
Rappelons tout d'abord qu'intuitivement, un nombre décimal est un nombre qui peut s'écrire sous la forme d'une partie entière et d'une partie décimale finies, l'une et l'autre séparées par une « virgule » – ou un point dans l'usage anglo‑saxon. De plus, pour écrire les nombres très petits ou très grands, on emploie la notation scientifique avec des puissances de 10 (cf. les exemples ci‑contre, issus du domaine de la physique, de la charge électrique élémentaire notée e W et du nombre d'Avogadro NA W).

A contrario, un nombre rationnel ou irrationnels ne peuvent pas s'écrire sous une telle forme, car leur partie décimale nécessiterait une infinité de chiffres. On doit donc se contenter d'approximations (cf. les exemples ci‑contre du nombre π W et de son approximation rationnelle 22/7).
Comme tous les langages de programmation généralistes, C et C++ disposent de types élémentaires de données pour représenter les nombres décimaux. Ces types de données sont dits à « virgule » flottante – en anglais, floating‑point – parce qu'ils sont encodés dans un format où la virgule est déplacée par multiplication ou division et compensée par un facteur exponentiel (comme en notation scientifique où l'on écrit 1,5 × 10−2 plutôt que 0,015).
Les trois types standards à virgule flottante des langages C et C++ sont codés float (déjà évoqué aux chapitres C2‑III et C3‑I ), double et long double. Ils sont conformes à la norme américain ANSI/IEEE 754‑1985, laquelle est approuvée et référencée par la norme internationale IEC sous la référence 60559:1989.
Bien entendu, les types flottants standards présentent des caractéristiques différentes les autres des autres, à la fois en termes d'étendue et la précision des valeurs qu'ils peuvent encoder, en contre‑partie de la taille de la mémoire requise pour cela. Le choix d'un type ne doit donc pas être négligé.
Dans le cadre d'une formation à la programmation, l'acquisition d'une bonne connaissance des types flottants est indispensable. Avec une approche similaire à celle du chapitre C2‑II consacré aux types entiers, le présent chapitre a pour objectif :
- de rappeler les notions mathématiques de nombre décimal et de nombre réel, et le principe de la notation scientifique des nombres ;
- de présenter les types flottants standards, en détaillant leurs caractéristiques (taille, étendue, etc.) ;
- de donner la syntaxe de codage des constantes littérale décimales ;
- d'expliquer le format d'encodage des données décimales dans les types flottants standards – signe, exposant décalé et significande – y compris pour les valeurs dites dénormalisées et les valeurs spéciales « infinis » et NAN, c'est‑à‑dire not a number ;
- d'exposer les particularités et précautions d'emploi des opérateurs et des fonctions sur les valeurs de types flottants, avec notamment les problématiques de débordements et d'opérations non définies.
Même si ce chapitre peut sembler étoffé, il faut avoir conscience qu'il ne s'agit que d'une introduction pour permettre au codeur débutant d'employer à bon escient les types flottants. En réalité, il s'agit d'un thème très complexe et d'une importance capitale. Sur l'encodage des nombres flottants repose la qualité des calculs effectués dans tous les logiciels scientifiques et techniques, et ce quel que soit le langage de programmation adopté !
Dans une perspective d'approfondissement des connaissances, on pourra consulter l'article de Wikipedia en français W puis en anglais W comme point de départ, en exploitant tous les liens vers des publications de référence que l'on peut trouver dans ces pages web.
Rappels de mathématiques
Notion de nombre décimal
Un nombre décimal W est un nombre formé d'une partie entière et d'une partie décimale, chacune constituée d'un nombre fini de chiffres et éventuellement nulle (ce qui inclut donc les nombres entiers). Mathématiquement, il peut s'écrire de la forme a/10n où
On appelle décimales les chiffres de sa partie décimale.

Les nombres décimaux sont typiquement ceux que l'on peut saisir sur une calculatrice. Mais ils ne se réduisent pas à cela car en théorie, il existe une infinité de nombre décimaux – cette infinité restant dénombrable. En effet, si on fixe des limites d'étendue (donc, le nombre de chiffres de la partie entière) et de précision (donc, le nombre de décimales), leur encodage exhaustif est théoriquement possible.
Toutefois, prenons dores et déjà conscience que ce n'est pas la stratégie adoptée par les formats à virgule flottante (même dans les calculatrices).
Il y a 20 001 nombres à deux décimales compris entre −100,00 et +100,00 (bornes incluses) – sachant qu'il ne faut pas oublier le nombre 0.
On comprend donc qu'il n'est pas réaliste avec cette stratégie d'espérer encoder à la fois des nombres avec beaucoup de décimales et une grande partie entière.
Notion de nombre réel
Un nombre réel W qui n'est pas décimal possède une partie décimale constituée d'un nombre infini de chiffres.
Un nombre est dit rationnel s'il est définissable par une fraction de deux nombres entiers, sinon il est dit irrationnel.
Aucun format ne permet d'encoder sans erreur la valeur réelle d'un nombre irrationnel, ou même d'un nombre rationnel non décimal (comme la fraction 1/3). Dans les programmes, on doit toujours se contenter d'approximations décimales pour représenter ces nombres.
De plus, il existe une infinité indénombrable de nombres réels, mais il est difficile de conceptualiser cette indénombrabilité. Une manière de l'approcher est donnée par l'argument de la diagonale de Cantor W dont on trouvera une explication très pédagogique dans la vidéo au lien suivant .
Et il faut avoir conscience que, quelles que soient deux bornes a et b (avec a < b), il existe autant de réels dans l'intervalle [a, b] que dans l'ensemble ℝ de tous les nombres réels. (Cette propriété est aussi vraie pour l'ensemble ℚ des nombres rationnels.)
Les approximations décimales ci‑dessous :
- 1/3 ≃ 0,33333333333… (nombre rationnel)
- 1/7 ≃ 0,14285714286… (nombre rationnel)
- √2 ≃ 1,41421356237… (nombre irrationnel)
- π ≃ 3,14159265359… (nombre irrationnel)
sont données avec 12 chiffres significatifs (exacts) en comptant la partie entière.
Certaines expressions calculatoires peuvent former des valeurs qui n'appartiennent pas à ℝ :
- √−1 est un nombre complexe,
- 1/0 est un « nombre » infini,
- 0/0 est non défini (ce n'est pas un nombre)…
De telles expressions peuvent intervenir en programmation, aussi est‑il nécessaire que leurs valeurs puissent être gérées.
Principe de la notation scientifique des nombres
La notation scientifique W d'un nombre décimal est son écriture en base 10 de la forme :
±m × 10n
où m est un nombre décimal appelée mantisse et n est un nombre entier appelé l'exposant.
De plus, la notation scientifique impose :
- que la partie entière de la mantisse soit réduite à un seul chiffre, obligatoirement non nul ; c'est le chiffre le plus significatif du nombre ;
- que la partie décimale de la mantisse comporte autant de décimales que nécessaire (mais éventuellement aucune) pour représenter le nombre ; la dernière décimale (la plus à droite) doit être non nulle, c'est le chiffre le moins significatif du nombre ;
- l'exposant est un nombre entier, éventuellement nul ou négatif ; le facteur exponentiel 10n donne l'ordre de grandeur du nombre.
En notation scientifique :
- 0,357 s'écrit 3,57 × 10−1 ;
- −65 536 s'écrit −6,5536 × 104 ;
- 5 000 000 s'écrit 5 × 106.
Variété des types à virgule flottante
Principe des types à virgule flottante
Un type dit à virgule flottante W – ou tout simplement flottant – est un type élémentaire de données numériques décimales. Son format binaire, détaillé infra , permet :
- d'encoder aussi bien les nombres négatifs que positifs ;
- pour chaque nombre, de répartir au mieux les chiffres de sa partie entière et sa partie décimale en fonction de sa valeur, grâce à un facteur exponentiel.
De façon générique pour tout type flottant, on peut schématiser comme ci‑dessous, sur l'axe des nombres réels (l'ensemble ℝ), les intervalles des valeurs encodables. Ces intervalles sont symétriques par rapport à l'origine de l'axe (le point d'abscisse ±0). Sont surlignés :
- en vert foncé, les intervalles des valeurs dites normalisées (normal number W) ;
- en vert clair, les intervalles des valeurs dites dénormalisées (denormal values, anciennement appelées subnormal number W), qui sont très petites en valeur absolue.

Un type à virgule flottante peut donc encoder, en valeurs absolues, aussi bien :
- de très grands nombres – par exemple, jusqu'à 1038 pour le type
float; - de très petits nombres – par exemple, jusqu'à 10−45 pour le type
float.
En contre‑partie de cette optimisation de l'étendue des valeurs encodables, un type flottant n'offre qu'une précision relative au regard de la valeur des nombres. Sur la figure ci‑dessus, il faut imaginer que les intervalles surlignés en couleur sont en fait « pleins de trous ». Les milliards de valeurs effectivement encodable dans un type flottant ne représentent qu'une infime minorité au regard de l'innombrabilité des réels.
Dans le type float dit à « simple précision » :
- le nombre 11 111 111 111 111 111 (≃ 1,11 × 1016) est encodé comme
11111111533264896, donc : - son erreur absolue d'encodage est d'environ 4,22 × 108,
- mais elle correspond à une erreur relative d'environ 3,8 × 10−8.
- le nombre 0,01 est encodé comme
0.009999999776, donc : - son erreur absolue d'encodage est d'environ 2,24 × 10−10,
- mais elle correspond à une erreur relative d'environ 2,24 × 10−8.
Dans les deux cas, l'erreur relative est de l'ordre de 10−8, soit 0,000001 %.
Erreur relative d'encodage
Les exemples ci‑dessus montrent que, dans un type flottant donné, l'erreur relative d'encodage garde un ordre de grandeur constant sur toute l'étendue des valeurs normalisées, même si cette erreur relative varie quand même un peu d'un nombre à l'autre.
Remarque. L'erreur d'encodage peut parfois être nulle : en effet, les nombres qui sont égaux à une somme finie de puissances croissantes de 2 (éventuellement d'exposant négatif) sont encodables sans erreur.
Dans le type float, dit à « simple précision » :
- le nombre 0,03125 est encodé sans erreur parce qu'il est une puissance de 2 (il vaut exactement 2−5) ;
- le nombre 1 073 741 824 est encodé sans erreur parce qu'il est une puissance de 2 (il vaut exactement 230) ;
mais ce sont en quelques sortes des exceptions, puisque dans le cas du premier nombre, ses « voisins » 0,03124 et 0,03126 (entre autres) se sont pas encodables sans erreur.
En définitive, on peut caractériser la précision d'encodage d'un type flottant par la valeur maximale de l'erreur relative d'encodage pour toutes les valeurs normalisées encodées dans ce type.
Notion de chiffres significatifs
En complément de l'erreur relative d'encodage, on définit la précision d'encodage d'un type flottant comme le nombre de chiffres significatifs (en notation scientifique) successivement exacts que l'encodage garantit comme identiques après encodage/décodage d'une valeur, et avec arrondi au dernier chiffre significatif le plus proche.
Cette notion fait référence à celle de précision arithmétique d'une valeur numérique, employée en mathématiques W.
L'erreur d'encodage commence donc à s'exprimer à partir du chiffre (éventuellement décimal) écrit à droite juste après le dernier chiffre (le moins) significatif.
Le type float admet une précision de 8 chiffres significatifs exacts pour la plupart des valeurs, mais qui peut fluctuer entre 7 et 9 chiffres significatifs. En reprenant les exemples donnés supra :
- le nombre 11 111 111 111 111 111 est encodé avec 8 chiffres significatifs (comme
11111111533264896) ; - le nombre 0,01 est encodé aussi avec 8 chiffres significatifs (comme
0.009999999776, soit0.010000000après arrondi au 8e chiffre significatif le plus proche).
Dans les deux cas, l'erreur d'encodage commence à s'exprimer à partir de la 8 e décimale de la mantisse en notation scientifique.
Classification des types à virgule flottante
En langages C et C++, il existe trois types standards à virgule flottante, usuellement désignés respectivement par :
-
float(simple précision), -
double(double précision) , -
long double(double précision étendue) W.
Ces trois types diffèrent les uns des autres par la taille en mémoire et donc aussi par la précision et l'étendue des intervalles de valeurs encodables.
Mais comme pour les types entiers standards, l'implémentation joue un rôle crucial. Pour une machine de type PC à architecture 64 bits avec une chaîne de compilation adaptée (GCC ou Mingw-w64), les caractéristiques essentielles sont détaillées dans le tableau ci‑dessous :
| PC 64 bits | taille | TRUE_MIN |
MIN |
MAX |
erreur relative maximale |
chiffres significatifs |
|---|---|---|---|---|---|---|
float |
4 | ≃ 1,4 × 10−45 | ≃ 1,1 × 10−38 | ≃ 3,4 × 1038 | ≃ 6,0 × 10−8 | 7 à 9 |
double |
8 | ≃ 4,9 × 10−324 | ≃ 2,2 × 10−308 | ≃ 1,7 × 10308 | ≃ 1,1 × 10−16 | 15 à 17 |
long double |
12/16 | ≃ 3,6 × 10−4951 | ≃ 3,3 × 10−4932 | ≃ 1,1 × 104932 | ≃ 5,4 × 10−20 | 19 à 21 |
sachant que dans le cas du type long double, seuls 12 des 16 bits sont réellement exploités pour le codage (la taille est implémentée comme un multiple de celle de l'architecture).
En revanche, sur des cartes à microcontrôleur, les types double et long double peuvent être réduits. Ainsi :
- sur les cartes à cœur 8 bits (Arduino Uno, Nano, Mega…) , ces deux types sont encodés sur 4 octets seulement ; ils sont donc équivalents au type
floatet n'apportent aucune précision supplémentaire (mais réciproquement, aucun surcoût en termes de temps de calcul) ; - sur les cartes à cœur 32 bits (Arduino Due, Zero, ESP8266), ces deux types sont l'un et l'autre encodés sur 8 octets ; autrement dit :
- le type
doubleapporte bien une double précision par rapport au typefloat, mais au prix de temps de calcul doublés puisqu'il fait deux fois la taille de l'architecture ; - le type
long doublen'apporte aucune précision supplémentaire (mais son emploi serait « indolore » en termes de temps de calculs) par rapport au type double.
- Les normes des langages C et C++ ne sont pas plus exigeantes avec le type
long doublequ'avec le typedouble. Elles n'imposent que deux types flottants standards effectivement différents – respectivement à simple et double précision – et laissent aux implémentations la liberté de fournir au codeur un troisième type flottant ayant réellement une double précision étendue. - En général sur les PC, le type
long doublen'exploite réellement que 80 bits, donc moins que la totalité des bits que lui confère sa taille (96 bits pour 12 octets, 128 bits pour 16 octets), laquelle est déterminée au regard des contraintes d'alignement de l'architecture machine (cf. chap. C3‑I ). - Il existe aussi trois autres types flottants désignés respectivement
_decimal32W,_decimal64W et_decimal128W. Ils diffèrent des types flottants standards à plusieurs titres : - ils sont à taille fixe, quelle que soit l'implémentation ;
- leur format binaire permet d'encoder sans erreur toutes les constantes littérales fractionnaires codées en base 10 avec un nombre restreint de décimales (mais en contre‑partie, pas les valeurs qui sont des sommes de puissances de 2).
Caractéristiques des types flottants sur une machine cible
À l'instar de ce qui est fait pour les types entiers (cf. chap. C3‑II ), la bibliothèque standard du langage C fournit dans un fichier d'en‑tête nommé float.h (cfloat pour le C++) les caractéristiques des types flottants, notamment leurs valeurs limites d'encodage.
Ces caractéristiques sont données sous forme de pseudo‑constantes qui prennent chacune une valeur spécifique lors de la compilation selon l'implémentation (machine cible et chaîne de compilation). Ces pseudo‑constantes sont désignées par des identificateurs en majuscules qui (à une exception près) comporte un préfixe de type. En règle général, ce préfixe est de la forme :
-
FLTpour les pseudo‑constantes qui caractérisent le typefloat; -
DBLpour les pseudo‑constantes qui caractérisent le typedouble; -
LDBLpour les pseudo‑constantes qui caractérisent le typelong double.
Le tableau ci‑dessous liste quelques unes de ces pseudo‑constantes, dont on trouvera la liste exhaustive sur une page de référence comme C :
| Identificateur | Caractéristique exprimée |
|---|---|
type_MAX |
plus grande valeur normalisée encodable |
type_MIN |
plus petite valeur normalisée encodable |
type_TRUE_MIN |
plus petite valeur dénormalisée encodable |
type_EPSILON |
écart absolu entre la valeur codée 1.0 et la plus proche valeur encodable – donc, le double de l'erreur relative maximale – dite pseudo‑constante de résolution |
type_DECIMAL_DIG |
nombre de chiffres significatifs inchangés par encodage/décodage d'une valeur |
- Certaines pseudo‑constantes ne sont pas définies dans les anciennes implémentations des langages. C'est notamment le cas des
type_TRUE_MINqui ont été introduites seulement à partir des normes C11 et C++17. - Certaines pseudo‑constantes sont préfixées par
FLTmais ne sont pas spécifiques au typefloat. C'est notamment le cas de :
Syntaxe de codage des valeurs décimales
Codage d'une constante littérale décimale
Dans un programme en langage C ou C++, un peu comme sur une calculatrice scientifique, on code une constante littérale décimale par la syntaxe générale suivante, sans aucun espace (ni saut de ligne) :
±x.y
e±n
Dans cette forme syntaxique, x, y et n sont trois séquences de chiffres (0 à 9) tels que :
- la séquence
x.yforme la mantisse, qui est elle-même constituée de : - sa partie entière
x; - sa partie décimale
.y; - la séquence
nest l'exposant et la séquencee±n
Particularités syntaxiques
Le séparateur d'exposant e est insensible à la casse : il peut aussi se coder E.
Par ailleurs, plusieurs éléments de la syntaxe peuvent être facultatifs :
- tout zéro non significatif, c'est‑à‑dire ;
- à gauche dans les séquences
xoun; - à droite dans la séquence
y; - le signe
+de la mantissex.y, comme celui de l'exposantn; - la partie décimale si la séquence
yest nulle et si le facteur exponentiel est codé ; - le facteur exponentiel si la séquence
nest nulle et si la partie décimale est codée.
Enfin, les valeurs exprimées par les séquences x, y et n doivent respecter certaines limites pour ne pas causer de débordement (cf. le tableau supra ).
- La constante littérale
123.45e6code la valeur 123,45 × 106. - La constante littérale
0123.450e06se code simplement123.45e6. - La constante littérale
123.0e5se code simplement123e5. - La constante littérale
123.0e0se code simplement123.0.
123.0 ne se code pas 123 car cette chaîne numérique serait interprétée par le compilateur comme une constante littérale entière. Au pire, on pourrait coder 123. mais l'absence du zéro décimal impacterait la lisibilité du code source. 123e0 ne se code pas 123 pour la même raison que celle donnée à l'exemple précédent. Syntaxe de codage alternative en notation hexadécimale et puissances de 2
On peut également coder les constantes littérales flottantes en notation hexadécimale et puissances de 2 via la syntaxe générale exposée supra mais :
- en préfixant la mantisse par
0xet en codant ses digits en base 16 (avec les chiffres0à9et les lettresAàF) ; - en codant le séparateur d'exposant par le symbole
p(et non pase), le facteur exponentiel étant alors interprété comme valant 2±n ;
sachant que cette syntaxe alternative est entièrement insensible à la casse.
La constante littérale codée 0xA.1p3 prend la valeur décimale :
10,0625 × 23 = 80,5
car A(16) = 10 et 0,1(16) = 0,1/16 = 0,0625.
On peut aussi coder cette constante 0Xa.1P3, puisque la syntaxe de codage des constantes littérales décimales est indifférente à la casse.
En employant cette syntaxe alternative (dans les limites des intervalles d'encodage du type de la constante), on code une valeur qui est forcément une somme de puissances de 2, donc encodable sans erreur.
Pseudo‑constantes mathématiques
On a vu au chapitre C2‑IV que certaines implémentations du fichier d'en‑tête math.h de la bibliothèque standard du langage C (cmath en C++) définissent par des pseudo‑constantes des approximations décimales de constantes mathématiques usuelles : M_PI pour π, M_E pour e, etc.
De plus, certaines implémentations définissent dans le même fichier des pseudo‑constantes relatives aux valeurs spéciales encodables dans les types flottants, notamment :
-
INFINITYdont la valeur est celle que prend toute expression de type flottant qui déborde par le haut en valeurs absolues (overflow) de ses limites d'encodage ±type_MAX; -
NAN(not a number) dont la valeur est celle que prend toute expression de type flottant qui code une opération non définie dans ce type (opérations telles que 0/0, √−1, etc.) ;
Ces pseudo‑constantes permettent notamment de tester la valeur de certaines expressions lors de l'exécution d'un programme et mettre en œuvre une gestion des erreurs.
Plus précisément, la valeur prise par la pseudo‑constante NAN est un qNAN (cf. infra ). En effet, lors de l'exécution du programme, puisque cette valeur n'est pas engendrée par un calcul mais introduite intentionnellement par le codeur, il ne serait pas pertinent qu'elle soit signalée.
Typage d'une valeur décimale
Type par défaut d'une valeur décimale
Dans une expression en langage C ou C++, toute constante littérale interprétée par le compilateur comme une valeur décimale est encodée par défaut (c'est‑à‑dire sauf spécification particulière) comme étant de type double ou long double par ordre de préférence, dès que cette valeur entre dans l'étendue d'un de ces types.
Dans une expression, sauf via une conversion explicite ou spécification par préfixe, une valeur décimale n'est donc jamais traitée comme étant de type float même si elle est incluse dans les intervalles des valeurs encodables de ce type.
Comme pour les entiers, cette stratégie permet de minimiser les risques de débordement et de pertes de précision au cours de l'évaluation des expressions calculatoires. De plus, elle optimise la capacité de calcul des architectures 64 bits puisque, en mémoire comme en registre, une donnée de type double fait exactement cette largeur.
Toutefois, cette stratégie présente un coût non négligeable en termes de temps de calcul sur des architectures « étroites » comme les cartes à microcontrôleur. C'est pourquoi l'environnement Arduino limite la taille des types double et long double(cf. supra), au détriment de leur étendue et de leur précision (cf. chap. C3‑I ).
Quelle que soit l'architecture de machine considérée :
- la constante littérale décimale codée
1e23est encodée de typedouble, même si elle aurait pu être encodée à moindre coût mémoire dans le typefloat(on rappelle queFLT_MAXvaut environ 3,4 × 1038) ; - la constante littérale décimale codée
4e567est encodée de typelong doublecar elle n'entre pas dans l'étendue du typedouble(on rappelle queDBL_MAXvaut environ 1,7 × 10308).
Spécification d'un type flottant
Comme pour les valeurs entières (cf. chap. C3‑II ), les langages C et C++ permettent d'imposer un type flottant autre que double à toute constante littérale décimale. Il suffit d'adjoignant à cette dernière le suffixe :
-
fouFpour qu'elle soit encodée de typefloat; -
louLpour qu'elle soit encodée de typelong double.
Pour coder l'affectation d'une constante littérale à une donnée de type long double, l'emploi du suffixe l ou L est indispensable. Sinon la valeur est encodée dans le type double avant l'affectation proprement dite, avec à la clef une perte de précision.
Considérons les deux déclarations-initialisations codées ci‑dessous :
long double a = 1.1; // prefix l or L missing! long double b = 1.1L; // OK
Compilées sur OnlineGDB (compilateur gcc 5.4.1 c99) :
- la première affecte à la variable
ala valeur :
1.100000000000000088178…
avec une précision de 17 chiffres significatifs qui est seulement celle du typedouble; - la deuxième affecte à la variable
bla valeur :
1.1000000000000000000217…
avec une précision de 20 chiffres significatifs qui est bien celle du typelong double.
A contrario, coder le suffixe f ou F est inutile pour l'affectation d'une constante littérale à une donnée de type float. En effet, même sans suffixe, la constante sera de toute façon convertie dans le type dans le type float lors de l'affectation. Et a priori, rien ne permet d'affirmer que l'ajout du suffixe f ou F puisse améliorer la vitesse de compilation ou d'exécution du programme, tant les compilateurs modernes intègrent des mécanismes d'optimisation…
Considérons les deux déclarations-initialisations codées ci‑dessous :
float c = 1.1; float d = 1.1F;
Toujours sur OnlineGDB, l'une et l'autre affectent respectivement aux variables c et d la même valeur :
1.100000023841858…
avec une précision de 8 chiffres significatifs qui est bien celle du type float.
Néanmoins, le suffixe f ou F trouve son utilité dans les expressions calculatoires hétérogènes, faisant intervenir des données décimales et entières. Si le type float est systématiquement imposé aux données décimales, les données entières ne seront converties que dans ce type, et non pas dans le type double, avec à la clef un gain en rapidité et en registres de calcul, ce qui est peut être appréciable sur des cartes à microcontrôleur.
Sur une carte Arduino à cœur ARM (Due, Zero…), si a est une donnée déclarée de type int, alors l'expression :
sizeof(0.1 * a)
prend la valeur 8 (octets), car la constante littérale 0.1 est interprétée de type double. Alors que l'expression :
sizeof(0.1f * a)
prend seulement la valeur 4 (octets), grâce au suffixe f. C'est donc dans le type float qu'elle sera évaluée.
Spécifications de conversion pour les entrées‑sorties standards
Les fonctions d'entrée‑sortie standards formatées des familles printf et scanf (cf. chap. C2‑VII ) requièrent des spécifications de conversions particulières pour l'écriture et la lecture des valeurs décimales.
Les caractères‑codes de ces spécifications sont indiquées dans le tableau ci‑dessous :
| Caractère code |
Format d'affichage |
|---|---|
g ou G |
valeur décimale, virgule flottante (format le plus court possible, 6 chiffres par défaut) |
f ou F |
valeur décimale, virgule fixe (sans exposant) |
e ou E |
valeur décimale, virgule flottante (avec exposant) |
a ou A |
valeur hexadécimale, virgule flottante (avec exposant) |
sachant que la casse des caractères-codes (minuscule ou majuscule) spécifie seulement la casse d'affichage.
En règle générale, la spécification de conversion % est à privilégier. Les autres spécifications restent utiles pour des besoins spécifiques. g
Le programme C ci‑dessous permet de comparer les spécifications de conversion %, g% et f% pour deux constantes eEX_F1 et EX_F2 déclarées de type float.
#include <stdio.h>
const float EX_F1 = 987.6543, EX_F2 = 9.87e6;
int main(void)
{
printf("EX_F1 %%g: %g \t %%f: %f \t %%e: %e\n", EX_F1, EX_F1, EX_F1);
printf("EX_F2 %%g: %g \t %%f: %f \t %%e: %e\n", EX_F2, EX_F2, EX_F2);
return 0;
}
On obtient en sortie standard l'affichage :
EX_F1 %g: 987.654 %f: 987.654297 %e: 9.876543e+02 EX_F2 %g: 9.87e+06 %f: 9870000.000000 %e: 9.870000e+06
La pseudo‑constante INFINITY (cf. supra. ) est respectivement affichée et saisie via les fonctions printf et scanf sous l'abréviation inf ou INF.
Quant à la pseudo‑constante NAN, elle est affichée et saisie comme son identificateur.
Paramètres optionnels
Les spécifications de conversions des valeurs décimales sont paramétrables par un préfixe potentiellement constitué de 4 sous-spécifications optionnelles, codées dans l'ordre entre le symbole % et le caractère-code de spécification du tableau ci‑dessus.
Ces sous-spécifications permettent de formater la valeur décimale à traiter dans un champ de n caractères qui peuvent être des espaces, des signes, des chiffres et des séparateurs (décimal et exponentiel).
Certaines sous‑spécifications sont également applicables aux spécifications de conversion des valeurs entières %, d% et u%. x
Leur syntaxe de codage est décrite dans le tableau ci‑dessous.
| Nº d'ordre | Syntaxe | Formatage |
|---|---|---|
| 1 | symbole(s) 1 à 4 |
|
| 2 | i ou * i : entier positif |
largeur minimale – en nombre de caractères – du champ de formatage (sinon ajustement automatique)
* : valeur spécifiée par un argument variable, cf. remarque B) infra |
| 3 | .j ou .*j : entier positif |
nombre de décimales traitées (valeur par défaut : 0)
* : valeur spécifiée par un argument variable, cf. remarque B) infra |
| 4 | lettre |
L obligatoire (et non pas l) si la valeur est de type long double par défaut, les spécifications de conversion opèrent pour le type double, qui est aussi le type par défaut des expressions à valeurs décimales |
Le programme C ci‑dessous montre une possible présentation d'un tableau de valeurs (juste quelques unes, par soucis de concision) d'une fonction mathématique, ici f(x) = e1/x.
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
int main(void)
{
printf(" x | exp(1/x) \n");
for (float x = -0.1; x < 0.11; x += 0.05) {
if (fabs(x) > 0.0001) {
printf(" %+5.2f | %+.3e \n", x, exp(1/x));
}
else {
printf(" %- 5.0f | not a number\n", round(x+0.0001));
}
}
}
On obtient sur le moniteur l'affichage :
x | exp(1/x) -0.10 | +4.540e-05 -0.05 | +2.061e-09 0 | not a number +0.05 | +4.852e+08 +0.10 | +2.203e+04
où l'on observe que, pour la colonne des « x » :
- la spécification
%+5.2f0») dans un champ de 5 caractères avec signage systématique et 2 décimales pour un format à virgule fixe ; - la spécification
%- 5.0f0» dans un champ de 5 caractères mais en justification à gauche, avec un caractère espace à la place du signe «+» et aucune décimale, toujours pour un format à virgule fixe ;
et pour la colonne des « exp(1/x) » :
- la spécification
%+.3e
La syntaxe des spécifications de conversion présente de nombreuses particularités qu'il est difficile de décrire en exhaustivité. En particulier :
- Dans la sous-spécification nº 1, le symbole
#code un formatage alternatif pour certaines spécifications. - Dans la sous-spécification nº 2 et 3, le symbole
*permet de spécifier la valeur attendue par un paramètre variable (et non pas une constante littérale) de typeint– paramètre qui codé dans la liste des arguments de la fonction juste avant celui dont la valeur est traitée. - Sur un PC Windows avec la chaîne de compilation Mingw‑w64, la sous‑spécification nº 4 codée
Ln'est pas opérationnelle, car elle est implémentée par une ancienne bibliothèque du logiciel d'exécution (run‑time) qui ne prend pas en charge le typelong double. Dès lors, le programme n'a pas la capacité d'afficher ou de lire les données de ce type F.
%g
printf("%g %#g \n", 2e10, 2e10);
Sur le moniteur, on obtient l'affichage :
2e+10 2.00000e+10
%#g), la partie décimale n'est pas omise même si elle est nulle. N_MAX qui est une constante déclarée de type int :
#include <stdio.h>
#include <math.h>
const int N_MAX = 4;
int main(void)
{
for (int n = 0; n <= N_MAX; n++) {
printf(" %*.0f \n", N_MAX + 1, pow(10.0, n));
}
}
1
10
100
1000
10000
%*.0f*N_MAX + 1 codé juste avant. printf C et scanf C sur un site comme cppreference. Encodage des données de types flottants
Attention ! La représentation en mémoire des nombres décimaux est bien plus complexe que celle des entiers. Pour comprendre le principe de l'encodage en binaire des valeurs de types flottants, il est nécessaire de connaître préalablement deux algorithmes élémentaires :
- l'algorithme de formatage d'un nombre décimal en notation scientifique,
- de conversion en base 2 d'un nombre décimal.
Ces algorithmes sont exposés ci‑après.
Formatage en notation scientifique des nombres décimaux
Rappelons que dans la notation scientifique d'un nombre décimal de la forme ±m × 10n (cf. supra ), la mantisse doit avoir une partie entière réduite à un seul chiffre et être non nulle.
Autrement dit, en notation scientifique, la mantisse m est forcément comprise entre 1,0… et 9,9999… – valeur maximale qui tend vers 10, la base de numération. Cette mise en forme est rendue possible en compensant la mantisse par le facteur exponentiel 10n.
Pour formater en notation scientifique un nombre décimal écrit de la forme x,y × 10n où x, y et n sont trois chaînes numériques quelconques, l'algorithme est le suivant :
- si x ⩾ 10, on divise x,y par 10 autant de fois que x compte de chiffres en plus de celui des unités et on incrémente d'autant l'exposant n ;
- si x = 0, on multiplie x,y par 10 autant de fois qu'il faut pour obtenir un chiffre des unités non nul et on décrémente d'autant l'exposant n.
Conversion en base 2 d'un nombre décimal
Pour convertir en base 2 un nombre décimal quelconque écrit de la forme x,y × 10n où x, y et n sont trois chaînes numériques quelconques, il faut commencer par annuler l'exposant (c'est‑à‑dire appliquer le procédé inverse à celui exposé supra ).
- Si n > 0, on multiplie x,y par 10 autant de fois que n et on décrémente d'autant n (qui devient nul).
- Si n < 0, on divise x,y par 10 autant de fois que la valeur absolue de n et on incrémente d'autant n (qui devient nul).
Une fois qu'un nombre décimal est formaté sans exposant, c'est‑à‑dire de la forme x,y, sa conversion en base 2 s'obtient en procédant séparément pour sa partie entière x et sa partie décimale 0,y.
La conversion en base 2 de la partie entière x s'effectue comme avec n'importe quel entier par divisions euclidiennes successives par 2 (cf. chap. C3‑II ).
Les bits dk obtenus constituent les coefficients binaires d'une somme discrète pondérée avec des poids de la forme 2k où k est le rang du bit, allant de 0 à m −1 (m étant le nombre de bit d'encodage).
La conversion en base 2 de la partie décimale 0,y s'effectue via un algorithme « réciproque » de multiplications-soustractions successives sur des valeurs purement décimales (c'est‑à‑dire des nombres de la forme « 0,… ») notées Fk où l'indice k est un rang négatif et commence par k = −1 avec F−1 = 0,y. À l'itération de rang k :

- on opère Fk × 2 puis :
- si 2.Fk ⩾ 1, alors Fk−1 = 2.Fk − 1 et on obtient dk = 1 ;
- sinon, Fk−1 = 2.Fk − 0 = 2.Fk et on obtient dk = 0 ;
- et ce, en principe, jusqu'à avoir Fk = 0. Mais en pratique, l'algorithme n'a le plus souvent pas de fin – de même qu'une division euclidienne ne s'achève presque jamais si on la prolonge dans le domaine décimal. On doit donc y mettre un terme en acceptant une erreur d'encodage après un nombre d'itérations suffisant pour atteindre une précision acceptable.
Les bits dk obtenus :
- constituent, comme pour un entier, les coefficients d'une somme discrète pondérée par les poids de la forme 2k où k est le rang du bit ;
- mais, en attribuant aux bits des rangs négatifs en commençant à −1 pour le bit immédiatement à droite du séparateur décimal, les poids sont fractionnaires, ils valent respectivement 2−1 = 0,5 puis 2−2 = 0,25 puis 2−3 = 0,125, etc.
Effectuons la conversion en base 2 du nombre décimal 14,8125, qui a l'avantage d'être une somme exacte de puissances de 2, donc de nécessiter un nombre fini d'étapes :
- on a vu au chapitre C3‑II comment procéder pour sa partie entière x = 14 ; son écriture binaire est 1110(2) ;
- pour la partie décimale 0,y = 0,8125 on procède comme sur la figure ci‑dessous, avec :
- à droite, la succession des multiplications-soustractions posées en cascade dont on peut directement extraire les valeurs des bits de la conversion d−1 à d−4 ;
- à gauche, pour une bonne compréhension, la mise en équation de ces opérations, qui permet de reconstituer la valeur 0,8125 comme une somme pondérée de puissances négatives de 2.
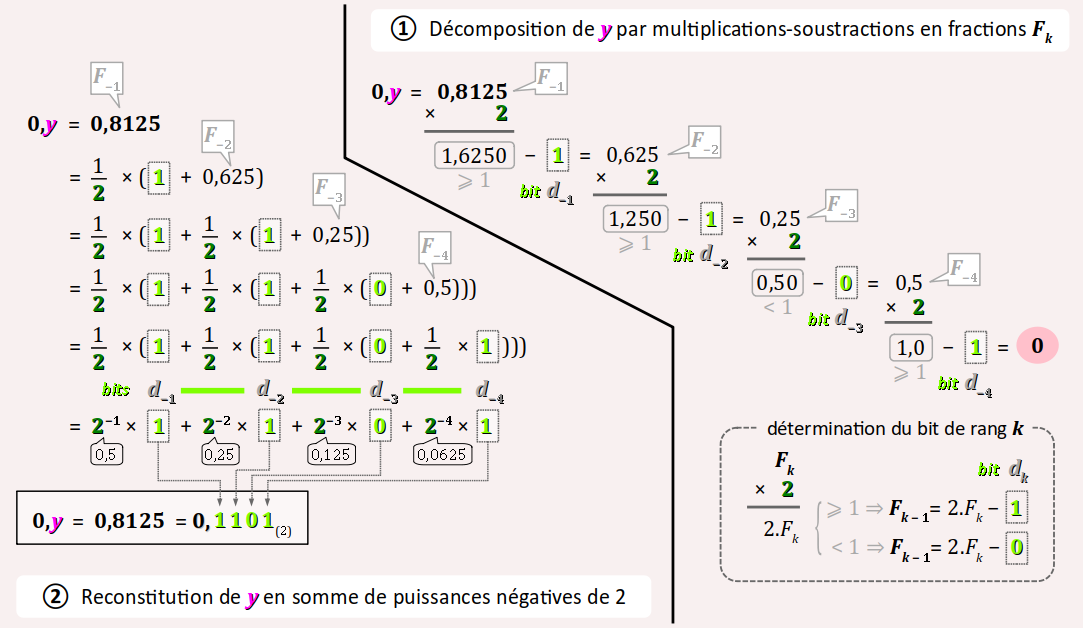
Ainsi, le nombre décimal 14,8125 s'écrit en binaire 1110,1101(2).
Formatage normalisé de l'écriture en base 2 d'un nombre décimal
À partir de l'écriture en base 2 d'un nombre décimal, il ne reste plus qu'à lui donner un format normalisé pour obtenir les éléments fondamentaux de son code binaire tel qu'il est encodé en mémoire dans une machine. Comme pour la notation scientifique, ce format requiert une partie entière réduite à un seul bit et non nulle, c'est‑à‑dire une mantisse de la forme :
1,f (2)
où f est la partie fractionnaire (ou décimale) de la mantisse – encore appelée significande.
Pour cela, il suffit d'adjoindre à l'écriture du nombre un facteur exponentiel de la forme 2p et de procéder comme exposé supra . Autant de fois que nécessaire, on déplace le séparateur décimal d'un rang :
- vers la droite en divisant le nombre par 2, donc en incrémentant de 1 l'exposant p pour compenser ;
- vers la gauche en multipliant le nombre par 2, donc en décrémentant de 1 l'exposant p pour compenser.
En reprenant l'exemple supra, le formatage normalisé du nombre décimal 14,8125 = 1110,1101(2) est le suivant :
1,1101101(2) × 23
après déplacement de la virgule vers la gauche de 3 rangs.
L'exposant p, qui peut être positif ou négatif, reste pour le moment exprimé en base 10. On va voir ci‑après qu'il n'est pas converti en binaire par la méthode du complément à 2, mais d'une manière différente avec la notion d'exposant décalé.
Champs de bits des types flottants
Conformément à la norme IEEE 754‑1985/IEC 60559:1989 W, tout type flottant standard des langages C/C++ est encodé dans un format binaire composé de 3 champs de bits : le signe (un seul bit), l'exposant décalé et le significande
Pour exploiter au mieux la taille d'implémentation qui leur est donnée, les types flottants ne diffèrent les uns des autres que par les largeurs des champs :
- de l'exposant décalé – largeur que l'on notera r ;
- et du significande – largeur que l'on notera w.
Largeurs des champs
Sur la plupart architectures d'ordinateurs, on a les largeurs de champs – et les caractéristiques qui en découlent – indiquées dans le tableau ci‑dessous.
| Type flottant |
Taille (octets) |
Exposant décalé |
Étendue d'exposant (en base 10) |
Significande | Précision relative |
|---|---|---|---|---|---|
float |
4 | 8 bits | ±38 | 23 bits | 10−7 |
double |
8 | 11 bits | ±308 | 52 bits | 10−16 |
long double |
12/16 | 15 bits | ±4932 | 63 + 1 bits | 10−19 |
La répartition des bits des 3 champs sur les octets d'encodage obéit aux règles suivantes :
- le bit de signe est placé au plus haut rang du format ;
- au rang immédiatement inférieur du bit de signe se trouve le bit de poids fort de l'exposant décalé ;
- le bit de poids faible du significande est placé au plus bas rang du format (0).
De plus, conformément au format à précision étendue dit x86 W, le type long double présente deux particularités :
- certains octets ne sont pas utilisés ; ils constituent ce qu'on appelle une marge dans le format (en anglais, padding) ;
- le significande comprend à son plus haut rang un bit supplémentaire (bit 63) qui code la partie entière de la mantisse (integer part), afin d'optimiser la vitesse d'exécution des algorithmes de calcul des opérations sur les valeurs de types flottants.
Dans le cas du type float, la répartition des bits est illustrée par la figure ci‑dessous.

Décodage des champs
Donné à titre d'exemple, le décodage du format binaire du type standard float permet de bien comprendre le principe général d'encodage des types flottants W.
Le bit de signe
Le bit de signe, ici noté usuellement s code le signe de la valeur avec la même convention que pour les entiers :
-
0pour un nombre positif, -
1pour un nombre négatif.
Toute valeur z encodée dans un type flottant peut donc s'exprimer par le produit :
z = (−1)s . |z|
En conséquence, toute valeur encodée possède une valeur de signe opposé, y compris la valeur zéro. Par la suite, il suffit d'étudier l'encodage des valeurs positives.
L'exposant décalé
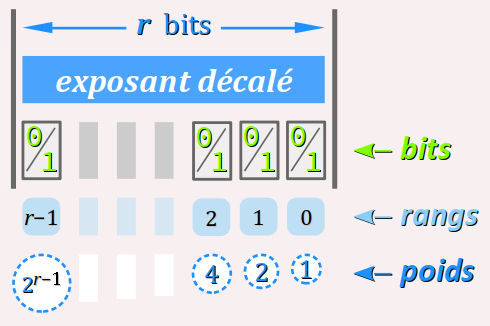
Le champ de l'exposant décalé (en anglais, biaised exponent W) encode en binaire naturel, de droite à gauche sur r bits, un nombre entier positif ou nul, qu'on note ici q.
Les valeurs de q vont donc de 0 à 2r − 1.
Dans le type float, on a r = 8 bits donc l'exposant décalé q va de 0 à 28 − 1 = 255.
La relation entre q et l'exposant normal, noté ici p, est :
p = q − qmed
avec qmed = 2r − 1 − 1
où qmed représente le milieu de l'étendue des valeurs de q.
Dans le type float on a qmed = 27 − 1 = 127.
Le décalage médian des valeurs d'exposant permet d'encoder les valeurs négatives de p sans recourir à un bit de signe dans le champ de l'exposant et de simplifier les algorithmes de calcul des opérations sur les valeurs décimales. Pour l'encodage d'une valeur décimale normalisée notée z :
- si q < qmed alors p < 0 ;
- si q = qmed alors p = 0 ;
- si q > qmed alors p > 0 ;
et dans tous les cas, on a |z| = m × 2p où m est la mantisse de la valeur décimale encodée z.
De plus, les valeurs extrêmes de q sont réservées :
-
00…00pour les valeurs dites dénormalisées, qui sont de très petites valeurs et qui comprennent les deux zéros ±0 – cf. infra ; -
11…11pour les deux « infinis » (±∞) et les valeurs dites NAN (not a number) – cf. infra .
Les valeurs de q laissées pour l'encodage des valeurs normalisées vont donc de qmin = 1 à qmax = 2r − 2.
Dans le type float, pour l'encodage des valeurs normalisées :
- qmin = 1 (encodé
00000001) correspond à l'exposant normal pmin = 1 − 127 = −126 ;
sachant que 2−126 ≃ 1,2 × 10−38, on retrouve ici la valeur usuelle de la pseudo‑constanteFLT_MIN; - qmax = 254 (encodé
11111110) correspond à l'exposant normal pmax = 254 − 126 = +126 ;
sachant que 2+126 ≃ 8,5 × 10+37, on retrouve ici la moitié de la valeur usuelle de la pseudo‑constanteFLT_MAX(moitié car il reste à multiplier pmax par la valeur maximale de la mantisse, qui tend vers 2, pour retrouverFLT_MAX).
Le significande
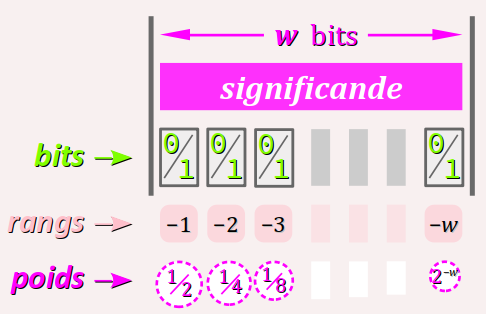
Le champ du significande encode en binaire décimal, de gauche à droite sur w bits, la partie fractionnaire (ou décimale) notée f de la mantisse de la valeur décimale encodée.
Ses bits, qu'on note ici fk ont des rangs négatifs k décroissants de −1 à −w. Ils sont associés à des poids 2k qui forment des puissances fractionnaires de 2, à savoir 2−1 = 1/2 puis 2−2 = 1/4 puis 2−2 = 1/8 etc.
Comme pour les entiers encodés en binaire naturel, la valeur décimale f (en base 10) du significande peut être calculée par la somme des valeurs des bits multipliés par leurs poids :
f = f−1 × 2−1 + f−2 × 2−2 + … + f−w × 2−w
Elle va de fmin = 0 (encodée 00…00) à fmax = 0,999999… (encodée 1 … 1) selon la précision octroyée par la largeur w du champ du significande.
Dans le type float (w = 23 bits), on a :
fmax ≃ 0,99999988
Le poids 2−w du dernier bit du significande détermine la précision du type flottant. Il donne l'écart entre deux valeurs successives de f, et correspond donc à la pseudo‑constante type_EPSILON.
Pour le type float (w = 23 bits), la précision est donnée par la pseudo‑constante :
FLT_EPSILON = 2−23 ≃ 1,2 × 10−7
Décodage des valeurs décimales
Détermination de la mantisse
À partir de la valeur f encodée dans le champ du significande, on obtient la valeur m de la mantisse d'un nombre décimal encodé dans un type flottant standard, sachant que cette dernière est toujours de la forme :
- 1,… (2) pour les valeurs normalisées ; on a donc m = 1 + f
- 0,… (2) pour les valeurs dénormalisées ; on a donc m = f
Comme la distinction entre les valeurs normalisées et dénormalisées est encodée par l'exposant décalé (cf. supra ), le bit unique de la partie entière de la mantisse n'a pas besoin d'être encodé pour le calcul de m. On dit que ce bit est « caché » W (sauf pour le type long double – cf. supra ).
Décodage des valeurs normalisées
En synthétisant tous les éléments précédents, on obtient la valeur en base 10 d'un nombre décimal normalisé z dans un type flottant standard par la formule :
z = (−1)s × (1 + f−1 × 2−1 + … + f−w × 2−w) × 2p avec p = q − qmed
Considérons le nombre décimal z encodé dans le type float par les 4 octets Ox416D0000 représentés sur la figure ci‑dessous :

On extrait les éléments :
| • bit de signe s = 0 | |
| • exposant q = 10000010 (2) = 128 + 2 = 130 donc p = 130 − 127 = 3 | |
| • significande | f = 0,1101101 (2) = 2−1 + 2−2 + 2−4 + 2−5 + 2−7 |
| f = 0,5 + 0,25 + 0,0625 + 0,03125 + 0,0078125 | |
| f = 0,8515625 | |
puis on obtient z = (−1)0 × (1 + 0,8515625) × 23 = 14,8125.
Décodage des valeurs dénormalisées
Dans tout type flottant standard, les valeurs dénormalisées sont encodées sur les mêmes champs que les valeurs normalisées, mais avec une interprétation différente :
- un exposant décalé q = 0 et un exposant dénormalisé fixe pden = − qmed + 1 (et non pas −qmed) ;
autrement dit, pden = pmin (minimum de l'exposant normal), et ce afin d'assurer la continuité des domaines normalisés et dénormalisés ;
- une mantisse à partie entière nulle, c'est‑à‑dire telle que m = f (et non pas 1 + f).
Si le significande est nul (00…00), la valeur dénormalisée encodée vaut ±0 selon la valeur du bit de signe.
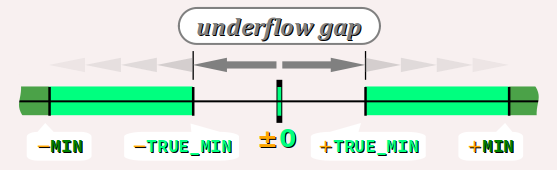
En « sacrifiant » une valeur d'exposant (la valeur p = −qmed) mais en permettant à la mantisse de prendre des valeurs très petites (jusqu'à 2−w), cette technique permet de réduire l'intervalle entre les plus petites valeurs encodables négatives et positives. Au lieu de s'étendre entre les valeurs normalisées ±type_MIN, il se réduit à celui entre les valeurs normalisées ±type_TRUE_MIN.
Cet intervalle est appelé l'underflow gap dans la mesure où toute valeur qu'il contient est forcément encodée ±0, ce qu'on qualifie de débordement par valeurs inférieures ou underflow (cf. infra ).
Dans le type float où on a usuellement :
FLT_MIN = 2−126 ≃ 1,17549435 × 10−38
les valeurs dénormalisées encodables s'échelonnent :
- de ≃ 0,99999988 × 2−126 ≃ 1,17549420 × 10−38 (presque
FLT_MIN) lorsque le significande est encodé11…11; - à
FLT_TRUE_MIN= 2−23 × 2−126 = 2−149 ≃ 1,4 × 10−45 lorsque le significande est encodé00…01.
Toutefois, la précision d'encodage des valeurs dénormalisées est moindre que celles des valeurs normalisées. L'écart relatif entre deux valeurs successives n'est pas constant, il croit exponentiellement tandis que les valeurs diminuent, pour atteindre 100 % au voisinage de type_TRUE_MIN. La pseudo‑constante type_EPSILON n'est donc pas représentative des valeurs dénormalisées.
Dans le type float, la valeur immédiatement supérieure à FLT_TRUE_MIN vaut environ 2,8 × 10−45, soit le double de FLT_TRUE_MIN.
Encodage de valeurs spéciales
Les types flottants standards des langages C/C++ réservent la valeur 11…11 du champ d'exposant décalé pour coder diverses valeurs spéciales : les « infinis » et les NAN .
Une valeur spéciale dite « infinie » (symbole mathématique ∞) est encodée par son champ du significande égal à 00…00. La valeur du bit de signe 0 ou 1 permet de distinguer respectivement « +∞ » et « −∞ ».
Une valeur spéciale dite « NAN » (pour not a number W) est encodée par son champ du significande différent de 00…00 ; mais ce dernier n'est employé que pour distinguer deux sortes de NAN. Avec la plupart des implémentations :
- de
00…01à01…11, il s'agit d'un NAN dit avertisseur – abrégé sNAN (« s » pour signaling) ; - de
10…00à11…11, il s'agit d'un NAN dit silencieux – abrégé qNAN (« q » pour quiet) ;
sachant qu'un sNAN déclenche une condition d'exception lors de l'exécution du programme, contrairement à un qNAN.
Pour un NAN, la valeur du bit de signe 0 ou 1 n'a pas d'interprétation.
De même, la valeur du champ du significande n'a pas d'interprétation hormis pour la distinction entre les deux sortes de NAN, que le bit de plus haut rang suffit à assurer (0 pour un sNAN, 1 pour un qNAN).
Tableau récapitulatif pour le type float
Le tableau ci‑dessous récapitule par catégories de valeurs encodées – dénormalisées, normalisées et spéciales – les plages des codes des champs exposant décalé et significande pour le type standard float.
Par soucis de simplicité, le bit de signe n'est pas pris en compte. Les valeurs encodées sont donc valables au signe ± près.
|
Catégorie de valeurs |
exposant décalé |
facteur exponentiel |
significande | mantisse m |
valeurs encodées |
|---|---|---|---|---|---|
| dénormalisées |
00…00 |
2−126 | 00…00 |
0 | 0 |
de 00…01 à 11…11 |
≃ 0,00000012 à 0,99999988 |
≃ 1,4 × 10−45 à 1,1 × 10−38 |
|||
| normalisées | de 00…01 à 11…10 |
de 2−126 à 2+126 |
de 00…01 à 11…11 |
≃ 1,00000000 à 1,99999988 |
≃ 1,1 × 10−38 à 3,4 × 10+38 |
| spéciales |
11…11 |
pas d'interprétation |
00…00 |
pas d'interprétation |
∞ |
de 00…01 à 01…11 |
sNAN | ||||
de 10…00 à 11…11 |
qNAN |
Opérations sur les données de types flottants
À l'exception des opérateurs booléens bits à bits et des opérateurs de décalages de bits, tous les opérateurs des langages C et C++ s'appliquent aux expressions à valeurs de types flottants. Toutefois, leur emploi requiert de la part du codeur une vigilance sur trois aspects : les débordements, les opérations non définies et les comparaisons.
Par ailleurs, les modules de mathématiques des bibliothèques standards des langages C et C++ mettent à disposition du codeur non seulement des fonctions mathématiques usuelles, mais aussi des fonctions spécifiques pour manipuler les données de types flottants. Il importe d'en connaître l'existence et de savoir où trouver leurs particularités.
Débordements
On a vu au chapitre C3‑II que, durant l'exécution d'un programme codé en C ou C++, quand une expression à valeurs entières dépasse l'étendue de son type (integer overflow – aussi bien par le haut que par le bas), le débordement est traité par rebouclage en arithmétique cyclique et sans sans arrêt du processus exécution.
Les débordements d'une expression à valeurs de type flottant sont également traités sans arrêt du processus d'exécution, mais par éléments absorbants et en distinguant deux cas, selon que le débordement opère par le bas (floating point underflow) ou par le haut (floating point overflow).
En raisonnant en valeurs absolues :

- tout débordement par le bas, c'est‑à‑dire toute évaluation inférieure à
type_TRUE_MIN(ou àtype_MINsi les valeurs dénormalisées ne sont pas implémentées) fait prendre à l'expression la valeur0.0; - tout débordement par le haut, c'est‑à‑dire toute évaluation supérieure à
type_MAXfait prendre à l'expression la valeur infini du même signe que la limite dépassée.
Propriétés des valeurs ±∞
Les valeurs ±∞ obéissent à des règles de calcul spécifiques. Ces règles sont consignées dans le tableau ci‑dessous, où a désigne une expression de type flottant prenant une valeur numérique quelconque normalisée ou dénormalisée, mais pas infinie ou non définie. On raisonne en valeurs absolues (avec des opérandes signés, le signe du résultat est en général conforme aux règles usuelles de calcul).
| opérations algébriques | comparaisons | ||
|---|---|---|---|
∞ + a → ∞ |
∞ + ∞ → ∞ |
∞ > a → 1 |
∞ > ∞ → 0 |
∞ - a → ∞ |
∞ - ∞ → NAN |
∞ < a → 0 |
∞ < ∞ → 0 |
∞ * a → ∞ ∞ * 0 → NAN |
∞ * ∞ → ∞ |
∞ == a → 0 |
∞ == ∞ → 1 |
∞ / a → ∞ a / ∞ → 0.0 |
∞ / ∞ → NAN 0 / ∞ → NAN |
∞ != a → 1 |
∞ != ∞ → 0 |
Gestion des opérations non définies
Contrairement à une expression à valeurs entières (cf. chap. C3‑II ), une expression à valeurs de type flottant dont l'évaluation durant l'exécution d'un programme retourne une valeur non définie – en l'occurrence, un NAN (not a number ) – ne provoque pas d'arrêt de l'exécution.
Comme les valeurs valeurs ±∞, les NAN obéissent à des règles de calcul spécifiques. Elles sont assez simples :
- un NAN se comporte comme un élément absorbant pour tous les opérateurs algébriques ; autrement dit, quelle que soit la valeur d'une expression a de type flottant (même ∞ ou NAN elle-même), on a :
NAN + a→ NANNAN + a→ NANNAN * a→ NAN etc. - toute comparaison avec NAN rend la valeur
0, c'est‑à‑dire faux, même une expression de la formeNAN == NANsauf, bien entendu, une expression de la formeNAN != NANqui rend toujours la valeur1.
Quant à la propagation des NAN selon leurs sortes sNAN et qNAN, elle est assez complexe et ne sera pas abordée ici. Pour en savoir plus, on pourra consulter cette référence .
Opérations de comparaison
Contrairement à une expression à valeurs entières, une expression à valeurs de type flottant ne doit pas être employée comme opérande des opérateurs == et !=, même si syntaxiquement, rien n'interdit de coder de tels tests.
En effet, les erreurs d'encodage dans les types flottants sont très fréquentes (cf. supra ) et biaisent l'évaluation des expressions de test d'égalité : même quand les deux valeurs comparées devraient être égales, il suffit que leurs significandes respectifs différent sur le bit de poids faible pour que le test d'égalité prenne la valeur booléenne 0, c'est‑à‑dire faux.
De même, les tests de différence sont très souvent évalués 1, c'est‑à‑dire vrai.
L'expression (0.1 + 0.2) == 0.3 (encodée par défaut dans le type double) prend la valeur booléenne 0 (faux), car :
- la constante littérale
0.1est encodée comme 0,1000000000000000055… - la constante littérale
0.2est encodée comme 0,2000000000000000111… - la constante littérale
0.3est encodée comme 0,2999999999999999889… avec un significande valant0x3333333333333; - mais l'expression
0.1 + 0.2prend la valeur 0,3000000000000000444… avec un significande valant0x3333333333334!
Entre les expressions 0.1 + 0.2 et 0.3, la seule différence d'encodage du bit de poids faible du significande suffit pour invalider le test d'égalité, alors qu'elle n'induit qu'un écart relatif infime entre leurs valeurs.
Méthode de codage des tests d'égalité des expressions décimales
Pour coder un test d'égalité entre deux expressions a et b de types flottants, il est donc vivement recommandé de coder un test de différence relative minime de la forme :
fabs((a - b) / a) <= k * type_EPSILON
où :
-
fabsest la fonction valeur absolue sur les valeurs de types flottants ; -
type_EPSILONest la pseudo‑constante de résolution (cf. supra ) du type le moins précis de ceux des deux expressionsaetb; -
kest un coefficient de précision, à choisir d'autant plus grand que l'égalité testée est approximative – la valeur 10 étant a priori recommandée.
Cette méthode n'est valable que pour tester l'égalité de valeurs normalisées et non nulles.
Pour tester une égalité au voisinage de 0.0 (donc avec des valeurs dénormalisées), il est recommandé de coder une expression de différence absolue et avoir conscience du risque d'underflow (cf. supra ).
À titre pédagogique, le programme en C ci‑dessous compare deux méthodes – égalité directe (non recommandée) et différence relative minime (recommandée) – pour tester l'égalité des valeurs respectives de deux variables a et b de type float, supposées égales mais en fait calculées de deux manières distinctes, avec des erreurs d'encodages différentes.
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <float.h>
int main(void)
{
float a = 0.0;
printf(" a | b | a == b | |(a - b)/a| <= 10 * ESP\n");
for (int i = 1; i < 10; i++) {
a += 0.1;
float b = i / 10.0;
printf(" %.8f | %.8f | %3d | %13d \n", a, b, a == b, fabs((a - b)/a) <= 10 * FLT_EPSILON);
}
return 0;
}
On obtient sur le moniteur l'affichage :
a | b | a == b | |(a - b)/a| <= 10 * ESP
0.10000000 | 0.10000000 | 1 | 1
0.20000000 | 0.20000000 | 1 | 1
0.30000001 | 0.30000001 | 1 | 1
0.40000001 | 0.40000001 | 1 | 1
0.50000000 | 0.50000000 | 1 | 1
0.60000002 | 0.60000002 | 1 | 1
0.70000005 | 0.69999999 | 0 | 1
0.80000007 | 0.80000001 | 0 | 1
0.90000010 | 0.89999998 | 0 | 1
où l'on observe que :
- le test d'égalité direct n'est pas toujours évalué vrai (ce qui est logique car les valeurs ne sont pas identiques) ;
- alors que le test de différence relative minime est fiable, la différence entre les deux valeurs ne s'exprimant qu'au 7e chiffre significatif.
Fonctions sur les valeurs de types flottants
Fonctions mathématiques
On a vu au chapitre C2‑IV que les bibliothèques standards des langages C et C++ mettent à disposition du codeur de nombreuses fonctions mathématiques qui opèrent sur des valeurs de types flottants, notamment dans le fichier d'en‑tête math.h C (cmath pour le C++).
Toutefois, quelques précautions s'imposent au regard du typage des arguments que ces fonctions prennent, même si la plupart sont en fait définies par des macro-commandes génériques qui s'adaptent aux différents types flottants standards du langage. À titre d'exemples, on peut citer :
- la fonction valeur absolue, qui a pour identificateur générique
fabsC (et non pasabs, qui ne prend que des arguments de typeint) ; - la fonction puissance, qui a pour identificateur générique
powC et qui nécessite l'ajout de la directive#include <tgmath.h>pour pouvoir être opérationnelle sur des données de typelong double.
Il est donc vivement recommandé de consulter les pages que des sites comme cppreference consacrent à ces fonctions avant de les employer, car il est difficile pour un codeur débutant de savoir (ou même, quand on a un peu d'expérience, de se souvenir) de toutes leurs particularités.
Fonctions de test et de manipulation
En plus des fonctions mathématiques usuelles, le fichier math.h donne accès à nombreuses fonctions qui permettent de manipuler ou de tester différents aspects d'une valeur de type flottant. À titre d'exemples, on peut citer :
Encore une fois, il est opportun de consulter un site comme cppreference C lorsque l'on souhaite coder une manipulation particulière sur des données décimales, car une fonction idoine peut déjà exister et il serait dommage de ne pas en profiter, plutôt que perdre (beaucoup) de temps à la réinventer, et souvent dans une version moins fiable et moins portable…