Les structures de données de type tableau ont été abordées superficiellement dès le chapitre C2‑VI, pour pouvoir en faire un usage simple dans des programmes. On avait alors notamment introduit :
L'essentiel du chapitre avait été consacré à la déclaration des données de type tableau et leur utilisation dans un programme, c'est‑à‑dire leur accès en lecture et écriture.
Toutefois, par souci pédagogique de simplicité, divers aspects avaient été sciemment omis – en particulier le typage des tableaux – faute d'avoir préalablement étudié la notion de pointeur de donnée, qui est incontournable en la matière.
Maintenant que ce prérequis est satisfait (cf. les chap. C5‑I et C5‑II ), il est possible de reprendre l'étude des tableaux de façon beaucoup plus approfondie. Dans ce chapitre, on aborde notamment :
- toutes les particularités syntaxiques de la déclaration d'un tableau (dimension, nombre d'élément, liste d'initialisation) ;
- le typage et l'encodage en mémoire d'un tableau ;
- l'identification d'un tableau et de ses éléments par pointeur de donnée, et la véritable définition de l'opérateur d'indexation
[].
Et comme ces aspects sont très techniques, on les étudie en premier lieu pour les tableaux unidimensionnels, pour pouvoir ensuite les généraliser aux tableaux multidimensionnels.
Quant aux manipulation des tableaux – et tout spécialement via des fonctions (comme argument ou comme valeur de retour), elles seront abordées au chapitre C5‑III .
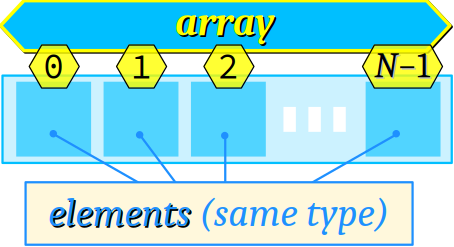
Tableaux unidimensionnels
Dans divers langages de programmation (Pascal, Delphi, Ada…), on déclare un tableau à l'aide du mot‑clef array. Les langages C et C++ sont plus symboliques : il n'y a pas de mot‑clef spécifique pour déclarer littéralement un tableau ; seuls les délimiteurs – une paire de crochets [] – codent symboliquement le fait qu'un nouvel identificateur désigne une donnée de type tableau et non pas une donnée scalaire (de même qu'une paire de parenthèses distingue un identificateur de fonction par rapport aux autres catégories d'identificateurs – cf. chap. C4‑I ).
Déclaration d'un tableau unidimensionnel
En langages C et C++, la syntaxe déclarative usuelle d'une donnée de type tableau unidimensionnel est la suivante :
descripteur de type identificateur du tableau [nombre d'éléments] [= {liste d'expressions}];
Cette syntaxe reprend la forme générale de la déclaration d'une donnée scalaire (cf. chap. C2‑III ) avec, en plus, le symbole déclaratif des crochets [] entre lesquels on peut coder nombre d'éléments du tableau.
Sur cette forme syntaxique, on peut apporter les précisions suivantes :
- L'expression nombre d'éléments code définitivement le nombre d'éléments que le tableau peut contenir au maximum. C'est donc une valeur cardinale qui est fixée pour toute la durée de vie de la donnée déclarée.
- en langage C, une expression constante entière (cf. chap. C2‑II ) – et ce quelle que soit la classe d'allocation, statique ou automatique, du tableau ;
- en langage C++ :
- La liste d'expressions entre accolades – séparées les unes des autres par le symbole
,– code l'affectation séquentielle de valeurs initiales aux différents éléments du tableau, dans l'ordre de leur indice respectif. - si le tableau est déclaré constant, autrement dit si le mot‑clef
constfigure dans son descripteur de type (comme pour une donnée scalaire) ; - ou le nombre d'éléments du tableau n'est pas codé entre les crochets ; dans ce cas, c'est le nombre d'expressions de la liste qui détermine implicitement le nombre d'éléments du tableau.
- de façon ciblée, par indexation directe de la forme :
[nº d'élément] = expression d'initialisation - et même ainsi, de façon groupée via la forme :
[nº d'élément 1 ... nº d'élément 2] = expression d'initialisation - les numéros d'éléments qui doivent être des expressions constantes entières ;
- les expressions d'initialisation qui doivent être des expressions constantes.
- Le code :
const uint8_t BUTTON_PIN[] = {2, 5, 7, 13};
déclare une constante de type tableau de 4 entiers non signés codés sur 8 bits chacun (uint8_t), valant respectivement2,5,7et13. Le nombre d'éléments du tableau n'étant pas explicitement codé entre les crochets, il est implicitement déterminé par le nombre d'éléments de la liste d'expressions. - Le code :
short duration[3] = {60, 5, 90}; - Le code :
float temperature[24] = {0.0}; - En langage C seulement, le code :
double pressure[5] = {[0] = 10.0, [1] = 20.0, [2 ... 4] = 30.0};
déclare une variable de type tableau de 5 décimaux (flottants double précision) initialisés aux valeurs : -
10.0,20.0respectivement pour les deux premiers éléments ; -
30.0pour les trois derniers éléments.
for, même si ces numéros ne sont pas consécutifs. 60, 5 et 90 par initialisation. Cette déclaration aurait pu aussi être codée short duration[] = {60, 5, 90};. 
0.0. 
float temperature[24] = {20.0};
alors seul le premier élément du tableau serait initialisé à la valeur
20.0. Les autres éléments seraient implicitement initialisés à la valeur 0.0. La déclaration d'un tableau présente d'autres points communs avec celle d'une donnée scalaire. Ceux évoqués ci‑après ne sont pas les seuls mais ils méritent une attention particulière.
- On peut préalablement déclarer un type synonyme de tableau avec le mot‑clef
typedef(cf. chap. C3‑I ). - Si un tableau est déclaré de classe statique (autrement dit s'il est soit global, soit local mais déclaré avec le mot‑clef
static– cf. chap. C4‑II ), son descripteur de type peut être omis et c'est alors le typeintqui est attribué par défaut à ses éléments. Toutefois, cette pratique de codage est vivement déconseillée.
Vector comme suit : typedef double Vector[2];
et ensuite, on peut enchaîner les déclarations de données de type
Vector comme, par exemple : Vector v1 = {3.0, 4.0}, v2 = {0, -2.5}; // etc.
Initialisation d'un tableau
L'initialisation séquentielle des éléments d'un tableau n'est commode que si le nombre d'éléments est restreint ou si on a des valeurs uniformes. Mais, même si cette possibilité peut sembler limitée, il faut savoir en profiter car elle existe uniquement dans le cadre de la déclaration du tableau, et pas ultérieurement. En effet, en langages C et C++, il n'est pas possible de coder une affectation globale sur un tableau.
Le codage du nombre d'éléments dans la déclaration d'une donnée de type tableau et l'initialisation de leurs valeurs présentent diverses subtilités .
- Hors de tout bloc, on peut déclarer une donnée globale de type tableau sans coder ni son nombre d'éléments ni d'initialisation, par exemple ainsi :
int tab[];
Mais alors, ce tableau aura par défaut un seul élément, ce qui ne présente a priori aucun intérêt – il va donc de soi que cette pratique est vivement déconseillée, le compilateur émettant en général un avertissement de la forme :
array assumed to have one element - A priori, le nombre d'éléments d'un tableau n'a pas de limite autre que celle imposée par la mémoire allouée au programme sur la machine cible. Mais comme ce nombre est reconnu par le compilateur dans le type
size_t, il est forcément inférieur ou égal àSIZE_MAX(cf. chap. C3‑I ). - Le nombre d'expressions d'initialisation ne peut évidemment pas être supérieur au nombre d'éléments codé, sinon le compilateur signalera une erreur avec un message de la forme :
too many initializers
En revanche, ce nombre d'expressions d'initialisation peut être inférieur au nombre d'éléments codé, et alors, les éléments non initialisés prennent implicitement la valeur 0 par défaut si au moins un des éléments est initialisé. - la valeur nulle pour la classe statique,
- une valeur indéterminée (a priori différente pour chaque élément) pour la classe automatique.
Considérons le programme académique suivant pour un feu de circulation, où la variable duration est déclarée localement dans la fonction main et n'est pas initialisée (cf. la ligne n :
#include <stdio.h>
int main(void)
{
short duration[3];
for (int i = 0; i < 3; i++) {
printf("duration[%d] = %d\n", i, duration[i]);
}
return 0;
}
Exécuté sur OnlineGDB, ce programme produit une sortie standard comme par exemple :
duration[0] = 0 duration[1] = 4136 duration[2] = -4917
et de plus, on peut constater que les valeurs affectées des éléments du tableau changent à chaque exécution – elles sont en quelque sorte aléatoires (cf. le chap. C4‑II pour l'explication de ce phénomène).
Identification des éléments d'un tableau unidimensionnel par indexation directe
En rappel du chap. C2‑VI , après la déclaration d'un tableau unidimensionnel, chaque élément de ce dernier est identifiable dans le code source par une expression de la forme :
identificateur du tableau [indice de l'élément]
en partant de 0 pour l'indice du premier élément du tableau (en anglais, on parle de zero‑based indexing W).
Cette expression est une l‑value dont le type est celui des éléments du tableau déclaré.
En fait, sauf dans le cadre d'une déclaration, la paire de crochets [] symbolise l'opérateur d'indexation, qui admet deux arguments :
- à gauche, un identificateur de tableau déjà déclaré ;
- dans les crochets, l'indice de l'élément, codé par une expression évaluée dans le type
size_t, qui exprime ici une valeur ordinale, à savoir le numéro d'ordre de l'élément dans le tableau.
Dans le tableau de classification des opérateurs du langage C, l'opérateur [] a le rang 1 de priorité et un sens d'associativité de gauche à droite (cf. chap. C2‑IV ). Ces aspects sont essentiels pour bien comprendre par la suite le traitement des expressions de tableaux multidimensionnels.
Bornes d'indexation d'un tableau
En C et C++ (contrairement à d'autres langages), dans la déclaration d'une donnée de type tableau, il n'existe pas de syntaxe directe pour coder explicitement les bornes initiales et finales de l'indexation d'un tableau : seul son nombre N d'éléments est codé.
En conséquence, dans tout tableau déclaré :
- le premier élément est toujours d'indice
0, - le dernier élément est d'indice
N − 1.

Attention ! Après la déclaration d'un tableau – par exemple, nommé tab – de N éléments, l'expression tab[N] n'identifie pas le tableau ! C'est une l‑value qui identifie la valeur des octets de l'espace mémoire de même taille et de même type qu'un élément du tableau, mais situé juste après le dernier élément (qui, lui, est identifié tab[N − 1]).
De même, on peut coder un indice plus grand que N, où même un indice négatif, mais les expressions ainsi formées prennent alors des valeurs qui n'ont rien à voir avec celle du tableau déclaré : ces valeurs sont celles que contient l'espace mémoire autour de celui alloué au tableau.
Contrairement à d'autres langages (Pascal, Delphi…), les langages C et C++ autorisent de tels « débordements » (cf. chap. C5‑IV pour approfondissement ).
Reprenons la déclaration du tableau de 3 éléments issu de l'exemple supra sur le thème d'un feu de circulation :
short duration[3] = {60, 5, 90};
L'identification directe des éléments de ce tableau est très simple :
- le 1er élément est identifié par
duration[0](valeur initiale60) ; - le 2e élément est identifié par
duration[1](valeur initiale5) ; - le 3e élément est identifié par
duration[2](valeur initiale90) ; - l'expression
duration[3]identifie la valeur des deux octets de l'espace mémoire situés immédiatement après le 3e (et dernier) élément du tableau, interprétés dans le typeshort.
Il existe des techniques de codage plus ou moins satisfaisantes pour implémenter un indice initial différent de 0. L'une d'elles est présentée infra .
Type, taille en mémoire et encodage d'un tableau unidimensionnel
Un tableau unidimensionnel déclaré est un objet d'un type dérivé spécifique déterminé par le descripteur de type et le nombre N de ses éléments.
Ce type dérivé est désigné par son nom de type (cf. chap. C3‑I ) de la forme descripteur de type[N], notamment pour être appliqué à l'opérateur sizeof (cf. chap. C3‑I ) et à l'opérateur de transtypage (cf. chap. C3‑VI ).
La taille en mémoire d'un tableau est le produit de son nombre d'éléments et de la taille du descripteur de type de ses éléments. Formellement, l'expression :
sizeof(descripteur de type[N])
prend la valeur N × sizeof(descripteur de type).
Virtuellement, les éléments d'un tableau sont toujours stockés les uns à la suite des autres avec des adresses croissantes dans l'ordre naturel des éléments, et ce dans le segment mémoire approprié selon la classe d'allocation de la variable déclarée – à savoir le segment data, rodata ou bss pour la classe statique, ou encore la pile pour la classe automatique – cf. chap. C4‑II .
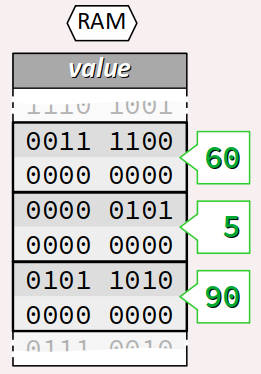
Reprenons la déclaration du tableau de 3 éléments issu de l'exemple supra sur le thème d'un feu de circulation :
short duration[3] = {60, 5, 90};
Le nom de type de ce tableau est short[3].
De plus, sachant que le type short est encodé sur 2 octets (cf. chap C3‑II ), la taille en mémoire du tableau duration – autrement dit l'expression sizeof(duration) ou encore short[3] – vaut 3 × 2 = 6 octets. On peut le vérifier aisément en exécutant le programme ci‑dessous :
#include <stdio.h>
int main(void)
{
short duration[3] = {60, 5, 90};
printf("%zu %zu\n", sizeof(duration), sizeof(short[3]));
return 0;
}
Exécuté sur OnlineGDB, on obtient la sortie attendue :
6 6
Virtuellement, et sans en expliciter aucune adresse, l'encodage en mémoire du tableau duration peut être conceptualisé par la figure ci‑contre où sont représentés ses 6 octets consécutifs.
Adresse d'un tableau unidimensionnel et de ses éléments
On rappelle (cf. chap. C5‑I ) que toute donnée déclarée n'est pas seulement identifiable par son identificateur, mais aussi par son adresse en mémoire.
Dans le cas d'une donnée de type tableau, son adresse coïncide avec celle de son 1e élément. Mais attention, la coïncidence des adresses ne signifie pas pour autant que les objets pointés soient identiques.
En effet, de façon générique, si on déclare un tableau nommé par exemple tab ayant un nom de type de la forme descripteur de type[N], avec l'opérateur d'adresse &, on peut former deux expressions remarquables qui sont à ne pas confondre.
| Expression | Cible | Nom de type | Type détaillé |
|---|---|---|---|
&tab[0] |
1er élément du tableau | descripteur de type * |
pointeur sur données de type descripteur de type |
&tab |
tableau complet | descripteur de type(*)[N] |
pointeur sur tableau unidimensionnel de N éléments de type descripteur de type |
On a donc deux valeurs d'adresses identiques mais de types différents, au même titre que deux variables peuvent avoir la même valeur tout en étant encodées dans deux types différents. Cette distinction devient flagrante par incrémentation de ces deux pointeurs : on n'obtient pas les mêmes valeurs d'adresses puisque les objets pointés n'ont pas la même taille.
Remarque. Dans le nom de type de la forme descripteur de type(*)[N], l'encapsulation entre parenthèses du symbole de pointeur (*) code la distinction syntaxique avec l'autre nom de type :
descripteur de type * [N]
qui caractérise un tableau unidimensionnel de N pointeurs de données de type descripteur de type ».
Reprenons la déclaration du tableau de 3 éléments issu de l'exemple supra sur le thème d'un feu de circulation :
short duration[3] = {60, 5, 90};
Il faut ne pas confondre :
- l'adresse
&duration[0]de son premier élément, dont le nom de type estshort *; - l'adresse
&durationdu tableau lui‑même, dont le nom de type estshort(*)[3].
Comme on peut le voir sur la figure ci‑dessous, ces deux addresses ont la même valeur, elles pointent sur le même octet.
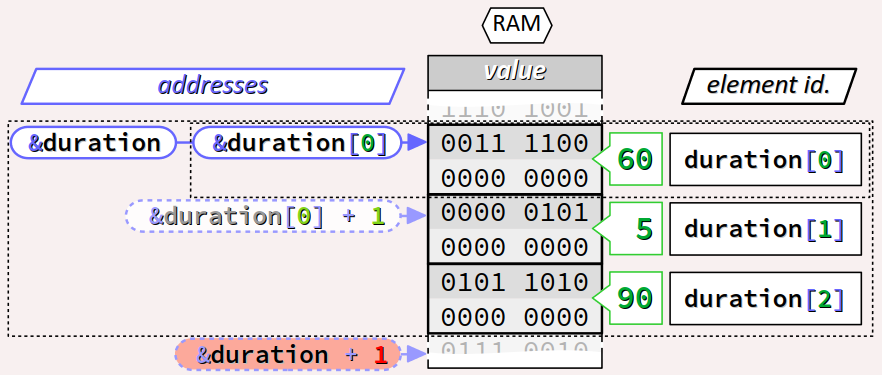
Mais ells sont de types différents, qui n'ont pas la même taille. Donc l'incrémentation unitaire de ces deux adresses ne pointent pas sur le même octet en mémoire :
- l'expression
&duration[1] + 1pointe sur le 2e élément du tableauduration; - l'expression
&duration + 1pointe en dehors de l'espace mémoire allouée au tableauduration, plus précisément, sur l'octet consécutif à cet espace.
On peut expérimenter cette différence de types en exécutant le programme ci‑dessous :
#include <stdio.h>
int main(void)
{
short duration[3] = {60, 5, 90};
printf("%12s %16s %16s\n", "Object", "Address", "Next Address");
printf("%12s %16p %16p\n", "1st element", &duration[0], &duration[0] + 1);
printf("%12s %16p %16p\n", "Array", &duration, &duration + 1);
return 0;
}
Sur OnlineGDB, on obtient une sortie comme par exemple :
Object Address Next Address
1st element 0x7ffcaf9fc292 0x7ffcaf9fc294
Array 0x7ffcaf9fc292 0x7ffcaf9fc298
- L'incrémentation de
&duration[0]augmente l'adresse de 2 octets – on passe de0x92à0x94, soit la taille d'une donnée de typeshort; - alors que l'incrémentation de
&durationaugmente l'adresse de 6 octets – on passe de0x92à0x98, soit la taille d'une donnée de typeshort[3].
Attention ! La connaissance des noms de types des pointeurs de tableaux est indispensable pour mettre en œuvre des conversions explicites sur des identificateurs de tableaux. Cet aspect sera abordé au chapitre C5‑IV .
Identification d'un tableau unidimensionnel et de ses éléments par pointeurs
On vient de voir supra comment identifier un tableau indirectement par son adresse. Il est évidemment possible de l'identifier directement par son identificateur mais, de façon contre-intuitive, c'est une approche plus subtile qu'il n'y paraît. En effet, on va voir qu'après la déclaration d'un tableau, le compilateur procède à la conversion implicite de son identificateur en un pointeur sur son premier élément dans presque toutes les expressions codées dans un programme. Pour ne pas coder des programmes erronés, cet aspect doit être maîtrisé dans ses moindres détails – précisément là où le Diable a la mauvaise habitude de se cacher !
Conversion implicite d'un identificateur de tableau en pointeur constant
En langages C et C++, sauf trois exceptions qui sont détaillées ci‑après, lors de l'évaluation d'une expression, toute occurrence de l'identificateur d'une donnée de type tableau est implicitement convertie en – autrement dit, se comporte comme – un pointeur constant de donnée (cf. chap. C5‑I ) :
- dont le type est celui des éléments du tableau (et non pas du tableau lui‑même) ;
- dont la valeur non mutable est l'adresse de son premier élément.
Cette conversion implicite peut être considérée comme une dégradation (cf. chap. C3‑VI ) car elle perd l'information du nombre d'éléments du tableau. Par déréférencement de ce pointeur, on n'obtient que la valeur du 1er élément du tableau, et non pas celle du tableau tout entier.
À cette règle générale, il y a trois exceptions, lorsque l'occurrence de l'identificateur du tableau est respectivement :
- l'objet de sa propre déclaration (mais donc, pas s'il est utilisé dans une expression d'initialisation d'une autre donnée) ;
- fait partie d'une expression appliquée à aux opérateurs
sizeof(opérateur de taille – cf. chap. C3‑I ) etalignof(opérateur de contraintes d'alignement – cf. chap. C3‑I ) ; - fait partie d'une expression appliquée à l'opérateur
&(opérateur d'adresse).
Attention ! Comme pour toute conversion (implicite ou explicite), on rappelle que celle d'un identificateur de tableau en pointeur de donnée ne forme pas un nouvel objet. Et à la manière d'une expression de la forme &a avec une variable déclarée a, le pointeur issu de la conversion implicite d'un identificateur de tableau n'a pas d'espace mémoire alloué – il prend simplement comme valeur l'adresse du premier élément du tableau et obéit à l'arithmétique des pointeurs avec le type de l'élément pointé.
En conséquence, une fois converti, l'identificateur d'une donnée de type tableau ne constitue pas une l‑value, donc il ne peut faire l'objet aucune affectation ni simple, ni combinée comme (++), etc.
Définition de l'opérateur d'indexation []
De façon surprenante, l'opérateur d'indexation [] introduit supra est applicable non seulement aux identificateurs de données de type tableau, mais plus généralement à toutes les expressions de type pointeur de donnée.
En fait, si l'opérateur d'indexation peut s'appliquer aux identificateurs de tableaux, c'est tout simplement parce que ces derniers sont implicitement convertis en pointeurs. Formellement :
- quelle que soit une donnée
pdéclarée de type pointeur de donnée, - et quelle soit une expression i à valeur entière, positive ou négative,
l'expression p[i] est définie comme *(p + i) – sauf dans le cadre d'une déclaration, bien évidemment puisque, dans ce cas, il ne s'agit pas de l'opérateur d'indexation.
L'opérateur d'indexation [] étant défini comme le déréférencement d'une expression d'addition, laquelle est une opération commutative, l'expression p[i] est équivalente à i[p]. Bien que valide, cette deuxième forme ne doit surtout pas être employée car elle n'est pas lisible (elle a tout pour semer la confusion).
Exemple
Reprenons la déclaration du tableau de 3 éléments issu de l'exemple académique sur le thème d'un feu de circulation :
short duration[3] = {60, 5, 90};
Tout d'abord, après cette déclaration, hormis les éventuelles exceptions (sizeof, & – cf. supra ), l'identificateur du tableau duration fait l'objet d'une dégradation implicite en pointeur constant de donnée dont le nom de type est short *. La figure ci‑dessous récapitule les expressions de type pointeur qui ciblent le tableau et ses différents éléments.

Analysons les pointeurs formés sans l'opérateur d'adresse, qui sont représentés sur fond beige :
- sur le 1er élément du tableau (valeur
60) : - l'expression
durationprend la même valeur que&duration[0](une adresse) ; - le déréférencement
*durationprend donc la même valeur queduration[0](l'entier60) ; - sur le 2e élément du tableau (valeur
5) : - l'expression
duration + 1prend la même valeur que&duration[1](une adresse) ; - le déréférencement
*(duration + 1)prend donc la même valeur queduration[1](l'entier5) ; - pour le 3e élément du tableau (valeur
90) : - l'expression
duration + 2prend la même valeur que&duration[2](une adresse) ; - le déréférencement
*(duration + 2)prend donc la même valeur queduration[2](l'entier90).
Pour s'en convaincre, on peut par exemple expérimenter le programme suivant qui teste les différentes expressions de déréférencement exposées juste avant pour afficher les valeurs des éléments du tableau sans recourir à l'opérateur d'indexation :
#include <stdio.h>
#include <stdint.h>
int main(void)
{
short duration[3] = {60, 5, 90};
printf("1st element: %2d \n", *duration);
printf("2nd element: %2d \n", *(duration + 1);
printf("3rd element: %2d \n", *(duration + 2));
return 0;
}
Sur OnlineGDB, on obtient bien la sortie attendue :
1st element: 60 2nd element: 5 3rd element: 90
D'un point de vue syntaxique, il n'est pas aisé de comprendre pourquoi les expressions duration, &duration et &duration[0] prennent la même valeur d'adresse. L'explication est la suivante :
- dans l'expression
duration, comme il ne s'agit pas d'une déclaration, l'identificateur est implicitement dégradé en un pointeur constant sur le premier élément du tableau ; sa valeur est donc l'adresse de ce 1er élément ; - mais dans l'expression
&duration, ce même identificateur n'est pas dégradé en pointeur (ce cas fait partie des exceptions à la règle), donc l'expression prend la valeur de l'adresse du tableau, qui coïncide avec celle de son 1er élément ; - et dans l'expression
&duration[0], l'opérateur d'indexation[](rang 1 de priorité) s'applique avant l'opérateur d'adresse&(rang 2 de priorité) ; or la sous‑expressionduration[0]est définie comme*(duration + 0), autrement dit comme*duration; on obtient ainsi l'expression équivalente&*duration, c'est‑à‑dire finalementduration(cf. chap. C5‑I ).
Pour autant, il faut souligner encore une fois qu'il existe une différence de type entre ces expressions :
- Les expressions
durationet&duration[0]ont pour nom de typeshort *. Autrement dit, en leur opérant une incrémentation unitaire, c'est‑à‑dire en formant les expressionsduration + 1et&duration[1], on obtient l'adresse de l'élément suivant dans le tableau. - Mais l'expression
&durationa pour nom de typeshort(*)[3]. Donc, après incrémentation unitaire, c'est‑à‑dire en formant l'expression&duration + 1, on obtient l'adresse du premier octet virtuellement consécutif au tableau tout entier (sachant que cette adresse peut, en plus, être éventuellement décalée par une contrainte d'alignement – cf. chap. 3‑I ).
Indexation décalée des éléments d'un tableau
La définition de l'opérateur d'indexation [] comme une composition des opérateurs de déréférencement et d'addition explique pourquoi il peut s'appliquer sans restriction à n'importe quel indice N d'élément d'un tableau, aussi grand que l'on veut (dans les limites d'encodage de l'implémentation, bien‑sûr) et même négatif !
Si ces possibilités présentent clairement des risques de dysfonctionnement de programmes qui seront évoqués au chapitre C5‑IV , elles offrent aussi des possibilités intéressantes, en particulier pour décaler l'indexation des éléments d'un tableau, comme on va le voir maintenant sur un exemple.
Reprenons la déclaration du tableau de 3 éléments issu de l'exemple supra sur le thème d'un feu de circulation :
short duration[3] = {60, 5, 90};
Après cette déclaration, rien n'interdit de déclarer également un autre pointeur de données durationOffset comme ci‑dessous :
short * durationOffset = duration - 1;
Alors l'expression durationOffset[1] vaut duration[0], donc le pointeur durationOffset permet une indexation des éléments du tableau duration à partir de 1 et non pas de 0.
Cette méthode d'indexation décalée présente néanmoins plusieurs inconvénients :
- Même si l'espace mémoire supplémentaire requis est négligeable (il suffit juste d'un pointeur), elle nécessite de s'encombrer d'un deuxième identificateur, avec tous les risques de confusion que cela peut induire dans le cas d'un gros programme (mais on verra qu'il y a une solution pour s'en passer avec les techniques d'allocation dynamique de mémoire).
- de plus, cette technique travestit la base des langages C et C++, dont tout le monde sait que « les tableaux toujours sont indexés à partir de
0». Dans un code volumineux, un contributeur qui ne penserait pas à examiner en détail les déclarations pourrait passer à côté d'une telle indexation décalée et risquerait alors de commettre des erreurs. Ce n'est donc pas forcément une technique très « lisible » dans le cadre d'un travail en équipe.
Par conséquent, cette méthode d'indexation ne doit pas être employée systématiquement mais seulement réservée à des cas particuliers qui le justifient.
Règle générale sur les valeurs de type tableau
Compte tenu des éléments de langages présentés supra, et en particulier du principe de dégradation implicite de tout identificateur de tableau en pointeur constant sur son premier élément, on doit retenir la règle générale suivante.
En langages C et C++, hormis dans le cadre d'une déclaration ou comme opérande des opérateurs & et sizeof, il n'est pas possible de former une expression dont la valeur est un tableau.
Cette règle est essentielle pour pouvoir comprendre par la suite les techniques de manipulation des tableaux – affectation, argument et valeur de retour d'une fonction – exposées au chapitre C5‑II .
Tableaux multidimensionnels

On rappelle (cf. chap. C2‑VI W) qu'en langages C et C++, un tableau multidimensionnel est tableau dont les éléments sont structurés, non pas simplement les uns à la suite des autres, mais comme une encapsulation de sous‑tableaux, ces derniers étant des éventuellement des tableaux de sous‑tableaux, et ce à chaque nouvelle dimension ajoutée.
Concrètement, on peut se représenter un tableau comme une structure en « lignes », « colonnes », « couches »… mais au delà de trois dimensions, toute visualisation géométrique (spatiale) devient difficile.
Au niveau le plus interne, on peut parler d'éléments cellulaires du tableau.
Pour comprendre le principe de la structuration des données sur plusieurs dimensions, il est d'usage de se référer à la notion mathématique de matrices qui sont des tableaux à deux dimensions, présentés en lignes et colonnes W. Mais cette analogie doit cependant être considérée avec circonspection. En particulier, il faut ne pas confondre :
- en mathématiques, le nombre de dimensions d'un espace vectoriel pour lequel une matrice définit une application linéaire (dans un espace de dimension 3, les matrices sont des tableaux de 3 lignes et 3 colonnes).
- en programmation, le nombre des dimensions d'un tableau, qui est indépendant du nombre d'éléments par dimension (lequel peut être différent d'une dimension à l'autre).
Pour ne pas se laisser étourdir par des considérations algébriques ou géométriques, il ne faut garder en tête qu'en termes de codage, ajouter une dimension relève toujours du même principe itératif d'encapsulation, quel que soit le nombre de dimensions déjà définies.
Déclaration d'un tableau multidimensionnel
En langages C et C++, la déclaration d'un tableau multidimensionnel obéit à une syntaxe très similaire à celle d'un tableau unidimensionnel, même si la forme générale peut sembler complexe :
descripteur de type identificateur du tableau [Np]…[N1] [= {liste encapsulée d'expressions}];
En effet, dans cette forme générale pour un tableau à p dimensions :
- N1 à Np codent les valeurs des nombres d'éléments respectivement dans chaque dimension numérotée de 1 – la plus interne – à p – la plus externe ;
- la liste encapsulée d'expressions doit présenter p niveaux d'encapsulation par des accolades
{}.
Pour simplifier, on se limite à détailler ces aspects dans le cas d'un tableau à deux dimensions :
- Le codage du nombre d'éléments par dimension s'effectue dans l'ordre inverse, c'est‑à‑dire de la dernière (la plus externe) à la première dimension (la plus interne) par rapport à l'ordre d'encapsulation des dimensions. Ainsi, un tableau à 2 dimensions – M lignes et N colonnes, codées
[M][N]– est en fait un tableau de M tableaux à N éléments. - 3 régimes de chauffe respectivement dits «
jour» (☼), «nuit» (☾) et «hors‑gel» (❄) ; - et pour chaque régime de chauffe, avec 2 niveaux de confort, respectivement dits «
confort» ou «économique». - dont les 2 lignes correspondent aux niveaux de confort ;
- et les 3 colonnes correspondent aux régimes de chauffe.
- L'affectation des valeurs initiales se fait de préférence par une liste structurée en autant de niveaux de sous‑listes qu'il y a de dimensions supplémentaires.
- Seul le nombre d'éléments de la dimension externe (la première dans l'ordre du codage) peut ne pas être codé entre crochets.
L'instruction :
int8_t heat[2][3];
déclare un tableau à deux dimensions, respectivement de 2 lignes (dimension externe) et 3 colonnes (dimension interne), c'est‑à‑dire 3 éléments par ligne. C'est donc un tableau ayant au total 2 × 3 = 6 éléments de type int8_t.
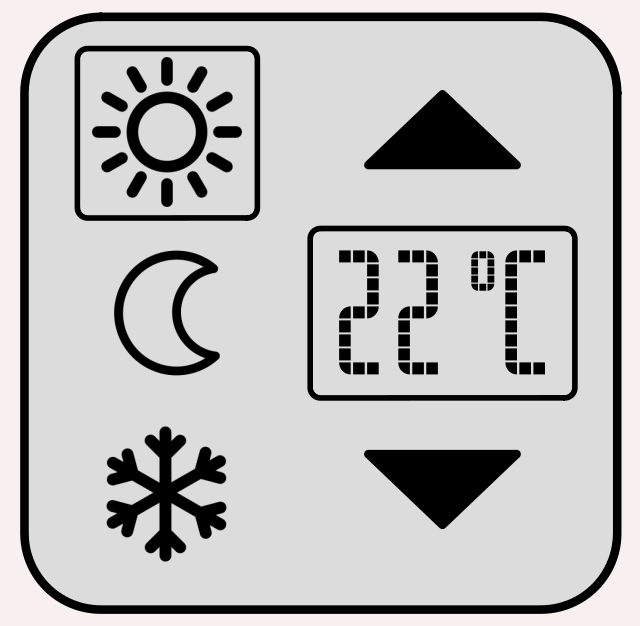
Une telle variable peut par exemple mémoriser les consignes de température dans un système de chauffage à thermostat, dans lequel on trouve typiquement :
On a donc 6 consignes de températures qui sont mémorisables de façon structurée dans le tableau déclaré ci‑dessus :
Par la suite, on utilisera ce tableau bidimensionnel comme exemple académique récurrent.
En prolongement de l'exemple académique précédent, l'instruction :
int8_t heat[2][3] = { {22, 17, 10}, {19, 15, 5} };
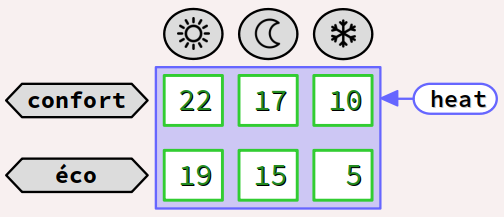
déclare le même tableau de 2 lignes et 3 colonnes, en spécifiant les valeurs initiales des éléments par les 2 sous‑listes d'expressions ci‑dessus, ligne après ligne, et dans chaque ligne (dans sa sous‑liste respective), colonne après colonne.
Remarque. On peut aussi initialiser les éléments cellulaires en une simple liste comme ceci :
{22, 17, 10, 19, 15, 5}
mais ce choix est moins bon en termes de lisibilité du code.
En prolongement de l'exemple académique précédent, la déclaration de l'exemple ci‑dessus peut aussi se coder avec la syntaxe implicite [] comme ci‑dessous :
int8_t heat[ ][3] = { {22, 17, 10}, {19, 15, 5} }; // ↑ unset dimension (implicit)
c'est‑à‑dire sans préciser le nombre d'éléments de la dimension externe du tableau (le nombre de lignes) dès lors que tous les éléments du tableaux font l'objet d'une initialisation.
En revanche, une déclaration erronée de la forme :
int8_t heat[][] = …; // error!
provoquerait une erreur de compilation, même si tous les éléments du tableau faisaient l'objet d'une affectation de valeur initiale par une liste structurée d'expression.
La norme du langage C spécifie que le nombre de dimensions doit pouvoir aller jusqu'à au moins 256 – ce qui est déjà largement suffisant pour tous les besoins imaginables en termes de structures de données – et sans préciser une quelconque limite maximale. Tout dépend donc de l'implémentation, et bien entendu de la mémoire disponible lors de l'exécution sur la machine cible.
Identification des éléments d'un tableau multidimensionnel par indexation directe
Un tableau multidimensionnel étant structuré comme un tableau de sous‑tableaux, le principe d'identification des éléments reprend celui pour un tableau unidimensionnel (cf. supra ) mais opère par compositions successives d'application de l'opérateur d'indexation [] sachant que son sens d'associativité est de gauche à droite (cf. chap. C2‑IV ).
À l'instar de la déclaration du tableau (cf. supra ), pour identifier un élément, on code ses indices i, j, k… dans les dimensions respectives du tableau selon l'ordre inverse de leur encapsulation, c'est‑à‑dire selon la forme …[k][j][i].
Attention : comme pour un tableau unidimensionnel (cf. supra ), toute valeur d'indice codée en dehors de la plage de sa dimension est acceptée à la compilation et pointe en dehors de l'espace mémoire alloué au tableau.
Reprenons l'exemple académique précédent pour un thermostat de chauffage avec la déclaration du tableau bidimensionnel complètement initialisé :
int8_t heat[2][3] = { {22, 17, 10}, {19, 15, 5} };
Avec l'opérateur d'indexation et l'identificateur du tableau, on peut former les expressions d'identification suivantes.
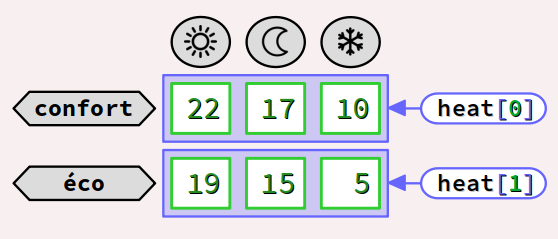
- L'expression
heat[0]identifie le sous‑tableau formant la 1re ligne (j = 0) du tableauheat. - L'expression
heat[1]identifie le sous‑tableau formant la 2e ligne (j = 1) du tableauheat.
Ces deux expressions constituent des identificateurs de sous‑tableaux (unidimensionnels) qui, rappelons‑le, sont dégradés en pointeurs constants, sauf exceptions (sizeof, &).
Quant aux éléments cellulaires de ces sous‑tableaux, ils sont identifiés par une expression de la forme heat[j][i], autrement dit tels que :
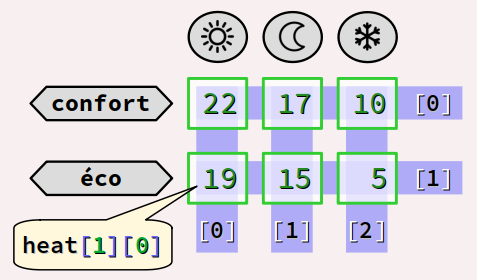
-
heat[0][0]est l'élément du tableau en 1re ligne (j = 0) et 1re colonne (i = 0) – valeur initiale22; -
heat[0][1]est l'élément du tableau en 1re ligne (j = 0) et 2e colonne (i = 1) – valeur initiale17; -
heat[0][2]est l'élément du tableau en 1re ligne (j = 0) et 3e colonne (i = 2) – valeur initiale10; -
heat[1][0]est l'élément du tableau en 2e ligne (j = 1) et 1re colonne (i = 0) – valeur initiale19; - etc.
En particulier, à titre d'exemple générique, l'expression heat[1][0] est en fait une composition de l'opérateur d'indexation appliqué à heat[0] avec l'indice 1. Sachant que le sens d'associativité de cet opérateur est de gauche à droite (→), on peut analyser cette expression comme étant de la forme (heat[1])[0] qui cible le 1er élément ([0]) de la 2e ligne (heat[1]) du tableau heat.
Type, taille en mémoire et stockage d'un tableau multidimensionnel
Selon le même principe que pour un tableau unidimensionnel (cf. supra ), un tableau multidimensionnel est d'un type dérivé spécifique déterminé par son descripteur de type de ses éléments ainsi que ses dimensions et leurs nombres d'éléments respectifs N, M, L… Son nom de type (cf. chap. C3‑I ) se code de la forme :
descripteur de type…[L][M][N]
où les nombres d'éléments des dimensions sont, comme dans une déclaration (cf. supra ), codés dans l'ordre inverse de celui d'encapsulation des dimensions.
Reprenons l'exemple académique précédent pour un thermostat de chauffage avec la déclaration du tableau bidimensionnel :
int8_t heat[2][3] = { {22, 17, 10}, {19, 15, 5} };
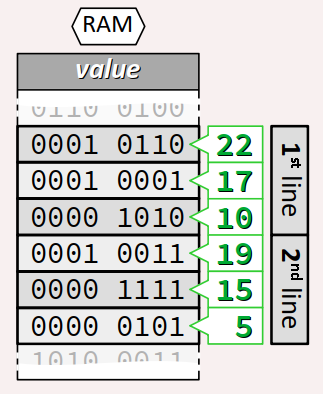
Ce tableau a pour nom de type int8_t[2][3].
Sachant que le type int8_t est encodé sur 1 octet, la taille en mémoire du tableau heat – autrement dit l'expression sizeof(heat) – vaut 2 × 3 × 1 = 6 octets.
Virtuellement, son stockage en mémoire peut être représenté comme sur la figure ci‑contre, avec dans l'ordre des adresses croissantes :
- les 3 éléments de la 1re ligne (1 octet chacun),
- puis les 3 éléments de la 2e ligne (idem).
Adresse d'un tableau multidimensionnel et de ses éléments
Comme pour un tableau unidimensionnel , l'adresse d'un tableau multidimensionnel coïncide avec celle de son premier élément, mais n'en partage pas le type. Et elle coïncide aussi avec l'adresse de sa première ligne, mais là encore, le type est différent.
Ainsi, en déclarant un tableau bidimensionnel nommé tab et ayant un nom de type de la forme descripteur de type[M][N], avec l'opérateur d'adresse &, on peut former trois expressions remarquables, récapitulées ci‑dessous :
| Expression | Cible | Nom de type | Type détaillé |
|---|---|---|---|
&tab[0][0] |
1er élément cellulaire | descripteur de type * |
pointeur sur données de type descripteur de type |
&tab[0] |
1re ligne | descripteur de type(*)[N] |
pointeur sur tableau unidimensionnel de N éléments de type descripteur de type |
&tab |
tableau complet | descripteur de type(*)[M][N] |
pointeur sur tableau unidimensionnel de M tableaux unidimensionnels de N éléments de type descripteur de type |
Là encore, ces trois expressions prennent la même valeur (adresse), tout en étant de types différents, et la différence apparaît lors d'une incrémentation, comme on va le voir dans l'exemple qui suit.
Remarque. Le nom de type descripteur de type(*)[M][N] peut être vu comme désignant un pointeur sur tableau bidimensionnel de M × N éléments de type descripteur de type, mais c'est une description moins précise.
Reprenons l'exemple académique précédent pour un thermostat de chauffage avec la déclaration du tableau bidimensionnel :
int8_t heat[2][3] = { {22, 17, 10}, {19, 15, 5} };
Il faut ne pas confondre :
- l'adresse
&heat[0][0]de son premier élément cellulaire est de typeint8_t*; - l'adresse
&heat[0]de sa première ligne est de typeint8_t(*)[3]; - l'adresse
&heatdu tableau lui‑même est de typeint8_t(*)[2][3].
Comme on peut le voir sur la figure ci‑dessous, ces deux addresses ont la même valeur, elles pointent sur le même octet.

Mais elles sont de types différents, qui n'ont pas la même taille. Donc l'incrémentation unitaire de ces deux adresses ne pointent pas sur le même octet en mémoire :
- l'expression
&heat[0][0] + 1pointe sur le 2e élément de la première ligne ; - l'expression
&heat[0] + 1pointe sur la 1e élément de la 2e ligne ; - l'expression
&heat + 1pointe sur le premier octet en dehors de l'espace mémoire allouée au tableauduration, plus précisément, sur l'octet consécutif à cet espace (éventuellement décalé par une contrainte d'alignement – cf. chap. C3‑I ).
Pour s'en convaincre, on peut visualiser ces différences en exécutant le programme ci‑dessous :
#include <stdio.h>
#include <stdint.h>
int main(void)
{
int8_t heat[2][3] = { {22, 17, 10}, {19, 15, 5} };
printf("%12s %16s %16s\n", "Object", "Address", "Next Address");
printf("%12s %16p %16p\n", "1st element", &heat[0][0], &heat[0][0] + 1);
printf("%12s %16p %16p\n", "1st row", &heat[0], &heat[0] + 1);
printf("%12s %16p %16p\n", "Array", &heat, &heat + 1);
return 0;
}
Sur OnlineGDB, on obtient une sortie comme par exemple :
Object Address Next Address
1st element 0x7fffddcca132 0x7fffddcca133
1st row 0x7fffddcca132 0x7fffddcca135
Array 0x7fffddcca132 0x7fffddcca138
sur laquelle on peut faire les constats suivants :
- L'incrémentation de
&heat[0][0]augmente l'adresse de 1 octet – on passe de0x32à0x33, soit la taille d'une donnée de type nomméint8_t. - L'incrémentation de
&heat[0]augmente l'adresse de 3 octets – on passe de0x32à0x35, soit la taille d'une donnée de type nomméint8_t[3]. - L'incrémentation de
&heataugmente l'adresse de 6 octets – on passe de0x32à0x38, soit la taille d'une donnée de type nomméint8_t[2][3].
Identification d'un tableau multidimensionnel et de ses éléments par pointeurs
La structure d'un tableau multidimensionnel est décisive pour l'identification des éléments par pointeurs.
On part du principe que, comme pour un tableau unidimensionnel, et sauf les exceptions mentionnées supra , lors de l'évaluation d'une expression, l'identificateur du tableau est dégradé en un pointeur constant sur son 1er élément (sauf pour les opérateurs sizeof et &). Mais comme un tableau multidimensionnel est un tableau de tableaux, son 1er élément est lui‑même un tableau. Donc :
- L'identificateur de ce 1er élément est aussi dégradé en un pointeur constant. L'identificateur du tableau est donc converti en un pointeur de pointeur, et ce autant de fois que le tableau compte de dimensions supplémentaires.
- Lorsqu'on applique à l'identificateur du tableau une incrémentation unitaire
(+ 1), on obtient l'adresse du sous‑tableau suivant.
Reprenons l'exemple académique précédent pour un thermostat de chauffage avec la déclaration du tableau bidimensionnel :
int8_t heat[2][3] = { {22, 17, 10}, {19, 15, 5} };
Rappelons qu'il est structuré comme un tableau de 2 sous‑tableaux (des éléments de type « ligne »), identifiés respectivement par les expressions heat[0] (1re ligne) et heat[1] (2e ligne). Chacun de ces deux sous‑tableaux est lui‑même formé de 3 éléments, donc de taille 3 × 1 = 3 octets. On peut le vérifier en évaluant par exemple l'expression sizeof(heat[0]) : on obtient la valeur 3.
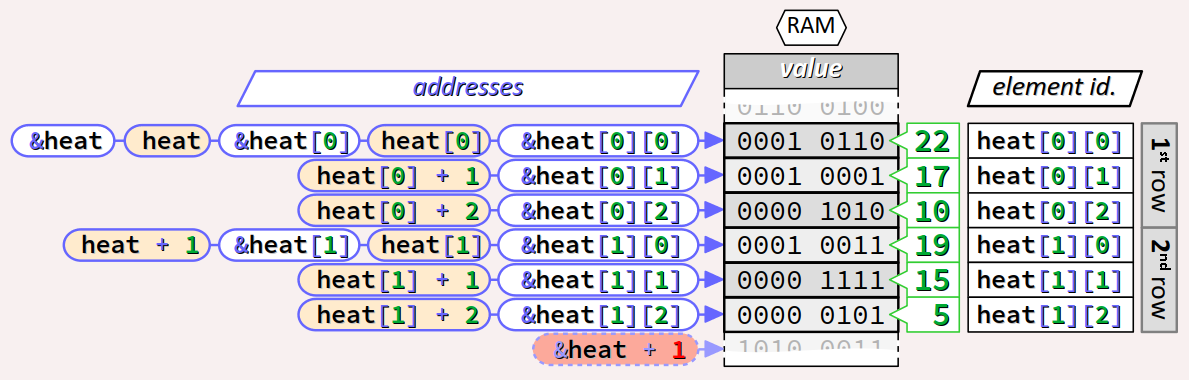
Analysons l'identification par pointeurs des éléments de la 1religne en s'aidant de la figure ci‑dessus où les pointeurs formés sans l'opérateur d'adresse apparaissent sur fond beige :
- L'expression
heatest un identificateur de tableau, donc implicitement dégradé en un pointeur sur son 1er élément, donc elle prend la même valeur que&heat[0]. - Les expressions de déréférencement
**heatet*heat[0]prennent donc l'une et l'autre la valeur deheat[0][0](valeur initiale22du premier élément cellulaire du tableau).
heat[0], l'identificateur heat est implicitement dégradé en &heat[0], donc elle prend la même valeur que &heat[0][0]. Voyons maintenant ce que produit une incrémentation de ces pointeurs :
- par dégradation implicite, l'expression
heat[0] + 1prend la même valeur que&heat[0][0] + 1, autrement dit que&heat[0][1](adresse du 2e élément de la ligne, qui est également le 2e élément cellulaire du tableau) ; - l'expression de déréférencement
*(heat[0] + 1)prend donc la valeurheat[0][1](valeur initiale17) ; - idem pour l'élément suivant auquel on accède par le pointeur
heat[0] + 2…
Le principe est le exactement même pour la 2e ligne lorsqu'on y accède par le pointeur heat + 1. En effet, par l'arithmétique des pointeurs, l'opération + 1 représente un saut d'adresse de la taille du type d'éléments du tableau heat, c'est‑à‑dire d'une ligne entière (on a vu supra que sizeof(heat[0]) vaut 3 octets).
Enfin, comme pour un tableau unidimensionnel (cf. supra ), l'expression &heat + 1 pointe sur l'adresse consécutive à l'espace alloué au dernier élément du tableau (et éventuellement décalée par une contrainte d'alignement spécifique à l'implémentation – cf. chap. 3‑I ).
Pour s'en convaincre, on peut par exemple exécuter le programme suivant qui teste les différentes expressions de déréférencement exposées juste avant pour afficher les valeurs des éléments cellulaires du tableau :
#include <stdio.h>
#include <stdint.h>
int main(void)
{
int8_t heat[2][3] = { {22, 17, 10}, {19, 15, 5} };
printf("1st element: %2d %2d\n", **heat, *heat[0]);
printf("2nd element: %2d \n", *(heat[0] + 1));
printf("3rd element: %2d \n", *(heat[0] + 2));
printf("4th element: %2d %2d\n", **(heat + 1), *(heat[1]));
printf("2nd element: %2d \n", *(heat[1] + 1));
printf("3rd element: %2d \n", *(heat[1] + 2));
return 0;
}
Sur OnlineGDB, on obtient bien la sortie attendue :
1st element: 22 22 2nd element: 17 3rd element: 10 4th element: 19 19 2nd element: 15 3rd element: 5
Plus généralement, pour un tableau bidimensionnel tab, quelles que soient les valeurs entières j et i prises comme indices respectifs de ses lignes et colonnes, les trois expressions ci‑dessous prennent la même valeur :
tab[j][i]
(*(tab + j))[i]
*(*(tab + j) + i)