En programmation, d'une façon générale, le type d'une donnée est une appellation catégorielle – entier, décimal, caractère, etc.) – qui détermine les valeurs qu'elle peut prendre, avec inévitablement des limites du fait que l'espace mémoire alloué pour stocker la donnée n'est pas infini.
On rappelle (cf. C2‑III ) qu'en langages C et C++, lors de la déclaration d'une donnée nommée (qui est un préalable à toute utilisation de cette dernière), le codage de son type est obligatoire et définitif. A contrario, dans des langages interprétés comme Matlab ou Python, le typage des données peut être implicite et dynamique (une variable pouvant ainsi prendre des valeurs de différents types au cours de l'exécution d'un programme).
Le typage des données est donc un aspect essentiel du codage en C/C++ et c'est pourquoi presque toute la partie C3 de ce module de formation y est consacrée – et sachant qu'elle se limite aux types élémentaires.
Mais avant d'aborder en détail ces différents types, ce chapitre préliminaire se donne pour objectif de présenter les bases du typage des données, à savoir :
- la classification générale des types de données et leurs principales caractéristiques ;
- la structure de la mémoire – essentielle pour comprendre ultérieurement l'encodage des données ;
- la syntaxe des descripteurs de types, qui est indispensable au codage des déclarations de données ;
- et enfin, des aspects plus approfondis – tailles, contraintes d'alignement – pour maîtriser le choix des types de données que l'on est amené à déclarer dans un programme.
Attention : la bonne compréhension de tous ces aspects nécessite quelques connaissances préalables en numération qui ne seront que succinctement rappelées. En cas de lacunes, on pourra se reporter à ce cours et ce sujet de travaux dirigés de Sciences de l'ingénieur.
Principes généraux du typage
Classification générale des types
En langages C et C++, on peut distinguer deux catégories principales de types de données :
- les types élémentaires, dit encore primaires ;
- les types dérivés, qui sont construits à partir de types élémentaires.
Les normes respectives des langages C et C++ n'emploient pas le même vocabulaire pour classer les catégories de types de données :
- la norme du langage C parle de types dérivés mais pas de types élémentaires, bien que ce terme soit d'usage courant dans la littérature ;
- la norme du langage C++ parle de types fondamentaux (fundamental types) et de types composés (compound types).
Les types élémentaires
Les types élémentaires sont peu nombreux (moins d'une vingtaine) et standards au langage – même si certaines de leurs caractéristiques sont parfois dépendantes de l'implémentation (cf. chap C2‑II ).
Ils spécifient des ensembles discrets (c'est‑à‑dire non continus, au sens mathématique du terme) de valeurs numériques qui peuvent être :
- booléennes, avec seulement deux valeurs possibles (
0et1) ; - entières avec, pour chaque type, une valeur minimale négative ou nulle et une valeur maximale positive délimitant l'ensemble des valeurs encodables dans le type, de la forme :
{MIN, … ,0, … ,MAX} ou {0, … ,MAX} - décimales avec, pour chaque type, en valeurs absolues, deux valeurs minimales très petites (normalisées et dénormalisées), une valeur maximale très grande délimitant l'ensemble des valeurs encodables de la forme :
{−MAX, … , −MIN, … , −TRUE_MIN,0,TRUE_MIN, … ,MIN, … ,MAX}
avec des limites de précision.
Quant aux types caractères simples, ils n'ont pas de type spécifique en langages C/C++ – et ce bien qu'il existe un type nommé char. En fait, ils constituent simplement une interprétation particulière d' entiers.
En langages C/C++, il existe aussi :
- le type vide, désigné par mot‑clef
void; il ne constitue pas à proprement parler un type de donnée (il ne comporte aucune valeur) mais sert à définir certaines fonctions (cf. chap. C4‑I ) et pointeurs (cf. chap. C5‑II ) ; - des types de données complexes au sens mathématique du terme, c'est‑à‑dire avec des valeurs issues de l'ensemble ℂ ; ils ne sont pas abordés dans le cadre de ce module de formation.
Tous les types élémentaires sont détaillés au fil des différents chapitres de cette partie C3 du cours.
Les types dérivés
Les types dérivés sont des types de données codés dans les programmes à partir de types élémentaires, à l'aide de procédés constructeurs pour former :
- des énumérations,
- des pointeurs,
- des tableaux,
- des structures hétérogènes par juxtaposition et superposition.
Ces procédés constructeurs permettent de définir des types sans limite de variété.
À l'exception des énumérations (au regard de la remarque A supra), les types dérivés de données ne seront abordés que dans la partie C5 du cours.
Notion de type scalaire
On parle de type scalaire pour désigner un type de données élémentaire ou dérivé – éventuellement synonyme, cf. infra – dont chaque valeur est représentable respectivement par un seul nombre. En conséquence :
- ne sont pas scalaires, les types de tableaux et de structures hétérogènes ;
- a contrario, tous les autres types, y compris les pointeurs, sont scalaires.
La notion de type scalaire est importante notamment pour caractériser les possibilités de conversions de valeurs d'un type vers un autre type (cf. chap. C3‑VI ).
Caractéristiques générales des types élémentaires
De façon générale, un type élémentaire présente différentes caractéristiques, notamment les suivantes : son descripteur, sa taille, son étendue, son format d'encodage et sa syntaxe de saisie dans le code.
Certains caractéristiques peuvent être exploitées dans les programmes – par exemple, la taille – alors que d'autres sont juste des notions utiles pour la bonne compréhension du codeur.
Détaillons ces caractéristiques.
- Le descripteur, qui peut être simple ou composé, est codé sous forme de mots‑clefs dans les déclarations de données ou les conversions de valeurs. Il sert aussi à désigner le type dans le méta‑langage.
-
unsignedqui spécifie que les valeurs de ce type sont sans signe, c'est‑à‑dire positives ou nulles ; -
shortqui spécifie que les valeurs de ce type ont une petite étendue (pour se faire une idée, moins de cent mille). - La taille (size) est le nombre d'octets nécessaires pour stocker une valeur de ce type en mémoire.
- L'étendue (range), est l'intervalle (ou la réunion des intervalles) des valeurs encodables dans ce type. Elle est déterminée par la taille et le format.
- Le format d'encodage est la représentation en mémoire (par valeurs des bits) des valeurs du type lors de l'exécution d'un programme.
- La syntaxe est l'ensemble des règles de codage des valeurs dans un fichier source. On peut aussi y ajouter par extension les règles de saisie et d'affichage dans le cadre d'entrées‑sorties sur un terminal d'exécution.
Le descripteur unsigned short est un descripteur de type entier (implicitement, int, ce mot‑clef pouvant ici être omis) composé de deux mots‑clefs :
Le type unsigned short a une taille de 2 octets, quelle que soit l'implémentation (attention, ce n'est pas le cas pour tous les types).
L'étendue du type unsigned short est l'intervalle des entiers naturels {0, … 65 535}.
Les valeurs du type unsigned short sont encodées au format binaire naturel, c'est‑à‑dire :
0, 1, 10, 11, 100, etc.
respectivement pour les entiers naturels 0, 1, 2, etc.
Pour spécifier dans le code source qu'une constante numérique appartient à un type unsigned, on lui adjoint le suffixe U, comme par exemple 1000U pour coder la valeur « mille ». Sans ce suffixe, la constante numérique 1000 serait interprétée par défaut dans le type int par le compilateur.
Déclaration de types synonymes
En langages C et C++, il est possible de déclarer un nouvel identificateur de type comme étant synonyme d'un descripteur de type, élémentaire ou dérivé.
Cet identificateur ne code pas un nouveau type, mais simplement d'un alias d'un type élémentaire ou d'un type dérivé déjà déclaré.
On code la déclaration d'un type synonyme d'un type élémentaire par une instruction de la forme simple W :
typedef
descripteur de type
identificateur;
où l'identificateur est le nom choisi par le codeur pour désigner le nouveau descripteur synonyme du descripteur de type initial.
En observance de bonne pratique (cf. chap. C2‑X ), on code usuellement cet identificateur avec une majuscule initiale.
Pour des déclarations de données, on peut alors employer ce nouvel identificateur à la place du descripteur de type dont il est synonyme, constantes ou variables.
- Cette pratique particulièrement utile pour les types dérivés ayant un descripteur très composé, notamment les tableaux (cf. chap. C5‑III ). Attention, cependant, les déclarations obéissent alors à des formes syntaxiques plus complexes, elles seront étudiées au cas par cas.
- C'est également utile lorsque l'on souhaite modifier facilement le type de nombreuses données dans un programme. En les déclarant via un type synonyme, une simple modification de cette définition suffit pour impacter toutes les données déclarées (c'est un principe analogue à celui qui opère lorsqu'on déclare une constante pour représenter diverses occurrences d'une même valeur numérique dans un programme).
- Dans un programme effectuant des calculs sur des grandeurs électriques (tension, courant, etc.), on pourrait coder la définition de trois synonymes du type élémentaire
floatcomme ci‑dessous : - Dans un programme effectuant des calculs sur un circuit doté de plusieurs résistors, chacun défini par ses bandes de couleurs déclaré comme un tableau constant de 4 entiers (cf. chap. C2‑VI ), il est commode de déclarer préalablement un tel type pour pouvoir ensuite déclarer plusieurs résistors de ce type, par exemple comme ceci :

typedef float Voltage; typedef float Amperage; typedef float Power;
int main(void)
{
Amperage nominalCurrent = 3.0;
Voltage nominalVoltage = 12.0;
Power nominalPower = nominalVoltage * nominalCurrent;
//...
Amperage, il suffirait de changer la définition de ce dernier en utilisant par exemple le descripteur double. nominalPower ne nécessite aucune conversion explicite, ce qui est bien commode, car ce calcul est conforme aux lois de la physique. nominalVoltage = nominalCurrent + 3;

typedef const int Strip_R[4];
Strip_R resistor_R1 = {1, 0, 2, 5}; // 1K: black - brown - red - gold
Strip_R resistor_R2 = {4, 7, 2, 5}; // 4.7K: yellow - purple - red - gold
Il existe une autre possibilité de définir un type synonyme en utilisant une directive #define (cf. chap. C4‑III ). C'est par exemple ainsi que l'identificateur bool était défini en langage C jusqu'à la norme C17 incluse, comme synonyme du type _Bool dans le fichier d'en‑tête stdbool.h de la bibliothèque standard (cf. chap. C3‑III ).
Structure de la mémoire
Pour bien comprendre certains aspects du typage de données comme les notions de taille ou d'adresse et les contraintes d'alignement (cf. infra ), il est nécessaire d'avoir quelques connaissances sur la technologie des mémoires. Pour tout approfondissement, on pourra consulter le lien suivant W.
Cellule mémoire – Notion de bit
Dans l'architecture matérielle d'un système numérique (ordinateurs, carte à microcontrôleur, etc.), les données sont le plus souvent stockées en mémoire vive (RAM – random access memory) W :
- cette technologie offre un temps d'accès très court, ce qui est essentiel pour la rapidité des traitements ;
- son principal inconvénient est d'être volatile (elle doit rester sous tension pour conserver l'information).
Les unités de mémoire vive sont constituées de cellules, des circuits électroniques essentiellement à base de transistors. Sauf pour des applications spéciales (notamment les bus), les cellules mémoires sont conçus pour n'avoir que deux états stables :
- l'état bas, interprété comme la valeur binaire
0; - l'état haut, interprété comme la valeur binaire
1.
L'information dans une cellule mémoire est appelée bit, abréviation du nom composé anglais binary digit, c'est‑à‑dire « chiffre binaire ».
Elle ne peut donc prendre que deux valeurs : 0 ou 1.
Il existe principalement deux technologies de mémoire vive :
Mémoire vive statique
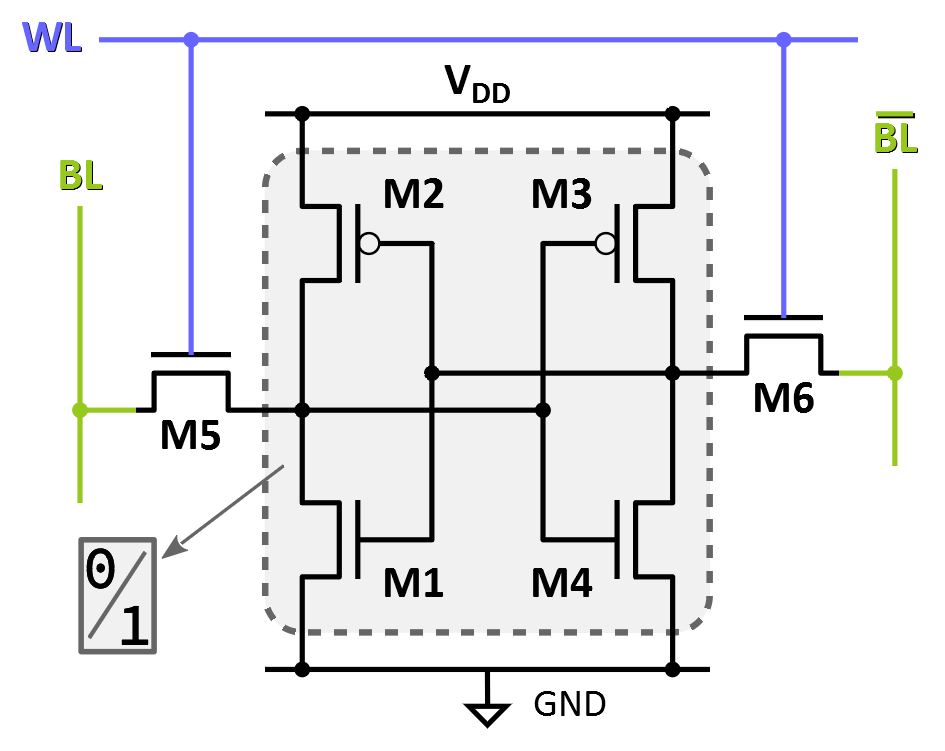
Le schéma électronique ci‑contre représente une cellule mémoire SRAM typique. Elle est constituée de 6 transistors CMOS W dont 4 forment un verrou (latch) à deux inverseurs logiques en boucle (transistors M1 à M4) :
- la cellule est rendue accessible (enabled) par la mise à l'état haut de la piste conductrice
WL(word line) qui déclenche les transistorsM5etM6; - Les opérations de lecture et d'écriture sont mises en œuvre par la combinatoire des états haut et bas des pistes conductrices
BLetBL(bit lines).
La technologie SRAM est employée pour la mémoire intégrée dans les microcontrôleurs, en raison de ses bonnes performances en termes de rapidité d'accès et de faible consommation électrique. En contre-partie, elle n'offre qu'une faible densité de cellules, du fait de sa « complexité » (6 transistors pour une seule cellule).
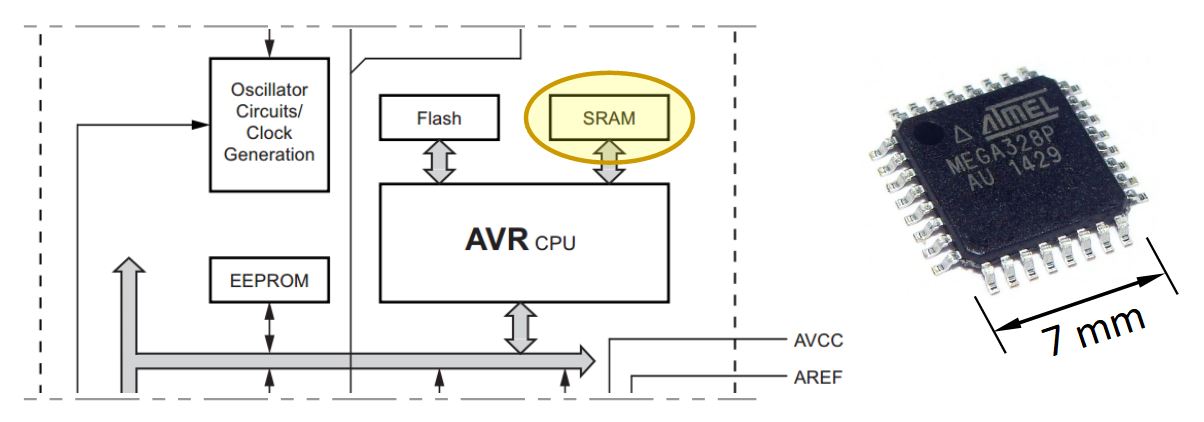
Le microcontrôleur Atmel ATmega328P intègre une unité de SRAM de 2048 ko (2048 lignes de largeur 8 bits). Cela peut sembler peu mais cette unité tient dans un très petit espace – une toute petite partie du composant en fig. ci‑dessous.
Mémoire vive dynamique
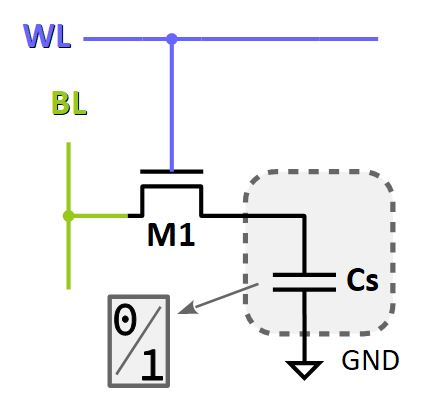
Le schéma électronique ci‑contre représente une cellule mémoire DRAM (dynamic random access memory) typique :
- le transistor FET W
M1joue le rôle d'interrupteur pour l'accès à la cellule, déclenché par mise à l'état haut de la pisteWL(word line) ; - l'information est mémorisée par un simple condensateur
Cs(storage condensator) ; une seule pisteBL(bit line) suffit pour effectuer les opérations de lecture et d'écriture.
Comme le condensateur se décharge en permanence, la cellule doit être rechargée périodiquement (avec une période de l'ordre de la milliseconde) pour garder son information, d'où le terme de mémoire dynamique. C'est un inconvénient en termes de consommation électrique.
La technologie DRAM est employée pour les barrettes de mémoire montées sur les cartes mères des ordinateurs, car elle offre une très haute densité de cellules.
La barrette mémoire en photo ci‑dessous comporte 8 puces de 1 Go chacune de SDRAM (synchronous DRAM) DDR4 (double data rate 4th generation) ; elle coûte seulement 40 € environ.

Unité de mémoire – Notion d'octet
Cas d'un microcontrôleur 8 bits
Dans les microcontrôleurs Atmel à cœur AVR 8 bits employés dans les cartes Arduino, la mémoire vive est structurée en une matrice à 8 colonnes de bits. Cette adéquation entre la largeur du bus et celle de la mémoire optimise les opérations de lecture et d'écriture des données stockées.
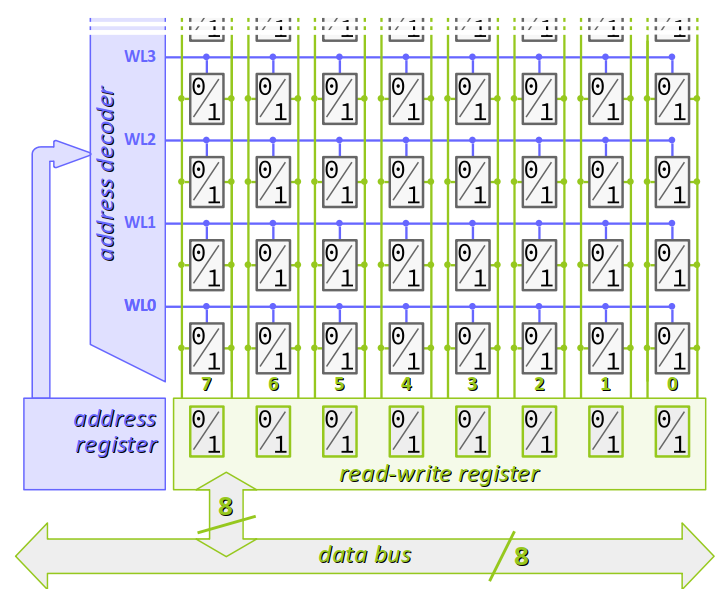
- On parle alors de « mot » de 8 bits pour désigner l'information stockée dans une ligne de la mémoire.
- Chaque bit d'un mot est repéré par le numéro d'ordre de ses pistes bit lines dans la matrice, qu'on appelle le rang du bit dans le mot.
D'un modèle de microcontrôleur AVR à l'autre, seul change le nombre de lignes, par exemple :
- 2048 pour l'Atmel ATmega328P qui équipe les cartes Uno,
- 8092 pour l'Atmel ATmega2560 qui équipe les cartes Mega…
Cas des architectures plus larges
Sur les architectures plus larges – carte à microcontrôleur 32 bits, ordinateurs 64 bits – la mémoire vive est organisée en matrices de largeur appropriée, respectivement 4 × 8 bits ou 8 × 8 bits. Toutefois – et y compris sur d'autres types de mémoires (ROM, mémoire de masse, etc.) – pour des raisons à la fois historiques et d'optimisation d'emploi des bits, la mémoire est toujours gérée en gardant le mot de 8 bit comme unité d'adressage.
Dans le cas d'une mémoire vive de largeur 32 bits comme sur la figure ci‑dessous, les word line sont numérotées de 4 en 4 puisqu'elles contiennent chacune 4 octets.

Pour effectuer une opération sur une donnée stockée sur un seul octet d'une ligne, le mot entier est copié dans un registre et le microcontrôleur lui applique une opération bit à bit avec un masque pour « cacher » les octets non concernés (cf. chap. C3‑III ).
Notion d'octet
Un octet (en anglais, byte) est un groupe ordonné – on dit aussi un multiplet – de 8 bits W :
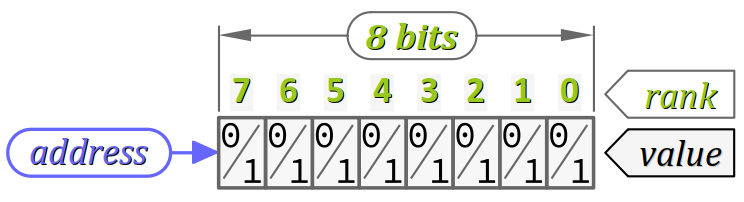
- les bits d'un octet y sont repérés par leur rang, c'est‑à‑dire leur numéro d'ordre, qui va de 0 à 7 ;
- l'adresse d'un octet donne sa position absolue dans la mémoire, techniquement appelée word line.
Plus précisément, on parle de 8‑bit byte, le terme byte signifiant non pas « octet » mais « morceau ». Néanmoins, on emploie presque toujours simplement le terme byte car les cas où l'unité d'adressage ne fait pas exactement 8 bits sont très rares aujourd'hui (cf. le lien W donnant des détails historiques sur la notion d'octet).
Par la combinatoire de ses bits, un octet peut encoder 256 valeurs (28).
Registres de calcul
Dans le cœur d'un microprocesseur ou d'un microcontrôleur, les opérations de calcul sont effectuées sur des données qui ont été préalablement transférées depuis la mémoire dans des registres W. On peut dire que les données y sont temporairement enregistrées.
Les registres sont des unités de mémoire vive situées au plus près de l'unité arithmétique et logique – en anglais, arithmetic and logic unit, ou ALU – qui effectue les calculs.
- Ils sont réalisés en technologie SRAM pour des questions évidentes de rapidité d'accès.
- Leur largeur (en bits) est celle de la capacité des circuits de calcul de l'ALU, en général identique à celle du bus du processus.
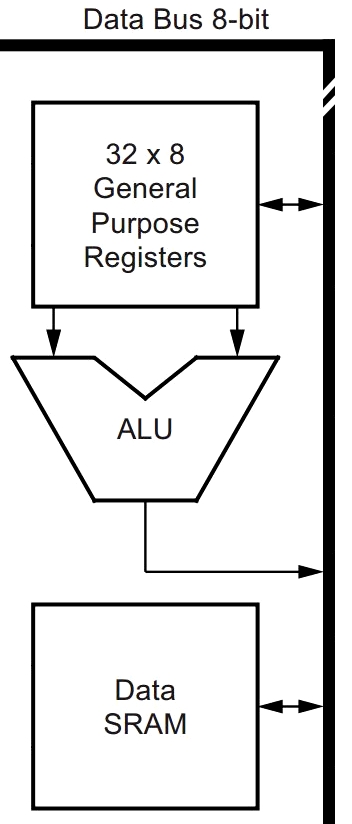
Le cœur AVR 8 bits des microcontrôleurs employés sur la plupart des cartes Arduino dispose de 32 registres d'usage général (general purpose registers). Ce nombre important permet de compenser la petite taille de l'architecture (cf. le schéma ci‑contre).
En particulier, le microcontrôleur peut très bien effecter une opération (addition, multiplication, etc.) sur deux données codées l'une et l'autre dans un type de taille 8 octets, en mobilisant pour cela 3 × 8 = 24 registres (8 registres pour chaque opérande et 8 registres pour le résultat).
Toutefois, si le programme est soumis à des exigences de vitesse, il faut veiller à ne pas employer des types surdimensionnés. En effet, en plus du temps nécessaire pour charger les opérandes et décharger le résultat dans la mémoire, il faut aussi compter le temps d'effectuer les calculs, octet par octet, et l'impact que représente l'occupation d'autant de registres, au détriment d'autres usages pour optimiser l'exécution.
On comprend également pourquoi les types très grands types comme long double ne sont pas implémentés à leur taille usuelle (12 octets – cf. chap. C3‑V ) sur une telle architecture ; sinon, il faudrait mobiliser 36 registres, or il n'y en a que 32 !
Conventions de boutisme
Dans un contexte informatique, le boutisme W – en anglais, endianness – est la convention qui détermine l'ordre de stockage des octets consécutifs d'une donnée dans la mémoire au sens large (mémoire vive, fichier, etc.).
Typiquement, ce stockage est effectué dans l'ordre croissant des adresses de la mémoire de deux manières possibles.
- Soit on commence par l'octet de bas rang – également dit de poids faible pour les données numériques, ou encore LSB pour least significant byte – et on parle alors de petit‑boutisme, en anglais little‑endianness (cf. la figure ci‑contre pour une donnée encodée sur 4 octets).
- Soit on commence par l'octet de haut rang – également dit de poids fort pour les données numériques, ou encore MSB pour most significant byte – et on parle alors de gros‑boutisme, en anglais big‑endianness (cf. la figure ci‑contre pour une donnée encodée sur 4 octets).
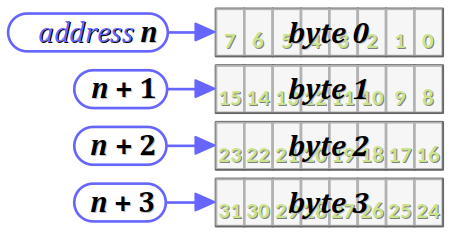

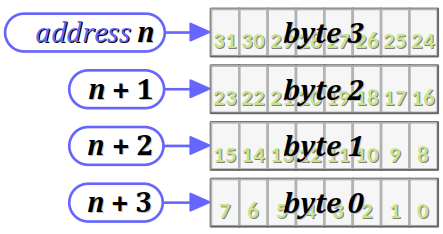


Le choix d'une convention de boutisme est avant tout opéré dans la conception des architectures matérielles des processeurs, du fait que les octets sont traités par mots – typiquement, de 8 octets sur un processeur 64 bits. Leur position relative dans le mot n'est pas indifférente pour l'implémentation des circuits de calcul.
Certaines architectures peuvent même gérer les deux conventions et on parle alors de bi‑boutisme. De plus, les microprocesseurs récents (x86, ARM) possèdent en général une instruction qui opère la permutation de convention d'un mot mémoire.
La convention de boutisme est également un choix décisif pour les protocoles de communication, qui détermine l'ordre dans lequel les octets sont transmis et reçus sur une liaison.
Bien entendu, le système d'exploitation peut adopter une autre convention que celle de l'architecture pour tel ou tel aspect mais au prix de traitements supplémentaires.
- Le petit‑boutisme est la convention adoptée par la grande majorité des architectures des machines – notamment celles à processeur x86 W – et tous les systèmes d'exploitation (Linux, Windows) suivent cette convention. Quant aux processeur de la famille ARM W, ils sont bi‑boutistes mais adoptent le petit‑boutisme par défaut.
- Le gros‑boutisme quant à lui est la convention adoptée pour la mise en œuvre des protocoles de communication, en particulier avec la pile de protocoles TCP/IP. Les octets y sont le plus souvent traités en mots de 32 bits et c'est toujours l'octet de haut rang qui est envoyé en premier. Si les machines qui communiquent sont opérées en petit‑boutisme, leur systèmes d'exploitation respectifs sont capables d'effectuer le changement de convention avec les composants matériels de la liaison (interface réseau – cf. chap. R2‑I ).
endian.h pour la bibliothèque Glibc de Linux). Quant aux conventions de boutisme adoptées pour l'encodage des caractères larges, il sera abordé au chap. C3‑IX .
Descripteurs de types élémentaires
Les types élémentaires du langage C
En langages C/C++, pour composer un descripteur de type élémentaire, on dispose des mots‑clefs :
bool char int float double short long signed unsigned
sachant que pour pouvoir utiliser le mot‑clef bool, une directive d'inclusion du fichier d'en‑tête stdbool.h est requise jusqu'à la norme C17 incluse (cf. chap. C3‑III ).
En termes d'usage intuitif (c'est‑à‑dire sans présumer des aspects syntaxiques complexes formalisés par les normes des langages C/C++), on peut classer ces mots‑clefs comme ci‑dessous.
- On a les mots‑clefs qu'on peut considérer comme « fondamentaux »
bool,char,int,floatetdouble. -
bool(character) permet de déclarer des données booléennes, c'est‑à‑dire dont les valeurs numériques sont limitées à0et1(cf. supra). -
char(character) permet de déclarer des données de nombres entiers très courts. -
int(integer) permet de déclarer des données de nombres entiers standards, sachant que l'étendue des valeurs encodables dans ce type dépend de la machine cible pour laquelle le programme est compilé. -
float(floating point decimal) permet de déclarer des données de nombres décimaux à virgule flottante simple précision. -
double(double precision floating point decimal) permet de déclarer des données de nombres décimaux à virgule flottante double précision. - On a les mot‑clefs qu'on peut considérer comme « modificateurs »
short,signedetunsigned: -
shortetlong, en principe, décrivent un type ayant une taille respectivement diminuée et augmentée par rapport à la taille du type auquel le mot‑clef est appliqué. -
signedetunsignedadaptent le format d'un type entier, respectivement pour permettre ou non l'encodage de valeurs négatives, donc codées avec un signe «-». - Mais on a aussi des règles de composition et d'abréviation qui font que :
- Il n'est pas possible d'employer les mots‑clefs modificateurs
shortoulong« à tout‑va ». Seules certaines combinaisons ont un sens. - Par composition, certains mots‑clefs deviennent redondants et peuvent donc être omis, ce qui permet d'alléger le code.
- Les descripteurs
long int,long long int, etlong doublesont syntaxiquement valides : ils codent des types qui existent en langages C/C++. - Les trois descripteurs de type suivants :
-
signed short int, -
short int, -
short,
char » fait référence au fait que l'étendue des valeurs positives de ce type (0 à 127) permet d'encoder les caractères du jeu ASCII restreint (cf. W et le chap. C3‑VIII ). De ce fait, il est surtout utilisé pour déclarer des chaînes de caractères, comme on l'a vu au chapitre C2‑VII . Quoi qu'il en soit, lorsqu'on déclare une variable de type char, on peut toujours lui affecter des valeurs numériques au moins comprises entre 0 et +127 (pour plus de détails, cf. chap. C3‑II ). Le descripteur short int désigne un type d'entiers encodés sur 2 octets seulement, alors que le type int est encodé sur 4 octet sur les ordinateurs de type PC usuels.
Le descripteur unsigned int désigne un type d'entiers positifs ou nuls, autrement dit, non négatifs, donc sans signe « - ».
long bool ou long float sont non valides. Ils n'ont aucun sens et codent des types qui n'existent pas. signed et int sont redondants avec short qui décrit un type entier toujours signé. Par souci de concision, c'est donc le descripteur short qui est privilégié, car tout codeur un tant soit peu expérimenté sait qu'il s'agit d'un type entier. - À l'origine, et jusqu'à la norme C90 incluse, le mot‑clef
intétait tellement facultatif que toute donnée déclarée sans type se voyait attribuer par défaut le typeintpar le compilateur. Mais cette pratique était quand même déconseillée et, depuis la norme C99, elle déclenche une erreur. - Le mot‑clef
signed, qui s'applique seulement aux types entiers, peut sembler inutile parce que sur les PC usuels (architecture x86), les types entiers fondamentaux sont signés par défaut, et il n'est alors pas nécessaire de coder le modificateursigned.
char est par défaut non signé ! Pour des questions de portabilité, il est donc toujours préférable de coder signed char pour décrire un type char dont les données peuvent prendre des valeurs négatives. Types énumérés
Les langages C/C++ fournissent le mot‑clef enum pour déclarer des types énumérés et leurs données.
Ces données sont nécessairement à valeurs entières et ne doivent en principe prendre qu'un nombre réduit de valeurs, lesquelles sont désignées respectivement par autant d'identificateurs de constantes entières listées lors de la déclaration du type.
Techniquement (selon les normes), les types énumérés sont considérés comme des types dérivés, mais dans la pratique, en première « approximation », ils peuvent assimilés à des types entiers (en termes d'encodage, c'est‑à‑dire de stockage des valeurs en mémoire, ils utilisent les mêmes formats).
Attention : en langage C++, les données de types énumérés ne sont pas facilement manipulables comme les types entiers élémentaires.
L'étude des types énumérés est approfondie au chapitre C3‑IV .
Les types spécifiques de la bibliothèque Arduino

Le framework Arduino fournit au codeur les descripteurs byte et word (ce ne sont pas des mots‑clefs des langages C/C++) pour déclarer des mots binaires, c'est‑à‑dire des séquences de bits par multiples de 8.
Introduits dans le fichier d'en‑tête principal Arduino.h G, les descripteurs byte et word redéfinissent par typedef deux types synonymes d'entiers non signés :
-
byteest synonyme deunsigned char; -
wordest synonyme deunsigned int.
Même s'ils sont fondamentalement des types entiers, les descripteurs byte et word sont détaillés dans le chapitre C3‑III consacrés aux types de données booléennes car ils ont vocation à être manipulés avec des opérateurs booléens (bit par bit).
Détermination du type d'une expression
Toute expression (ou sous‑expression) codée dans un programme source possède implicitement un type, dans lequel sa valeur est temporairement encodée.
Lors de l'évaluation de l'expression, son type implicite est déterminé dans l'ordre de traitement des opérateurs qui la composent, en fonction des types de leurs opérandes, et conformément à des règles spécifiques à chaque opérateur.
Les types des valeurs que donnent les opérateurs élémentaires sont globalement décrits dans le tableau du chap. C2‑IV , sachant que :
- dans le cas des opérateurs booléens et de comparaison, il s'agit toujours du type
int; - mais dans le cas des autres opérateurs, le type de la valeur dépend avant tout de celui des opérandes.
Règles générales de détermination du type implicite d'une opération
Pour garantir le meilleur résultat possible lors de l'évaluation d'une opération, le compilateur applique les règles générales suivantes.
- Avant le traitement d'une opération, sauf pour la l‑value d'une affectation (cf. chap. C2‑IV ), chacun des opérandes est implicitement promu dans un type suffisamment grand pour minimiser les risques de débordements (cf. chap. C3‑VI ), typiquement :
- pour les entiers, au moins le type
int– éventuellementunsigned; - pour les décimaux, au moins le type
double. - Ensuite, tout dépend de l'opérateur et du typage des opérandes (après éventuellement promotion).
- dans le cas d'un opérateur unaire, le type de la valeur est le même que celui de l'opérande ;
- dans le cas d'un opérateur binaire :
- si l'opération est homogène – typiquement, entre deux opérandes de types entiers, ou de deux types décimaux – alors le type de la valeur est le plus grand des deux ;
- si l'opération est hétérogène, alors le type décimal prime sur le type entier.
Le tableau ci‑dessous donne le type de l'opération binaire a * b où les opérandes a et b sont deux données déclarées chacune successivement dans différents types.
| Opérandes | b |
b |
b |
b |
||||
|---|---|---|---|---|---|---|---|---|
| Type déclaré | short |
long |
float |
long double |
||||
| Promotion | int |
– | double |
– | ||||
a * b |
int |
long |
double |
long double |
||||
Plus généralement, ces résultats de typage sont valables pour n'importe quel autre opérateur arithmétique ou algébrique.
Tailles des types et des objets – contraintes d'alignement
En langages C et C++, certaines caractéristiques des types – taille, valeurs extrêmes, contraintes d'alignement d'adresse – peuvent varier selon l'implémentation . Or ces informations sont parfois indispensable pour coder les instructions d'un programmes.
Plutôt que de laisser le codeur introduire ces caractéristiques sous formes de constantes littérales ou déclarées avec des valeurs extraites de documentations potentiellement obsolètes, les bibliothèques standards mettent à la disposition plusieurs outils :
- des fichiers de paramètres dimensionnels spécifiques aux types entiers et décimaux ; ils seront abordés dans leurs chapitres respectifs C3‑II et C3‑V ;
- des types adaptatifs comme
size_tetsize_type(pour ce dernier, en C++ seulement) ainsi que leurs éléments de syntaxe associés ; - les opérateurs généraux
sizeofetalignof– ou_Alignofen langage C jusqu'à la norme C17 incluse.
Le type size_t
Le descripteur size_t désigne un type entier non signé. Il est défini pour exprimer les valeurs rendues par l'opérateur sizeof.
La valeur maximale encodable dans le type size_t s'adapte à l'implémentation, afin qu'il permette d'exprimer la taille de n'importe quel objet, y compris un tableau, quel que soit son nombre d'éléments (donc potentiellement très grand).
Le type size_t n'est pas inclus dans le noyau du langage C, mais il est défini plusieurs fichiers d'en‑tête de sa bibliothèque standard, notamment stddef.h, stdlib.h, stdio.h et string.h. Sa définition, codée par de nombreuses directives de compilation conditionnelle, est très complexe (cf. par exemple G).
On peut déterminer la valeur maximale codable dans le type size_t sur une implémentation donnée en affichant la valeur de la variable d'environnement SIZE_MAX définie dans le fichier d'en‑tête stdint.h de la bibliothèque standard du langage C.
- Dans un programme pour carte Arduino, il suffit de coder l'instruction :
Serial.println(SIZE_MAX);
sans oublier d'initialiser préalablement le moniteur série (cf. chap. C3‑X ). - Dans un programme pour ordinateur doté de la chaîne de compilation GCC (pas Mingw‑g64), il suffit de coder l'instruction :
printf("%zu\n", SIZE_MAX);
où la spécification de conversion%zudans l'appel de la fonctionprintfest spécifique pour afficher les valeurs du typesize_t(cf. chap. C2‑VII ).
La variable d'environnement SIZE_MAX vaut :
- 65 535 dans un programme compilé pour une carte à processeur 8 bits (Arduino Uno, Nano, Mega, etc.) ;
- 4 294 967 295 dans un programme compilé une carte à processeur 32 bits (Arduino Due, Zero, ESP8266, etc.) ;
- 18 446 744 073 709 551 615 dans un programme compilé pour un ordinateur à architecture 64 bits et une chaîne de compilation adaptée à cette architecture (GCC ou Mingw‑w64).
- Sur un PC avec un système Windows, la spécification de conversion
%zun'est pas reconnue par la chaîne de compilation Mingw‑w64 (plus précisément, ce composant fait défaut dans la bibliothèque standard de Visual C++ qui se substitue à la bibliothèque standard GNU glibc). Il faut donc employer à la place la spécification de conversion du type entier ayant la même taille quesize_t, à savoir%I64u. - Le type
size_test souvent proposé par défaut par les éditeurs de code pour déclarer les indices d'itération des bouclesfor(et alors, une directive d'inclusion du fichierstddef.houstdlib.hest requise). Toutefois, ce choix n'est pas toujours optimal dans un programme Arduino. - En langage C++, il est recommandé d'utiliser préférentiellement le type
size_type, qui est plus générique quesize_t. Basé sur ce dernier, le typesize_typeest défini spécifiquement pour des classes d'objets itératifs commevectoroustring(cf. chap. C5‑VI ).
1 comme int8_t ou uint8_t (cf. chap. C3‑II ). L'opérateur sizeof
L'opérateur unaire sizeof est défini comme un mot‑clef du langage C. Il s'applique à un opérande pouvant être :
- un nom de type,
- ou une expression.
Il rend dans le type size_t la valeur de la taille – c'est‑à‑dire le nombre d'octets employés pour le stockage dans l'implémentation du programme – du type désigné ou de la valeur de l'expression que forme son opérande.
Attention ! Il est vivement recommandé d'encapsuler l'opérande de l'opérateur sizeof entre parenthèses () pour éviter des confusions.
Normalisé (cf. le brouillon de la norme C11 , section 6.7.7, p 136), le concept de « nom de type » est plus général que celui (approximatif) de descripteur de type introduit au chapitre C2‑III . Il permet que l'opérateur sizeof s'applique non seulement pour les types élémentaires, mais aussi à tous les types dérivés, dont les tableaux et les structures hétérogènes. Néanmoins, pour s'appliquer à certains de ces types dérivés (struct et union), il faut que le type ait été déclaré via typedef (ou que l'opérateur sizeof soit appliqué à une donnée déclarée de ce type).
Dans le tableau de classification des opérateurs du langage C, l'opérateur sizeof a le rang de priorité 2 (cf. chap. C2‑III ).
- L'expression
sizeof(unsigned int)prend la valeur (nombre d'octets) : -
2si le programme est compilé pour une carte Arduino à cœur AVR (Uno, Nano, Mega, etc.) ; -
4si le programme est compilé pour une carte Arduino à cœur ARM (Due, Zero, etc.) ou un PC ; - L'expression
sizeof(1 + 0.1)prend la valeur (nombre d'octets) : -
4si le programme est compilé pour une carte Arduino à cœur AVR (Uno, Nano, Mega, etc.) ; -
8si le programme est compilé pour une carte Arduino à cœur ARM (Due, Zero, etc.) ou un PC ;
Lors de l'évaluation d'une expression composée avec l'opérateur sizeof, son opérande n'est pas évalué, même s'il s'agit d'une expression (seule sa taille est déterminée).
L'opérateur alignof
Problématique
On a vu supra que sur des architectures 32 ou 64 bits, la mémoire vive est organisée en mots de 4 ou 8 octets . Mais comme il peut y avoir des données de taille inférieure à la largeur d'un mot mémoire, il ne serait pas judicieux de stocker systématiquement les données les unes immédiatement à la suite des autres au fil de leur déclaration dans le code source. En effet, des données pourraient se trouver à cheval sur deux mots mémoire alors qu'elles pourraient tenir sur un seul mot si elles étaient décalées.
Or une donnée stockée à cheval sur deux mots mémoires nécessite deux temps de processeur – au lieu d'un seul normalement – pour être chargée en registre. C'est pourquoi le compilateur détermine lui‑même des contraintes d'alignement pour les adresses attribuées aux données afin de minimiser les chevauchements sur plusieurs mots.
Supposons qu'une donnée A de taille 4 octets soit stockée à cheval sur deux mots mémoire comme sur la figure ci‑dessous.

Pour y accéder, en lecture ou en écriture, il faut transférer deux mots mémoire en registre. Pour une meilleure vitesse d'exécution, il est donc préférable de l'aligner sur un seul mot mémoire en décalant la donnée C d'un mot vers le haut, comme ci‑dessous :

Remarque : cette organisation est moins performante en termes d'occupation de la mémoire, mais cet aspect est jugé moins important que la vitesse, surtout sur les machines où la mémoire est largement disponible (postes de travail, etc.).
Notion de contrainte d'alignement – octets intercalaires
La contrainte d'alignement W d'une donnée en mémoire est la valeur entière positive dont son adresse mémoire doit être multiple.
Pour satisfaire aux contraintes d'alignement des données déclarées dans un programme, le compilateur réserve en mémoire des octets intercalaires – en anglais, padding bytes – entre les données consécutives. Le contenu de ces octets est inutilisable.
Sur la 2e figure de l'exemple supra, deux octets intercalaires sont insérés à la fin de la ligne WLi.
En règle générale, une contrainte d'alignement dépend :
- de la taille t du type de la donnée ;
- de la taille n de l'architecture de la machine cible ;
- de l'implémentation, c'est‑à‑dire des « choix » opérés par le compilateur.
La règle générale est que l'adresse en mémoire de la donnée doit être un multiple de sa taille t (ou de celle d'un de ses éléments s'il s'agit d'une donnée de type tableau), modulo la taille n de l'architecture.
Toutefois, le compilateur peut déroger à cette règle pour des questions d'optimisation. Et pour les types dérivés tels que les structures hétérogènes, le calcul d'une contrainte d'alignement peut être complexe ; d'où l'intérêt de l'opérateur _Alignof qui permet au codeur de connaître et d'exploiter la contrainte d'alignment d'une donnée ou d'un type.
L'opérateur alignof
L'opérateur unaire alignof (ou _Alignof en langage C jusqu'à la norme C17 incluse) est un mot‑clef. Il s'applique à un opérande pouvant être :
- un nom de type,
- ou une expression.
Il rend dans le type size_t la valeur du nombre dont doit être multiple, dans le code exécutable du programme, l'adresse d'une donnée du type spécifié par le nom ou identique au type de l'expression que constitue son opérande.
Comme pour l'opérateur sizeof, l' opérateur alignof doit être employé en codant son opérande entre parenthèses ().
De façon générale, l'expression académique alignof(long double) prend la valeur :
-
1si le programme est compilé pour une carte à cœur AVR (Uno, Nano, Mega, etc.) ; en effet, sur une architecture 8 bits, il n'y a a priori aucune contrainte d'alignement quel que soit le type considéré ; -
8si le programme est compilé pour une carte à cœur ARM (Due, Zero, etc.) ; dans cette implémentation, c'est aussi la taille du typelong double(lequel a la même taille – et donc, la même précision – que le typedouble) ;

On voit que la règle générale évoquée supra est prise en défaut au regard des deux dernières valeurs obtenues : le compilateur impose une contrainte d'alignement supérieure à la taille de l'architecture.
Comme avec l'opérateur sizeof, lors de l'évaluation d'une expression composée avec l'opérateur alignoff, son opérande n'est pas évalué, même s'il s'agit d'une expression (seule sa contrainte d'alignement est déterminée).