
On a vu au chapitre C1‑I que pour gérer la complexité grandissante des programmes, on s'efforce autant que possible de les décomposer en sous‑programmes W (en anglais, subroutine), chacun exécutant un traitement spécifique. En langages C et C++, on parle de fonction – notion que l'on a brièvement abordée au chap. C2‑I .
Lorsque la décomposition est bien pensée, les sous‑programmes peuvent être codés par différents développeurs puis assemblés pour constituer le programme complet. Et pour optimiser autant que possible les coûts de développement, on conçoit les sous‑programmes de sorte qu'ils puissent être compilés indépendamment les uns des autres, et éventuellement réutilisés dans d'autres programmes. En les organisant en bibliothèques W (en anglais, libraries), on met ainsi en œuvre une programmation modulaire (cf. chap. C1‑I ).
En langages Pascal ou Delphi, il existe les deux mots‑clef « function » et « procedure » pour déclarer un sous‑programme, afin de distinguer le fait que ce dernier retourne ou ne retourne pas une valeur en fin d'exécution. Plus généralement, le mot‑clef « function » apparaît également dans divers langages, notamment JavaScript ou php.
En langages C et C++, il n'y a aucun mot‑clef qui code directement la notion de sous‑programme. La distinction entre les notions de fonction et de procédure est codée autrement et il est d'usage de parler de fonction dans un sens très général – bien plus général que celui de fonction mathématique. En effet, en programmation, une fonction peut très bien :
- d'un moment à un autre, rendre différentes valeurs en sortie alors que les variables d'entrée – on parle d'arguments ou de paramètres – gardent les mêmes valeurs ;
- ne retourner éventuellement aucune valeur, comme pour une «
procedure» en langage Pascal ; - en plus ou au lieu de retourner une valeur, effectuer d'autres actions, notamment des opérations d'entrées‑sorties, des modifications de variables globales, etc.
Incontournable, la notion de fonction fait donc l'objet exclusif de ce chapitre d'introduction de la partie C4 du module, avec les objectifs listés ci‑dessous.
- Après avoir donné quelques exemples simples, on peut exposer les aspects fondamentaux sous‑jacents au concept de fonction – corps, en‑tête, argument, valeur de retour, etc. – et détailler les règles de syntaxe qui les gouvernent.
- On étudie ensuite les bases de la programmation procédurale qui repose, pour chaque fonction, sur le codage séparé de sa déclaration – appelée aussi prototype – et de sa définition, c'est‑à‑dire son code intégral.
- Enfin, on introduit des particularités et possibilités de codage avancées :
- fonction sans valeur de retour et/ou sans argument, grâce au type
void; - transmission des arguments par référence ;
- arguments optionnels avec une valeur par défaut ;
- surcharge d'un identificateur de fonction ;
Tous ces aspects méritent la plus grande attention. Ils seront essentiels pour pouvoir aborder sereinement les chapitres suivants, y compris des autres parties du module.
Exemples élémentaires
Des fonctions mathématiques
La fonction cube
Examinons le programme ci‑dessous :
#include <stdio.h>
double cube(double x)
{
return x * x * x;
}
int main(void)
{
for (int a = 0; a <= 10; a++) {
printf("%2d³ = %g\n", a, cube(a));
}
return 0;
}
On y trouve les éléments suivants :
- Aux lignes nº 3 à 6 est codée la définition de la fonction mathématique cube : x ⟼ x³ (ℝ ⟶ ℝ).
- La ligne nº 3 constitue son en‑tête de définition (header) avec dans l'ordre :
- son type de valeurs retournées
double; - son identificateur
cube; - son (seul) argument formel identifié par
x, qui est de typedouble. - Le corps de définition de la fonction est un bloc ne comprenant qu'une seule instruction (ligne nº 5), laquelle code la valeur retournée par la fonction, déterminée par l'expression
x * x * xcodée après le mot‑clefreturn. - Aux lignes nº 8 à 14 est codée la fonction principale
main, qui programme l'affichage en sortie standard des valeurs prises par la fonctioncubepour x allant de 0 à 10 par valeurs entières.
cube(a) constitue un appel de la fonction cube dont l'argument effectif est l'expression a. Lors de l'exécution, par exemple avec OnlineGDB, ce programme produit l'affichage suivant (abrégé), conforme aux attentes :
0³ = 0
1³ = 1
2³ = 8
3³ = 27
⁝
10³ = 1000
Il constitue un jeu d'essais partiel de la fonction.
La fonction factorielle
Examinons le programme ci‑dessous :
#include <stdio.h>
unsigned long long fact(unsigned n)
{
unsigned long long f = 1;
for (unsigned k = 1U; k <= n; k++) {
f *= k;
}
return f;
}
int main(void)
{
for (int a = 0; a < = 10; a++) {
printf("%2u! = %llu\n", a, fact(a));
}
return 0;
}
On y trouve les éléments suivants :
- Aux lignes nº 3 à 10 est codée la définition de la fonction mathématique factorielle : n ⟼ n! = 1 × 2 … × n (ℕ⁺ ⟶ ℕ⁺).
- La ligne nº 3 constitue son en‑tête de définition (header) avec dans l'ordre :
- son type de valeurs retournées
unsigned long long(parce que ces valeurs sont rapidement très grandes) ; - son identificateur
fact; - son (seul) argument formel identifié par
n, qui est de typeunsigned(la fonction n'est pas définie sur ℕ⁻). - Les lignes nº 4 à 10 forment le corps de définition de la fonction. C'est un bloc comprenant notamment :
- à la ligne nº 5, la déclaration d'une variable locale
f; - aux lignes nº 6 à 8, une boucle
forqui calcule dansfle produit itératif 1 × 2 … × n ; - à la ligne nº 9, l'instruction qui détermine la valeur retournée par la fonction, déterminée par l'expression
fcodée après le mot‑clefreturn. - Aux lignes nº 12 à 18 est codée la fonction principale qui programme l'affichage en sortie standard des valeurs prises par la fonction
factpour n allant de 0 à 10.
fact(a) constitue un appel de la fonction fact dont l'argument effectif est l'expression a. Dans le terminal d'exécution, par exemple avec OnlineGDB, ce programme produit l'affichage suivant (abrégé), conforme aux attentes :
0! = 1
1! = 1
2! = 2
3! = 6
⁝
10! = 3628800
Il constitue un jeu d'essais partiel de la fonction.
Des fonctions d'entrées‑sorties booléennes en Arduino

Le programme Arduino pour traiter l'exercice nº 3 du sujet de TP C2‑2 (Led & bouton), à savoir la génération en code morse d'un signal SOS répétitif – gagne en lisibilité à être décomposé à l'aide de fonctions, comme ci‑dessous :
const int LED_PIN = 2;
void setup()
{
pinMode(LED_PIN, OUTPUT);
digitalWrite(LED_PIN, LOW);
}
// Morse code durations in milliseconds
const int DASH_DURATION = 750;
const int DOT_DURATION = 250;
const int INTER_SYMBOLS_DURATION = 250;
const int INTER_LETTERS_DURATION = 750;
const int INTER_WORDS_DURATION = 3500;
void loop()
{
letter_S();
delay(INTER_LETTERS_DURATION);
letter_O();
delay(INTER_LETTERS_DURATION);
letter_S();
delay(INTER_WORDS_DURATION);
}
void letter_S()
{
for (int dot = 1; dot <= 3; dot++) {
digitalWrite(LED_PIN, HIGH);
delay(DOT_DURATION);
digitalWrite(LED_PIN, LOW);
if (dot < 3) delay(INTER_SYMBOLS_DURATION);
}
}
void letter_O()
{
for (int dash = 1; dash <= 3; dash++) {
digitalWrite(LED_PIN, HIGH);
delay(DASH_DURATION);
digitalWrite(LED_PIN, LOW);
if (dot < 3) delay(INTER_SYMBOLS_DURATION);
}
}
Ici, on a défini deux fonctions, letter_S (lignes nº 26 à 34) et letter_O (lignes nº 36 à 44), qui sont l'une comme l'autre :
- sans valeur de retour, d'où le type
void; - sans argument formel, d'où le code
()qui exprime un liste vide d'arguments.
Ces deux fonctions servent à regrouper des instructions de sorties booléennes dans un bloc respectif pour chacune. On peut ensuite appeler à volonté l'une ou l'autre pour qu'elle s'exécute dans le code d'une autre fonction, sans y répéter leur code. Ainsi, dans loop, on trouve :
- deux appels de
letter_S(lignes nº 18 & 22) ; - un appel de
letter _0(ligne nº 20).
Il en résulte que le code de la fonction loop devient très court, et donc très facile à lire. Il n'est pas encombré du détail des actions qu'il accomplit (détail qui peut être obtenu si nécessaire en consultant le code des fonctions appelées).
Aspects fondamentaux de la notion de fonction
Préambule
Analogie avec la notion de fonction mathématique
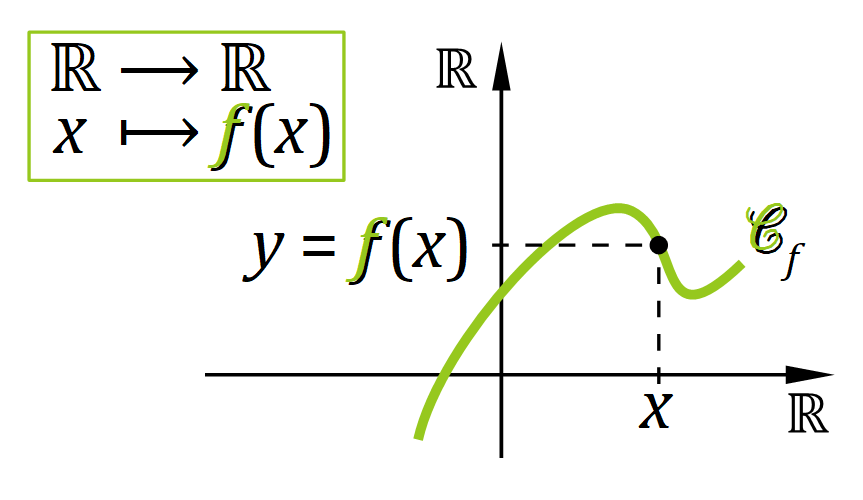
La notion de fonction mathématique est un concept algébrique qui permet d'établir une correspondance particulière entre :
- des éléments d'un ensemble dit de départ,
- et des éléments d'un ensemble dit d'arrivée,
avec la condition qu'un antécédent x dans l'ensemble de départ ne peut avoir qu'au plus une seule image y dans l'ensemble d'arrivée W (cette unicité est essentielle).
Intuitivement, on pourrait ajouter qu'une fonction mathématique est « invariante dans le temps », dans la mesure où à un antécédent x donné, une fonction f fait toujours correspondre la même image y = f(x). En fait, il est préférable de considérer qu'il n'y a ici tout simplement pas de notion de temps.
Même si l'on observe tout de suite des différences essentielles avec la notion de fonction en programmation, on peut quand établir une analogie intéressante pour certains aspects fondamentaux, notamment ceux illustrés en figure ci‑contre, avec :

- la distinction entre la déclaration et la définition,
- les notions d'appel et de jeu d'essais,
- la distinction entre les arguments formels et effectifs.
Représentation schématique

En Sciences de l'ingénieur, une représentation schématique courante d'une fonction est celle d'un bloc (rectangle) avec une ou plusieurs entrées à gauche et une sortie à droite. Un tel bloc est destiné à s'insérer dans ce qu'on appelle un schéma‑bloc W (en anglais, bloc diagram) plus vaste où sont représentées d'autres fonctions. En programmation :
- les entrées du bloc correspondent aux arguments de la fonction ;
- la sortie correspond à la valeur de retour de la fonction ;
dans l'hypothèse où ces éléments existent (on rappelle qu'une fonction peut n'avoir ni arguments, ni valeur de retour).
Une telle représentation n'est donc pas forcément pertinente dans tous les cas en programmation, mais elle peut avoir un intérêt pédagogique, notamment pour comprendre la notion de composition de fonctions (cf. infra ).
Généralités syntaxiques
De façon générale, dans le code source d'un programme, il est avant tout impératif de ne pas confondre :
- le code de la fonction, qui est unique et qui se décompose en deux parties : un en‑tête, puis un corps de définition ;
- et une ou plusieurs expression(s) d'appel de cette fonction afin de l'utiliser le programme.
Comme souvent en langages C et C++, ces éléments de langage obéissent à des règles de syntaxe complexes qui ont évolué au fil des normes. Pour ne pas compliquer davantage ce chapitre, la syntaxe « historique » de codage des fonctions en langage C n'est pas exposée dans ce cours, dans la mesure où elle est aujourd'hui désuète. On ne présente que la syntaxe ultérieure à la norme C99.
Codage de l'en‑tête d'une fonction
En langages C et C++, l'en‑tête (en anglais header) d'une fonction est une expression déclarative dont la forme syntaxique usuelle (simplifiée) est :
descripteur de type
nom de la fonction
(liste des arguments formels)
Dans cette forme syntaxique :
- le descripteur de type code le type des valeurs retournées – on dit aussi rendues – par la fonction (ces valeurs étant elles-mêmes déterminées par les instructions du corps de définition) ;
- le nom de la fonction est un identificateur choisi par le codeur pour pouvoir ensuite appeler la fonction dans le programme ; ce nom obéit aux règles usuelles de formation des identificateurs (cf. chap. C2‑X ) ;
- la liste des arguments formels – on emploie aussi le terme de paramètre – est une séquence (éventuellement vide) de n expressions de déclaration de données, conformes à la syntaxe générale déclarative (cf. chap. C2‑III ), c'est‑à‑dire de la forme :
descr. de type 1 nom de l'argument 1, … , descr. de type n nom de l'argument n
chaque nom d'argument étant un identificateur choisi par le codeur qui sera utilisable exclusivement dans le corps de définition de la fonction afin d'exploiter sa valeur.
Dans l'en‑tête d'une fonction :
- Les parenthèses
( )délimitant la liste des arguments formels sont essentielles. Ce sont elles qui, syntaxiquement, distinguent la déclaration d'une fonction de celle d'une donnée. - Comme dans la déclaration d'une donnée, le descripteur de type peut être omis. Implicitement, le compilateur encode alors les valeurs rendues par la fonction dans le type
int. Une telle omission est vivement déconseillée car elle entache inutilement la lisibilité du programme source. - Les arguments formels d'une fonction peuvent être déclarés constants (avec le mot‑clef
const) . Ils peuvent même se voir affecter une valeur par défaut pour devenir optionnels lors du codage d'un appel .
void comme descripteur de type – cf. infra . On souhaite implémenter une fonction qui détermine si deux nombres entiers strictement positifs sont premiers entre eux W, c'est‑à‑dire s'ils n'ont aucun diviseur commun hormis le nombre 1. Donc, cette fonction doit :
- prendre deux arguments formels (les deux nombres entiers à tester) déclarés par exemple dans le type
unsigned; - retourner une valeur booléenne :
-
truesi les arguments passés lors d'un appel sont des nombres premiers entre eux, -
falsedans le cas contraire.
Ainsi, l'en‑tête de cette fonction peut se coder par exemple comme ci‑dessous :
bool arePrime(unsigned a, unsigned b) //...
Remarque : comme de façon très générale en codage, l'en‑tête d'une fonction dépend des identificateurs choisis par le codeur, et aussi de l'ordre de déclaration des arguments.
Codage du corps de définition d'une fonction
En langages C et C++, le corps (en anglais, body) d'une fonction est un bloc d'instructions qui suit immédiatement l'en‑tête. Comme tout bloc, il délimité par des accolades { } et peut inclure autant d'instructions que nécessaire.
Dans le corps d'une fonction, on dispose d'une grande liberté de codage :
- On peut déclarer des données locales, c'est‑à‑dire des constantes ou variables qui n'existent que dans son bloc. Ces données peuvent ensuite être lues et modifiées (sauf les constantes, bien sûr) dans toutes les instructions du bloc qui suivent leur déclaration. En revanche, elles ne sont pas visible en dehors de ce bloc (cf. chap. C4‑II ).
- On peut lire et modifier les valeurs des arguments formels (sauf s'ils ont été déclarés constants).
- On peut lire et modifier des données globales du programme qui sont déclarées avant le corps de définition. Toutefois, cette pratique doit être aussi rare que possible, afin de minimiser les risques d'effets de bord indésirables (cf. chap. C2‑IV ).
- On peut appeler des fonctions préalablement déclarées, y compris la fonction elle‑même (on parle alors de récursivité).
- On peut coder des points de retour à l'instruction appelante par des instructions de la forme :
return expression;
où l'expression code la valeur retournée par la fonction lors de l'exécution.
Notion de point de retour d'un appel de fonction
Dès à présent, il importe de bien comprendre la notion de point de retour d'un appel de fonction. Lors de l'évaluation d'une expression d'appel de la fonction, le processus d'exécution :
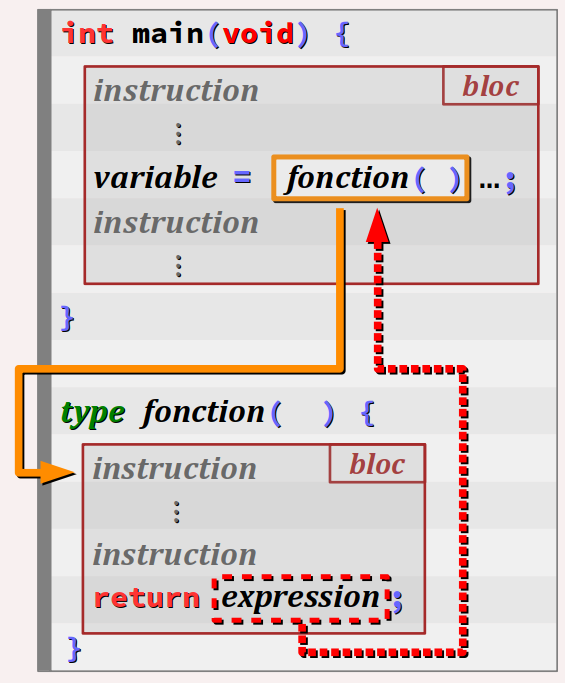
- suspend l'instruction appelante (celle dans laquelle l'expression d'appel est codée) ;
- passe aux instructions de la fonction appelée dans l'ordre défini par son code (ordre des instructions et structures de contrôle) ;
- et ce jusqu'à rencontrer la première instruction commençant par le mot‑clef
return;
Le processus d'exécution retourne alors à celui de l'instruction appelante en y injectant la valeur retournée par la fonction appelée. On comprend ainsi mieux le sens du mot‑clef return, qui pouvait peut‑être sembler abstrait jusque là.
En l'absence d'instruction return, la fonction appelée est exécutée jusqu'à sa dernière instruction et retourne une valeur « aléatoire ».
Dans le corps de définition d'une fonction, il est possible de coder des points de sortie de la fonction principale main, qui non seulement mettent fin à l'exécution de la fonction, mais qui également achève l'exécution du programme.
Il suffit pour cela d'appeler la fonction exit avec la syntaxe :
exit(expression);
où l'expression donne la valeur du code de sortie de la fonction main (cf. chap. C2‑I ).
La fonction exit est déclarée dans le fichier d'en‑tête de la bibliothèque standard stdlib.h du langage C (cstdlib en C++). Il faut donc une directive d'inclusion de ce fichier pour pouvoir l'utiliser (cf. chap. C2‑I .
Exemple
Reprenons l'exemple supra d'une fonction qui détermine si deux nombres entiers positifs sont premiers entre eux. Après l'en‑tête, le corps de définition de cette fonction peut se coder comme ci‑dessous (à partir de l'accolade ouvrante { à la ligne nº 5, et jusqu'à l'accolade fermante } de la ligne nº 13) en appliquant une version itérative de l'algorithme d'Euclide W :
#include <stdlib.h>
#include <stdbool.h>
bool arePrime(unsigned a, unsigned b)
{
if (a == 0 || b == 0) exit(1); // because algorithm would fail
while (b != 0) {
unsigned c = b;
b = a % b; // if (b) gets 0, then (b) is a multiple of (a)
a = c;
}
return (a == 1); // if (a == 1), then (b) had no higher dividers
}
//...
Ce bloc de définition code un processus récursif de calcul de reste de la division d'un nombre par l'autre, itéré tant que ce reste est différent de 0. On y trouve :
- une variable locale
cdéclarée en ligne nº 8 ; elle sert à garder en mémoire la valeur de l'argument formelbpour la recopier ensuite dans l'argument formela; - des modifications des arguments formels (lignes nº 9 & 10), ce qui est possible puisqu'ils n'ont pas été déclarés constants ;
- un point de retour normal à la fonction appelante (ligne nº 12), afin de retourner soit la valeur booléenne
1(équivalente àtrue), soit0(équivalente àfalse). - un point de sortie anormale (ligne nº 6), si l'un des deux arguments formels est nul, car dans ce cas, l'algorithme ne peut aboutir (cf. la remarque supra en version INITIÉ).
Dans ce corps de la fonction, on aurait pu aussi coder à la place de la ligne nº 12 (de façon algorithmiquement équivalente mais moins experte) :
if (a == 1) {
return true;
}
else {
return false;
}
On aurait eu alors deux points de retour normal.
Codage d'un appel de fonction
En C et C++ (comme dans la plupart des autres langages), un appel de fonction est une expression de la forme :
nom de la fonction(liste des arguments effectifs)
C'est en fait la même syntaxe que celle employée en mathématiques (cf. supra ).
Dans une expression d'appel de fonction :
- le nom de la fonction est l'identificateur de la fonction déclaré précédemment dans le fichier source ou dans le fichier d'en‑tête d'un module de bibliothèque inclus dans le programme ;
- la liste des arguments effectifs est une séquence de n expressions – autant que d'arguments formels dans l'en‑tête de la fonction – séparées par le symbole
,.
Au début de l’exécution d'un appel de la fonction, l'évaluation de chacune de ces expressions donne une valeur qui est affectée – on dit transmise – à chaque argument formel de la fonction, respectivement dans l'ordre de la liste.
Nonobstant les limites des langages C et C++ (notamment pour l'initialisation des variables globales – cf. chap. C2‑III ), un appel de fonction peut être codé dans n'importe quelle expression d'un code source dès lors que cette fonction a été préalablement déclarée ou définie.
Exemples
Reprenons le cas de la fonction arePrime définie dans un exemple précédent .
- Une expression d'appel comme par exemple
arePrime(10, 3)affecte les valeurs des arguments effectifs10et3respectivement aux arguments formelsaetbde la fonctionarePrime. Tout se passe comme si, au début du corps de la fonction, s'ajoutaient les instructions :
unsigned a = 10;etunsigned b = 10;
Ensuite, l'évaluation de l'expressionarePrime(10, 3)prend la valeur1(« vrai ») qui est retournée par la fonctionarePrimepuisque les entiers 10 et 3 sont premiers entre eux. - Considérons maintenant le code de la fonction principale
maind'un programme qui fait appel à la fonctionarePrime(à la ligne nº 26). - À la ligne nº 27, l'expression
arePrime(nb1, nb2)appelle la fonctionarePrimeavec comme arguments effectifs les variablesnb1etnb2(elles sont locales à la fonctionmain). - Lors de l'exécution, les valeurs courantes (préalablement saisies sur terminal par un utilisateur) de ces deux variables seront respectivement affectées aux arguments formels
aetbde la fonctionarePrime. - Les valeurs des variables
nb1etnb2ne sont pas modifiées par l'appel de la fonctionarePrime. Ce sont seulement leurs valeurs qui sont affectées aux arguments formelsaetbde façon temporaire lors de l'exécution.
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
bool arePrime(unsigned a, unsigned b)
{
if (a == 0 || b == 0) exit(1); // because algorithm would fail
while (b != 0) {
unsigned c = b;
b = a % b; // if (b) gets 0, then (b) is a multiple of (a)
a = c;
}
return (a == 1); // if (a == 1), then (b) had no higher dividers
}
int main(void) // test if two numbers are prime
{
unsigned nb1 = 0, nb2 = 0;
while (true) {
printf("Nombre entier 1 (taper 0 pour sortir) : ");
scanf("%u", &nb1);
if (nb1 == 0) break;
printf("Nombre entier 2 (taper 0 pour sortir) : ");
scanf("%u", &nb2);
if (nb2 == 0) break;
if (arePrime(nb1, nb2)) {
printf("%u et %u sont PREMIERS ENTRE EUX.\n\n", nb1, nb2);
}
else {
printf("%u et %u ne sont PAS premiers entre eux.\n\n", nb1, nb2);
}
}
printf("Au revoir.\n");
return 0;
}
arePrime(nb1, nb2), lors des appels de la fonction printf aux lignes nº 28 et 31, les expressions nb1 et nb2 gardent chacune la valeur qui a été saisie par l'utilisateur (par les appels de la fonction scanf codés aux lignes nº 21 et 24). Dans l'exemple 2) ci‑dessus, les variables nb1 et nb2 auraient très bien pu être nommées a et b comme dans le bloc de définition de la fonction. Le programme serait resté compilable car le compilateur fait la distinction entre les arguments formels d'une fonction et les arguments effectifs d'un appel de cette même fonction.
Notion de transmission d'argument par valeur
On formalise ici ce qui vient d'être abordé dans le cadre de l'exemple précédent.
La syntaxe usuelle (simplifié) de codage d'une fonction exposée au début du chapitre induit, lors de l'appel de cette fonction, ce qu'on appelle une transmission d'argument par valeur : ce sont les valeurs des arguments effectifs de l'appel sont qui transmises respectivement aux arguments formels de la fonction.
Dans ce mode de transmission, les éventuelles variables figurant dans les expressions formant les arguments effectifs ne sont pas modifiées par un appel de la fonction, même si chacune de ces expression a le même identificateur que son argument formel correspondant.
Plus précisément, lors de l'évaluation d'une expression d'appel de la fonction, chaque de ses arguments formels fait l'objet d'une affectation et prend la valeur courante de son argument effectif correspondant. En aucun cas la fonction n'agit directement sur l'espace mémoire adressable réservé aux arguments effectifs, pour la bonne et simple raison que ces arguments ne sont pas nécessairement des variables déclarées, mais parfois de simples constantes numériques mémorisées dans le code machine du programme (donc sans espace mémoire adressable) – cf. l'exemple 1 supra .
Et quand bien même les arguments effectifs se réduiraient à des identificateurs de variables, ces dernières ne sont pas modifiées par appel d'une fonction dont la syntaxe est celle d'une transmission d'arguments par valeur. Il ne s'agit en quelque sorte que d'une « copie » de valeurs comme dans l'exemple 2 supra .
Mais il est utile de savoir dès à présent qu'il existe deux autres syntaxes de codage pour pouvoir modifier des variables prises comme arguments effectifs d'une fonction :
Enchaînement d'appels de fonctions
Dans une expression d'appel de fonction, il est fréquent que l'expression codée pour un argument effectif soit elle‑même un autre appel de fonction, comme par exemple dans le schéma syntaxique simplifié suivant :
f1(f2(arg))

Un tel enchaînement d'appels de fonction consiste donc à passer la valeur retournée par la fonction f2 comme argument effectif de la fonction f1, ce qui peut se représenter par le schéma‑bloc ci‑contre.
Remarque. Sur le schéma‑bloc, dans le sens de lecture usuel (de gauche à droite), l'ordre des blocs des fonctions appelées apparaît inversé par rapport à celui de l'expression syntaxique de codage f1(f2(arg)) . Cette inversion met en lumière le fait que, lors de l'évaluation de cette expression, c'est la sous‑expression f2(arg)) qui est traitée en premier.
En mathématiques, on parle de composition de fonctions et on note ∘ (nommé « rond ») l'opérateur de composition ; par définition, on a f1 ∘ f2(x) = f1(f2(x)).
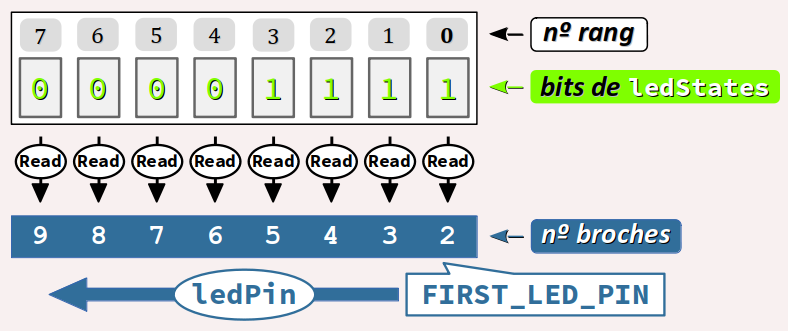
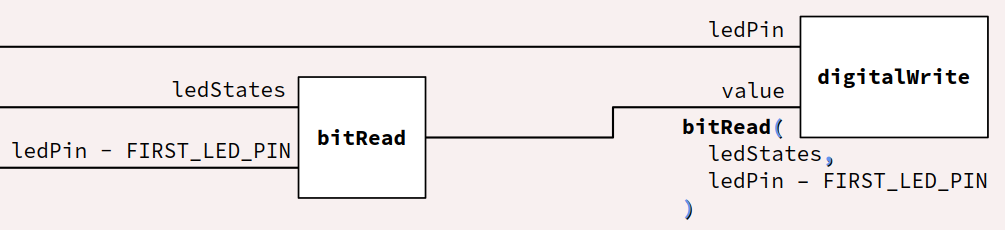
Dans le programme d'animation d'un bargraphe piloté par une carte Arduino (cf. le sujet de TP C3‑2 ), on peut opérer par l'intermédiaire d'une variable d'état nommée ledStates qui mémorise l'état des 8 leds sous la forme d'un mot binaire de 8 bits. Pour recopier les valeurs de ces bits sur les 8 broches du port de sortie numérique auxquelles les leds sont raccordées, on peut coder la boucle for suivante :
for (int8_t ledPin = FIRST_LED_PIN; ledPin <= LAST_LED_PIN; ledPin++) {
digitalWrite(ledPin, bitRead(ledStates, ledPin - FIRST_LED_PIN));
}
Dans cette boucle, l'appel de la fonction digitalWrite est composé avec celui de bitRead conformément au schéma‑bloc ci‑dessous.
Jeu d'essais d'une fonction
Un jeu d'essais d'une fonction est un programme qui comprend une série d'appels de la fonction, afin de tester son bon fonctionnement dans le plus grand nombre de cas possibles.
Pour chaque appel, il importe de choisir judicieusement les valeurs des arguments effectifs – valeurs usuelles, valeurs remarquables, cas limites… – sachant que tester la totalité des combinaisons des valeurs est le plus souvent infaisable.
Pour la fonction arePrime codée précédemment , on propose le jeu d'essais mis en œuvre dans la fonction main ci‑dessous :
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
bool arePrime(unsigned a, unsigned b)
{
if (a == 0 || b == 0) exit(1); // because algorithm would fail
while (b != 0) {
unsigned c = b;
b = a % b; // if (b) gets 0, then (b) is a multiple of (a)
a = c;
}
return (a == 1); // if (a == 1), then (b) had no higher dividers
}
int main(void) // test combinations of (a) and (b) < 10
{
unsigned nb1 = 10;
for (unsigned nb2 = nb1; nb2 >= 1; nb2--) {
if (arePrime(nb1, nb2)) {
printf("%u et %u sont PREMIERS ENTRE EUX. \n", nb1, nb2);
}
else {
printf("%u et %u ne sont PAS premiers entre eux. \n", nb1, nb2);
}
if (arePrime(nb1, nb2) != arePrime(nb2, nb1)) {
printf("ERREUR pour %d et %d !!! \n", nb1, nb2);
}
}
arePrime(0, 1); // you must test also arePrime(0, 1) and arePrime(0, 0)
return 0;
}
Avec OnlineGDB, on obtient en sortie standard l'affichage suivant :
10 et 10 ne sont PAS premiers entre eux.
10 et 9 sont PREMIERS ENTRE EUX.
10 et 8 ne sont PAS premiers entre eux.
10 et 7 sont PREMIERS ENTRE EUX.
10 et 6 ne sont PAS premiers entre eux.
10 et 5 ne sont PAS premiers entre eux.
10 et 4 ne sont PAS premiers entre eux.
10 et 3 sont PREMIERS ENTRE EUX.
10 et 2 ne sont PAS premiers entre eux.
10 et 1 sont PREMIERS ENTRE EUX.
...Program finished with exit code 1
On voit donc que ce jeu d'essais, bien que très limité, vise à opérer plusieurs vérifications essentielles :
- Il affiche le résultat de la fonction pour dix combinaisons de valeurs en fixant le premier entier à 10 et décrémentant le deuxième de 10 à 1 (tous les résultats obtenus sont faciles à vérifier de tête). On peut aisément vérifier de tête qu'on obtient des résultats conformes aux attentes.
- Il permet aussi de s'assurer automatiquement que la fonction retourne bien la même valeur lorsqu'on permute les valeurs des deux arguments effectifs ; sinon, il signalerait l'erreur (ici, ce n'est pas le cas donc tout va bien).
- Enfin, il tester le cas limites où le premier argument effectif est nul ; et on obtient bien, comme attendu, le code de sortie
1(et non pas0) du programme en fin d'exécution.
arePrime(0, 1) et arePrime(0, 0), mais cela n'est pas possible en une seule exécution, puisqu'une sortie anticipée du programme ne peut intervenir qu'une seule fois par exécution. Il faut donc modifier le code source et exécuter le programme pour chaque cas. Bases de la programmation procédurale
Principes de la programmation procédurale
La programmation procédurale W est une méthode de codage qui consiste à concevoir tout programme avec un algorithme principal – typiquement, celui de la fonction main en C ou C++ – le moins raffiné possible :
- chaque étape (ou partie) de l'algorithme faisant appel à une fonction distincte, qu'on peut qualifier d'auxiliaire ;
- chaque fonction auxiliaire pouvant elle‑même se décomposer de la sorte, jusqu'à atteindre une « élémentarité » suffisante pour que son code soit très facile à produire et vérifier.
Avec une telle décomposition, les fonctions « élémentaires » doivent pouvoir être codées séparément par les différents codeurs d'une équipe de développement (ou même par des sous‑traitants), sans connaître le code source des autres fonctions. En principe, il suffit de fournir pour chacune :
- son identificateur, son type de valeur de retour et ses arguments formels – autrement dit tous les éléments de sa déclaration ;
- son objectif – ou son rôle – c'est‑à‑dire, en définitive, tout ce qui détermine sa valeur de retour pour les différentes valeurs possibles de ses arguments formels.
Dans le cadre du développement d'un logiciel, la décomposition du code – et donc de la répartition du travail – obéit à des usages spécifiques à tel ou tel domaine (progiciel, jeux vidéo, etc.), et varie selon la composition de l'équipe en charge. Elle incombe en général au chef de projet ou à l'architecte logiciel, qui doit faire en sorte que son équipe dispose des informations nécessaires au travail de codage des définitions des fonctions.
Par ailleurs, pour des raisons évidentes d'optimisation des coûts de développement, on s'efforce :
- d'employer des fonctions déjà codées – en particulier dans les bibliothèques existantes – plutôt que de tout systématiquement « réinventer » ;
- d'organiser les nouvelles fonctions en modules de bibliothèque compilables séparément si elles sont susceptibles d'être réutilisées dans d'autres programmes.
Ce sont les bases de la programmation modulaire, qui sera abordée au chapitre C4‑VI .
Le programme académique de l'exemple 2 supra pour déterminer si deux nombres sont premiers entre eux peut encore être décomposé. En particulier, dans la fonction principale main :
int main(void) // test if two numbers are prime
{
unsigned nb1 = 0, nb2 = 0;
while (true) {
printf("Nombre entier 1 (taper 0 pour sortir) : ");
scanf("%u", &nb1);
if (nb1 == 0) break;
printf("Nombre entier 2 (taper 0 pour sortir) : ");
scanf("%u", &nb2);
if (nb2 == 0) break;
if (arePrime(nb1, nb2)) {
printf("Les entiers %u et %u sont PREMIERS ENTRE EUX.\n", nb1, nb2);
}
else {
printf("Les entiers %u et %u ne sont PAS premiers entre eux.\n", nb1, nb2);
}
}
printf("Au revoir.\n")
return 0;
}
la saisie des deux nombres à tester emploie deux fois un code similaire (lignes nº 20 à 22 et nº 23 à 25).
On a donc intérêt factoriser ce code dans une nouvelle une nouvelle fonction comme celle nommée enteringNumber codée ci‑dessous aux lignes nº 20 à 22 (effectuant un passage d'argument par adresse, elle utilise un pointeur – un concept qui sera étudié au chap. C5‑I ) :
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
bool arePrime(unsigned a, unsigned b)
{
if (a == 0 || b == 0) exit(1); // because algorithm would fail
while (b != 0) {
unsigned c = b;
b = a % b; // if (b) gets 0, then (b) is a multiple of (a)
a = c;
}
return (a == 1); // if (a == 1), then (b) had no higher dividers
}
void enteringNumber(unsigned order, unsigned * number)
{
printf("Nombre entier %u (taper 0 pour sortir) : ", order);
scanf("%u", number);
if (*number == 0) {
printf("Au revoir.\n");
exit(0);
}
}
int main(void) // test if two numbers are prime
{
unsigned nb1 = 0, nb2 = 0;
while (true) {
enteringNumber(1, &nb1);
enteringNumber(2, &nb2);
if (arePrime(nb1, nb2)) {
printf("%u et %u sont PREMIERS ENTRE EUX.\n\n", nb1, nb2);
}
else {
printf("%u et %u ne sont PAS premiers entre eux.\n\n", nb1, nb2);
}
}
}
Avec deux fonctions auxiliaires au lieu d'une seule, ce programme est plus procédural que dans sa version précédente.
Notion de prototype d'une fonction
Une idée clef de la programmation procédurale est de permettre, pour toute fonction auxiliaire d'un programme, de séparer sa déclaration et sa définition, dans la perspective que :
- la déclaration puisse être communiquée sans réserve à tous les développeurs du projet (ou du moins, à une grande partie) ;
- tandis que la définition reste confidentielle à un nombre restreint de personnes (ses développeurs bien sûr, le chef de projet…).
La fonction apparaît donc comme une concept de « boîte noire » dont on n'a pas besoin de connaître les détails de conception et de fonctionnement pour l'utiliser.
Plus généralement, c'est ainsi que fonctionnent tous les produits techniques, notamment les appareils « grand public » (pensons à un lecteur de DVD), que l'on commande à l'aide d'une interface très simple au regard de la complexité interne, que l'utilisateur n'a pas besoin – ni même envie – de maîtriser.
Les langages C et C++ disposent pour cela de la notion de prototype d'une fonction. C'est une instruction déclarative qui est :
- constituée du seul en‑tête de la fonction (et donc, pas suivi de son corps de définition) ;
- simplement terminée par le délimiteur
;de fin d'instruction.
Le prototype de la fonction arePrime définie supra se code tout simplement :
bool arePrime(unsigned a, unsigned b);
Attention, pour coder certains aspects avancés (cf. infra ), le prototype d'une fonction peut être différent de l'en‑tête de son code de définition.
En particulier, lorsqu'une fonction n'a pas arguments optionnels, on peut coder son prototype abrégé : dans la liste des arguments formels de la fonction, on peut omettre les identificateurs.
Structure d'un programme procédural
Dans un programme procédural en langage C ou C++, comme pour les données, il est obligatoire de préalablement déclarer toute fonction auxiliaire avant de l'utiliser dans le code, c'est‑à‑dire de l'appeler dans une autre fonction.
C'est notamment à cela que sert son prototype.
Même en restant dans le cadre d'un fichier unique (les techniques de répartition du code sur plusieurs fichiers ne seront abordées qu'au chapitre C4‑V ), un programme procédural doit être structuré selon des règles de bonnes pratiques. En particulier, il est recommandé que toutes les fonctions auxiliaires soient :
- déclarées par leur prototype avant la fonction principale
main; - définies par leur code complet (en‑tête et corps de définition) après la fonction
main, et dans le même ordre que celui des prototypes.
Cette manière de coder permet de garder la fonction main en début de fichier, ce qui rend son accès facile dans un éditeur de code. A contrario, il serait malcommode de la placer après la définition de toutes les fonctions auxiliaires : elle se retrouverait en en fin de fichier ce qui nécessiterait des manipulations fastidieuses pour l'atteindre.
L'ordre de déclaration des prototypes dépend de la complexité du programme.
- On peut adopter l'ordre d'occurrence des appels des fonctions auxiliaires dans la fonction
main. - C'est pourquoi on peut aussi privilégier un ordre thématique d'organisation, c'est‑à‑dire par exemple regrouper toutes les fonctions d'entrées‑sorties, les fonctions de connexion au réseau, etc. Presque toujours, cette approche est la plus satisfaisante, car elle préfigure la répartition du programme sur plusieurs fichiers.
Le programme académique des exemples précédents, qui teste en boucle si deux entiers saisis par l'utilisateur sont premiers entre eux, peut finalement se coder de façon plus conforme aux usages de la programmation procédurale, comme ci‑dessous :
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
void enteringNumber(unsigned n, unsigned * number);
bool arePrime(unsigned a, unsigned b);
int main(void) // test if two numbers are relatively prime
{
unsigned nb1 = 0, nb2 = 0;
while (true) {
enteringNumber(1, &nb1);
enteringNumber(2, &nb2);
if (arePrime(nb1, nb2)) {
printf("%u et %u sont PREMIERS ENTRE EUX.\n\n", nb1, nb2);
}
else {
printf("%u et %u ne sont PAS premiers entre eux.\n\n", nb1, nb2);
}
}
return 0;
}
void enteringNumber(unsigned n, unsigned * number)
{
printf("Nombre entier %u (taper 0 pour sortir) : ", n);
scanf("%u", number);
if (*number == 0) {
printf("Au revoir.\n");
exit(0);
}
}
bool arePrime(unsigned a, unsigned b)
{
if (a == 0 || b == 0) exit(1); // because algorithm would fail
while (b != 0) {
unsigned c = b;
b = a % b; // if (b) gets 0, then (b) is a multiple of (a)
a = c;
}
return (a == 1); // if (a == 1), then (b) had no higher dividers
}
Ici :
- les fonctions auxiliaires ont été placées après la fonction principale
main. - Leurs prototypes respectifs sont codés en préambule, après les directives d'inclusion.
Cas d'un programme Arduino

Dans les fichiers d'extension .ino d'un programme pour carte Arduino, le codeur n'a pas besoin de déclarer préalablement les prototypes des fonctions auxiliaires avant de les appeler dans les fonctions setup et loop.
Le fait de coder leur prototype en début de fichier peut même causer des erreurs de compilation.
En effet, sans doute pour faciliter la programmation aux codeurs « débutants », le logiciel Arduino IDE effectue des traitements préliminaires avant la compilation C++. Et en particulier, il ajoute automatiquement en début de fichier les prototypes des fonctions auxiliaires non déclarées.
En Arduino, il est donc d'usage de coder toutes les fonctions auxiliaires en fin de fichier et sans prototypes.
Toutefois, on doit garder à l'esprit :
- que cette pratique n'est pas valide dans un programme usuel en C ou C++, ou même dans un projet Arduino comportant des fichiers d'extension
.cpp; - que les prototypes restent parfois indispensables même dans un fichier d'extension
.ino, par exemple pour coder des fonctions avec des arguments formels prenant une valeur par défaut .
Dans un programme pilotant des led, il est usuel de regrouper tous les appels de fonctions pour la configuration et l'initialisation des broches d'entrées‑sorties numériques dans une fonction auxiliaire de type void nommée par exemple initPins.
De même, on peut utilement coder un bloc de clignotement paramétré par la période et la durée du clignotement dans une fonction auxiliaire de type void, nommée par exemple busyBlink.
Le programme académique ci‑dessous met en œuvre ces deux fonctions avec un bouton‑poussoir qui déclenche une telle séquence de clignotement d'une led. Il peut être testé sur Tinkercad avec le montage du sujet de TP C2‑1 .
const int LED_PIN = 2;
const int BUTTON_PIN = 7;
void setup()
{
initPins();
}
bool previousButtonLevel = LOW;
bool currentButtonLevel = LOW;
void loop()
{
previousButtonLevel = currentButtonLevel;
currentButtonLevel = digitalRead(BUTTON_PIN);
if (currentButtonLevel == HIGH && previousButtonLevel == LOW) { // rising edge
busyBlink(200, 1000);
}
}
void initPins()
{
pinMode(LED_PIN, OUTPUT);
digitalWrite(LED_PIN, LOW);
pinMode(BUTTON_PIN, INPUT);
}
void busyBlink(uint16_t halfPeriod, uint32_t duration)
{
uint32_t millisecondsCounter = 0;
while (millisecondsCounter <= duration - halfPeriod) {
digitalWrite(LED_PIN, HIGH);
delay(halfPeriod);
millisecondsCounter += halfPeriod;
digitalWrite(LED_PIN, LOW);
if (millisecondsCounter > duration - halfPeriod) {
return;
} // else
delay(halfPeriod);
millisecondsCounter += halfPeriod;
}
}
Restrictions sur les fonctions imbriquées
Les normes des langages C/C++ imposent certaines restrictions au codage du corps de définition d'une fonction. En particulier, il est interdit de coder la définition d'une fonction dans une autre fonction. En d'autres termes, on peut dire que l'imbrications de fonctions – ou fonctions « gigognes », en anglais nested functions – est interdite.


Toutefois – et même si cet usage est rare et plutôt déconseillé – il est autorisé par la chaîne de compilation GCC comme une extension au langage C, mais pas au C++. Et il est signalé par un avertissement en recourant à l'option de compilation -Wpedantic (cf. chap. C1‑II ).
En revanche, les normes des langages C/C++ autorisent le codage des prototypes de fonctions au sein d'autres fonctions même si, là encore, ce genre de pratique est rare.
- Il peut éventuellement se justifier en langage C pour limiter l'usage d'une fonction à la seule fonction dans laquelle le prototype est déclaré.
- Mais ce genre de technique est peu utile en C++ car on dispose de tous les outils de la programmation orientée objet, qui permet des limitations beaucoup plus souples et structurées, notamment avec la distinction des déclarations publiques/privées et la notion de fonction amie.
Reprenons l'exemple du programme académique proposé au chapitre C1‑II qui, à la ligne nº 3, définit la fonction square dans la fonction main :
int main(void)
{
float square(float x) {return x * x;} // nested function
return square(2);
}

On a déjà vu que ce programme était parfaitement compilable et exécutable via la commande gcc – donc, en langage C avec extensions GNU, sauf si l'on invoque comme option -Wpedantic ou -pedantic-errors.
En revanche, on observe un échec de la compilation avec la commande g++ – donc, en langage C++ – avec ou sans options :
g++ nestedSquare.c -o nestedSquarenestedSquare.c: In function ‘int main()’: nestedSquare.c:3:25: error: a function-definition is not allowed here before ‘{’ token 3 | float square(float x) {return x * x;} | ^ nestedSquare.c:4:10: error: ‘square’ was not declared in this scope 4 | return square(2); | ^~~~~~
Par ailleurs, si l'on code seulement le prototype de la fonction square dans main et qu'on déporte sa définition en fin de programme, comme ci‑dessous (cf. la ligne nº 7) :
int main(void)
{
float square(float x);
return square(2);
}
float square(float x) {return x * x;}
alors le programme devient compilable dans le strict respect de la norme en langages C/C++.
Et alors, en déclarant préalablement une autre fonction nommée foo dans laquelle on coderait un appel de la fonction square, comme ci‑dessous à la ligne nº 9 :
int foo(void);
int main(void)
{
float square(float x);
return square(2);
}
int foo(void) {return square(1);}
float square(float x) {return x * x;}
on aboutirait à une erreur de compilation :
gcc nestedProto.c -o nestedProtogcc nestedProto.c -o nestedProto nestedProto.c: In function ‘foo’: nestedProto.c:9:23: warning: implicit declaration of function ‘square’ [-Wimplicit-function-declaration] 9 | int foo(void) {return square(1);} | ^~~~~~ nestedProto.c:5:9: note: previous declaration of ‘square’ with type ‘float(float)’ 5 | float square(float x); | ^~~~~~ nestedProto.c:9:23: error: incompatible implicit declaration of function ‘square’ 9 | int foo(void) {return square(1);} | ^~~~~~ nestedProto.c:5:9: note: previous implicit declaration of ‘square’ with type ‘float(float)’ 5 | float square(float x); | ^~~~~~

Particularités et possibilités avancées de codage d'une fonction
Fonction sans valeur et/ou sans arguments – le type void
Rappelons que par défaut :
- s'il n'est pas explicitement codé, le type par défaut des valeurs retournées par une fonction est
int; - quel que soit le type d'une fonction, sans l'occurrence du mot‑clef
returnsuivi d'une expression dans le code de la fonction, sa valeur retournée est aléatoire.
Fonction sans valeur de retour
Pour prévenir les risques de confusion évoqués supra et d'éventuelles erreurs conséquentes, il est utile de pouvoir coder des fonctions qui, explicitement, ne retournent aucune valeur – ce qui correspond à la notion de « procédure » dans un langage comme Pascal.
Les langages C et C++ mettent à disposition le mot‑clef void qui désigne le type vide. Ainsi, un en‑tête de fonction de la forme :
void
nom de la fonction
(liste des arguments formels)
déclare une fonction qui ne retourne pas de valeur.
En conséquence, une telle fonction ne peut pas être appelée dans une expression de calcul ou d'affectation, mais seulement dans une instruction constituée du seul appel de cette fonction, c'est‑à‑dire de la forme :
nom de la fonction
(liste des arguments effectifs);
Dans le corps de définition d'une telle fonction, on peut coder des points de retour à l'instruction dans laquelle elle est appelée (main ou autre) par autant d'instructions de la forme :
return;
sans expression de retour après le mot‑clef return.
Bien entendu, ce n'est pas parce qu'une fonction ne retourne aucune valeur qu'elle est sans effet.
De nombreuses fonctions du framework Arduino comme setup, loop, delay, digitalWrite, bitSet, etc. sont de type void.
En revanche, certaines fonctions comme printf (cf. chap. C2‑VII ) ne sont pas de type void, même si elles sont très souvent appelées comme telles, en ignorant leur valeur de retour.
Fonction sans arguments
Le type void permet également de coder une fonction qui n'admet aucun argument, avec un en‑tête de la forme :
descripteur de type
nom de la fonction(void)
où la liste des arguments formels est donc remplacée par le mot‑clef void.
On code un appel d'une telle fonction par une expression de la forme :
nom de la fonction()
où la liste des arguments effectifs est simplement vide.
De nombreuses fonctions Arduino comme setup, loop, millis, Serial.end, Serial.available, etc. sont sans argument.
De même, de façon générale en langages C/C++, la fonction main est très souvent codée sans arguments – sachant qu'il peut aussi en être autrement – cf. partie C6).
Il existe une deuxième syntaxe fréquemment employée qui consiste à coder la liste des arguments formels de la fonction simplement par des parenthèses vides ().
Toutefois, en langage C, cette deuxième syntaxe n'est pas équivalente à la précédente. Pour comprendre la différence, il importe de bien distinguer le prototype et l'en‑tête de définition de la fonction. En effet, dans le prototype :
- le code
(void)impose explicitement que la fonction n'admet aucun argument formel ; - alors, l'en‑tête de définition de la fonction ne doit admettre aucun argument, autrement dit être codé
()ou(void), sinon la compilation échouera ; - et de même, toute expression d'appel de la fonction codée avec un argument effectif sera rejetée par le compilateur ;
- tandis que le code
()indique le fait que la fonction accepte un nombre quelconque d'arguments qui est déterminé dans l'en‑tête de définition ;
(void), les expressions d'appel de la fonction avec arguments effectifs sont acceptés par le compilateur, qui se contente de les ignorer. Pour illustrer cela, considérons le programme académique volontairement incohérent ci‑dessous :
#include <stdio.h>
void foo();
void bar();
int main(void)
{
foo(2, 3); // not consistent with the definition of foo!
bar(4); // not consistent with the definition of bar!
return 0;
}
void foo(int a)
{
printf("a = %d\n", a);
}
void bar(void)
{
printf("bar\n");
}
Le fait est qu'il est compilable en C – ce qui est tout à fait regrettable (on peut le vérifier sur OnlineGDB). Heureusement, il n'est pas compilable en C++.
De plus, si on remplace la ligne nº 8 par :
foo(); // not either consistent with the definition of foo!
on obtient lors de l'exécution une sortie standard comme a = 1 alors que l'appel de la fonction foo ne comporte aucun argument effectif. La valeur 1 affichée pour l'argument formel a est donc « fictive ».
En fait, cette deuxième syntaxe n'est maintenue valide que pour des questions de compatibilité avec les normes anciennes du langage C. Bien que moins rigoureuse, elle est très usitée, sans doute par « facilité » et ignorance des subtiles différences entre le C et le C++. Quoi qu'il en soit, il est recommandé de ne pas l'employer.
Transmission des arguments par référence (en C++)
Problématique
On a vu supra que la syntaxe usuelle de codage d'une fonction opère la transmission de tout argument effectif à son argument formel correspondant par valeur : même si dans une expression d'appel, l'argument effectif est codé comme l'identificateur d'une variable, la valeur de cette dernière n'est pas modifiée par l'appel de la fonction.
Néanmoins, en programmation impérative, il est indispensable que des fonctions puissent aussi modifier des variables.

On souhaite coder une fonction swapInt qui permute les valeurs respectives de deux variables entières :
#include <stdio.h>
void swapInt(int a, int b) // warning: DOES NOT WORK!
{
int c = a;
a = b;
b = c;
}
int nb1 = 1, nb2 = 2;
int main(void)
{
printf("BEFORE swap: nb1 = %d nb2 = %d\n", nb1, nb2);
swapInt(nb1, nb2);
printf(" AFTER swap: nb1 = %d nb2 = %d\n", nb1, nb2);
return 0;
}
Néanmoins, lors de l'exécution, la fonction swapInt codée ci‑dessus ne produit pas le résultat attendu :
BEFORE swap: nb1 = 1 nb2 = 2 AFTER swap: nb1 = 1 nb2 = 2
En effet, elle adopte la syntaxe usuelle de transmission des arguments par valeurs.
Bien entendu, il existe des solutions :
- en langage C (et donc aussi en C++), avec le recours aux pointeurs et la transmission des arguments par adresse, mais cette technique est abordée seulement à partir du chapitre C5‑I ;
- en langage C++ (et donc aussi en Arduino, mais pas en C), grâce à la notion de référence W, dont l'usage est très simple et peut être étudié dès maintenant.
Codage de la transmission d'un argument par référence (en C++)
En langage C++, dans le codage d'une fonction, un argument est transmis par référence si, dans la liste des arguments formels de l'en‑tête de la fonction, il est codé conformément au schéma syntaxique ci‑dessous :
descripteur de type & nom de l'argument
Dans l'appel de la fonction, l'argument effectif doit alors impérativement être l'identificateur d'une variable de type équivalent – même taille, même format – à celui de l'argument formel.
Quant au codage du corps de définition de la fonction, il suit les mêmes règles syntaxiques que si l'argument était transmis par valeur : ce dernier est manipulable directement par l'identificateur codé dans l'en‑tête.
Dans le prototype abrégé de la fonction (cf. supra ), l'identificateur de l'argument formel peut être omis (comme pour une transmission par valeur) mais le symbole de référence & doit être codé.
Reprenons l'exemple précédent la fonction qui doit permuter la valeur de deux variables entières. Codée ci‑dessous en C++ avec la transmission de ses deux arguments par référence :
#include <cstdio>
void swapInt(int & a, int & b) // With references, IT WORKS!
{
int c = a;
a = b;
b = c;
}
int nb1 = 1, nb2 = 2;
int main(void)
{
printf("BEFORE swap: nb1 = %d nb2 = %d\n", nb1, nb2);
swapInt(nb1, nb2);
printf(" AFTER swap: nb1 = %d nb2 = %d\n", nb1, nb2);
return 0;
}
la fonction swapInt devient opérationnelle puisqu'on obtient en sortie standard l'affichage attendu :
BEFORE swap: nb1 = 1 nb2 = 2 AFTER swap: nb1 = 2 nb2 = 1
Dans le programme ci‑dessus, on voit donc que par rapport à une transmission d'argument par valeur, seul l'en‑tête de la fonction swapInt est modifié. D'un point de vue syntaxique, la transmission d'argument par référence est donc particulièrement facile à coder, ce qui est appréciable pour les débutants.
- L'exigence d'équivalence de types entre un argument formel de fonction et son argument effectif lors d'un appel est stricte et aucune conversion implicite ou explicite ne peut y remédier.
- si, dans l'exemple supra, à la ligne nº 10, on codait les arguments effectifs
nb1etnb2de typeint32_t, le programme resterait compilable pour un PC puisque sur une telle machine, le typeintdes arguments formelsaetbest encodé sur 32 bits, ; - en revanche, si on codait
nb1etnb2de typeunsigned, la compilation échouerait, par incompatibilité de format (non signé versus signé) avec le typeint. - Insistons sur le fait que dans une transmission d'argument par référence, il est impératif que l'argument effectif ne soit pas une expression quelconque – alors que ce peut être le cas avec une transmission par valeur. Pour le comprendre, imaginons l'exemple absurde de l'instruction d'appel (non compilable) ci‑dessous :
swapInt(1, 2); // nonsense!
Cela reviendrait à essayer de permuter les valeurs stockées aux adresses respectives des nombres1et2– adresses qui bien évidemment n'existent pas puisque ce ne sont pas des données déclarées.
Argument prenant une valeur par défaut
Dans un appel de fonction, il est parfois commode de pouvoir omettre un argument effectif, et qu'alors son argument formel correspondant prenne une valeur par défaut. Un tel argument peut alors être considéré comme « optionnel ».
Cette possibilité existe en langage C++ (pas en C) en codant uniquement dans le prototype de la fonction (et pas dans l'en‑tête de définition) une affectation de valeur à l'argument formel (comme pour une initialisation dans le cadre d'une déclaration), conformément au schéma syntaxique :
(descripteur de type identificateur = valeur)
Et si plusieurs arguments font l'objet d'un tel codage, ils doivent être tous regroupés à la fin de la liste des arguments formels.
Dans les protocoles de communication (notamment pour la liaison série), on effectue souvent un contrôle de parité pour vérifier la bonne transmission des données. Ce contrôle consiste en particulier à compter dans un mot binaire le nombre de bits à 1 (cf. les techniques de checksum W).
À titre académique, on se propose de coder une fonction nommée bitCount :
- qui compte et retourne le nombre de bits valant
1dans une donnée de typeuint8_t; - et ceci en partant du bit de rang 0 et en allant jusqu'à un rang limite constituant un argument de la fonction, avec
7comme valeur par défaut (le plus haut rang possible des bits pour le typeuint8_t).
#include <stdio.h>
#include <stdint.h>
int bitCount(const uint8_t data, int limitRank = 7);
int main(void)
{
uint8_t byteData = 0b11111111;
printf("%d\n", bitCount(byteData, 4));
printf("%d\n", bitCount(byteData));
return 0;
}
int bitCount(const uint8_t data, int limitRank)
{
if (limitRank < 0) return -1;
else if (limitRank > 7) limitRank = 7;
int counter = 0;
uint8_t mask = 0b1;
for (int rank = 0; rank <= limitRank; rank++) {
if ((mask & data) == mask) counter++;
mask <<= 1;
}
return counter;
}
Dans le prototype de la fonction bitCount, l'argument formel limitRank se voit donc attribué 7 comme valeur par défaut. Cet aspect n'est pas codé dans l'en‑tête de définition de la fonction.
Dans la fonction main, on teste deux appels de cette fonction bitCount sur le mot binaire byteData qui vaut 0b11111111 (8 bits à 1) :
- en ligne nº 9, avec la valeur
4comme deuxième argument effectif, qui écrase la valeur par défaut ; - en ligne nº 10, avec un seul argument effectif, autrement dit sans valeur transmise à
limitRank, qui prend alors sa valeur par défaut (7) ;
5 puisqu'il y a bien 5 bits à 1 du rang 0 au rang 4 ; 8 comme attendu. Sur OnlineGDB, on peut facilement vérifier que ce programme n'est pas compilable en langage C.
Surcharge d'un identificateur de fonction
Dans un programme, il est souvent utile qu'un argument de fonction puisse prendre des valeurs de types différents. C'est notamment le cas avec les opérateurs arithmétiques, qui s'appliquent aussi bien à des données entières que décimales, et ce quelle que soit la taille ou le caractère signé/non signé du type dans lequel ces données sont encodées.
Cette possibilité existe en langage C++ (pas en C) à travers la notion de surcharge d'identificateur de fonction – on parle aussi de sur‑définition de fonction :
- techniquement, le compilateur accepte qu'un même identificateur soit employé pour plusieurs déclarations de la fonction, chaque déclaration étant accompagnée de sa définition ;
- mais pour que le compilateur puisse ensuite choisir quelle définition de la fonction appliquer lors d'un appel, il est impératif que chacune se distingue des autres par une liste d'arguments formels qui lui soit propre, grâce à des différences de types.
En termes de compilation, les règles de choix d'une fonction sur‑définie sont complexes (elles ne seront pas détaillées ici), et elles ne peuvent suffire à résoudre tous les conflits imaginables entre deux voire plusieurs déclarations. En particulier, un problème peut se poser lorsque une fonction sur‑définie est appelée avec un argument effectif dont le type ne correspond à aucun des types de l'argument formel qui lui est associé par sa position dans la liste. Le compilateur doit alors effectuer une conversion mais laquelle ? Lorsqu'un conflit est non résolu, il engendre une erreur de compilation.
On souhaite que la fonction bitCount présentée supra puisse aussi s'appliquer à un mot binaire de type uint16_t. Bien entendu, dans ce cas, la valeur par défaut de l'argument formel limitRank sera 15 et non plus 7.
Au programme précédent, il suffit donc d'ajouter un nouveau prototype :
int bitCount(uint16_t data, int limitRank = 15);
et une nouvelle définition de fonction :
int bitCount(uint16_t data, int limitRank)
{
if (limitRank < 0) return -1;
else if (limitRank > 15) limitRank = 15;
int counter = 0;
uint16_t mask = 0b1;
for (int rank = 0; rank <= limitRank; rank++) {
if ((mask & data) == mask) counter++;
mask <<= 1;
}
return counter;
}
Dans la fonction main, on peut alors coder un appel de chaque fonction bitCount avec pour premier argument effectif un mot binaire de longueur implicitement spécifié par son type, par exemple :
int main(void)
{
uint8_t byteData = 0b11111111;
uint16_t wordData = 0b111111111111111;
printf("%d\n", bitCount(byteData));
printf("%d\n", bitCount(wordData));
return 0;
}
Le compilateur g++ saura automatiquement laquelle des deux fonctions bitCount appliquer.
Le programme supra n'est pas compilable si on code directement une constante littérale comme premier argument effectif dans un appel de fonction bitCount, comme ci‑dessous :
printf("%d\n", bitCount(0b11111111));
En effet, le compilateur n'est alors pas capable de choisir la fonction à appliquer car il commence par interpréter cette constante littérale dans le type standard unsigned int (promotion systématique – cf. chap. C3‑VI ) et ensuite, il n'est pas capable d'identifier le type de l'argument formel qui lui correspond le mieux.