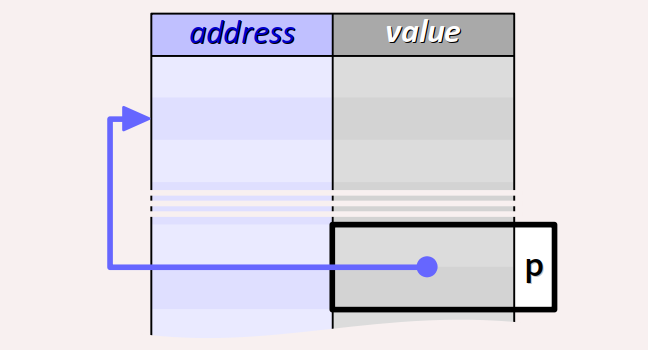
Un pointeur W est une donnée dont la valeur est une adresse dans le segment de la mémoire vive attribué au programme lors de son exécution sur la machine cible.
C'est une notion fondamentale en programmation, spécifique aux langages compilés. Rappelons que dans le code exécutable d'un programme compilé, plus aucun identificateur n'est employé : les données et les fonctions sont accédées uniquement via leurs adresses respectives (cf. chap. C4‑IV ).
La notion de pointeur permet de coder facilement dans le programme source des opérations de bas niveau en allant manipuler directement la mémoire, mais aussi des opérations haut niveau sur des données structurées et les fonctions. Apparue assez tôt dans l'histoire de la programmation (Algol68, Pascal…), c'est avec le langage C que les pointeurs acquièrent toute leur puissance. En effet, on y trouve :
- des éléments de langage les plus simples possibles qui optimisent la concision des expressions manipulant les pointeurs et les adresses – l'opérateur de déréférencement
*et l'opérateur d'adresse&sont codés chacun par un seul symbole ; - l'implémentation d'une arithmétique spécifique aux pointeurs, qui permet de passer d'une donnée à la suivante par une simple incrémentation, sans devoir préciser la taille en mémoire des données – ce qui est très utile dans une structure de donnée homogène comme un tableau, une chaîne de caractère, un fichier.


Mais cette puissance a une contre‑partie. L'emploi des pointeurs présente des risques en termes de sécurité du code : si un programme peut accéder et modifier très facilement à une zone de la mémoire, le moindre débordement a toutes les « chances » d'engendrer à l'exécution une erreur de segmentation W, qui sera très difficile à prévenir lors de la compilation.
C'est pourquoi le développement du langage C++ a notamment eu pour objectif de réduire l'emploi des pointeurs et, pour cela, a introduit la notion de référence (cf. chap. C4‑I ), qui permet :
- d'accéder à la valeur d'une donnée (comme avec l'opérateur de déréférencement sur un pointeur) ;
- mais pas à son adresse (comme avec l'opérateur d'adresse).
Les différences entre les notions de référence et de pointeur sont subtiles. En C++, plutôt que de les percevoir comme concurrentes, il est plus pertinent de les considérer comme complémentaires pour coder dans les programmes des fonctionnalités optimisées en termes de simplicité de codage, de vitesse d'exécution et de sécurité de fonctionnement.
Ce premier chapitre de la partie C5 du module a pour objectif d'introduire ces notions et d'en expliciter tous les aspects fondamentaux. On abordera donc les points suivants :
- la notion d'adresse d'une donnée et les opérateurs d'adresse et de déréférencement qui permettent respectivement de passer d'une donnée à son adresse et réciproquement ;
- la déclaration d'une donnée – constante ou variable – de type pointeur ;
- l'arithmétique des pointeurs et les opérations que l'on peut leur appliquer (affectations, incrémentations, décrémentations, comparaisons, conversions, etc.) ;
- la notion de référence (en C++ uniquement), sa syntaxe de déclaration, ses possibilités de manipulation des données, etc.
Tous ces aspects devront être bien assimilés pour pouvoir en étudier les nombreuses applications dans les chapitres suivants, consacrés respectivement aux applications directes des pointeurs et aux données structurées – tableaux, structures hétérogènes, etc.
Notions préliminaires
Notion d'adresse d'une donnée
Rappels et précisions sur la mémoire vive

On rappelle (cf. chap. C3‑I ) que la mémoire vive (RAM) d'un ordinateur peut être virtuellement représentée comme un immense tableau d'octets pour stocker des données ou des codes d'instructions (cf. la figure ci‑contre pour une architecture 64 bits avec des adresses codées sur 48 bits, c'est-à-dire 6 octets, soit des numéros composés de 12 digit hexadécimaux).
Dans ce tableau, chaque octet est repéré par un numéro d'ordre – qu'on appelle son adresse – et qui est établi à partir d'une adresse « zéro ». Il est d'usage d'exprimer les adresses en base 16 pour faciliter leur lecture. On emploie souvent le préfixe 0x ou 0X pour signaler cet aspect, comme en codage.
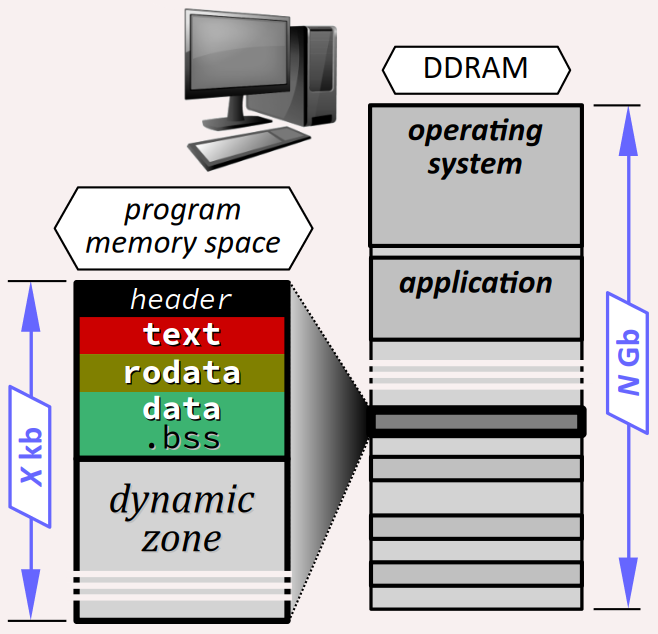
On rappelle également que tout programme s'exécutant sur un ordinateur se voit allouer un espace dans la RAM par une instance du chargeur de programme (un composant du système d'exploitation de la machine – cf. chap. C4-IV ). En effet, de nombreux programmes s'exécutent en parallèle les uns des autres et se partage la RAM.
Virtuellement, cet espace peut être conçu comme formant un bloc continu d'adresses qu'on peut éventuellement afficher lors de l'exécution du programme. Mais en pratique, l'emplacement réel des données est géré par le contrôleur de mémoire W, un circuit intégré spécialisé qui est typiquement localisé sur le northbridge W de la carte mère de la machine.
Par ailleurs, on rappelle (cf. chap. C4‑II ) que cet espace se divise en deux zones, dites statique et dynamique, elles‑mêmes subdivisées :
- en segments
text,rodataetdatapour la zone statique ; - en un tas (heap) et une pile (stack) pour la zone dynamique.
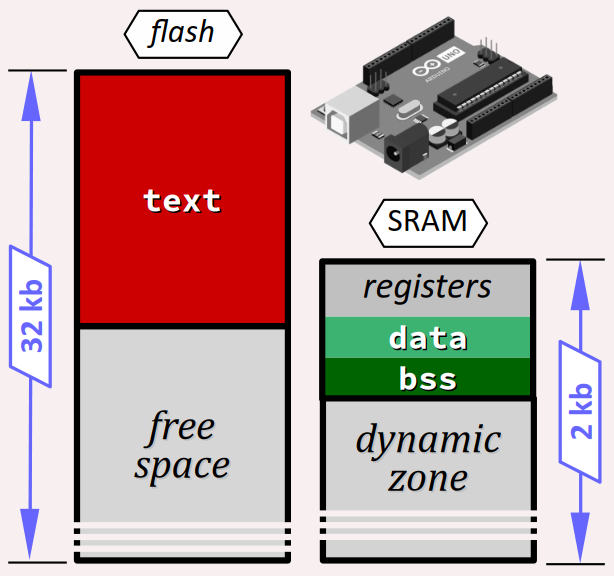
Dans le cas d'un programme s'exécutant carte à microcontrôleur, c'est la quasi‑totalité de la SRAM qui est allouée au programme lors de son téléversement, puisque le microcontrôleur ne peut exécuter qu'un seul programme utilisateur à la fois.
Toute adresse d'une donnée indique son emplacement réel – et non pas virtuel. Il n'y a pas de contrôleur de mémoire, sachant que cette dernière est intégrée dans le microcontrôleur.
Par ailleurs, ce segment est réparti un peu différemment que sur un ordinateur (cf. chap. C4‑II ).
- Le segment
textqui regroupe le code machine des fonctions et les constantesPROGMEMest écrit dans une mémoire non volatile (flash) qui possède son propre espace d'adressage – par exemple, de0x0000à0x7FFFsur le microcontrôleur Atmel 328P d'une carte Arduino Uno. - Les autres segments de la zone statique –
dataetbss– ainsi que toute la zone dynamique sont eux placés dans la SRAM. - En général, une plage basse de la SRAM est réservée pour le fonctionnement du microcontrôleur, en particulier pour stocker ses registres. Par exemple, sur le microcontrôleur Atmel 328P, cette plage va de
0x00à0xFF– autrement dit, la première adresse attribuable à une donnée commence à0x100. - Le microcontrôleur ou la carte peut éventuellement embarquer une mémoire EEPROM qui possède, là encore, son propre espace d'adressage.
- Sur un ordinateur et/ou avec un compilateur à architecture 32 bits, l'adresse la plus haute est
0xFFFFFFFF(4 octets, soit 8 digits hexadécimaux). Elle correspond au numéro d'ordre 4 294 967 295 – autrement dit, la mémoire virtuelle est forcément limitée à un volume de 4,3 Go maximum. - Sur une carte Arduino Uno, l'adresse la plus haute de la mémoire SRAM est
0x08FF(2303 en décimal), puisque son microcontrôleur ne dispose que de 2 ko (plus exactement, 2048 octets) pour les données, auxquelles s'ajoutent 256 octets de registres. Les adresses sont donc exprimées sur 2 octets seulement, soit 4 digits hexadécimaux.
Adresse d'une donnée
On rappelle (cf. chap. C2‑III ) qu'en programmation, une donnée est un « objet » dont on connaît a priori trois caractéristiques :
- son identificateur, qui est choisi par le codeur dans le code source ;
- son type, également choisie dont une caractéristique essentielle est la taille, c'est‑à‑dire le nombre d'octets nécessaires pour stocker la valeur de la donnée en mémoire ;
- sa valeur qui peut éventuellement varier au gré des affectations codées, et qui est encodée en mémoire dans les octets alloués (c'est la seule caractéristique de la donnée qui soit susceptible de changer au cours de l'exécution du programme).
Ces trois caractéristiques peuvent donc être explicitement codées dans la déclaration de la donnée.

Il existe une 4e caractéristique fondamentale d'une donnée qui est son adresse : c'est l'adresse du 1e octet (dans l'ordre des adresses) qui est alloué pour stocker la valeur de la donnée en mémoire.
En langage C, la valeur d'une adresse peut être affichée en sortie standard à l'aide de la spécification de conversion %p (cf. chap. C2‑VII ) et moyennant une conversion dans le type pointeur générique void * (cf. chap. C5‑II ).
Contrairement à ses autres caractéristiques, l'adresse d'une données n'est pas explicitement codable dans sa déclaration. Elle est attribuée non pas par le codeur mais par la machine.
Plus précisément, l'attribution de l'adresse d'une donnée par la machine dépend de sa classe d'allocation en mémoire (cf. chap. C4‑II ). Cette attribution est effectuée :
- soit par la chaîne de compilation lors de la construction de la section
.dataou.rodatadu fichier exécutable sur la machine cible, s'il s'agit d'une donnée de classe statique ; - soit par le processeur de la machine cible lors de l'exécution du programme :
- dans la pile s'il s'agit d'une donnée de classe automatique ;
- ou dans le tas, s'il s'agit d'une donnée déclarée par allocation dynamique.
Ordre d'adressage et contraintes d'alignement
Dans chaque segment de la mémoire allouée au programme, l'attribution des adresses aux données est typiquement effectuée au fur et à mesure de leur déclaration dans un ordre croissant ou décroissant selon la convention de boutisme adoptée par la chaîne de compilation et la machine cible (cf. chap. C3‑I ). Par exemple :
- dans l'environnement de simulation en ligne Tinkercad, l'attribution des adresses procède par ordre croissant ;
- dans l'environnement Arduino IDE l'attribution des adresses procède par ordre décroissant.

De plus, les adresses des données de taille supérieure ou égale à 2 octets répondent à des contraintes d'alignement (cf. chap. C3‑I ) en fonction de l'architecture de la machine cible : en règle générale, l'adresse attribuée est toujours un multiple de la taille de la donnée et pour pour respecter cette contrainte d'alignement, la chaîne de compilation laisse éventuellement des octets inexploités entre des données.
Considérons le programme académique suivant s'exécutant dans un terminal, qui affiche successivement les valeurs hexadécimales des adresses des variables a, b et c dans cet ordre (cf. la ligne nº 9).
#include <stdio.h>
int a = 2047;
short b = 5;
int c = -10;
int main(void)
{
printf("a: %p\nb: %p\nc: %p\n", (void *) &a, (void *) &b, (void *) &c);
return 0;
}
Exécuté sur OnlineGDB, ce programme produit typiquement une sortie comme :
a: 0x555f381b8010 b: 0x555f381b8014 c: 0x555f381b8018
En faisant abstraction des 10 digits de haut rang qui sont toujours identiques (0x555f381b80), on peut faire les observations suivantes.
- Les 3 adresses sont bien des multiples de 4 (on rappelle que
0x10vaut 16 en base 10). Cela est attendu puisque les données déclarées sont de typeintqui, sur un ordinateur, est encodé sur 4 octets. - La variable
bétant de typeshort, elle est stockée sur seulement 2 octets, autrement dit aux adresses0x14et0x15.
c est à l'adresse 0x18. Donc les octets d'adresse 0x16 et 0x17 sont inexploités en respect de la contrainte d'alignement qui impose un espacement de 4 octets minimum entre deux données consécutives. Remarque. Si ce programme était codé pour une carte Arduino, les valeurs d'adresse obtenues seraient beaucoup plus petites, car la mémoire vive (SRAM) intégrée au microcontrôleur est très réduite (cf. chap. C1‑III ).
De plus, avec l'architecture AVR 8 bits d'une carte Uno, on n'aurait pas de contraintes d'alignement ; autrement dit, l'adresse de la variable c serait seulement à 2 octets de celle de b (et non pas à 4 octets comme ci‑dessus).
L'opérateur d'adresse &

Dans une code source, pour désigner l'adresse d'une donnée, les langages C et C++ fournissent l'opérateur d'adresse (en anglais, address‑of operator), appelé aussi opérateur de référencement, dont le symbole est & (caractère « esperluette », en anglais ampersand W).
C'est un opérateur unaire qui, dans le tableau de classification des opérateurs du langage C, a le rang 2 de priorité (cf. chap. C2‑IV ). Comme la plupart des opérateurs unaires, son sens d'associativité est de droite à gauche.
L'opérateur d'adresse ne s'applique pas à n'importe quelle expression, mais seulement à une l‑value (cf. chap. C2‑IV ), typiquement un identificateur de donnée déclarée. En effet, d'une manière générale, dans un code source, une expression est destinée à être évaluée dans un registre de calcul du processeur, mais pas à être stockée durablement dans la RAM, donc elle n'a pas d'adresse.
En conséquence, lorsque l'opérateur & s'applique à un simple identificateur, il est a priori inutile d'encapsuler ce dernier dans des parenthèses, par exemple comme &(a).
Par ailleurs, les expressions &a et & a sont syntaxiquement équivalentes en vertu du format libre des langages C et C++ ; néanmoins, la première forme est usuellement préférée.
Enfin, l'expression &a n'est elle‑même pas une l‑value. En effet, le codeur ne peut pas changer l'adresse d'une donnée, que cette dernière soit locale ou globale.
Dans un programme académique, après une déclaration de variable globale comme :
int a = 2047;
l'expression &a prend pour valeur l'adresse de la variable a qui a attribuée par la machine lors du chargement du programme en mémoire (et pas par le codeur avant la compilation). La valeur 0x555f381b8010 affichée lors de l'exécution de l'exemple supra n'est qu'une possibilité parmi tant d'autres .
Cas de l'environnement Arduino
Remarque préliminaire. Dans l'environnement Arduino, on peut aussi faire afficher l'adresse d'une donnée. Toutefois, la valeur de l'expression &a n'est pas directement affichable par une instruction de la forme :
Serial.println(&a, HEX); // type error!
car &a n'est pas de type entier comme attendu par la méthode println, mais d'un type dérivé qu'on pourrait qualifier approximativement de « pointeur d'entier » (type qu'on va étudier à la section suivante).
En revanche, si on impose à l'expression &a une conversion explicite (un cast, cf. chap. C3‑VII ) vers le type int, il devient possible d'afficher sa valeur par la méthode println.

Considérons le programme académique pour une carte Arduino Uno (ou sa simulation dans Tinkercad) :
int a = 2047;
void setup()
{
Serial.begin(115200);
Serial.print("a: ");
Serial.println(int(&a), HEX); // OK
}
void loop() {}
Il affiche dans le moniteur série :
a: 100
où 100 est la valeur hexadécimale (256 en décimal) de l'adresse de la variable a (c'est l'adresse la plus basse possible qui puisse être attribuée à une donnée, comme on l'a vu supra ).

- Comme sur toute autre machine, cette adresse correspond au numéro hexadécimal du premier octet – ici, l'octet de poids faible (cf. chap. C3‑I ) – sur lequel la valeur de la variable
aest encodée. - Et comme la variable
aest de typeintqui est ici encodé sur deux octets (cf. chap. C3‑II ), l'adresse0x101contient l'octet de poids fort0000 0111de sa valeur2047(en effet, 2047 = 2048 − 1 = 211 − 1 et s'écrit111 1111 1111en binaire).
data. On verra par la suite que l'adresse immédiatement consécutive à &a, qui vaut ici 0x102 (et non pas 0x102), est codable par l'expression &a + 1.
Remarques.
- Si la variable
aavait été déclarée localement dans la fonctionsetup, elle se serait vu attribuer l'adresse0x8F6(2294 en décimal). Cette adresse est située à l'extrémité haute de la zone dynamique alloué au programme, dans le cadre (frame) réservé pour l'exécution de la fonctionsetupdans la pile ; - Si la variable
aétait locale mais déclarée de classe statique (cf. chap. C4‑II ), alors elle obtiendrait l'adresse0x100comme si elle était globale.
L'opérateur de déréférencement *
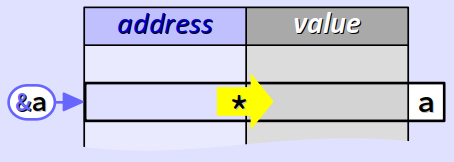
Dans une code source, pour désigner la valeur contenue dans la mémoire à une adresse d'une donnée, les langages C et C++ fournissent l'opérateur de déréférencement W (en anglais, dereference operator), appelé aussi opérateur d'indirection, dont le symbole est *.
Il est donc réciproque de l'opérateur d'adresse et, comme ce dernier, il est unaire, possède le rang 2 de priorité (cf. chap. C2‑IV ) et le sens d'associativité de droite à gauche.
L'opérateur de déréférencement ne s'applique pas à n'importe quelle expression, mais seulement à celles dont la valeur est une adresse, typiquement des pointeurs (cf. infra ).
En conséquence, lorsque l'opérateur de déréférencement s'applique à un simple identificateur, il est inutile d'encapsuler ce dernier dans des parenthèses, par exemple comme *(p).
Par ailleurs, les expressions *p et * p sont syntaxiquement équivalentes, en vertu du format libre des langages C et C++. Néanmoins, la première forme est usuellement préférée.
Reprenons l'exemple académique supra de la variable déclarée par l'instruction :
int a = 2047;
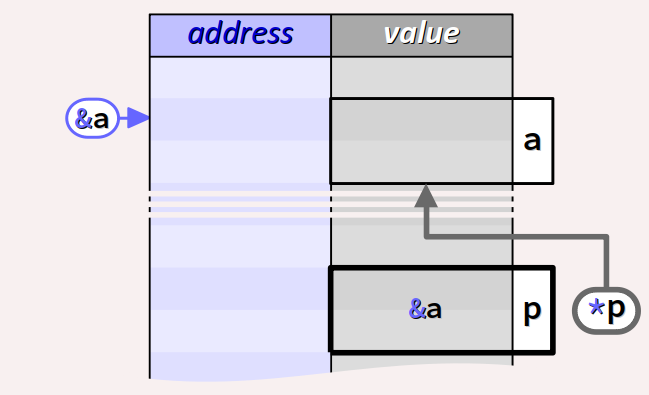
Pour mémoire, l'expression &a prend pour valeur l'adresse de a, donc l'expression *(&a) – qui se code tout simplement *&a – prend la valeur courante encodée à cette adresse, c'est‑à‑dire la valeur de la variable a, ici 2047.
Remarque. Cet exemple peut sembler « tourner en rond » mais il constitue le seul moyen d'illustrer l'opérateur de déréférencement sans recourir explicitement à la notion de pointeur, qui va être abordée par la suite.
Plus généralement, sachant que les opérateurs * et & sont réciproques, on peut considérer que :
- les expressions
*&aetasont équivalentes ; - les expressions
&*petpsont équivalentes.
Pour approfondir, soulignons que l'opérateur de déréférencement ne s'applique pas à n'importe quelle valeur d'adresse : encore faut‑il déjà que cette dernière correspondent à celle d'un identificateur déclaré.
En effet, reprenons l'exemple supra qui a permis d'illustrer l'opérateur d'adresse dans l'environnement Arduino :

- l'adresse
0x0101ne correspond pas à – on dit ne pointe pas sur – une donnée déclarée ; l'expression*0x0101n'aurait donc aucun sens ; - et de toute façon, même l'expression
*0x0100ne peut pas être employée dans un code source puisque, rappelons‑le, l'adresse0x0101est attribuée seulement lors de la compilation (si la donnée est de classe statique) ou de l'exécution (si la donnée est de classe automatique).
En conclusion, l'opérateur de déréférencement ne peut a priori s'appliquer qu'à une expression qui pointe sur une donnée déclarée, c'est‑à‑dire un pointeur…
Les pointeurs – déclaration et caractéristiques
La simplicité de la définition générale donnée en introduction (« un pointeur est une donnée dont la valeur est une adresse ») ne doit pas tromper. La notion de pointeur en langages C et C++ est pleine de subtilités, à l'image de la syntaxe pour la mettre en œuvre. Pour en maîtriser l'usage, il est indispensable de comprendre et connaître tous les aspects détaillés ci‑après.
Déclaration générale d'un pointeur de donnée
Quel que soit le type de donnée considéré – élémentaire ou dérivé – on peut déclarer une donnée de type pointeur de donnée de ce type via la syntaxe suivante :
descripteur de type * identificateur [=
expression;
où optionnellement, comme pour toute donnée, on peut coder l'affectation d'une valeur initiale.
Précisons cette syntaxe.
- Le descripteur de type spécifie le type de données sur lesquelles le pointeur déclaré est destiné à pointer.
- L'identificateur désigne le pointeur ainsi déclaré. C'est une nouvelle donnée dans le programme, avec toutes les caractéristiques d'une donnée (type, identificateur, valeur, adresse).
- Le symbole
*n'est pas l'opérateur de déréférencement . C'est un symbole déclaratif qui permet de composer toutes sortes de descripteurs de types de pointeurs. - L'expression (facultative) affecte une valeur initiale au pointeur déclaré. Elle doit nécessairement prendre une valeur d'adresse :
- soit l'adresse d'une donnée « ordinaire » (pas un pointeur) via l'opérateur d'adresse
&, - soit la valeur d'un autre pointeur de donnée (éventuellement incrémenté ou décrémenté).
const. À la suite d'une déclaration de cette forme, l'expression *identificateur formée avec l'opérateur de déréférencement est une l‑value (cf. chap. C2‑IV ).
Considérons les deux déclarations académiques suivantes :
int number = 5; int * pointer = &number;
La ligne nº 6 est la déclaration d'une variable nommée pointer (le symbole * n'est pas inclus dans cet identificateur) telle que :
- le type de cette variable est « pointeur d'entier standard » – son descripteur est
int *(et là, le symbole*est bien inclus dans le descripteur) ; - la valeur initiale de cette variable est l'adresse de la variable
number.
À la suite de cette déclaration, tant que la variable pointer n'aura pas fait l'objet d'une autre affectation, l'expression *pointer (composée avec l'opérateur de déréférencement) prendra la valeur courante de la variable number (c'est‑à‑dire 5 pour le moment) et suivra les affectations ultérieures dont number pourrait faire l'objet. Ainsi, en codant plus loin :
number = 0;
printf("%d\n", *pointer);
on obtient lors de l'exécution l'affichage 0 (et non pas 5).
De plus, l'expression *pointer est une l‑value, donc si par exemple on code ensuite :
*pointer = 3;
printf("%d\n", number);
on obtient lors de l'exécution l'affichage 3 (et non pas 0) car la valeur de variable number a été modifiée par l'intermédiaire de pointer. Autrement dit, tant qu'aucune affectation ne vient changer la valeur initiale de pointer (c'est‑à‑dire l'adresse sur laquelle il pointe), l'expression *pointer permet d'accéder aux valeurs de la variable number, aussi bien en lecture qu'en écriture. Grossièrement, on peut donc dire qu'elle en constitue un alias – du moins temporairement…
Car si par la suite on code :
int otherNumber = 10;
pointer = &otherNumber;
printf("%d\n", *pointer);
alors on obtient lors de l'exécution l'affichage 10 (et non pas 3). En effet, l'expression *pointer suit maintenant la valeur de la variable otherNumber et non plus celle de number. La valeur du pointeur pointer a changé !
De même, on peut changer la valeur d'un pointeur, c'est‑à dire l'adresse de la donnée qu'il pointe, en lui affectant celle d'un autre pointeur déjà déclaré, par exemple :
int * otherPointer = &number; pointer = otherPointer;
de sorte que maintenant, le pointeur de donnée pointer pointe à nouveau sur la variable number.
En conclusion, on voit qu'un pointeur de donnée déclaré n'est pas définitivement l'alias de la donnée sur laquelle il pointe lors de son éventuelle initialisation. C'est donc un outil très polyvalent et on verra qu'il est particulièrement commode pour accéder aux différents champs d'une donnée structurée (tableau, chaîne de caractère, etc.).
L'absence d'initialisation d'un pointeur déclaré comme une variable globale ou statique est problématique si l'on code son déréférencement sans avoir préalablement codé sa valeur d'adresse via une affectation. En effet, considérons le programme académique suivant, codé dans un fichier nommé noinitptr.c :
#includeint * p; int main(void) { *p = 5; printf("%p\n", (void *) p); return 0; }
Le pointeur p n'étant pas initialisé dans sa déclaration à la ligne nº 3, il prend par défaut la valeur nulle comme toute variable globale ou statique non initialisée (cf. chap. C2‑III ). Plus précisément, dans le cas d'une variable de type pointeur, la valeur par défaut est le pointeur null, lequel ne peut pas être déréférencé puisque l'adresse 0x0 n'existe pas (cf. chap. C5-II ).
- Un tel problème reste indétectable à la compilation par
gccsi l'on se contente d'invoquer les options usuelles d'avertissement-Wallet-Wextra(cf. chap. C1‑II ). - Pour y remédier, on peut néanmoins invoquer l'option
-fanalyserqui opère une analyse statique du programme. Voici l'avertissement qu'obtient dans un terminal d'exécution sous Linux :

gcc -fanalyzer noinitptr.c -o noinitptrnoinitptr.c: In function ‘main’: noinitptr.c:7:6: warning: dereference of NULL ‘0’ [CWE-476] [-Wanalyzer-null-dereference] 7 | *p = 5; | ~~~^~~ ‘main’: event 1 | | 7 | *p = 5; | |~~~^~~| | | | | (1) dereference of NULL ‘p’ |
-Werror – car l'exécutable généré par la commande gcc provoque sans surprise une erreur de segmentation : ./noinitptrSegmentation fault (core dumped)
Plus généralement, il est déconseillé de déréférencer un pointeur qui n'a pas été initialisé. En effet, en reprenant l'exemple précédent, même si l'on déplace la déclaration de p dans la fonction main comme ci‑dessous (cf. la ligne nº 5) :
#includeint main(void) { int * p; *p = 5; printf("%p\n", (void *) p); return 0; }
on obtient aussi un avertissement lors de la compilation avec l'option -fanalyser :
gcc -fanalyzer noinitptr.c -o noinitptrnoinitptr.c: In function ‘main’: noinitptr.c:6:6: warning: use of uninitialized value ‘p’ [CWE-457] [-Wanalyzer-use-of-uninitialized-value] 6 | *p = 5; | ~~~^~~ ‘main’: events 1-3 | | 5 | int * p; | | ^ | | | | | (1) region created on stack here | | (2) capacity: 8 bytes | 6 | *p = 5; | | ~~~~~~ | | | | | (3) use of uninitialized value ‘p’ here |
Et même si le programme exécutable semble observer un scénario normal d'exécution :
./noinitptr0x7ffcdcbe3888
cela n'en reste pas moins un comportement indéterminé selon la norme.
Choix du format de déclaration
Dans la déclaration d'un pointeur, les caractères d'espacement autour du symbole * (qui, rappelons‑le, n'est pas l'opérateur de déréférencement) n'ont aucune importance syntaxique.
Syntaxiquement, les quatre déclarations ci‑dessous sont équivalentes :
-
int * p = &a; -
int* p = &a; -
int *p = &a; -
int*p = &a;
mais en termes de lisibilité et de robustesse, le format nº 1 est à privilégier.
En effet, dans le cadre de déclarations plus complexes, les formats de codage ci‑dessus ne sont pas équivalents. Dans l'exemple supra :
- Le format nº 2 qui « colle » le symbole
*au descripteur de typeintmet bien en évidence le fait que la variable déclarée est de type pointeur d'entier (int*). En revanche : - ce format devient moins « clair » si le descripteur de type est composé de plusieurs mots‑clef, qui sont nécessairement séparés par au moins un espace ; par exemple, dans
unsigned int*, le symbole*s'applique àunsigned intet non pas seulement àint; - de format n'est pas « compatible » avec l'opérateur séquentiel (cf. chap. C2‑II ) ; en effet, si l'on code :
int a = 5, b = 3; int* p = &a, q = &b; // inconsistent initializer!
on obtient une erreur – ou a minima un avertissement – de compilation, car la variableqest en fait ici déclarée de typeintet non pasint*; dès lors, l'initialisationq = &b;est inconsistante ; syntaxiquement, il faut donc coder :
int* p = &a, *q = &b; // OK, but not easy to read
où le symbole*est associé à l'identificateur, et non pas au descripteur de type de la variable déclarée. - Le format nº 3 qui « colle » le symbole
*à l'identificateur du pointeur est donc plus satisfaisant, mais il peut induire en erreur un codeur débutant pour les affectations ultérieures à la déclaration d'un pointeur ; en effet, si on souhaite changer la valeur dep(c'est‑à‑dire l'adresse sur laquelle il pointe), il faut coder par exemple :
p = &b;
et surtout pas :
*p = &b;
qui est inconsistante puisque, par déréférencement,*pest de typeint, donc on ne peut lui affecter une adresse. - Quant au format nº 4, il n'est évidemment pas satisfaisant, car trop tassé (cf. les recommandations d'aération horizontale du code, chap. C2‑X ).
- En définitive, le format nº 1 avec un espace de part et d'autre du symbole
*est sans doute le plus satisfaisant. Dans le cas d'une déclaration séquentielle, il doit être employé comme ci‑dessous :
int * p = &a, * q = &b; // much better!
Type d'un pointeur de données – déclaration d'un type synonyme
Le type d'un pointeur de donnée (variable ou constant) est un type dérivé du type des données qu'il peut pointer.
Son descripteur se code en ajoutant le symbole suffixe * au descripteur de type des données pointées, c'est‑à‑dire de la forme :
descripteur de type *
Le descripteur unsigned int * code un type de pointeur sur des entiers standards non signés.
Déclaration d'un type synonyme de pointeur de données
Rappelons qu'en langages C et C++, on peut déclarer un type synonyme de n'importe quel type, élémentaire ou dérivé, à l'aide du mot‑clef typedef (cf. chap. C3‑I ).
Lorsqu'on déclare un type synonyme d'un type de pointeur, il est d'usage de préfixer son identificateur par la lettre P majuscule (puisqu'il s'agit d'un identificateur de type) pour en signaler la « nature ».
Le code ci‑dessous déclare le type P_uint comme synonyme de unsigned int *.
typedef unsigned int * P_uint;
L'identificateur P_uint peut ensuite être directement employé comme descripteur de type pour déclarer des pointeurs d'entiers non signés.
unsigned int a = 5, b = 3; P_uint p = &a, q = &b;
Pointeur constant versus pointeur en « lecture seule »
Dans une forme syntaxique plus générale de la déclaration d'un pointeur de données, le mot‑clef const peut apparaître en deux positions :
- avant le symbole
*; - après le symbole
*.
Il importe de bien distinguer ce qu'implique chacun des cas, qui définissent ce respectivement ce qu'on appelle un pointeur de données en lecture seule (read‑only pointer) et un pointeur constant (constant pointer).
Cette polyvalence est d'autant plus complexe que ces deux particularités peuvent se combiner, c'est‑à‑dire qu'il y ait, dans la même déclaration de pointeur (ou dans un même descripteur de type), deux occurrences du mot‑clef const !
Pointeur de donnée en « lecture seule »
Une déclaration de la forme :
const
descripteur de type *
identificateur
[=
expression;
déclare un pointeur de donnée en « lecture seule » (en anglais, read‑only pointer – cf. la remarque ci‑après) au sens où il ne peut pas modifier la valeur de la donnée sur laquelle il pointe. C'est donc le pointeur qui est en lecture seule, mais pas la donnée.
Plus en détails, si l'on déclare un pointeur de donnée « lecture seule » p, il n'est pas possible de coder une instruction d'affectation directe de la forme *p = expression.
En revanche, la donnée sur laquelle p pointe peut être une variable. Dans ce cas, elle peut elle‑même faire l'objet d'affectations, avec pour conséquence des changement de valeur de l'expression *p, qui n'est donc pas constante.
De plus, contrairement à un pointeur constant (cf. infra ), un pointeur en « lecture seule » peut changer de valeur, c'est‑à‑dire de donnée pointée.
Le recours à un pointeur de donnée « en lecture seule » apporte donc une sécurité de codage par rapport à un pointeur « ordinaire », puisqu'il permet d'accéder à la mémoire sans pouvoir la modifier directement.
Considérons le programme académique suivant, codé dans un fichier nommé readOnlyPtr.c où une variable p est déclarée comme un pointeur en lecture seule (cf. la ligne nº 4) sur une variable a – et non pas une constante (cf. la ligne nº 3). Et ensuite est codée une opération de d'affectation sur a par déréférencement de p (cf. la ligne nº 5) :
int main(void)
{
int a = 5, b = 4;
const int * p = &a;
*p = 4;
return *p;
}
En tentant de le compiler dans un terminal de commandes sous Linux, on observe que ce n'est pas la ligne nº 4 (le fait que p pointe sur une variable et non pas une constante) mais bien la ligne nº 5 qui provoque une erreur de compilation :
gcc readOnlyPtr.c -o readOnlyPtrreadOnlyPtr.c: In function ‘main’: readOnlyPtr.c:5:6: error: assignment of read-only location ‘*p’ 5 | *p = 4; | ^
En effet, il n'est pas possible de coder une affectation directe sur *p puisque p est déclaré en « lecture seule ».
En revanche, si la ligne nº 5 est remplacée par a = 4; ou encore par p = &b; c'est‑à‑dire deux instructions qui font changer indirectement la valeur de l'expression *p, alors le programme est parfaitement compilable et exécutable et retourne dans les deux cas la valeur 4 alors que la valeur initiale de a, la variable pointée par p était 5.
gcc readOnlyPtr.c -o readOnlyPtr & ./readOnlyPtr & echo $?[…] [2]+ Exit 4 ./testROpointer
Dans la littérature anglophone (cf. par exemple ce lien vers le forum Stack Overflow ), on parle de « pointer to constant » pour désigner un pointeur en lecture seule, plutôt que de « read‑only pointer ». Pourtant, cet usage n'est pas très heureux car il a tendance à engendrer l'idée qu'il s'agirait d'un pointeur sur une donnée déclarée de type const, ce qui n'est pas le cas !
Pointeur constant de donnée
Une déclaration de la forme :
descripteur de type * const
identificateur =
expression
déclare un pointeur constant de donnée au sens où sa valeur – l'adresse de la donnée sur laquelle il pointe – n'est pas modifiable. Elle est fixée par l'expression d'initialisation, laquelle est obligatoire dans la déclaration, comme pour une constante (cf. chap. C2‑III ).
En revanche, avec un point constant déclaré p, si la donnée qu'il pointe est une variable, alors l'expression *p :
- est susceptible de varier au gré des changement de valeur de cette variable ;
- peut elle‑même faire l'objet d'affectations dont elle est la l‑value, c'est‑à‑dire d'expressions de la forme
*p = expression.
Après les déclarations :
int a = 5, b = 3; int * const p = &a;
- il n'est pas possible de coder (dans une fonction,
mainou autre) une instruction commep = &b;puisquepest un pointeur constant ; - en revanche, il est possible de coder
*p = 1;pour changer la valeur de la variablea.
Opérations sur les pointeurs – arithmétique spécifique
Rappelons que même si une adresse mémoire est représentée par un nombre entier positif, la valeur d'un pointeur n'est pas assimilée à un type entier (comme unsigned long ou autre). En langages C et C++, un pointeur de donnée est forcément d'un type dérivé du type de données qu'il pointe.
Exemples : int *, char *, float * sont des types dérivés respectifs de int, char, float.
Il en résulte qu'a priori, on ne devrait pas pouvoir appliquer aux pointeurs les opérateurs de calcul sur les entiers. Mais une des forces des langages C et C++ est qu'ils mettent en œuvre la surcharge :
- des opérateurs arithmétiques binaires
+et-, - ainsi que des opérateurs à affectation composée
++,--,+=,-=(cf. chap. C2‑IV ),
afin qu'ils soient applicables aux pointeurs de données.
Toutefois, certaines opérations comme l'addition de deux pointeurs (c'est‑à‑dire deux adresses) – sans parler de la multiplication ni de la division – n'auraient aucun sens !
Les seules opérations valides sont les incrémentations et décrémentations – éventuellement multiples – ainsi que la soustraction. De plus, ces opérations obéissent à une arithmétique spécifique, dont le codeur débutant doit prendre pleinement conscience.
Opérations arithmétiques sur les pointeurs
Incrémentation d'un pointeur
Si on déclare un pointeur avec une adresse initiale comme ci‑dessous :
descripteur de type * p =
adresse;
alors l'instruction d'incrémentation unitaire :
p++;
augmente la valeur de p – c'est‑à‑dire l'adresse qu'il pointe – d'un nombre égal à sizeof(descripteur de type), soit la taille du type de données pointées par p, autrement dit le nombre d'octets nécessaires au stockage d'une donnée de ce type – cf. chap. C3‑I ).
Par un principe similaire, la décrémentation unitaire p-- diminue de la valeur de p de la taille du type de données qu'il pointe.
Plus généralement :
- l'itération n fois d'une incrémentation de
p, codéep += n, augmente la valeur depde n fois la taille du type de données qu'il pointe ; - l'itération n fois d'une décrémentation de
p, codéep -= n, diminue la valeur depde n fois la taille du type de données qu'il pointe.
Attention ! Dans un programme qui manipule des données hétérogènes (c'est‑à‑dire de types différents), rien ne garantit que l'adresse pointée après incrémentation ou décrémentation d'un pointeur soit celle d'une donnée déclarée compatible avec le type des données qu'il pointe. Le déréférencement du pointeur ayant été manipulé de la sorte peut alors n'avoir aucun sens dans la mesure où il interprète dans un type une zone de la mémoire réservée au stockage d'une donnée d'un autre type.
Expérimentons justement l'incrémentation d'un pointeur sur des données hétérogènes avec le programme Arduino ci‑dessous :
uint8_t a = 8;
uint8_t * p = &a;
uint16_t b = 256;
void setup()
{
Serial.begin(115200);
Serial.println("Address Value");
Serial.print(int(&a), HEX); Serial.print("\t");
Serial.println(a);
Serial.print(int(&b), HEX); Serial.print("\t");
Serial.println(b);
p += 3; // TEST POINTER INCREMENTATION
Serial.print(int(p), HEX); Serial.print("\t");
Serial.println(*p);
}
void loop() {}
Simulé dans l'environnement Tinkercad, il affiche dans la fenêtre du moniteur série la sortie suivante :
Address Value 100 8 103 256 103 0
Après exécution de l'incrémentation p += 3 (ligne nº 16), l'expression *p prend la valeur 0 car à l'adresse 0x103 se trouve l'octet de poids faible du mot de 16 bits qui encode en binaire naturel l'entier 256 (la valeur de la variable b). En effet, en binaire naturel sur deux octets, cette valeur est encodée :
0000 0001 0000 0000
donc :
-
0000 0000sur l'octet d'adresse0x103, -
0000 0001sur l'octet d'adresse0x104.
Après incrémentation, le déréférencement de p ne correspond donc pas à une donnée stockée, mais seulement une partie d'une donnée stockée à l'adresse pointée !
En règle générale, les opérations arithmétiques sur les pointeurs de données sont donc réservées :
- aux pointeurs d'octets ou de caractères étendus, pour scanner une zone de la mémoire vive, un fichier, un flux d'entrées-sorties… ;
- ou aux structures de données homogènes, c'est‑à‑dire de même type – donc usuellement des tableaux, des fichiers… sachant que ces structures peuvent très bien elles‑mêmes mémoriser des données hétérogènes.
Soustraction entre deux pointeurs dans un tableau
Les langages C et C++ autorisent également d'opérer une soustraction entre deux pointeurs de même type – ce qui est tout particulièrement le cas dans un tableau de données (cf. chap. C5‑III ).
- La soustraction entre deux pointeurs de même type calcule, conformément à l'arithmétique des pointeurs (cf. supra , le nombre de données entre les adresses pointées par ces deux pointeurs, avec un signe (c'est‑à‑dire, éventuellement négatif).
- Ce résultat est une valeur de type
ptrdiff_tC – un type spécial défini dans le fichier d'en‑têtestddef.hde la bibliothèque standard du langage C (cstddefen C++), au même titre que le typesize_t(cf. chap. C3‑I ). - Dans les entrées‑sorties standards (cf. chap. C2‑VII , les valeurs de type
ptrdiff_tdoivent être associées avec la spécification de conversion%td(pour mémoire, celles de typesize_tsont à associer avec la spécification de conversion%zu).
Le type ptrdiff_t dépend de la machine cible. Si cette dernière possède une grande mémoire vive (plus de 4 Go), une valeur de ce type ne peut pas être convertie en entier standard signé int, car l'étendue des valeurs codable dans ce type se borne à seulement 2 milliards environ (cf. chap. C3‑II ).
Pour pouvoir être exploitée (calcul, affichage, etc.) sur une telle machine, une valeur de type ptrdiff_t doit donc être convertie dans un type plus grand, comme long long.
La pratique des soustractions de pointeurs sera étudiée au chapitre C5‑IV consacré à la manipulation des tableaux.
Opérateurs de comparaison entre pointeurs
Comme les adresses sont, d'un point de vue mathématique, des nombres entiers, il est parfaitement possible de concevoir sur leur ensemble les relations d'ordre total usuelles, que l'on note respectivement « < » et « > ».
Tous les opérateurs de comparaison (cf. chap. C2‑IV ) des langages C et C++ s'appliquent aux pointeurs, à condition qu'ils soient de même type.
Ici, on ne peut pas parler de surcharge car il n'y a aucune différence conceptuelle entre l'application des opérateurs de comparaison aux entiers et aux pointeurs. Si p et q sont deux pointeurs de même type :
- l'expression
p == qest non nulle – c'est‑à‑dire vraie – si et seulement sipetqont la même valeur, autrement dit s'ils pointent sur la même adresse ; - l'expression
p > qest non nulle – c'est‑à‑dire vraie – si et seulement si la valeur (l'adresse sur laquelle il pointe) depest supérieure (comme numéro d'ordre) à celle deq; - et même principe pour
p < q…
Considérons le programme académique Arduino ci‑dessous, qui déclare deux pointeurs d'entiers standards p et q :
int a = 5, b = 3;
int * p = &a, * q = &b;
void setup()
{
Serial.begin(115200);
Serial.println(p < q);
}
void loop() {}
Lors de l'exécution sur une carte Uno, l'évaluation de l'expression p < q (ligne nº 7) donne la valeur affichée suivante :
-
0avec Arduino IDE, car l'attribution des adresses aux données procède dans l'ordre inverse de leurs déclarations respectives (aobtient l'adresse0x102etbl'adresse0x100) ; -
1en simulation sous Tinkercad, car l'attribution des adresses aux données procède dans l'ordre direct de leurs déclarations respectives (aobtient l'adresse0x100etbl'adresse0x102).
Conversions sur des types de pointeurs
On a vu au chapitre C3‑VII qu'afin de simplifier le codage des expressions, les compilateurs des langages C et C++ mettaient en œuvre des de nombreuses conversions implicites sur des valeurs de types élémentaires.
À quelques exceptions près (cas des identificateurs de tableaux, cf. chap. C5‑III ), il n'y a aucune conversion implicite prévue sur les pointeurs – et plus généralement, sur les données de types dérivés.
Lorsqu'on rencontre dans une expression un incompatibilité de types avec un pointeur, il faut donc recourir à une conversion explicite (cast – cf. chap. C3‑VII ).
Conversion d'un pointeur en entier
On a vu supra que pour afficher la valeur d'une adresse sur le moniteur série dans l'environnement Arduino, il fallait la convertir en entier (de type int par exemple), car c'est le type attendu du premier argument des méthodes print et println.
Plus généralement, pour convertir un pointeur en entier, il faut choisir un type dont la taille est suffisante au regard de l'étendue des valeurs des adresses sur la machine cible du programme.

Dans l'environnement de compilation en ligne OnlineGDB, les programmes sont compilés sur une architecture 64 bits. On peut choisir le type unsigned long, encodé sur 64 bits, pour afficher la valeur décimale d'un pointeur, comme dans le programme académique ci‑dessous.
#include <stdio.h>
int main(void)
{
int a = 5, * p = &a;
printf("%p %lu", (void *) p, (unsigned long) p);
return 0;
}
On obtient par exemple l'affichage :
0x7ffff1a474d4 140737247474900
Remarque. Comme souligné au chapitre C4‑II W, on peut observer la virtualité de l'adresse allouée à la variable a qui est affichée. En effet, même si cette dernière est locale – donc placée dans la pile, c'est‑à‑dire tout en « bas » de l'espace mémoire attribué au programme – il serait invraisemblable que ce segment compte environ 140 000 milliards d'adresses ! (la mémoire vive d'une machine se compte en dizaines de Go seulement.)
Conversions entre pointeurs de types différents
On peut affecter à un pointeur la valeur de n'importe quelle adresse de donnée déclarée, même si cette dernière n'est pas du type pointé par le pointeur. Il suffit de convertir explicitement cette adresse dans le type du pointeur.
Une telle affectation permet notamment d'interpréter la valeur d'une donnée dans un format d'encodage différent de son type déclaré.
Rappelons que la fonction printf (cf. chap. C2‑VII ) permet, en hexadécimal, d'afficher l'encodage d'une donnée de type int : il suffit d'utiliser la spécification de conversion %X, comme dans le programme ci‑dessous.
#include <stdio.h>
int main(void)
{
int a = -1;
printf("%d is encoded %X", a, a);
return 0;
}
Ainsi, avec l'environnement de compilation en ligne OnlineGDB, on obtient l'affichage attendu :
-1 is encoded FFFFFFFF
En effet, en complément à 2, l'entier relatif -1 est bien encodé comme 1…1 sur 32 bits, soit FFFFFFFF en hexadécimal (cf. chap. C3‑II ).
Mais il n'est pas possible de procéder de même pour une donnée de type float (ou de tout autre type flottant). En effet, si on code :
#include <stdio.h>
int main(void)
{
float a = 1.0;
printf("%.1f is encoded %X", a, a); // does NOT work!
return 0;
}
avec OnlineGDB, le compilateur émet un avertissement et on obtient une sortie incorrecte, typiquement :
main.c: In function ‘main’: main.c:14:28: warning: format ‘%X’ expects argument of type ‘unsigned int’, but argument 3 has type ‘double’ [-Wformat=] 14 | printf("%.1f is encoded %X", a, a); // does NOT work! | ~^ ~ | | | | | double | unsigned int | %f 1.0 is encoded B3500D48
Pour surmonter cet obstacle et afficher l'encodage d'une donnée de type float, il suffit de recourir à un pointeur d'entier non signé de même taille que la variable a, donc uint32_t (4 octets). Le code ci‑dessous implémente une telle solution :
#include <stdio.h>
#include <stdint.h>
float a = 1.0;
uint32_t * p = (uint32_t*) &a;
int main(void)
{
printf("%.1f is encoded %X\n", a, *p);
}
et avec OnlineGDB, on obtient l'affichage attendu :
1.0 is encoded 3F800000
Et en effet, on peut aisément vérifier que la valeur hexadécimale 3F800000 est bien conforme à l'encodage binaire de la valeur 1.0 dans le type float (cf. chap. C3‑V ) par l'analyse détaillée comme celle de la figure ci‑dessous :

que l'on peut décoder en partant de la gauche :
- le bit de signe vaut s = 0 ;
- l'exposant décalé vaut q = 127 (
0111 1111en binaire) ; - le significande vaut f = 0 ;
En définitive, on obtient bien (−1)0 × (1 + 0,0) × 2127 − 127 = 1 × 20 = 1,0.
Notion de référence
Motivation
Comme on a pu le constater, les pointeurs constituent un outil très puissant de programmation, puisqu'ils permettent de lire et écrire le contenu précis de n'importe quelle adresse du segment de mémoire allouée à un programme. Cependant leur emploi présente aussi un risque non négligeable de provoquer des erreurs d'exécution qu'il est difficiles d'anticiper.
Typiquement, une opération d'écriture via un pointeur qui déborde du segment alloué au programme constitue ce qu'on appelle une erreur de segmentation W, en anglais segment fault. Si elle n'est pas encadrée par un mécanisme de surveillance (comme lorsqu'on exécute un programme dans un terminal de commandes en ligne), une erreur de segmentation peut compromettre le bon fonctionnement du système d'exploitation et ainsi faire « planter » la machine. Un tel dysfonctionnement, inacceptable sur un produit fini, n'est pas si rare lors des essais de portage d'une application sur une nouvelle architecture matérielle.
Dans l'objectif d'améliorer la fiabilité du codage des programmes, le langage C++ n'interdit pas l'emploi des pointeurs, pour des raisons évidentes de compatibilité. Mais il fournit au codeur le concept alternatif de référence, certes moins puissant, mais beaucoup plus sûr.
De plus, c'est une notion moins complexe que celle de pointeur mais là encore, le codeur débutant doit accorder la plus grande attention aux détails pour ne pas faire de confusion – d'autant plus que le langage C++ surcharge le symbole & pour la déclaration des références (qui sont à ne pas confondre avec l'opérateur d'adresse).
Déclaration et caractéristiques d'une référence
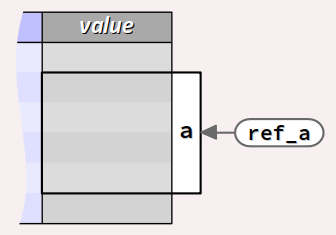
En langage C++ (et non en C), partant d'une donnée préalablement déclarée dans un type élémentaire ou dérivé, anonyme ou non, la déclaration d'une référence sur cette donnée se code via la forme syntaxique (simplifiée) :
descripteur de type &
identificateur de référence =
identificateur de donnée;
La référence ainsi déclarée se comporte alors définitivement comme un alias de la donnée. C'est une l‑value (cf. chap. C2‑IV ).
Dans la forme syntaxique supra :
- le descripteur de type est celui de la donnée préalablement déclarée ;
- l'identificateur de référence désigne la référence déclarée ;
- l'identificateur de donnée est celui de la donnée préalablement déclarée (il n'est pas composé avec l'opérateur d'adresse comme pour l'initialisation d'un pointeur) ; on l'appelle le référent ;
On peut déclarer un nombre illimité de références que l'on souhaite pour une même donnée. En revanche, soulignons bien qu'il n'est pas possible pour une même référence de changer de référent (l'initialisation est définitive, comme pour un pointeur constant – cf. supra ).
Procédons avec un exemple académique similaire à celui proposé pour illustrer la déclaration d'un pointeur (cf. exemple supra ) :
int number = 5; int & refNumber = number;
À partir de la donnée number déclarée en ligne n° 6, la référence déclarée refNumber aura toujours la même valeur que son référent qui est number, et ce quelles que soient les affectations effectuées sur l'une ou l'autre. Par exemple, dans l'extrait de code ci‑dessous :
number = 10; // refNumber = number = 10 refNumber++; // refNumber = number = 11
la variable number est modifiée aussi bien par affectation directe ou par l'intermédiaire de son référent. Autrement dit, si on l'on code par la suite :
int otherNumber = 7; refNumber = otherNumber; otherNumber = 2;
alors refNumber prend la valeur 7 mais pour autant, elle ne devient pas un alias de otherNumber. Car après exécution de l'instruction de la ligne nº 22 qui modifie la valeur de otherNumber, la référence refNumber ne vaut pas 2 mais encore 7.
En langage C++, une référence n'est pas une donnée. Elle partage avec son référent la même valeur, la même adresse et le même type ; seuls leurs identificateurs diffèrent.
Référence constante
Dans la forme syntaxique générale de déclaration d'une référence présentée supra , le descripteur de type peut contenir le mot‑clef const, même si son référent est une variable. On parle alors de référence constante.
Après une telle déclaration, mais dans toute sa portée seulement, la valeur du référent – et donc aussi de la référence – devient immuable comme une constante, ce qui peut être pertinent dans un contexte particulier (fichier, corps d'une fonction, etc.).
Dans le code académique ci‑dessous, la variable a devient immuable à partir de la ligne nº 32. Elle ne peut plus faire l'objet d'aucune affectation dans toute la portée de la référence ref_a.
int a = 7; // ... const int & ref_a = a;
Une référence constante peut même avoir pour référent une constante littérale (valeur numérique, caractère, etc.).
Applications des références
Transmission par référence d'un argument de fonction
La notion de référence trouve sa principale application dans la transmission des arguments d'une fonction lorsque cette dernière doit en modifier les valeurs. Cet aspect a été présenté de façon anticipée au chap. C4‑I parce qu'il est très facile à mettre en œuvre (a contrario d'une transmission par adresse).
Après avoir exposé en détail la notion de référence, on est en mesure de mieux comprendre comment procède cette transmission.

Reprenons l'exemple classique ci‑dessous de la fonction swapInt qui permet de permuter les valeurs respectives de deux variables. Ici, elle est codée en langage C++ avec passage des arguments par référence (cf. la ligne nº 3) :
#include <cstdio>
void swapInt(int & a, int & b)
{
int c = a;
a = b;
b = c;
}
int nb1 = 1, nb2 = 2;
int main(void)
{
printf("BEFORE swap: nb1 = %d nb2 = %d\n", nb1, nb2);
swapInt(nb1, nb2);
printf(" AFTER swap: nb1 = %d nb2 = %d\n", nb1, nb2);
return 0;
}
Compilé et exécuté sous OnlineGDB, ce programme produit la sortie ci‑dessous parfaitement conforme aux attentes :
BEFORE swap: nb1 = 1 nb2 = 2 AFTER swap: nb1 = 2 nb2 = 1
Détaillons maintenant pourquoi le passage des arguments par référence permet à la fonction swapInt de modifier les variables passées comme arguments effectifs dans une expression d'appel. Dans l'en‑tête de cette fonction (cf. la ligne nº 3) :
void swapInt(int & a, int & b)
les deux arguments formels a et b apparaissent comme des déclarations de références non initialisées.
Implicitement, c'est lors de l'appel de la fonction (cf. la ligne nº 15) :
swapInt(nb1, nb2);
que les arguments prennent leur valeur « initiale ». Tout se passe comme si, lors de l'exécution, le programme complétait les déclarations des références a et b par :
-
int & a = nb1; -
int & b = nb2;
Elles deviennent alors des alias de nb1 et nb2 et, durant l'exécution du code de la fonction, toute affectation sur les premières modifie respectivement les valeurs de ces dernières – ce qui est précisément le but d'une transmission par référence.
On verra au chapitre C5‑II à suivre qu'il est possible d'obtenir le même résultats à l'aide de pointeurs – c'est ce qu'on appelle la transmission par adresse. Néanmoins, en langage C++, il est préférable d'adopter la transmission par référence des arguments, car elle est plus lisible et elle évite les problèmes de non initialisation de pointeurs.
D'ailleurs, lorsque qu'une fonction admet des arguments structurés, il faut privilégier la transmission par référence plutôt que par valeurs, même si les appels de cette fonction n'ont pas pour vocation de modifier leurs arguments effectifs. En effet, cela rend le traitement des appels de fonction plus rapides à exécuter puisque qu'une référence a une représentation en mémoire aussi légère que celle d'un pointeur. Et si l'on craint, par une erreur de codage, un risque de modification d'un argument effectif par la fonction, alors il suffit de préfixer le descripteur de type de son argument formel avec le mot‑clef const (cf. supra ).
Récapitulatif des déclarations et expressions
On a pu voir tout au long de ce chapitre qu'en langages C et C+, l'emploi des pointeurs et des références passe par l'usage d'une syntaxe subtile :
- les symboles
*et&n'ont pas le même sens selon qu'ils sont employés dans une déclaration ou dans une instruction autre que déclarative ; - les données de type pointeur ou référence n'ont pas les mêmes propriétés et, en conséquence, ne se manipulent pas de la même manière.
Dans les chapitres à suivre de la partie C5, les descripteurs de types de pointeurs étudiés seront plus complexes que ceux de ce chapitre. Pour pouvoir les aborder sereinement, il est donc indispensable de bien maîtriser les éléments essentiels de ce chapitre.
Les tableaux ci‑dessous ont pour but de faire une synthèse récapitulative, sur la base de trois exemples académiques de déclarations. Pour chacune sont listées quelques expressions remarquables dont on donne (sous couvert d'existence) le type, la valeur, l'adresse et des exemples d'affectations possibles.
Les notations employées sont les suivantes :
-
XXXetYYYreprésentent des adresses arbitraires que le codeur ne peut a priori pas connaître au moment du codage du programme ; - « – » représente une absence d'adresse, ce qui signifie que l'expression n'est pas une l‑value (donc elle ne peut pas faire l'objet d'une affectation).
Après la déclaration int num = 5;
| expression | type | valeur | adresse | exemples d'affectations possibles | |
|---|---|---|---|---|---|
num |
int |
5 |
XXX |
num = 7;
num = otherNum;
num++; |
|
&num |
int* |
XXX |
– |
✘ (&num n'est pas une l‑value) |
|
*num |
non valide (num n'est pas un pointeur) |
||||
Après la déclaration int * ptr = #
| expression | type | valeur | adresse | exemples d'affectations possibles |
|---|---|---|---|---|
ptr |
int* |
XXX |
YYY |
ptr = &otherNum;
ptr = otherPtr;
ptr++; |
&ptr |
int** |
YYY |
– |
✘ (&ptr n'est pas une l‑value) |
*ptr |
int |
num |
XXX |
*ptr = otherNum;
*ptr = *otherPtr;
*ptr++; |
Après la déclaration int & refNum = num; (en C++ seulement)
| expression | type | valeur | adresse | exemples d'affectations possibles | |
|---|---|---|---|---|---|
refNum |
int |
num |
XXX |
refNum = otherNum;
refNum++; |
|
&refNum |
int* |
XXX |
– |
✘ (&refNum n'est pas une l‑value) |
|
*refNum |
non valide (refNum n'est pas un pointeur) |
||||