI . Par exemple, une instruction comme celle ci‑dessous est compilable :
string::size_type pos = 0;
Les constructeurs de la classe string
Pour un rappel sur la notion de constructeur, on se reportera au chapitre C2‑VI .
Outre le constructeur par défaut qui permet de coder une initialisation directe (cf. le chap. C2‑III ), la classe string dispose de divers constructeurs C pour déclarer des chaînes de caractères avec différentes méthodes d'initialisation intégrées.
Cette intégration permet d'éviter le codage, juste après une initialisation, une méthode de manipulation pour répondre à d'éventuels besoins spécifiques du programme.
Parmi les constructeurs de la classe string, on peut retenir les deux suivants comme étant les les plus usuels :
- Constructeur à allocation répétitive :
- Constructeur à copie partielle :
string (size_type count, char ch);
memset exposée supra , ce constructeur affecte à la chaîne déclarée un nombre count d'occurrences successives du même caractère ch. string (const string & other, size_type pos, size_type count);
Le programme académique ci‑dessous donne quelques exemples triviaux d'utilisation de trois constructeurs de la classe string :
#include <iostream>
#include <string>
using namespace std;
int main()
{
string line(5, '='); // repetitive allocation
string stars(10, '*'); // idem
cout << line << stars << line << endl;
string motto("I ♥ C++!"); // direct initialization
string language(motto, 6, 3); // partial copy
cout << motto << endl << language << endl;
return 0;
}
Exécuté avec OnlineGDB, il produit en sortie standard l'affichage suivant :
=====**********===== I ♥ C++! C++
Opérateurs et méthodes d'accès aux caractères
L'opérateur d'indexation [] étant surchargé dans la classe string, il est tout à fait possible de l'utiliser pour accéder aux différents caractères d'un objet déclaré de cette classe, exactement comme pour une chaîne de style C (cf. supra ).
Toutefois, on a souligné à plusieurs reprises à quel point cet opérateur est aussi puissant que dangereux (cf. les chap. C2‑VI , C5‑III et C5‑IV ).
Pour y remédier, la classe string dispose de la méthode at dont le prototype est :
char & at(size_type pos);
Cette méthode joue le même rôle que l'opérateur d'indexation mais lève une exception W lors de l'exécution au cas où la valeur de l'argument effectif correspondant à pos prend une valeur hors des bornes d'indexation de la chaîne de caractères à laquelle elle s'applique par l'opérateur de sélection.
Le programme académique suivant, volontairement erroné :
#include <iostream>
#include <string>
using namespace std;
int main()
{
string code("0123");
cout << code.at(5) << endl; // Out of range!
return 0;
}
n'est pas exécutable. En effet, à la ligne nº 9, l'appel de la méthode at est passé pour une position trop grande (5, alors que la chaîne num est déclarée avec seulement 4 caractères). Avec OnlineGDB, on obtient le message suivant :
terminate called after throwing an instance of 'std::out_of_range' what(): basic_string::at: __n (which is 5) >= this->size() (which is 4)
En revanche, si on remplace l'expression code.at(5) par code[5], alors l'exécution se déroule sans aucun message. Une telle erreur de codage pourrait passer inaperçue, c'est pourquoi il est recommandé de privilégier la méthode at pour accéder aux caractères d'une chaîne.
Autres méthodes d'accès
La classe string fournit aussi deux méthodes d'accès particuliers qui sont sans argument et qui sont nommées :
front C++ et back C++
Elles retournent respectivement la valeur du premier et du dernier caractère de la chaîne à laquelle elles s'appliquent.
Toutefois, les deux méthodes front et back ne lèvent pas d'exéception si la chaîne est vide, contrairement à la méthode at (cf. supra). Cette dernière reste donc à privilégier pour une meilleure robustesse du code. Par exemple :
- une expression comme
str.front()peut aussi se coderstr.at(0); - une expression comme
str.back()peut aussi se coderstr.at(str.length() - 1).
En contre‑partie, les méthodes front et back apportent une meilleure lisibilité.
Par ailleurs, la classe string fournit aussi deux méthodes d'accès pour assurer la compatibilité avec le langage C.
- La méthode
dataC++, qui est sans argument, retourne un pointeur sur le premier caractère de la chaîne. Elle peut donc jouer le rôle d'identificateur de tableau comme celui d'une chaîne déclarée de style C (cf. supra ). - La méthode
c_strC++, qui est sans argument, retourne une constante littérale de type chaîne de style C (donc, non modifiable – cf. supra ), équivalente à la chaîne déclarée de classestring.
string une fonction de la bibliothèque standard du langage C, à condition que l'argument formel correspondant soit en lecture seule – typiquement, printf mais pas scanf (pour une telle fonction, il faut utiliser la méthode data). Le programme académique ci‑dessous illustre comment employer respectivement les méthodes de compatibilité c_str et data (cf. les lignes nº 10 & 11).
#include <cstdio>
#include <string>
using namespace std;
int main()
{
string message;
printf("Type a message: ");
scanf("%[^\n]s", message.data());
printf("\nYou typed: \t%s\n", message.c_str());
return 0;
}
Testé dans l'environnement OnlineGDB, ce programme produit en sortie standard l'affichage attendu, comme par exemple :
Type a message: Hello, World! You typed: Hello, World!
Remarques. À la ligne nº 10, on a codé la spécification de conversion %[^\n]s pour pouvoir saisir la chaîne saisie dans son intégralité, c'est‑à‑dire jusqu'au caractère de fin de ligne généré par l'appui sur la touche ENTRÉE.
Si on avait juste codé la spécification %s, on aurait obtenu le scénario d'exécution non souhaité suivant :
Type a message: Hello, World! You typed: Hello,
Autrement dit, la mémorisation dans la variable message aurait tronqué la chaîne saisie au premier caractère espace.
Opérateurs et méthodes d'analyse
Longueur, capacité et taille en mémoire
Comme pour une chaîne de style C déclarée comme un tableau de caractères (cf. supra ), il faut ne pas confondre les notions de capacité et de longueur d'une chaîne déclarée de classe string.
- La capacité correspond au nombre d'unités d'encodage qui lui sont alloués en mémoire.
- La longueur correspond au nombre d'unités d'encodage qui sont effectivement affectés aux octets alloués.
Ces deux caractéristiques peuvent être déterminées respectivement par les méthodes :
capacity C++ et length C++ (également nommée size)
qui, l'une comme l'autre, sont sans argument et retournent une valeur de type size_type.
Par ailleurs, on dispose de la méthode empty qui est sans argument et qui retourne une valeur de type bool. Comme son nom l'indique, elle détermine si la chaîne à laquelle elle s'applique est vide ou non, c'est‑à‑dire de longueur nulle.
Attention ! Contrairement à ce que son nom pourrait laisser penser, la méthode size ne détermine pas la taille en mémoire de la chaîne. Elle est en fait une méthode synonyme de lenght, et coexiste avec elle pour des raisons historiques de lisibilité et de compatibilité.
De plus, dans le cas d'une chaîne de caractères déclarée de classe string ou autre, la taille en mémoire n'est pas exactement le produit de son nombre total d'éléments multiplié par la taille d'un éléments. Il faut aussi ajouter la taille occupée par les membres attributs de la classe en recourant à l'opérateur sizeof.
Contrairement à une chaîne de style C, une chaîne de classe string est un objet à taille dynamique. Durant l'exécution, sa capacité est automatiquement augmentée dans une certaine mesure pour s'adapter aux caractères qu'on lui ajoute par appel de diverses méthodes d'écriture (cf. infra ).
En revanche, pour éviter de recourir trop souvent à des mécanismes d'allocation dynamique, la capacité d'une chaîne n'est pas automatiquement diminuée lorsque sa longueur se réduit. Il revient donc au codeur d'appeler éventuellement des méthodes de redimensionnement pour optimiser l'utilisation de la mémoire par le programme.
Les principales méthodes de redimensionnement d'une chaîne de classe string sont les suivantes :
-
void shrink_to_fit();C++ demande un ajustement de la capacité de la chaîne à sa longueur actuelle. -
void resize(size_type count);C++ opère un redimensionnement de la chaîne à la capacité codée par l'argumentcount.
Le programme académique ci‑dessous reprend l'exemple précédent (cf. supra ) mais en utilisant directement les méthodes du fichier d'en‑tête iostream pour la saisie et l'affichage d'une chaîne de classe string. (On utilise la méthode getline pour saisir la totalité d'une ligne contenant d'éventuels espaces – et non pas simplement cin << message – pour la même raison que celle évoquée dans la remarque de l'exemple cité).
#include <iostream>
#include <string>
using namespace std;
int main()
{
string message;
cout << "Type a message: ";
getline(cin, message);
cout << endl << "You typed: \t" << message << endl << endl;
cout << "length: " << message.length() << " elements" << endl;
cout << "capacity: " << message.capacity() << " elements" << endl;
cout << "size in memory: " << sizeof(message) << " bytes" << endl;
return 0;
}
Dans l'environnement OnlineGDB, ce programme produit en sortie standard l'affichage ci‑dessous, lorsque l'utilisateur saisit, par exemple, le premier paragraphe du faux texte Lorem Ipsum W :
Type a message: Lorem ipsum dolor […] hendrerit. You typed: Lorem ipsum dolor […] hendrerit. length: 847 elements capacity: 960 elements size in memory: 32 bytes
On voit donc qu'à l'objet message a été automatiquement alloué une capacité plus que suffisante (960 caractères) pour mémoriser toute la chaîne saisie par l'utilisateur (847 caractères de longueur).
Et si nécessaire, on peut optimiser la capacité de message, typiquement en ajoutant au programme l'instruction :
message.shrink_to_fit();
La capacité de message devient alors égale à sa longueur (847 caractères).
Quant à la valeur retournée par l'opérateur sizeof, elle correspond seulement à l'espace mémoire utilisé pour stocker les valeurs des attributs de l'objet message (longueur, pointeurs…). Elle est indépendante de sa longueur.
Remarque.
Lorsque la saisie d'une chaîne de classe string est opérée avec la fonction scanf comme dans l'exemple supra , et que l'utilisateur tape une chaîne de caractères un tant soit peu longue (typiquement, au delà d'une vingtaine de caractères), un dysfonctionnement intervient. Le programme semble s'exécuter normalement mais se termine en fait prématurément avec l'affichage d'un log de fin d'exécution anormale :
Type a message: Lorem ipsum dolor sit amet, You typed: Lorem ipsum dolor sit amet, *** stack smashing detected ***: terminated
Il en ressort que espace mémoire automatiquement alloué dans la pile (cf. chap. C4‑II ) à la chaîne message est insuffisant.
Une solution consiste alors à déclarer message avec un nombre d'éléments initial suffisamment grand, typiquement via le constructeur à allocation répétitive (cf. supra ), comme ci‑dessous :
string message(1000, '\0');
Cette remarque est aussi une occasion de plus de mesurer meilleure polyvalence et robustesses des méthodes de la bibliothèque standard du C++, puisque le problème ici constaté d'allocation mémoire ne se pose pas lorsque la saisie est opérée avec getline.
Recherches de motifs
La classe string dispose de six méthodes de recherche de motifs, qui sont organisées différemment par rapport aux fonctions semblables de la bibliothèque standard du langage C.
Avec leurs noms explicites, et disposant de plusieurs prototypes, ces méthodes constituent une interface plus puissante et plus lisible.
Pour toutes ces méthodes, la valeur de retour est de type size_type (cf. supra ).
- En cas de succès, elle exprime la position où la recherche aboutit dans la chaîne analysée.
- En cas d'échec, elle prend la valeur de la constante
nposqui est déclarée dans le patron de classebasic_typeet qui vaut-1.
La méthode find C++ est la méthode de recherche générale dans le sens de lecture de la chaîne de classe string à laquelle elle s'applique.
Son premier argument formel est le motif recherché. Grâce à ses différents prototypes, il accepte comme argument effectif :
- d'une chaîne de classe
string - d'une chaîne de style C, qu'elle soit déclarée ou directement codée sous la forme d'une constante littérale ;
- d'un caractère isolé.
Elle possède également un deuxième argument formel nommé pos qui est optionnel et dont la valeur par défaut est 0. Il code l'indice du caractère dans la chaîne analysée à partir duquel la recherche commence.
Par ailleurs, il existe la méthode rfind C++ qui opère comme find mais dans le sens inverse de lecture, c'est‑à‑dire en partant de la fin de la chaîne à laquelle elle s'applique.