De nos jours, le domaine du développement des logiciels est extrêmement varié. Il existe :

- plusieurs centaines de langages de programmation W ; mais dans cette diversité, une dizaine de langages seulement représentent près de 90 % des applications ;
- divers paradigmes (ou style) de programmation W qu'il est possible d'adopter dans certains langages ;
- dans les langages les plus employés, une grande variété de frameworks W, c'est‑à‑dire des ensembles de bibliothèques de fonctions permettant de développer rapidement des programmes complexes ;
- un grand choix d'environnements (ou logiciel) de développement W pour créer des programmes ;
- et par ailleurs, toutes sortes d'outils logiciels pour gérer, héberger, partager et aider au développement des programmes – sites de dépôts, forums de discussion, IA génératives, etc.
Face à cette multitude, avant de commencer l'étude d'un langage particulier, il est utile d'avoir quelques repères, et c'est précisément l'objectif de ce chapitre. Les thèmes listés ci‑dessus sont présentés dans cet ordre, à l’exception de la notion de framework, qui est difficile dans un premier temps.
En revanche, après cette présentation, on peut déjà prendre conscience des efforts à fournir pour être à la hauteur des enjeux du génie logiciel W. Ils sont esquissés en fin de chapitre.
Catégories de langages
Notions de code source et de code machine
On rappelle que tout programme informatique :
- s’écrit sous forme d’instructions codées dans un langage rigoureusement défini ; ces instructions sont stockées dans un ou plusieurs fichiers et constituent le code source W du programme ;
- doit donc d'abord être traduit en code machine W (binaire) spécifique aux composants matériels employés (processeur, mémoire…) pour pouvoir s'exécuter.
La distinction entre code source et code exécutable est essentielle car :
- le code source est compréhensible par les codeurs, mais non exécutable tel quel par une machine ;
- le code machine est incompréhensible par les codeurs mais il est exécutable par les machines pour lesquelles il a été produit.
La figure ci‑dessous illustre cette distinction dans le cas du très classique programme de démonstration « Hello World » codé en langage C :
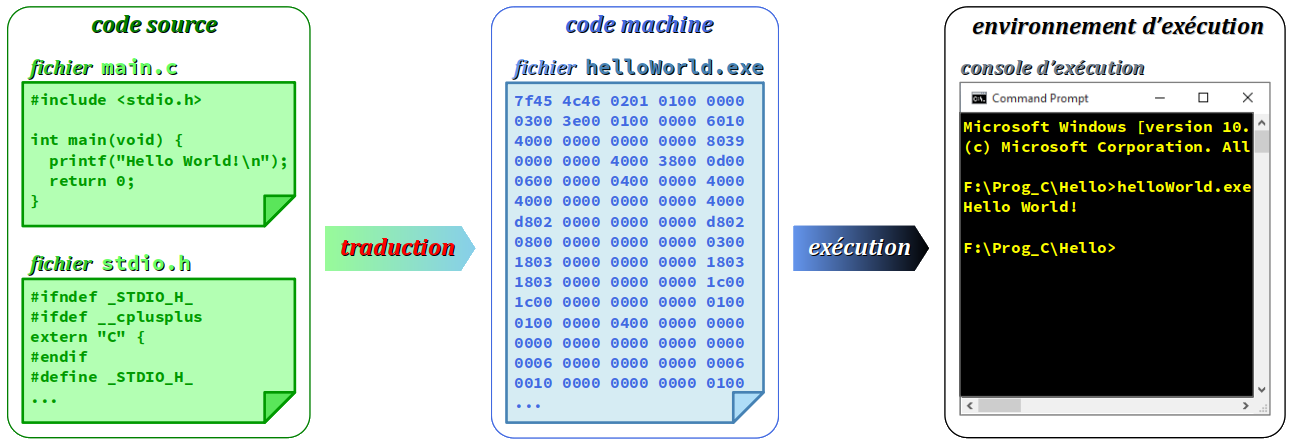
Le contenu du fichier exécutable peut être visualisé au format hexadécimal avec un éditeur de code mais il est indéchiffrable – sauf éventuellement pour un spécialiste du compilateur employé pour traduire le code source, mais au prix d'un grand effort…
Langages généralistes versus dédiés
- On parle de langage généraliste si ce dernier permet de développer toutes sortes de programmes : applications bureautiques, logiciels de simulation, programmes de contrôle‑commande, jeux, etc.
- Par opposition, on parle de langage dédié W pour caractérisé un langage conçu pour développer des applications ou formater des données dans un domaine bien particulier.
- Les principaux langages généralistes sont Python, C, C++, C# (C sharp), Java, Go, Rust, etc. – cf. l'index mensuel Tiobe des langages les plus populaires.
- Parmi les langages dédiés les plus remarquables, on trouve HTML/CSS/Javascript, php (pages web), XML (fichiers bureautiques), (La)TeX (fichiers de textes), SQL (bases de données), Matlab (calcul scientifique), R (statistiques), etc.








- Certains langages dédiés peuvent devenir plus généralistes moyennant un composant logiciel créant un environnement d'exécution approprié.
Exemple : JavaScript, avec Node.js. - Un langage peut être qualifié de métalangage s'il constitue une base syntaxique pour engendrer toute une famille de langages.
Exemple : XML dont sont issus XHTML, SVG, RSS…


Langages littéraux versus graphiques
- On parle de langage littéral W si les instructions du code source sont composées exclusivement sous forme de texte.
- On parle de langage graphique W si les instructions du code source sont présentées et saisies sous forme de schémas (boîtes, flèches, etc.) pour faciliter leur lecture et leur compréhension.
- La presque totalité des langages actuels (tous ceux cités supra) sont des Langages littéraux – cf. ci‑dessous le code du programme « Hello, World! » respectivement en C++ et Python.
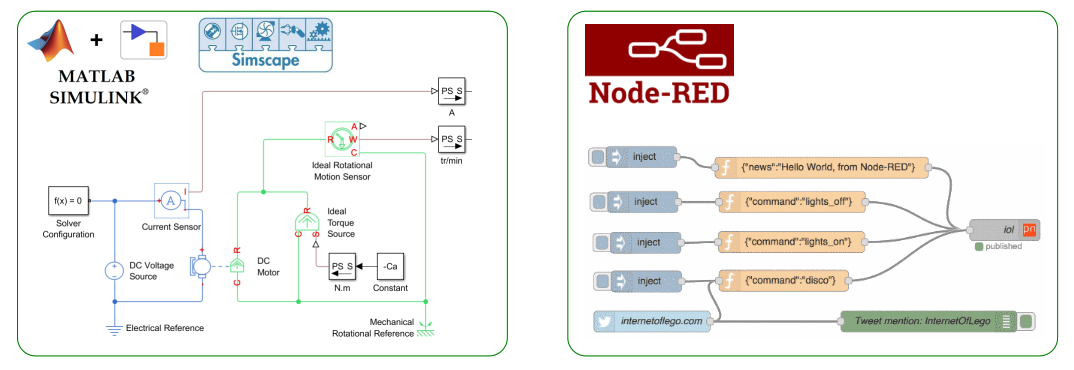
- Parmi les langages graphiques, on peut citer notamment Scratch (langage d'apprentissage par blocs), Simulink/Simscape (interfaces de modélisation multi‑physique du langage Matlab – cf. pour exemple la capture d'écran ci‑dessous), Node‑RED (outil de développement web pour l'IoT – cf. pour exemple la capture d'écran ci‑dessous), LD, FBD, SFC (langages pour automates programmables industriels)…
// "Hello World" in C++
#include <iostream>
int main()
{
std::cout << "Hello World!";
return 0;
}
#"Hello World" in Python
print("Hello, World!")
Langages interprétés versus compilés
Selon le langage de codage utilisé, la traduction du code source en code machine nécessite un logiciel spécifique qui peut être :
- soit un interpréteur W – on dit aussi un moteur d'interprétation ; on parle alors de langage interprété ou encore de langage de script ;
- soit un compilateur W – plus exactement une chaîne de compilation car il s'agit d'un ensemble de composants logiciels qui se succèdent pour produire le code machine ; on parle alors de langage compilé.
Ces deux types de logiciels traducteurs adoptent chacun un mode opératoire très différent, ils présentent l'un par rapport à l'autre des avantages et des inconvénients.
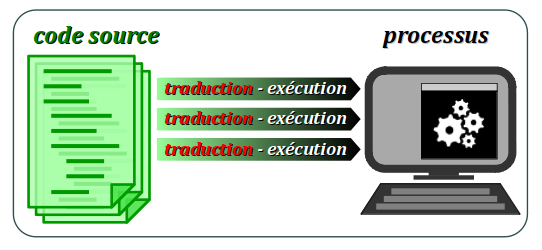
- Un interpréteur traduit une par une les instructions du programmes et les exécute à la volée. Il n'y a pas d'étape intermédiaire de production d'un fichier de code machine. Le fichier source est donc forcément stocké sur la machine d'exécution.
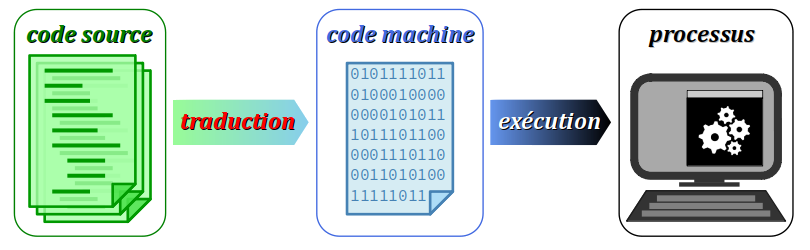
- Un compilateur traduit toutes les instructions d'un programme sont en code machine avant l'exécution, formant un fichier exécutable, indépendant du code source. C'est seulement ensuite que l'exécution du programme peut commencer.
- Parmi les langages interprétés les plus utilisés, on peut citer notamment :
- les 3 langages du web interprétés dans le navigateur, c'est‑à‑dire HTML/CSS et JavaScript ;
- quelques langages généralistes comme Python, Perl ou Ruby, Lua, etc. ;
- des langages spécialisés comme Matlab, R ;
- les langages de Shell comme Bash, Zsh (Linux), PowerShell (Windows)…
- Parmi les langages compilés les plus utilisés, on peut citer :
- la plupart des grands langages généralistes comme C/C++, Java, Ada, Delphi ;
- quelques langages spécialisés comme (La)TeX, LD/FBD/IL/ST/SFC (pour automates programmables).








- Certes emblématique, la compilation n'est qu'une étape d'un processus complexe, appelée chaîne de compilation (en anglais, tool chain) faisant intervenir de nombreux composants logiciels : préprocesseur, compilateur, éditeur de liens… Son étude sera abordée dans partie C4 du module.
- De nombreux interpréteurs procèdent par en fait par compilation à la volée W de blocs d'instructions dans un langage intermédiaire appelé bytecode W, qui est ensuite interprété pour exécuter le programme. C'est souvent le cas pour les langages Python, JavaScript, Ruby…
- Certains langages (Java, C♯…) sont compilés à la volée avant d'être interprétés sur une machine virtuelle W pour l'exécution proprement dite.
Vocabulaire technique
Pour un codeur, la connaissance de quelques termes anglais permet de mieux se familiariser avec l'univers de la programmation.
- Le résultat de la compilation d'un code source est appelé build ; ainsi :
- on trouve souvent un bouton ou menu «
Build» dans l'interface des logiciels de développement ; - on parle de nightly build pour désigner une toute nouvelle version d'un logiciel, peu ou pas encore testée.
- La phase d'exécution d'un programme est appelée run time (souvent orthographié « runtime »). Elle est précédée d'une phase de chargement – en anglais, (up)loading phase – du programme en mémoire centrale (RAM).
- On parle de compilation native W – en anglais, native compilation – lorsque le programme est produit sur une machine source ayant la même architecture matérielle (tout particulièrement, le même jeu d'instruction de son processeur) et le même système d'exploitation que la machine cible (target) sur laquelle le programme est destiné à s'exécuter.


Paradigmes (ou styles) de programmation
En programmation informatique, on parle de paradigme W pour désigner telle ou telle méthode générale de codage des instructions qui constitue un style conceptuel.
Au cours des trois dernières décennies et avec l'essor des technologies numériques, les pratiques de la programmation ont beaucoup évolué.
Le choix d'un langage n'impose pas forcément un paradigme de programmation particulier. Toutefois, le codage est grandement facilité si le langage a été conçu pour le paradigme adopté.
Partant de ce constat, la plupart des langages récents sont multi‑paradigmes pour s'adapter à toutes sortes de contextes de développement.
Le mot « paradigme » est issu du domaine de la grammaire. Dans son sens original, il désigne un modèle pour une conjugaison ou une déclinaison. Par exemple, « aimer » est souvent utilisé comme paradigme de la conjugaison des verbes du 1er groupe.
Programmation impérative versus déclarative
- On parle de programmation impérative W lorsqu'on peut affecter directement des valeurs aux variables. Les architectures matérielles usuelles des machines (processeur et mémoire en liaison directe par un bus) sont conçues pour ce paradigme qui est de loin le plus couramment adopté.
- Dans le cas contraire, si l'opération d'affectation directe n'est pas employée, on parle de programmation déclarative, et pour certains langages, de programmation fonctionnelle W, dans la mesure où un programme est alors constitué d'un ensemble de déclarations et d'appels de fonctions.
La programmation impérative est très intuitive mais elle présente un inconvénient : elle rend impossible toute vérification mathématique du bon fonctionnement d'un programme. En effet, l'affectation d'une valeur à une variable écrase irréversiblement sa valeur précédente et empêche ainsi de mener un raisonnement rétrospectif pour déterminer l'état précédent avant une affectation.
A contrario, La programmation fonctionnelle est réputée très fiable mais elle est intellectuellement complexe, et pour le moment beaucoup moins employée que la programmation impérative, sauf dans certains contextes spécifiques (recherche mathématique et informatique…)
- La très grande majorité des langages sont impératifs : C, C++, Python, Java, JavaScript, php, etc.
- Quelques langages particuliers sont déclararatifs. On peut citer notamment Lisp, CaML, FBD (langages dits fonctionnels), Prolog (programmation logique)…


Programmation séquentielle, structurée et procédurale
Programmation séquentielle

On parle de programmation séquentielle lorsque les instructions sont codées l'une après l'autre dans leur ordre d'exécution linéaire, du début à la fin du programme.
Il est très rare qu'un programme soit purement séquentiel. Pour des questions de lisibilité, de concision et de robustesse, on s'efforce de « factoriser » les répétitions de code grâce à des structures de contrôles (notamment avec des boucles – cf. la section suivante).

Dans l'extrait de programme ci‑dessous codé en C++ pour carte Arduino ci‑dessous (fonction setup), on configure en sortie (OUTPUT) les broches n° 2 à 5 du port d'entrées‑sorties numériques de la carte (typiquement, pour piloter des leds – cf. chap. C2‑VIII ).
On procède par programmation séquentielle en répétant 4 fois les appels des fonctions pinMode et digitalWrite. Cette solution lourdement répétitive est évidemment déconseillée.
void setup()
{
pinMode(2, OUTPUT);
digitalWrite(2, LOW);
pinMode(3, OUTPUT);
digitalWrite(3, LOW);
pinMode(4, OUTPUT);
digitalWrite(4, LOW);
pinMode(5, OUTPUT);
digitalWrite(5, LOW);
}
Programmation structurée

On parle de programmation structurée W lorsque les instructions sont codées avec des structures de contrôle d'embranchements (typiquement, avec des mots‑clefs comme if, etc.) et des répétitions (mots‑clefs for, while, etc.).
Ce style de programmation permet de factoriser le code source, c'est‑à‑dire fusionner plusieurs instructions similaires en une seule, plus générique. C'est une première étape décisive dans la recherche de modularité (cf. infra ).
Dans l'extrait de code ci‑dessous, les instructions de configuration des broches de l'exemple précédent (cf. supra ) sont factorisées à l'aide d'une structure de contrôle for (cf. les lignes n° 12 à 15 et pour plus de détails sur la syntaxe, le chap. C2‑VIII ).
Cette solution est déjà bien plus satisfaisante que la précédente en termes de lisibilité et de concision.
void setup()
{
for (int ledPin = 2; ledPin <= 5; ledPin++) {
pinMode(ledPin, OUTPUT);
digitalWrite(ledPin, LOW);
}
}
void loop()
{
//...
}
Programmation procédurale

Même en utilisant des structures de contrôles pour éviter les répétitions, au delà d'une centaine de lignes de code, il est difficile de concevoir un programme, ou même de le relire, aussi bien en phase de conception qu'en maintenance. Comme pour un texte, il est préférable qu'il soit décomposé en plusieurs parties, chacune repérée par un titre.
On pourrait bien sûr séparer les différentes parties du code par des sauts de ligne et ajouter des commentaires pour intituler chaque partie. Toutefois, cette solution n'est pas satisfaisante car, en procédant ainsi, une éventuelle réutilisation d'une partie du code est malcommode à réaliser.

La programmation procédurale W consiste à décomposer le code en procédures aussi élémentaires que possible, qui sont appelées par le programme principal et définies séparément de ce dernier. Cette décomposition permet à la fois de structurer le code, et aussi de factoriser certains traitements répétitifs, puisqu'une même procédure peut très bien être appelée plusieurs fois dans le programme.
De nos jours, plutôt que de « procédure », on parle plutôt de fonction (notamment en langages C et C++) ou encore de routine W (en anglais routine) ; mais le terme « programmation procédurale » est resté dans le vocabulaire technique.
Plus généralement, la programmation procédurale est un paradigme décisif dans la recherche de modularité qui consiste à produire du code réutilisable dans toutes sortes de programmes. En effet, en termes de coûts de développement, il est évidemment bien plus efficace de constituer des modules de bibliothèque regroupant les routines élémentaires d'usage général (fonctions mathématiques, fonctions d'entrées‑sorties, etc.) plutôt que de devoir les recoder dans chaque programme (cf. infra ).
Tous les langages permettent la programmation procédurale – et particulièrement C et C++ qui ont été conçus dans ce but, avec un noyau très réduit autour duquel peuvent s'agréger, selon les besoins, de vastes bibliothèques.
Dans l'extrait de code ci‑dessous, les instructions de configuration des broches de l'exemple précédent (cf. supra ) sont déportées dans une fonction auxiliaire configLedPins (à partir de la ligne n° 18), distincte de la fonction setup.
void setup()
{
configLedPins();
}
void loop()
{
//...
}
void configLedPins()
{
for (int ledPin = 2; ledPin <= 5; ledPin++) {
pinMode(ledPin, OUTPUT);
digitalWrite(ledPin, LOW);
}
}
L'intérêt de cette solution procédurale devient manifeste lorsque la fonction setup doit mettre en œuvre un grand nombre de tâches. Seuls les appels de fonctions de ces tâches sont alors codés dans setup, ce qui rend cette fonction plus facile à comprendre (un peu comme une table des matières dans un livre).
Sur la base de cet exemple, on peut également illustrer ce que serait une approche modulaire. En effet, dans la fonction configLedPins ci‑dessous, les numéros des broches à configurer sont codés dans le corps de la fonction. Cela n'est pas idéal dans la mesure où pour chaque programme, les broches utilisées sont différentes.
Pour y remédier, il suffit de doter cette fonction de deux arguments pour coder les numéros de la première et de la dernière broche à configurer, comme ci‑dessous :
void setup()
{
configLedPins(2, 5);
}
void loop()
{
//...
}
void configLedPins(int firstLedPin, int lastLedPin)
{
for (int ledPin = firstLedPin; ledPin <= lastLedPin; ledPin++) {
pinMode(ledPin, OUTPUT);
digitalWrite(ledPin, LOW);
}
}
Dans cet exemple, les numéros des broches 2 et 5 sont passés comme valeur des arguments dans l'appel de la fonction configLedPins et non plus dans son corps, qui devient polyvalent, donc susceptible d'être déporté dans un module de bibliothèque.
Programmation orientée objet

La programmation orientée objet W – en abrégé POO – consiste à intégrer dans les déclarations de types de variables les fonctions qui permettent d'opérer sur elles :
- plutôt que de types, on parle alors de classes – et alors, on qualifie d'objet toute donnée déclarée d'une certaine classe ;
- plutôt que de fonctions, on parle alors de méthodes.
L'avènement de la programmation orientée objet, au début des années 1990, était motivée par la recherche d'une plus grande modularité que celle apportée par la programmation procédurale, en réponse à la complexité grandissante des programmes. Elle a constitué une véritable révolution (au sens positif du terme) dans le monde de l'informatique, avec le développement de nombreux nouveaux langages.
- Presque tous les langages modernes (depuis 1990) sont nativement conçus pour permettre la POO : C++, Java, Python, JavaScript, php… .
- En particulier, le framework Arduino, qui est codé en C++, utilise « massivement » la POO, notamment pour la mise en œuvre du moniteur série et des autres bus de communication, des capteurs en tout genre, etc.
Programmation récursive

Un programme est dit récursif W s’il emploie des fonctions qui s’appellent elles‑mêmes.
Bien entendu, un appel récursif d'une fonction ne se fait pas avec la même valeur d'argument que l'appel initial, et le code de la fonction doit prévoir une valeur de sortie pour une valeur particulière d'argument qui empêche d'aboutir à un cycle sans fin.
La récursivité est un aspect essentiel de la programmation fonctionnelle, mais elle ne se limite pas à cette catégorie de langages. La plupart des langages généralistes – C, C++, Java, Python, JavaScript, etc. – autorisent la récursivité.
Cette pratique s'avère particulièrement adaptée aux calculs scientifiques et aux opérations répétitives car elle peut simplifier grandement l'écriture du code source. Cependant, elle reste modérément employée dans les applications industrielles en raison de sa difficulté conceptuelle.
Une illustration classique de la récursivité réside dans le codage de la fonction factorielle définie par n! = 1 × 2 × … × n. Elle est codée ci‑dessous en langage C de deux façons différentes, l'une récursive, l'autre non.
// Non recursive code
int factorial(int n)
{
int factor = 1;
for (int i = 1; i <= n; i++)
factor *= i;
return factor;
}
// Recursive code
int factorial(int n)
{
if (n == 1)
return 1;
else
return n * factorial(n - 1);
}
- Le code dans le cadre à gauche est une solution non récursif : le produit final est déterminé par une boucle
for, exactement comme la formule mathématique de la définition rappelée en préambule. C'est ici la solution la plus intuitive. - Le code dans le cadre à droite est récursif puisque la fonction
factorials'appelle elle‑même, avec une valeur diminuée de1comme argument (cf. la ligne n° 26). C'est la solution pertinente lorsque l'expression mathématique de la fonction n'est connue que par une formule de récurrence.
1 donnée pour la valeur d'argument n == 1 (cf. les lignes n° 23 & 24) est indispensable pour achever l'exécution dans tous les cas (à force de diminuer la valeur de l'argument n, ce dernier finit nécessairement par atteindre la valeur 1). Programmation parallèle
On parle de programmation parallèle W lorsque les instructions sont codées dans l'objectif d'exécutions simultanées – ce qu'on appelle usuellement le multithreading W.
Par anglicisme, on parle aussi de programmation concurrente W.
Sans entrer dans les détails matériels, selon que la machine employée est mono ou multiprocesseur et la façon dont le système d'exploitation gère ses ressources (ALU, mémoire…) pour exécuter un programme, la programmation parallèle sous‑tend des concepts complexes de processus (thread), de synchronisation, de partage de ressources, etc.
Certains langages sont particulièrement adaptés pour mettre en œuvre des programmes parallèles : Java, Ada, SFC…
Outils logiciels de développement
Éditeurs de code
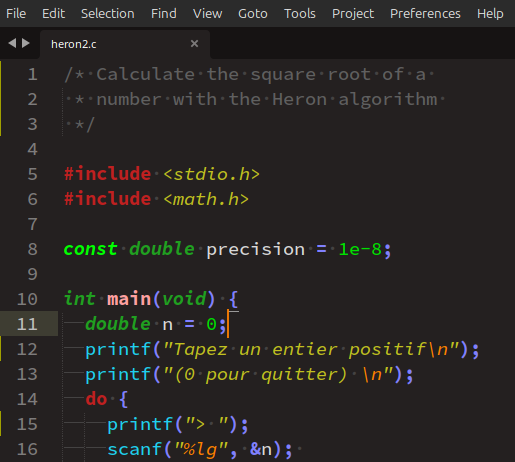
En principe, tout programme source peut être créé avec un éditeur de texte W qui est adapté à la programmation. On parle alors d'éditeur de code.
C'est un logiciel dont les fonctions principales sont la saisie et l'affichage du code et son enregistrement dans des fichiers. Il peut éventuellement être complété par des outils extensifs de développement – on dit plugin – pour tel ou tel langage.
Un éditeur de code est bien adapté :
- au développement de programmes interprétés, comme par exemple :
- les pages web, à exécuter directement dans un navigateur ;
- les scripts de commande, à exécuter directement en ligne (shell)…
- au développement de « petits » programmes compilés, typiquement ceux que l'on réalise au début d'un cursus d'apprentissage.

Tout système d'exploitation d'un poste de travail met à disposition de l'utilisateur au moins un éditeur de code par défaut, par exemple Notepad (l'outil « Bloc-Note ») sur Windows. Toutefois, cette solution n'est pas satisfaisante pour étudiant en informatique.
Heureusement, il existe plusieurs éditeurs gratuits et multiplateforme (Windows, Linux, MacOS) d'excellente qualité, très faciles à installer. On peut notamment citer les deux suivants :
- SublimeText W est un éditeur léger, extensible, facile à utiliser, il est vivement recommandé comme éditeur par défaut dans un environnement de bureau (cf. le chap. C1‑II pour plus de détails). Il est particulièrement bien adapté pour l'édition de code lorsqu'on débute en programmation.
- Vim W est un éditeur qui peut opérer dans un terminal de commandes en ligne, donc même sans environnement de bureau. Plus complexe à prendre en main qu'un éditeur usuel (car il opère de façon modale), il dispose en contre-partie de fonctionnalités avancées pour l'édition de code. Pour toutes ces raisons, il est particulièrement apprécié par les administrateurs systèmes (cf. le chap. S1‑III pour plus de détails).


Un éditeur de code peut également servir d'éditeur alternatif à celui d'un autre environnement de programmation – comme, par exemple, Tinkercad (cf. chap. C1‑III W ‑ en procédant par copier/coller pour passer de l'un à l'autre.
Un tel choix est motivé par :
- la meilleure ergonomie apportée par l'éditeur de code alternatif avec ses diverses fonctionnalités pour faciliter la saisie et la mise au point du programme : mode sombre, coloration syntaxique, auto‑indentation, auto‑complétion, etc.
- la facilité pour enregistrer le code sur le poste de travail, dès lors que l'on souhaite le réutiliser ultérieurement.
Tests des programmes en ligne de commande
Lorsque l'on conçoit des programmes avec un simple éditeur de code, les indispensables tests de bon fonctionnement doivent être menés avec des moyens externes à l'éditeur de code :
- soit dans une console d'exécution, c'est‑à‑dire une fenêtre émulant dans l'environnement d'exploitation de l'ordinateur un terminal en ligne de commande, et à condition d'avoir installé préalablement une chaîne de compilation ou un moteur d'interprétation ;
- soit en copiant‑collant le code source dans un environnement de programmation en ligne (cf. infra ).
Dans le cas d'un programme source de page web (HTML/CSS/JS ou php), les tests peuvent être effectués directement :


- dans un navigateur pour le côté client ;
- et éventuellement via un serveur virtuel (comme par exemple, WAMP server) pour simuler le côté serveur.
Environnements intégrés de développement
Pour développer des programmes complexes, un environnement intégré de développement W – EDI, en anglais IDE pour integrated development environment – est indispensable.
C’est un logiciel qui intègre ou synchronise :
- un éditeur de code, avec des fonctionnalités souvent très avancées ;
- tous les composants logiciels des chaînes de production du code exécutable – compilateurs, éditeurs de lien, débogueurs, etc. – des langages qu'il prend en charge.
Les IDE sont des logiciels souvent complexes à installer, paramétrer et utiliser. Leur prise en main nécessite un temps d'investissement conséquent.
Comme pour les éditeurs de code, chaque IDE a ses avantages et ses inconvénients. Leur perception varie au fur et mesure de l'expérience qu'on acquiert et dépend du contexte d'utilisation, professionnel ou occasionnel.
Certains IDE sont généralistes, d'autres spécialisés.


Pour les principaux langages généralistes comme C, C++, Java, Python, on dispose de divers IDE gratuits et néanmoins très performants. On peut citer notamment Eclipse W et VS Code W (Microsoft), ce dernier étant détaillé au chap. C1‑II .

Spécifique pour C++, il faut également citer l'IDE Qt Creator W, qui présente la particularité de faciliter grandement le développement d'applications à interface graphique pour environnement de bureau.
Environnements de programmation en ligne

Pour réaliser et tester des petits programmes, on peut aussi recourir à une application en ligne s'exécutant dans une page web comprenant typiquement :
- un cadre émulant un éditeur de code ;
- un cadre émulant une console d'exécution pour compiler (ou interpréter) et exécuter sur un serveur distant le code source saisi dans le cadre d'édition.
Certaines applications en ligne sont de petits utilitaires de test, d'autres constituent un véritable environnement avec un espace de stockage réservé à l'utilisateur (cloud), la possibilité de gérer des bibliothèques, etc.
Par rapport à un éditeur de code ou un environnement intégré, une application en ligne présente évidemment des avantages en termes de facilité d'emploi (pas d'installation) et de légèreté, au prix de performances bien moindres en ergonomie, puissance de traitement, vitesse, disponibilité, etc.

Pour la programmation généraliste dans divers langages, on peut employer un environnement en ligne comme OnlineGDB (cf. chap. C1‑II ).


Pour la programmation des cartes à microcontrôleurs compatibles avec le framework Arduino, on peut employer Arduino Web Editor. Il existe également Tinkercad W et Wokwi qui sont l'un et l'autre des simulateurs de circuits électroniques prototypés, dans lesquels on peut notamment placer des cartes à microcontrôleur (pour plus de détails, cf. chap. C1‑III ).
Outils de gestion de versions – sites de partage
Le développement d'un programme un tant soit peu complexe passe nécessairement par un codage progressif en versions successives, constituant autant d'étapes majeures de développement. Même pour un développeur travaillant seul, et a fortiori dans le contexte d'un travail en équipe, il devient rapidement difficile de mémoriser les particularités de telle ou telle version. Typiquement, il faut s'astreindre à :
- intégrer la numérotation des versions dans les noms des différents fichiers du code source ;
- ajouter des commentaires ou des fichiers de notes de version pour indiquer les modifications apportées par rapport à la version précédente.
Pour faciliter cette tâche laborieuse et en uniformiser les pratiques, des outils logiciels de gestion de versions W – en anglais, version control systems – ont été mis au point dès les années 1980.

Depuis les années 2010, l'outil de gestion de versions le plus utilisé est Git W, à peine 5 ans après sa première version. Gratuit et open‑source, il est très apprécié non seulement pour ses qualités en termes de rapidité, de robustesse et de flexibilité d'emploi, mais aussi et surtout pour l'approche décentralisée choisie par son développeur, Linus Torwalds W (également inventeur du noyau des systèmes d'exploitation Linux). Ainsi, chaque membre de l'équipe de développement dispose de ses propres fichiers d'archive, sans nécessiter en permanence l'accès à un serveur centralisé.
Fondamentalement, Git opère dans un terminal de commandes en lignes (en anglais, command line interface ou CLI), mais il existe aussi des interfaces graphiques, sachant qu'elles restent assez rudimentaires.
La popularité de Git s'est encore accentuée avec l'avènement des solutions d'hébergement et de partage de code source basées sur Git, notamment GitHub (2008), GitLab (2011) ou encore Bitbucket (anciennement Stash, créée en 2008).
- GitHub W est une plateforme web multi‑services ouverte aux particuliers et aux professionnels. L’hébergement est gratuit tant qu'il est public, autrement dit pour les codes open‑source (puisque n'importe qui peut y accéder – sauf dans certains pays sous sanctions américaines). L'entreprise a été rachetée en 2018 par Microsoft, sans occasionner de changements majeurs de politique commerciale.
- GitLab W est avant tout une application web qui peut être installée sur n'importe quel serveur web privé, pour permettre aux équipes de développement de maîtriser leur solution de partage de code source. Elle existe dans une version gratuite, dite CE (pour Community edition) une version commerciale, dite EE (pour Enterprise edition), avec davantage de fonctionnalités.


Forums de discussion

Développé avant tout par des codeurs, le web a rapidement hébergé d'innombrables ressources d'aide au codage : cours en ligne, tutoriels, etc. Parmi ces ressources, les forums de discussion tiennent une place à part, en ce qu'ils permettent a priori à quiconque de poser des questions très spécifiques sur telle ou telle particularité en faisant appel à l'expertise collective humaine pour y apporter des réponses. Et ces réponses font l'objet d'une évaluation des participants (coche verte, commentaires), ce qui permet à tout lecteur d'en estimer la qualité.
Depuis, certains forums sont devenu de véritables « institutions », mais en fait, tout forum ayant un peu d'envergure est soit une entreprise commerciale à part entière, soit rattaché à une grande entreprise, car il faut bien financer l'hébergement sur des serveurs de la base de données des discussions, la maintenance et l'évolution du code source des sites, la modération, etc.

Aujourd'hui, même en se limitant au domaine de la programmation, il est impossible de dresser une liste représentative de la diversité des forums de discussion, tant cette diversité est fluctuante. À titre d'exemple emblématique, on peut néanmoins citer Stack Overflow W. Il s'agit précisément d'un site de questions/réponses spécialisé dans le domaine de la programmation informatique. Créé en 2008 par Jeff Atwood W et Joel Spolsky W, Stack Overflow connaît un succès fulgurant et devient dès 2009 une entreprise à part entière. Acquise en 2021, pour près de 2 milliards de dollars par le fond d'investissement néerlandais Prosus (lui‑même filiale de la multinationale sud‑africaine Naspers ), Stack Overflow revendique aujourd'hui plus de 20 millions d'utilisateurs enregistrés et son site fait partie des 500 les plus visités au monde (ce qui est considérable étant donnée sa spécialisation).
Sur Stack Overflow, l'ensemble des pages de discussion est en libre consultation. C'est pour pouvoir y participer – poser des questions et répondre à celles des autres utilisateurs – qu'il faut être enregistré. De plus, un peu à la manière de Reddit W, chaque question ou réponse est soumise au vote positif ou négatif des autres utilisateurs, avec à la clef des avantages pour les utilisateurs les mieux notés (ce qui valorise leur expertise).
Depuis l'essor en 2022 des agents conversationnels dits « IA » (cf. infra ), les forums de discussion ont subi une forte baisse de fréquentation considérablement baisser . En effet, ces nouvelles formes de support ont l'avantage d'être beaucoup plus rapides. Cependant, il ne faut pas perdre de vue les considérations suivantes :
- Mme en informatique, les IA se trompent encore souvent ; il est donc sage de ne pas négliger les forums pour résoudre les problèmes rencontrés lors du codage ou de la mise au point d'une programme.
- Les connaissances des IA en informatique sont en partie basées sur les fils de discussion des forums. Le tarissement de cette source d'information pose un problème à long terme.
Agents conversationnels « intelligents »

Le 30 novembre 2022, l'entreprise OpenAI W mettait gratuitement à la disposition des internautes ChatGPT W, un agent conversationnel W – en anglais, chatbot (acronyme de chat et robot) – qui utilise un moteur d'intelligence artificielle générative W basé sur un grand modèle de langage W (large language model, abrégé LLM). Ce nouvel outil connaissait alors un succès extraordinaire puisque que, moins de 2 mois après cette date, il comptait déjà plus de 100 millions d'utilisateurs ! Cela s'expliquait par le très vaste spectre des applications possibles : la rédaction de textes de toutes sortes (lettre, article de presse, résumé de cours, synthèse, code informatique, etc.).



Depuis cette date, la concurrence s'est développée chez les grandes entreprises du numérique, mais aussi chez de nouveaux acteurs émergents du secteur, avec notamment Gemini W (Google), Mistral AI W, Claude W (Antropic W)…

Désormais, les agents conversationnels intelligents sont massivement utilisés par les codeurs professionnels, non seulement via leurs interfaces web, mais aussi directement dans les environnements intégrés de développement. À titre d'exemple, avec une extension comme Github Copilot W (co‑développé avec OpenAI) pour un IDE comme VS Code, on dispose notamment des fonctionnalités suivantes :
- L'agent fait des propositions du code à la volée, c'est‑à–dire précisément au moment où le codeur le saisit – comme de l'auto‑complétion mais pas seulement pour l'identificateur en cours (pour toute l'instruction).
- Le codeur peut aussi solliciter l'agent via la palette de commande, ou dans des menus contextuels, par exemple, la commande
Fix with copilot…pour corriger une erreur détectée par le logiciel.
En principe, ces fonctionnalités apportent un gain de productivité non négligeable dès lors que la base de connaissance de l'agent est à jour des connaissances requises pour le programme codé. Mais elles peuvent aussi être ressenties comme particulièrement dérangeantes lorsqu'elles ne cessent de prendre des initiatives qui sortent des objectifs du codeur.
Usage pour l'apprentissage de la programmation
Dans le cadre des études en informatique, et tout particulièrement pour l'apprentissage de la programmation, l'usage d'un agent conversationnel intelligent doit être fait avec mesure et précaution. En effet :
- Il est tentant d'y recourir à la moindre difficulté rencontrée, avec le risque de ne jamais acquérir la capacité de concevoir des algorithmes.
- Il est difficile d'évaluer la qualité des solutions proposées lorsqu'on débute.
En séances de travaux pratiques, il est contre‑productif d'y recourir dès lors qu'un(e) enseignant(e) est disponible pour répondre aux questions et veiller à la progression pédagogique.
En revanche, dans les situations d'apprentissage en autonomie (codage à la maison), une IA peut constituer une aide précieuse, dès lors :
- qu'on formule des questions aussi limitées que possibles sur ce que l'on ne parvient pas à coder – l'objectif principal restant l'acquisition de compétences ;
- qu'on lui demande des explications sur les éléments de code proposés (et qu'on prend le temps de les lire).
En tout état de cause, il ne faut surtout pas copier‑coller le sujet de TP en guide de prompt, car c'est le meilleur moyen pour ne rien apprendre.
Enfin, pour bien comprendre pourquoi un agent conversationnel est parfaitement capable de se tromper lourdement dans ses réponses, il est vivement recommandé de regarder cette vidéo de David Louapre Y sur sa chaîne YouTube Science Étonnante. Il y explique notamment comment fonctionne un grand modèle de langage pour générer un texte de réponse à une question, avec un algorithme qui est fondamentalement basé sur des estimations statistiques.
Enjeux du génie logiciel
Le foisonnement des langages et des paradigmes de programmation n'est pas le fruit du hasard. Il répond à :
- la complexité grandissante des programmes qu'exigent les besoins techniques de nos sociétés ;
- l'extrême difficulté qu'il y a à garantir le bon fonctionnement de ces programmes complexes.
Le terme génie logiciel W désigne la science des méthodes de développement des logiciels.
Ses enjeux – c'est‑à‑dire les grandes thématiques qui font l'objet de débats, de compétitions, d'évolutions – sont nombreux. Pour commencer, on peut considérer les trois suivants : lisibilité, modularité, portabilité .
Lisibilité
Un programme est toujours beaucoup plus lu qu'il n'est écrit :
- même en phase de conception, le codeur lui‑même passe énormément de temps à relire ses propres instructions ;
- s'ajoute à cela le temps de lecture des collaborateurs sur toute la durée de vie du logiciel, dont la maintenance (la production des mises à jours), qui est un aspect essentiel en termes de coût.
La bonne lisibilité d'un programme est donc un enjeu majeur du génie logiciel. Elle est impactée par :
- les détails du code (choix des noms des variables, commentaires), auxquels le lecteur est confronté dès qu'il commence à lire ;
- mais aussi par la structure du programme (algorithme, méthode formelle sous-jacente), sur laquelle le lecteur va nécessairement tenter de prendre du recul pour comprendre.
Au delà des enjeux spécifiques de rapidité ou d'économie de mémoire, la bonne lisibilité est à privilégier sur les solutions astucieuses et originales car la complexité de ces dernières peut compromettre la fiabilité de l'exécution. Souvent, c'est par difficultés de compréhension que les codeurs échouent à détecter des erreurs insidieuses.
Des règles de bonne pratiques, notamment en matière de lisibilité, sont exposées au chapitre C2‑X .
Modularité
Le plus souvent, une application commercialisée compte au bas mot plusieurs milliers de lignes de code, nombre qui peut aller jusqu'aux millions (voire même le milliard pour les plus gros logiciels ! ) Aucun programmeur ne peut maîtriser à lui seul un tel contenu.
La « réponse » au gigantisme des programmes est la modularité W qui, pour aboutir à des composants logiciels réutilisables, commence avec la programmation procédurale et s'affine grâce à la programmation orientée objet (cf. supra )
La recherche de modularité ne repose pas seulement sur la constitution de bibliothèques de fonctions, mais aussi sur une bonne documentation (détail des en‑tête de fonctions, exemples d'emploi, etc.) qui facilite grandement l'exploitation des composants modulaires.
Les notions clefs de la modularité (fonctions, classes, fichiers d'en‑tête, etc.) et les techniques de programmation qu'ils exigent sont étudiées dans la partie C4 du module. Mais dès le début de l'apprentissage, il faut mettre en place les bonnes habitudes de factorisation du code par un emploi pertinent des structures de contrôles, exposées dès le chapitre C2‑V .
Portabilité
Tout programme s'exécute nécessairement dans un environnement informatique donné (machine, système d'exploitation, navigateur…). La portabilité est l'aptitude d'un programme à bien fonctionner quel que soit l'environnement matériel et logiciel où il est exécuté W.
Et on parle de portage pour désigner les modifications entreprises pour faire fonctionner un programme existant dans un nouvel environnement.
La mondialisation des technologies numériques et l'essor des systèmes mobiles ou « intelligents » font de la portabilité un enjeu majeur, auquel l'évolution des langages s'efforce de répondre (normes, bibliothèques standards, machines virtuelles, etc.).