Les aspects fondamentaux de la notion de tableau – déclaration et identification des éléments d'un tableau, ainsi que du tableau lui‑même – ont été présentés au chapitre C5‑III. Il en ressort notamment :
- qu'un tableau est une donnée structurée constituant une série de n éléments de même type ordonnés les uns à la suite des autres dans le segment mémoire alloué au programme ;
- que sauf exceptions remarquables (dans une déclaration ou avec les opérateurs
sizeofet&), l'identificateur d'un tableau est implicitement dégradé en un pointeur constant dont le type et la valeur d'adresse sont ceux du 1er élément du tableau ; - qu'à partir de ce pointeur, et par l'arithmétique spécifique à laquelle il obéit, on peut identifier tous les éléments du tableau – et que c'est ainsi qu'est défini l'opérateur d'indexation
[]; - qu'un tableau multidimensionnel est en fait un tableau de sous‑tableaux, eux‑même pouvant éventuellement présenter cette structure – chaque niveau de structuration conférant au tableau une dimension supplémentaire .
Fort de ces connaissances, il est maintenant possible d'aborder le codage des « opérations » de manipulation d'un tableau. Il s'agit d'un sujet complexe car une donnée de type structurée ne se manipule pas comme une donnée élémentaire, par simple application d'un opérateur.
- Dans la première partie de ce chapitre, on étudie les manipulations « simples », comme :
- l'affectation de valeurs aux éléments d'un tableau, qui ne peut pas s'opérer de façon globale ;
- le comptage du nombre d'éléments d'un tableau ;
- la conversion de type d'un tableau pour interpréter différemment sa structure – par exemple, considérer un tableau de 2 lignes et 3 colonnes comme un tableau de 6 éléments.
- Dans la deuxième partie du chapitre, on étudie la transmission d'un tableau comme argument et/ou valeur d'une fonction. Il s'agit de manipulations assez techniques mais essentielles en programmation.
- Enfin, dans la troisième et dernière partie du chapitre, on présente applications concrètes des tableaux avec emploi conjoint de types énumérés. On mentionne également certaines bibliothèques de fonctions spécifiquement dédiées à la mise en œuvre de tableaux.
Attention ! Ce chapitre revêt une grande importance pour la suite. En effet, une bonne maîtrise de la manipulation des tableaux est impérative pour aborder de façon experte les chaînes de caractères qui sont, en langage C, implémentées sous forme de tableaux – cf. le chapitre C5‑VI qui leur est consacré.
Manipulations élémentaires de tableaux
Règle générale et conséquence
Rappelons tout d'abord une règle générale déjà énoncée (cf. les chap. C2‑VI et C5‑III ) dont la connaissance est impérative pour bien comprendre toute la suite du chapitre.
En langages C et C++, sauf éventuellement dans le cadre d'une déclaration, on ne peut coder aucune opération globale sur une donnée de type tableau.

Reprenons l'exemple académique récurrent utilisé au chapitre C5‑III d'un tableau exprimant les durées des couleurs d'un feu tricolore.
Supposons que ces durées soient susceptibles de changer puis d'être réinitialisées à leurs valeurs initiales respectives. Il est alors rationnel de déclarer par exemple :
- un tableau constant nommé
DURATION_INITavec ces valeurs initiales, - et un tableau variable nommé
duration,
comme dans le code ci‑dessous :
const short DURATION_INIT[3] = {60, 5, 90};
short duration[3];
Malheureusement, il n'est pas possible :
- dans la déclaration, de coder l'initialisation la valeur de la variable
durationavec celle deDURATION_INITcomme cela :
short duration[3] = DURATION_INIT; // invalid statement! - après la déclaration de
duration, de coder une affectation globale comme cela :
duration = DURATION_INIT; // invalid statement! - ou même comme cela :
duration = {0, 0, 0}; // invalid statement!
et ce d'autant plus qu'on ne peut pas former une liste de constante en dehors d'une déclaration (cf. chap. C.
En effet, toutes ces instructions ne sont pas compilables puisque dans chacune, l'identificateur du tableau duration est implicitement dégradé en pointeur constant sur son premier élément (cf. chap. C5‑III ) qui ne forme pas une pas une l‑value. Il ne peut donc pas faire l'objet d'une affectation.
En conséquence de la règle générale énoncée supra, toute opération sur une donnée de type tableau ne peut se faire que :
- élément par élément – de préférence, quand cela est possible, par une ou plusieurs boucles répétitives
for(cf. chap. C2‑V ) imbriquées l'une dans l'autre conformément à la structure dimensionnelle du tableau ; - ou par le biais de pointeurs, notamment pour le passage d'argument ou la valeur de retour d'une fonction.
Affectation de valeurs par éléments
Typiquement, on code l'affectation de valeurs à des éléments d'un tableau unidimensionnel tab de N éléments par une boucle itérative de variable k de la forme :
for (size_t k = 0; k < N; k++) {
tab[k] = fonction de k;
}
sachant que la fonction codée, qui est spécifique au contexte du programme, peut très bien :
- ne pas dépendre de la variable d'itération
k, - faire appel à une saisie d'utilisateur, notamment via la fonction
scanf, - ou encore inclure l'identificateur d'un autre tableau,
- etc.
NB : l'itération est codée entre la borne inférieure 0 incluse et la borne supérieure N exclue puisque le tableau est déclaré à N éléments implicitement indexés de 0 à N − 1.
Pour un tableau bidimensionnel de M lignes et N colonnes, le principe est similaire avec deux boucles itératives imbriquées de la forme :
for (size_t j = 0; j < M; j++) {
for (size_t i = 0; i < N; i++) {
tab[j][i] = fonction de i et j;
}
}
ou j et i sont les variables d'itération permettant de parcourir respectivement les lignes et les colonnes du tableau.
Reprenons l'exemple du tableau duration exprimant les durées des couleurs d'un feu tricolore.
Afin de copier les valeurs des éléments du tableau DURATION_INIT dans ceux du tableau duration, on codera une boucle for typiquement ci‑dessous :
for (size_t k = 0; k < 3; k++) {
duration[k] = DURATION_INIT[k];
}
Remarques.
- Le type
size_t(cf. chap. C3‑I ) est souvent employé pour les variables d'incrémentation mais il peut très bien être remplacé par n'importe quel type entier dont l'étendue des valeurs couvre la plage d'indexation de la boucle. - En langage C, il est également possible d'employer un type énuméré qui permet d'améliorer la lisibilité du code. Ainsi, en prolongement de l'exemple, on peut coder l'affectation des éléments du tableau
durationavec les valeurs des éléments du tableauDURATION_INITcomme ci‑dessous :
typedef enum {GREEN, YELLOW, RED} LightColor;
for (LightColor color = GREEN; color <= RED; color++) {
duration[color] = DURATION_INIT[color];
}
Risques de dysfonctionnements
Rappelons (cf. chap. C5‑III ) que le codeur doit veiller à ce que le parcours des éléments d'un tableau reste dans les bornes de ce dernier (cf. le cas général supra ), quelle que soit la méthode employée – indexation directe ou accès par pointeur.

En effet, on rappelle (cf. chap. C5‑III ) que le compilateur n'interdit jamais l'accès à une adresse en mémoire. Mais en cas d'erreur, on s'expose soit à une interruption inopinée du programme (une écriture dans un segment mémoire protégé qui engendrerait une erreur de segmentation – cf. chap. C4‑II ) voire à un fonctionnement défectueux inattendu.
Reprenons l'exemple récurrent d'un tableau exprimant les durées des couleurs d'un feu tricolore, en partant de la déclaration :
short duration[3] = {60, 5, 90};
Après cette déclaration, des instructions d'affectation élémentaire qui débordent de la taille du tableau comme :
duration[-1] = 0; // out of range!
ou encore :
duration[3] = 0; // out of range!
sont compilables ! Cependant, leur effet de bord peut être dévastateur lors de l'exécution : non seulement elles peuvent écraser une autre donnée du programme mais elles peuvent aussi provoquer une erreur de segmentation (cf. chap. 5‑I ).
À titre de démonstration académique, observons le programme ci‑dessous, où l'on déclare deux variables de type tableau, respectivement duration_test et duration. Dans la fonction main, on effectue une série d'affectation sur les éléments de duration_test mais volontairement avec une petite erreur : la condition de répétition de la première boucle for est codée k <= 3 au lieu de k < 3 (cf. la ligne nº 10).
#include <stdio.h>
short duration_test[3] = {1, 1, 1};
short duration[3] = {60, 5, 90};
int main(void)
{
printf("%c %15s %6s\n", "k", "Address", "Value");
// display addresses and modified values of array 'duration_test'
for (size_t k = 0; k <= 3; k++){ // error: <= should be <
duration_test[k] = k * 10;
printf("%2zu %15p %6d", k, &duration_test[k], duration_test[k]);
printf("%s", k == 0 ? " duration_test\n" : "\n"); // array name
}
// display addresses and values of array 'duration'
for (size_t k = 0; k < 3; k++){
printf("%2zu %15p %6d", k, &duration[k], duration[k]);
printf("%s", k == 0 ? " duration\n" : "\n"); // array name
}
return 0;
}
Il en résulte que lors de l'exécution :
- L'itération
k = 3de la première boucleforécrira la valeur30(évaluation dek * 10) surduration_test[3]. Or le dernier élément du tableauduration_testtel qu'il est déclaré estduration_test[2]. Donc l'écriture se fera à l'emplacement mémoire consécutif à ce dernier élément. - Or cet emplacement sera logiquement aussi alloué à
duration[0], le premier élément du tableauduration. Sa valeur60sera donc écrasée et remplacée par la valeur30, comme l'illustre la figure ci‑dessous.
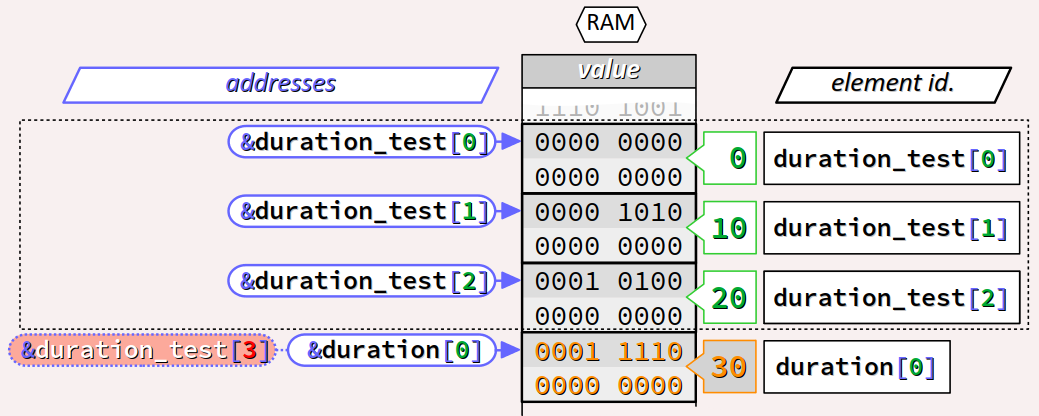
Pour s'en convaincre, on peut observer cet effet de bord en exécutant le programme supra avec OnlineGDB (cf. les lignes mises en orange avec une sortie standard typiquement comme ci‑dessous :
k Address Value 0 0x55fd44207010 0 duration_test 1 0x55fd44207012 10 2 0x55fd44207014 20 3 0x55fd44207016 30 0 0x55fd44207016 30 duration 1 0x55fd44207018 5 2 0x55fd4420701a 90
Comme prévu, la valeur 60 du premier élément du tableau duration est bel et bien écrasée par la valeur 30 via la dernière itération de la boucle d'affectation des valeurs du tableau duration_test.
Cet exemple illustre bien comment une petite erreur de codage, indétectable lors de la compilation, peut facilement engendrer un dysfonctionnement du programme (une variable est modifiée sans qu'aucune instruction du programme ne soit prévue pour cela). On retiendra donc qu'il faut être très vigilant dans la manipulation des tableaux avec l'opérateur d'indexation.
Conversions de types de tableaux
Conversions implicites
Rappelons qu'en langages C et C++, le compilateur met en œuvre de nombreuses conversions implicites sur les données scalaires pour faciliter le codage des expressions calculatoires (cf. chap. C3‑VI ).
Dans le cas d'une données de type tableau, hormis la dégradation systématique de son identificateur en pointeur constant sur son premier élément, aucune conversion implicite n'est opérée.
En effet, les types tableau sont potentiellement trop différents les uns des autres par divers d'aspects – nombre de dimensions, nombre d'éléments dans chaque dimension, types des éléments. Ils sont donc réputés incompatibles entre eux.
Les noms de types int8_t[2][3] et int8_t[6] désignent des tableaux de même taille mais avec structures différentes.
Le compilateur ne peut pas mettre en œuvre une conversion implicite de l'un vers l'autre, car il n'y a aucune raison de privilégier une structure plutôt que l'autre.
Conversions explicites
Rappelons qu'en langages C et C++, il existe l'opérateur de conversion explicite (cast operator) qui s'applique aux données scalaires – types élémentaires, énumérés, pointeurs – pour permettre au codeur d' interpréter leur contenu en mémoire dans un type différent du leur (cf. chap. C3‑VI ).
Dans le cas des données de types tableaux, comme les identificateurs sont systématiquement dégradés en pointeurs, les conversions explicites ne peuvent être opérées que par pointeurs interposés, en utilisant les noms de types appropriés.
Les conversions explicites de types de tableaux sont intéressantes pour coder facilement des opérations de copie de contenu entre des tableaux ayant des structures différentes.
Reprenons l'exemple académique récurrent d'un système de chauffage à thermostat introduit au chap. C5‑III avec la déclaration du tableau bidimensionnel qui mémorise les différentes consignes de chauffage selon le niveau de confort (confort/économique) et le régime de chauffe (jour/nuit/hors‑gel) :
int8_t heat[2][3] = { {22, 17, 10}, {19, 15, 5} };
Supposons que l'on veuille effectuer des calculs statistiques sur ce tableau. Une technique usuelle consiste alors à préalablement transposer ce tableau bidimensionnel en un tableau unidimensionnel de même taille pour pouvoir lui appliquer des algorithmes usuels de calculs. Pour cela, on déclare une nouvelle variable, par exemple :
int8_t heatStat[6] = { 1, 1, 1, 1, 1, 1, 1 };
initialisées avec des valeurs arbitraires (ici, que des 1). Ensuite, il faut copier les valeurs de heat (2 lignes, 3 colonnes) dans celles de heatStat, comme l'illustre la figure ci‑dessous (les manipulations d'indices sont expliquées ci‑après).
- Une première solution (classique) consiste, d'une manière générale, à établir la correspondance entre les valeurs des indices j et i des dimensions respectives du tableau de départ avec les valeurs de l'indice k de la dimension unique tableau d'arrivée. Pour cela, on dispose des opérateurs de division euclidienne
/et de reste%par le nombre de colonnes (ici,3) du tableau de départ. Ces opérations sont représentées sur la figure ci‑dessus et codées à la ligne nº 11 dans le programme ci‑dessous : - Parfaitement opérationnelle, la solution précédente requiert toutefois une bonne maîtrise du calcul. Pour un codeur inexpérimenté, il y a un risque d'erreur, typiquement celui d'inverser les indices de lignes et les colonnes. C'est pourquoi une autre solution consiste à opérer une conversion explicite de l'identificateur
heaten un simple pointeur d'entier 8 bits, c'est‑à‑dire de nom de typeint8_t *, comme ci‑dessous :
#include <stdio.h>
#include <stdint.h>
int main(void)
{
int8_t heat[2][3] = { {22, 17, 10}, {19, 15, 5} };
int8_t heatStat[6] = { 1, 1, 1, 1, 1, 1 };
printf("heatStat (after copy):\n");
for (size_t k = 0; k < 6; k++) {
size_t j = k / 3, i = k % 3; // the difficult point!
heatStat[k] = heat[j][i]; // copy via indexing
printf("%2d ", heatStat[k]); // for checking only
}
printf("\n");
return 0;
}
heatStat (ligne nº 13) ne sont pas ses valeurs initiales mais celles issues du tableau heat : heatStat (after copy): 22 17 10 19 15 5
// no line 11
heatStat[k] = ((int8_t *) heat)[k]; // copy via casting
[k] de la l‑value et de la r‑value dans l'affectation de copie. Et bien entendu, à l'exécution, on obtient exactement la même sortie. [] comme composition de * et + (cf. chap. C5‑III ), la ligne nº 12 pourrait également se coder comme ci‑dessous :
heatStat[k] = *((int8_t *) heat + k); // copy via casting
Réciproquement, après avoir éventuellement effectué une modification sur des éléments du tableau heatStat, il peut être nécessaire de les reporter dans le tableau heat. Il est alors nécessaire d'effectuer la transposition réciproque d'un tableau unidimensionnel à 6 éléments en un tableau bidimensionnel à 2 lignes et 3 colonnes, comme l'illustre la figure ci‑dessous.
- Comme précédemment, une première solution (classique) consiste à établir une correspondance entre les indices des dimensions respectives des tableaux de départ et d'arrivée. Mais cette fois, on utilise les opérateurs de multiplication
*et d'addition+(cf. la figure ci‑dessus et la ligne nº 12 dans le programme ci‑dessous) : - Là encore, cette solution présente un risque d'erreur d'inverser les indices de ligne et de colonne. C'est pourquoi on peut préférer le recours à une conversion explicite de l'identificateur
heatStaten un pointeur de tableau de 3 éléments de typeint8_t, donc dont le nom de type estint8_t(*)[3](cf. chap. C5‑III ). Il suffit pour cela de coder :
#include <stdio.h>
#include <stdint.h>
int main(void)
{
int8_t heatStat[6] = { 22, 17, 10, 19, 15, 5 };
int8_t heat[2][3] = { {1, 1, 1}, {1, 1, 1} };
printf("heat (after copy):\n");
for (size_t j = 0; j < 2; j++) {
for (size_t i = 0; i < 3; i++) {
size_t k = j*3 + i; // the difficult point!
heat[j][i] = heatStat[k]; // backward copy via indexing
printf("%2d ", heat[j][i]); // for checking only
}
printf("\n");
}
return 0;
}
heat ne sont ses valeurs initiales mais celles issues du tableau heatStat : heat (after copy): 22 17 10 19 15 5
// no line 12
heat[j][i] = ((int8_t(*)[3]) heatStat)[j][i]; // backward copy via casting
[j][i] pour la l‑value et la r‑value de l'affectation, ce qui enlève le risque d'erreur évoqué supra. Et bien entendu, à l'exécution, on obtient exactement la même sortie. [] comme composition de * et + (cf. chap. C5‑III ), la ligne nº 13 pourrait également se coder comme ci‑dessous :
heat[j][i] = *(*((int8_t(*)[3]) heatStat + j) + i); // backward copy via casting
Comparaison de tableaux
Tests de supériorité et d'infériorité
Sans même entrer dans des considérations de syntaxe ou de techniques de codage, rappelons qu'il n'existe pas de relation d'ordre total « naturelle » sur des objets non scalaires – donc en particulier sur les tableaux.
En effet, il serait insensé d'affirmer que, par exemple, le tableau {2, 5} est plus grand ou plus petit que le tableau {5, 2} sans fixer préalablement un critère spécifique de comparaison. Il faudrait sinon commencer par attribuer des poids aux éléments du tableau selon leur indice puis faire une somme pondérée à laquelle on pourrait alors appliquer la relation d'ordre usuelle sur les nombres réels.
En conséquence, on retiendra la règle suivante.
Il est inconcevable d'employer directement les opérateurs de comparaison > et < globalement entre des identificateurs de données de type tableau.
Néanmoins, il faut avoir conscience que si tab1 et tab2 sont deux tableaux déclarés de même type, alors une expression incongrue comme :
tab1 > tab2
serait compilable sans aucun avertissement. En effet :
- les identificateurs de tableaux étant implicitement dégradés en pointeurs constants sur leurs premiers éléments respectifs (cf. chap. C5‑III ),
- et les opérateurs de comparaison s'appliquant aux pointeurs (cf. chap. C5‑I ),
l'expression sera évaluée vraie si l'adresse attribuée à tab1 est supérieure à celle de tab2, et fausse dans le cas contraire. Et cela n'aura rien à voir avec les valeurs des éléments respectifs des deux tableaux.
Tests d'égalité et de non‑égalité
Le même principe d'évaluation d'une expression d'inégalité entre des identificateurs de tableaux exposé ci‑dessus vaut aussi pour les opérateurs d'égalité == et de non‑égalité !=.
En effet, si tab1 et tab2 sont deux tableaux déclarés de même type, alors l'expression incongrue :
tab1 == tab2
serait compilable mais toujours évaluée fausse puisque les adresses des deux tableaux sont forcément différentes – et ce quelles que soient les valeurs de leurs éléments respectifs.
Néanmoins, on peut parfaitement concevoir un test d'égalité entre deux tableaux de même type au regard du critère qu'il doivent avoir leurs éléments de même position égaux deux à deux.
Pour procéder à un tel test, la seule solution consiste à effectuer la comparaison éléments par éléments respectifs, typiquement via une ou plusieurs boucles itératives imbriquées comme présentées supra pour coder des affectations.
Considérons un exemple générique avec deux tableaux unidimensionnels déclarés de même type tab1 et tab2. Admettons qu'il comptent chacun 5 éléments, valeur qu'on peut aisément définir par une pseudo‑constante (cf. chap. C4‑III ) nommée N.
Le code ci‑dessous implémente un test d'égalité au sens où il détermine tous leurs éléments de mêmes indices sont respectivement égaux :
#include <stdio.h>
#include <stdbool.h>
#define N 5
int main(void)
{
int tab1[N] = {1, 2, 3, 4, 5};
int tab2[N] = {1, 2, 3, 4, 5};
bool arrayEquality = true;
for (size_t k = 0; k < N; k++) {
if (tab1[k] != tab2[k]) {
arrayEquality = false;
break;
}
}
printf("tab1 %s tab2\n", arrayEquality ? "\"==\"" : ""\"!=\"");
return 0;
}
Exécuté sur OnlineGDB, on obtient bien la sortie attendue :
tab1 "==" tab2
Cet algorithme de test est d'une grande simplicité :
- On utilise la variable booléenne
arrayEqualitydéclarée en amont de la boucle itérative, (cf. la ligne n° 10) avec la valeur initialetrue(ce qui revient à supposer qu'a priori, les deux tableaux sont égaux). - Dans la boucle itérative
for, dès la première différence constatée entre deux éléments de même indice, on affecte àarrayEqualityla valeurfalseet on sort immédiatement de la boucle.
Remarque. Dans les bibliothèques de fonctions usuelles, il est plutôt d'usage de coder cet algorithme en remplaçant les lignes n° 10 à 15 par les trois suivantes :
size_t k = 0;
while ((tab1[k] == tab2[k]) && k < N) k++;
printf("tab1 %s tab2\n", k == N ? "\"==\"" : ""\"!=\"");
Moins lisible, cette solution est un peu plus efficace car elle n'utilise pas de variable booléenne.
La problématique du test d'égalité de deux tableaux est l'occasion de faire un rappel important : si l'on doit tester un égalité ou non‑égalité entre nombres décimaux, il ne faut surtout pas employer les opérateurs == ou != (cf. chap. 3‑V ).
Par exemple, si tab1 et tab2 sont des tableaux d'éléments de type double, alors dans le programme ci‑dessus, il faut alors remplacer la ligne nº 12 par :
if (fabs((tab1[k] - tab2[k]) / tab1[k]) <= 10 * DOUBLE_EPSILON) {
où :
-
DOUBLE_EPSILONest la pseudo‑constante de résolution du typedoubledéfinie dans le fichier d'en‑têtefloat.hde la bibliothèque standard du langage C (cfloaten C++) ; -
10est une valeur usuelle pour le coefficient de précision.
Calcul du nombre d'éléments
Dans les manipulations de tableaux, il est souvent nécessaire de connaître le nombre d'éléments d'un tableau ou d'une de ses dimensions (c'est‑à‑dire d'un sous‑tableau). Néanmoins, pour déterminer une telle information, il n'existe pas d'opérateur dans le noyau des langages C et C++, ni de fonction dans leurs bibliothèques standards respectives.
Emploi de constantes
Une solution usuelle consiste, pour chaque tableau employé, à préalablement déclarer une constante ou une pseudo‑constante (incontournable en langage C – cf. chap. C4‑III ) pour chacune de ses dimensions. On peut alors exploiter ces constantes :
- dès la déclaration du tableau lui‑même, pour la rendre plus robuste aux changements ;
- pour calculer le nombre total d'éléments du tableau, tout simplement par multiplication des constantes ;
- dans les boucles itératives pour parcourir les éléments du tableau.
C'est précisément ce que l'on a fait dans tous les exemples précédents.
Reprenons l'exemple académique récurrent utilisé pour un thermostat de chauffage. Pour dimensionner le tableau heat, on peut définir les deux pseudo‑constantes comme ci‑dessous :
#define NB_OF_ROWS 2
#define NB_OF_COLUMNS 3
int8_t heat[NB_OF_ROWS][NB_OF_COLUMNS] = { {22, 17, 10}, {19, 15, 5} };
On peut ensuite coder des manipulations sur ce tableau en employant les pseudo‑constantes NB_OF_ROWS et NB_OF_COLUMNS dans les conditions de répétition de boucles itératives, comme par exemple ci‑dessous (cf. les lignes n º 12 & 13) pour déterminer la valeur maximale mémorisée dans le tableau :
#include <stdio.h>
#include <stdint.h>
#define NB_OF_ROWS 2
#define NB_OF_COLUMNS 3
int8_t heat[NB_OF_ROWS][NB_OF_COLUMNS] = { {22, 17, 10}, {19, 15, 5} };
int main(void)
{
int8_t heatMax = 0; // heat set point can't be negative (min. val. is 0)
for (size_t j = 0; j < NB_OF_ROWS; j++) {
for (size_t i = 0; i < NB_OF_COLUMNS; i++) {
if (heat[j][i] > heatMax) {
heatMax = heat[j][i];
}
}
}
printf("Max. heat value = %d °C\n", heatMax);
return 0;
}
Détermination du nombre d'éléments par routine
Une autre solution consiste à coder une routine – fonction ou pseudo‑fonction (cf. chap. C4‑III ) – qui calcule le nombre d'éléments d'un tableau par le rapport des valeurs rendues par l'opérateur sizeof appliqué successivement au tableau et à son premier élément (puisque tous les éléments d'un tableau ont nécessairement la même taille).
Ainsi, on peut coder les pseudo‑fonctions ci‑dessous :
-
#define nbOfElements(tab) (sizeof(tab)/sizeof(tab[0]))
pour obtenir le nombre d'éléments de la dimension externe d'un tableau, quel que soit son nombre de dimensions ; -
#define nbOfCells(tab) (sizeof(tab)/sizeof(tab[0][0]))
pour obtenir le nombre total de cellules dans le cas d'un tableau bidimensionnel.
Ces macro‑définition présentent, comme toutes les pseudo‑fonctions, d'employer des arguments non typés (cf. chap. C4‑III ). Elles peuvent donc être invoquées pour n'importe quel type de tableau ou de sous‑tableau. Et on rappelle que dans toute expression codée comme opérande de l'opérateur sizeof, un identificateur de tableau n'est pas converti en un pointeur, afin d'obtenir sa taille en octets (cf. chap. C5‑III ).
Reprenons le programme de l'exemple académique précédent pour rechercher la valeur maximale mémorisée dans le tableau heat de consignes d'un thermostat de chauffage.
Dans les boucles d'itération pour lire tous les éléments du tableau, à la place de pseudo‑constantes dimensionnelles, on utilise dans le programme ci‑dessous la routine proposée ci‑dessus, définie à la ligne n º 4. Les invocations de cette routine sont codées aux lignes n º 11 & 12.
#include <stdio.h>
#include <stdint.h>
#define nbOfElements(tab) (sizeof(tab)/sizeof(tab[0]))
int8_t heat[2][3] = { {22, 17, 10}, {19, 15, 5} };
int main(void)
{
int8_t heatMax = 0; // heat set point can't be negative (min. val. is 0)
for (size_t j = 0; j < nbOfElements(heat); j++) { // nb of rows
for (size_t i = 0; i < nbOfElements(heat[0]); i++) { // nb of columns
if (heat[j][i] > heatMax) {
heatMax = heat[j][i];
}
}
}
printf("Max. heat value = %d °C\n", heatMax);
return 0;
}
Remarques. Pour bien comprendre le fonctionnement de la pseudo‑fonction nbOfElements, analysons ses deux invocations dans le programme ci‑dessus pour obtenir successivement le nombre de lignes et le nombre de colonnes du tableau heat.
- À la ligne n º 11, l'expansion par le préprocesseur de
nbOfElements(heat)produit l'expression :
(sizeof(heat)/sizeof(heat[0])) -
sizeof(heat)est évaluée 2 × 3 × 1, soit 6 octets ; -
sizeof(heat[0])est évaluée 3 × 1, soit 3 octets ; - À la ligne n º 12, l'expansion par le préprocesseur de
nbOfElements(heat[0])produit l'expression :
(sizeof(heat[0])/sizeof(heat[0][0])) -
sizeof(heat[0])est évaluée 3 × 1, soit 3 octets ; -
sizeof(heat[0][0])est évaluée directement 1 octet ;
heat est un tableau de 2 lignes de chacune 3 éléments (colonnes) de type int8_t (1 octet) : heat. heat[0] est un tableau de 3 éléments (colonnes) de type int8_t (1 octet) : heat. Nombre d'éléments entre deux éléments donnés d'un tableau
Pour calculer le nombre d'éléments entre deux éléments d'un tableau, quelle que soit sa structure, il suffit de calculer la soustraction entre les adresses de ces deux éléments, puisque les éléments d'un tableaux sont toujours mémorisés les uns à la suite des autres. L'arithmétique des pointeurs mise en œuvre par la soustraction prend implicitement en compte la taille des éléments pointés (cf. chap. C5‑I ).
On rappelle à cette occasion que la soustraction de deux pointeurs de même type est une opération définie avec un résultat de type ptrdiff_t qui attend une spécification de conversion %td.
Attention : la différence entre deux adresses exclut dans le compte l'élément pointé par l'une des deux adresses. Le même principe vaut pour toutes les différences entre des nombres considérés comme ordinaux (cf. l'exemple ci‑dessous).
Reprenons l'exemple académique récurrent utilisé pour un thermostat de chauffage avec la déclaration du tableau bidimensionnel :
int8_t heat[2][3] = { {22, 17, 10}, {19, 15, 5} };
L'instruction ci‑dessous :
printf("%td\n", &heat[1][1] - &heat[0][1]);
compte le nombre d'éléments entre heat[1][1] (exclus) et heat[0][1] (inclus). Elle affiche donc la valeur 3.
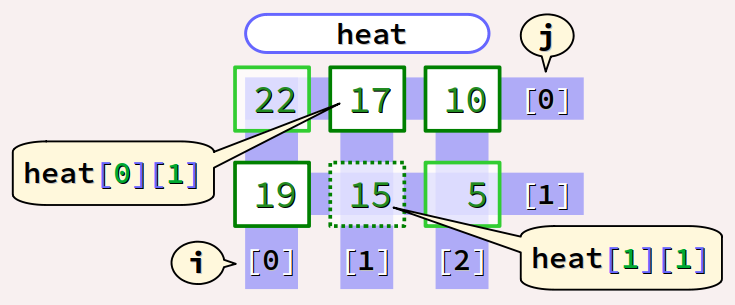
En effet, dans un tableau à 3 colonnes, entre le 2e élément de la 2e ligne (heat[1][1]) exclu et le 2e élément de la 1e ligne (heat[0][1]) inclus, il y a bien 3 éléments.
(De même, si l'on compte les nombres compris entre 5 exclu et 2 inclus, il y en a bien 5 − 2 = 3, à savoir les nombres 4, 3 et 2.)
Transmission d'un tableau comme argument et/ou valeur d'une fonction
Problématique de la transmission d'une valeur de type tableau
On rappelle la règle générale énoncée au début de ce chapitre : en langages C et C++, sauf dans le cadre d'une déclaration de donnée, il est impossible de former une expression dont la valeur est un tableau.
En conséquence immédiate, il est donc impossible pour une fonction de retourner une valeur de type tableau puisque, syntaxiquement, c'est bien une expression qui est attendue après le mot‑clef return.
Indirectement, le problème se pose dans les mêmes termes avec un appel de fonction pour la transmission de la valeur d'un argument effectif à son argument formel correspondant dans l'en‑tête de la fonction (cf. le principe général de transmission par valeur d'un argument de fonction exposé au chap. C4‑I , dont on reproduit la figure ci‑dessous).
En effet, cette transmission opère comme une affectation (cf. chap. C2‑IV ) où :
- l'argument formel, qui joue le rôle de la l‑value de l'affectation, est une expression qui sera évaluée in fine ; et s'il s'agit d'un identificateur de tableau, ce dernier est fatalement dégradé en un pointeur constant sur son premier élément ;
- l'argument effectif est une expression qui joue le rôle de r‑value de l'affectation – et là encore cela est impossible pour une valeur de type tableau (même s'il s'agissait d'un identificateur de tableau, ce dernier serait aussi dégradé en un pointeur constant sur son premier élément).
En conséquence, pour une fonction, le mécanisme de transmission d'argument par valeur n'est donc pas utilisable avec des données de type tableau, mais seulement de type pointeur de tableau – et alors, il s'agit d'une transmission par adresse (cf. chap. C5‑II ).
Les programmes proposés ci‑dessous sont des exemples académiques dysfonctionnels sur le thème récurrent du système de chauffage à thermostat (cf. supra ) : ils servent à illustrer l'impossibilité de la transmission d'un argument par valeur et de retour d'une valeur de type tableau.
- Essayons par exemple de coder la fonction
firstCouplequi retourne un tableau unidimensionnel constitué seulement des 2 premiers éléments d'un tableau unidimensionnel de 3 éléments de typeint8_tpris comme argument. Très maladroitement, on peut toujours tenter de coder un programme comme celui‑là : - La 1re erreur est assortie d'un message parfaitement explicite : une fonction ne peut pas retourner un tableau !
- La 2e erreur montre qu'après le mot‑clef
returnest attendue une expression et rien d'autre. Le délimiteur{n'est pas accepté ici pour former une liste. - La 3e erreur montre qu'un identificateur de fonction n'est pas accepté pour initialiser un tableau.
- Codons maintenant une fonction
firstRelDiffqui retourne la différence relative entre les 2 premiers éléments d'un tableau unidimensionnel de 3 éléments de typeint8_tpris comme argument formel. Pour mémoire, la différence relative entre deux nombres a (≠ 0) et b est égale à (b − a) / a.
#include <stdio.h>
#include <stdint.h>
int8_t firstCouple(int8_t tab[3])[2] // not compilable!
{
return {tab[0], tab[1]}; // not compilable!
}
int main(void)
{
int8_t heatConfort[3] = {22, 17, 10};
int8_t heatConfortNorm[2] = firstCouple(heatConfort); // not compilable!
return 0;
}
firstCouple sont non‑compilables. Sur OnlineGDB, on obtient les 3 erreurs suivantes : main.c:4:8: error: ‘firstCouple’ declared as function returning an array 4 | int8_t firstCouple(int8_t tab[3])[2] // not compilable! | ^~~~~~~~~~~ main.c: In function ‘firstCouple’: main.c:6:10: error: expected expression before ‘{’ token 6 | return {tab[0], tab[1]}; // not compilable! | ^ main.c: In function ‘main’: main.c:12:31: error: invalid initializer 12 | int8_t heatConfortNorm[2] = firstCouple(heatConfort); // not compilable! | ^~~~~~~~~~~
firstRelDiv prend pour argument effectif une valeur de type tableau formée par une liste de 3 éléments délimitée par { } :
#include <stdio.h>
#include <stdint.h>
float firstRelDiv(int8_t tab[3]) { // compilable
return (float) (tab[1] - tab[0]) / tab[0]; // compilable
}
int main(void)
{
printf("%g\n", firstRelDiv({22, 17, 10})); // not compilable!
return 0;
}
main.c: In function ‘main’:
main.c:10:30 : error: expected expression before ‘{’ token
10 | printf("%g\n", firstRelDiv({22, 17, 10})); // not compilable!
| ^
{22, 17, 10} qui n'est pas compilable en dehors d'une déclaration. Il est donc indispensable que, dans l'appel de la fonction firstRelDiv, l'argument effectif soit un identificateur de tableau. Or ce dernier serait implicitement dégradé en un pointeur et alors, il ne s'agirait plus d'une transmission par valeur mais d'une transmission par adresse. C'est ce que l'on va voir tout de suite après. L'impossibilité de la transmission d'un tableau, que ce soit comme valeur d'argument ou valeur de retour, est aussi une question d'efficacité dans l'exécution d'un programme. En effet, un tableau est un objet potentiellement très gros, du fait de la multitude de ses éléments.
Or, d'une manière générale, une transmission consiste toujours en une copie temporaire de valeur d'un emplacement mémoire vers un autre. En procédant par valeurs des éléments, la copie d'un tableau volumineux alourdirait donc considérablement le processus.
Au contraire, lorsqu'on opère une transmission par adresse, c'est seulement la valeur de l'adresse de l'objet (celle de son premier octet en mémoire) qui est copiée, l'objet lui‑même restant stocké au même emplacement. Pour un gros tableau, c'est évidemment bien plus efficace.
Transmission par adresse d'un argument de type tableau
Principe du recours à la transmission par adresse
Puisque la transmission par valeur d'un argument de type tableau n'est pas possible, l'alternative consiste à procéder par adresse, comme cela a été exposé au chapitre C5‑II , dont on reproduit la figure ci‑dessous.
- Dans l'en‑tête de la fonction, l'argument formel doit donc être codé sous la forme d'un pointeur de tableau.
- Dans l'expression d'appel de la fonction, l'argument effectif doit alors être une expression dont la valeur est un pointeur de même type que celui de l'argument formel – typiquement, un identificateur de tableau préalablement déclaré, puisque cet identificateur sera dégradé en pointeur lors de son évaluation.
Encore faut‑il pour cela connaître la syntaxe déclarative d'un pointeur sur une donnée de type tableau, c'est‑à‑dire un pointeur sur un élément du tableau.
- Pour un tableau unidimensionnel de données d'un type élémentaire, la syntaxe déclarative est de la forme :
descripteur de type * identificateur;
puisqu'il s'agit simplement d'un pointeur sur un élément de type descripteur de type (cf. chap. C5‑I ). - Pour un tableau bidimensionnel de données d'un type élémentaire, la syntaxe déclarative est de la forme :
descripteur de type (* identificateur)[nombre de lignes];
en rappelant qu'un tableau bidimensionnel est en fait un tableau de tableaux unidimensionnels (bref, un tableau de lignes).
Par ailleurs, comme pour toute déclaration, chaque forme syntaxique ci‑dessus peut être suivie d'une initialisation.
La forme déclarative d'un pointeur de tableau bidimensionnel présentée ci‑dessus est à ne pas confondre avec celles ci‑dessous qui, syntaxiquement, sont assez proches :
Les programmes proposés ci‑dessous sont des exemples académiques fonctionnels sur le thème récurrent du système de chauffage à thermostat, pour illustrer la transmission par adresse d'un argument de type tableau.
- La fonction
firstRelDiff_1calcule la différence relative entre les deux premiers éléments d'un tableau unidimensionnel : - Supposons maintenant que l'on veuille appliquer cette fonction a un tableau bidimensionnel. Dans le programme de l'exemple précédent, on pourrait se contenter d'appeler la même fonction en prenant pour argument effectif seulement la 1re ligne du tableau
heat, c'est‑à‑direheat[0], comme ci‑dessous :
#include <stdio.h>
#include <stdint.h>
float firstRelDiff_1(int8_t * tab) {
return (float) (tab[1] - tab[0]) / tab[0];
}
int main(void)
{
int8_t heatConfort[3] = {22, 17, 10};
printf("%g", firstRelDiff_1(heatConfort));
return 0;
}
-0.227273
int8_t heat[2][3] = { {22, 17, 10}, {19, 15, 5} };
printf("%g", firstRelDiff_1(heat[0]));
firstRelDiff_2 spécifique pour les tableaux bidimensionnels, et alors dans son appel, l'argument effectif doit être simplement l'identificateur du tableau heat, comme ci‑dessous :
float firstRelDiff_2(int8_t (* tab)[3]) {
return (float) (tab[0][1] - tab[0][0]) / tab[0][0];
}
int main(void)
{
int8_t heat[2][3] = { {22, 17, 10}, {19, 15, 5} };
printf("%g", firstRelDiff_2(heat));
return 0;
}
Codage de la transmission d'un argument de type tableau
La problématique de la transmission d'un argument de type tableau par une fonction est en fait bien plus plus complexe que pour un argument de type scalaire. En effet, le fait de procéder forcément par adresse (puisque la transmission par valeur est impossible) a deux conséquences notables :
- Il y a la perte de l'information du nombre d'éléments du tableau (ou de sa dimension la plus externe dans le cas d'un tableau multi‑dimensionnel). En revanche, la structure du tableau est « mémorisée » par le type du pointeur – cf. chap. C5‑III .
- Il y a aussi la possibilité inhérente – donc le risque – de modifier l'argument effectif alors que ce n'est pas toujours souhaitable.
Ces deux conséquences conduisent à adopter respectivement les techniques de codage suivantes :
- Si le nombre d'éléments du tableau (ou de sa dimension la plus externe dans le cas d'un tableau multi‑dimensionnel) est une donnée nécessaire dans l'algorithme de la fonction, il suffit de le transmettre comme un argument supplémentaire de la fonction.
- Pour prévenir le risque de modification accidentelle (par erreur de codage) de l'argument effectif lors d'un appel de la fonction, il suffit de préfixer par le mot‑clef
constdans le descripteur de type de l'argument formel correspondant dans l'en‑tête de la fonction. On a alors ce qu'on appelle un pointeur en « lecture seule » (cf. chap. C5‑I ).
Pour illustrer ces aspects, reprenons l'exemple récurrent du système de chauffage à thermostat (cf. supra ) et codons un programme qui calcule, par l'intermédiaire d'une fonction, la moyenne des valeurs contenues dans un tableau d'éléments de type int8_t.
- Commençons par le cas du tableau unidimensionnel
heatConfortqui regroupe les 3 valeurs de consigne de chauffage en mode « confort ». On nommemeanValue_1la fonction qui calcule, de façon générale, la moyenne des valeurs d'un tableau unidimensionnel, quel que soit son nombre d'éléments, grâce à la pseudo‑fonctionnbOfElementsprésentée supra . - le 1er argument formel
tabest déclaré avec le mot‑clefconst(pointeur en « lecture seule ») car la fonction n'a pas pour but de modifier le tableau pointé ; - on a un 2e argument formel
nbEltspour récupérer le nombre d'éléments du tableau passé comme premier argument. - Passons maintenant au cas d'un tableau bidimensionnel. On nomme
meanValue_2l'adaptation du code de la fonctionmeanValue_1à cette structure de tableau. - non seulement dans l'appel de la fonction
meanValue_2pour lui passer le nombre d'éléments du tableau, exactement comme dans l'exemple précédent (pour un tableau unidimensionnel) – sachant qu'il s'agit ici du nombre de lignes du tableau ; - mais aussi dans le corps de la fonction pour déterminer le nombre de colonnes du tableau par déréférencement du pointeur qui est transmis comme 1erargument de la fonction (
*tab– cf. la ligne nº 6). En effet, le déréférencement d'un pointeur de tableau bidimensionnel donne un pointeur de tableau unidimensionnel.
#include <stdio.h>
#include <stdint.h>
#define nbOfElements(tab) (sizeof(tab)/sizeof(tab[0]))
float meanValue_1(const int8_t * tab, size_t nbElts)
{
int sum = 0;
for (size_t i = 0; i < nbElts; i++) {
sum += tab[i];
}
return (float) sum / nbElts;
}
int main(void)
{
int8_t heatConfort[3] = {22, 17, 10};
printf("%g", meanValue_1(heatConfort, nbOfElements(heatConfort)));
return 0;
}
meanValue_1 (cf. la ligne nº 6), on a bien appliqué les deux techniques exposées supra : nbOfElements est invoquée dans l'appel de la fonction meanValue_1 (cf. la ligne nº 18) pour passer en qualité de 2e argument effectif le nombre d'éléments du tableau heatConfort qui est le 1er argument effectif de l'appel. 16.3333
#include <stdio.h>
#include <stdint.h>
#define nbOfElements(tab) (sizeof(tab)/sizeof(tab[0]))
float meanValue_2(const int8_t (* tab)[3], size_t nbLines)
{
size_t nbColumns = nbOfElements(*tab);
int sum = 0;
for (size_t j = 0; j < nbLines; j++) {
for (size_t i = 0; i < nbColumns; i++) {
sum += tab[j][i];
}
}
return (float) sum / (nbLines * nbColumns);
}
int main(void)
{
int8_t heat[2][3] = { {22, 17, 10}, {19, 15, 5} };
printf("%g", meanValue_2(heat, nbOfElements(heat)));
return 0;
}
nbOfElements : 14.6667
- Dans le programme pour tableau unidimensionnel, il n'est pas possible d'employer la pseudo‑fonction
nbOfElementspour se passer du deuxième argument formelnbEltsde la fonctionmeanValue_1. En effet, le programme suivant : - Le programme pour tableau bidimensionnel aurait pu être codé en faisant appel à la fonction
meanValue_1, qui présente l'avantage d'opérer sur un tableau unidimensionnel de n'importe quel nombre d'éléments. Il suffit pour cela : - dans l'expression d'appel de cette fonction, de convertir le tableau
heaten un tableau unidimensionnel, comme on l'a montré supra ; - et bien entendu, de coder par la multiplication :
nbOfElements(heat) * nbOfElements(heat[0])
le nombre total d'éléments à transmettre dans l'instruction d'appel.
#include <stdio.h>
#include <stdint.h>
#define nbOfElements(tab) (sizeof(tab)/sizeof(tab[0]))
float meanValue_1(const int8_t * tab)
{
int sum = 0;
for (size_t i = 0; i < nbOfElements(tab); i++) { // NOT WORKING! (random value)
sum += tab[i];
}
return (float) sum / nbOfElements(tab);
}
int main(void)
{
int8_t heatConfort[3] = {22, 17, 10};
printf("%g", meanValue_1(heatConfort));
return 0;
}
-16.5
nbOfElements(tab) prend une valeur aléatoire (ce qui est extrêmement dangereux puisque cette valeur est utilisée comme limite de parcours des éléments de tableau). nbOfElements permet d'extraire le nombre de colonnes de l'argument formel tab car cette information – la valeur 3 – est bien incluse dans la déclaration du type const int8_t (* tab)[3] de l'argument. Mais a contrario, il n'est pas possible de la même manière d'extraire le nombre de lignes car cette information est perdue lors de la transmission par adresse. Il faut donc inévitablement la passer comme 2e argument de la fonction meanValue_2.
#include <stdio.h>
#include <stdint.h>
#define nbOfElements(tab) (sizeof(tab)/sizeof(tab[0]))
float meanValue_1(const int8_t * tab, size_t nbElts)
{
int sum = 0;
for (size_t i = 0; i < nbElts; i++) {
sum += tab[i];
}
return (float) sum / nbElts;
}
int main(void)
{
int8_t heat[2][3] = { {22, 17, 10}, {19, 15, 5} };
printf("%g", meanValue_1((int8_t*) heat, nbOfElements(heat) * nbOfElements(heat[0])));
return 0;
}
Retour d'un tableau par une fonction
Comme cela a été détaillé supra , il est impossible procéder par valeur directe pour faire retourner un tableau à une fonction, tout simplement parce qu'il est impossible de former une expression dont la valeur est un tableau.
Comme pour le passage d'un argument, l'alternative consiste donc faire retourner un pointeur sur une variable préalablement déclarée de type tableau.
Ce faisant, pour éviter de recourir directement à une donnée globale (ce qui rend le code de la fonction pénible à porter dans un programme), il faut que cette variable pointée en sortie soit aussi transmisse comme argument de la fonction – et bien évidemment, par l'intermédiaire d'un pointeur.
Pour illustrer cet aspect, on peut coder toutes sortes de fonctions qui effectuent du calcul matriciel W, c'est‑à‑dire des fonctions qui font des opérations algébriques globales sur des tableaux de nombres (vecteurs, matrices).
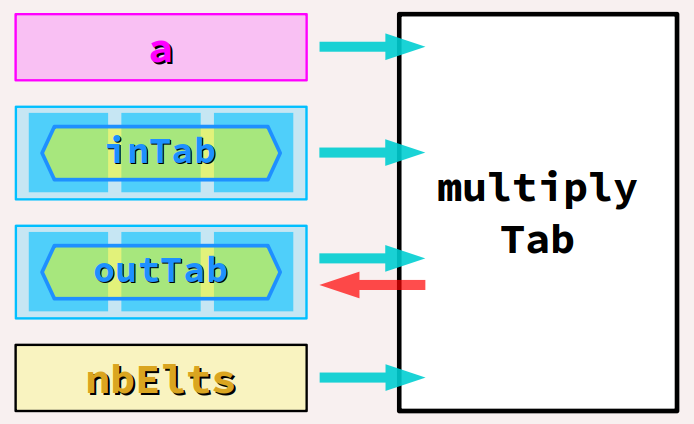
- Pour commencer, on peut facilement concevoir, de façon générale, une fonction qui multiplie par un coefficient un tableau unidimensionnel , qu'on nomme par exemple
multiplyTab, et qui prend pour argument, dans l'ordre (cf. la figure ci‑contre) : - le coefficient multiplicateur
a, - le tableau initial
inTab, - le tableau final
outTabqui est aussi la valeur de retour de la fonction, - le nombre d'éléments
nbEltsde ces deux tableaux (information indispensable, cf. supra ), lesquels ont forcément la même structure. - que l'argument
inTabdu tableau initial est déclaré avec le mot‑clefconst(cf. supra ) puisque qu'il est accédé en lecture seule par la fonction (elle n'a pas à modifier cette donnée) ; - alors qu'au contraire, l'argument
outTabdu tableau final ne doit pas être déclaré en lecture seule puisque le tableau pointé est bel et bien modifié par la fonction (c'est le but puisque c'est la valeur de retour de la fonction) ; -
nbEltsqui, comme usuellement, récupère le nombre d'éléments des tableaux pris en arguments . - Une autre approche de la multiplication d'un tableau par un coefficient consiste à procéder avec une fonction, qu'on nommera ici
multiplyTabInOutpour exprimer la particularité qu'elle emploie un seul argument formel de type pointeur de tableau, sur lequel elle produit un effet de bord voulu. Autrement dit, cet argument cumule les rôles de tableau initial et final. Les autres arguments (aetnbElts) sont inchangés.
duration – à partir d'une base de valeurs préétablie, mémorisées dans un tableau durationBase. C'est ce que met en œuvre le programme suivant.
#include <stdio.h>
#include <math.h>
#define nbOfElements(tab) (sizeof(tab)/sizeof(tab[0]))
short * multiplyTab(float a, const short * inTab, short * outTab, size_t nbElts)
{
for (size_t k = 0; k < nbElts; k++) {
outTab[k] = round(a * inTab[k]);
}
return outTab;
}
int main(void)
{
short durationBase[3] = {6, 1, 18};
short duration[3] = {0};
multiplyTab(5.0, durationBase, duration, nbOfElements(duration));
// Displaying both arrays
for (size_t k = 0; k < nbOfElements(duration); k++) {
printf("durationBase[%zu] = %2d duration[%zu] = %2d\n",
k, durationBase[k], k, duration[k]);
}
return 0;
}
multiplyTab (ligne nº 5 et suivantes), on peut remarquer : durationBase[0] = 6 duration[0] = 30 durationBase[1] = 1 duration[1] = 5 durationBase[2] = 18 duration[2] = 90
multiplyTab ignore sa valeur de retour. On pourrait alors se demander pourquoi ne pas tout simplement coder une fonction de type void ? multiplyTab est polyvalente et qu'on peut concevoir d'autres possibilités d'appel. Par exemple, on aurait pu supprimer l'instruction de la ligne nº 17 et coder la boucle itérative d'affichage, en appliquant à l'expression d'appel de la fonction multiplyTab l'opération de sélection [k] (cf. la ligne nº 12).
for (size_t k = 0; k < nbOfElements(duration); k++) {
printf("durationBase[%zu] = %2d duration[%zu] = %2d\n",
k, durationBase[k], k,
multiplyTab(5.0, durationBase, duration, nbOfElements(duration))[k]);
}
multiplyTab(5.0, durationBase, duration, nbOfElements(duration))
prend la valeur d'un pointeur de tableau, donc se comporte exactement comme un identificateur de tableau. L'opérateur de sélection vient donc tout naturellement cibler son élément d'indice
k. for. 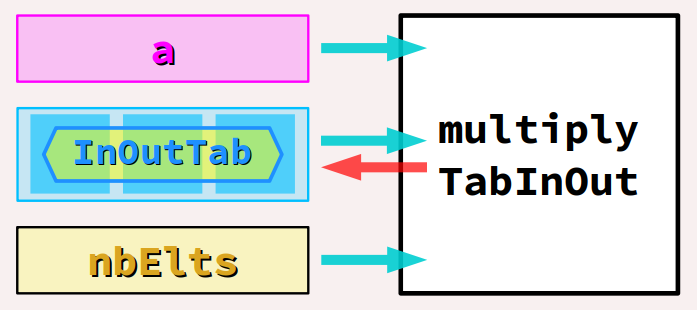
durationBase.
#include <stdio.h>
#include <math.h>
#define nbOfElements(tab) (sizeof(tab)/sizeof(tab[0]))
short * multiplyTabInOut(float a, short * inOutTab, size_t nbElts)
{
for (size_t k = 0; k < nbElts; k++) {
inOutTab[k] = round(inOutTab[k] * a);
}
return inOutTab;
}
int main(void)
{
short durationBase[3] = {6, 2, 18};
multiplyTabInOut(1.5, durationBase, nbOfElements(durationBase));
printf("After multiplication:\n");
for (size_t k = 0; k < nbOfElements(durationBase); k++) {
printf("durationBase[%zu] = %2d\n", k, durationBase[k]);
}
return 0;
}
After multiplication: durationBase[0] = 9 durationBase[1] = 3 durationBase[2] = 27
multiplyTabInOut dans la boucle for d'affichage, sinon on effectuerait 3 fois la multiplication par le coefficient a. addArray pour ajouter une valeur b à tous les éléments d'un tableau comme ci‑dessous (avec la même syntaxe que multiplyTab) :
short * addTabInOut(float b, short * inOutTab, size_t nbElts)
{
for (size_t k = 0; k < nbElts; k++) {
inOutTab[k] += b;
}
return inOutTab;
}
addTabInOut(2.0, multiplyTabInOut(1.5, durationBase, nbOfElements(durationBase)),
nbOfElements(durationBase));
2.0 à chaque élément du tableau duration après les avoir multipliés par 1.5. Ce code est équivalent à : multiplyTabInOut(1.5, durationBase, nbOfElements(durationBase)); addTabInOut(2.0, durationBase, nbOfElements(durationBase));
Syntaxe explicite d'un argument de fonction de type tableau
Dans l'en‑tête d'une fonction, la syntaxe de codage d'un argument formel de type tableau sous forme de pointeur peut sembler obscure pour les codeurs débutants. En effet, à moins que l'identificateur de l'argument soit explicite, la seule lecture du prototype de la fonction ne permet pas de savoir s'il s'agit d'un pointeur de donnée scalaire ou de type tableau. De plus, la syntaxe de codage peut devenir vraiment complexe s'il s'agit d'un tableau de pointeurs – ou pire encore, s'il s'agit en plus de pointeurs de fonctions.
Pour une meilleure lisibilité du code, il est donc recommandé d'adopter la syntaxe explicite de codage des tableaux avec le symbole déclaratif des crochets [], c'est‑à‑dire de la forme :
(descripteur de type identificateur de tableau[] …)
En effet, parce que cet élément de code n'est pas une déclaration de donnée (mais d'un argument de fonction), l'identificateur de tableau est converti en pointeur sur son premier élément, donc cette forme syntaxique est en fait équivalente à celle‑ci, moins lisible :
(descripteur de type * identificateur de tableau …)
Reprenons les exemples supra sur le thème d'un système de chauffage à thermostat. Les en‑têtes des fonctions firstRelDiff_1 et firstRelDiff_2 qui calculent la différence relative des deux premiers éléments d'un tableau de consignes de température, respectivement uni et bidimensionnel, avaient été codées initialement :
float firstRelDiff_1(int8_t * tab)
float firstRelDiff_2(int8_t (*tab)[3])
Pour une meilleur lisibilité, il est préférable de les coder avec la syntaxe explicite, respectivement comme ci‑dessous :
float firstRelDiff_1(int8_t tab[]) // more readable
float firstRelDiff_2(int8_t tab[][3]) // more readable
En effet, on voit ainsi tout de suite que l'argument formel tab de la fonction est un tableau, unidimensionnel dans le premier cas, bidimensionnel dans le second.
- En termes de résultat de compilation, on a vraiment une équivalence totale des deux syntaxes, au point qu'il est possible d'adopter l'une dans le prototype de la fonction et l'autre dans l'en‑tête qui précède son corps de définition – et vice‑versa. Évidemment, une telle hétérogénéité de codage n'est pas recommandée, par souci évident de lisibilité.
- Avec la syntaxe explicite, il est également possible – dans un but purement informatif pour les lecteurs d'un programme source – de coder le nombre d'éléments du tableau entre les crochets, comme par exemple ci‑dessous :
float firstRelDiff_1(int8_t tab[3]) // NOT RECOMMENDED! // ^ any number may be typed
[ ] ci‑dessus, car ce nombre est tout simplement ignoré par le compilateur ! Impossibilité de la syntaxe explicite pour le type des valeurs de retour d'une fonction
La syntaxe explicite de codage d'un argument formel de fonction de type pointeur de tableau, que l'on vient juste d'exposer, ne peut pas s'appliquer pour coder le type des valeurs de retour d'une fonction.
En effet, le codage du type de la valeur de retour d'une fonction s'effectue dans le cadre d'une déclaration dont l'identificateur de la fonction est l'objet. Donc si cet identificateur était codé comme étant de type tableau, il ne serait pas converti en pointeur mais interprété comme comme un tableau (ce qui n'est pas possible puisqu'il s'agit d'une fonction).
Reprenons un exemple supra sur le thème d'un feu tricolore. L'en‑tête de la fonction multiplyTab qui multiplie les valeurs des éléments d'un tableau par un coefficient et dont la valeur de retour est un pointeur sur le tableau modifié est codé ainsi :
short * multiplyTab(…
Il ne peut pas se coder :
short multiplyTab[](…
ni même :
short multiplyTab(…)[]
Dans les deux cas, le compilateur signalerait une erreur de syntaxe.
Emploi des tableaux
Dans les systèmes administratifs, scientifiques ou techniques, de nombreuses données présentent de toute évidence une structure de tableau : calendrier, relevés de mesures, valeurs de fonctions, vecteurs et matrices, etc. Même pour des données en petits nombres (déjà à partir de deux ou trois), il est très fréquent de recourir à des tableaux pour les structurer. Et lorsque leur nombre augmente (jusqu'à des millions…), on a intérêt à structurer les tableaux sur plusieurs dimensions pour accélérer les temps de traitements (tri, recherche d'éléments, etc.).
En programmation, on recourt donc à une utilisation massive des tableaux pour structurer les données. Et il existe de nombreuses bibliothèques de fonctions opérant sur les tableaux. Elles seront évoquées en fin de chapitre.
Dans le cadre d'un cours d'initiation comme ici, il est difficile de donner un aperçu réaliste de cette multitude d'applications. Les exemples académiques proposés dans ce chapitre et les précédents (C2‑VI , C5‑III ), de même que ceux donnés ci‑après en complément, ne sont nullement représentatifs d'une quelconque exhaustivité. Ils ont simplement pour vocation à illustrer quelques techniques générales de codage indispensables pour un programmeur débutant.
D'autres exemples académiques
On va voir ici comment coupler la déclaration d'un tableau à celle d'un type énuméré pour pouvoir identifier nommément un élément d'un tableau plutôt que par son indexation qui est un numéro souvent arbitraire.
Exemple 1 – Valeurs des cartes du jeu de Belote
Au chapitre C3‑IV , on avait présenté un exemple de déclaration d'un type énuméré, dont les constantes donnaient les valeurs (en points) des cartes à l'atout pour le jeu de la Belote :
enum Atout {
SEPT = 0, HUIT = 0,
DAME = 3, ROI = 4,
DIX = 10, AS = 11,
NEUF = 14, VALET = 20
};

Toutefois, cette solution n'est pas satisfaisante car, pour gérer une partie et compter les points, il faut aussi mémoriser les valeurs des cartes des autres couleurs (non atout). Or il n'est pas possible de définir un deuxième type énuméré avec les mêmes identificateurs de noms de cartes.
Une manière de résoudre ce problème consiste par exemple à déclarer les valeurs des cartes en les structurant en deux tableaux unidimensionnels, comme ci‑dessous.
const uint8_t POINTS_COULEUR[8] = {0, 0, 0, 10, 2, 3, 4, 11};
const uint8_t POINTS_ATOUT[8] = {0, 0, 14, 10, 20, 3, 4, 11};
De plus, pour conserver la lisibilité qu'apporte le type énuméré supra, on peut coder la déclaration complémentaire suivante :
enum Cartes {SEPT, HUIT, NEUF, DIX, VALET, DAME, ROI, AS};
où les constantes sont déclarées sans valeur explicite dans le même ordre que les valeurs des points dans les tableaux ci‑dessus. Ainsi, ces constantes énumérées SEPT, HUIT, NEUF, etc. prennent implicitement les valeurs :
0, 1, 2, etc.
qui correspondent respectivement aux numéros d'indice des valeurs de points des cartes mémorisées dans les tableaux POINTS_COULEUR et POINTS_ATOUT. Donc, l'expression :
POINTS_ATOUT[VALET]
vaut 20 conformément aux règles du jeu, et elle est bien plus lisible que :
POINTS_ATOUT[4] // less readable
Par ailleurs, les deux tableaux POINTS_COULEUR et POINTS_ATOUT ayant la même structure, on peut déclarer préalablement un type synonyme PointsCartes puis déclarer les deux tableaux pointsCouleur et pointsAtout.
typedef const uint8_t PointsCartes[8];
PointsCartes POINTS_COULEUR = {0, 0, 0, 10, 2, 3, 4, 11};
PointsCartes POINT_ATOUT = {0, 0, 14, 10, 20, 3, 4, 11};
Toujours dans un souci de rationalisation du code, et partant du constant que les deux tableaux ont la même structure, on peut aussi opter de les fusionner dans un tableau bidimensionnel :
- la dimension externe (lignes) distinguant la catégorie de la carte, selon qu'il s'agit de l'atout ou d'une autre couleur ;
- la dimension interne (colonnes) codant l'ordre des cartes (sept, huit, etc.) comme dans les tableaux unidimensionnels précédent.
Et comme pour l'ordre des cartes, il est commode de définir un autre type énuméré pour identifier de façon plus lisible les indices de catégories de cartes. En reprenant tout ces aspects, cela donne les déclarations suivantes :
const uint8_t POINTS[2][8] = {
{0, 0, 14, 10, 20, 3, 4, 11}, // atout
{0, 0, 0, 10, 2, 3, 4, 11} // couleur
};
enum Categories {ATOUT, COULEUR};
enum Cartes {SEPT, HUIT, NEUF, DIX, VALET, DAME, ROI, AS};
Ainsi, l'expression :
points[ATOUT][VALET]
vaut 20 comme précédemment et elle est bien plus lisible que :
POINTS[0][4] // less readable
Exemple 2 – Mapping sur un port d'entrées‑sorties d'une carte électronique
Lorsqu'on relie des composants aux broches d'un port d'entrées‑sorties d'une carte à microcontrôleur (Arduino ou autre…), il n'est pas toujours possible de respecter les contraintes de successions souhaitables pour les traitements répétitifs comme la déclaration des modes de fonctionnement des broches, les pilotages groupés (allumer une série de led), etc.
Une solution consiste alors à déclarer un voire plusieurs tableaux qui regroupent par domaines d'emplois les numéros de broches des ports d'entrée‑sortie de la carte. Les traitements répétitifs sont alors faciles à coder en utilisant l'indexation des tableaux dans des boucles itératives (for). On parle de mapping.
Et encore une fois, en complément des tableaux déclarés, on peut s'appuyer sur un ou plusieurs types énumérés pour améliorer la lisibilité de l'indexation des éléments du tableau.
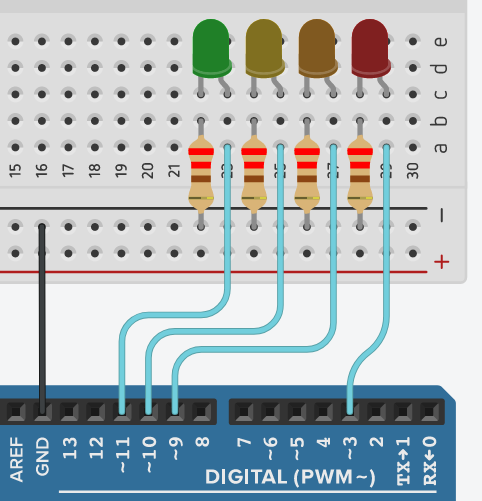
Sur une carte Arduino Uno, on souhaite commander en luminosité variable une série de 4 leds de couleurs différentes (verte, jaune, orange, rouge, par exemple). Malheureusement, sur ce modèle de carte, seules les broches 35691011 disposent de la fonctionnalité PWM requise (cf. chap. C3‑VII ) ; parmi elles, il n'y a donc pas 4 broches consécutives.
Pour surmonter cette difficulté, on peut par exemple déclarer un tableau de mapping d'entrées‑sorties VAR_LED_PIN et un type énuméré VarLedColor associé, dont les constantes sont listées dans l'ordre d'indexation des couleurs des led reliées aux broches sélectionnées, comme ci‑dessous :
const uint8_t VAR_LED_PIN[4] = {3, 9, 10, 11};
enum VarLedColor : uint8_t {RED, ORANGE, YELLOW, GREEN};
On peut ensuite très efficacement coder des traitements répétitifs sur ces broches, ainsi que des actions particulières de façon très lisible, comme par exemple dans le programme de démonstration ci‑dessous, qui peut être testé sous Tinkercad :
const uint8_t VAR_LED_PIN[4] = {3, 9, 10, 11};
enum VarLedColor : uint8_t {RED, ORANGE, YELLOW, GREEN};
#define nbOfElements(tab) (sizeof(tab)/sizeof(tab[0]))
void setup()
{
for (uint8_t k = 0; k < nbOfElements(VAR_LED_PIN); k++) {
pinMode(VAR_LED_PIN[k], OUTPUT);
analogWrite(VAR_LED_PIN[k], 0);
}
}
void loop()
{
analogWrite(VAR_LED_PIN[YELLOW], 128);
delay(10); // only for Tinkercad simulation
}
- Dans la fonction
setup, on a codé la configuration des broches par une boucle d'itérationsfordont la variable d'itérationkbalaye tous les indices du tableau de mapping pour cibler chacune des led qu'il répertorie (cf. les lignes nº 8 à 10). - Dans la fonction
loop, on a codé l'action particulière d'allumage de la led jaune avec une luminosité intermédiaire de façon très lisible grâce à la constante énuméréeYELLOWqui cible l'indice du numéro de broche de la led dans le tableau de mapping (cf. la ligne nº 16).
Bibliothèques de fonctions opérant sur tableaux
En langage C

En langage C, il existe quelques fonctions opérant sur les tableaux, déclarées dans le fichier d'en‑tête stdlib.h W de la bibliothèque standard (cf. chap. C4‑VII ). On trouve notamment les fonctions qsort (tri dans l'ordre croissant par l'algorithme quick sort des éléments d'un tableau) et bsearch (recherche par l'algorithme binary search d'un élément dans un tableau d'éléments triés par ordre croissant).
Les fonctions qsort et bsearch sont particulièrement intéressantes à étudier car elles sont conçues pour être opérationnelles quel que soit le type des éléments du tableau manipulé.
Ainsi, le prototype de la fonction qsort C :
// sort elements in an array of any type
void qsort( void * ptr, size_t count, size_t size,
int (* comp)(const void *, const void *) );
fait apparaître les 4 arguments formels suivants :
-
ptrest le pointeur vers le tableau à trier, ce dernier étant pris à la fois comme entrée et sortie de la fonction. -
countest le nombre d'éléments du tableau à trier, indispensable pour que la fonction puisse balayer tous les éléments (cf. supra ). -
sizeest la taille d'un élément du tableau à trier. -
compest un pointeur de fonction sur la fonction à coder pour effectuer la comparaison des éléments intrinsèque au tri. - Bien entendu, les deux arguments de cette fonction sont déclarés de type
void, c'est‑à‑dire comme des pointeurs génériques, pour pouvoir s'adapter à n'importe quel type d'éléments à comparer (ceux du tableau). - De plus, comme il s'agit d'une transmission par adresse et que les valeurs des éléments à trier doivent rester non modifiables, ces pointeurs sont déclarés avec le mot‑clef
const– ce sont des pointeurs en « lecture seule » (cf. chap. C5‑I ).
void indique qu'il s'agit d'un pointeur générique (cf. chap. C5‑II , afin qu'il puisse accepter un tableau d'éléments de n'importe quel type. La fonction de comparaison qui sera transmise comme argument effectif pour comp reste à coder par l'utilisateur de la fonction qsort. En notant respectivement a et b ses deux arguments, elle doit retourner :
- une valeur négative si a est considéré inférieur à b ;
- une valeur positive si a est considéré supérieur à b ;
-
0si a est considéré équivalent à b.

Pour illustrer une possibilité d'emploi de la fonction qsort, reprenons l'exemple d'un tableau de relevés mensuels de température donné au chap. C2‑VI (station de Versailles La Lanterne, année 2020 ). Il peut être intéressant de trier les données de ce tableau.

Dans le programme ci‑dessous :
- puisque les valeurs des éléments sont de type
float, on peut définir la fonction de comparaisoncompare_floatsà l'aide des opérateurs<et>; - l'appel de la fonction
qsortest codé à la ligne nº 15.
#include <stdio.h>
#include <stdlib.h>
int compare_floats(const void * a, const void * b)
{
const float A = *((const float*) a);
const float B = *((const float*) b);
if (A < B) return -1;
if (A > B) return +1;
return 0; // in all other cases
}
#define NB_MONTHS 12
int main(void)
{
float monthlyTempC[NB_MONTHS] = {6.0, 8.7, 8.1, 13.1, 14.3, 17.3, 19.2, 21.2, 17.2, 12.2, 9.3, 6.2};
qsort(monthlyTempC, NB_MONTHS, sizeof(float), compare_floats);
for (size_t k = 0; k < NB_MONTHS; k++) {
printf("%g ", monthlyTempC[k]);
}
printf("\n");
return 0;
}
Exécuté sur OnlineGDB, ce programme produit la sortie attendue. Les valeurs de température mensuelle du tableau ont bien été classées par ordre croissant (l'association aux numéros des mois respectifs à ces valeurs est donc perdue) :
6 6.2 8.1 8.7 9.3 12.2 13.1 14.3 17.2 17.3 19.2 21.2
Remarques. Dans l'en‑tête de la fonction compare_floats, les deux arguments formels a et b sont codés comme des pointeurs génériques. C'est une condition nécessaire pour qu'elle soit compatible avec le pointeur de fonction déclaré comme argument de la fonction qsort.
Le typage spécifique des objets manipulés par ces pointeurs intervient seulement dans le corps de la fonction (cf. les lignes nº 6 & 7), par déclaration de deux constantes locales A et B : elles sont initialisées par une après une conversion explicite de a et b avec le nom de type const float * puis déréférencement.
Par ailleurs, dans la bibliothèque standard du langage C, on trouve fichier d'en‑tête string.h, qui est consacré aux chaînes de caractères dites de « style C ». Comme on l'a brièvement expliqué au chap. C2‑VII , ces chaînes sont encodées comme des tableaux d'octets de longueur déterminée, dont la fin de la partie réputée pleine est marquée par le caractère NUL.
Les fonctions déclarées dans string.h seront étudiées au chapitre C5‑VI .
En langage C++

En langage C++, on trouve bien entendu les éléments de code correspondant du C, respectivement déclarés dans les fichiers cstdilib et cstring (et il existe aussi le module spécifique string, beaucoup plus puissant, car basé sur la notion de classe – cf. chap. C5‑VI ).
Mais surtout, on trouve plusieurs modules de la bibliothèque standard consacrés aux tableaux qui n'existent pas en C : vector, array, valarray C++.
Par ailleurs, d'autres modules de bibliothèque non standards ont été développés pour mettre en œuvre du calcul numérique vectoriel et matriciel (algèbre linéaire – cf. W). Là encore, il n'est pas question ici de présenter ces modules très techniques, qui sont tous codés dans le cadre de la programmation orientée objet, mais de simplement mentionner leur existence…