Au chapitre C4‑I , on a vu que la décomposition en fonctions d'un programme était la base de la programmation procédurale. Mais lorsque un programme dépasse quelques centaines de ligne (ce qui est très peu), sa conception devient déjà mal aisée s'il est codé sur un seul fichier. En effet, même avec les possibilités avancées de recherche des meilleurs éditeurs de code, faire des allers‑retours entre diverses parties éloignées du fichier devient fastidieux, chronophage…

C'est pourquoi les langages C et C++ sont conçus pour permettre de répartir sur plusieurs fichiers le code source d'un programme. De cette manière, même avec un simple éditeur de code, les accès rapides aux différentes fonctions d'un programme sont facilités : via le panneau de navigation et/ou les onglets affichés dans la fenêtre d'édition, il suffit d'ouvrir le fichier dans lequel une fonction est codée pour la trouver rapidement, dès lors que ce fichier reste de taille raisonnable. Cela suppose bien entendu de savoir dans quel fichier est codée la fonction – et c'est tout l'art de la répartition du code.
Plus généralement, la programmation multi‑fichiers présente d'autres intérêts déterminants.
- Lors de la mise au point du programme, on peut faire en sorte que seuls les fichiers modifiés soient recompilés, ce qui procure un gain de temps d'autant plus de important que le programme est grand. Les IDE modernes comme VS Code sont capables de mettre en œuvre une compilation intelligente en examinant les dates de modification des fichiers objets pour ne pas avoir à recompiler ceux qui demeurent inchangés depuis la dernière compilation.
- À terme, dans une perspective de réutilisation, certains fichiers peuvent être compilés pour former des modules de bibliothèque. Stockés dans un répertoire connu du système, les fichiers objets de ces modules sont alors directement disponibles pour l'édition de liens (cf. chap. C4‑IV ) de tout programme qui ferait appel à ces modules.
Mais la programmation multi‑fichiers n'est pas toujours simple à mettre en œuvre. En plus d'une connaissance suffisante du système d'exploitation de la machine et de l'environnement de programmation, elle requiert un savoir‑faire technique en codage, notamment pour la répartition du code sur les différents fichiers. De plus, pour maîtriser l'interdépendance des modules et faire en sorte que la compilation se déroule sans erreurs, il faut :
- comprendre où placer les déclarations des types, variables, prototypes des fonctions et leurs définitions ;
- et par précaution, toujours coder une pseudo‑constante et une directive de compilation conditionnelle afin de prévenir toute possibilité de double inclusion d'un fichier (cf. chap. C4‑III ).
L'objectif de ce chapitre est donc d'apporter les connaissances de base indispensables pour pouvoir ensuite acquérir ce savoir‑faire dans la pratique. On abordera dans l'ordre les parties suivantes :
- On commencera par le cas général de compilation native en langage C (les mêmes principes valent en C++). On illustrera l'étude avec l'exemple concret d'un programme académique de calendrier s'exécutant sur un terminal de commandes en ligne, compilé avec GCC sous Linux.
- On poursuivra avec cas plus spécifique de compilation croisée d'un programme Arduino, pour lequel on traitera l'exemple concret un programme académique de clignotement d'une led à fréquences multiples. Même si ce programme est encore une fois élaboré sur un poste de travail à système Linux, le processus est assez similaire avec ce que l'on peut observer sous Windows.


Cas général d'un programme en langage C/C++
Sans entrer dans le cas beaucoup plus complexe des gros logiciels, on se propose de décrire le principe général de répartition sur plusieurs fichiers du code source d'un programme.
Pour fixer les idées, on imagine d'abord un exemple générique nommé simpleProgram. Habituellement, on crée un répertoire de projet homonyme – c'est‑à‑dire portant le même nom que le programme, même si ce n'est pas une contrainte impérative – dans lequel seront stockés tous les fichiers sources (cf. chap. C2‑I ).
Structure modulaire d'un code source en langage C
En langage C, une méthode générale de répartition du code source sur plusieurs fichiers est basée sur une structure en modules, avec typiquement :
- un module principal où est codé la fonction
main; - des modules auxiliaires pour répartir les autres fonctions.
En règle générale, chaque module est constitué de 2 fichiers source, de préférence homonymes pour expliciter l'appartenance au même module :
- un fichier d'en‑tête d'extension
.h(pour header en anglais) ; - un fichier d'implémentation d'extension
.c.
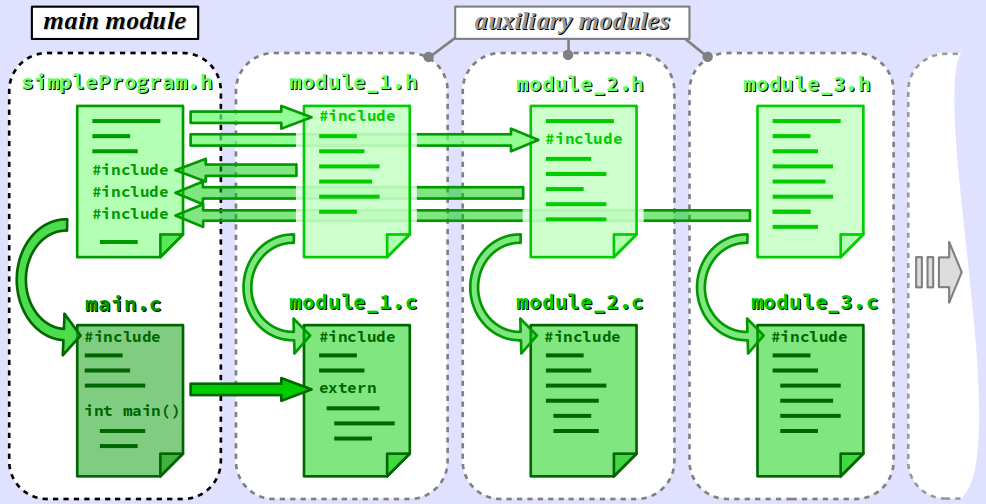
Tous les fichiers sources d'un programme sont liés entre eux par diverses directives d'inclusion, typiquement comme représenté sur la figure ci‑dessus et détaillées plus loin. En particulier, chaque fichier d'implémentation comporte une directive d'inclusion de son fichier d'en‑tête associé pour former une unité de compilation.
Il peut également exister d'autres liaisons, notamment celles relatives aux variables globales, via le mot‑clef extern (cf. infra ).
Toutefois, il importe de souligner que la méthode générale présentée ci‑dessus peut se décliner avec diverses variantes :
- Si le fichier d'en‑tête principal se limite à quelques directives d'inclusion, alors il peut être fusionné avec le fichier d'implémentation principal, conformément à la figure ci‑contre.
- Par ailleurs, lorsque les fichiers d'en‑tête sont peu volumineux, il est envisageable de les fusionner en un seul : celui du module principal. Chaque module auxiliaire est alors constitué de son seul fichier d'implémentation, qui commence par une directive d'inclusion de l'unique fichier d'en‑tête, conformément à la figure ci‑dessous.
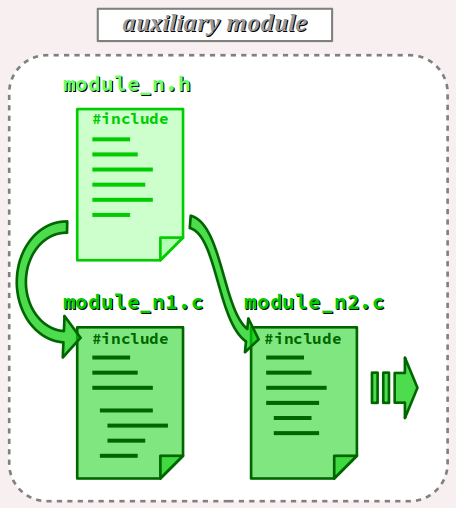
- Enfin, lorsque le programme comporte un module volumineux, il est possible de répartir son code sur plusieurs fichiers d'implémentation tout en conservant un seul fichier d'en‑tête, conformément à la figure ci‑contre.
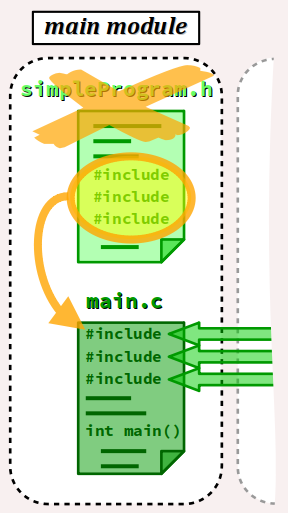
main. 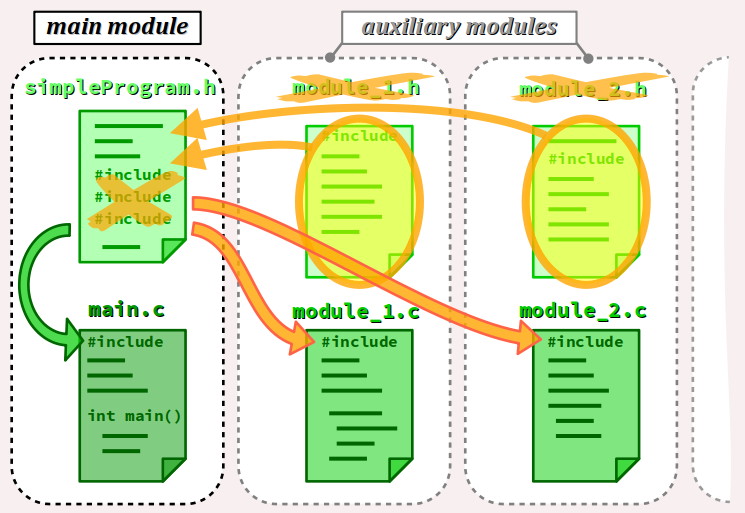
Comme expliqué au chap. C2‑I, le nommage main.c du fichier principal d'implémentation est une convention, pas une obligation.
Spécificités en langage C++
En langage C++, on adopte la même méthode générale de répartition du code source d'un programme sur plusieurs fichiers, avec seulement quelques spécificités pour les extensions de fichiers. Typiquement, on adopte :
- l'extension
.hhpour les fichiers d'en‑tête ; - l'extension
.cpppour les fichiers d'implémentation.
Ces aspects ont déjà été présentés plus en détail au chap. C4‑IV .
Principes de la répartition en fichiers

La structuration d'un programme en plusieurs modules est une tâche complexe, qui en général débouche sur diverses solutions. Dès qu'un programme devient volumineux, on aboutit à des conflits de classification inévitables. Typiquement se pose la question : dans quel module coder telle ou telle fonction ?
En général, au moins deux approches sont possibles.
- Au regard des spécifications auquel le programme doit répondre, on structure le code en grandes problématiques fonctionnelles : typiquement, le dialogue homme‑machine, les calculs techniques (le code dit « métier »), les commandes des actionneurs, les acquisitions par capteurs, les communications diverses, etc.
- Mais du point de vue des techniques d'implémentation, on est plutôt amené à structurer le code avec une logique d'objets : chaque module spécifique met en œuvre des variables d'une ou plusieurs classes spécifiques qui définissent toutes les fonctions pour manipuler ces objets.


Et bien entendu, ces deux approches peuvent être employées conjointement à différents niveaux de raffinement du code : ainsi, il est usuel d'adopter une logique d'objets dans chaque grande problématique fonctionnelle.
Les fichiers d'en‑tête

En principe, un fichier d'en‑tête – usuellement nommé avec l'extension .h en C ou .hpp en C++ – sert à coder, séparément du fichier d'implémentation, les déclarations publiques de types, de constantes et de fonctions (prototypes seuls) utilisées dans un module.
Le fichier peut également contenir des directives d'inclusion de fichiers, de définitions (pseudo‑constantes, pseudo‑fonctions…), de compilation conditionnelle, etc.
Ne contenant pas de code source algorithmique, ce fichier peut en principe être divulgué à d'éventuels partenaires de développement sans compromettre des aspects potentiellement confidentiels. C'est pourquoi on parle de fichier d'interface W.
Les déclarations codées dans un fichier d'en‑tête sont dites « publiques » dans la mesure où elles sont exploitables dans n'importe quel fichier source qui inclut ce fichier d'en‑tête par une directive #include.
A contrario, toutes les déclarations qui sont codées dans un fichier d'implémentation sont a priori exploitables seulement dans ce dernier. On peut donc considérer qu'elles sont « privées » (on verra toutefois que cette limitation peut aisément être contournée dans le cas des variables).
En règle générale, un fichier d'en‑tête n'est pas employé pour coder des instructions programmant des actions (même si cette pratique existe), ni des déclarations de variables globales (au risque sinon d'erreurs de compilation).
Considérons notre exemple générique d'un programme dont le fichier d'en‑tête principal est nommé simpleProgram.h. Comme expliqué au chapitre C4‑III , il doit avoir son contenu déclaratif en totalité protégé contre les doubles inclusions par une directive de compilation conditionnelle de la forme :
#ifndef SIMPLE_PROGRAM_H_INCLUDED #define SIMPLE_PROGRAM_H_INCLUDED // code protected against double inclusions #endif
Après cette directive de protection, le fichier d'en‑tête commence par des directives d'inclusion de tous les fichiers d'en‑tête des modules du programme (sauf lui‑même, bien entendu), ainsi que des fichiers d'en‑tête de bibliothèques. Par exemple, on peut avoir des directives de la forme suivante :
#include "module1.h" #include "module2.h" #include "module3.h" #include <stdio.h> // ...
Par ailleurs, il est possible que certains fichiers d'en‑tête auxiliaire .h commencent par la directive d'inclusion :
#include "simpleProgram.h"
afin de pouvoir exploiter les déclarations codées dans le fichier simpleProgram.h. Et comme le fichier d'en‑tête principal inclut lui‑même les fichiers d'en‑tête des modules auxiliaires, la protection contre les doubles inclusions empêche que ses propres déclarations lui soient incluses en retour.
Les fichiers d'implémentation

Un fichier d'implémentation, usuellement d'extension .c ou .cpp en C++, est un fichier dans lequel on code essentiellement la définition des fonctions déclarées dans le fichier d'en‑tête qui lui est associé.
Souvent, on parle spécifiquement de « fichier source » car c'est là que l'on trouve l'essentiel du code (les algorithmes mis en œuvre). Néanmoins, il s'agit d'un abus de langage, car en termes de compilation, un fichier d'en‑tête est aussi un fichier source – par opposition à un fichier objet ou un fichier exécutable (cf. chap. C4‑IV .
Dans le fichier d'implémentation principal – typiquement nommé avec l'extension main.c (ou .cpp) – on trouve en général :
- la directive d'inclusion du fichier d'en‑tête principal du programme ;
- la déclaration des variables globales du programme ;
- la définition de la fonction principale
mainqui, idéalement, devrait ne pas dépasser une page de moniteur pour que son algorithme soit simple à visualiser dans son ensemble. Dans cet objectif, la fonctionmainfait appel à de nombreuses fonctions de haut niveau définies dans les fichiers d'implémentation des différents modules auxiliaires.
Par ailleurs, chaque fichier d'implémentation auxiliaire comprend :
- la directive d'inclusion de son fichier d'en‑tête associé
.h, en principe de même nom ; - éventuellement des déclarations de données globales utilisées spécifiquement dans le fichier d'implémentation, chacune étant :
- précédée du mot‑clef
extern, si cette donnée est déjà déclarée dans un autre fichier d'implémentation ; - précédée du mot‑clef
static, si cette donnée doit rester locale au fichier d'implémentation (autrement dit que le codeur veut en interdire l'usage dans les autres fichiers par une déclaration avec le mot‑clefextern). - la définition de toutes les fonctions dont les prototypes sont déclarés dans le fichier d'en‑tête associé au fichier d'implémentation.
Organisation du répertoire de projet
On rappelle que pour les petits programmes (cf. chap. C1‑II :


- le développement peut très bien être mené à l'aide d'éditeur de code (Sublime Text ou autre…) ;
- la compilation – au sens large, c'est‑à‑dire avec l'assemblage et l'édition de liens – étant effectuée dans un terminal de commandes en ligne.
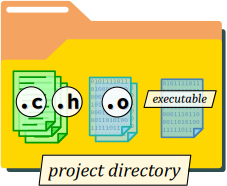
Dans un tel cas, l'organisation des fichiers source est totalement libre dès lors que leurs chemins d'accès respectifs sont saisis dans la commande de compilation. Toutefois, il est évidemment plus simple – et cela est vivement recommandé – de placer a minima tous les fichiers du programme dans ce qu'on appelle un répertoire de projet (cf. chap. C2‑I ).
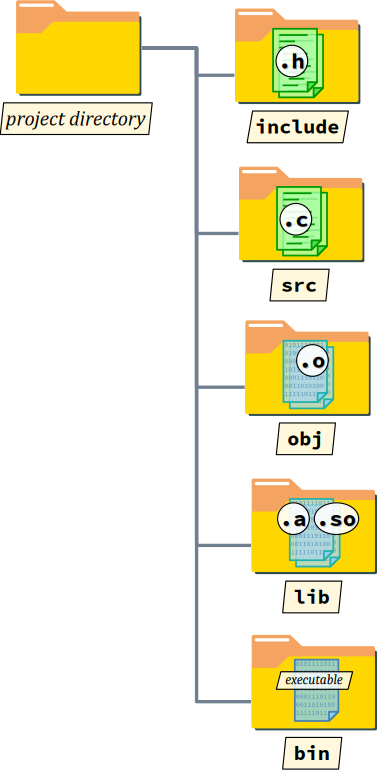
De plus, même si le programme comporte peu de fichiers source, il est rapidement malcommode de ranger au même niveau tous les fichiers, quels que soient leurs types respectives. La bonne pratique la plus courante consiste à les placer dans des sous‑répertoires spécifiques, nommées usuellement comme ci‑dessous :
-
includepour les fichiers d'en‑tête ; -
srcpour les fichiers sources d'implémentation ; -
objpour les fichiers objets ; -
libpour les bibliothèques (cf. chap. C4‑VI ) ; -
binpour le ou les fichiers exécutables.
Bien entendu, cette organisation nécessite d'adapter les commandes de compilation et d'édition de liens, ce que l'on va voir infra.
Par ailleurs, si le programme est d'usage fréquent sur le poste de travail, alors il est plus commode de placer le fichier exécutable – ou à défaut un lien symbolique vers ce dernier – dans un répertoire connu du système d'exploitation, par exemple, sous Linux :
/home/user/.local/bin
Commande de génération du code exécutable
Dans l'hypothèse d'un programme en langage C réparti sur plusieurs modules comme exposé supra , la commande de génération du code exécutable doit impérativement cibler tous les fichiers d'implémentation à compiler pour produire le code exécutable.
Quant aux fichiers d'en‑tête, ils n'ont pas besoin d'être ciblés puisqu'ils sont inclus dans le code source par des directives au préprocesseur. Seul le chemin d'accès à leur répertoire doit être indiqué au compilateur.
Avec GCC, dans le cas d'une compilation native et sans considération d'éventuelles options (avertissements, etc.), la commande de génération du code exécutable prend donc simplement la forme suivante :
gcc -Iinclude src/fichier_1.csrc/fichier_2.c…-o bin/fichier exécutable
où l'option -Iinclude ajoute le répertoire local include à la liste de ceux susceptibles de contenir des fichiers d'en‑tête (cf. chap. C4‑IV ).
Avec l'usage d'un joker * (wildcard – cf. chap. S1‑III ), cette commande peut se coder encore plus rapidement :
gcc -Iinclude src/*.c -o bin/fichier exécutable
puisqu'a priori, tous les fichiers d'implémentation dans le sous‑répertoire src sont à compiler.
Conservation des fichiers objets
On rappelle (cf. chap. C4‑IV ) que par défaut, les fichiers objets sont considérés comme intermédiaires par la commande gcc et donc ne sont pas conservés après la production du fichier exécutable.
Or justement, conserver les fichiers objets de chaque module permet d'éviter d'avoir à tout recompiler à chaque modification de tel ou tel fichier source.
Pour cela, plusieurs solutions sont possibles, notamment les deux suivantes :
- On peut compiler individuellement les fichiers sources d'implémentation à l'aide de l'option
-cpour produire à chaque fois un fichier objet, puis produire le fichier exécutable par édition de liens de tous les fichiers objets préalablement créés. C'est que qu'accomplit la succession de commandes ci‑dessous :
gcc -c -Iinclude src/fichier_1.c-o obj/fichier_1.o…gcc -c -Iinclude src/fichier_n.c-o obj/fichier_n.ogcc obj/*.o -o bin/fichier exécutable
-save-temps (cf. chap. C4‑IV ), sachant que de plus : - l'option
-dumpbasepermet d'imposer un préfixe aux fichiers intermédiaires différent de celui du nom du fichier exécutable – et éventuellement vide ; - l'option
-dumpdirpermet d'imposer un répertoire de destination pour les fichiers intermédiaires différent de celui du fichier exécutable ; - une commande supplémentaire
rm *.i && rm *.opermet de supprimer les fichiers intermédiaires autres que les fichiers de code objet.
gcc -save-temps -Iinclude src/*.c -o bin/fichier exécutable-dumpbase '' -dumpdir obj/ && rm obj/*.i obj/*.s
Après une première compilation, il est alors possible de recompiler individuellement chaque fichier d'implémentation qui a été modifié. Ensuite, pour actualiser le fichier exécutable, il suffit d'effectuer l'édition de liens de tous les fichiers objets. Dans le cas d'un gros programme, on peut ainsi économiser du temps de production de façon considérable.
Avec l'IDE VS Code
Rappel. On a découvert au chapitre C1‑II les principes de base de l'utilisation de VS code pour la programmation en langages C/C++ lorsque le code source est formé d'un seul fichier source :
- Lorsque le fichier source est actif dans l'éditeur de code, la génération du code exécutable peut être déclenchée par le raccourci CtrlshiftB (comme build) .
- Cette commande est définie dans le fichier
tasks.jsonautomatiquement créé par l'application dans le sous‑répertoire.vscode, lui‑même créé dans le répertoire de projet. Et ce fichier est modifiable à volonté pour adapter la commande de compilation aux besoins spécifiques du projet (invocation de telle ou telle option, etc.) .
Dans le cas d'un programme multi‑fichiers, l'application VS code n'est toutefois pas capable de créer automatiquement une commande de génération conforme aux spécificités du programme. Il revient donc au codeur d'apporter des modifications nécessaires dans le fichier tasks.json du projet.
Compte tenu des solutions élaborées précédemment, et en adoptant une approche générique, c'est‑à‑dire valable quel que soit le nom du répertoire de projet. Pour cela, il est utile de définir un espace de travail (workspace ‑ cf. chap. C1‑II ) associé au répertoire de projet
- On configure la tâche de génération par défaut (de type «
cppbuild», qui est associée au raccourci CtrlShiftB) avec la commande qui met en œuvre une compilation complète des fichiers sources (afin qu'elle soit toujours opérationnelle quelles que soient les modifications effectuées dans tel ou tel fichier) et qui effectue l'édition de liens pour produire le fichier exécutable, et qui conserve les fichiers objets. - On code deux nouvelle tâches :
- l'une pour effectuer uniquement la compilation du fichier source actif (à laquelle on peut par exemple associer le raccourci AltB) – typiquement, le fichier dans lequel on vient de coder des modifications ;
- l'autre pour effectuer l'édition de liens de tous les fichiers objets (à laquelle on peut par exemple associer le raccourci CtrlShiftAltL).
C'est justement ce que fait le code JSON proposé ci‑dessous, en remplacement complet des solutions proposées au chapitre C1‑II pour adapter le fichier tasks.json :
{
"tasks": [
{
"type": "cppbuild",
"label": "C/C++: gcc générer l'exécutable",
"command": "/usr/bin/gcc",
"args": [
"-fdiagnostics-color=always",
"-Wall",
"-Wextra",
"-Werror",
"-save-temps",
"-I${workspaceFolder}/include",
"${workspaceFolder}/src/*.c",
"-o",
"${workspaceFolder}/bin/${workspaceFolderBasename}",
"-dumpbase",
"''",
"-dumpdir",
"${workspaceFolder}/obj/",
"&&",
"rm",
"${workspaceFolder}/obj/*.i",
"${workspaceFolder}/obj/*.s"
],
"options": {
"cwd": "${workspaceFolder}"
},
"problemMatcher": [
"$gcc"
],
"group": {
"kind": "build",
"isDefault": true
},
"detail": "General pattern for a multi-file project"
},
{
"type": "shell",
"label": "Compile active C file",
"command": "gcc -I${workspaceFolder}/include -Wall -Wextra -Werror -c ${file} -o ${workspaceFolder}/obj/${fileBasenameNoExtension}.o",
"options": {
"cwd": "${workspaceFolder}"
},
"problemMatcher": [
"$gcc"
],
"presentation": {
"reveal": "always",
"panel": "shared"
},
"group": {
"kind": "build",
"isDefault": false
},
"detail": "Specifically coded in tasks.json"
},
{
"type": "shell",
"label": "Link all object files",
"command": "gcc ${workspaceFolder}/obj/*.o -o ${workspaceFolder}/bin/${workspaceFolderBasename}",
"options": {
"cwd": "${workspaceFolder}"
},
"problemMatcher": [
"$gcc"
],
"presentation": {
"reveal": "always",
"panel": "shared"
},
"group": {
"kind": "build",
"isDefault": false
},
"detail": "Specifically coded in tasks.json"
},
{
"type": "shell",
"label": "Run C/C++ File",
"command": "${workspaceFolder}/bin/${workspaceFolderBasename}",
"options": {
"cwd": "${workspaceFolder}"
},
"presentation": {
"reveal": "always",
"panel": "shared"
},
"isBackground": true,
"group": {
"kind": "test",
"isDefault": true
},
"detail": "Specifically coded in tasks.json"
},
{
"type": "shell",
"label": "C Compile and Run program",
"command": "${workspaceFolder}/bin/${workspaceFolderBasename}",
"options": {
"cwd": "${workspaceFolder}"
},
"dependsOn": [
"C/C++: gcc générer l'exécutable",
],
"dependsOrder": "sequence",
"presentation": {
"reveal": "always",
"panel": "shared"
},
"group": {
"kind": "test",
"isDefault": false
},
"detail": "Specifically coded in tasks.json"
},
],
"version": "2.0.0"
}
Remarques.
- La première tâche étant de type
cppbuildet non passhell, elle ne peut pas être définie par une commande sur une seule ligne. Néanmoins, ses arguments peuvent servir à enchaîner d'autres commandes (cf. les lignes nº 24 à 26 qui invoque une commandermpour supprimer des fichiers intermédiaires). - Parmi les options de compilation, on a bien évidemment invoqué celles concernant les avertissements (
-Wall -Wextra -Werror– cf. chap. C1‑II ), qui ont été passées sous silence dans la présentation générale de la commande de compilation multi‑fichiers pour ne pas alourdir inutilement l'exposé.
Quant aux raccourcis claviers, ils sont définis par le code JSON ci‑dessous, à insérer dans le fichier keybindings.json de l'utilisateur de VS Code :
{
"key": "alt+b",
"command": "workbench.action.tasks.runTask",
"args": "Compile active C file",
"when": "editorLangId == 'c' || editorLangId == 'cpp'"
},
{
"key": "ctrl+shift+alt+l",
"command": "workbench.action.tasks.runTask",
"args": "Link all object files",
"when": "editorLangId == 'c' || editorLangId == 'cpp'"
}
Exemple de programme multi‑fichiers en langage C
Description du programme
Contexte

Sous Linux, la commande cal ou ncal W permet d'afficher la page de calendrier d'un mois donné, avec possiblement la numérotation des semaines, comme le montre un exemple d'exécution ci‑dessous pour le mois de janvier 1900.
ncal -w -b 1 1900Janvier 1900 w| lu ma me je ve sa di 1| 1 2 3 4 5 6 7 2| 8 9 10 11 12 13 14 3| 15 16 17 18 19 20 21 4| 22 23 24 25 26 27 28 5| 29 30 31
Cahier des charge
On se propose de coder un programme similaire d'affichage de calendrier où, en boucle, l'utilisateur peut cibler une date donnée, de telle sorte que dans la page de calendrier affiché, le numéro du jour saisi par l'utilisateur apparaîtra précédé du symbole >.
Remarques.
- Pour des considérations académiques, le but étant de mettre en œuvre une programmation multi‑fichiers intéressante, on choisit ne pas recourir au module
timede la bibliothèque standard du langage C. - On limite la saisie des dates de sorte qu'elles ne soient pas antérieures à 1583 (sachant que l'instauration du calendrier Grégorien date de 1582 en France – cf. chap. R2‑VI R).
Structure du programme
Le code source du programme est structuré en 5 fichiers répartis sur 3 modules, comme le montre la figure ci‑dessous :
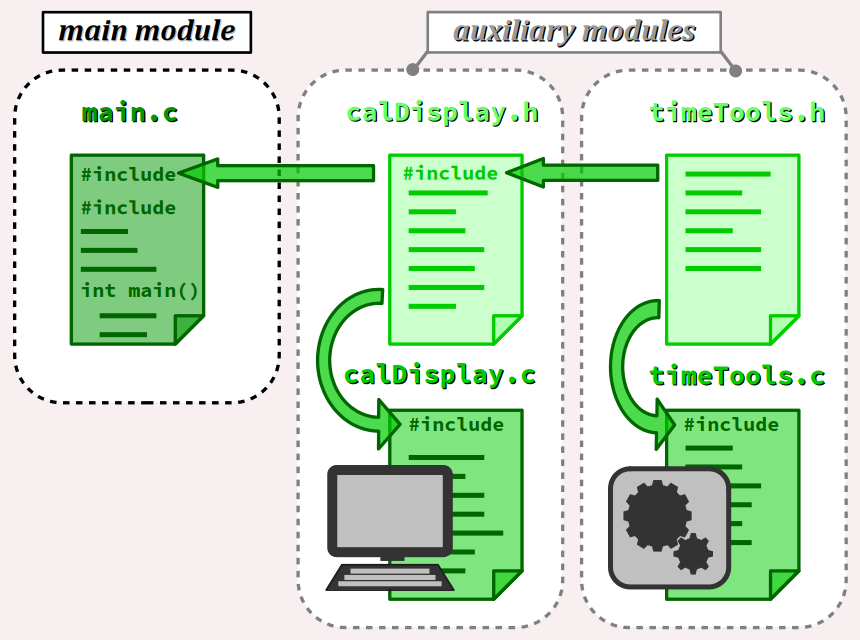
- Le module principal est constitué seulement du fichier d'implémentation
main.c. - Un premier module auxiliaire regroupe toutes les fonctions d'affichage du calendrier, constitué :
- d'un fichier d'en‑tête
calDisplay.h - et d'un fichier d'implémentation
calDisplay.c. - Un deuxième module auxiliaire regroupe toutes les fonctions de calcul du calendrier, constitué :
- d'un fichier d'en‑tête
timeTools.h - et d'un fichier d'implémentation
timeTools.c.
timeTools.h codée dans calDisplay.h. Pour faciliter l'expérimentation, le code source du programme est téléchargeable sous la forme d'un fichier d'archive .zip au lien suivant .

Il peut être testé dans l'environnement de programmation en ligne OnlineGDB, en cliquant sur le bouton New File (cf. la capture d'écran ci‑contre) pour ajouter des fichiers supplémentaires.
Le module principal

Le code source du fichier principal d'implémentation main.c, qui ne contient que quelques directives d'inclusion et la fonction principale main (point d'entrée du programme) est donné ci‑dessous :
/* SIMPLE CALENDAR PROGRAM
* display a full date with names of day and month
* and the calendar of the current month (6 lines of 7 days)
* with week numbers heading each line
*/
#include <stdio.h>
#include <stdlib.h>
#include "calDisplay.h"
int main(void)
{
printf(">>>>>>> Simple Calendar <<<<<<<\n\n");
while (1) {
int day = 0, month = 0, year = 0;
printf("Type a date with format day/month/year\n");
printf("(year ≥ %d, day = 0 to quit)\n", MINIMAL_YEAR);
while (1) {
printf(" > ");
scanf(" %02d/%02d/%d", &day, &month, &year);
if (day == 0) {
printf("\nGoodbye.\n");
exit(0);
}
if (isDateOutOfRange(day, month, year)) {
printf("Date is out of range or wrong!\n");
}
else {
break;
}
}
printFullMonth(day, month, year);
}
}
Au regard de ce code, on peut formuler les observations suivantes :
- Il n'y a pas de partie déclarative à proprement parler, mais seulement quelques directives d'inclusion qu'il n'est pas utile de déporter dans un fichier d'en‑tête.
- L'essentiel de la fonction
mainconsiste à gérer les saisies de l'utilisateur. - La complexité cachée du code est déportée dans deux fonctions auxiliaires codées dans le module
calDisplay: -
isDateOutOfRange, appelée à la ligne nº 28, pour vérifier la correction de la date saisie, c'est‑à‑dire sa compatibilité avec la limite spécifiée supra sa conformité à l'arithmétique calendaire ; -
printFullMonth, appelée à la ligne nº 35, qui réalise l'affichage demandé ;
timeTools.h ; calDisplay.h. Le module d'affichage

Le module d'affichage calDisplay regroupe, comme son nom l'indique, toutes les fonctions permettant l'affichage dans le terminal d'exécution de la page de calendrier dans laquelle s'inscrit une date donnée.
Fichier d'en‑tête
Le code fichier d'en‑tête calDisplay.h du module d'affichage est le suivant :
/* SIMPLE CALENDAR PROGRAM * calendar display functions * (printing text in the running terminal) */ #ifndef CALENDAR_DISPLAY_H_INCLUDED #define CALENDAR_DISPLAY_H_INCLUDED #include <stdio.h> #include "timeTools.h" /* All function prototypes */ void printShortNameOfDay(int wday); void printFullNameOfDay(int wday); void printFullNameOfMonth(int month); void printFullDate(int wday, int day, int month, int year); void printDaysHeader(void); void printFullMonth(int day, int month, int year); #endif // CALENDAR_DISPLAY_H_INCLUDED
Au regard de ce code, on peut formuler les observations suivantes :
- Par précaution d'usage, le fichier est protégé contre les inclusions multiples par une directive (cf. chap. C4‑III ).
- La partie déclarative se limite à celle des prototypes des fonctions, qui sont toutes des fonctions d'affichage dans le terminal d'exécution.
Fichier d'implémentation
Le code fichier d'implémentation caldisplay.c du module d'affichage est le suivant :
/* SIMPLE CALENDAR PROGRAM
* calendar display functions
* (printing text in the running terminal)
*/
#include "calDisplay.h"
void printShortNameOfDay(int wday)
{
switch (wday) {
case MON : printf("Mon"); break;
case TUE : printf("Tue"); break;
case WED : printf("Wed"); break;
case THU : printf("Thu"); break;
case FRI : printf("Fri"); break;
case SAT : printf("Sat"); break;
case SUN : printf("Sun"); break;
}
}
void printFullNameOfDay(int wday)
{
switch (wday) {
case MON : printf("Monday"); break;
case TUE : printf("Tuesday"); break;
case WED : printf("Wednesday"); break;
case THU : printf("Thursday"); break;
case FRI : printf("Friday"); break;
case SAT : printf("Saturday"); break;
case SUN : printf("Sunday"); break;
}
}
void printFullNameOfMonth(int month)
{
switch (month) {
case JAN : printf("January"); break;
case FEB : printf("February"); break;
case MAR : printf("March"); break;
case APR : printf("April"); break;
case MAY : printf("May"); break;
case JUN : printf("June"); break;
case JUL : printf("July"); break;
case AUG : printf("August"); break;
case SEP : printf("September"); break;
case OCT : printf("October"); break;
case NOV : printf("November"); break;
case DEC : printf("December"); break;
}
}
void printFullDate(int wday, int day, int month, int year)
{
printf("\n ");
printFullNameOfDay(wday);
printf(", ");
printFullNameOfMonth(month);
printf(" %d, %d\n\n", day, year);
}
void printDaysHeader(void)
{
printf("Wk|");
for (int wd = MON; wd <= SUN; wd++) {
printf(" ");
printShortNameOfDay(wd);
}
}
void printFullMonth(int day, int month, int year)
{
int wday = dayOfWeek(day, month, year);
printFullDate(wday, day, month, year);
int d = previousMonday(month, year); // looping day to be printed
int w = weekInYear(1, month, year); // week of d
int m = (d == 1) ? month : previousMonth(month); // month of d
int y = w == lastWeekInYear(year - 1) ? year - 1 : year;
// print an array of 6 lines of 7 days from Monday to Sunday
printDaysHeader();
for (int count = 0; count < 6 * 7; count++) {
if (count % 7 == 0) { // linebreak at each end of week
printf("\n%2d| ", w); // print the week number before monday
w = nextWeek(w, y); // increment the current week number
if (w == 1) {
y++; // increment the current year if first week
}
}
if (d == day && m == month) {
printf(">%2d ", d); // mark the day of the date with '>'
}
else {
printf("%3d ", d); // all others days are normally printed
}
d = d % nbOfDaysInMonth(m, year) + 1; // increment the current day
if (d == 1) {
m = nextMonth(m); // increment the current month if first day
}
}
printf("\n\n");
}
Au regard de ce code, on peut formuler les observations suivantes :
- Le fichier ne comporte aucune partie déclarative qui lui soit propre.
- Les quatre premières fonctions sont des routines d'affichage d'éléments de date (nom des mois et des jours, date complète).
- Les deux autres sont réellement des fonctions spécifiques aux besoins du programme principal :
-
printDaysHeaderaffiche la première ligne du calendrier (noms des jours de la semaine formant les têtes de colonnes du tableau). -
printFullMonthaffiche le reste du tableau. C'est la seule fonction qui soit algorithmiquement un peu complexe. Elle est basée sur une boucle répétitive à 42 itérations puisque le tableau est constitué de 6 lignes à 7 colonnes.
Le module de calcul

Le module de calcul timeTools regroupe toutes les fonctions de calcul spécifiques à l'arithmétique calendaire, c'est‑à‑dire qui permettent par exemple de calculer le nombre de jours dans un mois donnée, le nombre de jours dans une année, etc.
Fichier d'en‑tête
Le code fichier d'en‑tête timeTools.h du module de calcul est le suivant :
/* SIMPLE CALENDAR PROGRAM
* time calculation functions
* following the calendar arithmetic
*/
#ifndef TIME_TOOLS_H_INCLUDED
#define TIME_TOOLS_H_INCLUDED
#include <stdbool.h>
enum DayOfWeek {MON = 1, TUE, WED, THU, FRI, SAT, SUN};
enum Month {JAN = 1, FEB, MAR, APR, MAY, JUN, JUL, AUG, SEP, OCT, NOV, DEC};
extern int const MINIMAL_YEAR;
/* All function prototypes */
bool isLeapYear(int year);
int nbOfDaysInMonth(int month, int year);
int nbOfDaysInYear(int year);
int dayInYear(int day, int month, int year);
int lastWeekInYear(int year);
int weekInYear(int day, int month, int year);
int previousWeek(int week, int year);
int nextWeek(int week, int year);
int dayOfWeek(int day, int month, int year);
int previousMonth(int month);
int nextMonth(int month);
int previousMonday(int month, int year);
bool isDateOutOfRange(int day, int month, int year);
#endif
Au regard de ce code, on peut formuler les observations suivantes :
- Par précaution d'usage, le fichier est protégé contre les inclusions multiples par une directive (cf. chap. C4‑III ).
- La partie déclarative comporte :
- des déclarations de types énumérés de constantes associées aux numéros des jours et des mois, pour une bonne lisibilité du code ;
- la déclaration de la constante
MINIMAL_YEARqui limite l'année saisie par l'utilisateur ; il s'agit d'une donnée externe afin qu'elle soit utilisable dans tout fichier faisant l'inclusion de ce module (sa déclaration complète est codée dans le fichier d'implémentationtimeTools.c) ; - les prototypes des fonctions.
Fichier d'implémentation
Le code fichier d'implémentation timeTools.c du module de calcul est le suivant :
/* SIMPLE CALENDAR PROGRAM
* time calculation functions
* following the calendar arithmetic
*/
#include "timeTools.h"
const int MINIMAL_YEAR = 1583; // Gregorian calendar adopted in 1582
const int EPOCH_0_YEAR = 1900; // Reference date to calculate week numbers
/* no comment (classic formula) */
bool isLeapYear(int year)
{
return (year % 4 == 0 && year % 100 != 0) || year % 400 == 0;
}
/* no comment (everybody knows this) */
int nbOfDaysInMonth(int month, int year)
{
switch (month) {
case FEB :
return (isLeapYear(year)) ? 29 : 28;
case APR : case JUN : case SEP : case NOV :
return 30;
case JAN : case MAR : case MAY : case JUL ... AUG : case OCT : case DEC :
return 31;
default :
return 0;
}
}
/* no comment (everybody knows this) */
int nbOfDaysInYear(int year)
{
return isLeapYear(year) ? 366 : 365;
}
/* returns the position number of the day in a year (1 -> 365 or 366) */
int dayInYear(int day, int month, int year)
{
int nbOfDays = 0;
for (int m = JAN; m < month; m++) {
nbOfDays += nbOfDaysInMonth(m, year);
}
return nbOfDays + day;
}
/* returns the number of the last week in a year (52 or 53)
according to ISO 8601 */
int lastWeekInYear(int year) {
// special cases when the year has 53 weeks
if (dayOfWeek(1, JAN, year) == THU || (isLeapYear(year) && dayOfWeek(1, JAN, year) == WED)) {
return 53;
}
// general case
else {
return 52;
}
}
/* returns the position number of the week in a year (1 -> 52 or 53)
according to ISO 8601 */
int weekInYear(int day, int month, int year)
{
int dayInThisYear = dayInYear(day, month, year);
int wdayOfJan1 = dayOfWeek(1, JAN, year);
// based on the nb of days elapsed in the year
// 1) offsetting the week day of January 1st
// 2) divide by 7 (week length)
int rawWeekNb = (wdayOfJan1 + dayInThisYear - 2) / 7;
// and here we apply the ISO 8601 standard
if (wdayOfJan1 < FRI) { // 1st of January is yealier than Friday
rawWeekNb++; // partial first week is week number 1
}
// else partial first week is counted as the last one of last year
else if (dayInThisYear <= 8 - wdayOfJan1) {
return lastWeekInYear(year - 1);
}
// in any case, the week number does not exceed the last week number
return rawWeekNb <= lastWeekInYear(year) ? rawWeekNb : 1;
}
/* number of the previous week, cyclically (1 -> 52 or 53) */
int previousWeek(int week, int year)
{
return week >= 1 ? lastWeekInYear(year - 1) : week - 1;
}
/* number of the previous week, cyclically (1 -> 52 or 53) */
int nextWeek(int week, int year)
{
return week >= lastWeekInYear(year) ? 1 : week + 1;
}
/* number of days ellapsed since/missing before 01/01/1900 */
int nbOfDaysSinceEpoch0(int day, int month, int year)
{
int nbOfDays = 0;
if (year >= EPOCH_0_YEAR) {
for (int y = EPOCH_0_YEAR; y < year; y++) { // elapsed years since 1900
nbOfDays += nbOfDaysInYear(y);
}
// count of the
nbOfDays += dayInYear(day, month, year); // elapsed day this year
}
else { // idem but with a negative value
for (int y = EPOCH_0_YEAR - 1; y >= year; y--) { // years before 1900
nbOfDays -= nbOfDaysInYear(y); // this year included
}
nbOfDays += dayInYear(day, month, year); // elapsed days decounted
}
return nbOfDays;
}
/* day of week of a date (1 = Monday -> 7 = Sunday) */
int dayOfWeek(int day, int month, int year)
// for the record, EPOCH 0 (01/01/1900) is a Monday (useful reference date)
// proceeding by arithmetic modulo 7 plus 1 from EPOCH 0
{
if (year > EPOCH_0_YEAR) { // after 1900
return 1 + (nbOfDaysSinceEpoch0(day, month, year) - 1) % 7;
}
else { // before 1900
return 7 + nbOfDaysSinceEpoch0(day, month, year) % 7; // complementary
}
}
/* number of the previous month, cyclically (1 -> 12) */
int previousMonth(int month)
{
return month == JAN ? DEC : month - 1;
}
/* number of the next month, cyclically (1 -> 12) */
int nextMonth(int month)
{
return month == DEC ? JAN : month + 1;
}
/* returns the day-in-month number of the previous monday of a given month and year */
int previousMonday(int month, int year)
{
int wdayOf1 = dayOfWeek(1, month, year); // week day of the first day of the month
// if wdayOf1 == MONDAY then no change: previousMonday = 1;
// else, previousMonday = last day of previous month (31/30/29/28) - (wdayOf1 - 2)
return (wdayOf1 == MON) ? 1 : nbOfDaysInMonth(previousMonth(month), year) - (wdayOf1 - 2);
}
/* date may be out of range if wrongly typed by the user */
bool isDateOutOfRange(int day, int month, int year)
{
if (day < 1 || day > nbOfDaysInMonth(month, year) ||
month < MON || month > DEC ||
year < MINIMAL_YEAR) {
return true;
}
return false;
}
Au regard de ce code, on peut formuler les observations suivantes :
- On trouve une partie déclarative spécifique, avec :
- la déclaration complète de la constante
MINIMAL_YEAR, qui a été déclarée externe dans le fichiertimeTools.h– cf. supra ; - la déclaration de la constante
EPOCH_0_YEARen raison de sa particularité remarquable pour le calcul des jours de la semaine – le 1er janvier 1900 tombe un lundi. - La complexité de certains calculs (numéro des semaines, jour de la semaine) est résolue par la définition de nombreuses routines :
-
nbOfDaysInMonthqui détermine le nombre de jours dans un mois ; -
nbOfDaysInYearqui détermine le nombre de jours dans une année ; - etc.
- Le calcul le plus compliqué est certainement celui du numéro de la semaine dans l'année d'une date donnée, réalisé par la fonction
weekInYear. - Cette semaine appartient à l'année dans laquelle elle comporte la majorité de ses jours (il ne peut pas y avoir égalité puisqu'une semaine dure 7 jours).
- Il faut donc que le jour de l'an tombe au plus tard un jeudi pour qu'une semaine soit considérée comme faisant partie de la nouvelle année (sinon, elle est considérée comme la dernière semaine de l'année précédente).
Production et analyse du code exécutable

Pour produire le fichier exécutable du programme de calendrier tout en gardant les fichiers objets, on peut bien entendu procéder à l'aide de la commande unique proposée supra :
gcc -save-temps *.c -o bin/calendar -dumpbase '' -dumpdir obj/ && rm obj/*.i obj/*.s
On obtient alors 3 fichiers objets dans le répertoire obj :
ls -l objtotal 32 -rw-rw-r-- 1 fg fg 6880 mars 8 23:23 calDisplay.o -rw-rw-r-- 1 fg fg 2488 mars 8 23:23 main.o -rw-rw-r-- 1 fg fg 4480 mars 8 23:23 timeTools.o
et le fichier exécutable dans le répertoire bin :
ls -l bintotal 24 -rwxrwxr-x 1 fg fg 17056 mars 8 23:23 calendar
Parce qu'il est produit par édition de liens dynamiques (choix par défaut, cf. chap. C4‑IV ), cet exécutable est à peine plus volumineux que la somme des fichiers objets dont il est issu. Et il utilise toutes les fonctions qui y sont codées. On peut le vérifier grâce à la commande nm (name mangling – cf. chap. C4‑IV ) combinée avec un filtrage approprié (commande grep – cf. chap. S1‑IV S) :
nm -U bin/calendar | grep ' T ' | grep -v ' _'000000000000196e T dayInYear 0000000000001bc2 T dayOfWeek 0000000000001cf2 T isDateOutOfRange 000000000000183e T isLeapYear 00000000000019bb T lastWeekInYear 000000000000173e T main 00000000000018b3 T nbOfDaysInMonth 0000000000001943 T nbOfDaysInYear 0000000000001b23 T nbOfDaysSinceEpoch0 0000000000001c7c T nextMonth 0000000000001af3 T nextWeek 0000000000001c9c T previousMonday 0000000000001c5c T previousMonth 0000000000001ac4 T previousWeek 000000000000154d T printDaysHeader 00000000000014da T printFullDate 0000000000001598 T printFullMonth 00000000000012a5 T printFullNameOfDay 0000000000001381 T printFullNameOfMonth 00000000000011c9 T printShortNameOfDay 0000000000001a18 T weekInYearnm -U obj/calDisplay.o | grep ' T '0000000000000384 T printDaysHeader 0000000000000311 T printFullDate 00000000000003cf T printFullMonth 00000000000000dc T printFullNameOfDay 00000000000001b8 T printFullNameOfMonth 0000000000000000 T printShortNameOfDaynm -U obj/timeTools.o | grep ' T '0000000000000130 T dayInYear 0000000000000386 T dayOfWeek 00000000000004b6 T isDateOutOfRange 0000000000000000 T isLeapYear 000000000000017d T lastWeekInYear 0000000000000075 T nbOfDaysInMonth 0000000000000105 T nbOfDaysInYear 00000000000002e7 T nbOfDaysSinceEpoch0 0000000000000440 T nextMonth 00000000000002b7 T nextWeek 0000000000000460 T previousMonday 0000000000000420 T previousMonth 0000000000000288 T previousWeek 00000000000001da T weekInYear
Ici :
- l'option
-Upermet de lister seulement les objets définis ; - le filtrage d'inclusion de la chaîne
grep ' T 'permet de lister seulement les objets appartement à la section.textc'est‑à‑dire les fonctions (cf. chap. C4‑II ) ; - le filtrage d'exclusion de la chaîne
grep -v ' _'permet d'exclure de la liste les fonctions de la bibliothèque CRT comme_init(cf. chap. C4‑IV ).
Scénario d'exécution
Juste pour fixer les idées, on donne ci‑dessous un scénario d'exécution du programme dans un terminal en saisissant successivement deux dates, l'une avant 1900 et l'autre après 1900. (Rappelons en effet que l'année 1900 est une référence commode pour le calcul des jours de la semaine – cf. supra ).
De plus, les dates sont choisies spécialement pour mettre en évidence les changements d'années, qui sont particuliers pour le calcul des numéros de semaine – cf. supra.
./calendar>>>>>>> Simple Calendar <<<<<<< Type a date with format day/month/year (year ≥ 1583, day = 0 to quit) > 3/1/1892 Sunday, January 3, 1892 Wk| Mon Tue Wed Thu Fri Sat Sun 53| 28 29 30 31 1 2 > 3 1| 4 5 6 7 8 9 10 2| 11 12 13 14 15 16 17 3| 18 19 20 21 22 23 24 4| 25 26 27 28 29 30 31 5| 1 2 3 4 5 6 7 Type a date with format day/month/year (year ≥ 1583, day = 0 to quit) > 16/12/1928 Sunday, December 16, 1928 Wk| Mon Tue Wed Thu Fri Sat Sun 48| 26 27 28 29 30 1 2 49| 3 4 5 6 7 8 9 50| 10 11 12 13 14 15 >16 51| 17 18 19 20 21 22 23 52| 24 25 26 27 28 29 30 1| 31 1 2 3 4 5 6 Type a date with format day/month/year (year ≥ 1583, day = 0 to quit) > 0 Goodbye.
On peut vérifier que ces sorties sont conformes à celles de la commande ncal sous Linux :
ncal -w -b 1 1892Janvier 1892 w| lu ma me je ve sa di 53| 1 2 3 1| 4 5 6 7 8 9 10 2| 11 12 13 14 15 16 17 3| 18 19 20 21 22 23 24 4| 25 26 27 28 29 30 31ncal -w -b 12 1928Décembre 1928 w| lu ma me je ve sa di 48| 1 2 49| 3 4 5 6 7 8 9 50| 10 11 12 13 14 15 16 51| 17 18 19 20 21 22 23 52| 24 25 26 27 28 29 30 1| 31
Par ailleurs, on peut remarquer que :
- le 1er janvier 1882 est bien repéré comme appartenant à la semaine nº 53 de l'année 1881 puisqu'il tombe un vendredi (cette semaine comporte 4 jours en 1881 contre seulement 3 en 1882).
- le 31 décembre 1927 est bien repéré comme appartenant à la semaine nº 1 de l'année 1928 puisqu'il tombe un lundi (cette semaine comporte seulement 1 jour en 1927 contre 6 en 1928).
Cas général d'un programme Arduino
Par rapport au contexte de la programmation généraliste en C/C++, la production d'un programme Arduino pour carte à microcontrôleur présente des points communs mais aussi certaines spécificités en matière de programmation multi‑fichiers. Il est indispensable de les connaître et les comprendre pour garantir une bonne mise en œuvre.
Par ailleurs, rappelons que s'il n'est malheureusement pas possible de mettre en œuvre une programmation multi‑fichiers dans l'environnement de simulation Tinkercad, cela est en revanche faisable avec Wokwi, même avec l'offre gratuite (cf. chap. C1‑III ).
Organisation des fichiers dans l'environnement Arduino
En programmation des cartes Arduino et compatibles, on peut suivre le même principe de répartition sur plusieurs fichiers du code source que dans le contexte d'une programmation généraliste, avec une structuration en modules (cf. supra ).

De plus, le répertoire de projet doit contenir tous les fichiers sources du programme, à l'exception des fichiers de bibliothèque Arduino qui peuvent être rangés dans des répertoires externes (et à condition qu'ils soient ciblés par l'IDE).
Ces fichiers sources peuvent porter diverses extensions possibles, notamment .ino, .cpp, .c, .h. Mais attention ! le choix de ces extensions n'est pas indifférent : l'IDE se base dessus pour effectuer des traitements différentiés sur les fichiers sources selon leur extension, comme on va le voir dans la section suivante.
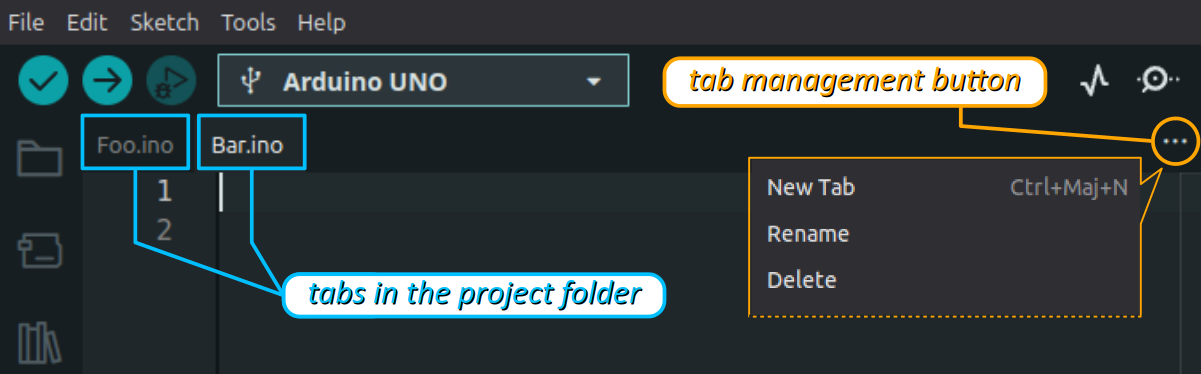
De plus, lors de l'ouverture d'un fichier .ino, l'IDE Arduino ouvre simultanément tous les fichiers de code source (.ino, .cpp, .h, etc.) placés dans le répertoire de projet. Chaque fichier apparaît dans un onglet séparé – en anglais, tab.
Et on trouve tout à droite dans la barre supérieure de la fenêtre principale de l'IDE un bouton de gestion des onglets, qui permet de créer/renommer/effacer/sélectionner un fichier source sans avoir à faire ces manipulations dans l'explorateur de fichier du système d'exploitation du poste de travail.
Traitements spécifiques opérés par l'IDE Arduino

Comme expliqué aux chap. C2‑I et C4‑I , pour rendre la programmation des cartes à microcontrôleur accessible à des non‑spécialistes, avant toute compilation, l'IDE Arduino effectue des traitements préliminaires spécifiques sur le code source, un peu à la manière d'un préprocesseur.
Ces traitements sont opérés en arrière‑plan (avant le processus de compilation), ils sont transparents pour l'utilisateur de l'IDE. Ils sont spécifiquement adaptés à chaque famille de carte Arduino.
L'IDE commence par créer un répertoire temporaire de compilation dans l'espace réservé à cet effet par le système d'exploitation du poste de travail (sous Linux, typiquement /tmp/arduino_build_xxxxxx/ où xxxxxx est un nouveau numéro généré automatiquement). Ce n'est donc pas le répertoire de projet.
Dans un sous‑répertoire nommé sketch du répertoire temporaire de compilation :
- Le fichier source principal de compilation est créé par copie directe du fichier « standard »
main.cppA (réf. pour les cartes à cœur AVR). - Un fichier d'implémentation auxiliaire d'extension
.cppest construit par concaténation – c'est‑à‑dire mise bout‑à‑bout – du contenu tous les fichiers sources d'extension.inoplacés dans le répertoire de projet : - en commençant par le fichier principal du projet, celui identifié par homonymie avec le répertoire de projet, où l'utilisateur a codé les fonction
setupetloop; - puis en procédant par ordre alphabétique pour les autres fichiers (mais pas les éventuels fichiers ayant une autre extension comme
.cppou.h). - ajout en première ligne la directive
#include <Arduino.h>; - génération des prototypes de toutes les fonctions définies dans ces fichiers.
- Enfin, tous les autres fichiers sources (
.h,.cppetc.) présents dans le répertoire de projet sont incorporés mais sans y effectuer des modifications significatives (seules des directives de marquage de lignes#linesont ajoutées).
main qui appelle les fonctions setup et loop (cf. chap. C2‑I ). 
C'est seulement après tout cela, lorsque le répertoire de compilation est prêt, qu'une chaîne de compilation GCC est invoquée en C++ avec une commande complexe (cf. infra ).
Consignes pour la programmation multi‑fichiers Arduino
Compte tenu des traitements spécifiques qui l'on vient de décrire, en plus de la méthode générale de répartition du code source proposée supra , on peut formuler les remarques suivantes lorsque l'on code un programme Arduino :
- La répartition sur plusieurs fichiers d'extension
.inopeut faciliter le travail du codeur mais n'apporte aucun gain en termes de temps de compilation puisque tous ces fichiers sont finalement concaténés en un seul et ne forme donc qu'une seule unité de compilation. - Il est donc préférable de surtout privilégier la répartition du code source sur plusieurs fichiers d'extension
.cpppour former plusieurs unités de compilation et ainsi gagner du temps lors de la mise au point du programme (les unités non modifiées n'ayant pas besoin d'être recompilées).
.cpp emploient des fonctions Arduino (par exemple, pinMode ou autre), alors il est indispensable de coder une directive #include <Arduino.h> au début du fichier ou dans son fichier d'en‑tête associé. Il importe aussi de prendre conscience qu'avec l'IDE Arduino, les fichiers objets et le fichier exécutable produits par la chaîne de compilation sont stockés dans un répertoire temporaire. A priori, ce répertoire est conservé tant que le projet est ouvert, mais il n'a pas vocation à être pérennisé dans la durée.
Ainsi, à chaque ouverture d'un projet qui était auparavant fermé, la première compilation est a priori plus longue que les suivantes puisqu'elle doit reprendre à zéro la production de tous les fichiers objets. C'est seulement ensuite que l'on bénéficie d'un gain de temps grâce à la structuration du code en plusieurs unités de compilation.
Exemple de programme Arduino multi‑fichiers
Il s'agit d'un programme « académique » qui met en œuvre juste une led et un bouton-poussoir, comme avec le montage du TP n° 1 du chapitre C2 . Nommé multiSpeedBlink, ce programme commande le clignotement de la led avec une demi-période réglable : partant d'une valeur donnée (2 s), à chaque appui sur le bouton, la période est divisée par 2, et au bout de 8 appuis, la led s'éteint. Le programme est réparti sur 8 fichiers formant 4 modules :
- le module principal,
- un module d'entrées‑sorties booléennes,
- un module de changement de la fréquence de clignotement,
- un module de détection des fronts montants sur le bouton-poussoir.
Module principal
Fichier d'en‑tête principal multiSpeedBlink.h
Dans une directive de compilation conditionnelle de protection contre les doubles expansions, il contient :
- les directives d'inclusion des trois fichiers d'en‑tête des autres modules du programme ;
- les directives de définition des pseudo‑constantes (numéros des broches utilisées) et les déclarations des constantes du programmes pour le réglage de la période de clignotement.
#ifndef MULTI_SPEED_BLINK_H_INCLUDED #define MULTI_SPEED_BLINK_H_INCLUDED #include "logicalSignals.h" #include "pinManagement.h" #include "blinkSpeedManagement.h" #define LED_PIN 2 #define BUTTON_PIN 4 const uint32_t BASE_BLINK_HALF_PERIOD = 2000000; // in microseconds (= 2 s) const uint16_t MAX_BLINK_SPEED = 256; // max divisor of the base period #endif // MULTI_SPEED_BLINK_H_INCLUDED
Fichier d'implémentation principal multiSpeedBlink.ino
Il contient :
- la directive d'inclusion du fichier d'en‑tête principal ;
- la déclaration des variables globales, l'une étant du type structuré
LogicalSignaldéfini dans le fichierLogicalSignals.h; - la définition des fonctions
setupetloopqui n'appellent que des fonction de haut niveau, définies dans d'autres fichiers.
#include "multiSpeedBlink.h"
// global variables
LogicalSignal buttonSignal = {BUTTON_PIN, 0b00}; // from LogicalSignals.h
uint16_t blinkSpeed = 1; // divisor of the base period
void setup()
{
configDigitalOutput(LED_PIN, LOW);
configDigitalInput(BUTTON_PIN, INPUT);
}
void loop()
{
updateSignal(buttonSignal);
if (risingEdge(buttonSignal)) {
switchToNextBlinkSpeed(blinkSpeed);
}
blinkDigitalOutput(LED_PIN, blinkSpeed);
}
Remarque : ce module principe ne met directement en œuvre aucune fonction de bas niveau ; il est donc a priori portable sur n'importe quel type de carte compatible avec l'environnement Arduino.
Module d'entrées‑sorties booléennes
Fichier d'en‑tête pinManagement.h
Il contient :
- la directive d'inclusion du fichier d'en‑tête
Arduino.hcar le fichier d'implémentation associé utilise des fonctions Arduino ; - la directive d'inclusion du fichier d'en‑tête principal du programme ;
- le prototype des trois fonctions définies dans le fichier d'implémentation associé
pinManagement.cpp.
#include <Arduino.h> #include "multiSpeedBlink.h" void configDigitalOutput(uint8_t pin, bool level); void configDigitalInput(uint8_t pin, byte mode); void blinkDigitalOutput(uint8_t pin, uint16_t speed);
Fichier d'implémentation pinManagement.cpp
Il contient :
- la directive d'inclusion du fichier d'en‑tête associé ;
- la définition des trois fonctions déclarées dans le fichier d'en‑tête associé ; ce sont des procédures qui opèrent des actions de bas niveau sur les broches de la cartes (déclarer une broche en sortie, en entrée, mettre en œuvre le clignotement sur une broche à une vitesse donnée).
#include "pinManagement.h"
void configDigitalOutput(uint8_t pin, bool level)
{
pinMode(pin, OUTPUT);
digitalWrite(pin, level);
}
void configDigitalInput(uint8_t pin, byte mode)
{
pinMode(pin, mode);
}
void blinkDigitalOutput(uint8_t pin, uint16_t speed)
{
static unsigned long previousMicros = micros();
if (speed == 0) {
digitalWrite(pin, LOW);
previousMicros = micros();
}
else {
uint32_t blinkHalfPeriod = BASE_BLINK_HALF_PERIOD / speed;
if (micros() - previousMicros >= blinkHalfPeriod) {
previousMicros += blinkHalfPeriod;
digitalWrite(pin, !digitalRead(pin));
}
}
}
Remarque. La fonction initDigitalInput peut sembler inutile dans la mesure où elle ne fait qu'appeler la fonction pinMode. Elle n'a pour but que de déporter du module principal une fonction de bas niveau qui serait éventuellement implémentée autrement dans un autre environnement matériel. Elle pourrait également apparaître plus pertinente pour un programme mettant en œuvre plusieurs entrées booléennes (en factorisant le code).
Module de changement de la fréquence de clignotement
Fichier d'en‑tête blinkSpeedManagement.h
Il contient :
- la directive d'inclusion du fichier d'en‑tête principal du programme ;
- le prototype de la fonction définie dans le fichier d'implémentation associé
blinkSpeedManagement.cpp.
#include "multiSpeedBlink.h" void switchToNextBlinkSpeed(uint16_t & blinkSpeed);
Fichier d'implémentation blinkSpeedManagement.cpp
Il contient :
- la directive d'inclusion du fichier d'en‑tête associé ;
- la déclaration de la variable externe de vitesse (déclarée dans le fichier d'implémentation principal) ;
- la définition de la fonction déclarée dans le fichier d'en‑tête associé ; c'est une procédure qui modifie la variable globale de vitesse conformément à la spécification ;
#include "blinkSpeedManagement.h"
void switchToNextBlinkSpeed(uint16_t & blinkSpeed)
{
if (blinkSpeed == 0) {
blinkSpeed = 1;
}
else {
blinkSpeed = (blinkSpeed * 2) % MAX_BLINK_SPEED;
}
}
Remarque. Il peut sembler fastidieux de créer un module pour une seule fonction, mais cela découle du fait que le programme est simple. Du point de vue fonctionnel, il semblerait peu cohérent de placer cette fonction dans l'un des trois autres modules.
Module de détection de fronts montants sur le signal du bouton
Fichier d'en‑tête LogicalSignals.h
Il contient :
- la directive d'inclusion du fichier d'en‑tête
Arduino.hcar le fichier d'implémentation associé utilise des fonctions Arduino ; - la déclaration du type
LogicalSignalqui regroupe dans un type structuré un numéro de broche du port numérique et un octet pour stocker sur ses deux premiers bits la valeur courante et la valeur précédente du niveau logique sur la broche (les types structurés sont abordés au chap. C5‑V ) ; - le prototype des deux fonctions définies dans le fichier d'implémentation associé
LogicalSignals.cpp.
#include <Arduino.h>
typedef struct {
uint8_t pin; // pin number to be declared as INPUT our INPUT_PULLUP
byte levels; // current level on bit 0, previous level on bit 1
} LogicalSignal;
void updateSignal(LogicalSignal & signal); // to be called once in loop function
bool risingEdge (LogicalSignal signal);
Fichier d'implémentation LogicalSignals.cpp
Il contient :
- la directive d'inclusion du fichier d'en‑tête associé ;
- la définition des deux fonctions déclarées dans le fichier d'en‑tête associé.
#include "LogicalSignals.h"
void updateSignal(LogicalSignal & signal) {
signal.levels <<= 1; // record previous level on bit rank 1
// copy current level on bit rank 0 and clear all bits ranging over rank 1
signal.levels = ((digitalRead(signal.pin) | signal.levels) & 0b11);
}
bool risingEdge (LogicalSignal signal) {
return (signal.levels == 0b01);
}
Remarque. Contrairement aux autres modules, celui‑ci ne requiert pas la directive #include "multiSpeedBlink.h" car aucune de ces fonctions ne fait appel à un élément spécifique du programme. Il peut être complété pour former une bibliothèque de fonctions lecture de niveaux et de fronts sur un signal d'entrée booléenne.