Le concept de programmation modulaire a été maintes fois évoqués dans les chapitres de ce module de formation – et dès le tout premier (cf. chap. C1‑I ). L'enjeu principal n'est pas seulement de pouvoir répartir le code d'un programme sur plusieurs fichiers pour mieux le maîtriser. Il est aussi de produire autant que possibles des modules qui soient des composants logiciels réutilisables pour toutes sortes de programmes.
C'est d'ailleurs dans cette perspective que les langages C et C++ sont construits : autour d'un noyau assez réduit, ils acceptent un nombre illimité de modules de bibliothèque d'objets et de fonctions. En particulier, l'ensemble des modules qui forment ce qu'on appelle la bibliothèque standard (étudiée en détail au chap. C4‑VII ) est directement utilisable par le codeur via des directives d'inclusion (cf. chap. C4‑III )

Par ailleurs, le codeur est aussi en mesure de produire ses propres modules de bibliothèque afin que les mêmes fonctions d'usage général puissent être utilisées dans divers programme sans que leur code soit copié/collé dans chaque répertoire de projet. Pour cela, il peut regrouper ses modules dans des répertoires identifiés par l'environnement de programmation – c'est‑à‑dire ciblés par une variable de chemin – afin de ne pas avoir à spécifier dans les directives d'inclusion un chemin spécifique. Le codeur peut également :
- mettre en œuvre une compilation séparée des modules, c'est‑à‑dire indépendante de celle des programmes qui les utilisent, sur la base des mêmes principes qu'en programmation multi‑fichiers ;
- utiliser les fichiers d'en‑tête comme des fichiers d'interface pour d'autres codeurs, en ne leur fournissant pas les fichiers sources d'implémentation des modules, mais seulement les fichiers objets déjà compilés, et éventuellement regroupés en archive (bibliothèque statique) ou bibliothèque partagée (dynamique).
Comme pour la programmation multi‑fichiers (cf. chap. C4‑V ), la création de modules de bibliothèque présente aussi des aspects techniques qui sont spécifiques à la chaîne de compilation utilisée, à l'architecture de la machine cible, au système d'exploitation du poste de travail et à l'environnement de programmation. Même en se limitant à GCC, et même si le principe général est similaire, la procédure n'est pas du tout la même selon qu'on opère avec VS Code pour générer un programme s'exécutant sur le poste de travail ou avec Arduino IDE pour générer un programme une carte à microcontrôleur.
Mais surtout, au delà de la procédure technologique, il y a la dimension méthodologique dans la mesure où, en plus de la « logique d'objets » avec laquelle on procède pour coder un module, il faut d'imaginer une implémentation la plus générale possible, afin de maximiser les opportunités de réutilisation du module.
Il s'agit donc encore une fois d'un sujet complexe qu'il n'est pas possible de traiter ici en profondeur. L'objectif de ce chapitre est simplement de proposer une initiation à la programmation modulaire en adoptant une plan similaire à celui du chapitre précédent :
- On examine d'abord le cas général d'une bibliothèque de fonctions « utilisateur » (non standard) codées en langage C (les mêmes principes valent en C++), compilée avec GCC sous Linux. On traitera les deux sous‑cas, selon que la bibliothèque générée est dite statique ou dynamique.


Création de modules de bibliothèque C ou C++
Principe général
En règle générale, la décision de créer un nouveau module de bibliothèque est prise :
- que lorsque certaines fonctions opérant sur un même type de variables (ou une même classe d'objets) sont nécessaires dans plusieurs programmes ;
- et qu'il n'existe pas d'implémentation existante de ces fonctions dans la bibliothèque standard ou dans un module déjà développé par la communauté libre – donc, sans droits d'utilisation.
Il serait contre‑productif de coder un nouveau module pour implémenter les fonctions arithmétiques calculant le plus petit commun multiple et le plus grand commun diviseur de deux nombres entiers, car ces fonctions existent déjà dans le module nommée numeric de la bibliothèque standard du C++ C++ : ce sont les fonctions gcd (greatest common divisor et lcm (least common multiple).
En langages C et C++, le principe général d'organisation d'un module de bibliothèque reprend celui de la programmation multi‑fichiers (cf. chap. C4‑V ), avec une décomposition du code source typiquement en deux fichiers :
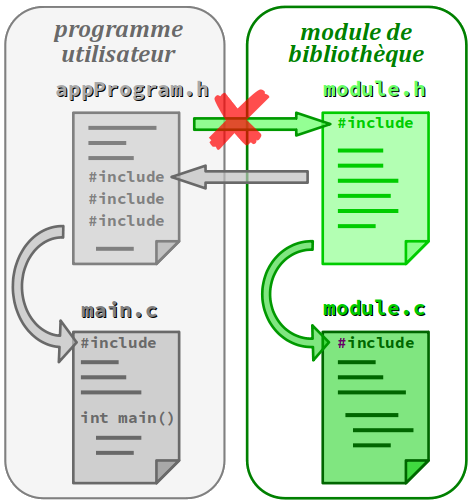
- un fichier d'en‑tête, usuellement d'extension
.hou.hpp, qui regroupe toute la partie déclarative publique du module – directives de définition (pseudo‑constantes et pseudo‑fonctions), déclarations de types (ou classes en C++), de constantes, prototypes de fonctions ; - un fichier d'implémentation, usuellement d'extension
.cou.cpp, qui comporte une directive d'inclusion du fichier d'en‑tête et qui définit toutes les fonctions qui y sont déclarées ; il peut aussi contenir des déclarations privées avec en particulier des variables statiques…
En revanche, ni le fichier d'en‑tête ni le fichier d'implémentation du module de bibliothèque ne doivent contenir aucune directive d'inclusion du fichier d'en‑tête principal du programme utilisateur ou de tout autre module spécifique au programme. Sinon le module ne serait pas indépendant de ce dernier, donc pas vraiment modulaire.
De plus, dans un module, parmi les fonctions définies ne figure jamais de fonction principale main.
Dans la pratique, il est tout à fait possible et même fréquent de concevoir des modules plus complexes, comportant plus de deux fichiers.
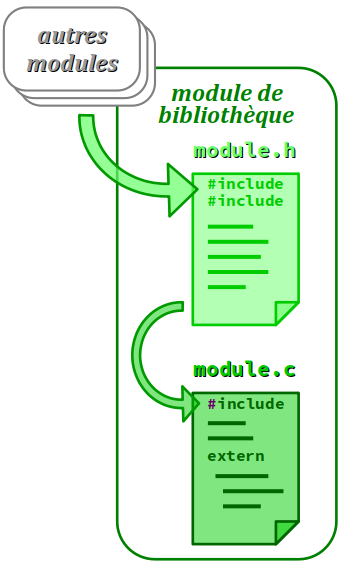
- Déjà, il n'est pas rare qu'un module utilise lui‑même d'autres modules de bibliothèque, par le biais d'autant de directives d'inclusion codées dans son fichier d'en‑tête (cf. la figure ci‑contre).
- Également, lorsqu'un module comporte de très nombreuses fonctions, dès lors que ces dernières peuvent être classifiées en plusieurs catégories, il est rationnel de répartir leur code de définition dans autant de fichiers d'implémentation.
- 2 fichiers d'en‑tête :
HardwareSerial.hetHardwareSerial_private.h; - 4 fichiers d'implémentation :
HardwareSerial.cppetHardwareSerial1.cppàHardwareSerial3.cpp.
Exemple. Le module Arduino Timezone de gestion automatique de l'heure d'été dans les différentes zones horaires (cf. chap. R2‑VI R) utilise le module Time qui implémente toutes les fonctions de base de la gestion du temps calendaire sur une carte à microcontrôleur.
Exemple. Le module Arduino HardwareSerial de gestion des liaisons séries sur une carte à microcontrôleur (cf. chap. C3‑X et le site de dépôt G) comporte :
Même s'ils sont issus du framework Arduino, les exemples proposés ci‑dessus sont représentatifs du cas général de la programmation modulaire en langages C/C++. Ils ont le mérite d'une relative simplicité, ce qui n'est pas le cas des modules de bibliothèque standard – sachant que pour ces derniers, on ne dispose même pas de leurs fichiers sources d'implémentation (seuls leurs fichiers objets sont fournis aux utilisateurs).
Techniques de création
Rappel. On a vu au chapitre C4‑V :
- comment répartir les fichiers dans des sous‑répertoires du répertoire de projet pour les ranger par types (fichiers d'en‑tête, d'implémentation, objets, etc.) ;
- comment compiler individuellement les fichiers source d'implémentation d'un programme en autant de fichiers objets, avec l'avantage ensuite de ne pas avoir à recompiler tout l'ensemble de ces fichiers à chaque modification ponctuelle du code (seul les fichiers sources modifiés doivent être recompilés) ;
- comment ces fichiers objets sont a priori réunis en un seul fichier exécutable par l'éditeur de liens.
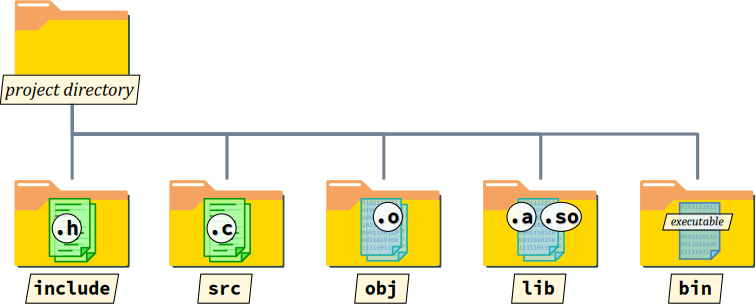
Le but de la création d'un module de bibliothèque est de réunir des fichiers objets qui ne forment pas à eux seuls un programme mais dont les fonctions ont vocation à être exploités dans divers programmes. Et on a vu au chapitre C4‑IV qu'il y a deux exploitations possibles d'une bibliothèque :
- par édition de liens statiques, c'est‑à‑dire en incorporant directement dans le fichier exécutable du programme le code objet de toutes les fonctions de bibliothèque utilisées ;
- par édition de liens dynamiques, c'est‑à‑dire en insérant dans le fichier exécutable du programme seulement des références qui seront résolues lors de l'exécution du programme ;
sachant que l'édition de liens dynamiques permet ensuite de générer ensuite des exécutables plus légers et qui peuvent bénéficier des mises à jours de la bibliothèque sans avoir à être recompilés eux‑mêmes, mais qui ne sont pas stand‑alone.
Avant d'entrer dans les détails, on peut déjà préciser que :
- l'édition de liens statiques requiert que le code objet à incorporer soit structuré dans ce qu'on appelle une bibliothèque statique ;
- l'édition de liens dynamiques requiert :
On emploie usuellement le terme de « bibliothèque » au sens de bibliothèque de fonctions. Mais au regard de l'immense développement logiciel, on parle aussi de module de bibliothèque, au sens où, par exemple, ce qu'on appelle la bibliothèque standard du langage est en réalité constituée d'un ensemble de modules.
Cas d'une bibliothèque statique
Réunir un ensemble de fichiers objets dans un répertoire distinct ne constitue pas une bibliothèque statique. Pour la créer, il faut utiliser un logiciel spécial qui, sous Linux, est l'archiveur ar W. Ce dernier effectue les traitements suivants :

- Il réunit par concaténation le code objet des fichiers
.opassés en argument dans un même fichier d'archive d'extension.a. - Il crée un index des symboles, c'est‑à‑dire une liste des fonctions et des données globales qui ont été compilées dans les fichiers
.o.
En phase de développement, il est d'usage de placer tous les fichiers d'archive d'un programme dans un sous‑répertoire lib, lui‑même placé dans le répertoire de projet.
Mais une fois que le code est stabilisé, il est préférable de déplacer les fichiers d'archive dans un répertoire commun du système de fichiers dont le chemin est spécifié dans la variable d'environnement PATH de l'utilisateur – sous Linux, typiquement :
/usr/local/lib
En phase de développement, et compte tenu de la structure du répertoire de projet proposée précédemment, la syntaxe d'invocation de la commande ar est de la forme :
ar rcs lib/fichier d'archiveobj/fichier objet 1obj/fichier objet 2…
où :
- les 3 options
rcsimposent respectivement : - le remplacement des fichiers si ces derniers sont déjà inclus dans l'archive (
rcommereplace) ; - la création du fichier d'archive si ce dernier n'existe pas encore (
ccommecreate) ; - la création de l'index des symboles ou sa mise à jour s'il existe déjà (
scommesymbols) ; - le nom du fichier d'archive doit impérativement être codé en première position ; usuellement, ce dernier est composé avec le préfixe
libet l'extension.a; - les fichiers objets à inclure dans l'archive portent usuellement l'extension
.o.
L'index des symboles généré par la commande ar avec l'option s est à ne pas confondre avec la table des symboles que comporte chacun des fichiers objets inclus dans le fichier d'archive.

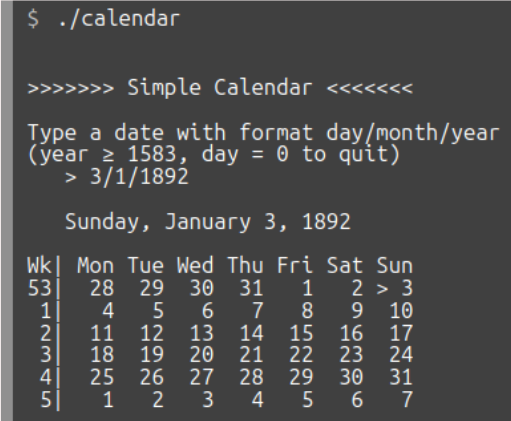
Reprenons l'exemple du programme calendar introduit au chapitre C4‑V pour illustrer un cas concret de répartition du code sur plusieurs fichiers (cf. la capture d'écran ci‑dessous).
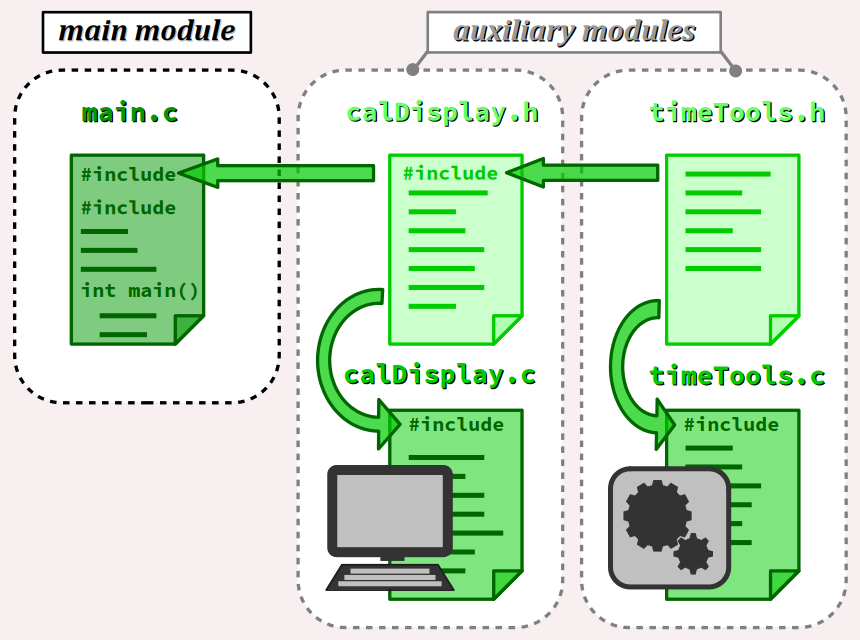
Pour mémoire, ce programme est réparti sur un fichier principal main.c et 2 modules auxiliaires, calDisplay et timeTools avec dépendance du deuxième par le premier (cf. la figure ci‑dessus). Lors de la génération de l'exécutable, on avait mis en œuvre dans le sous‑répertoire obj une sauvegarde des fichiers objets du programme principal et des deux modules auxiliaires.
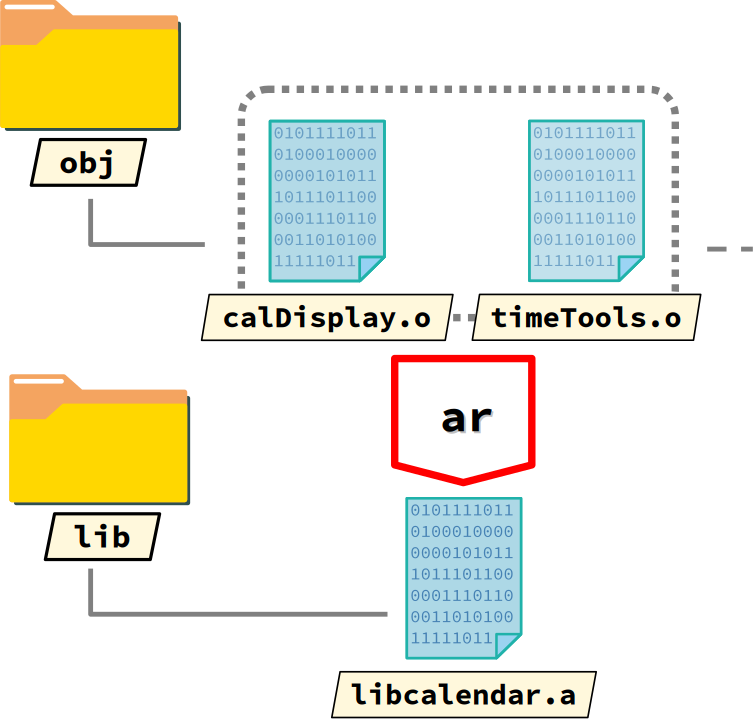
L'idée est donc de constituer, à l'aide de l'archiveur ar une bibliothèque statique à partir des fichiers objets de ces deux modules, pour pouvoir en réutiliser certaines fonctions dans d'autres programmes. C'est précisément ce qu'effectue la commande ci‑dessous en créant le fichier d'archive libcalendar.a dans le sous‑répertoire lib.
ar rcs lib/libcalendar.a obj/calDisplay.o obj/timeTools.o
À l'aide de la commande file, on peut vérifier que le fichier ainsi généré n'est pas au format ELF :
file lib/libcalendar.alibcalendar.a: current ar archive
De plus, l'aide de la commande ls :
ls -l lib-rw-rw-r-- 1 fg fg 11958 mars 10 11:49 libcalendar.a
on constate que ce fichier (environ 12,0 ko) est juste un peu plus volumineux (+0,6 ko) que les deux fichiers objets qui le composent (6,9 + 4,5 ko = 11,4 ko – cf. chap. C4‑V ). Cette différence correspond à la présence d'un index des symboles généré dans le fichier d'archive par la commande ar avec l'option s.
Et alors, on peut procéder à l'affichage de l'index des symboles grâce à la commande nm (name mangling) présentée au chapitre C4‑IV et invoquée ici avec l'option -s :
nm -s lib/libcalendar.aIndex de l'archive : printShortNameOfDay in calDisplay.o printFullNameOfDay in calDisplay.o printFullNameOfMonth in calDisplay.o printFullDate in calDisplay.o printDaysHeader in calDisplay.o printFullMonth in calDisplay.o MINIMAL_YEAR in timeTools.o EPOCH_0_YEAR in timeTools.o isLeapYear in timeTools.o nbOfDaysInMonth in timeTools.o nbOfDaysInYear in timeTools.o dayInYear in timeTools.o lastWeekInYear in timeTools.o dayOfWeek in timeTools.o weekInYear in timeTools.o previousWeek in timeTools.o nextWeek in timeTools.o nbOfDaysSinceEpoch0 in timeTools.o previousMonth in timeTools.o nextMonth in timeTools.o previousMonday in timeTools.o isDateOutOfRange in timeTools.o […]
Cas d'une bibliothèque dynamique
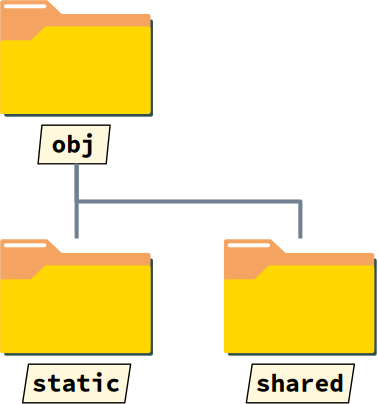
Avant de créer une bibliothèque dynamique au sein d'un répertoire de projet, il est nécessaire de réorganiser le sous‑répertoire obj, pour ne pas écraser les éventuels fichiers objets déjà compilés pour une utilisation normale (multi-fichiers) ou une bibliothèque statique. La solution usuellement retenue consiste à :
- créer deux sous‑répertoires nommés respectivement
staticetshared(cf. la figure ci‑contre) ; - placer dans
staticles fichiers objets compilés sans option particulière, et destinés à être archivés dans une bibliothèque statique ; - placer dans
sharedles fichiers objets issus d'une compilation avec l'option PIC, et destinés à être intégrés dans une bibliothèque dynamique.
Les autres fichiers objets spécifiques au projet – typiquement le fichier principal main.o – sont usuellement rangés directement dans le sous‑répertoire obj.
La création d'une bibliothèque dynamique requiert :
- la compilation des fichiers sources d'implémentation (
.c) des modules de la bibliothèque avec l'option PIC (position independent code W) pour créer autant de fichiers de code objet chargeable en mémoire partagée ; - l'édition de liens dynamiques de ces fichiers objets avec une option spécifique pour former le fichier de bibliothèque partagée.
La compilation doit être accomplie pour chaque fichier d'implémentation des modules de la bibliothèque, typiquement par une commande de la forme :
gcc -Iinclude -fPIC -c src/nom fichier.c-o obj/shared/nom fichier.o
compte tenu de l'organisation du répertoire de projet proposée précédemment. À options équivalentes, elle produit des fichiers objets de même taille que ceux produits par compilation usuelle.
On peut alors procéder à l'édition de liens dynamiques pour former le fichier de bibliothèque partagée, avec une commande de la forme :
gcc -shared obj/shared/fichier objet 1obj/shared/fichier objet 2…-o lib/fichier de bibliothèque partagée
sachant que ce fichier :
- doit être composé avec le préfixe
libet l'extension.so(pour shared object – cf. chap. C4‑IV ) ; - doit porter un nom de base différent que celui d'un éventuel fichier d'archive formant une bibliothèque statique à partir des mêmes éléments de code, tout simplement pour ne pas être confondu avec ce dernier.
Remarque. Si tous les fichiers objets contenus dans le répertoire obj/shared sont à inclure, la commande d'édition de liens dynamiques ci‑dessus peut se coder plus simplement comme ci‑dessous, avec l'emploi du méta‑caractère * :
gcc -shared obj/shared/* -o lib/fichier de bibliothèque partagée
Comparativement à un fichier d'archive de bibliothèque statique produit à partir des mêmes modules, un fichier de bibliothèque partagé est toujours un peu plus volumineux. En plus du code objet des modules, il comporte aussi des métadonnées de dépendances, de liaisons dynamiques et de relocalisation, notamment les tables GOT (global offset table W) et PLT (procedure linkage table ).
Poursuivons l'exemple du programme calendar proposé supra pour illustrer un cas concret génération d'une bibliothèque statique.
Commençons par la compilation des deux fichiers d'implémentation des modules de la bibliothèque avec l'option PIC :
gcc -Iinclude -fPIC -c src/calDisplay.c -o obj/shared/calDisplay.ogcc -Iinclude -fPIC -c src/timeTools.c -o obj/shared/timeTools.o
À l'aide de la commande cmp (pour compare W), on peut vérifier que les fichiers objets ainsi produits ne présentent ici aucune différence avec ceux produits par compilation usuelle :
cmp obj/shared/calDisplay.o obj/static/calDisplay.oecho $?0
En effet, les fichiers sources des modules sont de petite taille, ne comportent pas de variables globales et sont compilés sur une architecture récente (x86-64). Mais ce n'est pas toujours le cas (cf. la remarque infra ).
Procédons maintenant à l'édition de liens dynamiques pour générer le fichier de bibliothèque partagée à partir des fichiers objets, en lui attribuant un nom de base différent de libcalendar (déjà choisi pour le fichier d'archive de bibliothèque statique – cf. supra ) :
gcc -shared obj/shared/* -o lib/libcalutils.so
On peut aisément vérifier avec la commande file qu'on a ainsi bien produit un fichier de bibliothèque partagée :
file lib/libcalutils.solibcalutils.so: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, BuildID[sha1]=7fa70b735ff7027d2a705f7ce87df88df9ee0e02, not stripped
Comme on peut le constater en listant le répertoire lib :
ls -l lib-rw-rw-r-- 1 fg fg 11958 mars 10 11:49 libcalendar.a -rwxrwxr-x 1 fg fg 16640 mars 10 14:42 libcalutils.so
le fichier de bibliothèque partagée est un peu plus gros que le fichier d'archive. On peut s'en faire une image plus précise en affichant la liste des symboles qu'il contient, grâce à la commande nm (name mangling – cf. chap. C4‑IV ) suivante, combinée à un tri opéré sur la 2 e colonne (commande sort W) :
nm -s lib/libcalutils.so | sort -k2,200000000000040a8 b completed.0 w __cxa_finalize@GLIBC_2.2.5 0000000000003df8 d __frame_dummy_init_array_entry 0000000000003e00 d __do_global_dtors_aux_fini_array_entry 0000000000003e08 d _DYNAMIC 0000000000003fe8 d _GLOBAL_OFFSET_TABLE_ 00000000000040a0 d __dso_handle 00000000000040a8 d __TMC_END__ w __gmon_start__ w _ITM_deregisterTMCloneTable w _ITM_registerTMCloneTable U printf@GLIBC_2.2.5 U putchar@GLIBC_2.2.5 U puts@GLIBC_2.2.5 0000000000002158 r __GNU_EH_FRAME_HDR 0000000000002510 r __FRAME_END__ 0000000000002150 R MINIMAL_YEAR 0000000000002154 R EPOCH_0_YEAR 0000000000001000 t _init 00000000000012c0 t deregister_tm_clones 00000000000012f0 t register_tm_clones 0000000000001330 t __do_global_dtors_aux 0000000000001370 t frame_dummy 0000000000001df8 t _fini 0000000000001379 T printShortNameOfDay 0000000000001455 T printFullNameOfDay 0000000000001531 T printFullNameOfMonth 000000000000168a T printFullDate 00000000000016fd T printDaysHeader 0000000000001748 T printFullMonth 00000000000018ee T isLeapYear 0000000000001963 T nbOfDaysInMonth 00000000000019f3 T nbOfDaysInYear 0000000000001a1e T dayInYear 0000000000001a6b T lastWeekInYear 0000000000001ac8 T weekInYear 0000000000001b74 T previousWeek 0000000000001ba3 T nextWeek 0000000000001bd3 T nbOfDaysSinceEpoch0 0000000000001c72 T dayOfWeek 0000000000001d0c T previousMonth 0000000000001d2c T nextMonth 0000000000001d4c T previousMonday 0000000000001da2 T isDateOutOfRange
On y trouve notamment le repère de la GOT (global offset table – cf. supra ) à l'adresse 3fe8. Et pour visualiser l'existence de la PET, on peut utiliser la commande objdump suivante (cf. chap. C4‑IV ) :
objdump -d lib/libcalutils.so | grep '\.plt'Déassemblage de la section .plt : 0000000000001020 <.plt>:
Pour observer un effet de l'option PIC (position independent code) sur la compilation d'un fichier d'implémentation, il suffit de considérer un exemple qui comporte une variable globale, comme dans le code académique ci‑dessous.
int counter = 0;
int inc(void) {
counter++;
return counter;
}
Procédons à sa compilation d'abord sans puis avec l'option PIC, et comparons la taille des fichiers objets produits :
gcc -c inc.c # default output file is inc.ogcc -c -fPIC inc.c -o incPIC.ols -l *.o-rw-rw-r-- 1 fg fg 1416 mars 10 15:01 inc.o -rw-rw-r-- 1 fg fg 1472 mars 10 15:01 incPIC.o
On voit déjà que le fichier incPIC.o est un peu plus gros que inc.o. Et en listant leurs symboles :
nm -s inc.o0000000000000000 B counter 0000000000000000 T incnm -s incPIC.o0000000000000000 B counter U _GLOBAL_OFFSET_TABLE_ 0000000000000000 T inc
on peut voir que incPIC.o comporte une GOT (global offset table), contrairement à inc.o.
Exploitation d'un module de bibliothèque
Pour exploiter un module de bibliothèque dans un programme, ajouter au code source une directive d'inclusion comme on le ferait pour un module de la bibliothèque standard ne suffit pas, même en spécifiant le chemin relatif du répertoire du module à partir du répertoire du programme. En effet, si l'on se contente de générer le fichier exécutable par une commande gcc usuelle, typiquement :
gcc -Iinclude src/main.c -o bin/fichier exécutable
alors la chaîne de compilation ne s'achève pas comme souhaité :
- certes, la compilation elle‑même se déroule correctement ;
- en revanche, l'édition de lien échoue – on obtient un message d'erreur de l'éditeur de liens
ldcar ce dernier ne sait pas où trouver le code objet du module, qui se termine typiquement par :
collect2: error: ld returned 1 exit status
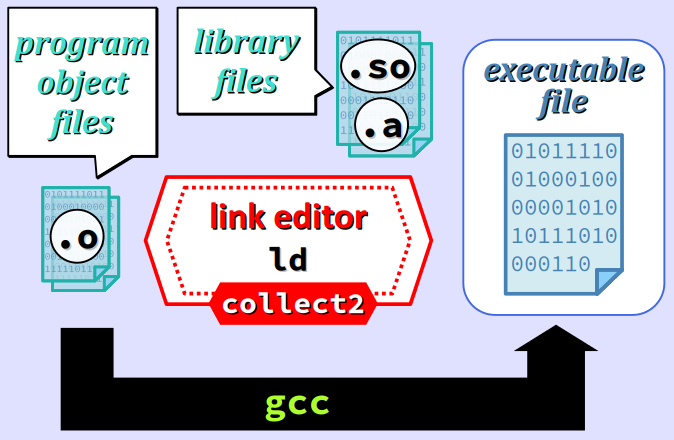
Lors de la génération du fichier exécutable d'une programme qui fait appel à des fonctions d'un module de bibliothèque non standard, il est impératif d'indiquer à l'éditeur de liens le nom et l'emplacement du fichier de bibliothèque, par des options spécifiques.
De plus, il est vivement conseillé d'utiliser le driver gcc et non pas directement l'éditeur de liens ld, même si l'on opère à partir de fichiers objets.
Au chapitre C4‑IV , on a listé les options de la commande gcc relatives à l'édition de liens. Avant de voir leurs applications concrètes le cadre d'un exemple de programmation modulaire, on peut déjà cerner les cas généraux suivants pour les options les plus techniques.
- On codera
-Llibsi on a placé dans le répertoire de projet un sous‑répertoire localliboù l'on souhaite placer les fichiers de bibliothèque. - On codera
-lexamplepour cibler un fichier bibliothèque dont le nom de base estlibexample(avec le préfixe «lib»), quelle que soit son extension – donc, idem pour une bibliothèque statique ou dynamique. - On codera
-Wl,-rpath=libpour indiquer, en vue du futur chargement du programme en mémoire, l'emplacement d'un fichier de bibliothèque partagée rangé dans le sous‑répertoire locallib.
Appliquons ces connaissances à la génération du code exécutable du programme calendar pour lequel on a construit successivement une bibliothèque statique libcalendar (cf. supra ) et une bibliothèque dynamique libcalutils (cf. supra ).
On rappelle qu'on a adopté une structuration classique du répertoire de projet en 5 sous‑répertoires include src obj lib bin (cf. supra ), sachant que obj est lui‑même structuré en deux sous‑répertoires static et shared (cf. supra ).
Pour générer un exécutable – qu'on nomme ici static-calendar – parce qu'il incorpore la bibliothèque statique libcalendar, on effectue une édition de liens statiques du fichier objet principal main.o avec le fichier d'archive libcalendar.a, via la commande suivante :
gcc obj/main.o -o bin/static-calendar -Llib -lcalendar
Si l'on souhaite au passage effectuer la compilation du fichier source principal main.c, il suffit simplement d'adapter la commande comme ci‑dessous en gardant les mêmes options pour l'édition de liens :
gcc -Iinclude src/main.c -o bin/static-calendar -Llib -lcalendar
On obtient un exécutable qui n'est pas complètement stand‑alone car l'édition de liens statiques ne concerne que la bibliothèque libcalendar, mais pas la bibliothèque standard (sinon, il aurait fallu employer l'option -static – cf. chap. C4‑IV ). On le vérifie aisément à l'aide de la commande file (cf. chap. S1‑III ) :
file bin/static-calendarbin/static-calendar: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=e1fc5127fdfbab8cdd3fd73c9e711c6cac723da1, for GNU/Linux 3.2.0, not stripped
On peut également expliciter sa dépendance à la bibliothèque standard (libc) à l'aide de la commande readelf -d (cf. chap. C4‑IV ) filtrée avec le drapeau NEEDED :
readelf -d bin/static-calendar | grep NEEDED0x0000000000000001 (NEEDED) Bibliothèque partagée : [libc.so.6]
Par ailleurs, l'exécutable a exactement la même taille que celle de l'exécutable calendar généré par une simple compilation multi‑fichiers (cf. chap. C4‑V ), comme on peut le constater ci‑dessous :
ls -l bin-rwxrwxr-x 1 fg fg 17056 mars 8 23:23 calendar -rwxrwxr-x 1 fg fg 17056 mars 11 12:14 static-calendar
Ce n'est pas surprenant dans la mesure où il incorpore le même code objet.
Pour générer un exécutable – qu'on nomme ici shared-calendar – parce qu'il exploite la bibliothèque partagée libcalutils, on effectue une édition de liens dynamiques du fichier objet principal main.o avec le fichier de bibliothèque partagée libcalutils.so, via la commande suivante :
gcc obj/main.o -o bin/shared-calendar -Llib -lcalutils -Wl,-rpath=lib
Comme avec une bibliothèque statique, on peut aussi partir du fichier source principal main.c :
gcc -Iinclude src/main.c -o bin/shared-calendar -Llib -lcalutils -Wl,-rpath=lib
On obtient alors un exécutable qui a deux dépendances de bibliothèques partagées (libcalutils.so et libc.so), comme on peut le constater avec la même commande readelf -d que supra :
readelf -d bin/shared-calendar | grep NEEDED0x0000000000000001 (NEEDED) Bibliothèque partagée : [libcalutils.so] 0x0000000000000001 (NEEDED) Bibliothèque partagée : [libc.so.6]
Par ailleurs, et de façon surprenante, l'exécutable a une taille à peine plus faible que celle de l'exécutable static‑calendar :
ls -lS bin/s*-rwxrwxr-x 1 fg fg 17056 mars 11 12:14 static-calendar -rwxrwxr-x 1 fg fg 16288 mars 11 12:45 shared-calendar
alors qu'il incorpore très peu de code objet (seulement celui de la fonction main et des utilitaire de la bibliothèque crt0). On peut s'en apercevoir à l'aide de la commande size (cf. chap. C4-IV ) :
size -G bin/s*text data bss total filename 753 2267 8 3028 bin/shared-calendar 3045 3212 8 6625 bin/static-calendar
Et c'est évidemment dans le segment text que l'exécutable shared-calendar est beaucoup plus léger, puisque presque tout le code des fonctions du programme est externalisé dans les modules de la bibliothèque partagée libcalutils.so.
Création d'un module de bibliothèque Arduino
Rappels sur les spécificités de l'IDE Arduino
Rappelons que par défaut, avec l'IDE Arduino, les fichiers objets et le fichier exécutable générés par la chaîne de compilation sont stockés dans un répertoire temporaire, donc non pérenne (cf. chap. C4‑V ).
Ainsi, on ne met pas en œuvre une compilation séparée comme avec un environnement de programmation généraliste.
On peut trouver des explications rationnelles à ce choix des concepteurs d'Arduino.
- Les programmes pour microcontrôleurs étant forcément « petits » (en comparaison de ceux que l'on peut exécuter sur un ordinateur), on ne peut espérer qu'un faible gain de temps en ne recompilant pas certaines parties du code . En ces termes, la compilation séparée systématique ne se justifie pas.
- Tout l'univers Arduino (tant les aspects matériels que logiciels) repose sur une philosophie open‑source ; en toute logique, l'IDE impose aux développeurs la publicité des fichiers sources s'ils veulent partager un programme ou un module. Obtenir le code objet d'un module pour pouvoir garder privé le code source n'est donc pas un objectif.
Toutefois, même si l'on ne peut donc pas compiler seul un module de bibliothèque, cela ne diminue en rien l'intérêt de la programmation modulaire en termes d'organisation du code en composants logiciels réutilisables.
Méthodes d'ajout d'un module de bibliothèque à l'IDE Arduino
Dans l'IDE Arduino, il existe plusieurs moyens pour ajouter un nouveau module bibliothèque A. Tout dépend de la provenance du module.
S'il s'agit d'un module déjà répertorié par la communauté des développeurs Arduino, en particulier s'il est distribué par un fournisseur de composants (Adafruit, Seeed, Grove, etc.), l'idéal est d'employer le gestionnaire de bibliothèques intégré dans l'IDE Arduino.
Les modules les plus usuels (SD, Servo, etc.) sont déjà inclus dans un répertoire principal de bibliothèques du dossier d'installation de l'IDE – typiquement sur un PC Windows :
C:\Program Files (x86)\Arduino\libraries
et sur machine Linux :
/opt/arduino-version/libraries
Si un module n'est pas encore inclus, la manière la plus usuelle de le faire consiste à passer la commande Gérer les bibliothèques dans le menu Outils. Cette commande ouvre une fenêtre qui liste dans l'ordre alphabétique l'ensemble des modules répertoriés par l'IDE.
Les modules très nombreux, il est recommandé d'utiliser la barre de recherche.
Par ailleurs, il faut savoir que certains modules sont répartis dans les répertoires spécifiques aux différents microcontrôleurs cibles de la compilation, qui sont compatibles avec l'IDE Arduino.
S'il s'agit d'un module non répertorié dont on dispose des fichiers sources (de conception personnelle ou fourni par un tiers), il faut commencer par les enregistrer dans répertoire homonyme. Ensuite, deux solutions sont possibles, aboutissant au même résultat :
- soit compresser le répertoire du module au format
zipet lancer la commande :
Ajouter la bibliothèque .ZIP…
du menuCroquis/Inclure une bibliothèque…; - soit copier directement le répertoire du module dans un répertoire « utilisateur » pour les bibliothèques, qui est par défaut inclus dans le répertoire général des programmes (« croquis ») de l'utilisateur de l'IDE Arduino, typiquement pour un PC Windows :
C:\Users\User\Documents\Arduino\librairies
et sur machine Linux :
/home/user‑name/Arduino/libraries
sachant que le chemin de ce répertoire étant modifiable dans la fenêtre Préférences à laquelle on accède via le menu Fichiers.
Attention. Il est déconseillé d'installer directement des modules dans le répertoire principal des bibliothèques, car ce dernier est entièrement effacé et réécrit lors d'une mise à jour de l'IDE Arduino. On risque donc de perdre tous les modules non standards.
Dans tous les cas, on peut ensuite vérifier que le module est bien inclus dans la liste des bibliothèques identifiées de l'IDE Arduino. Cette liste s'affiche affiche dans le sous‑menu :
Croquis/inclure une bibliothèque
On peut alors utiliser ce module via une directive #include en utilisant la syntaxe entre les chevrons < > pour spécifier le chemin d'accès au module.
Par ailleurs, il faut savoir qu'au cours d'une compilation modulaire, l'IDE Arduino recherche tout module de bibliothèque dans les divers répertoires mentionnés supra et sélectionne le premier trouvé, par ordre de priorité :
- d'abord dans le répertoire des bibliothèques « utilisateur »,
- ensuite dans les répertoires spécifiques aux microcontrôleurs cibles de la compilation,
- enfin dans le répertoire principal de bibliothèques de l'IDE Arduino
Fichiers complémentaires
Lorsqu'on souhaite diffuser un module de bibliothèque personnel au sein de la communauté Arduino, alors en plus des fichiers sources .h et .cpp, il est recommandé d'ajouter dans le répertoire du module des fichiers complémentaires pour faciliter la prise en main et l'utilisation du module par autrui :
- un fichier d'aide – typiquement nommé
readme.txt; - un fichier de coloration syntaxique – impérativement nommé
keywords.txt; - des fichiers sources
.inode programmes simples d'exemples d'application, chacun placé dans un répertoire homonyme – tous ces répertoires étant à regrouper dans un répertoireexamples.
Un exemple complet d'illustration est donné infra .
Fichier d'aide
Rappelons que les commentaires ajoutés au code pour le rendre facilement compréhensible doivent rester succins, afin de ne pas gêner sa lecture (cf. chap. C2‑X ).
Pour fournir des explications détaillées sur le module, en particulier sur les principes d'utilisation des fonctions, il est d'usage d'ajouter un fichier d'aide au format texte (simple, non mis en forme) qu'on nomme usuellement readme.txt.
En principe, ce fichier n'a pas de limites de taille. S'il est volumineux, il est évidemment recommandé de le structurer en plusieurs parties avec des titres hiérarchisés mis en forme « à la main » pour faciliter sa lecture.
Fichier de coloration syntaxique
Ajouté dans le répertoire de module, un fichier nommé keywords.txt permet de spécifie la coloration syntaxique à appliquer dans la fenêtre d'édition de code de l'IDE Arduino pour des identificateurs sélectionnés parmi ceux introduits par le codeur dans les fichiers sources.
Ce fichier doit être présenté sous la forme d'une suite de lignes commençant chacune par un identificateur du module suivi un caractère de tabulation horizontale puis :
-
KEYWORD1pour être affiché enorange(couleur appliquée pour les types par l'IDE) ; -
KEYWORD2pour être affiché enmarron(couleur appliquée pour les fonctions par l'IDE).
Exemples d'application
Pour bien expliquer l'usage d'un module de bibliothèque, rien ne vaut un bon exemple. Il suffit donc de coder un voire plusieurs programmes d'application directe du module et placer leur code source (fichiers .ino) dans un répertoire homonyme, lui‑même placé dans un répertoire nommé examples inclus dans le répertoire du module.
Dans l'IDE Arduino, une fois le module installé, ces fichiers seront directement accessibles via le menu Fichiers/Exemples, à condition d'avoir .
Exemple de module personnel Arduino
Reprenons l'exemple du programme multiSpeedBlink développé au chapitre C4‑V .
Il comprend un module de détection des fronts montants d'un signal sur une broche du port numérique de carte Arduino.
Ce module peut être conçu pour devenir un module de bibliothèque. En effet :
- il ne dépend pas des autres modules du programme ;
- il comprend une fonction
risingEdgeayant un usage très fréquent.
Dans une perspective de réutilisation la plus large possible, on peut l'enrichir avec :
- une fonction
fallingEdgede détection des fronts descendants, - une fonction
edgede détection de fronts (indifféremment montants ou descendants), - deux fonctions
isLowetisHighde détection de niveaux logiques (respectivement bas et haut).
Dans ce module, on dispose alors de toutes les fonctions utiles pour gérer des signaux logiques sur le port numérique d'une carte Arduino.
Le répertoire de module compressé au format ZIP peut être téléchargé au lien suivant .
Fichier d'en‑tête LogicalSignals.h
#include <Arduino.h>
// Main type to be uses
struct LogicalSignal {
uint8_t pin; // pin number to be declared as INPUT our INPUT_PULLUP
byte levels; // current level on bit rank 0, previous level on bit rank 1
};
// All function prototypes
void updateSignal(LogicalSignal & signal); // to be called once in loop function
bool isLow (LogicalSignal signal);
bool isHigh (LogicalSignal signal);
bool risingEdge (LogicalSignal signal);
bool fallingEdge (LogicalSignal signal);
bool edge (LogicalSignal signal);
Fichier d'implémentation LogicalSignals.cpp
#include "LogicalSignals.h"
void updateSignal(LogicalSignal & signal) {
signal.levels <<= 1; // record previous level on bit rank 1
// copy current level on bit rank 0 and clear all bits ranging over rank 1
signal.levels = ((digitalRead(signal.pin) | signal.levels) & 0b11);
}
bool isLow (LogicalSignal signal) {
return ((signal.levels & 0b01) == 0);
}
bool isHigh (LogicalSignal signal) {
return ((signal.levels & 0b01) == 1);
}
bool risingEdge (LogicalSignal signal) {
return (signal.levels == 0b01);
}
bool fallingEdge (LogicalSignal signal) {
return (signal.levels == 0b10);
}
bool edge (LogicalSignal signal) {
return (signal.levels == 0b01 || signal.levels == 0b10);
}
Exemple d'application ledButtonSimpleCommand.ino
#include <LogicalSignals.h>
#define LED_PIN 2
#define BUTTON_PIN 4
LogicalSignal button = {BUTTON_PIN, 0b00}; // LOW level expected initially
void setup() {
pinMode(LED_PIN, OUTPUT);
digitalWrite(LED_PIN, LOW);
pinMode(BUTTON_PIN, INPUT); // positive logic
}
void loop() {
updateSignal(button);
if (risingEdge(button)) {
digitalWrite(LED_PIN, !digitalRead(LED_PIN));
}
}
Fichier de coloration syntaxique keywords.txt
LogicalSignal KEYWORD1 updateSignal KEYWORD2 isLow KEYWORD2 isHigh KEYWORD2 risingEdge KEYWORD2 fallingEdge KEYWORD2 edge KEYWORD2
Fichier d'aide readme.txt
Arduino library module "LogicalSignals"
Designed to manage logical signals on the digital port of Arduino boards
- detect both logical levels (HIGH or LOW)
- detect all kind of edges (rising, falling or both)
To detect something happening on a digital pin, you need to:
- declare a structured variable of type LogicalSignal,
(specifiing the pin number and the initial level expected on the pin)
example: LogicalSignal button = {BUTTON_PIN, 0b00}; // LOW initial level expected
- to call the update function at each iteration of loop function
example: updateSignal(button);
- to call a detection function whenever needed
example: if (risingEdge(button)) // etc.