On appelle donnée toute information mémorisée dans un espace de stockage (mémoire) qui lui est alloué. En programmation, la faculté de mémoriser une information suppose l'aptitude à y accéder, c'est‑à‑dire consulter et éventuellement modifier sa valeur. Pour cela, il faut nécessairement être capable d'identifier la donnée. Le plus souvent, on lui donne un nom qu'on appelle identificateur. Ce procédé s'appelle une déclaration.
Généralement, on parle W :
- de donnée variable lorsque sa valeur est mutable, c'est‑à‑dire susceptible de changer au cours de l'exécution d'un programme,
- et de donnée constante lorsque sa valeur est immuable (en anglais immutable).
En langages C et C++, tous ces aspects recèlent de nombreuses particularités qui requièrent, dès les premiers programmes, une grande vigilance. Ce chapitre est donc consacré à :
- passer en revue tous les généralités relatives à la déclaration des données, qu'il est indispensable d'avoir à l'esprit pour comprendre ensuite toutes les particularités ;
- détailler les bases de la syntaxe des instructions de déclaration des variables et des constantes ;
- préciser le codage des expressions d'initialisation que ces instructions peuvent comporter ;
sachant que d'autres éléments de langages relatifs à la déclaration des données seront apportés dans les chapitres suivants, au fur et à mesure de l'étude des types de données élémentaires (partie C3) et structurées (partie C5).
Généralités
Notions de donnée, de valeur et de type
Les notions de donnée, de valeur et de type sont trois notions fondamentales indissociables en programmation. Elles font appel aux notions subalternes d'encodage en mémoire et d'interprétation de cet encodage.
En programmation, on appelle donnée une information stockée en mémoire par un programme – c'est‑à‑dire matériellement encodée durant son exécution par un ensemble de bits. L'encodage constitue ce qu'on appelle une représentation de bas niveau de l'information.
De plus, une donnée prend une valeur (constante ou variable) conformément à un type :
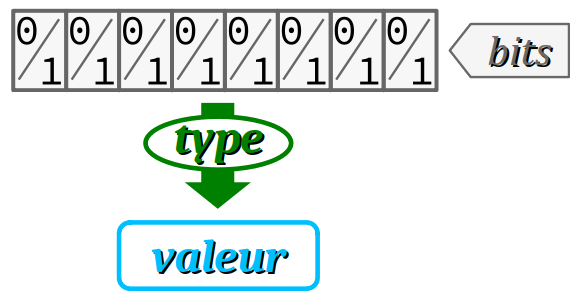
- la valeur est l'interprétation de haut niveau que confère le programme aux bits de la donnée, de sorte qu'on puisse donner lui un sens : tel nombre, telle chaîne de caractères, etc.
- le type d'une donnée est une appellation catégorielle qui détermine la valeur de la donnée à partir de son encodage en mémoire : par exemple, entier, décimal, caractère, etc.
En langages C et C++, une donnée peut figurer dans le code source d'un programme sous trois formes.
- Il peut s'agir d'une donnée anonyme, sous forme d'une constante littérale, c'est‑à‑dire d'une valeur codée dans un format qui détermine son type implicite.
- Il peut s'agir donnée nommée :
- soit sous la forme d'une variable ou d'une constante à laquelle le codeur associe, par une déclaration, un identificateur et un type explicite ;
- soit sous la forme d'une pseudo‑constante définie via la directive
#define(cf. chap. C4‑III ) avec un identificateur, mais alors avec un type implicite comme pour une constante littérale.
3, -5.4, 'M' (la lettre), "Hello" (une chaîne de caractères) int userAger = 25; #define AGE_MIN 18 Par l'instruction académique ci‑dessous, on déclare une donnée variable :
int myFirstVariable = 13;
- de type
int(entier standard) ; - nommée
myFirstVariable– c'est son identificateur ; - de valeur initiale spécifiée par la constante littérale codée
13, elle aussi préalablement interprétée par le compilateur comme étant implicitement de typeint(aucune conversion ne doit donc être mise en œuvre).

Sur un poste de travail récent à architecture 32 ou 64 bits, quel que soit le système d'exploitation, la valeur d'une donnée de type int est encodée en mémoire sur 4 octets, soit 4 × 8 = 32 bits. Ces 32 bits représentant la valeur entière 13 en binaire vaudraient :
00000000 00000000 00000000 00001101
Remarque. Si on avait déclaré myFirstVariable de type float (décimal à virgule flottante simple précision) comme ci‑dessous :
float myFirstVariable = 13.0;
alors durant l'exécution du programme, la variable aurait aussi été encodée sur 4 octets mais avec une représentation binaire complètement différente (qu'on détaillera au chap. C3‑V ) :
01000001 01010000 00000000 00000000
Réciproquement, si on interprétait cette représentation binaire dans le type int, on obtiendrait la valeur 1095761920 complètement différente de 13.0. On voit donc bien que le type est une caractéristique indispensable pour déterminer sa valeur par interprétation d'une représentation binaire en mémoire.

Les normes des langages C et C++ :
- distinguent fondamentalement la notion de donnée de celle de fonction ; en effet, dans un programme, une fonction possède bien un identificateur, un type et même une adresse mais elle n'a pas de valeur à proprement parler ;
- emploient le terme d'« objet » plutôt que de donnée ; toutefois, il est pédagogiquement préférable de réserver le terme d'objet pour désigner spécifiquement l'instance d'une classe dans le cadre de la programmation orientée objet.
- emploient le terme de « représentation des types » plutôt que d'encodage des données ; toutefois, le terme représentation appartient au vocabulaire général, il est préférable de pouvoir l'employer sans risque de confusion avec un sens technique particulier ; de plus, le mot « encodage » W est plus évocateur de ce que forment les bits d'une donnée, à savoir le résultat produit par un algorithme de numérisation.
Pourquoi déclarer ?
De façon générale, en programmation, les données nommées – et tout particulièrement les variables – sont indispensables pour mettre en œuvre des traitements un tant soit peu complexe.

Par exemple, pensons au calcul d'une moyenne de notes saisies au fur et à mesure sur une simple calculatrice :
- Il faut mémoriser le total provisoire de toutes les notes, qu'on additionne l'une après l'autre ; la calculatrice s'en charge ;
- Mais ensuite, une fois que la saisie est terminée, il faut diviser le total par le nombre de notes qui, lui aussi, doit être mémorisé au fur et à mesure ; pour cela, on peut utiliser une feuille de papier et tracer un baton à chaque note saisie (c'est une forme de mémoire « artisanale »).
Il faut donc au moins deux variables pour mener à bien ce travail. Et si on devait coder un programme informatique pour se faciliter la tâche, il faudrait même une troisième variable pour mémoriser la saisie courante de l'utilisateur.
En règle générale, dans un langage compilé – et c'est le bien cas en C et en C++ – une instruction de déclaration W est un préalable obligatoire pour pouvoir « employer » une donnée nommée constante ou variable dans un fichier source du programme (on exclut ici le cas des pseudo‑constantes mentionné supra ).
En programmation, « employer » une donnée signifie lire ou modifier sa valeur et nécessite pour cela de l'appeler par son nom – on dit aussi l'invoquer.
En effet, c'est grâce aux déclarations que le compilateur peut prévoir l'espace mémoire requis par toutes les données que le programme utilise (on verra au chapitre C4‑II comment cet espace est organisé en sections dans le code exécutable).
Les déclarations constituent également un aspect décisif pour la bonne lisibilité du code source. Pour toute donnée déclarée, on peut se référer à des spécifications précises sur ses caractéristiques : le fait qu'il s'agisse d'une variable ou d'une constante, le type de ses valeurs, sa classe d'allocation, etc.
Considérer une déclaration comme une instruction peut être contesté au regard de la norme du langage C (cf. C où les sections 6.7 Declarations et 6.8 Statements and blocs sont distinctes). Cette distinction est utile pour interpréter l'usage de certains symboles comme par exemple * ou [] qui n'ont l'un comme l'autre pas le même sens dans une déclaration que dans une instruction.
De plus, la déclaration d'une donnée globale est traitée par le compilateur qui réserve un espace mémoire dans le code exécutable du programme, et ne se traduit pas en instructions machine exécutables dans le code. En quelques sortes, une telle déclaration ne déclenche pas d'action lors de l'exécution.
Toutefois, on peut aussi faire les observations suivantes, qui plaident au contraire pour ne pas distinguer fondamentalement les notions de déclaration et d'instruction :
- Si une déclaration est codée dans un bloc avec une classe d'allocation automatique (cf. infra ), alors elle déclenche bien une action lors de l'exécution (la réservation d'un espace mémoire dans la pile – cf. chap. C4‑II ), même si cette action opère en arrière‑plan.
- Par ailleurs, une déclaration obéit à la même forme syntaxique globale que celle qui régit une instruction simple, avec le codage du délimiteur de fin
;.
D'ailleurs, la norme du langage C++ considère les déclarations locales comme des instructions (cf. C++ à la section 9.6 Declaration statement).
En conclusion, on peut « couper la poire en deux » en distinguant les déclarations comme des instructions d'un genre particulier.
Où déclarer ?
Contrairement à autres langages (Delphi, Ada…), dans les programmes écrits en C/C++, depuis la norme C99 incluse, il n'y a pas de zone spécifique du programme ou des fichiers qui est réservée pour coder des déclarations de données. Ces dernières peuvent être réparties partout dans le code source.


Mais une telle liberté peut être perturbante pour un codeur débutant, et par ailleurs, la zone de déclaration d'une donnée n'est pas indifférente : elle impacte notamment la visibilité de la donnée, c'est‑à‑dire le fait qu'on puisse ou non l'utiliser dans telle ou telle partie du code.
- Si la déclaration est codée dans un bloc
{ }, on dit que la donnée est locale au sens où elle est seulement visible : - dans son bloc,
- et seulement pour les instructions qui lui succèdent dans ce bloc.
- A contrario, si une donnée est déclarée hors de tout bloc, on dit qu'elle est globale ; elle est alors visible dans tous les blocs successifs à sa déclaration (dans le fichier).
La zone de déclaration d'une donnée a également un impact sur ce qu'on appelle sa classe d'allocation – aspect qui est introduit infra .
Bonnes pratiques
Même si les déclarations peuvent être codées n'importe où dans le code source, il est recommandé, pour une bonne lisibilité du code, d'adopter les règles générales suivantes :
- regrouper les lignes de déclaration,
- privilégier les premières lignes des fichiers et des blocs.
En principe, cette bonne pratique permet à tout lecteur du code source de faciliter la recherche de la déclaration des données employées dans un programme, notamment pour connaître leur type et leur valeur initiale.
Toutefois, il est également confortable pour la lecture du code que la déclaration d'une donnée soit aussi proche que possible des instructions où elle est utilisée, l'idéal étant qu'il ne soit pas nécessaire de naviguer dans le code pour visualiser l'ensemble.

Dans le framework Arduino, le programme utilisateur consiste en la définition non pas d'une fonction main, mais de deux fonctions, setup et loop, dans cet ordre et réunies dans un même fichier principal d'extension .ino (cf. chap. C2‑I ).
Dans ce contexte, il peut‑être pertinent de déclarer les données globales utilisées seulement dans la fonction loop juste au dessus de celle‑ci, et non pas au début du fichier (en dérogation de la règle générale énoncée supra).
C'est justement ce qui est fait ci‑dessous pour la constante BLINK_HALF_PERIOD (cf. la ligne nº 8), dans un très classique programme de clignotement de la led intégrée à une carte Arduino :
void setup()
{
pinMode(LED_BUILTIN, OUTPUT);
digitalWrite(LED_BUILTIN, LOW);
}
const unsigned BLINK_HALF_PERIOD = 500; // milliseconds
void loop()
{
digitalWrite(LED_BUILTIN, HIGH);
delay(BLINK_HALF_PERIOD);
digitalWrite(LED_BUILTIN, LOW);
delay(BLINK_HALF_PERIOD);
}
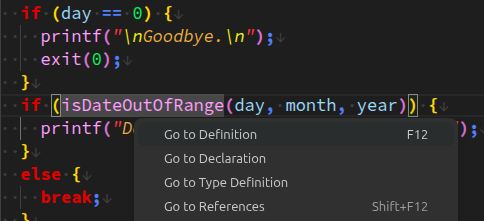
Enfin, il faut ne pas surestimer l'effort nécessaire pour retrouver la déclaration d'une donnée, car la plupart des éditeurs de code modernes offrent des fonctions de recherche automatique de déclaration de déclaration, via des commandes accessibles par menu contextuel (activé par clic‑droit sur toute occurrence d'un identificateur de donnée) et libellées typiquement comme (cf. la capture d'écran ci‑contre) :
Go to declaration…
Ces fonctionnalités se révèlent particulièrement efficaces dans le cadre d'une programmation multi‑fichiers, où l'on perdrait sinon beaucoup de temps à « scroller ».
Quelques subtilités
Le mode opératoire de déclaration d'une donnée présenté ci‑après est général et simplifié. Il n'est valable que pour des données de types élémentaires (cf. chap. C3‑I ). Des formes plus complexes seront détaillées :
D'une manière générale, dans un programme, la création d'une donnée nommée recèle deux aspects :
- la déclaration d'un identificateur pour appeler la donnée, et lui attribuer un type de valeurs possibles (entières, décimales, etc.) ;
- la définition d'un espace mémoire adressable qui sera alloué pour le stockage de la valeur de la donnée.
En langages C et C++, la distinction de ces deux aspects est importante. En effet, l'allocation mémoire peut intervenir :
- soit lors de la compilation du programme – et on parle alors de données de classe statique ;
- soit lors de l'exécution du programme – avec deux cas de figure :
- celui des données dites de classe automatique si l'espace mémoire qui leur est alloué est de taille fixe ;
- celui des données dites dynamiques si l'espace mémoire qui leur est alloué est de taille variable ;
sachant que :
- une variable globale est toujours de classe statique ;
- une variable locale est par défaut de classe automatique.
Les notions de classes d'allocation statique et automatique seront approfondies au chapitre C4‑II .
La notion de variable dynamique est abordée seulement dans la partie C6 du cours. C'est dans ce dernier cas qu'intervient la distinction entre déclaration et définition.
Syntaxes de déclaration des données de type élémentaire
Déclaration d'une variable
En langage C, une instruction de déclaration d'une variable de type élémentaire obéit à la forme syntaxique simplifiée suivant :
descripteur de type
identificateur
= expression d'initialisation
;
Rappel (cf. chap. C2‑II ) : ci‑dessus, les crochets gris ne sont pas des éléments du code mais des symboles du métalangage qui délimitent une partie optionnelle de la déclaration.
Dans cette forme syntaxique :
- le descripteur de type est une suite de mots‑clefs ou d'identificateurs de types (eux‑même préalablement déclarés) qui spécifient la catégorie de valeurs que la variable peut prendre ;
- standard dans le langage, notamment :
-
boolpour boolean, qui autorise seulement deux valeurs possibles,falseoutrue; -
intpour integer, c'est‑à‑dire à valeurs entières positives (0,1,2,3…) ou négatives (-1,-2…) – on dit qu'il s'agit d'un type signé parce que ses valeurs peuvent porter un signe ; -
floatpour floating point decimal, c'est‑à‑dire à valeurs décimales comme3.14… - défini par le codeur, avec un identificateur de type déclaré à l'aide d'une instruction commençant par
typedef; - l'identificateur est le nom de la variable choisi par le codeur pour la désigner dans le code source – cf. les règles de choix au chap. C2‑II ;
-
= expression d'initialisationest l'affectation optionnelle d'une valeur initiale (en anglais, initializer) qui doit être codée par : - une expression constante (c'est‑à‑dire composée sans identificateurs de variables, par exemple
5 + 1.0/3– cf. chap. C2‑II ) si la variable est de classe statique (cf. supra ) et que l'on code en langage C ; - une expression évaluable au moment de l'exécution de l'instruction de déclaration (donc, pouvant comporter des identificateurs de variables) dans tout autre cas, c'est‑à‑dire en langage C++ ou si la variable est classe automatique.
unsigned, long, etc. ; - La notion de descripteur de type est commode pour décrire sans trop de complications les formes syntaxiques de déclarations élémentaires, mais ne suffit pas pour aborder les déclarations données de types dérivés comme les pointeurs, les tableaux ou les structures hétérogènes. En toute rigueur, conformément à la norme du langage C (le principe étant le même en C++), on devrait parler de spécificateur de type (cf. par exemple le brouillon de la norme C11 C, section 6.7.2, p. 111).
- En langage C, jusqu'à la norme C17 incluse, il faut une directive
#include <stdbool.h>pour utiliser le typebool. À partir de la norme C23, et en langage C++ quelle que soit sa normel, aucune directive n'est nécessaire car le typeboolest intégré au noyau du langage.
Le code ci‑dessous contient quatre déclarations (lignes nº 5, 6, 11 et 12). Toutes les variables déclarées sont initialisées.
#include <stdio.h>
#include <stdbool.h>
// global variables (static)
bool isUserRegistred = true;
unsigned int pointAccount = 10 + 50; // init + bonus
int main(void)
{
// local variables (automatic)
float inflationRate = 0.07;
int nextPointAccount = pointAccount * (1 + inflationRate);
// ...
}
L'étude des types sera approfondie dans toute la partie C3 du module.
Déclaration d'une constante
On rappelle qu'une constante est une donnée qui, en principe, a vocation ne pas changer de valeur durant toute l'exécution du programme, qu'elle qu'en soit le scénario.

Déclarer une constante est un acte volontaire du codeur pour se prémunir d'éventuelles erreurs de codage par lui‑même ou un autre membre de son équipe. Une telle démarche prend tout son sens avec des données immuables ou considérées comme telles dans le cadre du projet de programmation, notamment :

- des constantes physiques : vitesse de la lumière W, charge élémentaire W nombre d'Avogadro W, etc.
- des paramètres dimensionnels du système : volume d'une cuve, longueur d'un axe, nombre de cylindres, etc.
- des valeurs limites de conception du système : nombre maximal d'utilisateurs, temps maximal d'attente, etc.
Pour déclarer une constante de type élémentaire, on emploie la forme syntaxique simplifiée suivante :
const
descripteur de type
identificateur
= expression d'initialisation
;
ou encore :
descripteur de type const
identificateur
= expression d'initialisation
;
avec les mêmes précisions que pour la déclaration d'une variable (cf. supra ), sauf que :
- par convention, on code l'identificateur entièrement en MAJUSCULES (cf. chap. C2‑X ) ;
- l'affectation
= expression d'initialisationn'est pas optionnelle mais au contraire requise, - la valeur résultant de l'évaluation de cette expression et affectée à la constante déclarée n'est pas seulement initiale, mais aussi définitive.
L'élément de code déterminant ici est le mot‑clef qualificateur const. Syntaxiquement, il fait partie du descripteur de type de la donnée et peut prendre plusieurs positions, dans certains cas (pointeurs), ne sont pas toujours indifférentes. Dans certaines déclarations complexes, il peut même présenter plusieurs occurrences, chacune ayant un sens différent ‑ cf. chap. C5‑I .
Dès lors qu'on a déclaré une donnée constante, quelle que soit sa position dans le code, le compilateur déclenchera une une erreur ou un avertissement si, plus loin dans le code source, il détecte respectivement une affectation directe ou indirecte sur la constante.
Ne pas tenir compte d'un tel avertissement est évidemment une très mauvaise idée :
- Si on a affaire à une constante globale ou statique, l'exécution sur une machine à système d'exploitation conduira typiquement à une erreur de segmentation dans la mesure où l'on aura essayé d'écrire dans le segment
rodatade la mémoire où est stockéA, alors que ce segment est en lecture seule (le préfixe «ro» signifie read only — cf. chap. C4‑II ). - Si on a affaire à une constante locale, alors aucune erreur d'exécution ne se produira spécifiquement, mais en revanche, on aura une modification de la constante puisque le système n'a aucun moyen d'interdire l'écriture de données dans la pile. C'est un scénario encore pire que le précédent puisque le programme poursuivra insidieusement son exécution alors qu'il ne se comporte pas comme prévu.
- Commençons par une exemple purement académique avec le programme ci‑dessous s'exécutant sur un ordinateur, dont le fichier source est stocké dans un fichier source nommé
testConst.c, dans lequel l'on a volontairement codé à la ligne nº 7 une affectation directe sur une constante déclarée globaleA: - Si l'exécutable est produit par
gcc, on obtient : - En revanche, si l'exécutable est produit par
g++, on obtient : - Voyons maintenant un exemple normal d'emploi de constantes déclarées dans un très classique programme de clignotement d'une led externe reliée au port numérique d'un carte Arduino.
- D'une part, cela améliore grandement la lisibilité des expressions qui invoquent cette donnée. En effet, la ligne :
- D'autre part, l'emploi d'une constante nommée améliore la robustesse du code à d'éventuelles modifications. Imaginons par exemple qu'on décide finalement de relier la led à la broche 2 du port numérique de la carte. Ici, il suffit juste de modifier la valeur d'initialisation de la constante dans la ligne de sa déclaration :
#include <stdio.h>
const int A = 3;
int main(void)
{
A = 5;
printf("A = %d\n", A);
return 0;
}

gcc testConst.c -o testConsttestConst.c: In function ‘main’: testConst.c:7:5: error: assignment of read-only variable ‘A’ 7 | A = 5; | ^
&, en argument de la fonction scanf (autrement dit, on demande à l'utilisateur de saisir une valeur qui sera mémorisée à l'adresse de A). Alors, même sans aucune option particulière d'avertissement (cf. chap. C1‑II ), avec une version récente, le compilateur de gcc émet avertissement (idem avec g++) : gcc testConst.c -o testConsttestConst.c: In function ‘main’: testConst.c:7:3: warning: writing into constant object (argument 2) [-Wformat=] 7 | scanf("%d", &A); | ^~~~~
gcc ou g++ employée auparavant, l'exécutable déclenche comme prévu une erreur de segmentation juste après la saisie de l'utilisateur : ./testConst5 Segmentation fault (core dumped)
A soit locale dans la fonction main (cf. la ligne nº 5 ci‑dessous) :
#include <stdio.h>
int main(void)
{
const int A = 3;
scanf("%d", &A);
printf("A = %d\n", A);
return 0;
}
gcc ou g++ émettent l'une comme l'autre le même type d'avertissement : gcc testConst.c -o testConsttestConst.c: In function ‘main’: testConst.c:6:3: warning: writing into constant object (argument 2) [-Wformat=] 6 | scanf("%d", &A); | ^~~~~
0. Toutefois, on observe un comportement différent selon le langage C ou C++ :
./testConst
5
A = 5
echo $?
0
A a bel et bien été modifiée par la saisie de l'utilisateur !
./testConst
5
A = 3
echo $?
0
A n'est pas modifiée ! 
const int LED_PIN = 5;
void setup()
{
pinMode(LED_PIN, OUTPUT);
digitalWrite(LED_PIN, LOW);
}
const unsigned BLINK_HALF_PERIOD = 500; // milliseconds
void loop()
{
digitalWrite(LED_PIN, HIGH);
delay(BLINK_HALF_PERIOD);
digitalWrite(LED_PIN, LOW);
delay(BLINK_HALF_PERIOD);
}
LED_PIN plutôt que la constante littérale 5 correspondant à sa valeur (cf. la ligne nº 1 ci‑dessus) présente deux avantages significatifs : digitalWrite(LED_PIN, HIGH)
digitalWrite(5, HIGH)
const int LED_PIN = 2;
5 est utilisé pour autre chose : const unsigned BLINK_HALF_PERIOD = 500; // milliseconds
En langage C, le compilateur autorise quand même – et sans avertissement – à déclarer une constante sans lui affecter une valeur. En effet, s'il est interdit par la suite de coder directement une affectation sur cette une constante, il reste la possibilité de lui affecter une valeur via un pointeur (cf. chap. C5‑I ) au moment de l'exécution du programme.
Une telle pratique est évidemment particulièrement déconseillée à un codeur peu expérimenté. D'ailleurs, elle est interdite en C++.
Bonne pratique avec les constantes
À la lumière des exemples précédents, on peut énoncer cette règle générale, sur laquelle on n'insistera jamais assez auprès d'un public de codeurs débutants.
Pour une meilleure lisibilité du code et aussi une robustesse aux erreurs de codage, il est recommandé de remplacer autant que possible les constantes littérales numériques (c'est‑à‑dire les valeurs codées directement sous forme de nombres) par des constantes déclarées (ou des pseudo-constantes – cf. chap. C4‑III ).
Cette recommandation devient une règle absolue dès lors qu'une constante littérale est employée à plusieurs reprises dans un programme pour exprimer la valeur d'un seul et même paramètre.
Faute d'appliquer cette règle, si la valeur venait à faire l'objet de modifications au cours de l'élaboration ou de la maintenance du programme, il y aurait un risque d'oublier certaines occurrences de la constante littérale dans le programme, avec les conséquences que cette mégarde pourrait avoir en termes de dysfonctionnements immédiats ou ultérieurs.
Déclarer une constante nommée pour représenter une valeur numérique permet de ne saisir cette valeur qu'une seule fois dans le code, lors de la déclaration. Toute modification de cette dernière se répercute alors automatiquement lors de la compilation à chaque occurrence de l'identificateur de la constante dans le code.
De plus, déclarer une constante nommée permet de l'identifier comme un paramètre du programme que l'on peut placer au tout début d'un fichier source pour maximiser sa lisibilité. Le codeur peut alors très facilement la trouver pour la modifier sans avoir à chercher les lignes de code où elle est employée. Cette règle vaut même si la constante n'est employée qu'une seule fois.
Reprenons un exemple académique du chapitre C2‑II :
if (userAge >= 18) {
Même si la constante littérale 18 n'apparaît qu'une seule fois dans le programme, il est quand même préférable de coder préalablement en début de fichier la déclaration :
const int LEGAL_AGE = 18;
pour pouvoir recoder mieux la ligne n° 10 supra comme ci‑dessous :
if (userAge >= LEGAL_AGE) {
En effet, ce paramètre d'âge peut changer selon l'époque, le pays ou même le contexte. En le définissant comme une donnée déclarée, il sera plus commode par la suite de modifier sa valeur d'initialisation, typiquement via une variable d'environnement.
Déclaration séquentielle de données
La syntaxe des langages C et C++ autorise, par le même descripteur de type, à coder plusieurs déclarations (et initialisations éventuellement associées) dans une même instruction.
Pour séparer deux déclarations successives, il suffit simplement d'employer le symbole , (qui n'est pas l'opérateur séquentiel présenté au chap. C2‑II ).
Dans le code académique ci‑dessous, trois variables a, b c de type int sont déclarées :
int a, b = 3, c = 10;
On peut remarquer que la variable a ne fait pas l'objet d'une initialisation, ce qui est autorisé par la syntaxe, même si ce n'est en général pas une bonne pratique (ici, c'est juste fait pour l'exemple).
Bonne pratique
Une déclaration séquentielle n'apporte un gain éventuel en lisibilité :
- qu'avec des données semblables (dans ce qu'elles représentent),
- et si on leur attribue des identificateurs courts.
Sinon, la ligne de code devient vite trop longue et la déclaration de chaque donnée peut y être difficile à repérer. De plus, regrouper dans une même ligne la déclaration de plusieurs données qui n'ont rien de commun hormis leur type peut prêter à confusion : un lecteur du code pourrait se mettre à penser que les deux données sont liées…
Sauf cas particuliers, il est donc recommandé de respecter la principe :
« une donnée, une instruction de déclaration (sur une ligne distincte). »
Détails sur l'initialisation des données
Cas des variables non initialisées
Dans le cas d'une variable non initialisée dans sa déclaration, quelle valeur par défaut lui est‑elle attribuée par le compilateur ? Selon la norme (C11, §6.7.9 10, cf. C p. 140) :
- si la variable est de classe statique (donc en particulier, si elle est globale), elle prend la valeur nulle ;
- si la variable est de classe automatique (a priori si elle est locale), elle prend une valeur indéterminée (en fait, typiquement déterminée par les anciennes valeurs des bits de l'espace mémoire qui lui est alloué).
Autant que possible, il est préférable d'initialiser toute variable dès sa déclaration, même si la valeur attribuée peut sembler n'avoir aucun sens.
Cela permet ensuite de tester cette variable en toutes circonstances.
On peut être amené à déclarer une variable sans lui affecter une valeur initiale, lorsque cette variable est destinée à recevoir des valeurs non prévisibles lors du codage du programme, typiquement si elle sera saisie par un utilisateur durant l'exécution :
#include <stdio.h>
int main(void)
{
int patientAge; // uninitialized variable
printf("How old the patient is? ");
scanf("%d", &patientAge);
// ...
}
Pourtant, il est préférable de coder la déclaration :
int patientAge = -1;
La valeur a priori « absurde » -1 permet de coder ensuite dans le programme des tests pour savoir si la saisie n'a pas encore eu lieu (ou si elle a éventuellement échoué).
Initialisation des données en langage C++
La syntaxe de la déclaration des données du langage C reste valable en langage C++.
De surcroît, en C++, l'expression d'initialisation dans la déclaration d'une donnée n'est jamais soumise à la contrainte d'être une expression constante (cf. chap. C2‑II ). Partout dans un programme – donc, même pour la déclaration d'une donnée globale – il est possible de recourir à des identificateurs de variables, à condition bien sûr qu'elles soient déjà déclarées pour coder cette expression d'initialisation.
Plus précisément, la possibilité évoquée ci‑dessus est valable quelle que soit la classe d'allocation statique ou automatique de la donnée que l'on déclare (et non pas, comme en langage C, seulement pour la classe automatique – cf. supra ).
Le code des deux déclarations de variables globales ci‑dessous est compilable en langage C++ :
float nominalVoltage = 12.0; float startingVoltage = nominalVoltage/2.0;
En langage C, la ligne n° 6 serait refusée lors de la compilation car l'expression d'initialisation nominalVoltage/2.0 n'est pas une expression constante : elle utilise l'identificateur de variable nominalVoltage.
Remarque : si l'on permutait l'ordre de ces deux déclaration, ce code ne serait plus compilable même en C++, car l'identificateur nominalVoltage ne serait pas défini au moment de l'évaluation de l'expression d'initialisation de la variable startingVoltage.
Syntaxes alternatives d'initialisation en C++
Pour l'initialisation des données (variables ou constantes), il existe des syntaxes alternatives propres au langage C++. D'un point de vue purement syntaxique, dans le codage d'une initialisation :
= expression d'initialisation
le symbole d'affectation = devient facultatif si l'expression d'initialisation est encapsulée dans des parenthèses () ou des accolades {} (les accolades étant indispensables dans le cas des variables structurées – cf. chap. C2‑VI ).
Lorsqu'on code l'initialisation d'une donnée sans le symbole = :
- On parle de initialisation directe si on emploie les parenthèses :
( expression d'initialisation)
Cette syntaxe correspond d'une manière générale à l'instanciation d'un objet d'une classe via le constructeur par défaut implicitement conçu par le compilateur pour chaque type de données déclarées (cf. chap. C2‑VI ) - On parle de initialisation uniforme si on emploie les accolades :
{ expression d'initialisation}
Cette syntaxe a été introduite à partir de la norme C++11 pour pallier ce qu'on appelle le « most vexing parse » W, c'est‑à‑dire une confusion possible entre une déclaration de fonction et une instanciation d'objet codée avec la syntaxe des parenthèses.
Par opposition, toute forme syntaxique d'initialisation qui comporte le symbole = est ce qu'on appelle une initialisation par copie.
Les deux déclarations avec initialisation sont codées ci‑dessous sans symbole =.
- Initialisation directe :
float nominalVoltage (12.0);
float nominalVoltage {12.0};
Équivalentes, elles sont compilables en langage C++ alors qu'elles ne le sont pas pas en langage C.
En revanche, les deux déclarations ci‑dessous codées avec le symbole = sont des initialisations par copie, même avec l'emploi d'accolades ou de parenthèses qui sont ici facultatives et n'apportent rien.
float nominalVoltage = {12.0};
float nominalVoltage = (12.0);
Ces déclarations sont compilables en C comme en C++.
En langage C++, dans la déclaration des données, la syntaxe alternative d'initialisation uniforme est recommandée.
Dans la pratique, c'est néanmoins la syntaxe d'initialisation directe qui le plus souvent utilisée, en particulier pour l'instanciation des objets.
En effet, les différentes syntaxes d'initialisation des données du C++ ne sont pas équivalentes. Si on ne code pas de symbole d'affectation = dans l'instruction, alors :
- au moment de l'initialisation de la donnée, le compilateur n'effectue aucune conversion implicite par ajustement ou dégradation de type (cela permet de prévenir toute perte d'information – cf. chap. C3‑VI ) ;
- en cas d'incompatibilité de types entre la donnée déclarée et son expression d'initialisation, l'échec de la compilation permet de détecter une erreur de codage dont résulterait la nécessité de recourir à une conversion implicite.
La déclaration codée ci‑dessous avec une initialisation uniforme, et qui comporte volontairement une incohérence de typage :
int nominalVoltage {12.0}; // Error of types! Build not possible.
n'est pas compilable en C++ – et c'est heureux !
En effet, le compilateur refuse d'ajuster une valeur 12.0 de type décimal dans une donnée déclarée de type entier (même si, dans le cas présent, il y aurait priori une perte d'information puisque la partie décimale de la valeur 12.0 à affecter est nulle).
A contrario, la même déclaration ci‑dessous, mais codée avec une initialisation par copie, et qui est encore plus incohérente que la précédente :
int nominalVoltage = 12.5; // Error of types, but build is possible!!
est malheureusement compilable en C++, tout comme en C – et ce sans le moindre avertissement, même avec les options de compilation -Wall -Wextra – alors qu'elle engendre une perte d'information : la variable nominalVoltage est initialisée avec la valeur 12 et non pas 12.5 !
On voit donc tout l'intérêt des syntaxes alternative d'initialisation sans symbole d'affectation.
Typage automatique des données initialisées
En langage C++ norme C++11, il est possible de laisser le compilateur procéder à l'attribution automatique d'un type élémentaire à une donnée lors de sa déclaration, si cette donnée est initialisée.
Il suffit pour cela d'employer dans la déclaration le mot‑clef auto à la place du descripteur de type souhaité. C'est alors le type d'évaluation de l'expression d'initialisation, conformément aux règles usuelles (cf. chap. C3‑I ) qui détermine l'attribution du type à la donnée.
Sans se soucier des questions de taille des types, on peut coder comme ci‑dessous en langage C++ les déclaration à typage automatique suivantes :
auto voltage {230.0};
auto userAge {50};
auto typedChar {'\0'};
Respectivement, ces données seront compilées implicitement dans les types double, int, et char.
- Commode, l'emploi du mot‑clef
auton'est pas forcément judicieux lorsque la machine cible dispose d'une mémoire limitée, notamment s'il s'agit d'une carte à microcontrôleur Arduino Uno ou Nano. En effet, les choix par défaut du compilateur (int,double…) sont souvent surdimensionnés au regard de l'étendue des valeurs effectivement prises par les données au cours de l'exécution du programme. - Attention ! Le mot‑clef
autoa une toute autre interprétation en langage C, ainsi qu'en C++ avant la norme C++11 : il sert à spécifier la classe d'allocation automatique pour une donnée (cf. chap C4‑II .)