
Dans tout langage littéral, un programme source se compose d'éléments lexicographiques de différentes sortes, qui s'agencent selon des règles de syntaxe W. Ces différents aspects peuvent varier selon le langage et le paradigme de programmation adoptés, mais on retrouve presque toujours les mêmes notions fondamentales : celles de commentaire, d'instruction, d'expression, de mot‑clef, etc.
Toutefois, ces notions fondamentales peuvent avoir des acceptions particulières dans certains langages, et c'est notamment le cas pour les langages C et C++, où :
- l'affectation (le fait d'attribuer une valeur à une variable) est considérée juste une opération parmi d'autres ;
- tout sous‑programme est vu comme une fonction, même s'il ne retourne pas de valeur.

Pour bien débuter l'apprentissage de la programmation dans un langage donné – et, bien évidemment, en langages C et C++ – il est absolument indispensable d'acquérir et maîtriser suffisamment pour ne pas les confondre ces notions fondamentales sur lesquelles reposent toutes les règles de syntaxe. L'enjeu est en effet considérable, car un compilateur est un logiciel déterministe – il ne fait rien au hasard – et inflexible. La moindre erreur de codage produit :

- au mieux, l'échec de la compilation (aucun programme exécutable n'est alors généré, et la seule issue possible consiste à corriger l'erreur) ;
- au pire, un code exécutable défectueux dont les erreurs ne sont ni flagrantes, ni immédiatement détectables (donc, potentiellement difficiles à diagnostiquer), mais risquent d'engendrer un dysfonctionnement inattendu, à un moment inopportun et avec des conséquences imprévisibles.

Très souvent, c'est par confusion des notions fondamentales dont ils ont négligé l'étude que les débutants échouent à comprendre leurs erreurs répétitives et se laisse finalement aller au découragement. Aussi, plutôt que de vouloir écrire tout de suite des premiers programmes exitants et chercher ainsi des satisfactions immédiates (mais illusoires…), l'étude de la syntaxe fondamentale invite à la patience. Bref, avant de « mettre les gaz », prenons encore un peu de temps pour se familiariser avec le poste de pilotage…
Ce chapitre a donc pour objectif de présenter les éléments de syntaxe fondamentale des langages C et C++, à savoir dans l'ordre :
- quelques notions préliminaire du métalangage, en particulier celles de syntaxe, de sémantique, d'environnement d'exécution et de comportement du programme ;
- les commentaires, qui ne sont pas du code mais qui sont utiles au codeur pour mieux le documenter ;
- les instructions et les expressions, qui forment les « briques » du code, et qui sont deux notions essentielles à ne pas confondre ;
- les identificateurs et les mots‑clefs, qui forment les termes choisis par le codeur ou imposés par le langage ;
- les séparateurs et les délimiteurs, qui confèrent au code sa structure au même titre que la ponctuation dans un texte.
Notions préliminaires du métalangage
Qu'est‑ce‑que le métalangage ?

Lorsqu'on aborde sérieusement l'étude d'un langage, qu'il soit naturel ou informatique, on a forcément besoin de prendre conscience de l'existence du métalangage W, c'est‑à‑dire d'un langage au dessus de celui que l'on étudie, et qui a vocation à le décrire avec formalisme et précision (le préfixe « méta » W vient du grec ancien μετά qui veut dire « au delà, après », et par extension « qui dépasse, qui englobe »).
En effet, dans le cadre de l'étude d'un langage de programmation, parmi les principales notions du métalangage, on trouve notamment les suivantes : syntaxe, forme, sémantique, interprétation, donnée, type, valeur, implémentation, environnement, effet de bord, comportement, etc. Tous ces termes font référence à des notions hyper‑fondamentales de programmation dont le codeur, même débutant, doit avoir connaissance pour bien progresser dans son apprentissage.

Une manière d'introduire « en douceur » le métalangage en programmation ainsi que les notions qui en découlent consiste à procéder par analogie avec l'étude d'un langage naturel écrit (qu'il s'agisse d'une langue maternelle ou étrangère).
On va donc procéder de la sorte, et plus tard, on signalera systématiquement cette approche par le pictogramme ci‑contre.
- Sans entrer dans les détails, quand on étudie un langage naturel, on évoque typiquement l'orthographe (les règle d'écriture des mots) et la grammaire W, dans laquelle on distingue usuellement :
- la morphologie, à savoir les variations de forme d'un mot dans une conjugaison, une déclinaison, ou autre ;
- et la syntaxe, à savoir les règles de construction de tout ou partie d'une phrase, notamment la position des mots, les règles d'accord, etc.
- d'une part, des ouvrages scolaires, à la fois synthétiques et pédagogiques mais, en contre‑partie, forcément incomplets ;
- d'autre part, des ouvrages scientifiques (dans le domaine de la linguistique), réputés complets mais aussi beaucoup plus complexes à aborder, surtout pour des débutants.
- En programmation, presque tout ce qui est du ressort des règles formelles de composition du code source constitue ce qu'on appelle la syntaxe du langage W. On ne distingue pas de notion d'orthographe ou de morphologie à proprement parler, même si l'on emploie parfois des termes qui y font référence, comme par exemple « préfixe » et « suffixe ».

Exemple. Sans doute la première règle de grammaire qu'on apprend à l'école primaire est :
Plus précisément, il s'agit d'une règle de syntaxe sur la manière correcte d'écrire une phrase en termes de ponctuation et de typographie.



Exemple. Par analogie avec l'exemple précédent, une règle de syntaxe parmi les premières qu'un codeur en langages C/C++ doit assimiler est :

Bien entendu, on dispose également dans ce domaine de textes de référence, à commencer par les normes des langages – cf. chap. C1‑II pour le C et le C++ . Là encore, une telle documentation est a priori complète (sachant qu'il s'agit avant tout de spécifications pour le développement de compilateurs) mais, en contre‑partie, très complexe.
C'est pourquoi il est recommandé aux débutants de se référer plutôt en premier lieu à des ouvrages pédagogiques ou des sites internet comme celui‑ci (cf. également les liens externes fournis dans le panneau latéral pour plus de références, en cliquant sur le bouton  ).
).
Avant de clore cette introduction au métalangage en programmation par analogie avec la grammaire d'un langage naturel, on doit aussi faire une importante distinction :
- Même écrit avec des fautes de grammaire (tant qu'elles restent modérées), un texte peut rester compréhensible, car il est contient des éléments de redondance et il est destiné un processus informel d'analyse – la lecture par un humain ou même une intelligence artificielle – capable de souplesse et d'adaptation.
- A contrario, dans un programme, la moindre petite faute de syntaxe est le plus souvent fatale, car le processus d'analyse mis en œuvre par le compilateur ou l'interpréteur du langage est formel et rigide (une certaine souplesse existe, mais elle est très limitée en comparaison avec ce dont est capable un humain ou un agent IA).
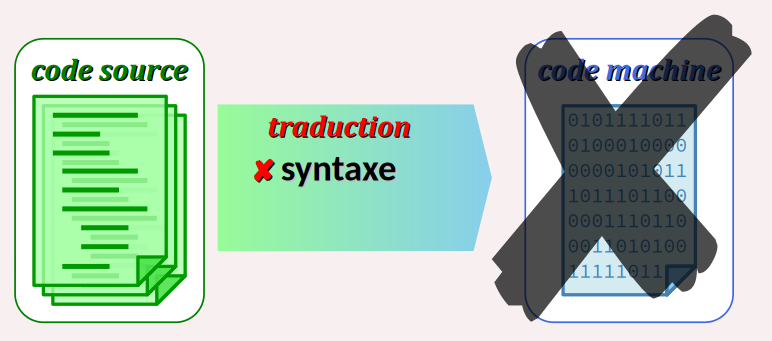
En effet, lors de la traduction du code source en code machine, une analyse syntaxique – parmi d'autres vérifications – est toujours mise en œuvre. Un strict respect des règles est donc indispensable au codeur pour produire ne serait-ce que des programmes exécutables.
Notion de forme syntaxique
D'une manière générale, les règles de la syntaxe d'un langage de programmation s'énoncent par des formes syntaxiques à respecter, c'est‑à‑dire des schémas textuels dans lesquels sont essentiellement agencés :
- des termes génériques du métalangage, qui sont destinés à être remplacés par des éléments de code particuliers d'une certaine catégorie et respectant d'éventuelles contraintes ;
- des éléments du langage qui sont intangibles et spécifiques à chaque forme syntaxique.
Dans la norme d'un langage, les formes syntaxiques sont très abstraites et complexes car elles doivent prendre en compte tous les cas possibles. Et pour rester synthétiques, elles sont souvent récursives, ce qui peut dérouter un codeur débutant.

En langage C, la forme syntaxique qui régit les déclarations comporte 4 schémas principaux contenant des termes génériques (par exemple, declaration‑specifiers), eux‑mêmes définis par 5 schémas secondaires (cf. la reproduction ci‑contre du brouillon de la norme C23, p. 97 C). Et les schémas secondaires font encore appel à d'autres formes syntaxiques qui sont définies ailleurs dans la norme (ici, par exemple, storage-class-specifier). Enfin, ces schémas sont complétés par un certain nombre de contraintes, listées à la suite.
Maintenant, il n'est pas question d'expliquer davantage cette forme syntaxique ni même d'en donner un exemple concret d'application. Le but est simplement de donner un aperçu de la complexité de la norme pour mieux apprécier les formes syntaxiques simplifiées qui sont proposées dans ce module de formation.
Dans une approche pédagogique progressive, il est pertinent de proposer des formes syntaxiques simplifiées, limitées à des cas d'utilisation simples pour commencer. Et par la suite, il reste commode de les compléter par d'autres schémas analogues pour traiter des éléments de langage plus évolués. L'ensemble de ces formes simplifiées est évidemment moins synthétique que ceux de la norme, mais restent plus facile d'emploi.
En langage C, une déclaration de variable de type élémentaire peut se coder en respectant la forme syntaxique simplifiée suivante (cf. chap. C2‑III ) :
descripteur de type
identificateur
= expression d'initialisation
;
Dans cette forme syntaxique (beaucoup plus simple que celle de la norme), on trouve :
- 3 termes génériques du métalangage, à savoir descripteur de type, identificateur et expression d'initialisation, qui sont à remplacer par des éléments de code spécifiques au gré des besoins du programme (cf. les exemples ci‑après) ;
- 2 éléments de code du langage, à savoir les symboles
=(l'opérateur d'affectation) et;(le séparateur d'instruction) ; - Quant aux crochets gris
, ils ne sont pas des éléments du langage mais des symboles du métalangage pour délimiter une partie optionnelle dans la forme syntaxique.
Une telle forme syntaxique convient parfaitement pour régir des déclarations simples de variables de types élémentaires comme celles dont on a besoin dans les premiers programmes que tout débutant est amené à coder, par exemple :
-
int x = 42; -
const unsigned BLINK_HALF_PERIOD = 500;
En revanche, la forme syntaxique simplifiée proposée ci‑dessus trouve rapidement ses limites :
- elle ne convient pas pour une déclaration de constante, dans laquelle l'expression d'initialisation n'est pas optionnelle (un tel cas est donc traité plus loin dans le chapitre C2‑III ) ;
- elle passe sous silence les classes d'allocation qui peuvent être codées différemment pour chaque variable déclarée (cet aspect n'étant abordé qu'au chapitre C4‑II ) ;
- et l'on ne parle même pas ici du cas des données de types dérivés (énumération, pointeurs, tableaux, structures) qui sont traités bien plus tard dans ce module de formation par d'autres formes syntaxiques plus complexes.
Notion de sémantique
Comme précédemment , on procède par analogie avec l'étude d'un langage naturel pour expliquer en quoi consiste cette notion complexe du métalangage qu'est la sémantique.
Dans le domaine de la linguistique, la sémantique W est l'étude de la signification des constructions syntaxiques, c'est‑à‑dire des phrases, propositions, groupes nominaux et autres.
La sémantique possède aussi ses règles, mais qui sont à la fois moins formelles et plus complexes que celles de la syntaxe.
Exemple. Hors de tout contexte particulier (poésie, dessin animé…), même dans un sens figuré, la phrase :
Le chien est plombier.
est correcte syntaxiquement (elle respecte le schéma sujet‑verbe‑complément) mais pas sémantiquement, au sens où elle met en relation deux concepts (« chien » et « plombier ») qui sont a priori disjoints (aucun chien n'a jamais réparé un tuyau).
En revanche, la phrase :
Le chien est philosophe.
bien que bizarre au premier abord, n'est pas sémantiquement incorrecte car un chien est capable de comportements que l'on qualifierait de « sages », donc on peut le qualifier de « philosophe » au sens figuré.
À travers ce simple exemple, on peut d'ores et déjà comprendre que, dans un langage naturel, la frontière n'est pas toujours nette entre les phrases sémantiquement correctes et celles qui ne le sont pas. On peut donc anticiper que les règles de sémantique sont complexes à définir.
En programmation, de façon analogue à ce que l'on entend en linguistique, la sémantique décrit l'effet attendu des expressions, instructions, déclarations, etc. qui sont supposées syntaxiquement correctes, durant l'exécution du programme.
Et bien évidemment, il existe des règles de sémantiques à respecter pour que les instructions d'un programme source puissent être traduites en code exécutables.
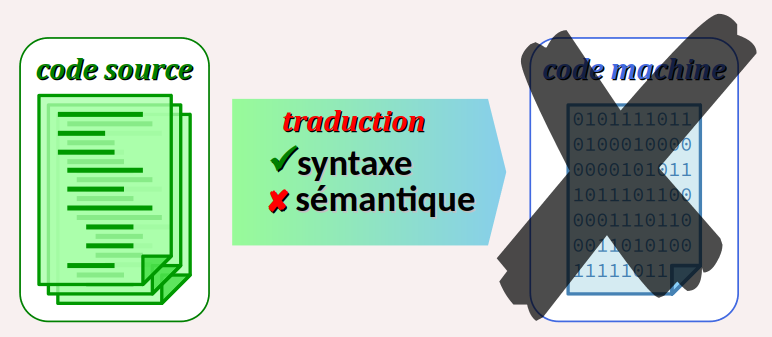
Lors de la traduction du code source en code machine, l'analyse sémantique est opérée après l'analyse syntaxique. En cas d'erreur, le verdict est similaire : le code machine n'est pas généré et le programme n'est donc pas exécutable.
On doit donc d'ores et déjà comprendre que coder un programme nécessite de se conformer à beaucoup de règles, et non pas seulement celles de la syntaxe.

En langage C, le programme académique ci‑dessous est sémantiquement incorrect, comme on peut le constater si on tente de le compiler et exécuter avec OnlineGDB.
int main(void)
{
x = 42;
printf("%d\n", x);
return 0;
}
En effet, bien que la ligne nº 3 soit syntaxiquement correcte (c'est une simple affectation de la valeur 42 à la variable x), elle déclenche une erreur de compilation car x n'a pas été préalablement déclarée :
main.c: In function ‘main’:
main.c:3:5: error: ‘x’ undeclared (first use in this function)
3 | x = 42;
| ^
Pour rendre ce programme sémantiquement correct, il suffit :
- de transformer l'instruction de la ligne nº 3 en une déclaration, typiquement comme ci‑dessous :
int x = 42;
x comme une variable, par exemple : int x; x = 42;
Dans les deux cas, le programme devient compilable et s'exécute normalement en affichant la valeur 42.
Notion de machine abstraite et d'environnement d'exécution
Dans l'étude d'un langage naturel, la syntaxe et la sémantique ne reposent pas que sur des règles formelles. Elle s'appuient aussi sur d'autres notions du métalangage, notamment celle de contexte.
En programmation, il en va de même, et en premier lieu, il existe la notion fondamentale d' environnement d'exécution du programme. Et pour être bien conçue, cette notion nécessite évidemment que l'on soit capable de distinguer le programme lui‑même en cours d'exécution et tout ce avec quoi il peut interagir.
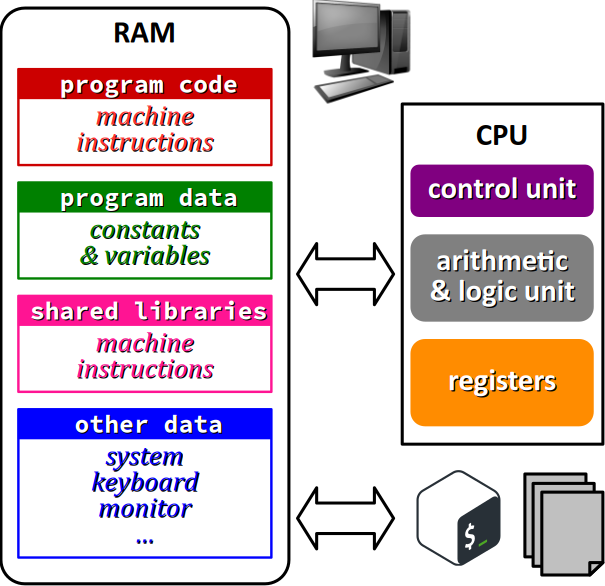
Brièvement, l'exécution d'un programme (codé dans un langage compilé) sur une machine à système d'exploitation (situation qualifiée de « hosted environment » par la norme) procède typiquement de la manière suivante :
- Le code machine du programme est chargé dans un segment de la mémoire vive (RAM W).
- Au moins un autre segment mémoire est alloué au programme pour le stockage des données directement manipulées par le programme.
- Les calculs sont effectués par l'unité arithmétique et logique, les valeurs étant temporairement stockées dans des registres.
- Éventuellement, d'autres données stockées dans la RAM peuvent être indirectement accédées par le programme – paramètres du système, buffers des flux des périphériques (unités de stockage de masse, dispositifs d'entrée‑sortie, etc.) via des appels de fonctions de bibliothèque dédiées (par exemple,
printf).
Mais, pour ne pas s'embarrasser des détails spécifiques à telle ou telle implémentation (cf. chap. C1‑II ), les normes des langages C et C++ préfèrent concevoir l'exécution du programme comme une machine abstraite W qui change d'état au fil des instructions et de la modification des données du programme.
Quant au contexte des autres données externes au programme et des dispositifs périphériques avec lequel il interagit, il est appelé l'environnement d'exécution du programme. On va voir que c'est grâce à ce concept que l'on peut définir la notion de comportement.

Dans le cas d'un programme embarqué sur une carte à microcontrôleur, donc sans système d'exploition, l'architecture change un peu (la RAM est intégrée au microcontrôleur, les périphériques d'entrée‑sortie sont différents) mais la notion d'environnement d'exécution reste sensiblement la même dans son principe : tout ce avec quoi le programme interagit.
Notions d'effet de bord et de comportement du programme
En programmation, parmi les autres notions du métalangage sur laquelle les normes s'appuient pour détailler des règles de syntaxe et de sémantique, il y a aussi celle de comportement du programme. Cette notion n'est pas simple à définir, elle fait appel à la notion plus générale d'effet de bord et à l'existence au moins virtuelle d'un observateur de l'exécution du programme.
Toujours par analogie avec l'étude d'un langage naturel, on peut faire le rapprochement avec des notions comme celles de locuteur, de narrateur ou encore de lecteur, sans qu'il soit nécessairement possible d'établir une stricte correspondance.
Notion d'effet de bord
De façon synthétique, on appelle effet de bord toute modification par le programme :
- de l'état de sa machine abstraite ;
- de son environnement d'exécution ;
autrement dit, des données auxquelles il a accès, directement ou non, dès lors que cette modification survit au contexte du calcul qui l'a mis en en œuvre (c'est‑à‑dire l'évaluation d'une expression – cf. infra codée).
De façon générale, sont des effets de bord :
- l'affectation d'une valeur à une variable du programme – par exemple,
x = 42; - la lecture ou écriture de caractères sur le terminal d'exécution – le programme modifiant le buffer du flux de entrée/sortie standard via une fonction dédiée ;
- la mise en service d'un périphérique géré par le système d'exploitation et commandé par le programme (haut‑parleur, caméra, etc.) – le programme modifiant une variable du système.
Au contraire, la simple modification d'un registre au cours d'un calcul – par exemple, x + 2 – n'est pas un effet de bord (sauf bien entendu dans le cas particulier d'une donnée stockée expressément dans un registre – cf. chap. C4‑II ).
Dans les livres de programmation en langages C/C++, la notion d'effet de bord est le plus souvent introduite dans un contexte de mise en garde contre les mauvaises pratiques, à propos :
- des opérateurs qui modifient leurs opérandes (
++, etc.) ; - des fonctions qui modifient leurs arguments ou des variables globales.
En effet, il peut arriver qu'un tel effet de bord soit indésirable car non anticipé par le codeur et produisant dysfonctionnement inattendu du programme.
Mais c'est oublier le fait qu'en langages C/C++, l'affectation directe est codée par l'opérateur = qui est fondamentalement à effet de bord : il modifie son premier argument, la variable affectée, dite l‑value (cf. chap. C2‑IV ).
L'effet de bord est donc le concept central de la programmation impérative et il ne doit pas être diabolisé. Il est indispensable pour caractériser la notion d'expression (cf. infra ).
Notion de comportement
On appelle comportement du programme tout effet de bord qui constitue une modification observable de son environnement d'exécution. Autrement dit, un comportement est toujours un effet de bord mais l'inverse n'est pas vrai : un effet de bord qui ne modifie que les données du programme n'est pas un comportement.
La notion de comportement est extrêmement importante dans les normes des langages C et C++ pour plusieurs raisons.
D'abord, en matière de sémantique d'un langage, une norme ne peut pas être exhaustive car trop de cas sont à considérer. En effet, on a vu supra que la validité d'une instruction ne dépend pas forcément que d'elle‑même mais éventuellement d'autres instructions précédentes. De plus, il faut laisser une marge de manœuvre au regard de la diversité des implémentations possibles.

C'est pourquoi, dans la description sémantique d'une expression, instruction, déclaration, etc., la norme peut faire référence à des cas de comportements non définis – en anglais, undefined behavior W, abrégé UB. Un tel comportement résulte d'un élément problématique du programme problématique, auquel la norme, ni tout autre document de référence, n'impose aucune exigence, autrement dit elle ne précise pas ce qu'il en adviendra, tant à la compilation, que lors de l'exécution – sachant implicitement qu'un tel comportement risque fort de provoquer un dysfonctionnement du programme.
Dans la norme du langage C, l'annexe J.2 est donne une liste non exhaustive de comportements non définis (cf. le brouillon de la norme C23 , p. 588).
Attention ! Un comportement non défini n'est pas forcément aléatoire. Dans la pratique, il peut très bien se traduire par un fonctionnement identique du programme à chaque exécution, pour une implémentation donnée.
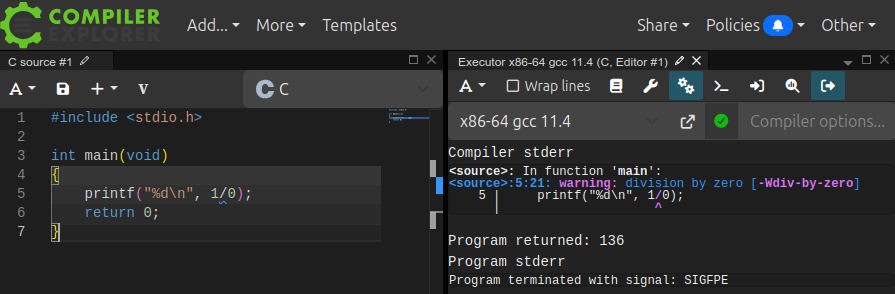
Toute expression codée qui contient une opération de division d'entiers par zéro – par exemple, l'expression 1/0 engendre un comportement non défini du programme (cf. le brouillon de la norme C23 , section 6.5.6, p. 86, ligne 6 : « if the value of the second operand is zero, the behavior is undefined »).
Dans la pratique, en règle générale, le compilateur – typiquement GCC – émet seulement un avertissement mais l'exécution peut engendrer des comportements différents :
- Sur une machine à architecture x86-64, le système d'exploitation déclenche l'interruption de l'exécution du programme et ce dernier retourne une valeur non nulle (code d'erreur) – cf. chap. C2‑I . On peut l'expérimenter sur le site Compiler Explorer godbolt.org (cf. chap. C1‑II ), comme le montre la capture d'écran ci‑dessous.
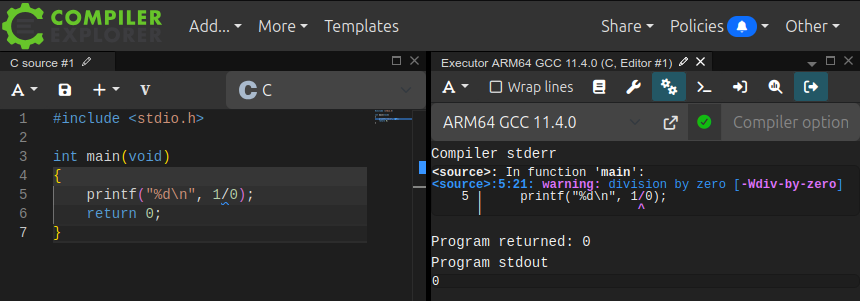
- sur une machine à architecture ARM64, la division prend la valeur invalide
0tandis que le programme poursuit son exécution et retourne la valeur0. On peut aussi l'expérimenter sur le site Compiler Explorer, comme le montre la capture d'écran ci‑dessous.
Remarque. Au regard de la définition de la notion de comportement, on pourrait s'étonner qu'elle s'applique à l'évaluation d'une expression comme 1/0 qui, a priori, n'est même pas à effet de bord. En fait, c'est son utilisation ici comme argument de la fonction printf qui engendre un comportement indéfini (l'affichage d'une valeur impossible qui se traduit parfois par l'interruption du programme – un comportement indiscutable observable dans l'environnement d'exécution).
Par ailleurs, les normes des langages C et C++ définissent également plusieurs autres types de comportements, à savoir les suivants.
- On peut avoir un comportement non spécifié – en anglais unspecified behavior, à ne pas confondre avec undefined behavior. Il s'agit de cas où un élément de code engendre un parmi plusieurs comportements possibles – mais pas n'importe quel comportement (contrairement à ce qui peut se passer dans le cas d'un comportement non défini) – sans que la norme précise lequel doit être mis en œuvre lors de l'exécution.
- Dans la norme du langage C, l'annexe J.1 est donne une liste non exhaustive de tels comportements (cf. le brouillon de la norme C23 , p. 586).
- On peut aussi avoir un comportement défini par l'implémentation – en anglais implementation‑defined behavior lorsque ce dernier n'est pas décrit par la norme mais par un document de référence de l'implémentation.
- C'est le point (1) de l'annexe J.3.5 citée supra : « The number of bits in a byte. »
- C'est également le premier point de la sous‑section 4.4 du manuel de référence de GCC : « Determined by the ABI. » (application binary interface) – parce que cela dépend de l'architecture de la machine cible pour laquelle le programme est compilé.
- Et puis on a les comportements spécifiques aux paramètres régionaux – en anglais, locale‑specific behavior, typiquement tout ce qui dépend de la langue d'écriture, de l'heure locale et de ses conventions d'écriture.
Exemple : l'ordre d'évaluation des arguments effectifs dans un appel de fonction (cf. chap. C4‑I ) est un cas typique de comportement non spécifié – c'est le point (16) de l'annexe J.1. Tous les ordres sont possibles, ce qui peut avoir son importance si l'évaluation de ces argument met en œuvre des effets de bord.
Exemple : le nombre de bits dans un octet est un cas fameux de comportement spécifié par l'implémentation :
Enfin, pour les normes des langages C et C++, un autre intérêt majeur de la notion de comportement est qu'elle permet de cerner ce qu'il faut imposer aux compilateurs au regard des optimisations qu'ils peuvent opérer lors de la génération du code exécutable : ne rien faire qui puisse modifier le comportement du programme. On aboutit à la fameuse règle implicite « as‑if » W qui autorise le compilateur à modifier le programme exécutable généré à partir du code source tant que cela ne change pas son comportement. Dans la norme, cette règle n'est pas explicitement formulée de la sorte mais découle de la notion d'implémentation conforme (cf. le brouillon de la norme C23, section 5.1.2.4, §6, p. 14 C).
En particulier, l'optimisation peut supprimer des instructions qui, même si elles ont un effet de bord, ne produisent aucun comportement : c'est par exemple le cas de la déclaration d'une variable non utilisée dans le programme. En revanche, si la valeur de cette variable a une incidence sur le comportement ultérieur du programme, sa déclaration ne doit surtout pas être supprimée.
Les commentaires
Définition et syntaxe de saisie
De façon générale, dans un programme source, un commentaire est un morceau de « code » délimité qui est ignoré lors de la compilation ou de l'interprétation. Il ne constitue donc pas du code à proprement parler.
En langages C/C++, dans un fichier source, un commentaire est délimité :
- soit entre le séparateur
//, qui marque le début d'un commentaire, et la fin de ligne où le commentaire est saisi, qui clôt le commentaire ; - soit par une paire de délimiteurs
/* … */entre lesquels le texte saisi peut éventuellement s'étendre sur plusieurs lignes consécutives du fichier ; on parle alors de bloc de commentaires.
Ainsi détecté par le préprocesseur (cf. chap. C1‑II ), tout commentaire ne fait l'objet d'aucune transmission au compilateur.
On retiendra la règle syntaxique suivante : en langages C/C++, les commentaires peuvent être placés partout où l'« ajout d'un espace est autorisé ». Plus précisément, dans le cadre de ce qu'on appelle le format libre (cf. infra ), si l'ajout d'un espace dans le code n'a aucun impact sur l'interprétation du code par le compilateur, alors cet espace peut être remplacé par n'importe quel commentaire, aussi long soit‑il.
En revanche, on ne peut pas encapsuler deux blocs de commentaires l'un dans l'autre, comme ci‑dessous, où l'erreur de syntaxe est déjà visible par coloration syntaxique à la ligne nº 8.
// DO NOT DO THIS! (it will generate an error) /* starting of comment bloc 1 /* starting of comment bloc 2 ending of comment bloc 2 */ ending of comment bloc 1 */ // the error is visible here
En effet, pour le préprocesseur :
- à la ligne nº 4, le délimiteur initial
/*du bloc 2 (interne) n'est alors pas reconnu comme tel, mais comme un commentaire ; - à la ligne nº 6, le délimiteur final
*/du bloc 2 (interne) est donc reconnu comme celui du bloc 1 ; - à la ligne nº 8, le délimiteur final
*/du bloc 1 (externe) est génère donc une erreur syntaxique puisqu'il n'est pas apparié à un délimiteur initial.
Une éventuelle solution consiste donc à mettre en commentaire individuellement toutes les lignes avec autant de séparateurs // comme ci‑dessous :
// THIS IS OK (but not very convenient) // starting of comment bloc 1 // ///* starting of comment bloc 2 // //ending of comment bloc 2 */ // //ending of comment bloc 1
Malcommode à saisir à la main, cette solution peut néanmoins être automatisée par une fonctionnalité de l'éditeur de code. En règle générale, il suffit de sélectionner le bloc de lignes à commenter ou décommenter et d'appuyer simultanément sur une séquence de touches :
- Ctrl : sur Sublime Text,
- CtrlShift / sur VS Code,
pour successivement commenter/décommenter d'un seul coup toutes les lignes du bloc sélectionné.
On verra au chapitre C4‑III qu'il existe une meilleure solution pour les grosses parties de code à commenter, en utilisant une directive de compilation conditionnelle.
Emploi des commentaires

Dans un programme, les commentaires sont réservés aux seuls lecteurs du code source. Ils servent principalement à apporter des explications complémentaires au code que le codeur juge utiles pour lui‑même (notamment, pour plus tard…) ou ses éventuels collègues.
Les commentaires peuvent avoir d'autres emplois, notamment :
- former des lignes de séparation dans le code ;
- rendre « invisible » pour le compilateur une partie de code.
Apporter des explications complémentaires sur le code est parfois nécessaire, mais il faut ne pas abuser des commentaires, au risque sinon de gêner la lecture du code lui‑même. Des recommandations de rédaction des commentaires sont données au chapitre C2‑X .

Dans l'extrait de programme ci‑dessous pour carte Arduino ont été ajoutés divers commentaires pour illuster quelques possibilités d'emploi de façon académique. Certes, ils sont un peu trop nombreux pour un programme aussi simple, mais ils ont été placés pour gêner le moins possible la lecture du code.
/* * * * * * * PROGRAM: basic LED blink * * * * * * *
* Hardware:
* - board: any Arduino board
* - green LED associated with 220 ohm resistor
* Version : 1.0 (01/04/2018)
*/
const int LED_PIN = 2; // avoid pin 0 and 1 (serial port)
// const int BUTTON_PIN = 3; // comment if not needed
void setup() {
pinMode(LED_PIN, OUTPUT);
}
// =====================================================
On peut remarquer que dans la présente page web, les commentaires sont automatiquement mis en italique gris par le script de coloration syntaxique Code Prettify (cf. chap. C2‑X ). C'est un style d'atténuation qui poursuit le même but de gêner le moins possible la lecture du code proprement dit, et c'est la pratique adoptée par tous les éditeurs de code.
Les langages C et C++ n'acceptent pas les commentaires au sein d'une chaîne de caractères (morceau de code délimité entre des guillemets doubles "). Ainsi, le code :
"text /* comment */ text"
est compris par le compilateur comme une chaîne de caractères qui inclut les séquences /* et */ comme des caractères ordinaires.
Cette restriction est conforme avec la propriété énoncée supra qu'un commentaire peut être placé partout là où l'ajout d'un espace est ignoré dans le cadre du format libre de codage. En effet, dans une chaîne de caractères, tout ajout d'un caractère d'espace est « significatif » (cela change la valeur de la chaîne).
Les instructions et les expressions
Attention ! Les notions d'instruction et d'expression sont fondamentales en programmation ; on les retrouve dans la plupart des langages. Traditionnellement (et même dans la norme du langage C – cf. p. ex. le brouillon de la norme draft C23, p. 107 pour le premier point ci‑dessous), on considère que, durant l'exécution d'un programme :
- une instruction est destinée à accomplir une action ;
- une expression est destinée à prendre une valeur.
Cependant, cette approche est d'abord passablement simpliste dans l'univers moderne de la programmation, mais surtout, elle totalement prise en défaut par les fondements des langages C et C++. En effet :
- l'affectation est traitée comme un opérateur parmi d'autres ; son effet de bord (que l'on peut apparenter à une « action ») intervient donc lors de son évaluation, potentiellement bien avant la fin du traitement de l'instruction dans laquelle elle est codée ;
- une fonction peut ne retourner aucune valeur (si elle est de type
void), donc une expression d'appel d'une telle fonction ne prendra aucune valeur.
Or la bonne compréhension des notions fondamentales de programmation n'est pas une question philosophique accessoire. C'est un prérequis décisif pour pouvoir coder correctement. On accordera donc la plus grande attention à ce qui va suivre.
Généralités

Ces deux notions sont à ne pas confondre. Heureusement, d'un point de vue syntaxique, la distinction est très facile à faire.
Les directives commencent toujours par le symbole # et sont séparées des autres parties de code (autres directives ou instructions) par de simples sauts de ligne – et non pas par le symbole ; qui délimite une fin d'instruction simple (cf. infra ).
Elles servent à modifier le code source avant la compilation, notamment pour inclure d'autres fichiers source, mettre en place des substitutions de termes ou encore pour sélectionner des parties de code à compiler ou ignorer, sous certaines conditions. Leur codage est détaillé au chapitre C4‑III .
Les instructions sont les principales unités de codage source à traduire en langage machine. Elles peuvent être regroupées dans des blocs, qui sont des séquences d'instructions délimitées par des accolades ouvrantes et fermantes { }.
Par ailleurs, un bloc (en anglais, compound statement) peut être :

Considérons le programme académique ci‑dessous qui teste une formule de génération de nombres aléatoires compris entre 1 et 6, par exemple pour modéliser le comportement d'un dé à six faces :
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX_VALUE 6
int nbRoll = 50;
int main(void)
{
srand(time(NULL));
for (int roll = 1; roll <= nbRoll; roll++) {
int dice = (rand() % MAX_VALUE) + 1;
printf("%d ", dice);
}
printf("\n");
return 0;
}
On y trouve dans l'ordre :
- quatre directives (aux lignes n° 1, 2, 3 et 5) – toutes commencent bien par le symbole
#; - une instruction de déclaration d'une variable globale (à la ligne n° 7) ;
- la définition de la fonction nommée
maindont le bloc ainsi nommé comporte lui‑même quatre instructions : - une instruction simple à la ligne n° 11 ;
- une instruction structurée (boucle
for) dont le bloc anonyme comporte : - une instruction de déclaration locale à la ligne n° 13 ;
- une instruction simple à la ligne n° 14 ;
- puis encore deux instructions simples aux lignes n° 16 & 17.
Instructions
Dans un fichier source, une instruction W – en anglais, statement (la traduction transparente « instruction » étant réservée pour le niveau machine) – est une unité de codage au même titre qu'une phrase dans un texte. De façon simplifiée, on peut classer les instructions en deux catégories :
- On a des instructions simples, sans structure de contrôle, terminées par un symbole
;au même titre que dans un texte, on a des phrases simples (des successions de mots qui font sens, terminées par un point). - Et on a aussi des instructions structurées avec des mots‑clefs qui contrôlent le flux d'exécution du programme (cf. chap. C2‑V ), et qui sont composées d'autres instructions, au même titre que dans un texte, on a des phrases structurées avec des signes de ponctuations plus divers (« : », « ; », « – »), des sauts de lignes, des indentations, etc.
Les instructions sont traitées par le compilateur comme des « unités » devant former un tout cohérent, chacune étant presque toujours traduite en plusieurs instructions machines dans le code exécutable.
Bien entendu, les normes proposent une classification plus complexe (cf. le brouillon de la norme C23, pp. 154–158 C). En particulier, elles distinguent les instructions‑étiquettes comme case : et default : (cf. chap. C2‑V ) ainsi que celles définies par l'utilisateur pour effectuer des sauts inconditionnels avec le mot‑clef goto (cf. chap. C2‑V ) .
- La norme du langage C fait aussi la distinction entre les notions d'instruction et de déclaration. Dans ce sens plus strict, l'exemple issu du code donné supra et reproduit ci‑dessous n'est pas une instruction mais une déclaration :
- En langages C/C++, rien n'interdit de coder une instruction inutile, par exemple :
- De même, il existe l'instruction vide :
int nbRoll = 50;
2 + 2;
-Wall de la commande gcc (cf. chap. C1‑II ), elle sera quand même signalée par un avertissement du compilateur, du genre : warning: statement with no effect [-Wunused-value] 3 | 2 + 2; | ^
;
Instructions simples
Une instruction simple – aussi appelée instruction‑expression – est constituée d'une seule expression (laquelle peut éventuellement être complexe) immédiatement suivie du symbole ; (en anglais, semicolon W). Ce symbole, qui délimite unilatéralement la fin d'instruction, pourrait en quelques sorte être vu comme un « opérateur » qui transforme l'expression en instruction pour constituer une unité de codage du fichier source, reconnue par le compilateur.
On voit donc qu'une instruction simple pourrait être vue comme étant « presque une expression », or on touche ici un point crucial de la distinction qu'il ne faut cependant jamais perdre de vue entre ces deux notions. Contrairement à l'intuition que pourrait avoir un codeur familier d'autres langages de programmation mais débutant en langage C, c'est l'évaluation de l'expression (cf. infra ) qui potentiellement engendre un effet de bord (cf. supra ) lors de l'exécution du programme, et non pas l'achèvement de l'instruction qui englobe cette expression.
Ainsi, même une instruction simple peut enclencher plusieurs effets de bord successifs au cours de l'évaluation de son expression, en particulier si cette dernière est composée avec l'opérateur séquentiel comme une succession de sous‑expressions (cf. infra ).
On a déjà vu dans les programmes donnés en exemples précédemment de nombreux exemples des deux cas les plus emblématiques d'instructions simples comme :
-
userAge = 20;où l'expression est une affectation, -
printf("%d ", dice);où l'expression est un appel de fonction.
Instructions structurées
Une instruction structurée permet de faire bifurquer ou reboucler le flux séquentiel de l'exécution du programme qui normalement suit l'ordre d'inscription des instructions dans le ou les fichiers sources.
Syntaxiquement, une instruction structurée se compose :
- d'expressions encapsulées dans des parenthèses
(), - d'instructions simples ou d'autres instructions structurées,
- de mots‑clefs comme
if,else,while, etc. - de délimiteurs de blocs
{}.
Attention : l'accolade fermante } d'un bloc intégré à une structure de contrôle n'est jamais suivie par un séparateur ; de fin d'instruction. C'est un aspect syntaxique distinctif des instructions structurées par rapport aux instructions simples (cf. supra ).
En particulier, il faut ne pas confondre avec la fin d'une déclaration qui se termine par une liste, dont l'accolade fermante }, elle, est bien suivie du séparateur ; de fin d'instruction, comme dans l'exemple ci‑dessous issu du chapitre C3‑IV :
enum Color {GREEN,YELLOW,BLUE};
(Le cas particuliers de la structure do… while qui, elle, se termine bien par un séparateur de fin d'instruction ; n'est pas concerné par cette règle puisque son dernier élément de code est une expression encapsulée dans des parenthèses et non pas un bloc – cf. chap. C2‑V ).
L'extrait de code académique ci‑dessous ne comporte qu'une seule instruction structurée, dite de bifurcation :
if (userAge >= LEGAL_AGE) {
entrance = true;
}
else {
entrance = false;
}
Cette instruction est composée de deux instructions simples, dont une seule sera exécutéeselon le résultat du test spécifié par l'expression entre parenthèses après le mot‑clef if.
Expressions

La notion d'expression W – mot ayant une traduction transparente en anglais – est également une notion très importante : on la retrouve dans tous les langages de programmation. Pour un codeur débutant, il est pertinent de faire une analogie avec les mathématiques, où l'on parle d'expression pour désigner « toute écriture qui puisse être calculée », en remplaçant les occurrences des variables par leurs valeurs respectives.
Syntaxe d'une expression
D'un point de vue syntaxique, en langages C/C++, une expression est un élément de code composé typiquement :
- d'appels de fonctions ; ex. :
sin( ),abs( ), etc. - d'opérateurs ; ex. :
+-*/,()=!&&, etc. - d'identificateurs de données déclarées (variables ou constantes) ; ex. :
newVoltage,previousVoltage… - de constantes littérales (valeurs numériques, caractères isolés, chaînes de caractères, etc.) ; ex. :
100.0,'A',"hello"…
qui doivent eux‑même respecter les règles de syntaxes auxquelles ils sont soumis.
À chaque emploi d'un opérateur ou appel d'une fonction, une expression peut se décomposer en sous‑expressions jusqu'à ce que ces dernières se réduisent à :
- soit à un identificateur de donnée,
- soit à constante littérale,
constituant autant d'expressions atomiques – ou plus simplement, d'atomes – au sens où elles‑mêmes ne sont pas décomposables (littéralement, elles sont indivisibles).
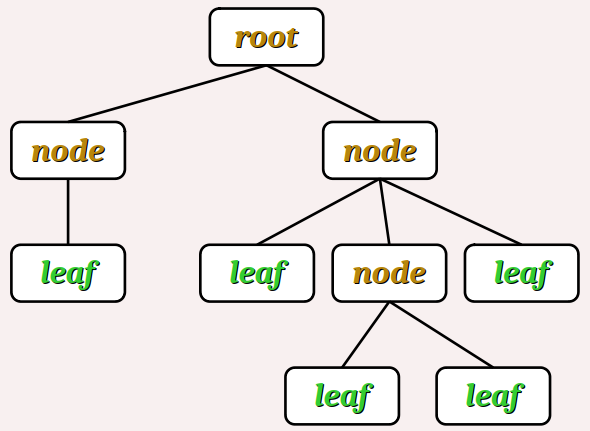
De façon analytique, on peut représenter la composition d'un expression par un arbre syntaxique dont :
- les nœuds sont des opérateurs et appels de fonctions,
- les feuilles sont des atomes
Il est d'usage de représenter cet arbre « à l'envers », c'est‑à‑dire avec la racine en haut (le premier nœud) et les feuilles en bas, comme sur la figure ci‑contre.
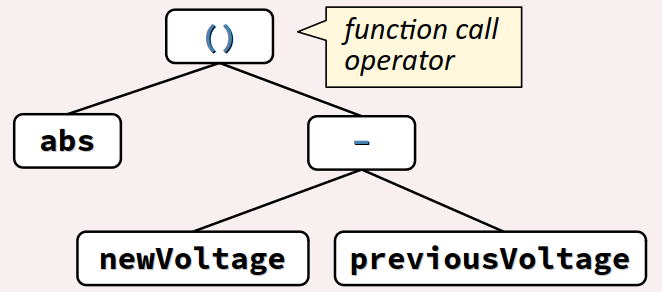
- L'expression codée en langage C :
abs(newVoltage - previousVoltage)
correspond à l'expression mathématique |newVoltage − previousVoltage| - de l'appel de la fonction
abs(valeur absolue) appliquée à la sous‑expressionnewVoltage - previousVoltage; - cette sous‑expression étant elle‑même composée via l'opérateur
-(soustraction) appliqué aux deux atomesnewVoltageetpreviousVoltage. - L'expression codée en langage C :
newVoltage = previousVoltage / 2.0
est une fondamentalement une affectation dont l'opérateur est codé=(cf. chap. C2‑IV ). - de l'atome
newVoltageet de la sous‑expressionpreviousVoltage / 2.0; - cette sous‑expression étant elle‑même composée via l'opérateur
/(division) appliqué aux deux atomespreviousVoltageet2.0, cette dernière étant une constante littérale numérique de type décimal.
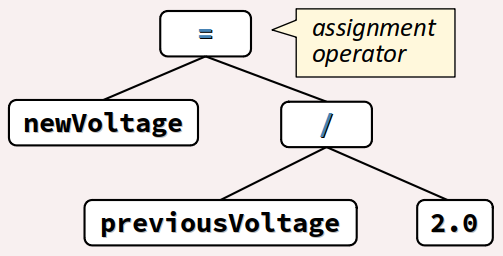
Sémantique d'une expression
En langages C/C++, d'un point de vue sémantique, une expression :
Durant la compilation ou l'exécution du programme, on appelle évaluation le processus qui consiste :
- à calculer la valeur d'une expression ;
- mettre en œuvre les effets de bord qui lui sont associés.
Au cours de l'exécution des instructions machines correspondant à une instruction du code source comportant des expressions produisant chacune des effets de bord, ces derniers sont donc mis en œuvre au fur et à mesure de l'évaluation des expressions, et non pas tout à la fin du traitement de l'instruction source.
Le codeur doit avoir pleinement conscience de ce mode opératoire, au risque sinon de générer des comportements indésirables du programme.
Considérons le programme académique suivant codé dans un fichier source nommé sideEffects.c :
#include <stdio.h>
int main(void)
{
int a = 0;
printf("a=%d\n", a = 1);
return 0;
}
La ligne n° 6 est constitué d'une instruction simple (ou instruction‑expression) qui comporte juste une expression d'appel de la fonction printf. Or son deuxième argument est composé de la (sous‑)expression a = 1 qui possède un effet de bord.
Lors de l'exécution de cette instruction :
- la variable
aest affectée et prend la valeur1; - l'expression
a = 1est évaluée et prend la valeur1; - cette valeur est ensuite injectée dans la spécification de conversion
%d.

Sans surprise, on a une compilation sans avertissement et le programme produit en sortie standard l'affichage attendu :
gcc -Wall sideEffect.c -o sideEffect && ./sideEffecta=1
Mais considérons maintenant une version modifiée du programme comme ci‑dessous :
#include <stdio.h>
int main(void)
{
int a = 0;
printf("a=%d a=%d\n", a = 1, a = 2);
printf("a=%d\n", a);
return 0;
}
Cette fois, dans l'expression d'appel de printf (ligne n° 6 ), on trouve deux arguments qui sont des expressions à effet de bord sur a. Et là, cela pose un problème, car la norme du langage C ne précise pas dans quel ordre les arguments d'une fonction sont évalués. Ce choix est laissé à la discretion de l'implémentation. On a donc un programme qui, sémantiquement, aura un comportement indéfini.
C'est donc pourquoi lors de la compilation, l'option -Wall déclenche un avertissement :
gcc -Wall sideEffect.c -o sideEffectsideEffects.c: In function ‘main’: sideEffects.c:6:35: warning: operation on ‘a’ may be undefined [-Wsequence-point] 6 | printf("a=%d a=%d\n", a = 1, a = 2); | ~~^~~
Et le fait est que l'exécution du programme donne un affichage difficile à prévoir :
./sideEffectsa=1 a=1 a=1
En effet, en principe l'expression a = 2 devrait prendre la valeur 2 à transmettre à la 2e spécification de conversion %d dans la chaîne de format. Et pourtant, c'est la valeur 1 qui est affichée.
On retiendra donc qu'il est vivement recommandé de ne coder pas plus d'une expression à effet de bord sur une même variable dans une même instruction.
Expression constante
En première approximation, on peut dire qu'une expression constante est une expression dont les atomes sont exclusivement des constantes littérales ou déclarées (cf. supra ). Cette restriction rend bien évidemment impossible tout recours à un opérateur d'affectation (simple ou composé), qui ne peut s'appliquer qu'à une variable déclarée.
De plus, une expression constante ne doit comporter aucun appel de fonction ni aucun recours à l'opérateur séquentiel.
En règle générale, une expression constante doit donc pouvoir être évaluée dès la compilation du programme, et non pas seulement lors de son exécution.
L'expression 1 + (a / 2) :
- est bien une expression constante si
aest une constante déclarée dans une instruction préalable ; - n'est pas une expression constante si
aest une variable déclarée dans une instruction préalable.
Pour plus de détails, il est vivement recommandé de consulter :
Expression constante entière
En première approximation, on peut dire qu'une expression constante entière est une expression constante qui :
- doit être évaluée dans un type entier ;
- ne peut être composée qu'avec d'autres expressions constantes entières et des constantes littérales – ce qui signifie que les constantes déclarées sont interdites.
La notion d'expression constante entière est très importante, car elle est requise dans de nombreuses formes syntaxiques en langage C – par exemple, pour coder le nombre d'éléments d'un tableau, les valeurs des cas d'une bifurcation multiple switch, etc.
Sa définition est subtile et elle ne doit pas être confondue avec celle d'expression constante à laquelle on imposerait seulement en plus d'être de type entier.
Sont par exemple des expressions constantes entières :
-
(8 * 7) - 3ou encore n'importe quelle expression arithmétique composée de constantes littérales entières, et même en utilisant l'opérateur/qui agit comme la division euclidienne (cf. chap. C3‑II ; -
RED + 1oùREDpeut‑être l'identificateur : - d'une constante entière listée dans la déclaration d'un type énuméré (cf. chap. C3‑IV ), car une telle constante a justement le statut d'expression constante entière ;
- d'une pseudo‑constante dont la valeur après expansion complète est celle d'une constante entière (cf. chap. C4‑III ) ;
-
(int) (7.0/3)où la constante littérale décimale7.0impose une division algébrique, mais dont la valeur décimale est ensuite convertie explicitement par l'opérateur(int)dans un type entier (cf. chap. C3‑VI ).
Là encore, pour plus de détails, il est vivement recommandé de consulter la norme du langage C , section 6.6.
L'opérateur séquentiel
Les langages C et C++ incluent l'opérateur séquentiel dont le symbole est , (comma operator). Cet opérateur permet de concaténer (c'est‑à‑dire réunir bout à bout) plusieurs expressions. Le code :
expression 1,
expression 2,
…,
expression n
constitue une expression séquentielle qui, lorsqu'elle est évaluée, procède aux évaluations successives de expression 1 à expression n dans cet ordre.
Attention ! Lorsque qu'un programme comporte plusieurs expressions successives très courtes, il pourrait être tentant de concaténer avec l'opérateur séquentiel afin de les faire tenir sur une seule ligne de code, comme par exemple :
a = 0, b = 2;
Toutefois, pour une bonne lisibilité, sauf exceptions, il est recommandé de respecter le principe :
« une affectation, une ligne de code ».
Néanmoins, on verra que l'opérateur séquentiel trouve son utilité dans certaines parties structurées du code, notamment pour enrichir les trois expressions spécifiant les conditions de répétition d'une boucle for (cf. chap. C2‑V ).
Les identificateurs et mots‑clefs
Identificateurs
Dans le code source, on appelle identificateur W – en anglais, identifier – est une suite de caractères formant un nom pour désigner :
- une donnée (constante ou variable),
- un type de données,
- une fonction…
Dans tout langage de programmation, de nombreux identificateurs sont évidemment déjà définis, en particulier les mots‑clefs (cf. infra ), qui constituent le noyau du langage (en anglais, core). On dit qu'ils sont des identificateurs réservés, au sens où ils ne peuvent pas être redéfinis par le codeur.
De plus, tout module de bibliothèque apporte aussi son lot d'identificateurs déjà déclarés. En langages C/C++, ces identificateurs peuvent être employés dans le code dès lors qu'on a codé la directive d'inclusion du module (cf. chap. C2‑I ).
En revanche, tout nouvel tout nouvel identificateur choisi par le codeur doit être préalablement faire l'objet d'une déclaration ou d'une définition avant d'être utilisé dans une instruction.
Choix d'un identificateur
Le choix par le codeur d'un nouvel identificateur obéit à des règles lexicographiques impératives, spécifiques aux langages C et C++ :
- employer seulement le jeu de caractères autorisés qui comprend (sauf configurations de compilation spéciales) :
- les lettres de l'alphabet latin
AàZetaàz, - sans accents,
- avec distinction de la casse (majuscules et minuscules non confondues) ;
- les chiffres dits « arabes »
0à9; - le tiret bas
_(underscore) qui est assimilé à une lettre. - ne pas commencer par un chiffre (mais donc, un identificateur peut commencer par un tiret bas).
- (hyphen) qui symbolise l'opérateur de soustraction ; - Identificateurs valides :
iD5d5newVoltageNEW_VOLTAGE_exceptions… - Identificateurs non valides :
-
5D(chiffre initial interdit), -
énergieCumulée(lettres accentuées interdites), -
new Voltage(espace interdit), -
new-Voltage(trait d'union interdit).
- Commencer un identificateur par un tiret‑bas
_est syntaxiquement correct, mais en pratique réservé pour des identificateurs spéciaux, notamment ceux désignant les variables d'environnement (par exemple__cplusplus, cf. chap. C1‑II ). - Certains compilateurs de la famille GCC autorisent l'emploi du caractère
$en qualité de lettre dans les identificateurs.
Mots‑clefs
Un mot‑clef W – en anglais, keyword – est un identificateur réservé du langage. Il est reconnu sans déclaration préalable ni instruction spécifique par le compilateur.
En langage C/C++, les mots‑clefs servent principalement à coder les déclarations, des structures de contrôle voire certains opérateurs.
Les mot‑clefs d'un langage évoluent au fil des normes :
- le langage C en compte 44 depuis la norme C11 (avec 6 ajouts par rapport à la norme C99) ;
- le langage C++ en compte 94 depuis la norme C++20 (avec 7 ajouts par rapport à la norme C++17) .
Les mots‑clefs s’apprennent au fur et à mesure de leur utilisation. Certains étant très techniques et d'usage rares, il faut plusieurs années de pratique avant de les aborder.
Dans un premier temps, on peut se contenter de retenir les mot‑clefs listés ci‑dessous, relatifs :
- aux types :
const(constante),void(vide),int(entier),float(décimal à virgule flottante),bool(booléen),char(caractères)… - aux structures de contrôle (cf. chap. C2‑V ) :
if,else,switch,case,break,default,for,while,do…
Aux yeux d'un codeur débutant, certains identificateurs d'usage très courant peuvent abusivement passer pour des mots‑clefs du langage, alors qu'ils sont en fait introduits sous d'autres formes dans des modules de bibliothèques.
Ainsi, dans le framework Arduino, contrairement à false et true qui sont bel et bien des mots‑clefs du C++, les identificateurs LOW et HIGH ne sont pas des mots‑clefs mais des pseudo‑constantes (cf. chap. C4‑III ) définies dans le fichier d'en‑tête Arduino.h.
Les séparateurs et délimiteurs
Séparateurs et délimiteurs symboliques
Séparateurs
Un séparateur W est un symbole ou une séquence de symboles. Il sert à la chaîne de compilation pour distinguer les uns des autres les éléments de code successifs d'un programme.
Les séparateurs du langage C sont listés ci‑dessous. Certains peuvent avoir de multiples usages.
| Symbole(s) | Usage courant |
|---|---|
; |
fin d'instruction |
, |
entre expressions (arguments de fonctions, valeurs de tableau, etc.) |
... |
entre expressions (valeurs de cas, index de tableaux, fin des arguments explicites) | : |
fin d'étiquette (case) |
// |
début de commentaire de fin de ligne |
- Le symbole
;sert également séparer les expressions codant l'en‑tête d'une bouclefor(cf. chap. C2‑V ), lesquelles ne sont pas à proprement parler des instructions. - Le symbole
,est aussi celui de l'opérateur séquentiel (cf. supra ). - Le séparateur
...est appelé ellipsis en anglais W.
Délimiteurs
On parle de délimiteurs W – en anglais, balanced delimiter – lorsque deux séparateurs fonctionnent par paire pour encadrer une partie de code.
Ceux du langage C sont listés ci‑dessous. Comme les séparateurs, ils peuvent avoir de multiples usages.
| Symboles | Usage courant |
|---|---|
{ } |
séquence d'instructions (bloc), liste de valeurs, de constantes… |
( ) |
expression |
[ ] |
nombre d'éléments ou indice d'élément d'un tableau |
< > |
nom de fichier d'en‑tête de module de bibliothèque |
' ' |
caractère seul |
" " |
chaîne de caractères |
/* */ |
bloc de commentaires (sur une ou plusieurs lignes) |
- Certains délimiteurs jouent très souvent le rôle d'opérateur, en particulier
()et[](cf. chap. C2‑IV ). - La distinction entre séparateurs et délimiteurs ne fait pas l'unanimité. On pourrait en effet considérer que
;est un délimiteur de fin d'instruction, alors que,serait un « vrai » séparateur d'expressions (il est placé entre deux expressions, mais pas à la fin). En définitive, même si elle emploie le terme delimiters, la norme classe tous ces éléments de code dans la même catégorie punctuators (avec les symboles des opérateurs). - Quoi qu'il en soit, ces symboles requièrent la plus grande attention. Toute confusion, omission ou mauvais placement est une source d'erreur de codage. C'est pourquoi :
- il est vivement recommandé de les placer conformément aux règles usuelles de formatage du code, avec des espaces d'aération entre les symboles (cf. infra) ;
- il est très utile que l'éditeur de code mette en œuvre une coloration syntaxique pour rendre les séparateurs et délimiteurs particulièrement visibles.
Séparateurs « blancs »
Dans un fichier source, les principaux caractères d'espacement sont :
- l'espace (saisi par la barre « espace ») ;
- le saut de tabulation horizontale (saisi par la touche « TAB ↹ ») ;
- le saut de ligne (saisi par la touche « entrée ↲ ») – en anglais newline.
Dans certains cas, ils peuvent jouer le rôle de séparateurs entre deux éléments de code atomiques successifs. On parle de séparateurs « blancs » W.
- Il existe également deux autres caractères d'espacement qui sont acceptés en langages C et C++ :
- le saut de tabulation verticale (vertical tabulation, abrégé VT),
- et le saut de page W (form feed, abrégé FF),
- Également en héritage des téléscripteurs, un saut de ligne est souvent implémenté dans un fichier source par une séquence de deux caractères de contrôle CR LF (non affichés à l'écran mais opérant une action lors de la visualisation du fichier), à savoir :
- un caractère de retour chariot W (carriage return ou CR) ;
- un caractère de nouvelle ligne W (littéralement, d'alimentation d'une ligne supplémentaire par rotation du tambour, d'où le terme anglais line feed ou LF).
- avec Linux, un saut de ligne est par défaut implémenté par un caractère LF seul ;
- avec MacOS, un saut de ligne est par défaut implémenté par un caractère CR seul.

View/Line Endings. Comme pour les expressions (cf. supra ), on a la notion d'élément de code atomique pour désigner toute succession de caractères du code source qui ne peut pas être divisée par un séparateur blanc sans en changer le sens. En particulier, sont des éléments atomiques :
- tous les mots‑clefs et autres identificateurs,
- toutes les constantes littérales,
- tous les symboles constitués de plusieurs caractères (
//<<etc.).
Dans la déclaration académique suivante :
int userAge;
- l'identificateur
userAgeest un atome ; - en revanche, au moins un espace de séparation entre
intetuserAgeest indispensable comme séparateur ;
int user Age; avec un espace au milieu, le compilateur détecterait deux nouveaux identificateurs distincts user et Age ; intuserAge; le compilateur ne détecterait qu'un seul identificateur et pas le mot‑clef int. Principe du format libre
En langages C/C++, les caractères d'espacement diffèrent des autres séparateurs car ils peuvent être surnuméraires d'un point de vue purement syntaxique. Ceux qui sont « en trop » sont tout simplement supprimés par le préprocesseur (au même titre que les commentaires).
On dit que les langages C/C++ sont à format libre, au sens où le programmeur est libre d'espacer et d'indenter son code.

A contrario, un langage comme Python n'est pas à format libre : l'indentation des instructions d'un programme code la structure d'exécution de ce dernier, ce qui permet de faire l'économie des délimiteurs de blocs.
La déclaration de l'exemple académique précédent pourrait aussi se coder de façon « fantaisiste » :
int
userAge
;
Mais bien entendu, il n'est pas question d'abuser ainsi de la liberté du format ! Pour faciliter la lecture, on doit trouver un bon compromis entre aération et compacité. Ici, les espaces ne sont pas ajoutés avec pertinence – au contraire, ils nuisent à la bonne lisibilité du code (cf. chap. C2‑X ).
Codage d'un saut de ligne « fictif »
Lorsqu'une ligne de code est très longue, il peut être souhaitable pour bonne la lisibilité d'insérer un saut de ligne « fictif », c'est‑à‑dire sans séparateur blanc.
Un tel saut de ligne doit apparaître lors de l'édition de code mais pas durant la compilation.
Les langages C/C++ permettent justement de demander au préprocesseur d'ignorer un saut de ligne : il suffit de faire précéder la séquence de caractères de ce saut de lignes par le symbole \ (contre‑oblique, en anglais antislash ou backslash).
Attention ! Aucun séparateur blanc ni commentaire ne peut être inséré entre le symbole \ et le caractère (ou la séquence de caractères) de saut de ligne.
Considérons code académique ci‑dessous (qui, au passage, est mal colorisé par le script Code Prettify utilisé dans cette page web – cf. chap. C2‑X ) :
printf("====================\
====================\
====================");
Avant même sa compilation, il sera transformé par le préprocesseur en :
printf("============================================================");
Il produira donc l'affichage d'une ligne de caractères « = » sans discontinuité.
Le codage de sauts de ligne fictifs peut fausser les indications de numéros des lignes dans les messages d'avertissement ou d'erreurs émis par la chaîne de compilation.