
On a vu dès le chapitre C1‑I que la lisibilité des programmes est un enjeu décisif du génie logiciel – cf. le livre Clean Code: a handbook of agile software craftsmanship qui est entièrement consacré à cette question, et dont il existe une version française (Coder proprement). Le respect de l'exigence de lisibilité du code tient avant tout à l'observance de bonnes pratiques générales, certaines ayant déjà été proposées dans divers chapitres de cette partie C2 du cours, par exemple au chap. C2‑III pour la déclaration des constantes .
Mais ce qu'on appelle « bonne pratique » peut varier d'une période, d'un langage ou d'un contexte professionnel à l'autre (entreprise, laboratoire de recherche, équipe…). Très souvent, un chef de projet informatique impose à son équipe de développement une convention de codage W, c'est‑à‑dire un ensemble de règles et de recommandations à respecter, pour notamment :
- prévenir des erreurs classiques grâce à des obligations et des interdictions formelles (par exemple, pas de
goto…) ; - garantir l'homogénéité du code, dont la production est nécessairement répartie entre plusieurs codeurs, et ainsi faciliter sa relecture ainsi que la coordination du projet.
Néanmoins, pour un codeur débutant à qui l'on demande de composer des programmes courts et très simples comme ceux des premiers exercices et travaux pratiques de ce module de formation, il est difficile de comprendre l'importance des conventions de codage. Souvent perçues comme inutilement contraignantes, ces dernières semblent pénaliser l'effort intellectuel nécessaire pour concevoir les solutions aux problèmes posés.
Il faut pourtant y accorder la plus grande attention pour adopter dès le début de bonnes habitudes. Elles prendront tout leur sens au fur et à mesure de l'apprentissage individuel (ne serait‑ce que pour pouvoir relire son propre code plus facilement) puis dans le cadre d'un travail d'équipe.
Sans prétention d'exhaustivité, les recommandations de ce chapitre se concentrent sur les premiers détails auquel tout codeur est confronté au début de son apprentissage :
- choisir des identificateurs de données ou de fonctions,
- rédiger des commentaires,
- indenter et espacer les éléments de code…
D'autres aspects importants pour la lisibilité – la décomposition en fonctions, le choix des algorithmes et des structures de données – seront abordés au fur et à mesure des chapitres, avec un repérage explicite, comme cela a déjà été fait dans les chapitres précédents.


Pour une présentation plus détaillée, on pourra consulter le guide rédigé et gratuitement distribué par l'ANSSI (Agence nationale de la sécurité des systèmes d'information W), en gardant toutefois à l'esprit qu'en matière de bonnes pratiques, personne ne détient de vérité absolue – même une agence nationale.
Les identificateurs
Pour tous les identificateurs choisis par le codeur (noms de variables, types, classes, fonctions…), trois règles simples sont à observer :
- n'employer que l'anglais ;
- choisir des noms explicites ;
- adopter une convention typographique usuelle.
Ces règles sont respectivement détaillées dans les trois sections qui suivent.
Tout en anglais

Dans un code source, quel que soit le langage de programmation, le recours exclusif à l'anglais (GB ou US) pour nommer les identificateurs est vivement recommandé car il présente plusieurs avantages décisifs sur toute autre langue.
- En premier lieu, il y a l'homogénéité linguistique car, sauf exception, quel que soit le langage de programmation, tous les mots‑clefs, les noms de types et les identificateurs de fonctions standards sont déjà issus de l'anglais. Si le codeur forme aussi ses identificateurs en anglais, le code peut former des instructions très semblables à des phrases dans cette langue.
- Un deuxième aspect important est la concision des termes car les mots en anglais sont, en règle générale, plus courts en anglais que dans la plupart des autres langues – notamment le français.
- Un autre atout de l'anglais est l'absence de caractères diacritiques (lettres accentuées, etc.) qui sont non conformes aux restrictions de codage des identificateurs (cf chap. C2‑II . Avec une langue assez accentuée comme le français, on s'expose à des risques de confusion sur le sens des identificateurs choisis.
- le premier mot
precedentpeut être interprété de deux façons : - comme « précédent » (adjectif) – c'est ce que l'on veut dire ici ;
- mais aussi comme « précèdent » (forme conjuguée).
- le dernier mot
affichepeut aussi être interprété de deux façons : - comme « affiché » (participe passé) c'est ce que l'on veut dire ici ;
- ou encore comme « affiche » (le nom).
- Enfin, il faut aussi prendre en compte l'universalité linguistique dans le cadre d'équipes internationales de développement, où tout le monde parle anglais – ce qui est rarement le cas pour d'autres langues.

Pour un programme de simulation de lancers d'un dé à 6 faces, le code ci‑dessous est rendu particulièrement lisible grâce à l'emploi d'identificateurs explicites en anglais :
while (randomNumber == previousDisplayedNumber) {…
En effet, avec le mot‑clef while forcément en anglais l'instruction se lit presque mot‑à‑mot comme le début d'une phrase en langage naturel :
« While the random number equals the previous displayed number… »
En prolongement de l'exemple précédent d'un programme de simulation de lancers d'un dé à 6 faces, observons l'identificateur anglais :
randomNumber
Il fait 3 lettres de moins que son équivalent en français :
nombreAleatoire
Ce gain de longueur de 25 % n'est pas négligeable. Il devient d'autant plus sensible lorsqu'on emploie l'identificateur dans une expression un peu élaborée, au point de nécessiter parfois des sauts de lignes indésirables.
En prolongement de l'exemple précédent d'un programme de simulation de lancers d'un dé à 6 faces, considérons maintenant l'identificateur anglais :
previousDisplayedNumber
Son équivalent en français le plus direct est :
precedentNombreAffiche (sans accents)
où :
Ces multiples possibilités font que, lors d'une première lecture, le sens de l'identificateur français « ne saute pas immédiatement aux yeux ».
Des identificateurs explicites
En règle générale, tout identificateur doit préciser en lui‑même le rôle de l'objet qu'il désigne.
La précision avec laquelle un identificateur décrit son objet résulte d'un compromis :
- Elle doit être suffisante pour rendre intelligibles le sens des instructions dès leur première lecture.
- Les identificateurs
b,pboupush_bsont à bannir car ce sont abréviations non universelles, ici beaucoup trop courtes, donc pas claires. - Les identificateurs
buttonoupushButtonne sont pas assez explicites, car ils omettent de préciser que l'objet désigné est un niveau logique de tension – aspect matériel très important. - Les identificateurs
buttonLeveloupushButtonLevelconviennent, le premier ayant l'avantage de la concision. Son manque de précision sur le type du bouton (poussoir, tournant, tactile, etc.) n'a pas d'impact en termes de compréhension dès lors que cet aspect n'est pas déterminant pour la compréhension du code. Avec ce choix, un test conditionnel comme par exemple :
if (buttonLevel == HIGH)
est parfaitement compréhensible. C'est donc la solution le plus souvent retenue. - Mais il faut que la précision ne soit pas excessive, car plus les identificateurs sont longs, plus les instructions sont pénibles à lire et même à formater (on est amené parfois à devoir insérer des saut de lignes indésirables).
- Dans l'exemple précédent d'une variable qui mémorise le niveau logique de tension sur une entrée du port numérique d'une carte à microcontrôleur à laquelle un bouton‑poussoir, l'identificateur :
pushButtonLogicalVoltageLevel
est certes plus précis mais en contre‑partie, il alourdit considérablement le code, sans grande utilité. - Dans un programme de contrôle commande de moteur à courant continu, pour ajuster la fréquence de modulation de largeur d'impulsion sur la grille d'un transistor MOSFET à canal N, il est utile de déclarer :
- un identificateur de constante comme par exemple :
NMOS_TRANSISTOR_GATE_PIN
pour désigner la grille du transistor (gate en anglais) ; - un identificateur de variable comme par exemple :
pwmFrequency
pour désigner la fréquence de modulation ; -
pulseWidthModulationà la place depwm, -
NEGATIVE_CHANNEL_METAL_OXYDE_SEMICONDUCTORà la place deNMOS.
rpm, mph, pwm, etc. 
Pour nommer une variable qui mémorise le niveau logique de tension sur une entrée du port numérique d'une carte Arduino à laquelle un bouton‑poussoir est relié :
HIGH et LOW par d'autres comme IDLE et PUSHED. On pourrait alors coder un test conditionnel très lisible comme, par exemple : if (button == PUSHED)


analogWriteFrequency(NMOS_TRANSISTOR_GATE_PIN, pwmFrequency);
Dans la pratique, on observe dans du code professionnel des exceptions à la règle supra. En particulier, pour les variables d'itération de boucles for, dont l'usage est tellement familier, un identificateur constitué d'une seule lettre générale comme i ou k ou n peut suffire. Par exemple, on peut coder :
for (int i = 1; i <= 10; i++) {…
en pensant raisonnablement que cette ligne de code ne présente aucune difficulté de compréhension.
Néanmoins, si le bloc de la boucle for est complexe, alors il peut être préférable d'employer un identificateur plus explicite pour la variable d'itération. Par exemple, on peut choisir row si l'itération porte sur les numéros de lignes d'un tableau de NB_ROW lignes à parcourir. Le code acquiert alors une bonne lisibilité et tout en gardant une bonne consision :
for (int row = 0; ledPin < NB_ROW; row++) {…
Une typographie optimisée
Usage du tiret‑bas : le style « snake case »
En langages C et C++, le tiret‑bas _ est le seul caractère symbolique autorisé dans les identificateurs. Il est tentant de l'employer pour simuler un espace et ainsi former des identificateurs composés de plusieurs mots, comme par exemple push_button_level.

Ce style de typographie porte le nom de « snake case » W, parce que la succession des mots et des tirets peut faire penser à un serpent. Son principal avantage est qu'elle facilite grandement la lecture des identificateurs par le fait que les mots qui le composent se détachent bien les uns des autres.

La typographie « snake case » est utilisée à divers endroits de la bibliothèque standard du C++, par exemple dans le fichier d'en‑tête random, où l'on trouve notamment les classes de moteurs de génération de nombres aléatoires suivantes C++ :
-
linear_congruential_engine, -
mersenne_twister_engine, subtract_with_carry_engine…
Ce choix est particulèrement bien venu ici pour des identificateurs déjà assez complexes.
Toutefois, par rapport au « camel case » (cf. ci‑après), le style snake case présente l'inconvénient qu'il allonge un peu les identificateurs.
Mots compactés : le style « camel case »
Pour ne pas recourir au tiret‑bas, une solution typographique très répandue pour former un identificateur consiste à commencer chaque mot qui le compose par une lettre majuscule, comme par exemple : pushButtonLevel.

Ce style de typographie est appelé « camel case » W parce que les majuscules au début de chaque mot peuvent faire penser aux bosses d'un chameau. Elle produit des identificateurs plus compacts mais un peu moins lisibles qu'en « snake case ».

Dans le framework Arduino, c'est surtout la typographie « camel case » qui est employée. Pour s'en convaincre, il suffit de jeter un œil au fichier d'en‑tête principal arduino.h avec, aux lignes nº 104 et suivantes, des exemples remarquables :
-
clockCyclesPerMicrosecond, -
clockCyclesToMicroseconds, -
microsecondsToClockCycles…
Attention, le style « camel case » présente quelques subtilités.
1) Par convention, on ne met pas de majuscule à la toute première lettre de l'identificateur si ce dernier désigne une donnée ou une fonction. En effet, on réserve l'emploi d'une majuscule initiale seulement pour les identificateurs de types déclarés par le codeur (cf. chap. C3‑I ).
Il est d'usage courant de donner presque le même identificateur pour désigner une unique variable d'un type défini par le codeur et le type lui‑même. Dans un tel cas, ils se distinguent uniquement par le fait que :
- l'identificateur du type prend une majuscule initiale ;
- l'identificateur de la variable prend une minuscule initiale.

Par exemple, dans le cadre d'un programme académique de jeu de Puissance 4 recodé en langage C++ avec les concepts de la programmation orientée objet (cf. chap. C2‑VI ), on déclare un seul objet nommé connect4board de la classe Connect4board – donc avec presque le même identificateur sauf pour la majuscule initiale « C » :
Connect4board connect4board;
2) Même si un mot est un sigle dans la langue courante (par exemple, LED, PWM, etc.), il n'est pas opportun de le saisir en majuscules dans les identificateurs car cela complique leur lecture.

Dans l'identificateur d'une variable qui mémorise la couleur d'une LED à technologie RGB (cf. le sujet de TP. C3‑2 ), comme par exemple :
middleLEDColor
il est difficile de lire la transition entre les mots LED et Color. On pourrait alors être tenté de coder plutôt :
middleLEDcolor
mais ce n'est pas la pratique courante. La solution usuelle consiste plutôt à coder le sigle LED en minuscules pour retrouver une typographie « camel case » classique, comme ci‑dessous :
middleLedColor
La règle nº 1 énoncée supra qui consiste à ne jamais employer une majuscule initiale pour un identificateur de donnée prime aussi sur la convention générale d'employer des majuscules pour les sigles.
En effet, la présence d'une majuscule initiale dans un identificateur est automatiquement détectée par de nombreux éditeurs de code, qui assimilent alors l'identificateur à celui d'un type ou d'une classe et lui confère alors le style spécifique réservé à cette catégorie syntaxique (selon les réglages par défaut ou choisis).

Exemple. Observons la mise en forme automatique opérée dans sur cette présente page web par le script Code Prettify (cf. infra ) sur les deux identificateurs déclarés ci‑dessous pour une variable censée mémoriser l'état éteint ou allumé d'une LED (sigle anglais pour light emitting diode) :
int ledState = 1; // OK int LEDstate = 1; // NOT OK! Data identifier detected as a type name
- La ligne n° 10 ne pose pas de problème puisque, avec sa minuscule initiale,
ledStateest bien détecté comme une identificateur de donnée. - En revanche, à la ligne n° 11, à cause de la majuscule initiale,
LEDstateest détecté comme un identificateur de type, et affiché enitalique vert, comme le descripteurint, ce qui n'est pas satisfaisant puisqu'il s'agit d'une donnée, et non pas d'un type.
Identificateurs en majuscules
Par convention, on met entièrement en majuscules les identificateurs des constantes déclarées et surtout des pseudo‑constantes (introduites par des macro‑définitions – cf. chap. C4‑III ).
Lorsqu'un identificateur entièrement en majuscules est composé de plusieurs mots, le tiret‑bas _ est alors bienvenu pour les séparer. Le style « snake case » est alors incontournable.
Cette convention permet, lors de la lecture d'un d'un code source, de distinguer au premier coup d'œil les constantes et les variables, sans avoir besoin de retruver leur déclaration dans le code (ce qui peut être fastidieux, notamment si le code est réparti sur plusieurs fichiers).
- Pour gérer les modes de marche et d'arrêt d'un système, il est préférable de définir des constantes explicites, plutôt que d'employer directement les valeurs booléennes
0et1. On pourra ainsi coder : - Pour coder les numéros des première et dernière broches du port numérique d'une carte Arduino toutes reliées à des LED formant un chenillard ou un bargraphe (cf. les sujet de TP. C2‑2 et C3‑1 ), on déclare typiquement les identificateurs de constantes :
FIRST_LED_PINetLAST_LED_PIN

const bool STOP = 0; const bool RUN = 1; bool mode = STOP;
0 signifie « arrêt » et 1 signifie « marche »). Comme il s'agit d'identificateurs très courts, le fait de les coder en majuscules n'alourdit pas le code tout en les rendant plus faciles à repérer que des valeurs numériques qui peuvent partager bien d'autres usages. 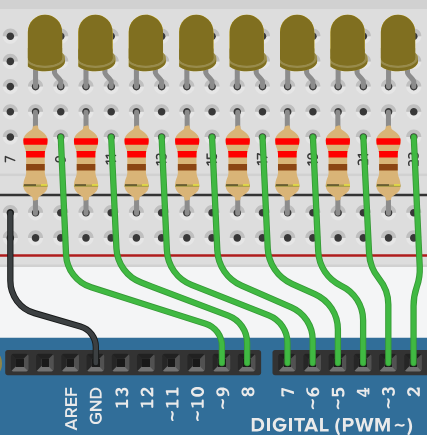
for dont l'en‑tête est :
for (int ledPin = FIRST_LED_PIN; ledPin <= LAST_LED_PIN; ledPin++) { //…
Les commentaires

Parce qu'ils ne sont pas du code et qu'ils sont potentiellement très divers, les commentaires ne peuvent faire l'objet que de règles informelles. Au delà des aspects purement syntaxiques qui ont été présentés au chapitre C2‑II , une manière d'aborder cet aspect non normalisé de la programmation consiste à suivre un questionnement analytique classique :
Pourquoi ? Où ? Comment ?
Pourquoi ?
On rappelle (cf. chap. C2‑II ) que la principale fonction d'un commentaire est de fournir aux lecteurs du code source une explication complémentaire à une partie de code.
Dans l'idéal, si les identificateurs ont bien été choisis, alors les éléments de code doivent se comprendre à leur simple lecture. On dit que l'on produit un code auto‑documenté, et les commentaires sont alors superflus.
Cette mise en perspective est essentielle pour déterminer la quantité et le niveau de détail requis des commentaires afin qu'ils jouent pleinement leur rôle, mais sans excès. En effet, rédiger des commentaires :
- demande du temps (y compris durant la maintenance du code) qui ne doit pas augmenter démesurément celui qui est consacré au codage proprement dit ;
- occupe dans les fichiers un espace qui ne doit pas nuire à la lisibilité du code.
Donc, sauf dans un contexte pédagogique, il n'est pas question de saisir des commentaires pour expliquer le rôle de chaque instruction. On suppose que tout lecteur potentiel, y compris un chef de projet, a suffisamment de compétences pour comprendre l'essentiel du code. On veillera donc à commenter le moins possible, c'est‑à‑dire presque jamais !
En pratique, il est recommandé d' ajouter des commentaires pour préciser ponctuellement :
- les unités des valeurs numériques lorsqu'elles ne sont pas évidentes ;
- les calculs complexes pour lesquels une brève explication ou une confirmation facilite la lecture du code ;
- les précautions à prendre, notamment en vue d'éventuelles futures modifications du programme ;
- et aussi le sens de tout élément de code contre‑intuitif.

Dans les programmes pour carte à microcontrôleur, les calculs mis en œuvre font souvent appel à de nombreuses unités de mesure. Mais les instructions du programme ne manipulent que des données numériques et les unités de mesure restent implicites, ce qui ne facilite pas la compréhension des instructions.

Par exemple, on emploie généralement deux unités de temps, la milliseconde ou la microseconde. Dans la déclaration d'un donnée temporelle, il est pertinent indiquer l'unité qui est implicitement choisie, comme par exemple dans le commentaire de fin de ligne ci‑dessous :
const int CYCLE_DURATION = 20000; // microseconds
En effet, l'interprétation de la valeur de cette variable ne peut se faire qu'à la lecture des expressions qui l'utilisent (comme par exemple un appel de la fonction delayMicroseconds), et qui peut être codées bien plus loin dans le fichier.
Dans les programmes pour carte à microcontrôleur, lorsqu'on emploie un capteur, on effectue des calculs spécifiques à ce dernier (on applique sa fonction de transfert). Sans explications, le code qui implémente ces calculs reste difficile à comprendre.

Par exemple, le commentaire ajouté ci‑dessous en ligne nº 10 détaille la formule d'interprétation de la valeur de tension aux bornes d'un capteur de courant, qui est reliée à une broche du port analogique d'une carte à microcontrôleur.
// current sensor : 0.1 V/A around 2.5 V batteryDischargeAmp = (2.5 - (analogRead(ampSensorPin) * 2.5 / 1024.0)) / 0.1;
Cette formule est indispensable pour pouvoir comprendre à la ligne nº 11 le calcul de la variable qui mémorise le courant de décharge d'une pile.
Dans les programmes pour carte à microcontrôleur, on est parfois amené à ajouter des composants au fur et à mesure de l'évolution d'un projet, et donc à éventuellement devoir modifier le câblage. Si le bon fonctionnement du programme répond à des contraintes de broches, il est nécessaire de les préciser.
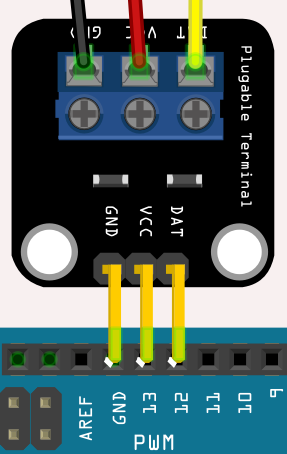
Par exemple, dans un programme qui utilise un capteur de température (Dallas DS18B20 – cf. sujet de TP P3‑1 ), il est possible de brancher directement le connecteur à trois broches du capteur directement sur le port numérique d'une carte Arduino, à condition de faire jouer à la broche nº 13 le rôle de VCC. Les commentaires de fin de ligne apportent cette précision bienvenue dans le code ci‑dessous :
const int SENSOR_VCC_PIN = 13; // will be constantly set to HIGH -> VCC const int SENSOR_DAT_PIN = 12; // Grouped 3-pin connector GND-VCC-DAT

On a vu au chapitre C2‑IX qu'il était opportun de rajouter une pause artificielle (appel de la fonction delay) pour fluidifier la simulation d'un programme Arduino dans l'environnement Tinkercad.
Dans un programme qui se veut réactif, donc où le recours à une fonction comme delay est a priori « proscrit », le rôle spécifique de cette pause artificielle doit être précisé en commentaire, comme par exemple ci‑dessous :
delay(10); // only for a quicker Tinkercad simulation
Ainsi, tout lecteur du code comprend immédiatement que cette pause peut être supprimée ou mise en commentaire dans un contexte d'exécution sur une vraie carte.
Il faut avoir conscience que, dans un programme, si l'on doit ajouter beaucoup de commentaires (pour toutes les raisons que l'on vient indiquer), cela doit aussi amener à éventuellement s'interroger sur les choix algorithmiques… et peut‑être rechercher une solution plus simple.
Où ?
On rappelle (cf. chap. C2‑II ) qu'en principe, un commentaire peut être inséré dans le code partout où un espace peut l'être, sans impacter le code.
Toutefois, pour une bonne lisibilité, on doit surtout veiller à ne jamais couper les instructions.
Il faut donc placer les commentaires autour des instruction en s'efforçant de gêner le moins possible la lecutre du code. Diverses possibilités existent, leur choix dépend de la nature des commentaires et de circonstances particulières comme la longueur des instructions.
- Les premières lignes du fichier sont toujours réservées à l'en‑tête descriptif du programme, qui doit impérativement préciser toutes les données nécessaires à la compréhension globale du code : objet, matériel mis en œuvre, algorithme, version, etc.
- Une ligne au dessus ou dessous d'une fonction, d'un bloc ou même d'un groupe d'instructions peut être employée pour en décrire l'objectif ou se repérer au premier d'œil dans le code.
- Une fin de ligne est aussi un bon emplacement pour un commentaire ponctuel relatif à une instruction ; si la ligne de code est longue, on peut placer le commentaire au dessus ou au dessous, en dernier recours.

Dans un programme pour carte Arduino de commande d'une LED par un bouton (cf. le sujet de TP C2‑1 ), pour décrire le montage et les spécification du fonctionnement attendu, on pourrait saisir le commentaire d'en‑tête suivant :
/* * * * * * * * * * LED-BUTTON COMMAND PROGRAM * * * * * * * * * * * BOARD: any Arduino board * LED: builtin LED * BUTTON: push button on D8 pin with pull-down 2k resistor (positive logic) * COMMAND: on/off LED on rising edge of push button signal */

Dans un programme pour carte Arduino de compte à rebours (cf. TP C4‑2 ), la fonction loop finit par s'étendre sur plus de 60 lignes de code, ce qui dépasser la capacité d'affichage vertical d'un moniteur. Il devient alors difficile d'avoir une vision d'ensemble du programme.
Une ligne de commentaires au dessus de chaque bloc est alors bien utile pour préciser le rôle de chacun, comme par exemple ci‑dessous.
// state changes
if (mode == WORK) {
if (risingEdge(startStopButtonSignal)) {
state = State (!bool(state));
}
if (remainingSeconds == 0) {
state = STOP;
}
}
Dans le même programme de compte à rebours, on a ajouté un commentaire de fin de ligne (nº 50) pour apporter une précision sur l'usage du type de données énumérées State.
enum Mode : uint8_t {WORK, SET};
enum State : uint8_t {STOP, RUN}; // in mode WORK only
Le lecteur peut alors comprendre sans peine que les valeurs STOP et RUN ne sont valables que lorsque le système est dans le mode WORK.
Quand ?
Dans la pratique, commenter le code est vu au mieux comme une corvée nécessaire, au pire une activité nuisible à la concentration qui est requise pour le codage proprement dit.
Lors de la mise au point d'un programme, alors qu'on ne cesse de changer ses instructions, on se demande bien à quoi bon commenter, s'il faut ensuite perdre du temps à tout effacer. Procrastiner (remettre au lendemain ce qu'on devrait faire le jour même) est un défaut banal, surtout si l'on a le commentaire bavard…
Mais si l'on adopte les bonnes pratiques permettant de commenter très peu, alors il n'y a pas d'obstacle à commenter immédiatement ce qui doit l'être.
Le risque de ne pas le faire tout de suite, c'est d'oublier ensuite l'intuition qui a fait sentir une difficulté méritant d'être signalée, et d'être soi‑même confronté à nouveau à cette difficulté quelques heures ou quelques jours plus tard.
Comment ?
Comme les identifiants, et pour des mêmes raisons – homogénéité du texte, concision des termes, universalité linguistique – il est préférable d'exprimer les commentaires tout en anglais, et ce même si l'éditeur de code est paramétré pour afficher les caractères accentués.
Certes, cela demande quelques compétences, mais l'acquisition du vocabulaire spécifique nécessaire à la rédaction des commentaires est un investissement intellectuel qui finit par payer.
C'est par de tels efforts réguliers que peu à peu, on arrive aussi à mieux comprendre la documentation technique des bibliothèques de fonctions ou les débats publiés sur des forums incontournables en programmation comme Stack Overflow W.
Le format du code
On a vu au chapitre C2‑II qu'en langages C/C++, le code source est dit à format libre : sauf dans les éléments de code atomiques, on peut ajouter partout autant de séparateurs blancs que l'on souhaite.
Il en résulte qu'il n'y a pas de contraintes strictes de position où placer les instructions dans les blocs, ni des atomes et symboles dans les expressions.
Pourtant, l'exigence de lisibilité veut que l'on respecte quand même des conventions de formatage, certaines étant universellement adoptées à quelques variantes près, d'autres pouvant être très souples.
Comme pour les commentaires, il est vivement recommandé de formater le code dès la saisie, et en tout premier lieu l'indentation, qui en révèle la structure. Sinon, le codeur risque de perdre lui‑même beaucoup de temps lors du codage pour se repérer dans la hiérarchie des blocs.
Alignement et indentation
Un éditeur de code affiche toujours les caractères d'un fichier source alignés à gauche (conformément au sens d'écriture des langues occidentales).
De plus, il emploie toujours par défaut une police de caractères à chasse fixe – la chasse étant la largeur du rectangle d'enveloppe des caractères W.

Contrairement à une police dite « proportionnelle » comme Cambria (cf. ci‑contre), une police à chasse fixe comme Consolas, Courrier new, Source Code Pro, etc. permet une indentation régulière des lignes de code, c'est‑à‑dire un décalage horizontal vers la droite du début de l'instruction d'un ou plusieurs caractères espace ou mieux, de tabulation.
Partant du principe général qu'on saisit une ligne de code par instruction simple (ou par directive), l'indentation évolue au fur et à mesure des instructions selon les structures de contrôles employées :
- l'indentation est augmentée à chaque « entrée » dans un bloc et diminuée d'autant à chaque « sortie » de bloc ; toutes les lignes du bloc ayant la même indentation, elles sont donc alignées verticalement, à gauche) ;
- quant aux accolades de blocs, elles peuvent être positionnées de deux manières :
- soit l'une et l'autre en début de ligne, afin qu'elles soient alignées verticalement,
- soit l'accolade ouvrante
{en fin de ligne et l'accolade fermante}en fin de ligne, alignée avec le mot-clef de la structure de contrôle.
Ces bonnes pratiques permettent de repérer au premier coup d'œil, par l'alignement des lignes de code, les blocs des structures de contrôle.
Pour formater le code générique d'une boucle while imbriquée dans un test if… else, les deux variantes ci‑dessous sont usuelles, celle de droite étant un peu plus compacte, mais moins aérée que celle de gauche.
if (condition) { instruction; ⫶ while (condition) { instruction; ⫶ instruction; } instruction; } else { instruction; ⫶ instruction; }
if (condition) { instruction; ⫶ while (condition) { instruction; ⫶ instruction; } instruction; } else { instruction; ⫶ instruction; }
Emploi de la touche tabulation
Pour maîtriser la régularité de l'indentation, on peut recourir à la touche de tabulation horizontale TAB qui, en principe, insère dans le texte à chaque appui un caractère HT (horizontal tabulation, code ASCII 0x09).
Avec la plupart des éditeurs de code, en sélectionnant un groupe de lignes de code, on peut le décaler d'une tabulation :
- vers la droite en appuyant sur la touche TAB ;
- vers la gauche en appuyant simultanément sur les touches ⇧TAB ;
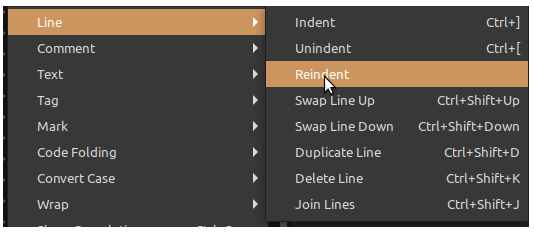
De plus, la plupart des éditeurs de code possèdent une fonction d'auto-indentation d'une partie de code sélectionnée.
Dans Sublime Text, on trouve ces fonctionnalités (et bien d'autres) via le menu Edit/Line (cf. la figure ci‑contre).
Valeur de l'unité d'indentation
Sur la plupart des éditeurs de code, il est possible de régler la taille de la tabulation en nombre de caractères espaces équivalents :
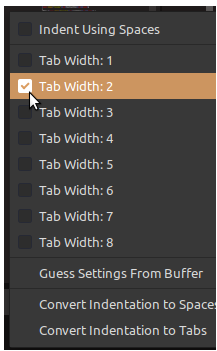
- une grande valeur – typiquement 4 espaces, voire plus – met bien en évidence l'imbrication des blocs mais elle consomme davantage la largeur de ligne disponible qui est limitée par celle de la fenêtre d'affichage, et en définitive, par celle du moniteur ;
- aussi, pour éviter les débordements de la fenêtre ou les retours à la ligne intempestifs, il est préférable de choisir une petite valeur en fixant la tabulation à 2 espaces seulement ; c'est valeur minimale recommandée car en dessous, l'indentation étant à peine visible, elle ne remplit plus sa fonction.
De plus, il est également possible de convertir automatiquement dans le fichier source tous les espaces en tabulations, et vice‑versa.
Sur Sublime Text, on accède à ces réglages et fonctionnalités via le menu View/Indentation, ou encore en cliquant sur la zone Tab Size dans la barre d'état tout en bas de la fenêtre pour faire apparaître un menu déroulant et choisir la valeur d'une tabulation (cf. la figure ci‑contre).
Reprenons l'exemple ci‑dessous et comparons le code générique indenté par tabulations de deux espaces (code de gauche) et quatre espaces (code de droite) :
if (condition) { instruction; ⫶ while (condition) { instruction; ⫶ instruction; } instruction; }
if (condition) { instruction; ⫶ while (condition) { instruction; ⫶ instruction; } instruction; }
Ici, on pourrait facilement préférer l'indentation à quatre espaces, parce que les conditions et instructions génériques forment des motifs très courts. Mais en pratique, c'est rarement le cas…
Aération horizontale et verticale
À l'exception des codes composés en réponse à des petits exercices académiques, les programmes sources deviennent vite très complexes. Leur lecture peut devenir très pénible s'ils sont présentés de façon trop compacte.
L'aération du code consiste à ajouter des caractères d'espacement surnuméraires (c'est‑à‑dire non indispensable d'un point de vue purement syntaxique) entre les éléments de code pour faciliter leur lecture.
L'aération du code est nécessaire autant horizontalement que verticalement.
Aération horizontale
Il est recommandé d'insérer des caractères espaces :
- entre les opérateurs et les opérandes,
- entre les mots‑clefs, les délimiteurs et les expressions.
Mais comme il n'y aucune règle obligatoire, contrairement à la typographie, les usages sont divers et difficiles à décrire. Tout est une question de dosage ; il y a aussi une part d'habitudes et de subjectivité.
On se contentera donc ici de donner un exemple sans et avec aération, voire trop, pour comparer.
L'exemple est issu du programme réactif de clignotement de la led intégrée à une carte Arduino, présenté au chapitre C2‑IX .
- L'instruction sans aucune aération comme ci‑dessous :
if(millis()-previousMillis>=BLINK_HALF_PERIOD){ previousMillis+=BLINK_HALF_PERIOD; digitalWrite(LED_BUILTIN,!digitalRead(LED_BUILTIN)); }est pénible à lire, même avec la coloration syntaxique, car l'œil a du mal à repérer les opérateurs perdus au milieu des identificateurs (avec la fatigue, on pourrait facilement manquer le symbole+accolé à=pour former l'opérateur d'incrémentation+=qui est ici essentiel). - La même instruction modérément aérée comme ci‑dessous :
if (millis() - previousMillis >= BLINK_HALF_PERIOD) { previousMillis += BLINK_HALF_PERIOD; digitalWrite(LED_BUILTIN, !digitalRead(LED_BUILTIN)); }est bien plus facile à lire (la composition des expressions se détache mieux), d'autant plus que les espaces ajoutés reprennent en partie les règles typographiques usuelles (un espace après,mais pas avant, etc.). - Enfin, la même instruction très aérée comme ci‑dessous :
if ( millis () - previousMillis >= BLINK_HALF_PERIOD ) { previousMillis += BLINK_HALF_PERIOD ; digitalWrite ( LED_BUILTIN , ! digitalRead ( LED_BUILTIN ) ) ; }est moins lisible que dans le format précédent. Elle « consomme » trop d'espace et détache des éléments qui sont usuellement liés, en particulier les parenthèses d'arguments des appels de fonctions.
Aération verticale
Il est recommandé d'insérer un voire plusieurs sauts de ligne pour mieux détacher verticalement :
- les blocs de définition des différentes fonctions,
- les déclarations des instructions proprement dites,
- et plus généralement tous les groupes d'instructions (même si elles ne forment pas nécessairement un bloc) qui implémentent à elles‑seules un sous‑algorithme du programme.
De plus, l'ajout d'une dizaine de sauts de lignes entre les grandes parties d'un programme permet de repérer facilement ces dernières dans l'image miniature du fichier que génère certains nombreux éditeurs de code.
Soulignons que dans tous les cas, la taille d'un fichier source importe peu en termes de mémoire et d'affichage. En effet, même dans le cas d'un gros logiciel, la programmation modulaire permet de modérer la taille des fichiers. En principe, la doubler avec les espacements ne pose pas de problème.
Ce qui compte, c'est de pouvoir visualiser facilement sur un écran ou une feuille imprimée les unités principales du programme (fonctions, blocs, etc.) – qu'on s'efforce d'ailleurs de rendre les plus simples et courtes possible pour mieux les comprendre.
Là encore, tout est une question de mesure et d'habitudes.
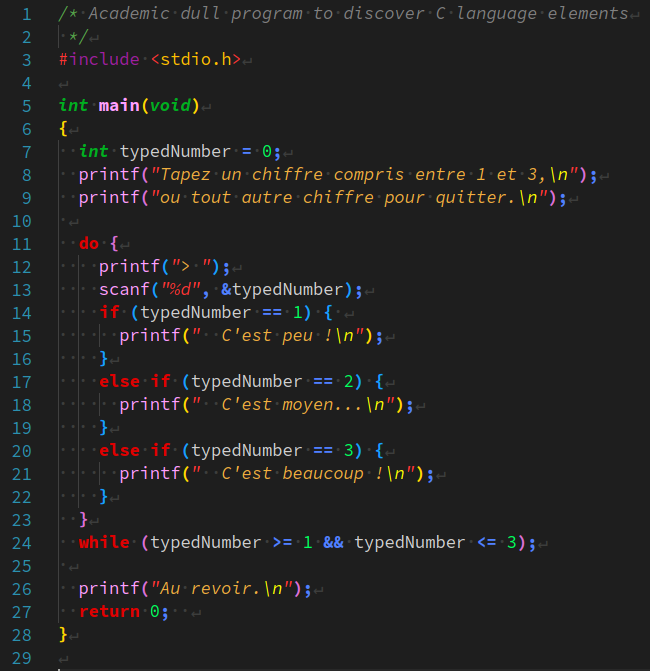
Considérons le programme académique ci‑dessous qui calcule le nombre de jours dans un mois de l'année, en tenant compte du fait que cette dernière est bissextile ou non (certaines parties du code ont déjà été données en exemples au chap. C2‑V ).
/* Program that calculate the number of days in the month of a given date
*/
#include <stdio.h>
#include <stdbool.h>
int main(void)
{
printf("Type a date with format mm/yyyy (mm = 0 to quit)\n");
int month = 0, year = 0;
while (true) {
int daysInMonth = 0;
bool leapYear = false;
// scan and check the date typed by the user
printf("> ");
scanf(" %d/%d", &month, &year);
if (month == 0) break;
if (month < 0 || month > 12) {
printf("Month is out of range!\n");
continue;
}
// check if the year is a leap year
if ((year % 4 == 0 && year % 100 != 0) || year % 400 == 0) {
leapYear = true;
}
else {
leapYear = false;
}
// calculate and display the number of days in the month
switch (month) {
case 2 : // February
if (leapYear) {
daysInMonth = 29;
}
else {
daysInMonth = 28;
}
break;
case 4 : case 6 : case 9 : case 11 :
daysInMonth = 30;
break;
default :
daysInMonth = 31;
}
printf("Number of days in the month: %d\n\n", daysInMonth);
} // while(true)
printf("Goodbye.\n");
return 0;
}
En plus des lignes de commentaires, on a ajouté des sauts de ligne – cf. les lignes nº 10, 11, 15, 24, 32, 51 et 52 – pour mieux séparer les différentes parties du code, ce qui améliore sa lisibilité.
Pour séparer différentes parties du code, il serait tentant d'utiliser des lignes de commentaires du genre :
//================================
Pourtant, cette pratique présente des inconvénients :
- il est difficile de leur donner une longueur identique d'une ligne à l'autre, sauf à y consacrer une attention fastidieuse (au détriment du codage) ;
- elles prennent plus de temps à saisir et effacer que de simples sauts de ligne.
Coloration syntaxique
La coloration syntaxique W (syntax highlighting) consiste à afficher le code source en employant des couleurs et des styles (gras, italique…) par catégories syntaxiques : mots‑clefs, descripteurs de types, opérateurs, etc.
Aujourd'hui, tous les éditeurs de code proposent cette fonctionnalité, car elle améliore considérablement la lisibilité du code. Il serait dommage de ne pas se l'approprier ! Car même si ce n'est pas toujours aisé pour un débutant, la mise en forme du code est paramétrable.


Ainsi, le présent site web utilise le script de coloration externe Code Prettify principalement développé en langage JavaScript/CSS par Grant Timmerman chez Google dans le cadre d'un projet open‑source, que l'on peut trouver en archive ici G. Loin d'être parfait (cf. notamment quelques problèmes signalés au chap. C5‑VI ) et non maintenu depuis 2020, il présente l'avantage d'être très simple à exploiter.
On pourrait penser que les choix en matière de coloration syntaxique sont une affaire de goûts personnels, mais on peut néanmoins énoncer quelques principes de bon sens, au regard de la hiérarchie des catégories syntaxiques du langage et des caractéristiques de l'œil humain (mais en gardant à l'esprit que ces règles sont subjectives, comme les précédentes).
- Pour diminuer la fatigue, on privilégie un
arrière‑plan sombre(on parle de dark mode), noir ou du moins très foncé. En effet, plus l'arrière plan s'approche du gris moyen, plus il écrase le contraste avec le texte (surtout s'il est en couleur) ; à la longue, la lecture devient pénible. - Pour tous les éléments structurels qui articulent le code, le style
grasaide à renforcer la perception ; de plus, il est opportun de choisir des couleurs primaires, vives, qui attirent l'attention et qui contrastent bien entre elles ; par exemple, on peut choisir de mettre : - les mots‑clefs en
rouge, - les séparateurs et délimiteurs en
bleu. - Pour les opérateurs qui sont, comme les délimiteurs et séparateurs, des symboles isolés, on peut choisir le même format
bleu, éventuellement avec une nuance de couleur. - Pour les descripteurs de types et leurs valeurs numériques associées, on peut choisir du
vert(c'est la troisième couleur primaire). - Enfin, pour les commentaires, on privilégie le style
italique, plus semblable à l'écriture manuscrite (donc d'apparence moins formelle que le code proprement dit), et dans une nuance degrisqui apparaît moins vive que le code, mais qui contraste suffisamment avec l'arrière‑plan pour rester lisible.
En définitive, cette combinaison de couleurs et de styles permet de gagner en lisibilité, tant sur moniteur que sur feuille imprimée, même en noir et blanc (les éditeurs de code savent éliminer la couleur d'arrière‑plan lors d'une impression).
On compare différents choix de coloration syntaxique pour le même code source, à savoir le programme de l'exercice 1 de la feuille nº C2‑0 .
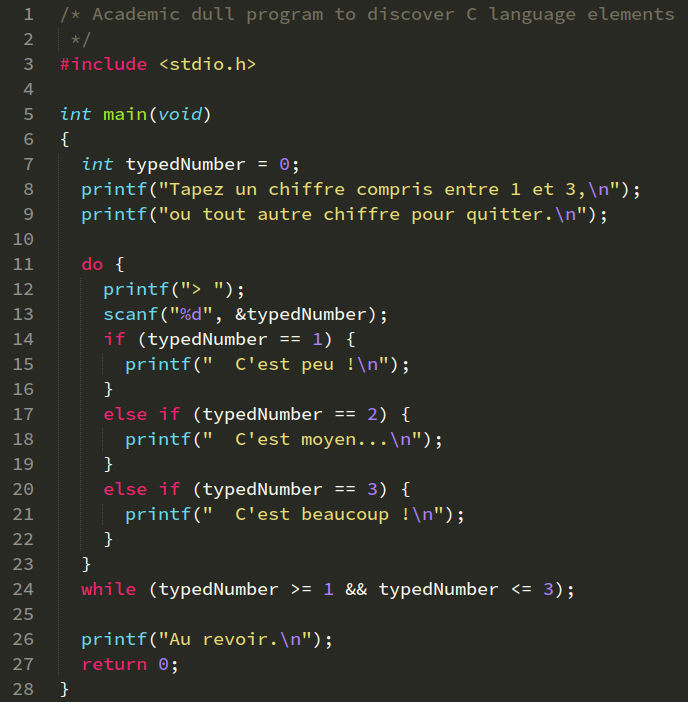
- Avec l'éditeur de code Sublime Text, en choisissant le schéma de couleurs
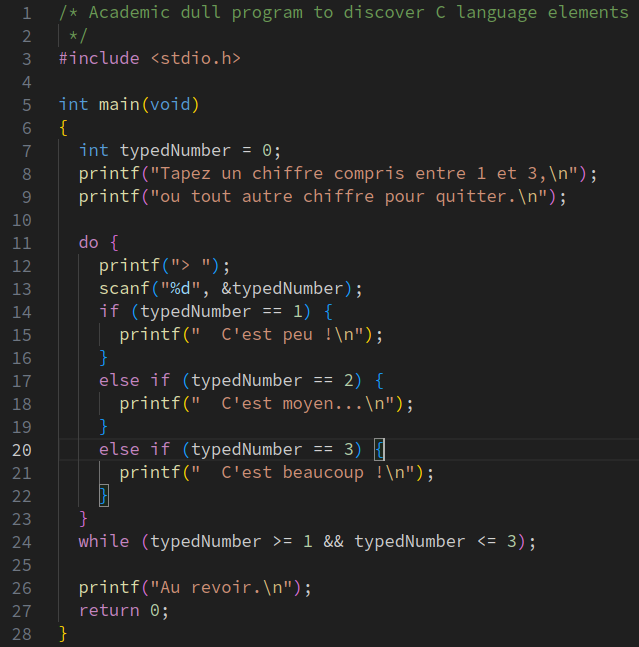
Monokai, on obtient par défaut l'aspect suivant, très convenable car suffisamment contrasté entre les différents éléments de langage : - Avec l'IDE VS Code, on obtient par défaut l'aspect suivant, qui peut sembler satisfaisant au premier abord, mais qui en fait présente un déficit de contraste :
-
entity.name.function.c -
meta.function.definition.parameters.c

DarkStudy.sublime-color-scheme au format json, téléchargeable au lien suivant . Il faut le placer dans le répertoire des préférences de l'utilisateur, accessible sous Linux typiquement par le chemin : /home/user‑name/.config/sublime-text/Packages/User
C:\Users\user‑name\AppData\Roaming\Sublime Text\Packages\User
DarkStudy via le menu Preferences/Select Color Scheme. On obtient alors le résultat suivant : 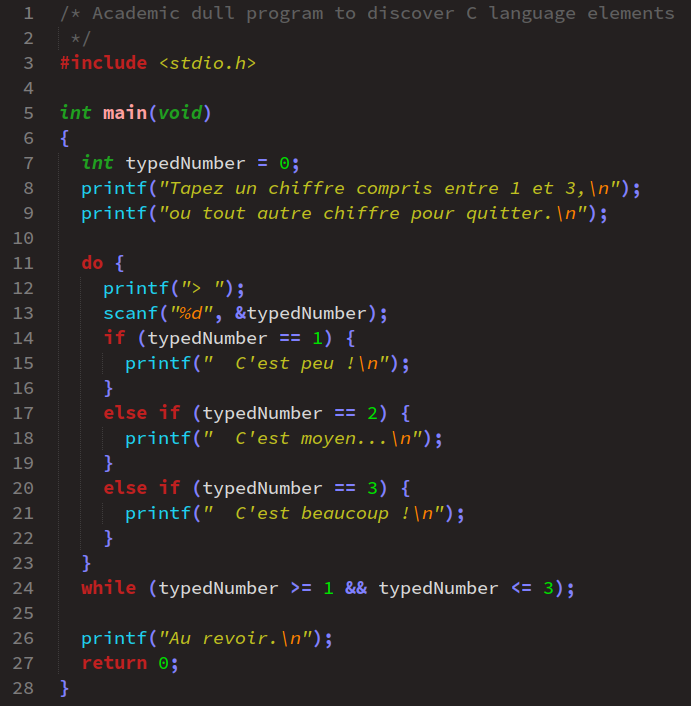

settings.json téléchargeable au lien suivant . "editor.tokenColorCustomizations"
Developer: Inspect Editor Tokens and Scopes
sachant que pour fonctionner, l'extension C/C++ doit être désactivée et le logiciel relancé (sinon, cela crée un conflit avec la fonctionnalité Intellisense).
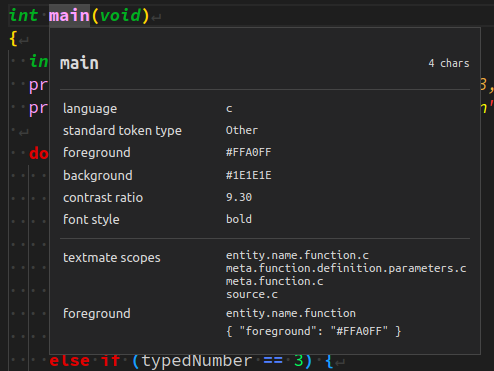
main appartient notamment aux catégories (scopes) : settings.json, on peut alors coder les règles de mise en forme de ces catégories, comme par exemple ci‑dessous :
{
"editor.tokenColorCustomizations": {
"[Visual Studio Dark - C++]": {
"textMateRules": [
{
"scope": ["entity.name.function.c"],
"settings": {
"foreground": "#ffa0ff" // pale rose
}
},
{
"scope": ["meta.function.definition.parameters.c"],
"settings": {
"fontStyle": "bold"
}
}
]
}
}
}
rose clair gras.