Les données déclarées constantes ou variables sont la matière d'œuvre sur laquelle un programme agit. Après l'étude des types (partie C3 du module) qui constituent un aspect primordial dans la déclaration d'une donnée, on aborde maintenant deux autres caractéristiques qui pourraient a priori paraître secondaires, mais qui sont néanmoins fondamentales : la portée et la durée de vie d'une donnée.
- La portée caractérise le fait qu'une donnée déclarée soit accessible en lecture et éventuellement en écriture (s'il s'agit d'une variable) :
- ou bien de façon globale, c'est‑à‑dire partout dans le code après sa déclaration ;
- ou bien de façon locale, c'est‑à‑dire seulement dans une partie limitée du code – typiquement, un bloc, et en particulier celui qui définit la fonction dans laquelle la donnée est déclarée.
- La durée de vie caractérise le fait qu'une donnée déclarée existe :
- soit de manière permanente, c'est‑à‑dire durant toute l'exécution du programme ;
- soit de manière temporaire au cours du processus d'exécution du programme – typiquement, seulement durant les appels de la fonction où la donnée est déclarée.
Ces deux caractéristiques sont étroitement liées aux mécanismes d'allocation mémoire, c'est‑à‑dire à la façon dont une donnée déclarée se voit attribuer un espace de stockage pour mémoriser sa valeur dans la machine lors de l'exécution du programme. Cet espace de stockage est repéré par une adresse dans l'espace mémoire global attribué au programme durant son exécution. Bien entendu, les mécanismes d'allocation dépendent de l'architecture matérielle (microprocesseur ou microcontrôleur, mémoire vive, bus…) et des aspects logiciels de bas niveau du système d'exploitation (jeu d'instruction, gestion de la mémoire…) ou de son fonctionnement primitif (dans le cas d'une carte à microcontrôleur).
En règle générale, dans la plupart des langages de programmation, c'est le positionnement dans le code d'une déclaration de donnée qui détermine sa portée et sa durée de vie. Mais en C et C++, il est possible d'imposer une classe d'allocation particulière à une donnée – la classe statique – pour rendre permanente une donnée locale déclarée dans un bloc. Cette possibilité est essentielle pour éviter le recours à trop de données globales dont le principal inconvénient est la visibilité totale, qui expose au risque de modifications indésirables dans le cadre du développement de gros programmes.
Tous ces aspects pourraient sembler secondaires dans un module de formation initiale à la programmation. Ils sont pourtant essentiels dans la perspective d'aborder la programmation modulaire, dont on ne cesse de souligner l'importance. Le présent chapitre y est donc entièrement consacré, avec l'objectif de les présenter simplement dans l'ordre de cette introduction :
- tout d'abord la notion de portée d'une donnée, et la visibilité qui en découle ;
- puis la notion de durée de vie d'une donnée, où l'on aborde les différentes zones d'allocation de mémoire et les mécanismes qui les régissent ;
- enfin, la notion de classe d'allocation de mémoire et les possibilités de codage afférentes à cette notion.
Portée d'une donnée – notion de niveau visibilité
Niveau d'une donnée déclarée
On a vu au chapitre C4‑I qu'en langages C et C++, le code source d'un programme est essentiellement constitué de fonctions, chacune étant définie par un bloc d'instructions délimité par des accolades { }. De plus, un bloc de définition de fonction peut lui‑même contenir d'autres blocs, notamment de structures de contrôle (if, while, etc).
Dans un fichier source, le niveau de visibilité d'une donnée déclarée est le numéro d'ordre hiérarchique du bloc dans lequel elle est déclarée :
- en partant de 0 pour le niveau le plus bas, c'est‑à‑dire hors de tout bloc – y compris celui de la fonction principale
main; - en incrémentant de 1 à chaque encapsulation dans un bloc.
De plus, un argument formel de fonction peut être vu comme une donnée déclarée au tout début du bloc de définition de cette fonction.
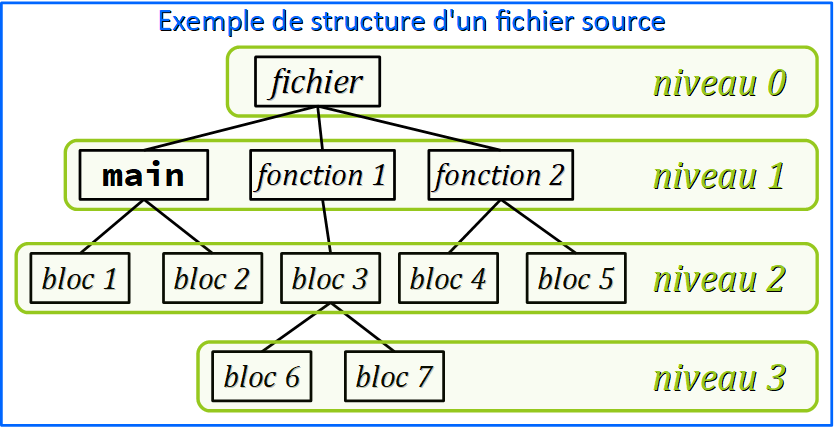
Partant de la structuration du code source en fonctions — selon le principe de programmation procédurale (cf. chap. C1‑I ) – on peut modéliser tout fichier source par une structure en arbre dont :
- la racine est le niveau 0 ;
- chaque niveau hiérarchique 1, 2, 3… comporte éventuellement plusieurs branches indépendantes.
La connaissance de cette structure est utile pour déterminer la visibilité d'une donnée dans telle ou telle branche, et à tel ou tel niveau.
Notion de donnée déclarée globale ou locale
Dans un fichier source, on dit d'une donnée déclarée qu'elle est :
Cette distinction « globale/locale » joue un rôle primordial dans le cadre d'une programmation multi‑fichiers. En effet, lorsqu'on code une directive d'inclusion d'un fichier d'en‑tête dans un fichier source, il en résulte la fusion des niveaux 0 de ces fichiers. Ainsi, toutes les données globales déclarées dans ce fichier d'en‑tête de bibliothèque sont également globales dans le fichier principal.
Reprenons une version du programme académique ayant servi d'exemple au chapitre C4‑I pour illustrer la notion de fonction. Ce programme teste en boucle si deux nombres entiers strictement positifs saisis par l'utilisateur sont premiers entre eux.
Dans le code, on a ajouté des commentaires pour indiquer les différents niveaux de ce programme – et ce même si, pour certains niveaux, aucune variable n'est déclarée.
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
/* ========================= LEVEL 0 ======================= */
// function prototypes
void enteringNumber(unsigned n, unsigned * number);
bool arePrime (unsigned a, unsigned b);
int main(void)
{ /* ======================= MAIN - LEVEL 1 ======================= */
unsigned number1 = 0, number2 = 0;
while (true) {
/* ===================== MAIN - LEVEL 2 ======================= */
enteringNumber(1, &number1);
enteringNumber(2, &number2);
if (arePrime(number1, number2)) {
/* ===================== MAIN - LEVEL 3 ======================= */
printf("%u et %u sont PREMIERS ENTRE EUX.\n", number1, number2);
}
else {
/* ================== MAIN - OTHER LEVEL 3 ==================== */
printf("%u et %u ne sont PAS premiers entre eux.\n", number1, number2);
}
}
}
/* ========================= LEVEL 0 ======================= */
void enteringNumber(unsigned n, unsigned * number)
{ /* ======================= FUNCTION1 - LEVEL 1 ======================= */
printf("Nombre entier %u (0 pour sortir): ", n);
scanf("%u", number);
}
/* ========================= LEVEL 0 ======================= */
bool arePrime (unsigned a, unsigned b)
{ /* ======================= FUNCTION2 - LEVEL 1 ====================== */
if (a == 0 || b == 0) exit(1); /* <---- LEVEL 2 */
while (b != 0) {
/* ======================= FUNCTION2 - LEVEL 2 ====================== */
unsigned c = b;
b = a % b;
a = c;
}
/* ======================= FUNCTION2 - LEVEL 1 ====================== */
return (a == 1);
}
/* ========================= LEVEL 0 ======================= */
On va voir infra comment les données déclarées se répartissent sur les différents niveaux identifiés.
Notions de visibilité et de portée d'une donnée déclarée
On dit qu'une donnée déclarée est visible dans une partie du code source si son identificateur peut y être employé dans les expressions sans provoquer d'erreur de compilation au motif qu'il est inconnu.
On appelle portée W ou espace de visibilité – en anglais, scope – de la donnée toute la partie du code où elle est visible.
Le terme « visibilité » est parfois aussi employé pour qualifier dans quelle mesure une donnée est accessible dans sa portée, c'est‑à‑dire le fait qu'elle soit « publique », « privée », etc.
Ces aspects plus spécifiques seront revus lors de l'étude de la programmation orientée objet.
Relation entre la visibilité et le niveau d'une donnée déclarée
Une donnée déclarée de niveau N est :
- visible dans le bloc où elle est déclarée – donc y compris à l'intérieur des blocs encapsulés dans son bloc – mais attention, seulement dans la partie du bloc située après sa déclaration ;
- invisible avant sa déclaration ainsi que dans tous les niveaux inférieurs à sa déclaration – c'est‑à‑dire dans les blocs qui encapsulent le sien – et aussi dans tous les autres blocs qui ne partent pas de la branche où elle est déclarée.
Dans le programme académique commenté supra :
- il n'y a aucune variable globale ;
- les variables locales
number1etnumber2sont visibles dans toute la fonctionmainpuisqu'elles sont déclarées au tout début de cette dernière ; - les arguments formels
aetbde la fonctionarePrimesont aussi considéré comme des variables locales ; ils sont visibles seulement dans le bloc de définition de cette fonction ; - la variable locale
cest visible seulement dans le bloc de la bouclewhilede la fonctionarePrime.
Surcharge d'un identificateur de donnée – notion de masquage
En programmation, on parle de surcharge d'un identificateur de donnée lorsque ce dernier désigne, à lui seul, plusieurs données distinctes dans le code source d'un programme.
Cela peut surprendre, mais les langages C et C++ autorisent la surcharge d'un identificateur de donnée si les déclarations dont il fait l'objet sont toutes inscrites dans des niveaux ou des branches différentes.
Dans ce cas, le compilateur interprète toutes les déclarations d'un même identificateur comme autant de données différentes. Pour dissiper toute éventuelle confusion que pourrait faire un codeur débutant, la surcharge ne permet donc pas de changer le type d'une même donnée.
Dans son espace de visibilité, une donnée déclarée à un niveau N masque toutes celles qui portent le même identificateur dès lors qu'elles sont déclarées à un niveau inférieur à N.
Cette pratique est néanmoins peu recommandée, dans la mesure où elle peut se révéler défavorable à la lisibilité du code.
Dans l'environnement Arduino, on code le programme académique volontairement confus ci‑dessous qui crée trois variables ayant le même identificateur foo. On leur donne des types différents pour bien les distinguer.
/* ============ (LEVEL 0 - GLOBAL) */
float foo = 0.0; // declaration of var. "foo #1"
void setup()
{ /* ============ (LEVEL 1 - SETUP) */
Serial.begin(9600);
foo = 1.1; // assignment of "foo #1"
Serial.println(foo); // display on the monitor -> 1.10
int foo = 0; // declaration of var. "foo #2"
foo = 2.1; // assignment of "foo #2"
Serial.println(foo); // display on the monitor -> 2 (int)
}
void loop()
{ /* =========== (LEVEL 1 - LOOP) */
Serial.println(foo); // display on the monitor -> 1.10
bool foo = true; // declaration of var."foo #3"
Serial.println(foo); // display on the monitor -> 1 (true)
delay(100000);
}
Remarques.
- À la ligne nº 10, la valeur affectée à la variable
foo« #2 » n'est pas2.1mais2(affichée à la ligne nº 11). En effet, comme cette variablefooest déclarée typeint, le compilateur tronque sa valeur par ajustement de type (cf. chap. C3‑VI ). - À la ligne nº 15, la valeur affichée sera
1.10car il s'agit de la variablefoo« #1 » (globale). En effet : - elle n'est plus masquée par la variable locale
foo« #2 » – cette dernière n'existant pas en dehors de la fonctionsetup; - elle n'a pas changé de valeur depuis son affectation de la ligne nº 7.
Durée de vie d'une donnée – allocation de mémoire
Pour bien comprendre la notion qui va être abordée de durée de vie d'une donnée déclarée, il est nécessaire de connaître les bases de l'allocation de la mémoire vive durant l'exécution d'un programme compilé. Comme toujours avec les mécanismes de bas niveau, on est confronté à une technologie complexe qui dépend de l'architecture de la machine cible – celle sur laquelle le programme doit s'exécuter (cf. chap. C1‑II ). Il n'est pas question ici de détailler cette technologie mais d'en exposer seulement quelques grands principes. Pour plus d'explications, on pourra se reporter à ces articles comme point de départ W .
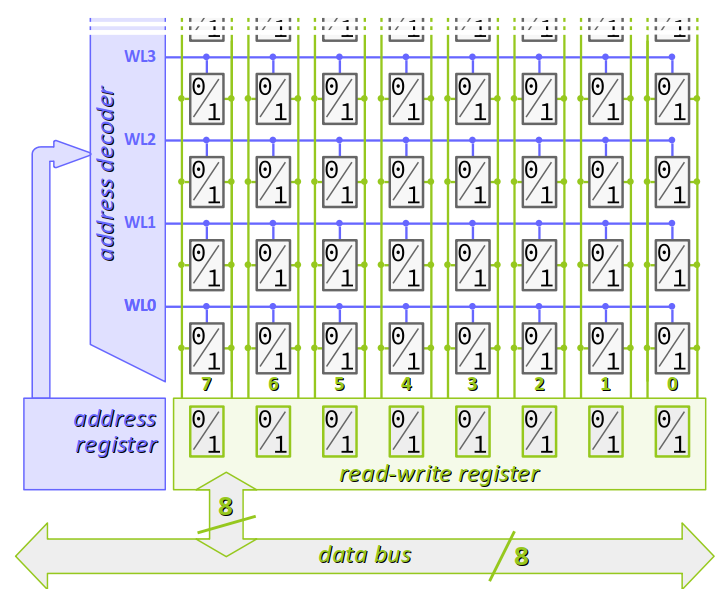
On rappelle avant tout que la mémoire vive d'une machine est matériellement implémentée par des circuits matriciels spécialisés (cf. chap. C3‑I et la figure ci‑contre en rappel). D'un point de vue logiciel, quelle que soit la largeur en bits de l'architecture de la machine, on peut voir cette mémoire comme un très grand tableau d'octets, chacun étant indexé par une adresse.
Dans ce tableau, l'adresse d'un élément (donnée, fonction) est celle de son premier octet.
Mécanismes d'allocation de mémoire
Pour être précis, on doit distinguer deux cas, selon que la machine cible du programme est :
- un ordinateur (PC, serveur, carte Raspberry Pi…), c'est‑à‑dire une machine sur laquelle s'exécute un système d'exploitation qui gère simultanément de nombreux processus partageant la mémoire vive (on se basera sur des expérimentations de programmes compilés avec GCC sous Linux) ;
- ou une carte à microcontrôleur (Arduino, ESP32, etc.), c'est‑à‑dire une machine sans système d'exploitation et qui gère un seul programme utilisateur – lequel dispose donc de toute la mémoire vive (on se basera sur des expérimentations de programmes compilés avec GCC sur une carte Arduino Uno).


Les explications qui suivent sont seulement valables pour le cas simple d'un petit programme. Elles ne prennent pas en considération les conséquences d'un éventuel parallélisme d'exécution (multithreading – cf. chap. C1‑I W) en termes d'allocation mémoire.

De plus, les explications qui suivent sont en décalage avec la littérature (Wikipedia, etc.) qui, malheureusement, donne une représentation académique dépassée en termes de segmentation de la mémoire. Elle ne correspond plus à la réalité des chaînes de compilation et des systèmes d'exploitation modernes.
Cas d'une machine cible de type ordinateur
Sur une machine cible de type ordinateur, au lancement de l'exécution d'un programme compilé, son code exécutable est placé en mémoire vive par le chargeur de programmes (cf. chap. C4‑IV )). Il se voit ainsi allouer un espace mémoire délimité entre une adresse basse et une adresse haute, avec un intervalle potentiellement très grand, même pour un petit programme.
Mais, chose essentielle, l'espace mémoire alloué est adressé de façon virtuelle par le noyau du système d'exploitation W – à charge pour le contrôleur mémoire W de déterminer les emplacements physiques réels de stockage de tel ou tel mot.
La virtualisation apporte une grande souplesse : si la mémoire RAM vient à faire défaut, une fraction du disque dur de la machine peut être sollicitée comme espace d'échange pour s'y substituer (c'est la technique dite de swap W), sans qu'il soit nécessaire de changer l'espace d'adressage.
Sur une machine 64 bits W, les adresses virtuelles sont encodées sur 48 bits, autrement dit elles sont exprimées sur 12 digits hexadécimaux. Cette implémentation octroie environ 2,8 ×1014 adresses – soit aujourd'hui de l'ordre de dix‑mille fois plus que le nombre d'octets de mémoire RAM réellement disponibles sur les machines usuelles – typiquement, 16 ×109 !

Par ailleurs, les adresses virtuelles délimitant l'espace mémoire alloué au programme sont déterminée aléatoirement, selon un mécanisme appelé ASLR - pour address space layout randomization W. Cela permet de compliquer les possibilités d'attaque, notamment celles par buffer overflow W.
D'un point de vue macroscopique, l'espace mémoire alloué au programme se décompose en deux zones principales, l'une dite statique, l'autre dynamique. Et pour prévenir toute confusion grossière, précisons bien que ces qualificatifs ne caractérisent pas la technologie matérielle de la mémoire vive de la machine – SRAM ou DRAM – mais la façon dont ces deux zones sont gérées d'un point de vue logiciel.
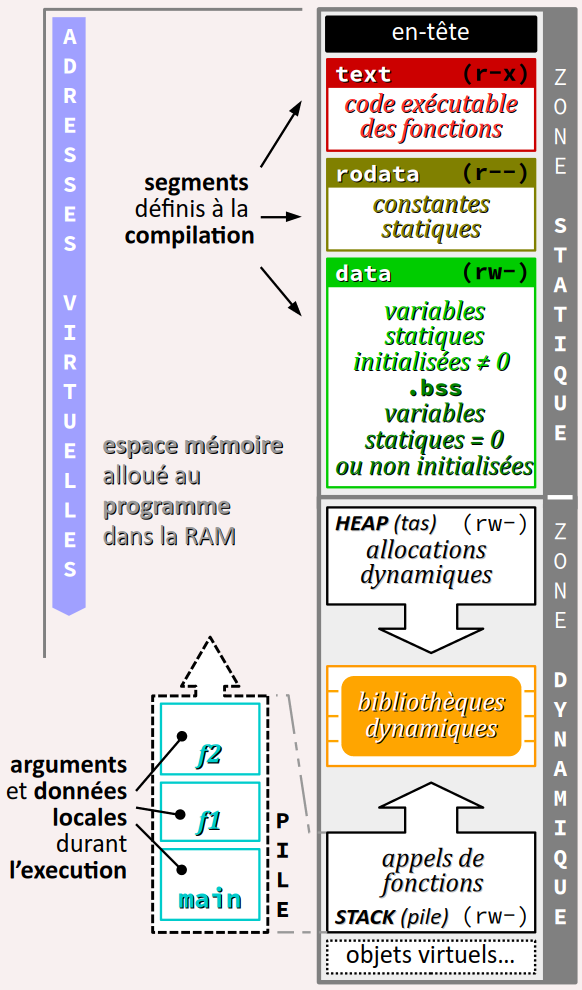
La zone statique est définie lors de génération du code exécutable du programme (compilation, etc.). Comme son nom l'indique, sa structure n'est pas susceptible de changer durant l'exécution du programme. En principe, elle comporte entre autre les 3 segments principaux suivants :
-
textW, accessible en lecture seule et exécutable (coder-x), est le segment où est copié le code objet des fonctions définies par le programme. -
rodataW, accessible en lecture seule (coder--– le préfixe «ro» formant les initiales de read‑only), est le segment où sont copiées les constantes globales ou statiques (cf. infra ) déclarées dans le programme, ainsi que les constantes littérales chaînes de caractères (cf. chap. C2‑VII ). -
dataW, accessible en lecture/écriture (coderw-) est le segment où sont stockées les valeurs des variables déclarées globales ou statiques.
.bss W (pour block starting symbol), réservée aux variables non initialisées ou encore initialisées avec la valeur 0 lors de leur déclaration dans le code source (les variables non initialisées se voyant automatiquement attribuer la valeur 0 par défaut). Ces segments sont répartis en respectant des alignements de pagination typiquement de 4 ko – plus précisément, 0x1000, soit 4096 octets. Par exemple, si un segment se termine à l'adresse 0x2100, le segment suivant commence à l'adresse 0x3000.
Quant à la zone zone dynamique, elle comporte essentiellement deux régions accessibles en lecture/écriture et ayant une taille variable durant l'exécution. Pour optimiser l'usage de cette zone, elles sont « diamétralement disposées » et séparées par les segments des éventuelles bibliothèques dynamiques exploitées par le programme.
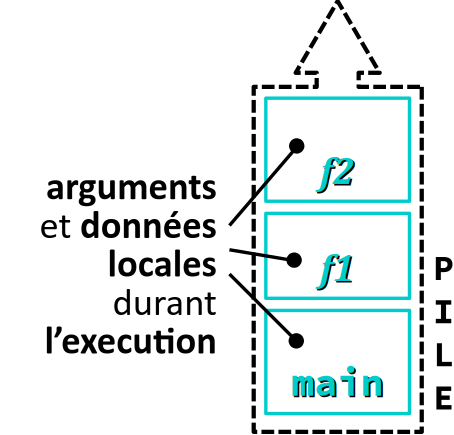
- La pile d'exécution W – en anglais, (call) stack – est la zone dans laquelle chaque appel de fonction ou chaque exécution de bloc se voit allouer, durant son exécution, un cadre (en anglais, frame) pour le stockage de ses arguments formels et de ses données locales.
- Le tas W – en anglais, heap – est la zone réservée pour le stockage des données allouées dynamiquement (en cours d'exécution), programmées en langage C avec les fonctions
mallocetfreedéclarées dans le fichier d'en‑têtestdlib.hde la bibliothèque standard du langage C (ou avec les mots‑clefsnewetdeleteen C++). - Entre la pile et le tas, on trouve également les segments des bibliothèques dynamiques exploitées par le programme (cf. chap. C4‑IV ). Dans la pratique, ces bibliothèques sont stockées en mémoire partagée, mais elles sont virtuellement représentées dans l'espace mémoire de chaque programme qui les exploite pour résoudre les liens dynamiques lors du chargement du programme.
Sur une machine à système Linux, on peut avoir une confirmation expérimentale de ces aspects grâce aux outils de monitoring. Il suffit par exemple de saisir dans un terminal une commande de la forme :
./program& cat /proc/$!/maps
qui, après avoir lancé l'exécution du programme, vient afficher le mapping de la mémoire qui lui est allouée (/proc/ est le répertoire où sont stockées toutes les informations relatives aux processus en cours d'exécution, et la variable d'environnement $! récupère le PID du dernier processus lancé).
- La représentation ci‑dessus de la zone statique est simplificatrice. Dans la pratique sont présents de nombreux autres segments, qui contiennent des métadonnées et des informations essentielles au monitoring du programme (table des symboles, etc.). Ces aspects seront revus en détails au chapitre C4‑IV, notamment lors de l'analyse du code objet .
- La sub‑division du segment
dataavec la section.bsspermet de diminuer significativement la taille du fichier exécutable et le temps de chargement du programme. En effet, puisque dans cette section, toutes les variables vaudront initialement0lors du chargement du programme, elle est simplement définie dans le fichier exécutable par son adresse de début et le nombre d'octets qu'il faut globalement lui allouer. Lors du chargement du programme en mémoire, la partie correspondante du segmentdataest créé simplement en initialisant tous ces octets à0. - La pile et le tas ont forcément chacun une taille limitée ; ces régions sont donc susceptibles de débordements si le programme les sollicite au delà de la capacité de la zone dynamique – d'où notamment l'expression stack overflow…
text déclenche une exception qui termine le processus d'exécution avec en sortie sur la console un message de la forme : Segmentation fault (core dumped)
0 – cf. chap. C5‑III ). Pour plus de détails sur les mécanismes d'allocation de mémoire, on peut consulter cet article W et ce Wiki même si la désignation des segments ne correspond pas exactement à celle présentée ici (cf. l'avertissement supra ).

Sur un poste de travail à architecture x86‑64 opérée sous Linux, en compilant avec GCC puis en exécutant son fichier source testSegments.c, le programme académique ci‑dessous affiche dans le terminal les adresses de différentes données déclarées ainsi que celle de la fonction main. Il utilise pour cela l'opérateur d'adresse & qui sera étudié en détail au chapitre C5‑I .
#include <stdio.h>
const char GC_A = 0; // GLOBAL CONSTANT = 0
const char GC_B = 1; // GLOBAL CONSTANT ≠ 0
char gv_a = 1; // global variable ≠ 0
char gv_b = 0; // global variable = 0
char gv_c; // global variable non initialized
int main(void)
{
gv_c = 2;
const char LC_A = 1; // LOCAL CONSTANT ≠ 0
const char LC_B = 0; // LOCAL CONSTANT = 0
char lv_a = 1; // local variable ≠ 0
char lv_b = 0; // local variable = 0
printf("%p: main [text]\n", (void *) main);
printf("%p: GC_A [rodata]\n", (void *) &GC_A);
printf("%p: GC_B [rodata]\n", (void *) &GC_B);
printf("%p: gv_a [data]\n", (void *) &gv_a);
printf("%p: gv_b [data .bss]\n", (void *) &gv_b);
printf("%p: gv_c [data .bss]\n", (void *) &gv_c);
printf("\n");
printf("%p: LC_A [stack - main frame]\n", (void *) &LC_A);
printf("%p: LC_B [stack - main frame]\n", (void *) &LC_B);
printf("%p: lv_a [stack - main frame]\n", (void *) &lv_a);
printf("%p: lv_b [stack - main frame]\n", (void *) &lv_b);
scanf("_");
return 0;
}

La sortie standard ainsi obtenue sur le terminal d'exécution permet de déterminer les adresses attribuées par la machine aux éléments déclarés. Les indications entre crochets [] précisent pour chacune le segment principal ou la région dans laquelle chaque élément est stocké en mémoire.
0x62bfa3ed11a9: main [text] 0x62bfa3ed2008: GC_A [rodata] 0x62bfa3ed2009: GC_B [rodata] 0x62bfa3ed4010: gv_a [data] 0x62bfa3ed4012: gv_b [data .bss] 0x62bfa3ed4013: gv_c [data .bss] 0x7ffca8331e14: LC_A [stack - main frame] 0x7ffca8331e15: LC_B [stack - main frame] 0x7ffca8331e16: lv_a [stack - main frame] 0x7ffca8331e17: lv_b [stack - main frame]
Grâce à cette sortie, on peut aisément distinguer :
- la zone statique, dont les adresses commencent par
0x62bfa3ed; - la zone dynamique , dont les adresses commencent par
0x7ffca833.
De plus, dans la zone statiques, on voit que les allocations se font pour des données de même catégorie par groupes d'adresses consécutives, qui sont décalés les uns des autres par multiples de 0x1000 octets. Ces décalages sont dûs aux alignements de pagination et témoignent de changements de segment.
Plus en détails, on observe que, comme attendu, la fonction main se voit bien attribuer une adresse « basse » (par rapport aux données), puisqu'elle est censée être placée dans le segment text.
De plus, sachant que toutes les données déclarées sont de type char, donc encodées sur un seul octet et sans contraintes d'alignement (cf. chap. C3‑I ), on peut faire les déductions suivantes (qui seront vérifiées par la suite).
- Les constantes globales
GC_AetGC_Bobtiennent des adresses consécutives. Quelle que soit leur valeur (0ou autre), elles sont a priori placées dans le même segmentrodata. - Les variables globales
gv_a,gv_betgv_cobtiennent des adresses très proches. Elles sont donc placées dans le même segment, a prioridata.
gv_b et gv_c, respectivement initialisée nulle et non initialisée sont placées à des adresses consécutives, avec un « saut » de 2 octets après gv_a, qui témoigne vraisemblablement du passage dans la section .bss. Quant aux quatre données locales LC_A, LC_B, lv_a et lv_b, elles se trouvent dans la zone dynamique, plus précisément tout en bas dans la pile, et plus précisément encore dans le cadre (frame) alloué à la fonction main. Peu importe alors que ces données soient constantes ou variables, initialisées ou non, elles obtiennent des adresses consécutives.
Remarque. Les adresses affichées sont bien virtuelles, puisque la différence entre la plus haute (0x7ffca8331e17) et la plus basse (0x62bfa3ed11a9) représente environ 32 × 1012 octets, soit environ 2000 fois plus que la mémoire vive disponible sur le poste de travail (16 Go soit 16 × 109 octets).
Pour observer de façon plus certaine la segmentation de l'espace mémoire du programme, saisissons dans le terminal la commande de mapping suivante (cf. supra ) :
./testSegments & cat /proc/$!/maps
On obtient alors la sortie standard suivante, reformatée et colorisée pour faciliter sa lecture :
62bfa3ed0000-62bfa3ed1000 r--p 00000000 08:23 50466151 […]/testSegments 62bfa3ed1000-62bfa3ed2000 r-xp 00001000 08:23 50466151 […]/testSegments 62bfa3ed2000-62bfa3ed3000 r--p 00002000 08:23 50466151 […]/testSegments 62bfa3ed3000-62bfa3ed4000 r--p 00002000 08:23 50466151 […]/testSegments 62bfa3ed4000-62bfa3ed5000 rw-p 00003000 08:23 50466151 […]/testSegments 62bfbd5ca000-62bfbd5eb000 rw-p 00000000 00:00 0 [heap] 756b4ea00000-756b4ea28000 r--p 00000000 08:01 1576680 […]/libc.so.6 756b4ea28000-756b4ebb0000 r-xp 00028000 08:01 1576680 […]/libc.so.6 756b4ebb0000-756b4ebff000 r--p 001b0000 08:01 1576680 […]/libc.so.6 756b4ebff000-756b4ec03000 r--p 001fe000 08:01 1576680 […]/libc.so.6 756b4ec03000-756b4ec05000 rw-p 00202000 08:01 1576680 […]/libc.so.6 756b4ec05000-756b4ec12000 rw-p 00000000 00:00 0 756b4eddf000-756b4ede4000 rw-p 00000000 00:00 0 756b4ede4000-756b4ede5000 r--p 00000000 08:01 1573349 […]/ld-linux-x86-64.so.2 756b4ede5000-756b4ee10000 r-xp 00001000 08:01 1573349 […]/ld-linux-x86-64.so.2 756b4ee10000-756b4ee1a000 r--p 0002c000 08:01 1573349 […]/ld-linux-x86-64.so.2 756b4ee1a000-756b4ee1c000 r--p 00036000 08:01 1573349 […]/ld-linux-x86-64.so.2 756b4ee1c000-756b4ee1e000 rw-p 00038000 08:01 1573349 […]/ld-linux-x86-64.so.2 7ffca8312000-7ffca8334000 rw-p 00000000 00:00 0 [stack]
On y retrouve, conformément à la présentation générale proposée supra :
- en rouge, le segment
text; - en vert olive, le segment
rodata; - en vert, le segment
data; - en bleu, le tas et la pile de la zone dynamique, respectivement mentionnées
heapetstack; - en orange, les segments des bibliothèques dynamiques (shared objects) exploitées par le programme, à savoir
libc(bibliothèque standard du langage C, d'où est issue la fonctionprintfappelée par le programme) etld-linux(le chargeur/éditeur de liens dynamiques, indispensable pour exécuter le programme).
À l'aide de leurs adresses respectives obtenues lors de l'exécution (cf. supra ), on peut ensuite patiemment vérifier que les fonctions et données du programmes appartiennent bien aux segments présupposés.
Sur une machine à système d'exploitation Linux, on peut aussi retrouver des éléments de la structuration des données d'un programme exécutable au format ELF (executable and linkable format), en affichant sa table des symboles. On peut le faire notamment grâce à la commande nm W (name mangling W, le verbe anglais to mangle signifiant « essorer », « déchiqueter »). Il s'agit d'un utilitaire inclus dans le paquet GNU Binary utilities qui est usuellement déjà installé avec la plupart des distributions Linux. Si tel n'est pas le cas, on peut y remédier, typiquement via la commande :
sudo apt install binutils
La commande nm (cf. chap. C4‑IV pour plus de détails) affiche en particulier tous les identificateurs de données globales et des fonctions déclarées dans les fichiers source d'un programme. Elle indique pour chacune son adresse et, par une lettre‑code, la section du code exécutable dans laquelle l'élément est codé, à savoir :
-
Toutpour une fonction définie dans la section.text; -
Rourpour une donnée dans la section.rodata; -
Doudpour la section.data; -
Boubpour la section.bss;
sachant que, lors de l'exécution du programme, ces sections ont vocation à être chargées en mémoire dans leurs segments homonymes respectifs, à l'exception de .rodata qui est affectée au segment text.
Pour trier les symboles par adresses et non pas selon l'ordre alphabétique des identificateurs, il suffit d'appeler la commande nm avec l'option -n. Bien entendu, on trouve le détail des autres options en consultant le manuel de la commande ou sur une page web comme celle‑ci. Toutefois, nm affiche aussi les symboles d'autres objets « cachés ». Pour ne pas s'en encombrer, il est aussi nécessaire de lui appliquer un filtre, typiquement avec la commande grep (cf. chap. S1‑IV S) à adapter au cas par cas.
Ensuite, il est possible de retrouver la correspondance entre les segments et les sections à l'aide de la commande readelf W, un autre outil du paquet binutils, très polyvalent pour analyser les fichiers au formats ELF. Ici en l'occurrence, il suffit d'utiliser les options -l et -W (pour un affichage au format large).
Dans un terminal de commande en ligne sur une machine Linux, appliquons la commande nm au fichier exécutable nommé testSegments du programme académique proposé supra :
nm -n testSegments | grep -E '\<[TRDB]\>' | grep -v '\<_'0000000000001189 T main 0000000000002008 R GC_A 0000000000002009 R GC_B 0000000000004010 D gv_a 0000000000004012 B gv_b 0000000000004013 B gv_c
Dans la sortie ci‑dessus, les adresses sont calées à zéro puisqu'il n'y pas encore d'allocation dans la RAM. Mais :
- par rapports aux adresses affichées durant l'exécution, on retrouve bien le même ordre d'allocation, et les mêmes deux digits de poids faibles ;
- les deux constantes globales
GC_AetGC_Bsont bien identifiées par la lettre‑codeRcomme appartenant à la section.rodata; - la variable globale
gv_a, initialisée non nulle, est bien identifiées par la lettre‑codeDcomme appartenant à la section.data; - les variables globales
gv_betgv_c, respectivement initialisée nulle et non initialisée, sont bien identifiées par la lettre‑codeBcomme appartenant à la section.bss.
Quant aux données locales (LC_A, LC_B, etc.), elles ne figurent pas dans la table des symboles puisqu'elles seront créées à la volée dans la pile seulement lors de l'exécution du programme (pas à la génération du code exécutable).
Voyons maintenant la correspondance des segments avec les sections grâce à la commande readelf :
readelf -lW testSegmentsElf file type is DYN (Position-Independent Executable file) Entry point 0x10c0 There are 13 program headers, starting at offset 64 Program Headers: Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align PHDR 0x000040 0x0000000000000040 0x0000000000000040 0x0002d8 0x0002d8 R 0x8 INTERP 0x000318 0x0000000000000318 0x0000000000000318 0x00001c 0x00001c R 0x1 [Requesting program interpreter: /lib64/ld-linux-x86-64.so.2] LOAD 0x000000 0x0000000000000000 0x0000000000000000 0x000718 0x000718 R 0x1000 LOAD 0x001000 0x0000000000001000 0x0000000000001000 0x000341 0x000341 R E 0x1000 LOAD 0x002000 0x0000000000002000 0x0000000000002000 0x0001e4 0x0001e4 R 0x1000 LOAD 0x002da0 0x0000000000003da0 0x0000000000003da0 0x000271 0x000278 RW 0x1000 DYNAMIC 0x002db0 0x0000000000003db0 0x0000000000003db0 0x0001f0 0x0001f0 RW 0x8 06 NOTE 0x000338 0x0000000000000338 0x0000000000000338 0x000030 0x000030 R 0x8 07 NOTE 0x000368 0x0000000000000368 0x0000000000000368 0x000044 0x000044 R 0x4 08 GNU_PROPERTY 0x000338 0x0000000000000338 0x0000000000000338 0x000030 0x000030 R 0x8 09 GNU_EH_FRAME 0x002104 0x0000000000002104 0x0000000000002104 0x000034 0x000034 R 0x4 10 GNU_STACK 0x000000 0x0000000000000000 0x0000000000000000 0x000000 0x000000 RW 0x10 11 GNU_RELRO 0x002da0 0x0000000000003da0 0x0000000000003da0 0x000260 0x000260 R 0x1 12 Section to Segment mapping: Segment Sections... 00 01 .interp 02 .interp .note.gnu.property .note.gnu.build-id .note.ABI-tag .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt 03 .init .plt .plt.got .plt.sec .text .fini 04 .rodata .eh_frame_hdr .eh_frame 05 .init_array .fini_array .dynamic .got .data .bss 06 .dynamic 07 .note.gnu.property 08 .note.gnu.build-id .note.ABI-tag 09 .note.gnu.property 10 .eh_frame_hdr 11 12 .init_array .fini_array .dynamic .got
On observe bel et bien que :
- la section
.textest inscrite dans le segment03accessible en lecture/exécution (R E) – c'est le segmenttext; - la section
.rodataest inscrite dans le segment04accessible en lecture seule (R) – c'est le segmentrodata; - les sections
.dataet.bssest inscrite dans le segment05accessible en lecture/écriture (RW) – c'est le segmentdata.
Et par ailleurs, le segment data présente la particularité que sa valeur FileSiz (la taille totale des valeurs des données y recopier – ici 0x271) est inférieure à celle de MemSiz (la taille totale des données en mémoire – ici 0x278). Cette différence correspond à la taille de la section .bss où il n'y a aucune valeur de données à recopier puisqu'elles sont toutes initialisées à 0.
Cas d'une carte à microcontrôleur
Lorsque la machine cible est une carte à microcontrôleur, l'allocation mémoire est globalement similaire à celle mise en œuvre sur un ordinateur, mais avec des différences significatives, car il s'agit d'une architecture très spécifique sur laquelle n'opère aucun système d'exploitation.
En effet, dans les configurations usuelles – cartes Arduino, ESP ou autre – la mémoire disponible :
- n'est pas externe mais intégrée au microcontrôleur ; elle n'est pas virtualisée (non seulement il n'y a pas de système d'exploitation, mais pas non plus de contrôleur mémoire, ni espace d'échange qui justifie la virtualisation) ;
- est beaucoup plus réduite, mais par ailleurs non partagée (elle est intégralement allouée au seul programme que la carte peut gérer) ;
- est hétéroclite (flash, SRAM, EEPROM), notamment pour que le code exécutable du programme et certaines données puissent rester mémorisées même en cas de rupture d'alimentation électrique de la carte.
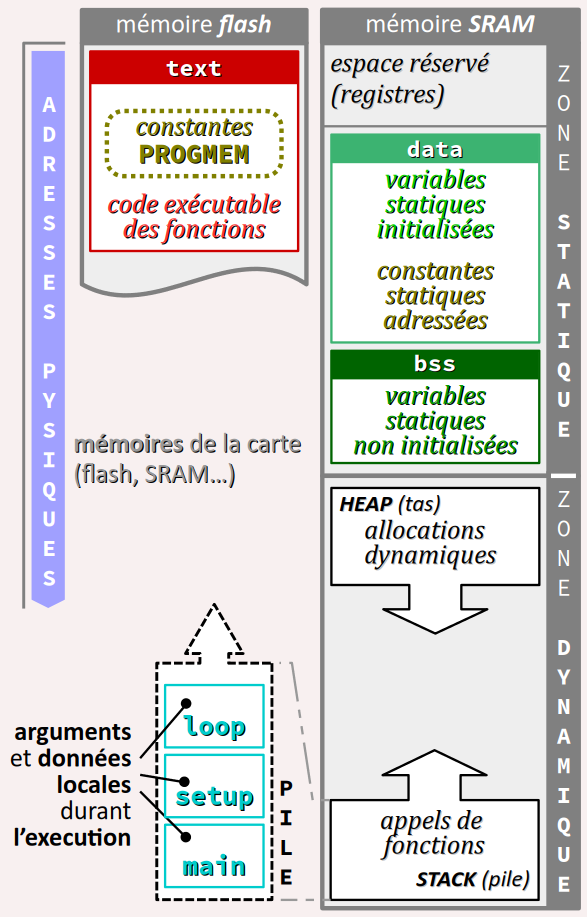
En conséquence, la zone statique est physiquement séparée en deux parties :
- Dans la mémoire non volatile (de type flash), on trouve le segment
text. - Dans la mémoire vive (SRAM), on trouve deux segments de données distincts
dataetbss, mais pas de segmentrodata.
.data et .bss du code exécutables sont placées dans deux segments mémoire distincts car une copie du segment data est également placée dans la mémoire flash, pour pouvoir être rechargé dans la SRAM à chaque réinitialisation du programme. Quant au segment bss, seule sa taille est mémorisée dans la mémoire flash, ce qui est suffisant pour procéder à sa remise à zéro dans la SRAM à chaque réinitialisation du programme. rodata, elle s'explique par le fait qu'il n'y a sur la carte aucun moyen d'interdire l'accès en écriture dans une zone spécifiée dans la SRAM. Aussi, les constantes globales déclarées de types élémentaires qui feraient l'objet dans le code d'un référencement en mémoire (par usage de l'opérateur d'adresse &) sont placées dans le segments data, sachant qu'il s'agit d'une allocation purement formelle. En effet, en compilation Arduino, avec l'option d'optimisation de la taille du code exécutable (cf. chap. C4‑IV ) toutes les constantes sont traitées par substitution de valeur dans le code exécutable, à la manière du préprocesseur avec les pseudo‑constantes (cf. chap. C4‑III ). Ainsi, il n'y a donc a priori aucun risque de modification de la valeur d'une constante élémentaire par pointeur interposé. data, mais elles sont évidemment trop grosses pour faire l'objet d'une substitution de valeur dans le code exécutable. Elles sont donc vulnérables au risque de modification par pointeur interposé (cf. chap. C5‑I ). Sur une carte à microcontrôleur, la zone dynamique adopte presque la même structure que sur une machine de type ordinateur :
- le tas part de la fin de zone statique et s'étend dans le sens des adresses croissantes, au gré des allocations dynamiques programmées ;
- la pile part de la fin de l'espace mémoire et s'étend dans le sens des adresses décroissantes, au gré des appels de fonctions ;
- mais bien évidemment, il n'y a pas de segments de bibliothèques dynamiques puisqu'il n'y a pas de mémoire partagée.
Attention ! L'espace mémoire étant assez limité sur une carte à microcontrôleur, les risques de collision entre la pile et le tas ne sont pas négligeables – sachant qu'un tel événement constitue en général un dysfonctionnement majeur du programme. Or si le compilateur peut calculer l'espace mémoire utilisé par la zone statique (cette information est toujours affiché dans le compte‑rendu de compilation), il ne peut pas anticiper les besoins du programme dans la zone dynamique. Le codeur doit donc être particulièrement vigilant dans ce contexte de développement, surtout s'il emploie des fonctions récursives (cf. chap. C1‑I ) ou des allocations dynamiques répétitives de données.
Pour plus de détails sur ces aspects, on peut consulter cet article .

Adaptons dans le framework Arduino le programme académique d'étude de l'allocation mémoire proposé supra pour une machine de type ordinateur.
- La déclaration des données est presque inchangée, à l'exception de la constante globale
GC_Aqui utilise la macro‑définitionPROGMEM(cf. supra ). - L'affichage des adresses des données déclarées est effectué dans le moniteur série à l'aide une fonction spécifique nommée
displaySymb. Pour pallier l'incommodité de la méthodeSerial.print(compararivement àprintf), elle utilise des pointeurs – notion qui est abordée seulement au chapitre C5‑I .
Le code source du programme, stocké dans un fichier nommé testSegmentsUNO.ino est donnée ci‑dessous.
const char GC_A PROGMEM = 1;
const char GC_B = 0;
char gv_a = 1; // global variable ≠ 0
char gv_b = 0; // global variable = 0
char gv_c; // global variable non initialized
void setup()
{
Serial.begin(115200);
Serial.println();
gv_c = 2;
const char LC_A = 1; // LOCAL CONSTANT ≠ 0
const char LC_B = 0; // LOCAL CONSTANT = 0
char lv_a = 1; // local variable ≠ 0
char lv_b = 0; // local variable = 0
Serial.println("Flash content:");
displaySymb(&GC_A, "GC_A [text]");
displaySymb((void*) setup, "setup [text]");
displaySymb((void*) loop, "loop [text]");
displaySymb((void*) displaySymb, "displaySymb [text]");
Serial.println();
Serial.println("SRAM content:");
displaySymb(&gv_a, "gv_a [data]");
displaySymb(&gv_a, "GC_B [data]");
displaySymb(&gv_b, "gv_b [bss]");
displaySymb(&gv_c, "gv_c [bss]");
displaySymb(&LC_A, "LC_A [stack - setup frame]");
displaySymb(&LC_B, "LC_B [stack - setup frame]");
displaySymb(&lv_a, "lv_a [stack - setup frame]");
displaySymb(&lv_b, "lv_b [stack - setup frame]");
}
void loop()
{
delay(1000);
}
void displaySymb(const void * address, const char * name)
{
Serial.print("0x"); Serial.print(int(address), HEX);
Serial.print(": "); Serial.println(name);
}
Compilé et téléversé avec Arduino IDE sur une carte Arduino Uno R3 (32 ko de mémoire flash pour le programme, 2048 octets de mémoire SRAM pour les données), ce programme produit sur le moniteur série la sortie suivante :
Flash content: 0x68: GC_A [text] 0x234: setup [text] 0x192: loop [text] 0x1E7: displaySymb [text] SRAM content: 0x100: gv_a [data] 0x101: GC_B [data] 0x220: gv_b [bss] 0x221: gv_c [bss] 0x8F5: LC_A [stack - setup frame] 0x8F6: LC_B [stack - setup frame] 0x8F7: lv_a [stack - setup frame] 0x8F8: lv_b [stack - setup frame]
On peut ainsi bien visualiser la séparation de la zone statique en deux parties avec :
- dans la mémoire flash, formant le segment
text, le code des fonctions du programme et la constante globaleGC_Adéclarée avec la macro‑définitionPROGMEM; - dans la mémoire SRAM, les segments
dataetbsscontenant les données globales.
GC_B est bien placée dans le segment data puisqu'il n'y pas de segment rodata. On peut également faire quelques observations sur l'espace d'adressage de la mémoire SRAM du microcontrôleur Atmel ATmega328p qui équipe la carte Arduino Uno R3.
- Les adresses
0x000à0x0FFsont celles des différents registres (cf. chap. C3‑1 ). Ces adresses viennent s'ajouter à celles de l'espace allouable aux données du programme (2048 octets) ; c'est pourquoi la zone statique commencent seulement à l'adresse0x100. - C'est aussi pourquoi l'adresse haute de la SRAM est
0x8FF. En effet, arithmétiquement, on a :
(8FF)16 − (100)16 = (8FF)16 = (2047)10
main). Remarque. Simulé sur une Tinkercad, le programme produit une sortie similaire (les adresses diffèrent un peu).
Contrairement à un programme s'exécutant sur ordinateur, il n'est pas possible de faire de mapping mémoire. En revanche, on peut trouver le fichier exécutable testSegmentsUNO.ino.elf du programme dans le répertoire :
/home/user/.cache/arduino/sketches/
et on peut alors afficher la liste de ses principaux symboles à l'aide de la commande nm -n et un filtrage spécifique (pour masquer les symboles non pertinents ici) :
nm -n testSegmentsUNO.ino.elf | grep -E '\<[TtRrDdBb]\>' | grep -vE '__|_e|ZN|ZT|Z14|Z17|\.|ti'00000068 t _ZL4GC_A 000000c0 t micros 00000324 t loop 000003ce t _Z11displaySymbPKvPKc 00000468 t setup 000006d6 T main 00800100 d gv_a 00800101 d _ZL4GC_B 00800220 b gv_b 00800221 b gv_c 0080022b b Serial
sachant que le compilateur adopte une syntaxe particulière pour désigner certains symboles :
- les constantes globales
GC_AetGC_Bsont préfixés par_ZL4, où le nombre4indique la taille (nombre de caractère) de l'identificateur de la donnée ; - la fonction
displaySymbest préfixée par_Z11, où le nombre11indique la taille (nombre de caractère) de son identificateur de la donnée ; elle est suffixée parPKvPKcpour décrire ses arguments – un pointeur en lecture seule de typevoid(PKv) et pointeur en lecture seule de typechar(PKc).
Cette analyse permet de confirmer les observations faites supra sur la sortie d'exécution du programme :
- la constante globale
GC_A(déclarée avecPROGMEM) est bien inscrite dans la section.text; - la constante globale
GC_Best bien inscrite dans la section.data.
Enfin, on peut aussi vérifier la correspondance entre les segments et les sections à l'aide de la commande readelf :
readelf -lW testSegmentsUNO.ino.elfElf file type is EXEC (Executable file) Entry point 0x0 There are 3 program headers, starting at offset 52 Program Headers: Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align LOAD 0x000094 0x00000000 0x00000000 0x007e4 0x007e4 R E 0x2 LOAD 0x000878 0x00800100 0x000007e4 0x00120 0x00120 RW 0x1 LOAD 0x000998 0x00800220 0x00800220 0x00000 0x000a8 RW 0x1 Section to Segment mapping: Segment Sections... 00 .text 01 .data 02 .bss
Ici, le nombre de segments et de sections est réduit au minimum, ce qui facilite grandement la vérification de leur correspondance.
Notions d'existence et de durée de vie d'une donnée
On dit qu'une donnée déclarée existe à un instant considéré de l'exécution d'un programme (runtime) si, à cet instant, est alloué un espace mémoire adressable à cette donnée. On parle donc de durée de vie (en anglais, lifetime) de la donnée pour désigner l'intervalle de temps durant lequel cette donnée existe – et ce même si, dans la pratique, on ne quantifie jamais cette durée.
Concrètement, on qualifie donc de permanente une donnée qui existe sans discontinuer du début à la fin de l'exécution d'un programme. Sinon, on dit que la donnée est temporaire.
Relation entre l'existence et la déclaration d'une donnée
Compte tenu des mécanismes d'allocation de mémoire présentés supra, on peut énoncer les règles générales suivantes :
- Toute donnée globale est permanente et ce sans considération du fait qu'elle soit déclarée avant ou après le point d'entrée du programme, à savoir la fonction
mainen C/C++ , la fonctionsetupdans l'environnement Arduino (cf. chap. C2‑I ). - Toute donnée locale est temporaire, sauf instruction spécifique modifiant sa classe d'allocation (cf. infra ). Plus précisément :
- sa durée de vie s'étend de l'instant où son instruction de déclaration est exécutée à l'instant où s'achève l'exécution du bloc dans lequel elle est déclarée ;
- si le bloc est ré‑exécuté ultérieurement, la donnée reprend une nouvelle existence sans mémoire de son existence précédente.
Exemple académique
Reprenons l'exemple volontairement confus élaboré supra dans l'environnement Arduino avec trois variables différentes portant le même identificateur foo. Bien que contraire aux bonnes pratiques, ce programme permet d'illustrer la notion de durée de vie.
float foo = 0.0; // global var. "foo #1" (.data segment)
// exists all along the run-time
void setup()
{
Serial.begin(115200);
foo = 1.1; // global var. "foo #1" is modified
Serial.println(foo); // display on the monitor -> 1.10
int foo = 0; // local var. "foo #2" starts to exist
foo = 2.1; // local var. "foo #2" is modified
Serial.println(foo); // display on the monitor -> 2 ("foo #2" is int)
}
// local var. "foo #2" has ceased to exist
void loop()
{
Serial.println(foo); // display on the monitor -> 1.10 ("foo #1")
bool foo = true; // local var. "foo #3" starts to exist
Serial.println(foo); // display on the monitor -> 1 ("foo #3" is boolean)
}
// local var. "foo #3" has ceased to exist
// But just after that, a new local variable "foo #4" will be created
// and so on…
// NB: the global variable "foo #1" still and always exists
Au regard des mécanismes d'allocation mémoire, on peut maintenant préciser que :
- la variable globale
foo« #1 » déclarée à la ligne nº 2 est permanente (elle existe durant toute l'exécution du programme) ; - la variable locale
foo« #2 » déclarée à la ligne nº 9 (danssetup) est temporaire (elle n'existe que jusqu'à la fin de l'exécution de la ligne nº 11) ; - la variable locale
foo« #3 » déclarée à la ligne nº 17 (dansloop) est temporaire (elle n'existe que jusqu'à la fin de l'exécution de la ligne nº 18) ;
foo « #4 » sera créée lors de la deuxième itération de la fonction loop ; et ainsi de suite… Classes d'allocation de mémoire des données
Les langages C et C++ mettent à la disposition du codeur plusieurs mots‑clefs – auto, static, register, extern et volatile – pour imposer, lors de la déclaration d'une donnée un mécanisme spécifique d'allocation de mémoire.
On parle ici de classes d'allocation de données, sachant que l'emploi de ce terme est bien évidemment à ne pas confondre avec celui de classe en programmation orientée objet.
Dans le présent chapitre, seuls les mots‑clefs auto, static et register seront abordés. En effet :
- Le mot‑clef
externsera présenté lors de l'étude des techniques de programmation multi‑fichiers (cf. chap. C4‑V ). - Quant au mot‑clef
volatile, il est surtout relatif aux interruptions et il ne sera pas étudié dans ce module de formation.
La classe automatique
La classe automatique d'allocation de mémoire regroupe toutes les données locales et temporaires ainsi que les arguments formels des fonctions qui sont gérés automatiquement dans la pile (alors que dans le tas, c'est au codeur de gérer lui‑même les allocations et libérations).
En langage C, on peut imposer la classe automatique à une donnée de niveau 1 ou plus en faisant précéder sa déclaration du mot‑clef auto. Mais en règle générale, c'est inutile, car toute donnée locale est par défaut de classe automatique. Néanmoins, on peut pourrait éventuellement prendre cette précaution pour une donnée que l'on souhaite protéger d'une potentielle optimisations du compilateur.
En langage C++, cette possibilité n'existe plus. À partir de la norme C++11, le mot‑clef auto a été réservé pour un autre usage : le typage automatique des données (cf. chap. C3‑IV ).
Aujourd'hui, il est vraiment difficile de trouver un exemple pertinent d'utilisation du mot‑clef auto en langage C.
Initialisation
En langages C et C++, une donnée locale de classe automatique n'est pas initialisée à zéro par défaut lors de l'exécution de sa déclaration, si cette dernière ne comporte pas d'affectation – laquelle est, rappelons‑le, optionnelle (cf. chap. C2‑III ).
Dans un tel cas, la donnée prend une valeur « aléatoire », qui est en fait l'interprétation dans le type de la donnée des valeurs des bits de l'espace mémoire qui lui est alloué dans la pile au moment de l'appel de la fonction (typiquement, les valeurs des bits d'anciennes données automatiques qui occupaient cet espace avant que leur cadre soit « supprimé » – mais pas effacé).
En termes de bonnes pratiques, on rappelle qu'il est préférable d'initialiser toute variable locale dès sa déclaration, même si cette affectation est écrasée peu après dans le code (cf. chap. C2‑III ).
La classe statique
La classe statique regroupe, comme son nom l'indique, toutes les données stockées dans la zone statique de la mémoire allouée au programme (segments rodata, data et bss), donc en particulier les données déclarées globales.
En langages C et C++, on peut imposer classe statique à une donnée de niveau 1 ou plus (qui sont, par défaut, de classe automatique) en faisant précéder sa déclaration du mot‑clef static. La donnée se voit alors allouer un espace mémoire dans la zone statique, et non pas dans la pile.
La déclaration d'une donnée locale dans la classe statique a des conséquences subtiles :
- Elle ne modifie en rien la visibilité de la donnée, qui reste locale.
- Elle accorde à la donnée une durée de vie permanente et donc une mémorisation de sa valeur même après la fin d'exécution de la fonction ou du bloc dans lequel est codé sa déclaration. Et notamment, si la fonction ou le bloc est de nouveau exécuté, la donnée n'est pas réinitialisée lors de l'exécution de l'instruction de déclaration et garde sa valeur précédente.
- En conséquence, toute expression d'initialisation codée dans la déclaration d'une donnée statique codée est évaluée une seule fois :
- en C, lors de la compilation – en rappelant qu'il doit obligatoirement s'agir d'une expression constante (cf. chap. C2‑III ) ; en termes de temps d'exécution du programme, cette opération est considérée comme « gratuite ».
- en C++, lors la première (et seule) exécution de la déclaration de la donnée dans tout le processus d'exécution du programme.
.bss du code exécutable). 
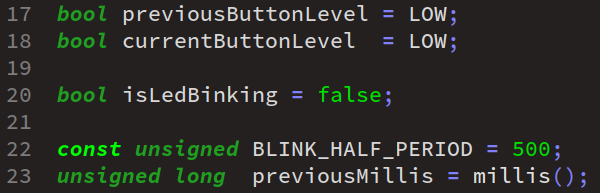
Reprenons le programme de démonstration de clignotement de la led intégrée sur une carte Arduino, dans sa version réactive – c'est‑à‑dire sans recours à la fonction delay, qui a été proposé au chapitre C2‑IX .
Dans ce programme, on avait déclaré deux données globales :
- en ligne nº 1, la constante
BLINK_HALF_PERIODpour mémoriser la demi‑période de clignotement souhaitée ; - en ligne nº 9, la variable
previousMillispour mémoriser la valeur retournée par la fonctionmillislors du dernier changement d'état de la led.
Mais au regard des bonnes pratiques, il est préférable de déclarer ces deux données non pas globales mais locales dans la fonction loop puisqu'elles ne sont pas utilisées ailleurs dans le code. Pour ce faire, on leur attribue la classe statique, ainsi qu'on peut le lire ci‑dessous dans la nouvelle version du programme :
void setup()
{
pinMode(LED_BUILTIN, OUTPUT);
}
void loop()
{
static const unsigned BLINK_HALF_PERIOD = 1000; // 1 seconde
static unsigned long previousMillis = millis();
if (millis() - previousMillis >= BLINK_HALF_PERIOD) {
previousMillis += BLINK_HALF_PERIOD;
digitalWrite(LED_BUILTIN, !digitalRead(LED_BUILTIN));
}
}
On peut observer que :
- dans le cas de
previousMillis, la classe statique est indispensable, sinon elle ne garderait pas en mémoire sa valeur puisqu'elle serait réinitialisée à chaque nouvelle itération de la fonctionloop; - dans le cas de
BLINK_HALF_PERIOD, la classe statique est préférable, pour éviter que le programme re‑crée la même constante à chaque itération de la fonctionloop.
Avantages des variables locales statiques par rapport aux variables globales
La déclaration d'une donnée locale de classe statique plutôt que globale présente plusieurs avantages :
- améliorer la lisibilité du code par le regroupement dans une même entité de toutes les instructions (déclarations et actions) nécessaires à une fonctionnalité ;
- faciliter le travail réparti des équipes de codage, car :
- la portée limitée des données locales permet le cloisonnement du programme en parties « étanches » ; une équipe en charge du développement d'une partie A ne pourra pas utiliser les données locales d'une partie B confiée à une autre équipe (toute tentative d'accéder à une donnée invisible étant rejetée dès la compilation) ;
- les équipes peuvent utiliser les mêmes identificateurs sans risques de conflits, puisqu'ils ne sont visibles que dans leurs parties respectives du programme (c'est très commode pour des identificateurs courants comme, par exemple,
previousMillis).
Limites d'emploi des variables locales statiques
Malgré tous les avantages constatés que cette pratique présente, il faut néanmoins rester prudent lors de l'attribution de la classe statique à une donnée locale. En particulier, il ne faut pas perdre de vue l'unicité d'une telle donnée pour plusieurs appels de la même fonction.
Toujours dans la thématique du clignotement de led, Il serait tentant d'accentuer la modularité du programme précédent en créant une fonction blink et de croire qu'il suffit alors d'appeler cette fonction pour faire clignoter plusieurs leds, comme dans le programme dysfonctionnel ci‑dessous.
const int LED_PIN_1 = 7;
const int LED_PIN_2 = 13;
void setup()
{
pinMode(LED_PIN_1, OUTPUT);
pinMode(LED_PIN_2, OUTPUT);
}
void loop()
{
blink(LED_PIN_1, 1000);
blink(LED_PIN_2, 500); // FAILING CODE: LED n° 1 does not blink!!!
}
void blink(uint8_t ledPin, unsigned long blinkHalfPeriod)
{
static unsigned long previousMillis = millis();
if (millis() - previousMillis >= blinkHalfPeriod) {
previousMillis += blinkHalfPeriod;
digitalWrite(ledPin, !digitalRead(ledPin));
}
}
En effet, ce programme est défaillant, la même variable previousMillis ne pouvant pas gérer deux temporisations différentes.
Pour y remédier – et bien que cela puisse sembler laborieux – il n'y a pas d'autre choix (sans éléments de langage plus puissants) que de créer deux fonctions distinctes de clignotement, comme dans le code ci‑dessous.
void loop()
{
blink1(LED_PIN_1, 1000);
blink2(LED_PIN_2, 500);
void blink1(uint8_t ledPin, unsigned long blinkHalfPeriod)
{
static unsigned long previousMillis = millis();
if (millis() - previousMillis >= blinkHalfPeriod){
previousMillis += blinkHalfPeriod;
digitalWrite(ledPin, !digitalRead(ledPin));
}
}
void blink2(uint8_t ledPin, unsigned long blinkHalfPeriod)
{
static unsigned long previousMillis = millis();
if (millis() - previousMillis >= blinkHalfPeriod) {
previousMillis += blinkHalfPeriod;
digitalWrite(ledPin, !digitalRead(ledPin));
}
}
Cette solution n'est pas satisfaisante car elle oblige à une redondance de codage.
Mais bien entendu, il existe des solutions. C'est en particulier l'un des grands intérêt de la programmation orientée objet, qui consiste à associer les fonctions – on les appelle des méthodes – aux classes d'objets. Ainsi, lorsqu'on déclare un objet – on dit aussi instancier une classe – ce dernier se voit attribuer des méthodes dont les variables locales lui sont propres.
Et plus généralement, pour coder une fonction récursive (c'est‑à‑dire qui s'appelle elle‑même), il faut ne pas employer de variable statique. Le risque est grand d'obtenir une exécution défectueuse, sans que le compilateur émette le moindre avertissement.
Restriction syntaxique en langage C
En langage C, dans une boucle d'itération for (cf. chap. C2‑V , les variables codées dans l'en‑tête ne doivent (et ne peuvent)pas être déclarées de classe statique. Ainsi, le compilateur signale une erreur si on code quelque chose comme :
for (static int i = … // Error (not possible in C)
En revanche, un tel codage est possible en C++, mais il importe d'en comprendre les conséquences. Car même si d'une façon générale, l'instruction d'initialisation d'une boucle for n'est exécutée qu'une seule fois (juste avant la première itération du corps de la boucle), la variable d'itération n'est pas gérée de façon statique. En effet, si elle était statique, elle ne serait pas ré‑initialisée lors d'une deuxième exécution de la boucle (ici, on ne parle pas d'itération de son bloc).
Dans le programme académique ci‑dessous, on a deux boucles for imbriquées l'une dans l'autre, la deuxième étant régie par la variable d'itération i déclarée statique.
#include <stdio.h>
int main(void)
{
for (int j = 1; j <= 2; j++) {
for (static int i = 1; i <= 3; i++) {
printf("Hello World!\n");
}
}
return 0;
}
Il en résulte qu'en sortie standard sur la console d'exécution, la chaîne de caractère « Hello World! » est affichée seulement 3 fois, et non pas 6 fois. En effet :
-
iétant déclarée statique, elle n'est pas réinitialisée lors de la deuxième itération de première bouclefor, c'est‑à‑dire pourjvalant2; -
igarde donc sa valeur4affectée à la fin de la première itération de cette première bouclefor(pourjvalant 1) ;
La condition de répétition i <= 3 reste donc invalidée, et plus aucune itération du bloc de la deuxième boucle for n'est exécutée.
La classe registre
L'emploi d'une donnée de classe automatique consomme du temps d'exécution :
- il faut d'abord lui allouer un espace mémoire dans la pile avant de pouvoir y accéder en lecture ou écriture ;
- ensuite, comme toute donnée stockée dans la mémoire vive, un accès en lecture ou écriture prend également un peu de temps, surtout si cette mémoire est externe au processeur, comme c'est le cas avec la mémoire vive sur un ordinateur (il faut passer un bus et le contrôleur de mémoire pour déterminer l'adresse physique).
Pour une donnée très utilisée déclarée dans une fonction, et à condition qu'elle soit de type élémentaire, le compilateur prend souvent l'initiative de la stocker dans un registre du processeur, c'est‑à‑dire un espace mémoire très proche de l'unité arithmétique et logique qui exécute les opérations (cf. chap. C3‑I ).
Une telle optimisation obéit à un algorithme complexe, car les registres existent en nombre restreint W.
En langage C et C++, le codeur peut indiquer au compilateur qu'il souhaite qu'une donnée automatique – c'est‑à‑dire une donnée locale ou un argument de fonction non statique – soit préférentiellement stockée en registre plutôt que dans la pile. Il suffit de faire précéder sa déclaration du mot‑clef register.
Néanmoins, cette demande n'est pas forcément satisfaite (tout dépend de la complexité du programme et des ressources de la machine cible).
Pour un codeur débutant, il est préférable de ne pas employer cette possibilité et de faire confiance au compilateur. Mal‑employée, elle peut avoir des effets contre‑productifs en termes de performance.
De plus, une donnée déclarée avec la classe register (et même si cette demande n'est effectivement pas satisfaite par le compilateur) ne peut pas être la cible d'un pointeur – plus précisément, on ne peut pas lui appliquer l'opérateur d'adresse &. En particulier, on ne peut donc pas saisir sa valeur via la fonction scanf (cf. chap. C2‑VII ).
D'ailleurs, en langage C, cette restriction peut être aussi le réel motif pour lequel on emploie cette classe d'allocation : empêcher tout pointage sur la donnée, donc toute possibilité de la modifier « insidieusement ». En revanche, en langage C++, cet intérêt n'existe pas, car il reste toujours la possibilité de déclarer une référence sur la donnée (cf. chap. C5‑I ).