
Toute machine informatique dispose d'une horloge interne pour cadencer son processeur. Le le plus souvent, cette horloge est basée sur un oscillateur électronique à quartz externe W (cf. celui d'une carte Arduino en photo ci‑contre). Ce dispositif génère un signal périodique d'horloge W de (très) haute fréquence – au moins 1 MHz, mais le plus souvent de l'ordre du GHz. Il définit ce qu'on appelle le temps processeur (cf. chap. C2‑IX ).
En comptant le nombre d'impulsions du signal d'horloge depuis un instant initial, on peut en déduire la durée écoulée, et donc, moyennant quelques calculs, implémenter un temps calendaire, c'est‑à‑dire une horloge qui indique la date et heure courante conformément à la localisation du système, c'est‑à‑dire sa position dans le système des zones horaires du monde (cf. la capture d'écran ci‑contre sur un PC Windows).
Néanmoins, tout oscillateur électronique comporte des imperfections qui lui sont propres. Au fil du temps, même un écart minime sur la fréquence d'oscillation par rapport à la valeur théorique finit par engendrer une dérive significative du système d'horodatage de la machine, avec des conséquences non négligeables.
- Dans le cas d'un poste de travail, tout l'étiquetage des fichiers et des processus (cf. la capture d'écran ci‑contre) risque d'être faussé par rapport à la réalité.
- Dans un réseau informatique, certains services – notamment la messagerie électronique, les requêtes sur bases de données – requièrent une bonne synchronisation entre les machines, qui peut être compromise par un écart entre les horloges respectives des serveurs.
- Dans un système de production qui met en œuvre un processus d'horodatage des produits, si ce dernier n'est pas exact, cela risque de poser des problèmes ultérieurs de traçabilité.

On comprend donc la nécessité de synchroniser régulièrement les horloges des machines avec une référence de temps commune.

Mais définir une référence de temps commune n'est pas simple. Cette problématique ancienne, qu'on a cru pouvoir résoudre avec les observations astronomiques, s'est complexifiée avec l'amélioration des techniques de mesure du temps. Aujourd'hui, on distingue principalement deux échelles de temps.
- D'une part, on a le temps universel W (universal time, abrégé UT) qui est basé sur les notions de jour solaire moyen et d'année tropique. L'inconvénient de cette unité est qu'elle a une durée variable (certes, très faiblement, mais néanmoins gênante lorsqu'il s'agit de chronométrer des phénomènes). En revanche, elle offre à l'échelle d'une année une synchronisation avec l'alternance des jours et des saisons que l'on constate sur Terre, donc en phase avec les activités humaines.
- D'autre part, on a le temps atomique international W (international atomic time, abrégé TAI) qui est exclusivement basée sur la définition atomique de la seconde comme unité fondamentale du temps propre terrestre (car sa valeur est très proche d'une fraction remarquable du jour solaire moyen). Aux incertitudes techniques près, la durée d'une seconde atomique est extrêmement stable.

Si le temps atomique international est privilégié pour les expériences scientifiques, il n'est en revanche pas retenu comme référence pour le temps civil – et donc dans les systèmes informatiques – car il présente une dérive par rapport au temps universel, certes très faible (de l'ordre d'une minute par siècle) mais techniquement insatisfaisante : il est difficile d'accepter que les saisons se décalent peu à peu dans le calendrier.

Depuis la fin des années 1960, c'est un concept intermédiaire appelé temps universel coordonné W (en anglais, coordinated universal time), abrégé officiellement UTC, qui est adopté, pour offrir un bon compromis entre les deux échelles de temps présentées supra.
L'adoption de l'UTC comme référence de temps mondiale n'a de sens que si elle peut être facilement partagée entre les machines. Sur l'Internet ont donc été développés des protocoles de communication spécifiques : d'abord TP W (time protocol) puis NTP W – pour network time protocol – dont la version 4 (juin 2010) est la plus récente aujourd'hui. C'est sur ce protocole que reposent la plupart des services de temps sur les réseaux.
Comme presque tous les protocoles applicatifs, NTP est conçu sur un modèle client‑serveur et une architecture spécifique. Pour un technicien réseau, il est nécessaire d'en connaître les bases, auquel le présent chapitre est justement consacré, avec les objectifs listés ci‑dessous
- Tout d'abord, on décrit la problématique générale de la définition du temps, en rappelant :
- d'une part, la définition de la seconde atomique qui constitue l'étalon de durée ;
- d'autre part, les notions de jour solaire et d'année tropique.
- la notion de temps universel et ses concepts sous‑jacents de fuseau horaires et d'heure d'été.
- la notion de temps universel coordonné avec la notion sous‑jacente de seconde intercalaire ;
- Dans un deuxième temps, on aborde les représentations du temps calendaire dans les systèmes informatiques, en introduisant la notion de timestamp.
- Ensuite, on décrit le système de partage du temps universel coordonné, en détaillant l'architecture réseau pour les serveurs de temps et le protocole NTP.
- Enfin, on aborde les différentes techniques de manipulation des paramètres calendaires dans une machine informatique.
Pour une étude plus approfondie, on pourra consulter les pages web rédigées à titre pédagogique par l'Université du Delaware. Ce n'est pas un hasard car cette université compte parmi ses effectifs David L. Mills W, professeur émérite et principal concepteur du protocole NTP.
Problématique générale de la définition du temps

La définition d'une échelle de temps constitue une problématique très ancienne pour les sociétés humaines (cf. la photo d'un vestige de cadran solaire égyptien, vieux d'environ 3300 ans). La problématique a beaucoup évoluée au gré des besoins en précision requis par les activités sociales et des progrès accomplis, à la fois dans les techniques de mesure des durées et la compréhension des phénomènes astronomiques.
Aujourd'hui, l'unité de temps – la seconde – est celle qui est la mieux maîtrisée de toutes les unités du système international. Et les phénomènes astronomiques qui gouvernent le temps terrestre sont bien compris.
Néanmoins, cinquante ans après son adoption, l'échelle du temps universel coordonné fait encore l'objet de controverses – certains scientifiques préférant qu'on privilégie le temps atomique international.
La seconde atomique : un étalon de durée
On rappelle que la seconde W (symbole s) est l'unité de temps du Système international d'unités (SI). Elle y a été introduite en 1889 lors de la 1re Conférence générale des poids et mesures W.

En 1967, par la résolution nº 1 de la 13e Conférence générale des poids et mesures , la seconde a été définie comme la durée de 9 192 631 770 périodes de la radiation correspondant à la transition entre les deux niveaux hyperfins de l'état fondamental de l'atome de césium 133.
Depuis 1967, aucun changement majeur n'a été apporté à cette définition atomique de la seconde. Seules des précisions sur l'état de l'atome de césium 133 (non perturbé, à 0 K) ont été apportées pour mieux spécifier les conditions de mesure de sa période de radioactivité.
La seconde constitue aujourd'hui une unité de mesure réputée fixe à 10−14 près.
La durée d'une seconde ainsi définie par le nombre de périodes de radioactivité de l'atome de césium a été choisie pour coïncider au mieux avec ses anciennes définitions :
- d'abord un 86 400e du jour solaire terrestre moyen (unité de l'échelle du temps universel W adoptée jusqu'en 1956) ;
- puis un 31 556 925,974 7e de l’année tropique 1900 (unité de l'échelle du temps des éphémérides W adoptée de 1960 à 1967).
Les notions de jour solaire et d'année tropique sont détaillées infra.
Les horloges atomiques – le temps atomique

Une horloge atomique W est une machine qui délivre un signal périodique de fréquence connue et très stable basée sur des phénomènes atomiques.
Dans le cas de technologie dite à jet de césium (cf. l'équipement en photo ci‑contre à titre d'exemple), cette fréquence est de 9 192 631 770 Hz – en rappelant que 1 Hz = 1 s−1. Des dispositifs électroniques appelés diviseurs de fréquences permettent notamment d'en extraire un signal périodique de période 1 seconde très précisément.
Les horloges atomiques sont notamment utilisées pour :
- définir la seconde atomique et ainsi compter l'écoulement du temps atomique international ;
- par la même occasion, fournir la base du temps universel coordonné ;
- implémenter un service de temps embarqué dans les satellites des systèmes de localisation (GPS, Glonass, Galileo…) et plus généralement dans tous les systèmes qui requièrent une échelle de temps extrêmement précise, ne devant pas être entachée par des délais de transmission.
Le temps atomique international W abrégé TAI est une échelle de temps purement périodique, aux défauts techniques impondérables près.
Elle est établie par le bureau international des poids et mesures W (BIPM) qui publie régulièrement un tableau correctif rétrospectif des valeurs fournies par les compteurs incrémentaux.
Ces corrections sont calculées par moyennes pondérées de l'échelle de temps générées par plus de 500 horloges atomiques réparties dans le monde.
Le jour solaire : un phénomène de durée variable
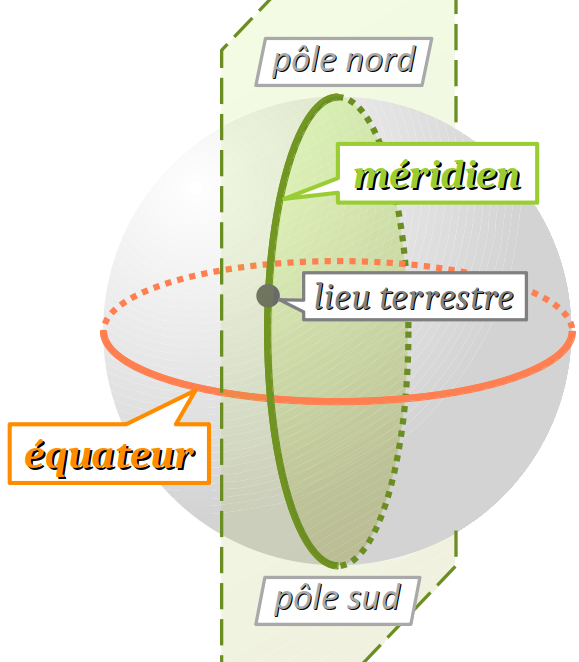
On peut définir intuitivement le jour solaire W comme la durée supposée périodique entre deux passages consécutifs du Soleil dans le plan méridien W d'un même lieu terrestre, principalement (mais pas seulement…) du fait de la rotation de la terre sur elle‑même.
Avec des moyens de mesure rudimentaires (une horloge du commerce), on peut constater sans difficulté que cette durée n'a pas de valeur constante tout au long de l'année.
Les variations du jour solaire sont principalement causées par des facteurs astronomiques qui s'accentuent ou se compensent mutuellement au cours d'un cycle annuel. L'amplitude de ces variations autour d'une valeur moyenne s'inscrit dans un intervalle d'environ −21 à +30 s.
Si l'on établit une échelle de temps basée sur le jour solaire, dite temps solaire vrai, il en résulte des variations cumulées sur une année d'environ −16 à +14 min par rapport à une échelle de temps à jour de durée fixe comme le TAI. La courbe représentative de ces variations obéit à ce qu'on appelle l'équation du temps W.
Pour bien comprendre les multiples facteurs qui impactent la durée du jour solaire, rappelons déjà qu'il faut ne pas confondre cette notion avec celle de jour sidéral W qui est la durée de rotation de la Terre sur elle‑même lorsqu'elle est considérée dans un repère stellaire – d'où le terme « sidéral » W. Cette durée peut être précisément mesurée par chronométrage de deux passages successifs d'une étoile lointaine dans un système de visée fixe sur Terre ; elle vaut environ 23 heures 56 minutes.
Pour terminer un jour solaire complet, il faut qu'un point pris comme référence à la surface terrestre se retrouve exactement face au Soleil. Or, en même temps qu'elle tourne sur elle‑même, la Terre se déplace selon sa trajectoire orbitale dans sa révolution autour du Soleil. Elle doit donc effectuer sur elle‑même une rotation d'angle supérieure à 360° pour que son point pris comme référence se retrouve dans l'axe solaire (cf. la figure ci‑dessous qui, bien évidemment, n'est pas à l'échelle). Le temps nécessaire pour accomplir ce surcroît de rotation est d'environ 4 minutes (soit environ +0,3 % par rapport au jour sidéral). Il en résulte que le jour solaire dure approximativement 24 heures.
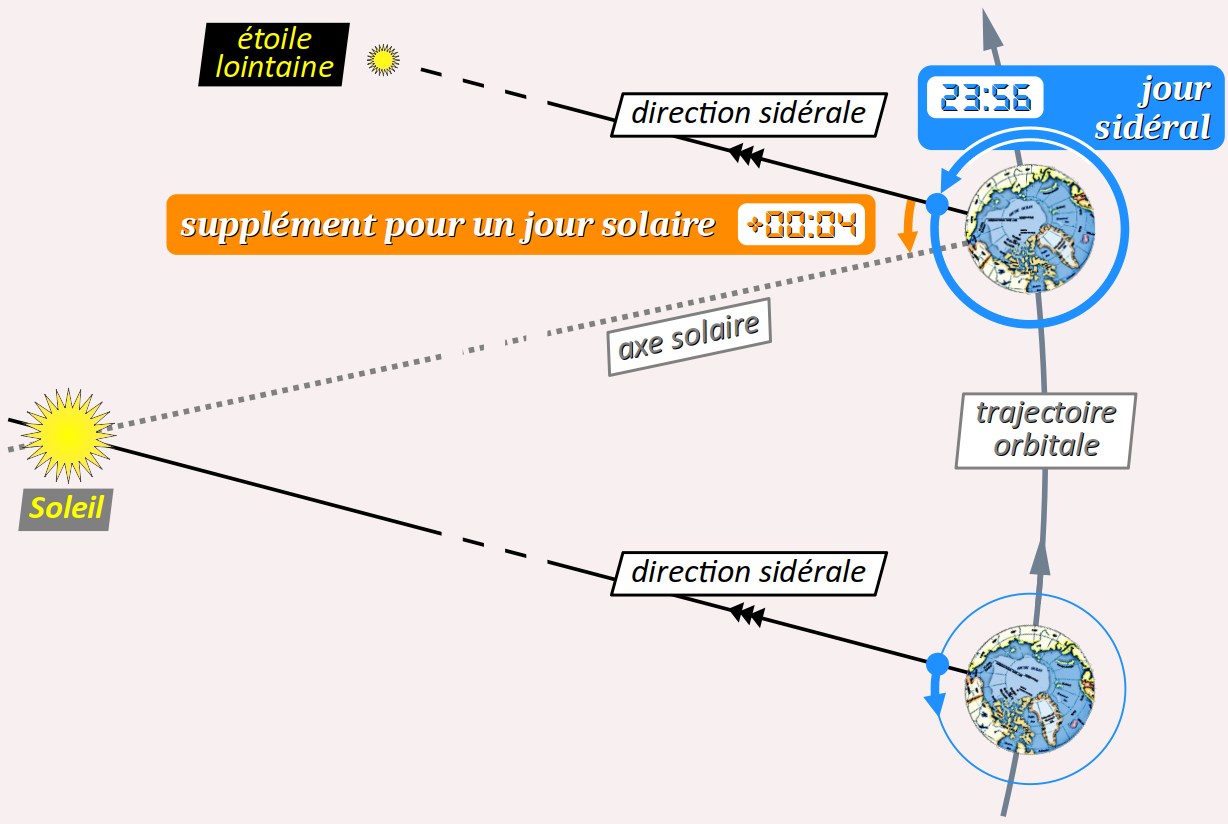
(Bien évidemment, le fait qu'un jour solaire dure 24 heures ne doit rien au hasard, puisqu'en fait, l'heure est implicitement définie comme la durée égale à 1/24e du jour solaire – cf. infra.)
Mais de plus, il faut aussi tenir compte de l'excentricité de l'orbite terrestre autour du Soleil. Même si cette excentricité est assez faible, elle impacte quand même la vitesse de la Terre sur sa trajectoire orbitale – le phénomène ayant une période annuelle.
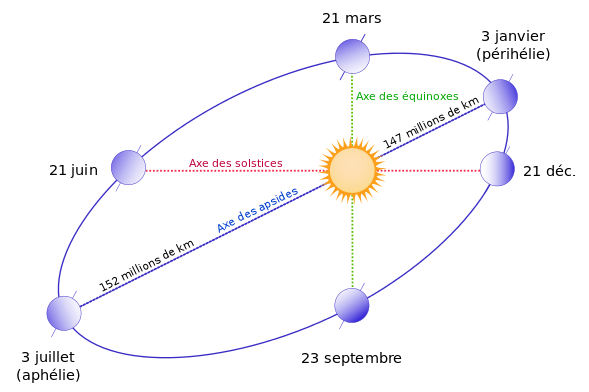
En effet W :
- au voisinage du périhélie, la plus grande proximité du Soleil induit sur la Terre une accélération radiale plus forte, donc une vitesse plus élevée, donc une trajectoire parcourue plus grande, donc un supplément de rotation plus grand, donc un jour solaire plus long que la moyenne.
- Et au voisinage de l'aphélie, c'est l'inverse : la Terre a une vitesse plus lente, donc un jour solaire plus court que la moyenne.
Par ailleurs, l'inclinaison de l'axe de rotation de la Terre par rapport au plan de l'écliptique induit également une variation du jour solaire, mais selon une période semestrielle : il augmente « autour » des solstices et diminue « autour » des équinoxes W.
Le jour solaire moyen
Au regard des variations périodiques du jour solaire, il a été jugé commode à la fin du XIXe siècle de prendre le jour solaire moyen – c'est‑à‑dire sa moyenne annuelle – comme principale unité de temps.
La seconde était alors déterminée comme valant exactement un 86 400e du jour solaire moyen et l'heure comme 3600 secondes, donc 1/24e du jour solaire moyen.
Toutefois, cette définition s'est révélée quand même insatisfaisante en raison de multiples facteurs.
- D'abord, encore fallait‑il préciser la durée d'une année pour calculer la moyenne ; on verra infra que c'est la notion d'année tropique qui a été retenue.
- Mais surtout, il est apparu que même le jour solaire moyen n'est pas constant d'une année sur l'autre. De nombreux phénomènes astronomiques et géologiques engendrent des perturbations de la fréquence de rotation de la Terre ainsi que sa vitesse orbitale.
- Il y a l'influence gravitationnelle de la Lune qui provoque les marées, mais aussi les écoulements des masses atmosphériques (air, eau), les mouvements de la croûte (tectonique des plaques), du magma interne et du noyau liquide. Tous les phénomènes dissipent de l'énergie mécanique et modifient le moment d'inertie de la planète.
- Il y a même l'influence d'autres planètes du système solaire qui, selon leur proximité ou leur éloignement avec la Terre, modifient son accélération.

Certains de ces facteurs sont imprévisibles. Mais sur le très long terme – depuis le tout début de l'histoire de la Terre – on constate un ralentissement, c'est‑à‑dire une augmentation de la période de rotation de la Terre, actuellement de l'ordre de 1,3 ms/j, soit 1 s / 800 j environ.

- Pour se faire une idée du ralentissement de la rotation de la Terre sur elle‑même, on estime qu'à l'époque du Dévonien, c'est‑à‑dire il y a environ 380 Ma W :
- un jour terrestre durait environ 22 h ;
- et une année environ 400 de ces jours.
- Et néanmoins, depuis 2020, on observe plutôt une stabilisation de la vitesse de rotation de la Terre sur elle‑même (cf. infra ) – mais il s'agit vraisemblablement d'un épiphénomène.
L'année tropique : période du cycle des saisons
L'année sidérale et l'année tropique
Comme pour la notion de jour, la notion d'année se décline en deux sous‑notions détaillées ci‑dessous
- L'année sidérale W qui est la durée supposée périodique de révolution de la Terre autour du Soleil, lorsqu'elle est observée par rapport aux étoiles. Elle vaut en moyenne 365,25636042 jours solaires moyens.
- L'année tropique W qui est concrètement la durée supposée périodique d'un cycle des quatre saisons, en considérant comme référence de répétition l'équinoxe de printemps de l'hémisphère nord. Elle vaut en moyenne 365,2421898 jours solaires moyens.
Une année tropique est donc plus courte qu'une année sidérale d'environ année 0,01417062 jour, soit 1224,341568 s, autrement dit approximativement 20 min et 24 s.
Un phénomène : la précession des équinoxes
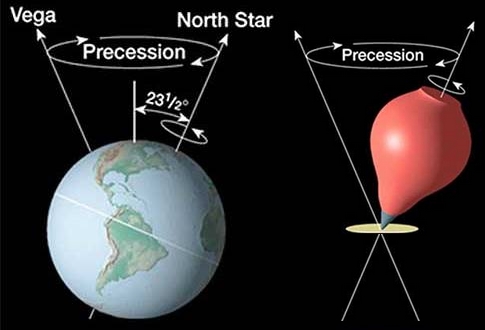
La différence entre les deux notions d'année sidérale et d'année tropique résulte principalement d'un phénomène appelé – par relation de cause à effet – la précession des équinoxes W. C'est ainsi qu'on appelle le mouvement d'oscillation de l'axe de rotation de la Terre – à la manière d'une toupie, mais très lentement puisque la période de cette oscillation est d'environ 25 800 ans.
Ainsi, à la moitié de cette période (donc, tous les 12 900 ans), l'angle que présente l'axe de rotation de la Terre avec la normale au plan de l’écliptique prend une valeur opposée à celle qu'il avait au début de la période. Par exemple :
- à notre époque, le solstice d'hiver de l'hémisphère nord se produit lorsque la Terre est voisine de son périhélie ;
- mais dans environ 12 900 ans, c'est le solstice d'été qui se produira au voisinage du périhélie !
Ce phénomène pourrait sembler négligeable tant sa période est grande à l'échelle de l'histoire contemporaine. Et pourtant, il est identifié comme problématique depuis Hipparque (Ie siècle avant J.‑C. W) ! Et en effet, par la différence de durée entre l'année sidérale et l'année tropique, à chaque siècle, les solstices et équinoxes se décalent de plus d'une journée dans l'année sidérale. C'est ce qu'on appelle la dérive séculaire des saisons.
Choix de l'année tropique pour les calendriers civils
Afin d'éviter une lente dérive des saisons, c'est donc l'année tropique qui a été retenue comme durée de référence pour établir les calendriers civils W.
Ainsi, le calendrier Julien – appelé ainsi car imposé par Jules César en l'an 46 avant J.‑C. – avait déjà introduit la notion d'année bissextile : toutes les 4 années, un jour supplémentaire était ajouté au mois de février (le 29), portant la durée moyenne de l'année julienne à 365,25 jours.
Mais sachant la durée réelle de l'année tropique (environ 365,242 jours), cette règle n'était pas adéquate : l'année julienne ainsi définie était encore trop longue d'environ 11 min et 14 s. Il en résultait encore une dérive non négligeable des équinoxes et des solstices (un jour tous les 128 ans), qui fut constatée dès le IIIe siècle.
Et c'est seulement depuis l'adoption du calendrier grégorien que la durée de l'année civile est pratiquement égale à celle de l'année tropique.
Le calendrier grégorien
Le calendrier grégorien W est un calendrier solaire – autrement dit, un système de numérotation des jours solaires. Il a conçu au début du XVIe siècle à la demande du pape Grégoire XIII pour mieux corriger la dérive des solstices W que le calendrier julien.
Il est adopté par la quasi‑totalité des états du monde W (dès 1582 par les pays catholiques comme la France).

Dans le calendrier grégorien, l'année commune W compte 365 j. Et, comme dans le calendrier julien, si le numéro d'année est divisible par 4, on ajoute un jour intercalaire (en anglais, leap day) – le 29 février – et on parle alors d'année bissextile W (en anglais, leap year).
Or cet ajustement n'est pas suffisant puisque, en nombres de jours, la partie fractionnaire de l'année tropique est légèrement inférieure à ¼. En conséquence :
- les années dont le numéro est divisible par 100 (donc par 4) font exception à la règle générale ; elles sont donc considérées comme commune et non pas bissextiles ;
- mais les années dont le numéro est divisible par 400 (donc par 100) font exception à la règle supra ; elles sont bel et bien considérées comme bissextiles et non pas communes.
Cette solution ajuste la valeur moyenne de l'année calendaire W à 365,2425 j. La différence avec la valeur moyenne de l'année tropique (pour mémoire, environ 365,2422 jours) induit une dérive des saisons très lente – environ 3 jours tous les 10 000 ans – qui n'est pas considéré comme un problème aujourd'hui…
Par ailleurs, il faut aussi prendre en compte le ralentissement de la rotation de la Terre sur elle‑même qui aura tendance à accentuer cet écart.
Enfin, il ne faut pas perdre de vue que l'année tropique elle‑même n'a pas une durée constante. Perturbée par la présence des autres planètes du système solaire, elle a tendance diminuer de 0,5 s par siècle…
Le temps universel
Le temps universel, abrégé UT1, est une échelle de temps solaire basée sur le chronométrage au regard d'une échelle du temps atomique :
- de la rotation de la Terre sur elle‑même – ce qui permet de déterminer la durée moyenne du jour solaire ;
- et de la révolution de la Terre autour du soleil au sens de l'année tropique ;
On procède par l'observation d'objets célestes très distants – des quasars W – et l'emploi de techniques d'interférométrie W.
Le temps universel UT1 reprend les mêmes principes, mais avec des mesures plus précises, que temps moyen de Greenwich – Greenwich mean time, abrégé GMT – largement adoptée dans le monde au début du XXe siècle W.
Attention. La seconde du temps universel n'a pas exactement (mais presque) la même durée que celle du temps atomique. Elle est définie comme un 86 400e du jour solaire terrestre moyen, dont la durée est calculée sur la base des chronométrages effectués par le Service international de la rotation terrestre et des systèmes de référence W – en anglais, International Earth rotation and reference systems service ou IERS.
Il en résulte un décalage par rapport au temps atomique international (cf. supra ) de quelques secondes sur une cinquantaine d'années. On va voir que ce décalage est à l'origine de la définition du temps universel coordonné ou UTC (cf. infra ).
Les zones horaires : définition du temps mondial
Dans chaque pays, quelle que soit l'échelle de temps adoptée, l'heure officielle – et donc aussi la date – est décalée par rapport à l'heure internationale (cf. infra), au regard de sa position géographique et de choix politiques.
Ce décalage, spécifique à telle ou tel lieu géographique, permet aux horaires remarquables 0 h – minuit – et 12 h – midi – de correspondre partout sur Terre (sauf aux latitudes extrêmes) à la même réalité solaire, c'est‑à‑dire respectivement au milieu du jour et de la nuit .
Lors de la Conférence internationale de Washington W (1884), le méridien de Greenwich W – du nom d'un quartier de Londres où se situe l'Observatoire Royal – a été adopté comme méridien de référence pour définir l'heure internationale. Il sert également à diviser le globe terrestre en deux hémisphères dits Ouest et Est.
Quant aux anciens fuseaux horaires W, ils sont issus d'une division historique du globe en 24 secteurs angulaires réguliers de 15° dont l'un est centré sur le méridien de Greenwich.
Aujourd'hui, on ne parle plus de fuseaux mais de zones horaires W – en anglais, time zone car leur découpage est plus complexe :
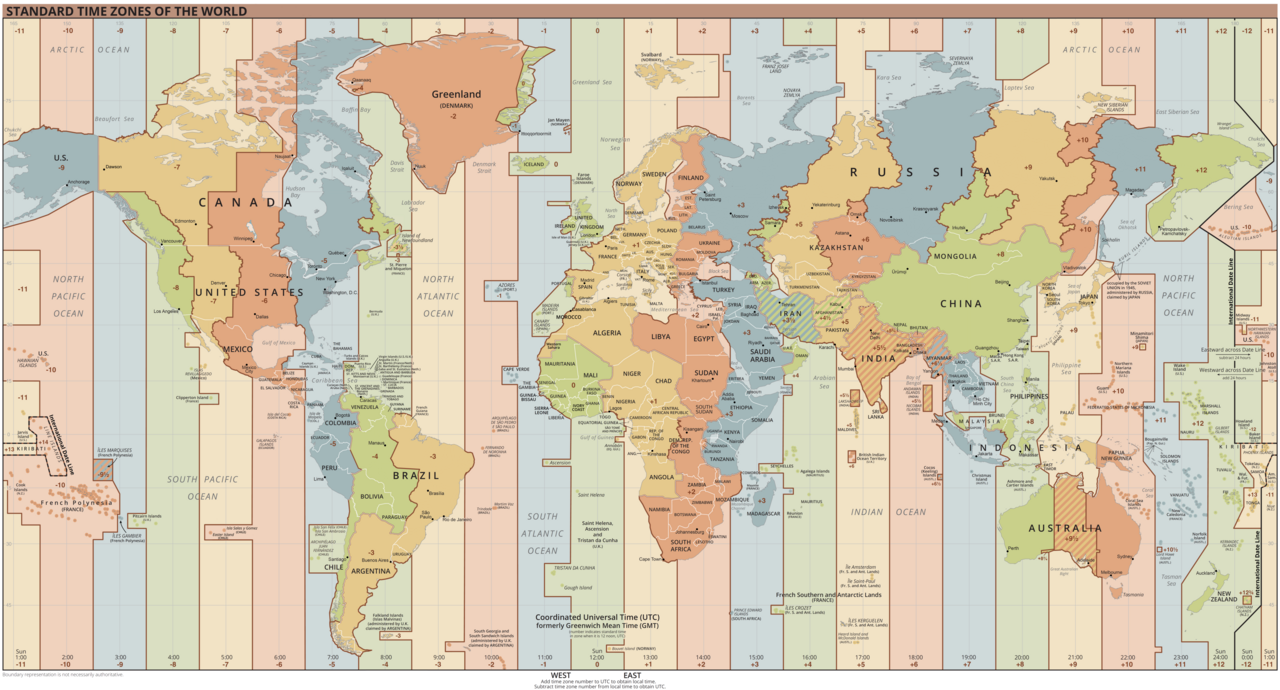
- sur la carte mondiale W, on distingue bien 24 grandes zones horaires qui sont chacune étiquetée par un décalage horaire entier positif ou négatif ;
- mais la zone la plus à droite se divise en deux, étiquetées respectivement +12 et −12 ;
- et même, à l'extrême gauche, on observe deux petites zones étiquetées +13 et +14 !
- enfin, certains pays (par exemple, l'Inde…) adoptent un décalage horaire fractionnaire – c'est‑à‑dire qui ne s'exprime pas par un nombre entier d'heures, la résolution autorisée étant de 15 minutes.
Pour approfondir ces aspects, on pourra consulter la vidéo de la chaîne YouTube de vulgarisation historique et géographique TéléCrayon au lien suivant Y.
Désignation des zones horaires
Toute zone horaire peut être désignée par une chaîne de caractères de la forme UTC±hh:mm où :
- le sigle
UTCfait référence à l'échelle du temps universel coordonné mondialement adopté pour l'heure internationale (cf. infra ) ; - la forme
hh:mmreprésente les digits du décalage horaire par rapport à l'heure internationale, chiffré à 15 min près ; - le sens du décalage est spécifié par un signe
+ou−
Lorsque le décalage s'exprime en heures pleines (sans minutes), on adopte une écriture simplifiée de la forme UTC±h où h représente le nombre d'heures du décalage. Exemple : on écrit simplement UTC+2 pour indiquer la zone horaire dite d'Europe de l'est.
De plus, on peut omettre l'indication du décalage lorsqu'il est nul. Ainsi, la zone horaire d'Europe de l'Ouest UTC+0 se note tout simplement UTC (elle était anciennement désignée GMT).
Pour faciliter les traitements informatiques, certaines zones horaires sont également désignées par un voire plusieurs sigles comme illustré ci‑dessous.
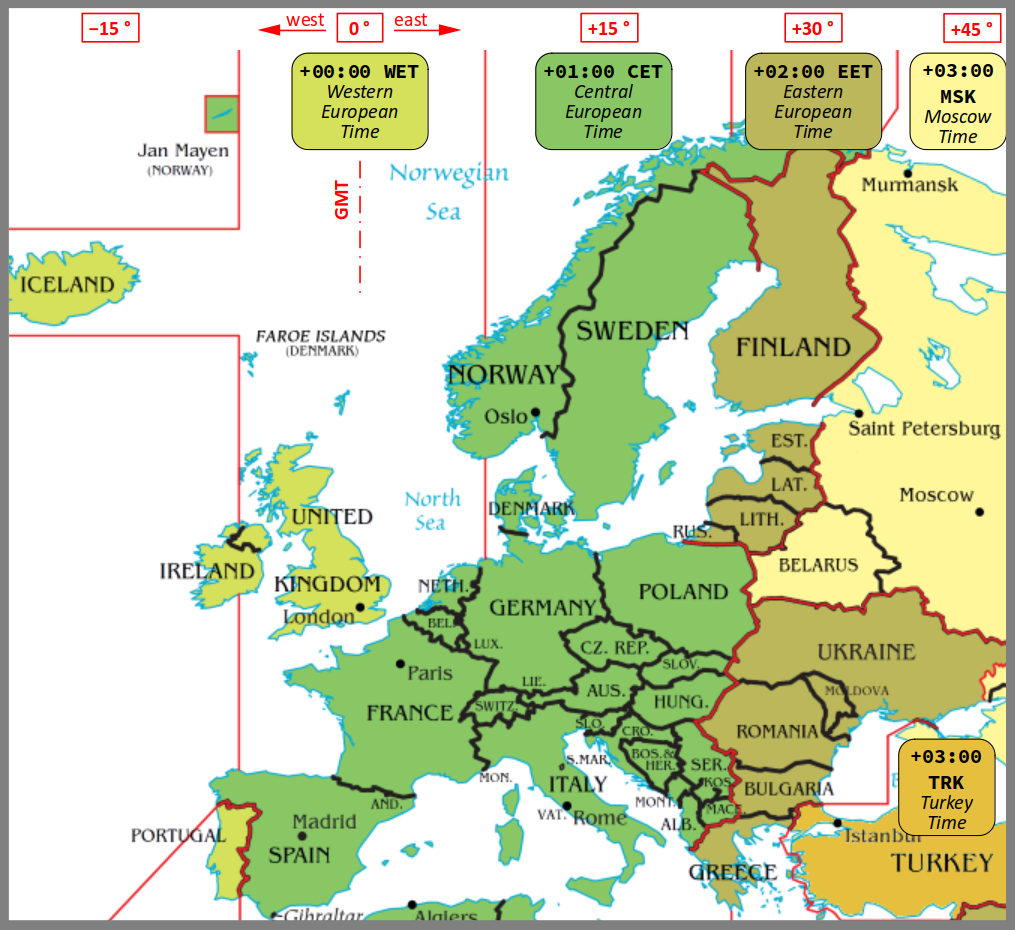
Par exemple :
- WET W pour Western European Time – anciennement Greenwich mean time ou GMT – qui correspond à UTC+0 ;
- CET W pour Central European Time ou WAT pour West Africa Time qui correspondent l'une et l'autre à UTC+1 ;
- EET W pour Eastern European Time ou CAT pour Central Africa Time qui correspondent l'une et l'autre à UTC+2 ; etc.
Selon sa position géographique, un pays peut hésiter entre deux zones horaires voisines pour de nombreuses raisons W, notamment politiques. Mais le choix effectué n'est jamais indifférent en termes de décalage avec le temps solaire W.
L'heure d'« été »
La possibilité pour un pays d'adopter un décalage horaire au quart d'heure près ne suffit pas à optimiser la superposition des horaires d'activité avec les horaires solaires, et ce d'autant plus que ce pays est situé à des latitudes élevées, c'est‑à‑dire avec des saisons contrastées.
Une mauvaise superposition a tendance à occasionner une surconsommation énergétique, en particulier pour l'éclairage en soirée.
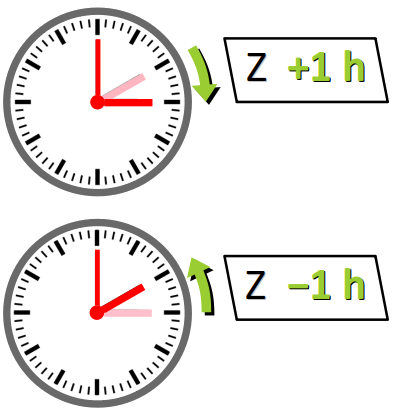
Le décalage dit d'heure d'été W – en anglais, daylight saving time ou DST – consiste à augmenter d'une heure le décalage horaire établi dans une zone horaire durant une période dite estivale (summer time) au sens large. Hors de cette période, on parle d'heure standard (standard time) ou encore d'heure d'hiver.
Il en résulte que :
- le jour de passage à l'heure d'été dure 23 h ;
- le jour de retour à l'heure d'hiver dure 25 h.
Comme le choix de la zone horaire, l'adoption ou nom du décalage d'heure d'été est en principe une décision politique, souveraine ou éventuellement supra‑nationale (c'est précisément le cas au sein de l'Union Européenne).
De plus, les jours et horaires de passages ne sont pas pas harmonisée au niveau mondial. Leurs choix sont également le fruit de décisions politiques locales.
- En particulier, les jours de passage sont fixés par des contraintes calendaires complexes – par exemple, le « dernier dimanche du mois de mars » pour le passage à l'heure d'été et le « dernier dimanche du mois d'octobre » pour le retour à l'heure d'hiver.
- Quant aux heures de transition, elles sont en général fixées la nuit, typiquement entre
01:00et03:00heures du matin.
Pour faciliter les traitements informatiques, les zones horaires où le décalage d'heure d'été est en vigueur sont désignées par des sigles spécifiques. Par exemple :
- WEST pour Western European Summer Time qui correspond à UTC+1 ;
- CEST pour Central European Summer Time qui correspond à UTC+2 ; etc.
Dans toutes les zones horaires de l'Union Européenne, les règles de changement d'heure sont harmonisées (cf. la carte ci‑dessous, actualisée en 2017) :
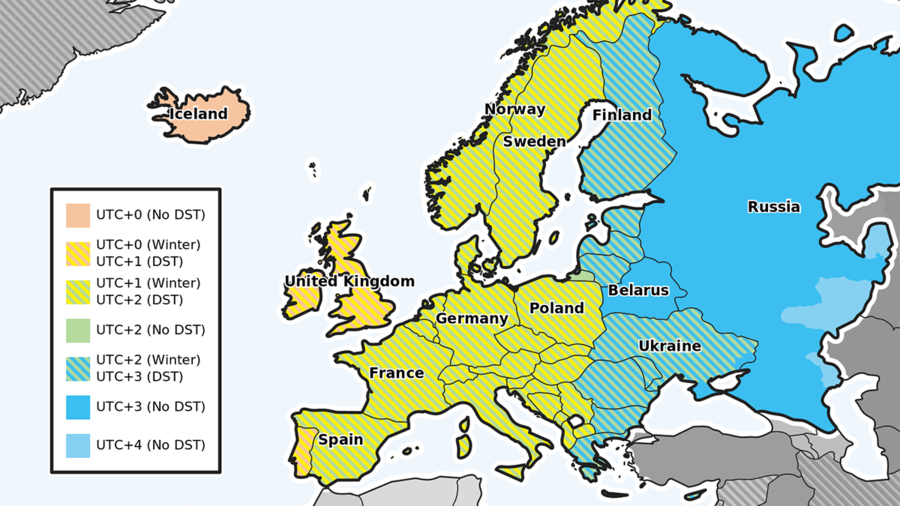
- Le passage à l'heure d'été intervient le dernier dimanche du mois de mars à
01:00:00 UTC. - Le passage à l'heure d'hiver intervient le dernier dimanche du mois d'octobre à
02:00:00 UTC.
00:59:59, l'heure officielle est 02:00:00. 01:59:59, l'heure officielle est 01:00:00. Chaque changement d'heure se déroule au même instant quelle que soit la zone horaire, donc avec une ou deux heures de décalage par rapport à l'heure locale. Ainsi, dans la zone horaire d'Europe centrale (CET) :
- le passage à l'heure d'été intervient à
02:00:00 CETqui devient03:00:00 CEST(Central European Summer Time) ; - le passage à l'heure d'hiver intervient à
03:00:00 CESTqui redevient02:00:00 CET(Central European Time).
Le 26 mars 2019, le Parlement européen a voté un projet de directive d'abandon des changements d'heure, conformément au résultat d'une consultation populaire menée par la Commission européenne .
Toutefois, cette décision n'a pas encore été validée par le Conseil de l'Europe — étape indispensable avant la mise en application de cette décision. De plus, ce sujet ne figure pas encore sur l'agenda du Conseil .
Pour un technicien en informatique, il reste donc indispensable de savoir gérer ce dispositif qui va vraisemblablement perdurer encore au moins quelques années.
Le temps universel coordonné
Le temps universel coordonné W – coordinated universal time ou UTC – est une échelle de temps en vigueur depuis le 1er janvier 1972.
L'UTC est basé sur le temps atomique international (TAI) avec un retard initial de 10 secondes pour corriger le décalage accumulé avec l'échelle de temps universel UT1.
De plus, l'UTC est sporadiquement ajusté par incrémentation ou décrémentation unitaire d'une seconde intercalaire W (en anglais, leap second) chaque fois que nécessaire pour garantir un écart toujours inférieur à ±0,9 s avec le temps universel UT1.
L'UTC est aujourd'hui adopté dans tous les pays développés comme échelle du temps officiel, aux décalages de zones et d'heure d'été près.
C'est l'IERS (cf. supra ) qui prend la décision d'ajouter ou retrancher une seconde intercalaire au compteur de secondes de l'UTC. Cette décision dépend de la différence avec le temps universel UT1 dont l'IERS a la responsabilité de la mesure.
En principe, un ajustement de l'UTC :
- ne peut intervenir que dans la dernière seconde d'un mois dans la zone horaire
UTC+0, de préférence le 30 juin ou le 31 décembre ; - doit intervenir au même instant partout sur le globe – donc à l'heure décalée spécifiquement dans chaque zone horaire.
La décision de modifier ou non l'UTC est annoncée environ six mois à l'avance par une publication comme celle‑ci .
Dernièrement, une seconde intercalaire a été ajoutée.
- Dans la zone
UTC+0, le 31 décembre 2016, juste après la secondeT23:59:59, l'heure courante est passée àT23:59:60, avant de basculer (encore une seconde après) au 1er janvier 2017,T00:00:00. - Dans la zone
UTC+1, ce changement est intervenu au même instant – donc selon l'heure locale, le 1er janvier 2017, àT00:59:59.

Depuis le 1er janvier 1972, en plus des 10 secondes additionnelles de rattrapage initial, un total de 27 secondes intercalaires ont été ajoutées à l'UTC, portant le décalage avec le TAI à 37 secondes. Le graphique ci‑contre représente la différence W :
DUT1 = UT1 − UTC
au fil des années depuis 1976, ou chaque pic représente une seconde intercalaire ajoutée par l'IERS.
On constate donc :
- que jusqu'à présent, la tendance est constamment à la baisse (aucune seconde intercalaire jamais n'a été retranchée), la cause principale étant que la rotation de la Terre ralentit (cf. supra ), ce qui induit un retard croissant de l'UT1 sur le TAI ;
- mais que d'une année à l'autre, le phénomène est stochastique, ce qui est logique en considérant la multitude des facteurs d'influence du temps solaire ;
- et que récemment (depuis 2020), l'UT1 semblerait même « stabilisée » (cf. la remarque ci‑après).
En pratique, l'IERS décide de l'ajout ou de la suppression d'une seconde intercalaire dès que la différence DUT1 dépasse ±0,5 s. Compte tenu du délai entre l'annonce de la décision et son exécution (6 mois), la différence DUT1 ne dépasse jamais ±0,8 s.
Au début de l'année 2021, des articles dans la presse ont fait écho du constat que la rotation de la Terre s'était très légèrement accélérée ! (À l'époque, on pouvait déjà observer l'amorce d'un palier sur le diagramme ci‑dessus.) Il avait même été évoqué l'éventualité que l'IERS prenne prochainement la décision – pour la première fois – de soustraire une seconde à l'UTC !
Mais du fait des risques informatiques liés à l'ajustement de UTC, il a été envisagé de ne plus procéder à l'ajout ou retrait des secondes intercalaires au plus tard en 2035. C'est ce qu'a traduit la résolution nº 4 de la 27e conférence générale des poids et mesures qui s'est tenue du 15 au 18 novembre 2022 au Palais des Congrès de Versailles .
Et par ailleurs, les spécialistes de la géophysique du globe ont tendance à penser qu'il ne s'agit que d'un épiphénomène lié à divers facteurs (changement de la structure interne de la Terre, phénomène atmosphérique global, ou autre) qui ne peut pas impacter durablement la tendance au ralentissement .
Conséquences sur les unités de temps
En temps universel coordonné, la seconde et tous ses sous‑multiples ont, comme en temps atomique international, une durée fixe.
En revanche, toutes les unités supérieures – minute, heure, jour, année – n'ont pas toujours la même durée, selon qu'est intervenu ou non l'ajout ou le retrait d'une seconde intercalaire.

- Ainsi, une minute dure presque toujours 60 s mais peut exceptionnellement durer 61 s en cas de seconde intercalaire additionnelle, étant alors comptée de 0 à 60 – cf. l'image ci‑contre.
- En conséquence, l'heure et le jour incluant cette minute durent respectivement 3 601 s et 86 401 s.
Même exceptionnelles, les secondes intercalaires compliquent la détermination d'une date d'arrivée à partir d'une autre date de départ et d'une durée : il faut tenir compte du nombre de secondes intercalaires ajoutées entre ces deux dates et les décompter de la durée pour pouvoir ensuite opérer une division entière de la durée par celle d'une heure normale (3 600 s) ou d'une journée normale (86 400 s).
Représentation du temps calendaire dans les systèmes informatiques
Représentations littérales d'une date (haut niveau)
On rappelle que la représentation littérale d'une information est juste une écriture formelle particulière qui peut s'insérer dans tout type de texte.
Pour éviter les ambiguïtés dans les échanges internationaux, la norme ISO 8601 W (Data elements and interchange formats) spécifie diverses représentations littérales d'une date – au sens large, car ce peut aussi être une heure, voire une date et heure – quelle que soit l'échelle de temps adoptée (UTC, UT1, TAI).

Ces représentations, intelligibles pour l'humain, sont des chaînes de caractères et se déclinent en six formats différents, selon l'unité de résolution choisie – typiquement, le jour pour une date calendaire et la seconde pour une heure civile (cf. la figure donnée à titre d'exemple).
En règle générale, la norme ISO 8601 :
- exclut tout emploi de noms (de mois, de jours, etc.) puisqu'ils sont spécifiques à une langue particulière ;
- impose une représentation de gauche à droite par unités de durées décroissantes (année, mois, jour, heure, etc.) ;
- impose l'emploi systématique des zéros non significatifs dans l'expression des numéros de mois, jours, etc. indépendamment de l'emploi ou non de séparateurs ;
- recourt à des symboles littéraux spécifiques, par exemple
Tcomme préfixe de la représentation d'une heure, pour la séparer de celle d'une date.
Ainsi, pour exprimer une date du calendrier géorgien, l'unité de résolution étant le jour, le format normalisé usuel est yyyy-mm-dd où :
-
yyyyreprésente les 4 digits décimaux du numéro d'année (year), -
mmreprésente les 2 digits décimaux du numéro de mois (month), avec la convention usuelle01pour janvier, etc. -
ddreprésente les 2 digits décimaux du numéro de jour (day).
Selon les même principes, pour exprimer une date et heure UTC à la seconde près, le format normalisé usuel est :
yyyy-mm-dd T hh:mm:ss ±hh:mm
où l'indication de la zone horaire (cf. supra ) peut être abrégé par la lettre Z en cas de décalage nul (heure dite UTC).
La norme ISO 8601 offre par ailleurs de très nombreuses possibilités de représentation, qu'il ne serait pas pertinent de détailler toutes ici. Pour approfondir, on pourra consulter ce lien W.
Dans le format normalisé usuel, la date et heure d'ouverture de la 1re session de la 26e Conférence générale des poids et mesures , qui a débuté le 13 novembre 2018 à 9 h au Palais des congrès de Versailles (zone CET), est :
2018-11-13T09:00:00+01:00
Elle correspond à 2018-11-13T08:00:00Z, heure UTC (sans décalage horaire).
Représentations numériques d'une date (bas niveau)
Dans une machine informatique, la taille de représentation en mémoire d'une date et heure de l'échelle UTC dépend du rôle de cette machine au regard de la mise en œuvre du protocole NTP (cf. l'introduction ). Il faut a priori distinguer le cas :
- d'un serveur de temps qui a pour rôle de partager la date et heure courante de référence, et qui doit par conséquent mémoriser cette valeur avec la plus grande résolution possible – donc dans un format de grande taille ;
- et tout autre machine qui agit simplement en qualité de client NTP pour bénéficier du partage de la date et heure courante ; sauf cas particulier, elle peut se contenter d'une résolution modérée – donc d'un format plus petit.
Et même dans le cas des serveurs de temps, la résolution requise – donc la taille du format – n'est pas la même selon qu'il s'agit :
- d'une machine directement reliée à une horloge atomique – on parle de serveur de stratum 1 (cf. infra ) ;
- ou d'un serveur dans un réseau local – c'est‑à‑dire de stratum supérieur à 1.
Dans ce qui suit, on ne considère pas le cas des montres et autres équipements radio‑pilotés W. En effet, ils utilisent un protocole de communication différent de NTP, qui œuvre exclusivement par ondes électromagnétiques, hors des réseaux TCP/IP.
Le format timestamp NTP

Pour représenter une date et heure sur l'échelle de l'UTC, le protocole NTP adopte un format décimal non signé à virgule fixe sur 64 bits, appelé timestamp NTP.
Une valeur encodée dans ce format exprime la durée en secondes écoulée depuis depuis le 1er janvier 1900 à 00 h 00 dans la zone horaire UTC+0 – secondes intercalaires non incluses.
Il s'agit de la date de référence choisie par convention comme instant 0 de l'UTC et appelée en anglais epoch 0.
Plus précisément :
- La partie entière est encodée sur 32 bits en binaire naturel, elle peut donc représenter un nombre de secondes compris entre 0 et 4 294 967 295 (exactement comme le type
uint32_ten langage C). - La partie fractionnaire est encodée presque comme le significande du type flottant en langage C (cf. chap. C3‑V C) avec des poids fractionnaires en puissances négatives de 2 allant jusqu'à 2−32 ≃ 2,33 × 10−10 s – donc avec une résolution de 233 ps (picosecondes).

Le terme « timestamp » fait référence à un outil d'horodatage manuel de documents comme celui en photo ci‑contre (en anglais, stamp signifie « timbre » ou « tampon »).
En français, on pourrait parler d'estampille temporelle W, mais dans la pratique, ce terme n'est pas usité.
Le format timestamp Unix
Depuis la fin des années 1980, avec le développement de nombreuses variantes du système d'exploitation Unix W, l'IEEE (cf. chap. R1‑I ) a édité des normes pour standardiser les interfaces de programmation des applications (en anglais, application programming interface ou API). On les appelle normes POSIX W pour portable operating system interface, le « X » faisant référence à celui d'Unix.
En particulier, les versions récentes d'Unix et de ses variantes Linux s'efforcent de respecter les normes POSIX. Il en est de même des systèmes d'exploitation pour serveurs comme Windows NT.
Les normes POSIX imposent que la partie entière de la date et heure courante soit encodée dans un format différent de celui du timestamp NTP . On parle de format timestamp POSIX, appelé également timestamp Unix W.
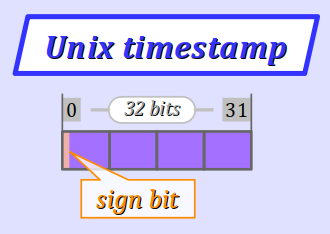
Le plus souvent, ce format est implémenté en mémoire par type entier signé sur 32 bits, donc d'étendue comprise entre −2 147 483 648 et +2 147 483 647.
Un timestamp Unix exprime en secondes – mais sans inclure les secondes intercalaires – la durée écoulée depuis le jeudi 1er janvier 1970 à 00 h 00 exactement dans la zone horaire UTC+0. Cette date est appelée en anglais epoch Unix ou POSIX.
Sachant que 2 147 483 647 secondes représentent une demi‑période de 68 ans environ, un timestamp Unix permet d'encoder une date comprise entre le 13 décembre 1901 et le 19 janvier 2038.
On détermine la valeur d'un timestamp Unix correspondant la même date et heure que celle de la partie entière d'un timestamp NTP par la formule :
où l'epoch Unix est exprimée dans le format d'un timestamp NTP et vaut 2 208 988 800 s (70 ans).
Sur l'Internet, on trouve toutes sortes de page web comme celle‑ci qui :
- affiche la valeur courante du timestamp Unix ;
- effectue à la demande la conversion au format date et heure d'une valeur de timestamp Unix, et vice‑versa.
Problèmes futurs liés aux représentations numériques des dates
On a vu supra que l'encodage de la date et heure courante sur seulement 32 bits par un nombre entier de secondes écoulées depuis une date de référence ne permet d'étiqueter le temps calendaire que sur une période limitée à 136 ans. Compte tenu des dates de références choisies :
- la partie entière du timestamp NTP rebouclera à 0 en l'an 2036 ;
- le timestamp Unix rebouclera à −2 147 483 648 en l'an 2038.
L'un et l'autre de ces bugs annoncés sont bien évidemment anticipés par les concepteurs des systèmes informatiques.
- Un nouveau format date NTP avec une partie entière sur 64 bits a justement été introduit dès 2010 dans la version 4 du protocole NTP pour y remédier (cf. infra). Étant rétrocompatible avec le format précédent, il ne pose pas de gros problèmes de mise en œuvre, et c'est pourquoi on peut considérer qu'il n'y aura pas de bug de l'an 2036.
- Dans le même esprit, les nouvelles versions des systèmes d'exploitation adoptent déjà un format plus large (64 bits) que l'actuel timestamp Unix pour éliminer à très long terme tout risque de débordement. Toutefois, ce nouveau format n'est pas rétrocompatible avec le format précédent à cause du bit de signe, aussi son adoption est complexe et laisse encore ouverte la question du bug de l'an 2038 W.
Le format date NTP
En prévision des besoins futurs en précision et étendue, la version 4 du protocole NTP introduit donc un nouveau format d'encodage élargi – dit date NTP – pour exprimer une date et heure courante de l'échelle de l'UTC. Ce format est conçu pour étendre le précédent format timestamp NTP de façon rétrocompatible (cf. la figure ci‑dessous).

Toutefois, il n'est pas encore utilisé en pratique pour le partage de l'UTC.
Il en résulte que le format date NTP est également décimal à virgule fixe, mais implémenté avec :
- une partie entière encodée sur 64 bits, avec un bit de signe opérant en complément à 2 (cf. chap. C3‑II C) ;
- une partie décimale également encodée sur 64 bits ;
soit une largeur totale de 128 bits (16 octets).
Le signe de la partie entière s'interprète comme suit :
- toute valeur positive correspond à une date et heure ultérieure à la date de référence ;
- toute valeur négative correspond à une date et heure antérieure à la date de référence ;
sachant que la date de référence reste la même que celle du timestamp NTP, à savoir le 1er janvier 1900 à 00 h 00 dans la zone horaire UTC+0.
Avec une largeur de 64 bits, le format de la partie entière est semblable au type long long du langage C (cf. chap. C3‑II ), qui peut encoder plus de 18 milliards de milliards de valeurs. Cela est largement suffisant pour exprimer plus de 40 fois l'âge actuel de l'Univers W !
Quant à la partie fractionnaire, elle atteint une résolution allant jusqu'à 2−64 ≃ 5 × 10−20 s – laquelle est un million de fois plus petite que la résolution du temps atomique (cf. supra ) !
Soulignons toutefois que même dans sa version v4, le format des messages du protocole NTP ne permet pas de transmettre des données au format date NTP. Ce dernier ne peut servir que pour mémoriser la date et heure courante dans les horloges atomiques.
La notion d'ère
Pour exprimer des dates antérieures ou ultérieures à la période actuelle couverte par le timestamp NTP (du 1er janvier 1900 au 7 février 2036) mais sans recourir au format date NTP complet, le protocole NTP introduit la notion d'ère – en anglais, era.
Elle consiste à former un ordinal de type entier signé avec les bits 0 à 31 du format date NTP.
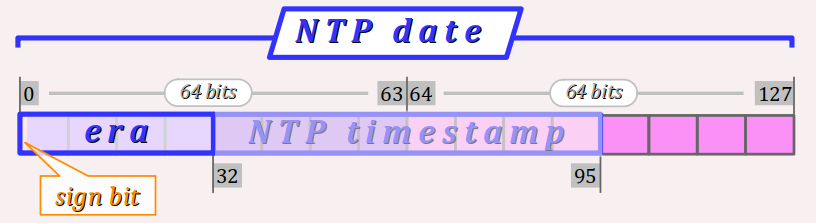
Ce numéro d'ère peut prendre des valeurs allant de −2 147 483 648 à 2 147 483 647, chacune désignant une période d'environ 136 ans – soit environ 18 × 1018 années au total ! Il suffit alors d'associer un numéro d'ère à un timestamp NTP pour reconstituer la partie entière d'une valeur encodée au format date NTP.
Ainsi :
- l'ère 0 correspond à la période actuelle ;
- l'ère −1 correspond à la période allant de l'année 1764 à l'année 1899 ;
- l'ère +1 correspond à la période allant de l'année 2036 à l'année 2172 ;
- etc.
sachant que les changements d'ère se produisent en cours d'année (et même de journée…).
Toutefois, même dans sa version v4, le format des messages du protocole NTP ne permet pas de transmettre des données d'ère.
Prise en compte des secondes intercalaires
Il peut paraître surprenant que le format date NTP – et donc les timestamp NTP et Unix (ou Posix) qui en sont issus donnent la date et heure UTC alors que, par un choix de conception, n'incluent pas les secondes intercalaires (cf. supra ).
Ce choix se justifie au regard d'un objectif opérationnel principal : pouvoir déterminer un temps calendaire par un algorithme immuable relativement simple, c'est‑à‑dire être capable de calculer la date et heure UTC à partir d'un timestamp NTP, et réciproquement (sauf aux instants d'ajustement par une seconde intercalaire, qui sont exceptionnels).
En contre‑partie, ce choix obère la possibilité de calculer une durée par simple soustraction entre deux timestamp NTP étiquetant deux instants sur l'échelle de l'UTC. En effet, pour effectuer un tel calcul, il faut, en plus de la soustraction, tenir compte des secondes intercalaires éventuellement ajoutées ou retranchées entre ces deux instants.
Pour bien comprendre ces deux aspects, il faut étudier en détail la gestion des secondes intercalaires avec les échelle de temps TAI et UTC.
Cas d'une seconde ajoutée
Prenons l'exemple de la seconde intercalaire qui a été ajoutée le 30 juin 2015, détaillée sur la figure ci‑dessous.
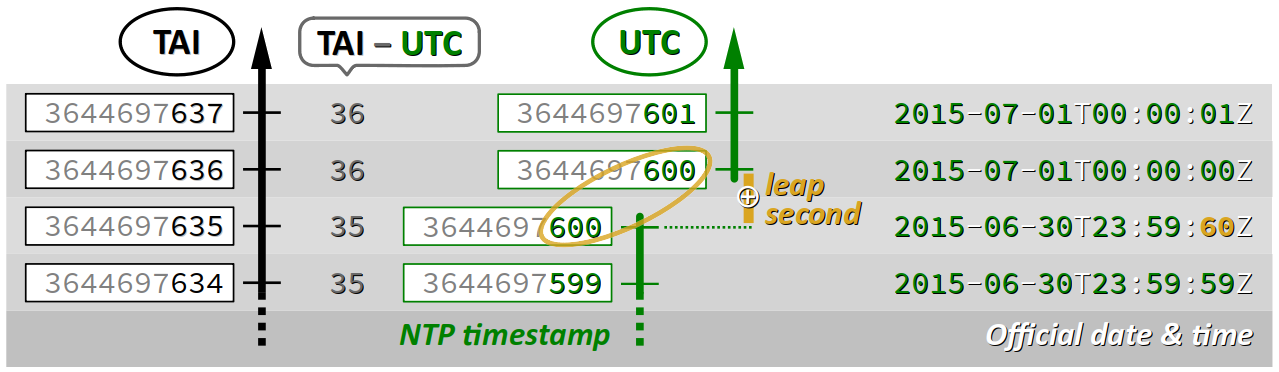
- Sur l'échelle du TAI (temps atomique international), le compteur des secondes écoulées depuis le 1er janvier 1900 est incrémenté régulièrement.
- En revanche, sur l'échelle de l'UTC, le compteur des secondes que constitue la partie entière du timestamp NTP est comme figée durant une seconde à la valeur
3644697600. - Au passage, la différence TAI − UTC augmente d'une unité : elle passe de
35à36.
23:59:60. En définitive, on constate que deux secondes différentes du TAI correspondent à une même valeur du timestamp NTP. Pour conserver une relation d'ordre total sur ces valeurs, on doit donc distinguer deux échelles, avant et après l'ajout de la seconde intercalaire.
On peut également observer qu'à l'heure remarquable 00:00:00 du 01/07/2015, la valeur 3644697636 du timestamp TAI n'est pas un multiple de 86 400 (la durée d'un jour en secondes). Il n'y a donc pas d'algorithme simple pour établir la correspondance entre le TAI et le temps calendaire.
Pour une compréhension plus fine de l'ajout d'une seconde intercalaire, il est pertinent de le schématiser sur un diagramme bidimensionnel, avec en abscisse le TAI et en ordonnée l'UTC, comme ci‑dessous.
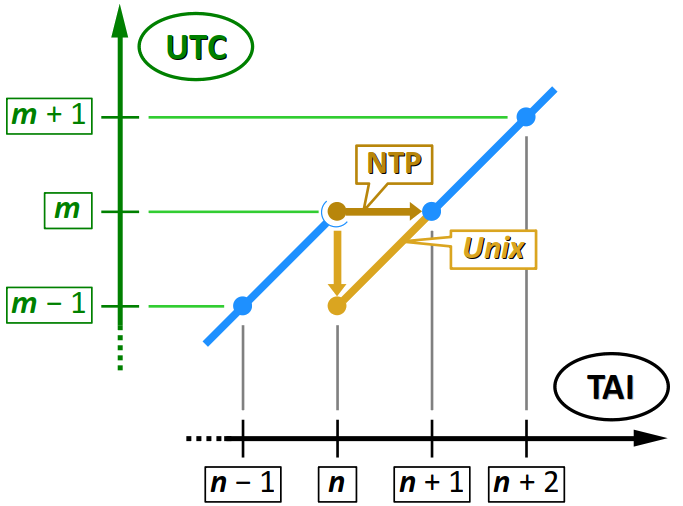
- En règle générale, la relation entre les deux échelles est une droite à 45°, puisque chaque incrémentation sur l'une opère également sur l'autre de façon synchrone.
- Mais lors de l'ajout d'une seconde intercalaire, un décalage vers la droite apparaît. Durant cette seconde, le timestamp NTP est figé.
Cas d'une seconde retranchée
La suppression d'une seconde intercalaire n'ayant jamais été effectuée depuis l'adoption du temps universel coordonné, il n'y a donc pas d'exemple réel sur lequel se baser comme on vient de le faire pour une seconde additionnelle. On peut toutefois raisonner avec des valeurs génériques de timestamp sur les échelles du TAI et de l'UTC au moment de la suppression, qu'on note respectivement n et m, comme sur la figure ci‑dessous.
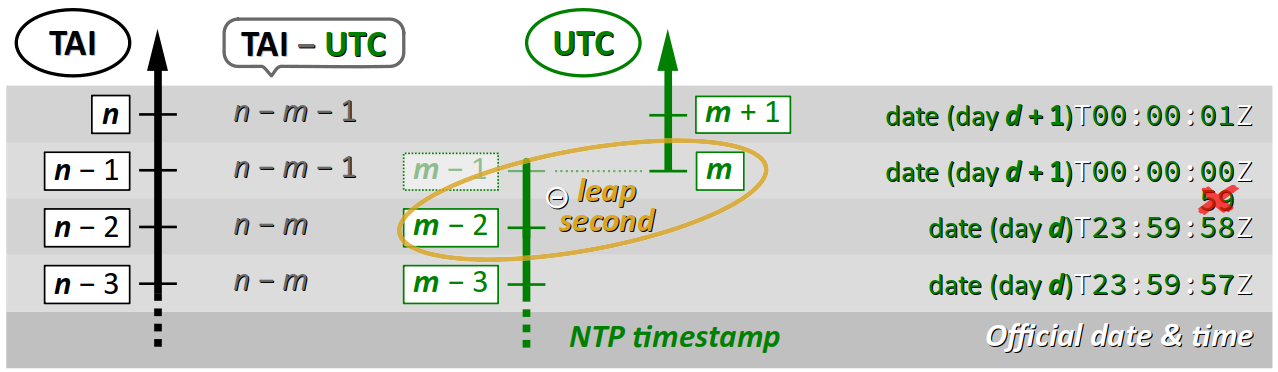
- Sur l'échelle du TAI, le timestamp est incrémenté normalement lors de la suppression de la seconde intercalaire, sans aucune irrégularité.
- En revanche, sur l'échelle de l'UTC, le timestamp NTP est incrémenté de deux unités à la fin de la seconde m − 2 et passe donc directement à la valeur m sans passer par m − 1.
Pour ne pas avoir une irrégularité d'échelle résultant de cette double incrémentation, il est nécessaire là aussi de distinguer deux échelles, avant et après la suppression de la seconde intercalaire.
Prise en compte des zones horaires et de l'heure d'été
La prise en compte des zones horaires et de l'heure d'été est indépendante de l'UTC, dont l'échelle n'est pas affectée en elle‑même par ces changements. Il s'agit simplement de décalages d'affichage pour définir la date et heure locale dans un lieu donné.
Dans le cas d'un système informatique, il peut être préférable régler l'horloge interne sur l'UTC et d'appliquer le décalage de la zone horaire uniquement pour les affichages.
Mais si, au contraire, l'horloge interne de la machine est directement réglée sur l'heure locale, alors il est impératif de conserver en mémoire la zone horaire et l'éventuel décalage du DST, sinon aucun horodatage ne peut ensuite être situé sur l'échelle de l'UTC.
Partage du temps universel coordonné
Généralités

Le partage de l'UTC sur un réseau – en particulier via l'Internet – peut s'effectuer par l'intermédiaire de divers protocoles applicatifs (c'est‑à‑dire appartenant à la couche n° 7 du modèle OSI). Le choix du protocole dépend des besoins en précision, mais aussi des contraintes de sécurité.
Développé au milieu des années 1980, le protocole NTP W (network time protocol) est de loin le plus utilisé pour le partage du temps. Sa dernière version – v4, basée sur la RFC 5905 publiée en 2010 – tend à se généraliser progressivement dans les systèmes d'exploitation des machines.

Initié par les travaux du Pr. David Mills W qui a accompli l'essentiel de sa carrière à l'Université du Delaware (USA), le protocole NTP est étonnamment complexe au regard de l'apparente simplicité de son objectif principal : partager le timestamp de la date et heure courante sur l'échelle de l'UTC.
Cette complexité s'explique par le fait :
- que la donnée partagée est constamment changeante ;
- que pour garantir une précision meilleure que la seconde, il faut tenir compte des délais de transmission sur le réseau, qui sont très contextuels selon le client, le serveur et la distance qui les sépare ; ces délais constituent un facteur d'erreur significatif ;
- qu'il existe par ailleurs de très nombreuses causes de déréglage des horloges (dérive, défaillance d'un composant, défaut d'alimentation…) ; en conséquence, la consultation d'une seule horloge ne garantit pas toujours une précision satisfaisante de la date et heure courante transmise.
Pour atteindre l'objectif de synchroniser les machines en réseau avec une précision de l'ordre de la milliseconde, le protocole NTP prévoit plusieurs modes d'association possibles entre machines pour le partage la date et heure courante de l'UTC.
- Le mode client‑serveur permet à toute machine en réseau (poste de travail, serveur, carte à microcontrôleurs, routeur, etc.) de se synchroniser individuellement à la date et heure courante de l'UTC.
- Le mode pair‑à‑pair permet à un pool de serveurs de temps de se synchroniser mutuellement pour garantir une meilleure précision de la date et heure courante qu'ils sont en mesure de partager
- un mode de diffusion qui permet à un serveur de temps de cadencer la synchronisation d'un ensemble de machines dans son réseau local – diffusion broadcast – ou dans une liste d'abonnement – diffusion multicast.
Comme la plupart des protocoles applicatifs de service, NTP n'est donc pas simplement basé sur des algorithmes d'émission‑réception de messages, il repose aussi sur une architecture matérielle spécifique dont la grande redondance permet de garantir une référence temporelle fiable.
Architecture des serveurs NTP
La mise en œuvre du protocole NTP s'appuie des arborescences descendantes de machines hiérarchisées en strates W. Dans une telle arborescence :
- la strate des racines – dite stratum 0 – est implémentée par des horloges atomiques ; ces dernières ne communiquent qu'avec la strate immédiatement inférieure, typiquement par liaison série ;
- la strate immédiatement inférieure – dite stratum 1 – constitue les serveurs primaires de temps ;
- la strate suivante – dite stratum 2 – constitue les serveurs secondaires de temps qui sont beaucoup plus nombreux (mais un peu moins précis) que les serveurs primaires ; etc.
Plus le numéro de stratum est petit, meilleure est la précision de la date et heure courante partagée.
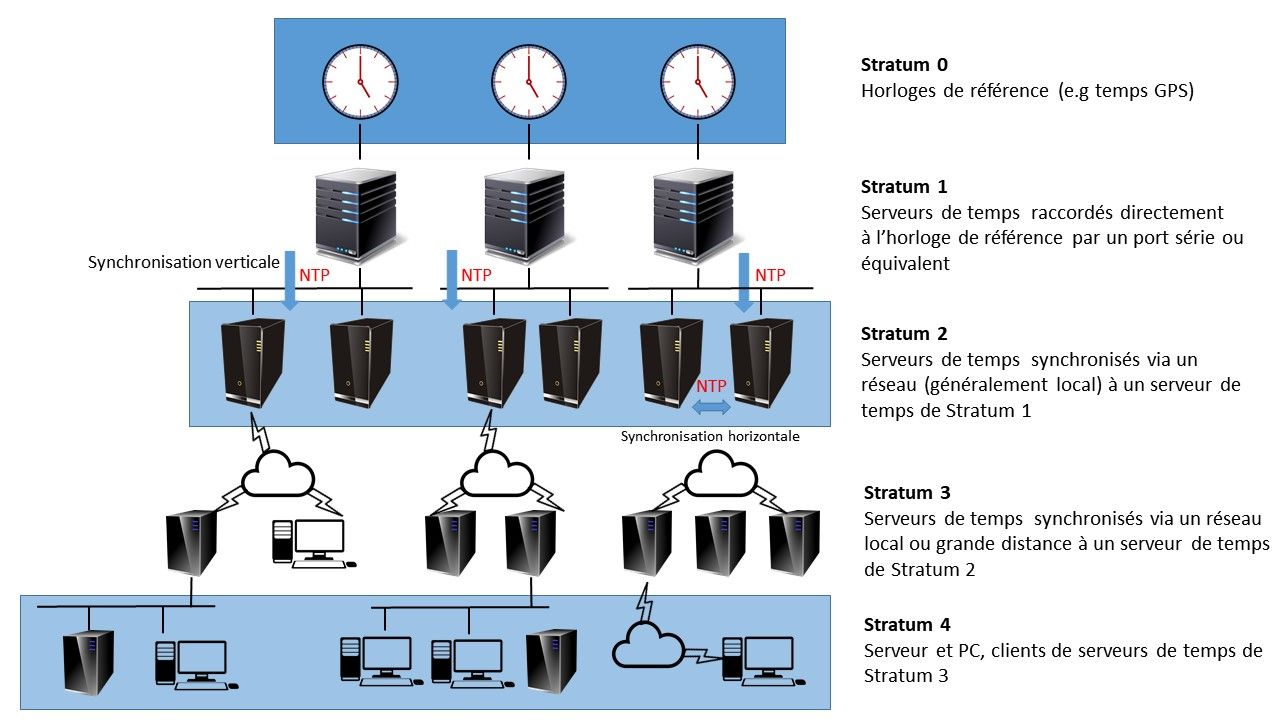
Dans une strate (à l'exception du stratum 0) :
- les machines obtiennent la date et heure courante en mode client‑serveur depuis la strate immédiatement supérieure ; ainsi, un serveur de temps agit régulièrement comme client NTP pour se synchroniser ; on parle de synchronisation verticale ;
- certains serveurs de temps peuvent agir en mode pair‑à‑pair pour affiner leur synchronisation ; on parle de synchronisation horizontale.
Différents cas de figures selon le réseau local
Dans un réseau local, sauf si l'on souhaite constituer un pool de serveurs de temps, il n'est pas nécessaire de mettre en place une arborescence NTP.
- Dans les cas les plus simples (collectivités, administrations, petites entreprises sans besoins spécifiques), il suffit simplement de paramétrer les systèmes d'exploitation des machines pour qu'ils se synchronisent régulièrement sur des serveurs de temps publics sur l'Internet.
- Dans des contextes qui requièrent une précision meilleure que la seconde et/ou avec une grande fiabilité, un ou plusieurs serveurs de temps dédiés, avec plusieurs sources de synchronisation redondantes (Internet, satellite, radio) sont nécessaires.
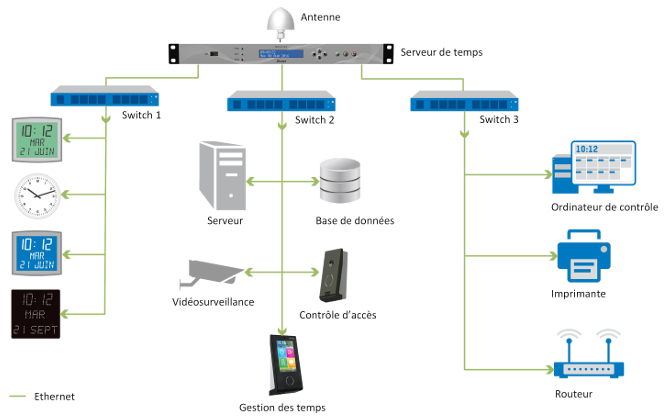
Machine dédiée serveur de temps

Une machine dédiée en serveur de temps W est une machine serveur (en général, de type rack) qui dispose :
- d'un circuit d'horloge interne très précis ;
- d'un ou plusieurs plusieurs moyens de synchronisation (liaison directe à une horloge atomique, antenne satellite, antenne radio) sur des références de temps classifiées stratum 0 ;
- d'une ou plusieurs interfaces réseau très rapides pour pouvoir partager sa date et heure courante avec de bonnes performances.
Très souvent, elle est aussi dotée d'une interface utilisateur avec un afficheur pour visualiser la date et l'heure courante.
De plus, elle doit exécuter en tâche de fond un composant logiciel qui met en œuvre un protocole de partage de temps en qualité de serveur, typiquement NTP.
Les serveurs de temps publics
Un grand nombre de serveurs de temps sont librement accessibles sur l'Internet. On en trouve une liste des noms de domaines assez fournie au lien suivant G.
Parmi ces noms de domaines, on peut notamment citer :
- ceux des grandes entreprises de l'Internet (Google, Facebook, Cloudflare, Facebook, Apple, Microsoft, etc.) ;
- ceux du gouvernement des États‑Unis – le National internet time service, abrégé NIST (sous tutelle de l'organisme gouvernemental homonyme, le National institute of standard and technology W) – dont le nom de domaine principal
time.nist.govdonne accès exclusivement à des serveurs de stratum 1 ; - ceux du NTP pool project donc le nom de domaines principal est
pool.ntp.org.
fr.pool.ntp.org
Aspects logiciels généraux du protocole NTP
Pour des raisons évidente de rapidité et de légèreté, le protocole NTP utilise le protocole de transport UDP (cf. chap. R1‑IV ) pour la transmission de ses messages.
Il exploite le port nº 123, tant pour l'émission que pour la réception des messages.

Le protocole NTP adopte un format de message unique, quel quel soit le mode d'association et quel que soit le rôle de la machine dans ce mode. Ce format est détaillé en figure ci‑contre de façon classique par un tableau d'une suite de mots de 4 octets (32 bits).
Un message NTP se divise en deux parties :
- un en‑tête de 48 octets, comprenant diverses informations administratives, suivies par 4 champs de 8 octets chacun (64 bits) pour y inscrire respectivement 4 timestamp (
ref,org,rec,xmt) ; - une partie optionnelle constituée potentiellement de deux champs d'extension, chacun de taille variable, et toujours suivis :
- d'une clef d'identification de 32 bits ;
- d'un message d'authentification de 128 bits dit MAC (pour message authentication code).
Codage des champs d'un message NTP
Détaillons maintenant le codage de chaque champ de l'en‑tête d'un message NTP en version 4.
-
LI, pour leap indicator, codé en binaire naturel sur 2 bits, avertit si une seconde intercalaire va intervenir à la fin du mois en cours, avec le détail des valeurs ci‑dessous : -
VN, pour version number, codé en binaire naturel sur 3 bits, précise le numéro de la version du protocole employée ; -
mode, codé en binaire naturel sur 3 bits, indique le mode d'association adopté par l'émetteur du message, avec le détail des principales valeurs ci‑dessous : -
stratum, codé en binaire naturel sur 8 bits, indique la strate du serveur émetteur du message (cf. supra ), sachant que : -
0signifie invalide, lorsque le serveur ne délivre pas le timestamp attendu (pour diverses raisons, cf. infra) ; -
16signifie que la machine est désynchronisée. -
poll(interval), codé en binaire naturel sur 8 bits, quantifie dans le cas d'un client ou d'un pair la période de synchronisation qu'il souhaite établir avec le serveur. Dans son message de réponse, le serveur va typiquement recopier la même valeur si elle est compatible avec son taux de charge ou éventuellement l'augmenter – à charge alors pour le client d'en tenir compte. -
precision, codé en complément à 2 sur 8 bits (car la valeur est typiquement négative), quantifie dans le cas d'un serveur ou d'un pair la précision de l'horloge interne de la machine exprimée en secondes mais codée en échelle logarithmique à base 2. -
root delayetroot dispersionsont codés l'un et l'autre sur 32 bits dans un format décimal à virgule fixe non signé ; ils sont dédiés à des mesures de durées de transmission déterminées durant le protocole d'échanges de messages entre un client et un serveur pour optimiser la valeur du timestamp à transmettre au client. -
reference id. / kiss of death, codé sur 32 bits, prend différentes formes selon la réponse apportée par le serveur à une requête : - En cas de refus ou échec (champ
stratumcodé0– cf. supra), il s'agit d'un message de débogage, appelé kiss of death codé sous la forme d'une chaîne de 4 caractères ASCII ; la liste des codes standardisés est consultables sur le site de l'IANA . - En cas de succès, de la part d'un serveur primaire (champ
stratumcodé1), il s'agit d'un message précisant l'horloge de référence à laquelle le serveur est relié, codée sous la forme d'une chaîne de 3 ou 4 caractères ASCII justifiée à gauche (l'octet n° 15 éventuellement non employé est mis à0) ; la liste des codes usuels est consultables sur le site de l'IANA ; - En cas de succès, de la part d'un serveur secondaire (champ
stratumcodé2ou plus), le champ contient le numéro de référence du serveur, exprimé en notation hexadécimale et établi automatiquement à partir de son adresse IP. - Les quatre timestamps sont à ne pas confondre :
-
refindique l'instant de la dernière synchronisation de la machine (client ou serveur) ; -
orgindique l'instant de l'émission (origine) du message de requête du client ; -
recindique l'instant de réception par le serveur du message de requête du client ; -
xmtindique l'instant d'émission de la réponse du serveur à la requête du client.
0 |
pas de seconde intercalaire |
|---|---|
1 |
seconde intercalaire ajoutée |
2 |
seconde intercalaire retranchée |
3 |
statut inconnu (horloge désynchronisée) |
3 pour le champ LI dans un message à destination d'un serveur, même si son horloge n'est pas particulièrement désynchronisée. 3 pour le champ LI est une information critique : elle signale que les valeurs de timestamp contenues dans le message ne sont pas fiables. 0 |
valeur réservée pour un usage ultérieur |
|---|---|
1 |
pair symétrique actif |
2 |
pair symétrique passif |
3 |
client |
4 |
serveur |
5 |
broadcast |
0 signifie aussi non spécifié et c'est la valeur codée par un simple client (n'étant pas un serveur, il n'a pas de stratum) ; 10 exprime une période de synchronisation de 210 = 1024 s. -18 exprime une précision de 2−18 ≃ 3,8 × 10−6 s (soit environ 4 µs). GAL désigne un satellite du système de positionnement européen Galileo W. reference id. est indifférent. dst). La donnée des cinq timestamps cités supra permet d'optimiser la valeur du timestamp à employer pour régler l'horloge du client, afin d'atteindre une précision de synchronisation meilleure que la seconde.
Signalons par ailleurs que dans un message NTP, la valeur 0 affectée à un timestamp ne correspond pas à la date epoch 0 (cf. supra ). Elle signifie que ce timestamp est indéterminé – ce qui est typiquement le cas lorsqu'un client n'est pas encore synchronisé.
Quant au codage de la partie optionnelle d'un message NTP, il ne sera pas abordé ici. On consultera les RFC 5905 , 7822 et 8573 pour s'en informer.
Décodage des valeurs de timestamp
Rappelons que la convention de gros boutisme W (en anglais, big endianness) systématiquement employée dans le format des paquets des protocoles des réseaux TCP/IP est l'inverse de celle adoptée pour l'encodage des données en programmation (notamment en langage C) – cf. chap. C3‑I C.
Par conséquent, lorsqu'on souhaite exploiter dans un programme la valeur d'un champ timestamp contenu dans un message NTP, il est nécessaire de réordonner ses octets dans l'ordre inverse de celui d'enregistrement dans le message.
Pour illustrer cette nécessité, on détaille des extraits de code en langage C++ des programmes fournis avec le sujet de TP R2‑4 où l'on met en œuvre un client NTP sur une carte Arduino équipée d'un shield Ethernet.
On analyse d'abord la méthode decodeTimestamp appartenant à la classe NTPpacket, dont le code source est placé dans le fichier d'implémentation NTPclient.cpp. Cette méthode sert à décoder la partie entière d'un timestamp codé dans un message NTP (ref, org, rec ou xtm – cf. supra ). Elle retourne une valeur de type uint32_t et possède :
- un argument implicite nommé
ntpMessagequi est un membre privé de la classeNTPpacket; c'est le tableau d'octets mémorisant le message NTP envoyé par le serveur de temps ; - un argument formel nommé
byteOffsetqui est le numéro du premier octet où est codé la partie entière du timestamp à décoder dans le message NTP envoyé par le serveur de temps.
uint32_t NTPpacket::decodeTimestamp(int8_t byteOffset)
{
uint32_t ntpTimestamp = 0;
for (int8_t byteRank = 0, bitShift = 24; byteRank <= 3; byteRank++, bitShift -= 8) {
ntpTimestamp |= (uint32_t(ntpMessage[byteOffset + byteRank])) << bitShift;
}
return ntpTimestamp;
}
Cette méthode utilise une boucle for (cf. les lignes nº 136 à 138) à deux variables d'itération :
-
byteRankqui exprime le rang d'octet (allant de0à3inclus) en cours de décodage ; -
bitShiftqui exprime le décalage de bits (allant de24à0) qu'il faut appliquer à l'octet en cours pour le placer correctement dans le formatuint32_t.
Elle accède successivement aux 4 octets encodant le timestamp – les éléments de tableau identifiés par l'expression ntpMessage[byteOffset + byteRank] – et effectue :
- la conversion de l'octet dans le type
uint32_t; - le décalage vers la gauche (
<<) des bits de l'octet de la valeur de la variable de bouclebitShiftrangs, laquelle est initialisée à24et décrémentée de8à chaque itération de la boucle ; ainsi : - les bits du 1er octet sont décalés de 24 rangs pour former le 4e octet (octet de poids fort) de la partie entière du timestamp ;
- les bits du 2e octet sont décalés de 24 - 8 = 16 rangs pour former le 4e octet de la partie entière du timestamp ;
- et ainsi de suite jusqu'au 4e octet qui forme l'octet de poids faible de la partie entière du timestamp ;
- la « concaténation » des bits de l'octet avec l'opérateur bit à bit à affectation combinée
|=dans la variable localentpTimestamppréalablement déclarée de typeuint32_t.
L'appel de la méthode decodeTimestamp intervient dans la méthode getUnixTimestamp pour décoder la partie entière du timestamp xmt à l'instant d'émission du message NTP par le serveur de temps :
uint32_t xmtTimestamp = decodeTimestamp(XMT_BYTE);
sachant que la constante XMT_BYTE vaut 40 (elle exprime le numéro du premier octet du timestamp xmt dans le message — cf. supra cf. supra ).
Quant au décodage de la partie factionnaire d'un timestamp, il est réalisé par la méthode decodeFracTimestamp qui possède les mêmes arguments que la fonction decodeTimestamp mais retourne une valeur de type float.
float NTPpacket::decodeFracTimestamp(int8_t byteOffset)
{
uint32_t ntpFracTimestamp = 0;
for (int8_t byteRank = 0, bitShift = 24; byteRank <= 3; byteRank++, bitShift -= 8) {
ntpFracTimestamp |= (uint32_t(ntpMessage[byteOffset + byteRank])) << bitShift;
}
float frac = 0.0;
for (int8_t bitRank = 31; bitRank >= 0; bitRank--) {
frac += ((ntpFracTimestamp >> bitRank) & 0b1) * pow(2, bitRank - 32);
}
return frac;
}
Elle procède en deux étapes :
- D'abord à l'aide d'une boucle
forà deux variables d'itération, (cf. les lignes nº 148 à 150), elle effectue l'inversion de l'ordre des 4 octets encodant la partie fractionnaire du timestamp dans le message NTP pour former sur 32 bits un significande intermédiaire binaire. - Puis (cf. les lignes nº 151 à 154) elle effectue la conversion de ce significande en une somme de puissances fractionnaires de 2 dans une variable locale
fracde typefloat. Dans une bouclefor, en procédant bit par bit dans l'ordre décroissant des rangs (c'est‑à‑dire de31à0), elle opère : - le décalage vers la droite (
>>) jusqu'au rang zéro et le masquage de tous les autres bits (& 0b1), ce qui isole la valeur du bit (0ou1) ; - la multiplication de cette valeur binaire par la puissance fractionnaire de 2, c'est‑à‑dire avec l'exposant négatif
bitRank - 32(donc allant de-1à-32) ; - l'ajout de cette valeur fractionnaire à la variable
frac.
decodeTimestamp exposé supra. L'appel de la méthode decodeFracTimestamp intervient dans la méthode getUnixTimestamp pour décoder la partie fractionnaire du timestamp xmt à l'instant d'émission du message NTP par le serveur de temps :
float xmtFrac = decodeFracTimestamp(XMT_BYTE + 4);
sachant que l'expression XMT_BYTE + 4 (soit 40 + 4) cible l'octet nº 44 dans le message NTP, là où commence la partie fractionnaire du timestamp xmt.
Protocole d'échange de messages NTP
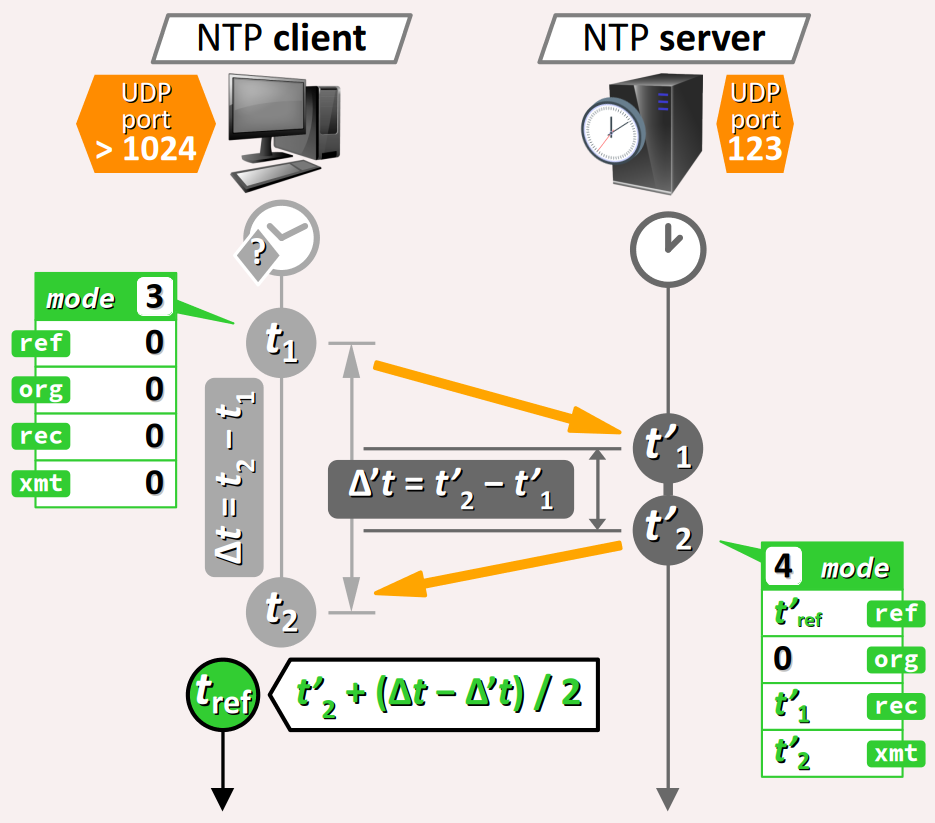
Dans le cas d'un mode d'association client‑serveur, le déroulement du protocole NTP se réduit à l'échange de deux messages : une requête du client (message de mode 3) suivie d'une réponse du serveur (message de mode 4). Avec un algorithme de traitement suffisamment bien pensé, en exploitant :
- les timestamp
ref,recetxmttransmis dans le message de réponse d'une part, - et la connaissance des instants d'émission t1 de la requête et de réception t2 de la réponse d'autre part,
le client doit être en mesure de se synchroniser sur l'échelle de l'UTC avec un écart de précision inférieur à ±0,2 s – ces écarts étant dus aux incertitudes de temps de transmission entre le client et le serveur.
Lors d'une première synchronisation, le client ne dispose a priori d'aucune référence temporelle calendaire. En conséquence, tous les timestamp de son message de requête sont mis à zéro.
Lors de la réception de la réponse du serveur, le client doit effectuer les traitements suivants pour se synchroniser à la date et heure courante de l'UTC.
- Il doit utiliser son temps processeur pour chronométrer précisément la durée Δt = t2 − t1 entre :
- l'instant t1 d'envoi du message de requête ;
- l'instant t2 de réception du message de réponse.
- Il doit calculer la durée Δt' = t'2 − t'1 entre :
- l'instant t'1 de réception par le serveur du message de requête, codé dans le timestamp
rec(received) ; - l'instant t'2 d'envoi par le serveur du message de réponse, codé dans le timestamp
xmt(emitted)
En faisant l'hypothèse que les temps de transmission aller et retour entre le client et le serveur sont égaux, le client peut alors immédiatement synchroniser son horloge avec ce qui constituera son nouveau timestamp de référence :
tref = t'2 + (Δt − Δt') / 2
- Dans la pratique, la durée Δt' = t'2 − t'1 que met le serveur à traiter la réponse d'un client est inférieure à 100 µs. Elle est négligeable en comparaison de la durée Δt, laquelle est de l'ordre de 100 ms voire plus de 1 s en Wi‑Fi. Si l'on se contente d'une précision de synchronisation de l'ordre de 0,1 s, alors on peut poser t'1 = t'2 = t' et ainsi réduire la formule de calcul du timestamp de référence à tref = t' + Δt / 2.
- En revanche, la partie fractionnaire f du timestamp
xmtne doit pas être négligée. En effet, c'est a priori une valeur aléatoire dans l'intervalle [0 ; 1 s[ qui peut donc aller jusqu'à 0,999… s. Une solution pour le client consiste à différer le réglage de la synchronisation du complément à la seconde suivante, en synchronisant son horloge à la valeur entière immédiatement supérieure à tref.
Toujours dans le cadre du sujet de TP R2‑4 où l'on met en œuvre un client NTP sur une carte Arduino équipée d'un shield Ethernet, voici comment est codée la synchronisation au serveur NTP :
- Dans le fichier principal
megaNTPclient_elv.ino, au début de la fonctionloopest codé un appel de la méthodesynchronizeBoardIfNeededAndPossibleassociée à l'objet globalntpPacket.
ntpPacket.synchronizeBoardIfNeededAndPossible();
NTPclient.cpp), on trouve un appel de la méthode getValidTimestamp (dans le même fichier). La valeur 0LU (0 imposé dans le type unsigned long) passée pour son argument orgTimestamp code ici le fait que la carte n'est pas encore synchronisée.
if (getValidTimestamp(0LU)) { // first synchro => origin timestamp = 0
isSynchroPossible = true;
}
getValidTimestamp :
bool NTPpacket::getMessage(uint32_t orgTimestamp)
{
millisAtSending = millis();
sendMessage(orgTimestamp);
bool fail = true;
while (fail) {
fail = !udp.parsePacket();
if (millis() >= millisAtSending + NTP_CONNECTION_TIME_OUT) break;
}
if (!fail) {
millisAtReceived = millis();
led.switchOff();
udp.read(ntpMessage, NTP_HEADER_SIZE); // copy the packet header into buffer
#ifdef NTP_SERIAL_DEBUG
Serial.println("\t NTP message received from the server");
Serial.flush();
#endif
}
return !fail;
}
- envoie d'un message de requête au serveurNTP avec mémorisation de l'instant d'émission t1 d'envoi grâce au temps processeur de la carte (lignes nº 64 & 65) ;
- mémorisation de l'instant t2 de réception du message de réponse du serveurNTP.
synchronizeBoardIfNeededAndPossible à ligne nº 274 par la méthode setTime issue du module Time de la bibliothèque Arduino.
if (isSynchroNeeded) {
if (isSynchroPossible) {
time_t newTimestamp = setUnixTimestamp();
time_t oldTimestamp = now(); // memo for polling interval optimization
setTime(newTimestamp); // NTP synchronization
setTime, il est calculé par la méthode setUnixTimestamp codée dans le fichier d'implémentation NTPclient.cpp. C'est ici que se joue toute la subtilité de la synchronisation pour pouvoir réduire l'erreur à moins de 0,2 s :
time_t NTPpacket::setUnixTimestamp()
{
uint32_t xmtTimestamp = decodeTimestamp(XMT_BYTE);
float xmtFrac = decodeFracTimestamp(XMT_BYTE + 4);
uint32_t addedMillis = (millisAtReceived - millisAtSending) / 2
+ (xmtFrac * ONE_THOUSAND);
#ifdef NTP_SERIAL_DEBUG
Serial.println("Protocol delay: " + String(addedMillis) + " ms");
#endif
delay(ONE_THOUSAND - (addedMillis % ONE_THOUSAND)); // synchronization delay
return xmtTimestamp + 1 + (addedMillis / ONE_THOUSAND) - UNIX_EPOCH; // +1 for synchro
}
xmt transmis par le serveur NTP : - À la ligne nº 164, on calcule dans la variable
addedMillis, exprimé en millisecondes, le délai supposé de transmission du timestamp par la formule Δt / 2 (cf. supra ), délai auquel on ajoute les millisecondes correspondant à la partie fractionnaire du timestampxmt– le but étant de se synchroniser sur une valeur ronde de l'échelle de UTC (donc, au tout début d'une seconde). - À la ligne nº 171, on fait donc une pause de synchronisation de la fraction de seconde complémentaire pour atteindre la fin d'une seconde sur l'échelle de UTC. En millisecondes, c'est donc la différence entre
1000et le reste de la division euclidienne deaddedMillispar1000. - La valeur retournée par la fonction (ligne nº 172) :
La tz database
La tz databate W – aussi dite zoneinfo – est une base de données collaborative multi‑format qui collectionne toutes les informations historiques sur la gestion du temps calendaire dans tous les pays du globe.

Focalisée prioritairement sur la période récente écoulée depuis le 1er janvier 1970 (Unix Epoch), elle réunit également beaucoup d'informations plus anciennes.
Gestion informatique du temps et manipulation des données calendaires
Manipulations sous Linux
Accès aux paramètres de date et heure courante – réglages temporels du système
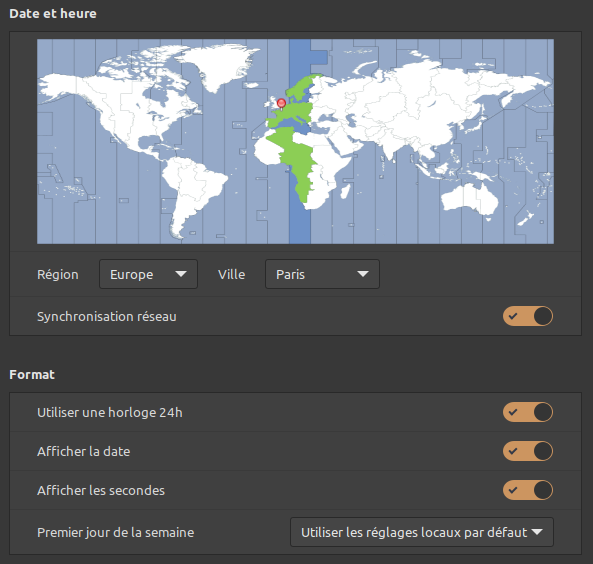
Si le système d'exploitation de la machine est dotée d'un bureau, l'affichage de la date et heure courante est prévu par défaut – typiquement, dans un coin du tableau de bord (barre de tâche). En cliquant sur cette zone, on accède à des réglages élémentaires via une fenêtre graphique, comme on peut le voir sur la capture d'écran ci‑contre pour le système Linux Mint / Cinnamon. Il est ainsi possible :
- de choisir la zone horaire, en sélectionnant la région continentale du globe et la capitale régionale de la zone ;
- d'activer/désactiver la synchronisation réseau ;
- ou si la synchronisation réseau est désactivée, de régler la date et heure à une valeur choisie ;
- de paramétrer quelques aspects du format d'affichage de la date et heure.
Toutefois, il n'est pas possible de paramétrer le choix du serveur de temps ou la fréquence de synchronisation.
Sur une machine Linux, la date et heure courante est mise en œuvre par un processus système paramétré par quelques fichiers de configuration ainsi qu'un ensemble de fichiers binaires définissant les règles de décalage dans les différentes zones horaires.
Avec les droits d'administration, il est possible de paramétrer ce processus via diverses commandes, ainsi qu'en modifiant les fichiers de configuration.
La commande date permet notamment :
- sans option ni argument, d'afficher la date et heure courante dans la zone horaire du système ;
- avec l'option
-uou--utc, d'afficher la date et heure courante de l'UTC (sans aucun décalage) ; - avec l'option
-sou--setsuivi d'un argument de la forme"mm/dd/yyyy hh:mm:ss", de régler la date et heure courante à la valeur ainsi codée.
systemd W comme Linux Mint). Sur les distributions de Linux mettant en œuvre le daemon systemd – Linux Mint, par exemple – la commande timedatectl permet notamment :
- sans option ni argument, d'afficher les informations essentielle sur la date et heure courante et les réglages du système ; par exemple, on peut typiquement obtenir une sortie comme :
timedatectlLocal time: dim. 2023-01-22 00:36:31 CET Universal time: sam. 2023-01-21 23:36:31 UTC RTC time: sam. 2023-01-21 23:36:31 Time zone: Europe/Paris (CET, +0100) System clock synchronized: yes TP service: active RTC in local TZ: no
set-time suivie d'un argument de la forme "yyyy-mm-dd hh:mm:ss", de régler la date et heure courante à la valeur ainsi codée. set-timezone suivie d'un argument de la forme "region/place", de régler la zone horaire ainsi codée ; set-ntp suivie d'un argument booléen (1 ou 0), de respectivement activer/désactiver la synchronisation du système avec un serveur de temps ; timesync-status sans argument, d'afficher les informations essentielles sur la synchronisation du système avec un serveur de temps ; par exemple, on peut typiquement obtenir une sortie comme : timedatectl timesync-statusServer: 2620:2d:4000:1::41 (ntp.ubuntu.com) Poll interval: 34min 8s (min: 32s; max 34min 8s) Leap: normal Version: 4 ratum: 2 Reference: A71C1419 Precision: 1us (-25) Root distance: 1.174ms (max: 5s) Offset: +358us Delay: 25.992ms Jitter: 20.304558s Packet count: 19 Frequency: -11,348ppm
Le fichier de configuration /etc/systemd/timesyncd.conf code la configuration par défaut effectuée par compilation. Dans l'exemple ci‑dessous, certaines lignes ont été décommentées pour être prises en compte.
NTP=fr.pool.ntp.org FallbackNTP=ntp.ubuntu.com time.nist.gov #RootDistanceMaxSec=5 PollIntervalMinSec=64 PollIntervalMaxSec=4096
Pour que les modification à ce fichier soient effectives, il faut redémarrer le service systemd-timesyncd.
sudo systemctl restart systemd-timesyncdtimedatectl timesync-statusServer: 162.159.200.1 (fr.pool.ntp.org) Poll interval: 2min 8s (min: 1min 4s; max 1h 8min 16s) Leap: normal Version: 4 Stratum: 3 Reference: A1A0804 Precision: 1us (-25) Root distance: 11.772ms (max: 5s) Offset: +803us Delay: 19.890ms Jitter: 0 Packet count: 1 Frequency: -11,563ppm
Manipulations en langages C/C++
La bibliothèque standard du langage C comprend le fichier d'en‑tête time.h C (ctime en C++). Par le biais de multiples inclusions, ce dernier déclare divers types et fonctions pour pouvoir effectuer toutes les manipulations usuelles :
- non seulement sur le temps calendaire – avec la gestion des zones horaires et du DST ;
- mais aussi sur le temps processeur, avec si nécessaire une très haute résolution.
Certaines implémentations – notamment GCC – fournissent des extensions POSIX de ce module, avec certaines fonctions très puissantes, à condition de définir préalablement par une directive #define certaines pseudo‑constantes comme _XOPEN_SOURCE ou _POSIX_C_SOURCE.
Par ailleurs, pour gérer le temps calendaire avec une précision meilleure que la seconde, il est nécessaire de faire appel à des types et des fonctions déclarées dans le fichier d'en‑tête sys/time.h C.
Enfin, pour qu'un programme opère sur les réglages des paramètres de temps du système d'exploitation de la machine (Linux), il est nécessaire de faire appel à des types et des fonctions déclarées dans le fichier d'en‑tête sys/timex.h C. (Il faut également que son processus d'exécution possède les droits requis.)
Toutes ces fonctionnalités sont complexes et il n'est pas envisageable de les traiter en exhaustivité dans ce chapitre. Seuls quelques rudiments et exemples académiques sont donnés ci‑après. Pour plus de détails, on pourra se reporter à cet article .
Principaux types du temps calendaire
Le fichier d'en‑tête time.h déclare principalement deux types de mémorisation du temps calendaire :
-
time_test un type scalaire, laissé à la liberté d'implémentation, pour déclarer toute donnée représentant un timestamp Unix. -
tmest un type structuré –struct, cf. chap. C5‑V C – pour déclarer toute donnée représentant une date et heure définie par ses composantes calendaires (année, mois, jour, heure, etc.). En anglais, cette structure est appelée broken‑down time.
time_t peut usuellement être saisie ou affichée en entrées‑sorties formatées directement avec la spécification de conversion %ld. int décrits dans le tableau ci‑dessous : struct, on accède aux différents champs d'une donnée de type tm avec l'opérateur de sélection . (cf. chap. C2‑VI C). tm, le compilateur ne procède à aucune vérification si la valeur se situe hors de ses valeurs nominales. Il revient donc au codeur de prendre cette précaution, soit en procédant par arithmétique cyclique et en tenant compte des répercussions sur les autres champs, soit en appelant la fonction mktime (cf. infra) qui automatise de tels traitements. Chacun de ces deux types a ses usages privilégiés :
- Le type
time_test incontournable pour mémoriser une date et heure UTC à partir de celle du système (à l'aide de la fonctiontime– cf. infra) ou de la partie entière du timestamp NTP transmis par un serveur de temps. - Le type
tmest incontournable pour mémoriser toute date et heure calendaire particulière. Il suffit juste d'adapter la valeur de chaque champ compte‑tenu de son intervalle de valeurs nominales. - Déterminer dans le type
time_tla valeur du timestamp Unix d'une date et heure calendaire serait beaucoup moins commode : il faudrait calculer le nombre de seconde séparant cette date du 1er janvier 1970. - On va voir infra que le type
tmest également commode pour déterminer une date à partir d'une autre avec un décalage d'une durée exprimée dans n'importe quelle unité – notamment les mois et années, ce qui n'est pas commode avec le typetime_t.
Si ntpNow est une variable de type uint32_t mémorisant la partie entière du timestamp NTP transmis par un serveur de temps, on peut déclarer une variable mémorisant le timestamp Unix correspondant par le code ci‑dessous :
const uint32_t unixEpoch = 2208988800; time_t unixNow = ntpNow - unixEpoch;
time_t peut aussi être utilisé pour effectuer des calculs de durée entre deux dates directement par soustraction, ou pour déterminer une date et heure à partir d'une autre avec un décalage – par addition ou soustraction – d'une durée exprimée en secondes ou d'autres unités à nombre de secondes fixe : la minute (60 s), l'heure (3600 s), le jour (86400 s) mais pas le mois ni l'année. Pour déterminer une date et heure D2 fixée 100 jours après une date et heure D1 définie par son timestamp Unix t1, il suffit de calculer le timestamp Unix t2 par une instruction comme :
t2 = t1 + 86400 * 100
On peut mémoriser la date et heure de signature de l'Armistice de la première guerre mondiale – le 11 novembre 1918 à 5 h 15 W – dans la variable armistice par le code suivant :
struct tm armistice = {
.tm_sec = 0,
.tm_min = 15,
.tm_hour = 5,
.tm_mday = 11,
.tm_mon = 10, // november (0 = January)
.tm_year = 18 // 1918
};
sachant qu'il n'est pas indispensable de coder les valeurs pour les autres champs – ils peuvent être automatiquement calculés grâce à la fonction mktime (cf. infra).
Principales fonctions de manipulation du temps calendaire
Les fonctions déclarées dans le fichier d'en‑tête time.h sont, pour la plupart, des fonctions de conversion entre différents formats de représentation d'une date et heure. Elles ont la particularité d'opérer sur des arguments de type pointeur, donc avec un passage par adresse.
Les fonctions qui sont présentées ci‑après sont les plus usuelles. On donne leur prototype précédé d'un commentaire qui explique la signification de leur nom.
-
// current time time_t time(time_t * arg);
La fonctiontimeC retourne la valeur du timestamp Unix correspondant à la date et heure courante fournie lors de l'exécution par le système d'exploitation de la machine cible sur laquelle le programme s'exécute, dans la zone horaire UTC+0. -
// GMT time struct tm * gmtime(const time_t * timer);
La fonctiongmtimeC effectue la conversion du timestamp Unix passé par l'argumenttimer(un pointeur sur donnée de typetime_t) en une valeur structurée de typetm, retournée via un pointeur sur une variable préalablement déclarée de ce type. Elle opère sans décalage de zone horaire, c'est‑à‑dire en restant dans la zone horaire UTC+0 (anciennement GMT). - le champ
tm_monne vaut pas1mais0(la numérotation des mois commence à l'indice0) ; - le champ
tm_yearne vaut pas2023mais123(nombre d'années écoulées depuis 1900) ; - le champ
tm_wdayvaut5car le premier jour de la semaine est le dimanche, numéroté0; - le champ
tm_isdstvaut0car en janvier, l'heure d'été n'est pas bien évidemment pas active. -
// local time (in the timezone defined by the locale) struct tm * localtime(const time_t * timer);
La fonctionlocaltimeC effectue la même conversion que la fonctiongmtime, mais en opérant un décalage dans la zone horaire définie dans l'environnement d'exécution du programme – par défaut, celle du système d'exploitation. -
// make time time_t mktime(struct tm * arg);
La fonctionmktimeC effectue la conversion inverse de celle opérée par les fonctionsgmtimeetlocaltime. À partir d'une date et heure locale encodée dans une variable de type structurétm, pointée par son argumentarg, elle retourne une valeur de timestamp Unix. Elle tient compte de l'éventuel décalage de zone horaire et du paramètre DST définis dans l'environnement d'exécution du programme (par défaut, les réglages du système). - d'abord en pointant sur la variable structurée
tmThenLocalqui mémorise la date et heure locale correspondant au timestamp Unix1674216400(20 janvier 2023, 12:06:40 UTC) ; - puis en pointant sur la variable structurée
tmThenqui mémorise la date et heure UTC correspondant au même timestamp Unix. - a, dans le premier cas, été correctement restituée, puisque issue d'une heure locale (la valeur de
tmThenLocal) ; - a, dans le deuxième cas, été diminuée de
3600, soit la valeur du décalage horaire de la zone, puisque issue d'une heure UTC (la valeur detmThen). -
// string from time size_t strftime(char * str, size_t count, const char * format, const struct tm * arg);
La fonctionstrftimeC est une fonction complexe de transcription : - dans une chaîne de caractères – l'argument
str, - conformément aux spécifications de transcription d'une chaîne de format – l'argument
format, - et dans la limite d'un nombre d'octets – l'argument
count, - de la date et heure mémorisée dans l'argument
argqui est un pointeur sur type structurétm. -
"%FT%T%z"code un format conforme à la norme ISO 8601 (remarque : le séparateurTest inséré entre les spécifications%Fet%T) ; -
"%c"code un format abrégé d'usage courant dans le monde anglo‑saxon (la zone horaire n'étant pas précisée) ; -
"%A, %B %d, %Y, %R %Z"code un format long sur mesure, là encore usuel dans le monde anglo‑saxon. -
// string parsed time char * strptime(char * str, const char * format, struct tm * arg);
La fonctionstrptimeC est une fonction complexe de transcription inverse de celle opérée par la fonctionstrftime. Elle effectue l'analyse (parsing) : - d'une chaîne de caractère formatée exprimant un ou plusieurs éléments de date et heure – l'argument
str, - avec un format codé avec des spécifications de transcription une chaîne de format – l'argument
format, - À la ligne nº 7, on commence par déclarer une chaîne de caractère nommée
stringTheninitialisée avec la date et heure du 20 janvier 2023, 12:06:40 UTC, composée dans le format de la norme ISO 8601. - À la ligne nº 8, on déclare une variable structurée nommée
tmThende typetm, dont tous les champs sont initialisée à0. - À la ligne nº 10, on appelle la fonction
strptimeavec pour deuxième argument effectif la chaîne de format"%FT%T%z". - Les lignes nº 12 à 17 permettent d'afficher les valeurs de tous les champs de la variable
tmThen.
arg peut être le pointeur NULL (c'est le cas usuel), sinon un pointeur sur une variable déclarée de type time_t qui prend alors la valeur retournée par la fonction (par déréférencement, cf. chap. C5‑I ). (time_t) (-1), c'est‑à‑dire -1 si le type time_t est implémenté signé, sinon la valeur maximale encodable dans ce type (par rebouclage cyclique). Le programme ci‑dessous code la déclaration d'une variable systNow de type time_t et son initialisation par appel de la fonction time pour lui donner la valeur du timestamp Unix de la date et heure courante de l' UTC du système.
#include <stdio.h>
#include <time.h>
int main(void)
{
time_t systNow = time(NULL);
printf("Unix timestamp now: %ld\n", systNow);
return 0;
}
Exécuté sur OnlineGDB le 20 janvier 2023 à 12:06:40 UTC, ce programme a produit l'affichage :
Unix timestamp now: 1674216400
Remarque. On aurait pu aussi coder la ligne nº 6 par :
time_t systNow = 0; time(&systNow);
Le programme ci‑dessous code la déclaration d'une variable structurée tmThen de type tm et son initialisation par appel de la fonction gmtime avec pour argument effectif l'adresse de la variable then, un timestamp Unix dont la valeur correspond à la date et heure calendaire du vendredi 20 janvier 2023, 12:06:40 UTC (cf. l'exemple précédent supra ).
Les instructions suivantes (lignes nº 8 à 13) codent l'affichage des différents champs de la variable tmThen pour vérification.
#include <stdio.h>
#include <time.h>
int main(void)
{
time_t then = 1674216400; // i.e. Jan. 20th 2023, 12:06:40 UTC+0
struct tm tmThen = *gmtime(&then);
printf("tm_hour: %2d \t tm_min: %2d \t tm_sec: %3d\n",
tmThen.tm_hour, tmThen.tm_min, tmThen.tm_sec);
printf("tm_mday: %2d \t tm_mon: %2d \t tm_year: %3d\n",
tmThen.tm_mday, tmThen.tm_mon, tmThen.tm_year);
printf("tm_wday: %2d \t tm_yday: %2d \t tm_isdst: %3d\n",
tmThen.tm_wday, tmThen.tm_yday, tmThen.tm_isdst);
return 0;
}
Exécuté sur OnlineGDB, ce programme produit en sortie standard l'affichage suivant :
tm_hour: 12 tm_min: 6 tm_sec: 40 tm_mday: 20 tm_mon: 0 tm_year: 123 tm_wday: 5 tm_yday: 19 tm_isdst: 0
Et conformément aux propriétés du type tm (cf. supra ), on observe que :
En prolongement des exemples précédents, le programme ci‑dessous initialise la variable structurée tmNowLocal de type tm avec un appel de la fonction localtime. Elle lui affecte la date et heure définie par le timestamp Unix then (20 janvier 2023, 12:06:40 UTC) mais décalée dans la zone horaire du système et en tenant compte de la valeur du paramètre DST (dayligth saving time).
#include <stdio.h>
#include <time.h>
int main(void)
{
time_t then = 1674216400; // i.e. Jan. 20th 2023, 12:06:40 UTC+0
struct tm tmThenLocal = *localtime(&then);
printf("tm_hour: %2d \t tm_min: %2d \t tm_sec: %3d\n",
tmThenLocal.tm_hour, tmThenLocal.tm_min, tmThenLocal.tm_sec);
return 0;
}
Compilé et exécuté sur un poste de travail en France métropolitaine – zone horaire CET, soit UTC+1 – il produit en sortie standard l'affichage suivant :
tm_hour: 13 tm_min: 6 tm_sec: 40
où l'on voit que le champ tm_hour de la variable tmThenLocal a pris la valeur 13 conformément au décalage horaire de +01:00 par rapport à l'UTC.
En prolongement des exemples précédents, le programme ci‑dessous code deux affectations successives à la variable then de type time_t par appel de la fonction mktime :
#include <stdio.h>
#include <time.h>
int main(void)
{
time_t then = 1674216400; // i.e. Jan. 20th 2023, 12:06:40 UTC+0
struct tm tmThenLocal = *localtime(&then);
struct tm tmThen = *gmtime(&then);
then = mktime(&tmThenLocal);
printf("then: %lu\n", then);
then = mktime(&tmThen);
printf("then: %lu\n", then);
return 0;
}
Compilé et exécuté sur un poste de travail sous Linux situé en France métropolitaine – zone horaire CET, soit UTC+1 – il produit en sortie standard l'affichage suivant :
then: 1674216400 then: 1674212800
où l'on observe que la valeur originale du timestamp then :
Il apparaît donc clairement qu'à l'exécution, une date et heure mémorisée dans une variable structurée de type tm est toujours considérée comme locale par la fonction mktime pour déterminer le timestamp correspondant. En effet, le type tm ne comporte aucun champ de zone horaire. Seul le paramètre DST est mémorisé.
tm_wday et tm_yday sont ignorés pour le calcul de la valeur de retour de la fonction mktime. Cette dernière se base uniquement sur les composantes calendaires qui définissent une date et heure de façon usuelle, c'est‑à‑dire avec l'année, le mois, le jour, les heures, les minutes et les secondes. str. format présentent des similitudes avec les spécifications de conversion des fonctions printf et scanf du module de bibliothèque stdio du langage C (cf. chap. C2‑VII C). Mais au delà du recours à la syntaxe %caractère‑code, ce ne sont pas les mêmes spécifications, tout simplement parce qu'elles ciblent des valeurs numériques de types temporels (heures, minutes, secondes, etc.). On peut consulter ces spécifications sur cette page web de référence C. Reprenons l'exemple précédent qui a servi à illustrer la fonction gmtime (cf. supra ) avec la date et heure calendaire du vendredi 20 janvier 2023, 12:06:40 UTC mémorisée dans la variable tmThen de type structuré tm. C'est ce qu'on retrouve aux lignes nº 6 & 7 du programme ci‑dessous.
À la ligne nº 8, on déclare une variable de type chaîne de caractère pour pouvoir mémoriser l'effet de la fonction strftime. On appelle alors cette dernière successivement 3 fois pour illustrer diverses spécifications de transcription parmi toutes celles possibles.
#include <stdio.h>
#include <time.h>
int main(void)
{
time_t then = 1674216400; // i.e. Jan. 20th 2023, 12:06:40 UTC+0
struct tm tmThen = *gmtime(&then);
char stringThen[50] = "";
strftime(stringThen, sizeof stringThen, "%FT%T%z", &tmThen);
printf("%s\n", stringThen);
strftime(stringThen, sizeof stringThen, "%c", &tmThen);
printf("%s\n", stringThen);
strftime(stringThen, sizeof stringThen, "%A, %B %d, %Y, %R %Z", &tmThen);
printf("%s\n", stringThen);
return 0;
}
Compilé et exécuté sur un poste de travail sous Linux situé en France métropolitaine, ce programme produit en sortie standard l'affichage suivant :
2023-01-20T12:06:40+0000 Fri Jan 20 12:06:40 2023 Friday, January 20, 2023, 12:06 GMT
où l'on peut observer l'effet des différentes chaînes de format :
Il est également possible d'obtenir un formatage conforme à la langue locale en codant le programme modifié comme ci‑dessous :
#include <stdio.h>
#include <time.h>
#include <locale.h>
int main(void)
{
setlocale(LC_TIME, "fr_FR.utf-8");
time_t then = 1674216400; // i.e. Jan. 20th 2023, 12:06:40 UTC+0
struct tm tmThen = *gmtime(&then);
char stringThen[50] = "";
strftime(stringThen, sizeof stringThen, "%FT%T%z", &tmThen); // unchanged
printf("%s\n", stringThen);
strftime(stringThen, sizeof stringThen, "%c", &tmThen); // unchanged
printf("%s\n", stringThen);
// format string changed below
strftime(stringThen, sizeof stringThen, "%A %d %B %Y, %R %Z", &tmThen);
printf("%s\n", stringThen);
return 0;
}
L'affichage devient alors conforme aux usages en France :
2023-01-20T12:06:40+0000 ven. 20 janv. 2023 12:06:40 vendredi 20 janvier 2023, 12:06 GMT
Remarque. En ligne nº 7, l'appel de la fonction setlocale affecte au paramètre régional LC_TIME la valeur "fr_FR.utf-8" dans l'environnement d'exécution du programme (par défaut, ce paramètre prend la valeur "C" comme tous les autres paramètres régionaux – cf. chap. C3‑VIII , quels que soient les valeurs des paramètres du système). Ce changement ne produit aucun décalage d'heure pour tenir compte de la zone horaire du système mais cela modifie seulement le format d'affichage.
tm accédée par pointeur – l'argument arg. strftime. strptime n'est pas incluse dans la bibliothèque standard du langage C mais elle fait partie des outils complémentaires GNU. Pour l'utiliser, il est nécessaire de coder au début du programme la direction : #define _GNU_SOURCE
Pour donner un emploi typique de la fonction strptime, reprenons l'exemple précédent en sens inverse.
#define _GNU_SOURCE
#include <stdio.h>
#include <time.h>
int main(void)
{
char stringThen[] = "2023-01-20T12:06:40+0000";
struct tm tmThen = {0};
strptime(stringThen, "%FT%T%z", &tmThen);
printf("tm_hour: %2d \t tm_min: %2d \t tm_sec: %3d\n",
tmThen.tm_hour, tmThen.tm_min, tmThen.tm_sec);
printf("tm_mday: %2d \t tm_mon: %2d \t tm_year: %3d\n",
tmThen.tm_mday, tmThen.tm_mon, tmThen.tm_year);
printf("tm_wday: %2d \t tm_yday: %2d \t tm_isdst: %3d\n",
tmThen.tm_wday, tmThen.tm_yday, tmThen.tm_isdst);
return 0;
}
Sans surprise, on obtient en sortie standard l'affichage attendu suivant:
tm_hour: 12 tm_min: 6 tm_sec: 40 tm_mday: 20 tm_mon: 0 tm_year: 123 tm_wday: 5 tm_yday: 19 tm_isdst: 0
Manipulations dans l'environnement Arduino
Sur une carte à microcontrôleur, la mise en œuvre du temps calendaire est plus complexe que sur un poste de travail. En effet, on ne peut pas s'appuyer sur les fonctionnalités du système d'exploitation puisqu'il n'y en a pas. On ne peut pas non plus recourir à des interfaces graphiques pour effectuer des paramétrages : tout doit être codé par le biais des API des modules de bibliothèque qui, heureusement, existent dans ce domaine.
Le module Time
Dans l'environnement Arduino, les modules time et ctime des bibliothèques standards des langages C/C++ sont difficilement utilisables (en particulier sur les cartes à cœur AVR – Uno, Nano, Mega, etc.). En effet, en l'absence de système d'exploitation pour entretenir un temps calendaire, il faut en implémenter un à l'aide de la fonction millis – cf. chap. C2‑IX C.
Justement, le module Time A de la bibliothèque Arduino (fichier d'en‑tête TimeLib.h) implémente un temps calendaire, c'est‑à‑dire une horloge temps‑réel qui s'incrémente en tâche de fond.
De plus, ce module met à la disposition du codeur des types et quelques fonctions similaires à ceux et celles qui sont déclaré(e)s dans le fichier d'en‑tête time.h du langage C, mais avec des fonctionnalités plus réduites.
Dans le module Time, on trouve essentiellement deux types :
- le type scalaire
time_t(synonyme deunsigned long– 32 bits quel que soit le modèle de carte Arduino) ; - une partie entière de timestamp NTP ;
- les valeurs positives de timestamp Unix ;
- le type structuré
tmElements_t, similaire au typetmdu C/C++ mais avec seulement 7 champs – le paramètres DST n'étant malheureusement pas inclus.
On trouve également de nombreuses fonctions :
- La fonction
nowretourne la valeur de la date et heure courante mémorisée sous la forme d'un timestamp Unix. - Les fonctions
hour,minute,second,day,weekday,monthetyear, retournent respectivement l'heure, les minutes, les secondes, le jour du mois, le jour de la semaine, le mois et l'année correspondant à un timestamp Unix passé en argument. - La fonction
setTimerègle la date et heure courante de la carte à partir de la valeur d'un timestamp Unix passé comme argument.
now) qui est considéré. Autrement dit, un appel comme hour() donne la valeur de l'heure courante. Le paramètre DST n'est pas pris en charge dans le module Time mais il existe d'autres modules de bibliothèque qui permettent de gérer cet aspect, notamment Timezone, décrit ci‑dessous.
Le module Timezone
Le module Timezone A de la bibliothèque Arduino implémente la gestion automatique du décalage horaire avec prise en compte du DST dans une zone horaire déterminée.
Il utilise les éléments de code du module Time (types, fonctions), dont il complète les fonctionnalités.
Pour mettre en œuvre le module Timezone dans un programme, il est tout d'abord nécessaire de déclarer deux variables globales (ou deux variables locales mais statiques) de type structuré TimeChangeRule. Ces deux variables définissent respectivement le passage de l'heure d'hiver à l'heure d'été et vice‑versa. L'une et l'autre sont à initialiser par une liste qui comprend dans l'ordre :
- l'appellation de la zone horaire après changement (une chaîne de 5 caractères maximum, par exemple WET, CET, etc.) ;
- le moment du changement, défini par :
- la semaine dans le mois (l'une des constantes énumérées
First,Second,Third,Fourth,Last) ; - le mois (l'une des constantes énumérées
Jan,Feb, etc.) ; - l'heure (un nombre entier, par exemple
2) ; - le décalage horaire par rapport à l'UTC exprimé en minutes (un nombre entier signé, par exemple
+60pour le décalage UTC+1).
On peut coder les règles de changement d'heure en France métropolitaine (cf. supra ) sans la fonction setup :
static TimeChangeRule localDST = {"CEST", Last, Sun, Mar, 2, +120};
static TimeChangeRule localSTD = {"CET", Last, Sun, Oct, 3, +60};
Ensuite, on doit déclarer une objet global de la classe Timezone via son constructeur, en passant comme argument les valeurs des deux variables de changement d'heure préalablement déclarées. On peut alors disposer des méthodes toLocal et toUTC de cette classe pour obtenir :
- le timestamp déterminant la date et heure locale dans la zone horaire prenant en compte l'éventuelle heure d'été à partir du timestamp correspondant de l'UTC ;
- et vice‑versa.
Ce timestamp est utilisable comme n'importe quel autre pour régler l'heure sur la carte Arduino à l'aide de la fonction setTime du module Time (cf. supra ).
En prolongation de l'exemple précédent, en faisant l'hypothèse qu'on dispose d'une variable nommé utc mémorisant le timestamp courant sur l'échelle de l'UTC, pour déterminer le timestamp local dans la zone horaire définie par les règles localDST et localSTD, il suffit de coder :
static Timezone localTZ(localDST, localSTD); time_t localTimestamp = localTZ.toLocal(utc);
Les modules de client NTP
On trouve plusieurs modules de bibliothèque Arduino qui mettent en œuvre un client NTP pour synchroniser à l'UTC une carte Arduino ou compatible.
Parmi ces modules, NTPClient est répertorié comme officiel A car :
- il est facile à utiliser ;
- il est opérationnel avec tous les modèles de cartes.
Cependant, il ne décode pas la partie fractionnaire du timestamp transmis par le serveur NTP et ne prend pas en compte le délai de transmission. Par conséquent, on obtient une synchronisation imprécise avec une erreur qui peut être supérieure à un seconde (ce qui reste néanmoins suffisant pour toutes sortes d'applications).
Parmi les autres modules qui mettent en œuvre un client NTP, on peut également citer ezTime G. De conception bien plus complexe, il est intéressant car :
- il reste facile à utiliser avec son interface de programmation soignée et sa documentation détaillée ;
- il offre une synchronisation précise avec la prise en compte de la partie fractionnaire du timestamp transmis par le serveur de temps et du délai de transmission ;
- il forme un tout‑en‑un en prenant en charge les fonctions usuelles des modules de bibliothèque
TimeetTimezone.
Par ailleurs, le sujet de TP R2‑4 fourni à l'exercice 2 un programme d'application incluant un client NTP à la fois simple et précis, dont une partie du code a été détaillée supra .