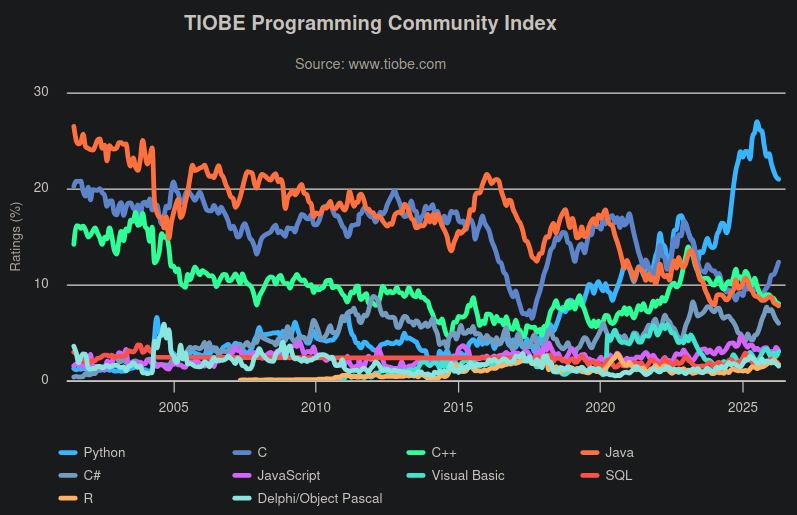
Le langage C, inventé il y a une cinquantaine d'années, s'est peu à peu imposé comme incontournable dans l'univers de la programmation. Aujourd'hui encore, il reste l'un des plus employés (sur l'index Tiobe W, il est toujours dans le « top 3 » – cf. sa courbe de popularité grise sur la capture d'écran ci‑contre, datée de 2026 . Et il est toujours en évolution : il est régi par une norme internationale qui fait l'objet de révision périodiques (environ tous les cinq ans).
Un tel succès n'a rien de fortuit. On dit parfois que langage C est un langage qui « fait confiance au codeur », au sens où il met à sa disposition une syntaxe très puissance qui permet d'exécuter certaines manipulations impossibles dans d'autres langages, notamment l'accès direct à la mémoire. Qui se priverait d'un tel outil de développement ?
Mais le revers de la médaille, c'est que le langage C nécessite une stricte discipline dans la façon de coder pour ne pas créer des programmes incidemment défectueux. Pour un débutant – et a fortiori s'il est autodidacte – cette discipline est difficile à acquérir. Et bien évidemment, lorsqu'il s'agit de développer des programmes de systèmes cruciaux (contrôle‑commande de composants pour véhicules, machines‑outils, appareils médicaux…), ce n'est pas un outil à employer à la légère.
Aussi le langage C, même s'il est déjà ancien, n'en reste pas moins primordial dans un cursus d'apprentissage professionnel en informatique. En effet :
- de très nombreux logiciels ont été écrits en C, leur maintenance requiert d'énormes besoins en compétences ;
- la souplesse des instructions de bas niveau de C et leur vitesse d'exécution le rendent incontournable pour toutes les applications en prise directe avec le matériel (commandes de microcontrôleurs, systèmes d'exploitation, pilotes de périphériques…) ;
- la syntaxe épurée du C font qu'il a inspiré de nombreux langages généralistes plus évolués ou dédiés, en premier lieu C++, mais aussi C# et Objective‑C bien entendu, et encore Java, JavaScript, Perl… W (autant de langages qui se disputent le top‑10 de l'index Tiobe).
- son étude permet d'aborder tous les mécanismes fondamentaux des programmes qui sont transparents pour le codeur dans les autres langages – pointeurs, allocation de la mémoire, processus parallèles, etc.
Quant au langage C++, inventé il y a une quarantaine d'années, il constitue le langage moderne avec tous les concepts de la programmation orientée objet (POO, cf. chap. C1‑I ) évidemment le plus en continuité avec le langage C, d'autant plus qu'il en inclut tous les éléments. Il permet donc de coder des mécanismes complexes avec des instructions de très haut niveau mais aussi éventuellement, si nécessaire, de recourir à des instructions de bas niveau. Et comme le langage C, il est régi par une norme internationale révisée périodiquement (environ tous les trois ans).
Même s'il est concurrencé dans certaines applications par des langages plus récents (par exemple Python pour l'analyse de données et l'intelligence artificielle), le langage C++ reste privilégié pour le développement des gros logiciels, mais aussi de ce qu'on appelle des « micrologiciels » dans le domaine de l'informatique embarquée W.

En contre‑partie, le langage C++ est tellement complexe – beaucoup plus que le C – que son apprentissage doit être envisagé sur plusieurs années (voire une décennie). S'il est conseillé de disposer préalablement de bonnes bases en C, rien n'interdit de découvrir déjà quelques éléments du C++ (particularités de syntaxe du noyau, bases de la POO…) qui sont immédiatement utiles pour la programmation des cartes à microcontrôleurs, notamment Arduino. C'est la stratégie qui est choisie dans ce module de formation.
Avant de commencer l'étude de la programmation proprement dite, et au delà de cette introduction, le présent chapitre a pour objectifs :
- de donner quelques repères (historique, norme, principales caractéristiques, domaines d'emploi) sur les langages C et C++ ;
- de présenter sommairement des outils logiciels pour commencer à programmer dans ces deux langages, et en premier lieu, d'introduire la notion de chaîne de compilation ;
- d'évoquer également la notion d'implémentation et de sensibiliser déjà à la question du choix de la norme du langage employé.
Le langage C
Bref historique

Le langage C W a été mis au point dans les années 1970, essentiellement par Dennis Ritchie W et Ken Thompson W au sein des laboratoires Bell dans le but de recoder le système d’exploitation Unix W.
Non seulement cet objectif sera atteint, mais le langage C deviendra, dès le milieu des années 1980 – et durant toutes les années 1990, de façon hégémonique – le langage de programmation le plus populaire Y, avant d'être détrôné par Java au début des années 2000, mieux adapté au développement d'applications web et mobiles.
Comme souligné en introduction, du fait de la spécificité de sa syntaxe très puissante, il reste (et restera certainement encore très longtemps) un langage majeur dans l'univers de la programmation.


Fondé sur un standard ouvert (les spécifications sont librement accessibles), le langage C fait l’objet depuis 1989 d'une norme internationale éditée par l'ISO (environ 750 pages) W. Elle est élaborée par le groupe de travail ISO/IEC JTC1/SC22/WG14 W, qui est toujours actif.
Comme toutes les normes, celles du langage C ne sont pas gratuites. Néanmoins, on trouve sur l'Internet en libre accès les brouillons (drafts), par exemple ici G ou encore là C (c'est la page officielle du groupe de travail WG14). Ces textes conviennent parfaitement comme références de normalisation, même pour un codeur expérimenté.

Également, il faut avoir conscience que, comme toutes norme de langage de programmation, celle du langage C est particulièrement complexe. Elle a vocation à servir de texte de référence pour l'élaboration des compilateurs. Ce n'est pas un document pédagogique (c'est d'ailleurs écrit noir en première page) et, pour un codeur, il serait donc très inefficace de baser dessus son apprentissage. En revanche, il est souvent judicieux de la consulter pour éclaircir un détail technique précis.
Le choix du nom « C » découle du fait qu'initialement, Thompson et Ritchie tentaient d'adapter le langage BCPL W (basic combined programming language) pour recoder Unix, et avaient nommé « B » leur variante. Toutefois, trop de remaniements étaient nécessaires aussi, pour exprimer cette grande différence, ils passèrent à la lettre suivante de l'alphabet comme nom du langage qu'ils étaient en train de créer.
Principales caractéristiques
Caractéristiques générales
Le langage C est un langage littéral généraliste compilé conçu pour la programmation impérative et structurée (cf. chap. C1‑I ).
Il est particulièrement bien adapté à la programmation procédurale multi‑fichiers. Il permet l'emploi de bibliothèques de fonctions pré‑compilées, ce qui est un gage de modularité (cf. chap. C1‑I ) et d'efficacité dans le cadre du développement logiciel.
De plus, comme tout langage compilé, C garantit une assez bonne portabilité (cf. chap. C1‑I ) des programmes :
- en principe, il suffit de disposer du code source du programme et d'une chaîne de compilation munie de sa bibliothèque standard pour générer un code exécutable sur une architecture de machine souhaitée (processeur, mémoire…) ;
- mais en réalité, ce n'est pas toujours si simple, car la norme du langage laisse un certain nombre de libertés d'implémentation aux compilateurs (cf. infra ), et par ailleurs, les compilateurs ne respectent pas tous exactement la norme.
Syntaxe
Le langage C emploie une syntaxe (cf. chap. C2‑II ) dite semi‑symbolique. En effet, par rapport à d'autres langages plus verbeux (Delphi, ST…) :
- les symboles
{et}remplacent respectivement les mot‑clefs explicitesbeginetend; - les abréviations
int,char,boolremplacent les noms de types completsinteger,character,boolean…
Cela donne un code source concis, rapide à lire et écrire pour les initiés, mais cela peut s'avérer déboussolant pour les débutants.
Typage
Le langage C met en œuvre un typage des données W :
- explicite car toute constante, variable ou fonction doit être déclarée en spécifiant son type ;
- statique car, une fois codé, il est définitif – aucune variable ne peut changer de type en cours d'exécution ;
- faible car le compilateur tolère une grande part d'hétérogénéité de typage dans les expressions (il procède à de nombreuses conversions implicites durant l'évaluation des expressions).
Points forts
Le langage C permet de coder facilement des opérations de bas niveau comme des manipulations de données au sein même de la mémoire de la machine, grâce à des variables de types pointeurs (cf. chap. C5‑I ) très simples à manipuler.
De plus, grâce au préprocesseur (cf. chap. C4‑III ) intégré en tête de chaîne de compilation, le langage C possède une grande puissance d'expression pour coder des programmes modulaires et portables (cf. chap. C1‑I ).
Points faibles
Le langage C n'est pas adapté à la programmation orientée objet (cf. chap. C1‑I ). C'est pour cela que d'autres langages comme C++ ou Java ont été inventés.
De plus, en comparaison d'autres langages plus modernes – C++, Java, JavaScript, Python… – C n'est pas très commode pour manipuler des structures de données de taille variable (chaînes de caractères, listes, etc.).
Domaines d'emploi

Le langage C constitue un choix privilégié pour le codage des systèmes d'exploitation W des machines informatiques (postes de travail, serveurs, routeurs…) et des composants logiciels qui les complètent : pilotes d'équipements (carte audio, carte graphique…), implémentation de protocoles de communication, logiciels serveurs, etc.
C'est également un langage encore très employé dans le domaine de l'informatique embarquée W, qui est très vaste :
- La grande majorité des petits micrologiciels propriétaires W (en anglais, firmwares), notamment ceux des appareils électroménagers (lave‑linge, four…), des périphériques grand‑public d'ordinateur (imprimante, scanner…), etc. sont codés en langage C.
- De même, une grande part des logiciels embarqués dans des systèmes de contrôle‑commande de taille moyenne – véhicules, ascenseurs, feux de circulation, équipements médicaux, sattellites, etc. – sont codées en langage C.
- Quant aux gros systèmes, qu'ils soient stationnaires (machines‑outils, lignes de production, etc.) ou mobiles (engins de chantiers ou militaires, avions, bâteaux…), ils exploitent de nombreux composants logiciels écrits en langage C.
- Les lignes de production, machines‑outils, etc. sont souvent équipées par des automates programmables W, qui ont une très grande sûreté de fonctionnement et qui utilisent des langages spécifiques (LD, ST, IL, FBD, SFC) normalisés par l'ISO/CEI 61131 W.
- Quand au domaine de l'avionique, il est également spécifique pour questions évidentes de sécurité critique. Certains composants logiciels comme les contrôleurs de vols sont préférentiellement programmés avec des langages à syntaxe très stricte comme Ada, ou plus récemment Rust.





La liste ci‑dessous donne quelques exemples emblématiques – mais elle ne constitue qu'un tout petit aperçu – des logiciels codés en langage C.

- GIMP W, logiciel libre d'édition et de manipulation d'images ;
- GNU/Linux W, adaptation du système Unix pour ordinateurs personnels ;
- pcap/libcap W, bibliothèque de fonctions / API pour la capture et l'analyse de paquets réseaux, notamment utilisée par Wireshark ;
- Radare2 W, outil de retro‑ingénierie pour l'analyse des fichiers binaires ;
- BIND W, serveur DNS ;
- Zend Engine W, moteur d'interprétation du langage php ;
- NGINX W, logiciel de serveur web ;
- Apache W, logiciel de serveur web ;
- SQLite W, moteur de base de données embarqué ;
- Postfix W, serveur du protocole de messagerie SMTP ;
- Dovecot W, serveur du protocole de messagerie IMAP/POP3 ;
- Cyrus W, serveur du protocole de messagerie IMAP ;
- OpenVPN W, logiciel de VPN ;
- Asterisk W, logiciel de serveur de téléphonie (IPBX) ;
- Jami W, logiciel de téléphonie (soft phone) ;
- Libopus W, codec des signaux audio ;
- Mosquitto , implémentation du protocole de communication MQTT ;
- Subversion W, utilitaire de gestion de versions logicielles.
Le langage C++
Généralités

Le langage C++ W a été créé dans les années 1980, par Bjarne Stroustrup W au sein des laboratoires Bell comme une extension majeure au langage C pour renforcer la structuration du code.
Il n'en doit pas moins être considéré comme un langage à part entière, avec sa propre normalisation dont l'évolution est indépendante de celle du langage C.
C'est aussi un langage très populaire, très souvent dans le « top 3 » de l'index Tiobe W, mais en concurrence directe avec Java.

Comme C, le langage C++ est libre de droits et fait l'objet depuis 1998 d'une norme internationale (qui fait maintenant plus de 2000 pages !) avec un groupe de travail associé ISO/IEC JTC1/SC22/WG21 W. On peut trouver la liste des standard drafts sur cette page web C++.
- La plus récente, dite C++26 W, est référencée ISO/IEC 14882:2026, mais elle n'est encore prise en charge par les versions expérimentales des chaînes de compilation.
- C'est donc la révision précédente, dite C++23 W, référencée ISO/IEC 14882:2023, qui constitue l'« état de l'art » – sachant qu'elle‑même n'est pas prise en charge par toutes les chaînes de compilation, et notamment pas par celles utilisées pour le framework Arduino (cf. chap. C1‑III ).
Le langage C++ présente une forte compatibilité unilatérale avec le langage C.
- L'ensemble des bibliothèques du C sont a priori utilisables dans un code source compilé en C++ (il en existe d'ailleurs des adaptations spécifiques – cf. chap. C2‑I ).
- Et néanmoins, un programme compilable en C ne l'est pas nécessairement en C++, car il existe quelques rares éléments incompatibles.
Inversement, un programme codé en C++ n'est a priori pas compilable en C (sinon, cela signifie qu'il est codé exclusivement avec des éléments de ce langage, ce qui n'a aucun intérêt).
Toutefois, soulignons dès à présent que de nombreux éléments de langage du C (notamment les pointeurs) sont déconseillées en C++. En effet, ce dernier introduit à la place de nouveaux concepts dans une perspective de permettre une meilleure sécurité des programmes codés.
De surcroît, le langage C++ apporte de nombreuses fonctionnalités de haut niveau (cf. infra) qu'il est dommage d'ignorer en recourant aux techniques moins évoluées, plus fastidieuses – et donc, là encore, moins sûres – du langage C. C'est pourquoi en règle générale, un programme qui exploite pleinement les possibilités du C++ est potentiellement incompréhensible pour un codeur qui ne connaîtrait que le C.
Le nom « C++ » fait référence à l'opérateur d'incrémentation unitaire ++ du langage C (cf. chap. C2‑IV ). On peut y lire l'expression d'une évolution positive du langage C.
Principaux apports par rapport au C
Les principaux apports du langage C++ sont les concepts fondamentaux pour la programmation orientée objet (POO – cf. chap. C1‑I ), notamment :
- les classes de variables, auxquelles on peut associer spécifiquement des fonctions qu'on appelle méthodes ;
- l'héritage, c'est‑à‑dire le fait qu'une sous-classe de variables dispose (hérite) de toutes les méthodes de la classe dont elle est issue ;
- la surcharge, c'est‑à‑dire le fait qu'on puisse utiliser les mêmes identificateurs pour définir des fonctions semblables d'une classe à une autre ; en particulier, cela permet d'employer les opérateurs usuels
+ - * /, etc. sur des objets plus complexes que de simples nombres.
Les concepts de la POO sont tellement performants en termes de lisibilité et de fiabilité qu'ils sont devenus incontournables dans de nombreux domaines du développement logiciel, même pour la programmation de cartes à microcontrôleurs. Par exemple, la mise en œuvre usuelle des liaisons séries et plus généralement des bus de données (SPI, I²C, etc.) sur les cartes Arduino repose sur l'emploi de classes.
Domaines d'emploi

Avec la puissance expressive apportée par les concepts de la programmation orientée objet, le langage C++ constitue un choix privilégié pour le codage d'applications pour postes de travail :
- bien sûr les logiciels « grand public » de bureautique, jeux, de communication (navigation web, courriel), etc.
- mais aussi les très nombreux logiciels professionnels de comptabilité, gestion, supervision, modélisation, simulation, etc.
sachant que ce domaine est fortement concurrencé par les solutions « web », c'est‑à‑dire qui s'exécutent dans un navigateur, et qui sont souvent développées avec d'autres langages (Javascript, Java, PHP, Ruby, Perl…)

Le langage C++ est également privilégié dans l'informatique embarquée, en concurrence directe avec le langage C dès lors qu'un compilateur est développé pour le matériel utilisé (cf. les domaines listés supra ).
Et en particulier, c'est le langage imposé par le framework de programmation des cartes Arduino et compatibles (ESP32, etc.), qui sera présenté en détail au chapitre C1‑III .
La liste ci‑dessous donne quelques exemples emblématiques des logiciels principalement ou totalement codés en langage C++.

- Microsoft Office W (suite bureautique qu'on ne présente plus), ainsi que d'autres logiciels phares de la firme de Redmond, comme Outlook ;
- LibreOffice W, suite bureautique libre et open‑source ;
- Adobe Illustrator W, logiciel de dessin vectoriel ;
- Adobe Photoshop W, logiciel de traitement d'images matricielles ;
- Catia W, logiciel CAO (conception assistée par ordinateur) ;
- Scilab W, logiciel de simulation et calcul numérique ;
- Sublime Text W, éditeur de code ;
- Code::Blocks W, environnement intégré de développement ;
- Wireshark W, logiciel de capture et d'analyse de paquets réseaux ;
- FileZilla W, logiciel client FTP (transferts de fichiers entre hôtes distants) ;
- Blink W, moteur de rendu du navigateur Chrome ;
- WebKit W, moteur de rendu du navigateur Safari ;
- Gecko W, moteur de rendu du navigateur Firefox ;
- 7-Zip W, utilitaire de compression de données ;
- 3CX W, logiciel de téléphonie VoIP.
Mais encore une fois, insistons sur le fait qu'il ne s'agit là que d'un tout petit aperçu qui passe sous silence les innombrables applications industrielles du langage C++ inconnues du grand public.
Outils logiciels de programmation en C et C++
Les chaînes de compilation – généralités
Sauf recours à un environnement de programmation en ligne (cf. chap. C1‑I ), il est indispensable d'installer sur le poste de travail au moins une chaîne de compilation C/C++ W – en anglais, toolchain – pour pouvoir compiler et exécuter les programmes composés dans ces langages.
Pour un débutant, l'installation d'une chaîne de compilation peut parfois sembler « transparente » :
- si l'on emploie un environnement intégré de développement que l'on a téléchargé avec un installateur combiné qui inclut la chaîne de compilation ;
- si le poste de travail fonctionne avec une distribution usuelle du système d'exploitation Linux comme Ubuntu, Mint, Debian, etc. où la chaîne de compilation est installée par défaut.
Dans tous les cas, il est préférable de savoir précisément où est installée cette chaîne de compilation et quelle est sa version.
Les chaînes de compilation GCC et MinGW
Dans le monde académique (enseignement, recherche… ), et aussi dans une part non négligeable des entreprises qui développent des logiciels, on emploie principalement les chaînes de compilation élaborées dans le cadre du projet GNU W, qui est fédérateur du monde du logiciel libre. En anglais, on parle de GNU toolchain.
Ces chaînes de compilation sont distribuées sous licence GNU GPL W (general public licence) version 3 .

Parmi ces chaînes de compilation, on trouve une famille d'outils emblématiques désignés par le sigle GCC W – lequel signifiait originellement GNU C Compiler et aujourd'hui GNU Compiler Collection.
Pour différentes architectures de machines cible, une chaîne de compilation GCC regroupe notamment :
En règle générale, toute chaîne de compilation apporte des extensions aux langages qu'elle prend en charge, qui viennent en complement des spécifications de la norme, pour faciliter le codage des programmes. Dans le cas des chaînes GCC, on parle d'extensions GNU. On peut en trouver la liste exhaustive pour les langages C/C++ sur cette page de référence C.
Cependant, l'usage des extensions présente l'inconvénient principal de rendre les programmes ainsi codé moins portables. En effet, ils ne peuvent a priori pas être compilés avec une autre chaîne de compilation.

Enfin, dans les archives d'installation, à une chaîne de compilation GCC est le plus souvent associée un débogueur GDB W. C'est un outil logiciel du projet GNU (donc, ouvert et gratuit) qui permet l'exécution pas à pas d'un programme – à condition que son code source soit disponible.
À partir d'un certain niveau de complexité des programmes développés, un débogueur est indispensable pour la mise au point. Il facilite grandement la recherche des causes de dysfonctionnement.
Procédures d'installation de GCC
La procédure d'installation de GCC dépend du système d'exploitation du poste de travail.
- Avec une distribution Linux usuelle, la procédure est assez simple, car GCC fait partie des composants logiciels partiellement voire totalement pré‑installés. Dans un terminal de commandes en ligne :
- On commence par vérifier si l'installation est déjà faite en saisissant successivement les commandes ci‑dessous. Si les paquets de GCC sont complètement installés, on doit obtenir des réponses indiquant le chemin vers le fichier exécutable dans le système.


which gcc/usr/bin/gccwhich g++/usr/bin/g++
bash: which: g++ : not found
build-essential via la commande ci‑dessous (cf. ce lien pour plus d'informations ) : sudo apt install build-essential
gcc --versiongcc (Ubuntu 13.3.0-6ubuntu2~24.04.1) 13.3.0 Copyright (C) 2023 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.g++ --versiong++-13 (Ubuntu 13.3.0-6ubuntu2~24.04.1) 13.3.0 […]
sudo apt install gcc-14 g++14
sudo update-alternatives --set gcc /usr/bin/gcc-14sudo update-alternatives --set g++ /usr/bin/g++-14

where gcc (where.exe sur un terminal de commande. Si aucun chemin n'est trouvé par le système, sachant qu'on peut être confronté pour ce composant à un installateur défectueux, il est préférable de , comme indiqué ci‑dessous : - Télécharger l'archive de la dernière version stable des fichiers nécessaires sur la page suivante .
- Extraire son contenu via la commande
Extraire icidu sous‑menu contextuelZ-Zip. - Déplacer le dossier extrait
mingw64dans le répertoire des programmes pour architecture 64 bitsC:\Program Files(on peut procéder par glisser déposer via le panneau latéral d'exploration où ce répertoire apparaît dans celui du système sous l'intituléProgrammes). - Pour que cette chaîne de compilation soit utilisable dans un terminal de commandes en lignes, il faut encore que le chemin des exécutables figure dans la variable variable d'environnement
PATHde l'utilisateur comme indiqué ci‑dessous (cf. ce lien pour plus de détails si nécessaire ). - Dans la barre de recherche du système, taper le mot‑clef
envet cliquer sur le premier choix proposé :
Modifier les variables d'environnement - Dans la fenêtre de dialogue ainsi ouverte, sélectionner la ligne
pathet cliquer sur le boutonModifier. - Dans la nouvelle fenêtre de dialogue ainsi ouverte, cliquer sur le bouton
Nouveauet, compte tenu des choix précédents, saisir le chemin :
C:\Program Files\mingw64\bin
puis fermer les fenêtres de dialogue en validant. - Fermer la session utilisateur puis l'ouvrir à nouveau et, dans un terminal de commandes en lignes, saisir :
echo %PATH%($Env:Pathsur un terminal PowerShell) - On peut ensuite afficher quelle version de Mingw‑w64 est installée en saisissant dans le terminal la commande
gcc --version.
where (cf. supra). Il faut ne pas confondre la commande système gcc avec « la » chaîne de compilation GCC :
- La commande
gccappelle la chaîne de compilation du langage C installée sur le poste de travail, aussi bien sous Windows que Linux. - Mais entre ces deux systèmes d'exploitation, la chaîne de compilation employée n'est pas exactement la même – Mingw‑w64 étant une version réduite de GCC.
Mode d'emploi rudimentaire de GCC
L'emploi rudimentaire d'une chaîne de compilation GCC ou MinGW installée sur un poste de travail est très simple. Pour un programme source codé en C et destiné à s'exécuter sur la même machine – compilation dite native, cf. chap. C1‑I – on saisit dans un terminal une commande de la forme :
gcc -Wallfichier source-ofichier exécutable
et idem pour un programme en C++ avec la commande g++.
Dans cette forme :
- l'option
-Wallstipule l'affichage dans la console de (presque) tous les avertissements («W» est l'initiale de warnings etallsignifie « tous ») émis par le compilateur ; - fichier source est le chemin relatif d'accès au fichier du programme source, lequel est conventionnellement doté de l'extension
.c; et il peut éventuellement y en avoir plusieurs ; - l'option
-ostipule que la sortie (output) est spécifiée par l'argument consécutif à l'option, ici le chemin relatif d'accès au fichier exécutable ; en cas de succès de la compilation, ce fichier est créé s'il n'existe pas, sinon il est écrasé ; - sous Windows, le fichier exécutable doit être nommé avec l'extension
.exe(en l'absence d'extension, le système la lui attribue automatiquement) ; - sous Linux, il est d'usage de ne lui donner aucune extension (toute extension est a priori acceptée par le système).



Pour simplifier la pratique, il est préférable dans un premier temps que le terminal de commande agisse depuis un même répertoire où sont directement placés le ou les fichiers sources et le fichier exécutable – on parle alors de répertoire de projet. Ainsi, les chemins relatifs d'accès à ces fichiers se réduisent simplement à leur noms, ce qui facilite la saisie de la commande de compilation.
Gestion des avertissements et erreurs
Dans les commandes gcc et g++, la gestion des avertissements admet un très grand nombre d'options – pour se faire une idée, il suffit d'observer le résultat de la commande man gcc | grep '\-W' sur une machine à système Linux. Et en particulier, on peut citer les deux options usuelles ci‑dessous :
-
-Wextraqui affiche des avertissements supplémentaires, dont les causes sont considérées comme étant suffisamment moins risquées en termes de dysfonctionnements potentiels du programme pour pouvoir être passées sous silence, mais qu'il peut être pertinent d'afficher quand même ; -
-Werrorqui convertit artificiellement tout avertissement affiché en une erreur de compilation, bloquant ainsi la production du code exécutable.
Pour une programmation vraiment sûre, il est recommandé d'employer ces sous‑options. On saisit donc toute commande de compilation de la forme :
gcc -Wall -Wextra -Werror…
Enfin, pour une détection plus poussée des erreurs potentielles, les commandes gcc et g++ disposent de l'option -fanalyser qui met en œuvre une analyse statique approfondie du programme (cf. un exemple d'utilité au chap. C5‑I ). Sans aller jusqu'à tester son exécution, cette option explore de nombreux scénarios possibles, mais bien sûr au prix d'un surcoût en terme de temps d'exécution d'autant plus lourd que le programme est complexe.
Exécution d'un programme compilé
Lorsque le compilateur ne signale aucune erreur, un nouveau fichier exécutable est donc produit. En règle générale, l'exécution du programme s'effectue simplement en saisissant le chemin d'accès de ce fichier, qui constitue en quelque sorte une nouvelle commande. En particulier, si le terminal de commandes est exécuté depuis le répertoire du fichier exécutable :
- Sous Windows, on saisit la commande :
fichier exécutable (.exe)
.\. ./fichier exécutable
. pour coder le répertoire courant. L'environnement de programmation OnlineGDB

OnlineGDB est un environnement de programmation en ligne, c'est‑à‑dire mis en œuvre via une page web. Principalement conçu pour C et C++, il prend aussi en charge près de 40 autres langages, dont Java, Python, JavaScript, Ruby, Perl…
Sa première version date de 2016.
Caractéristiques remarquables
OnlineGDB utilise des serveurs distants pour compiler et exécuter les programmes en ligne. Pour les langages C et C++, il exploite des chaînes de compilation GCC et le débogueur GDB (cf. supra ), d'où le nom du site. Pour connaître le détail des versions exploitées, on peut consulter cette page de foire aux questions .
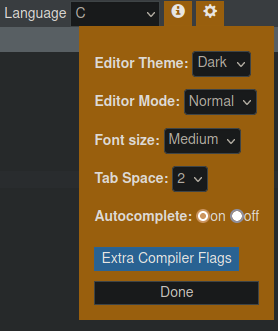
L'interface se présente de façon très classique avec :
- un cadre d'édition central avec une coloration syntaxique basique et un cadre inférieur qui simule une console d'exécution (terminal) ;
- une barre d'outil minimale, dotée d'un bouton
Run▶ qui compile puis exécute (en l'absence d'erreurs) le programme saisi dans le cadre d'édition ; - un menu de paramètres ⚙ via lequel on peut également spécifier des options de compilation avec un éditeur de ligne de commande ; on y accède en cliquant sur le bouton
Extra Compiler Flags.
Pour garantir un minimum de disponibilité à un grand nombre d'utilisateurs, il leur impose certaines limitations, notamment :
- un code source dont chaque fichier ne dépasse pas 100 ko et 200 ko au total ;
- un temps de compilation de 10 secondes maximum ;
- que le programme exécutable n'ait aucune interaction avec d'autres pages web.
D'autres fonctionnalités avancées sont disponibles dans une panneau latéral droit rétractable.
L'éditeur de code Sublime Text

Sublime Text W est un éditeur de code multiplateforme (Linux, Windows, MacOS). Développé initialement par Jon Skinner, il est distribué en shareware W par la société Sublime HQ, et jusqu'à présent sans limite de durée d'utilisation (mais périodiquement, le logiciel invite l'utilisateur à acquérir une licence).
Sa première version date de 2008. Il est disponible en version 4 depuis mai 2021.
Caractéristiques remarquables
Dans le contexte d'étude des bases de la programmation générale (dans lequel s'inscrit ce module de formation), l'emploi de Sublime Text est vivement recommandé, en particulier parce que cet éditeur est considéré et recommandé comme une solution de référence pour la programmation web (HTML/CSS/JS…). En optant pour le même éditeur, on évite aux étudiants de s'investir dans plusieurs environnements différents au moment où il est préférable de consacrer l'essentiel des efforts cognitifs à l'acquisition des éléments de langage.
De plus, Sublime Text n'est pas apprécié pour rien. Il possède de nombreux atouts, parmi lesquels on peut citer :
- sa légèreté, le lancement étant quasi‑instantané sur un poste de travail, même avec une configuration matérielle peu performante ;
- son interface minimale qui maximise l'espace de l'écran pour l'édition du code ;
- la sauvegarde automatique de la saisie (à tout moment, le logiciel garde en mémoire son état intégral et, même en cas de fermeture inopinée, même lors d'un arrêt brutal du système, le contenu des fichiers est restitué tel quel lorsqu'il est à nouveau relancé) ;
- ses fonctionnalités ergonomiques pour le développement (multi‑fenêtrage pour visualiser différentes parties d'un fichier ou plusieurs fichiers différents, visualisation miniature du contenu des fichiers, coloration syntaxique spécifique au langage, auto‑complétion, macro‑commandes, raccourcis clavier, etc.) ;
- le paramétrage des préférences permet de configurer finement l'interface utilisateur – notamment la coloration syntaxique W – et ce de façon portable (cf. chap. C1‑I ) ;
- un grand nombre d'extensions (plugins) développées par la communauté des utilisateurs qui permettent d'augmenter considérablement les fonctionnalités au gré des besoins spécifiques de chaque codeur.
Installation
L'installation de Sublime Text ne pose pas de difficulté particulière :
- avec Windows, on télécharge un installateur
setup.exeet on suit la procédure usuelle, comme pour tout logiciel ; - avec Linux, selon la distribution, on peut soit passer par la logithèque – choix recommandé avec Linux Mint 21 – ou un installateur de paquets.

Paquet Système et non pas Flatpack. /opt qui, sous Linux, est usuellement réservé aux applications dites optionnelles. Prise en main
Une fois que l'application Sublime Text est installée, son emploi est très intuitif et l'on peut d'ores et déjà commencer à coder des programmes. On bénéficie de tous les raccourcis usuels des logiciels de traitement de texte : CtrlC pour copier, CtrlV pour coller, CtrlS pour sauvegarder, etc.
Une coloration syntaxique conforme au langage est automatiquement adoptée sitôt que le fichier source en cours d'édition est enregistré avec une extension reconnue – typiquement (cf. chap. C2‑I ) :
-
.cou.hpour le langage C, -
.cppou.hpppour le langage C++
Il est également possible d'imposer le langage du code en le sélectionnant manuellement via le bouton sélecteur tout à droite de la barre de notification, en bas de la fenêtre.
Dans le menu View, on peut afficher ou cacher le panneau latéral Side Bar qui permet de naviguer dans une arborescence de fichiers. On peut directement y glisser‑déposer des icônes de répertoires pris sur le bureau pour que leur arborescence apparaisse instantanément et qu'on puisse dès lors ouvrir n'importe quel sous‑répertoire ou fichier en cliquant sur son nom.
On peut également diviser la fenêtre d'édition en plusieurs cadres, disposées en colonnes ou rangées, via le menu View/Layout.
Pour un meilleur confort visuel (ce qui est essentiel lorsque l'on passe beaucoup de temps à lire ou composer les détails d'un programme), il est recommandé d'adopter un thème d'affichage sombre, ce qui est immédiatement faisable via le menu Preference/Select theme…. La totalité de la fenêtre – y compris le panneau latéral – s'affiche alors en texte clair sur fond sombre.
Enfin, pour augmenter les fonctionnalités de Sublime Text, on peut ajouter des extensions via le menu déroulant Tools/Command Palette, à commencer par celle intitulée Package control qui permet d'ajouter ou supprimer des paquets optionnels. Les messages d'installation (déroulement, succès ou échec…) sont affichés dans la barre de notification tout en bas à gauche de la fenêtre principale.
Parmi les paquets recommandés pour la programmation en langages C/C++, on peut citer notamment :
-
BracketHighlighterqui permet de visualiser, dans la barre de numérotation les lignes, les paires de délimiteurs correspondants (parenthèses, accolades, crochets…) dès lors qu'on sélectionne l'un des deux avec le curseur ; -
PackageDevqui permet de paramétrer facilement la coloration syntaxique des éléments d'un code source selon le langage employé ; -
Language - French - Françaisqui offre un dictionnaire de correction orthographique en français (pour vérifier les entrées‑sorties textuelles et les commentaires).
Accès aux paramètres de réglage
Comme présenté supra, Sublime Text est un éditeur de code fortement paramétrable, ce qui permet de l'adapter à toutes sortes de contextes de développement et de préférences du codeur.
Le paramétrage est effectué par le biais de fichiers au format JSON W – JavaScript objet notation – constitué de listes hiérarchisées de couples paramètre : valeur.
Ainsi, on accède aux fichiers de réglages généraux via le menu Preferences/Settings. Automatiquement, une nouvelle fenêtre de l'application Sublime Text s'ouvre (cf. la capture d'écran ci‑après) avec deux fichiers homonymes nommés Preferences.sublime-settings, respectivement affichés dans deux onglets :
- À gauche, on a le fichier de réglages par défaut, à ne pas modifier (il est placé dans le répertoire d'installation de l'application, en principe accessible seulement avec des droits d'administration). Volumineux, il est agrémenté de longs commentaires pour expliquer toutes les possibilités de réglage.
- À droite, on le fichier de réglages utilisateur, placé dans répertoire de préférences de l'utilisateur, dans lequel ce dernier peut coder, pour chaque paramètre du fichier par défaut, des valeurs différentes de celle du fichier par défaut en s'inspirant de sa syntaxe et des commentaires assortis.
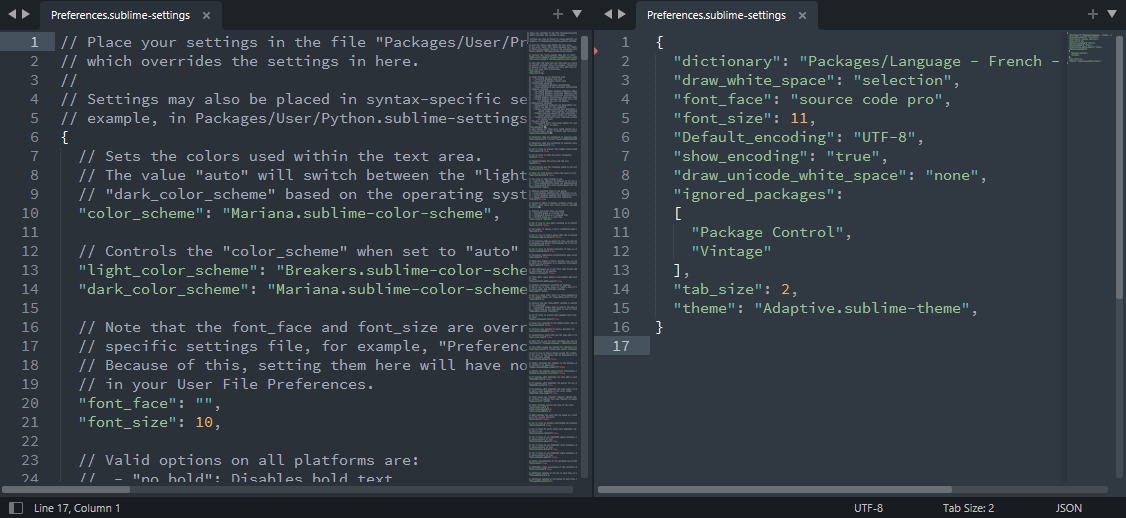
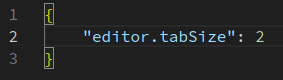
Sur la capture d'écran ci‑dessus, l'utilisateur a entre autres codé les préférences suivantes :
- en ligne nº 4, la police de caractères d'édition (paramètre
font-face, valeursource code pro– cf. TP S1‑1 ) ; - en ligne nº 5, la taille des caractères d'édition, exprimée en nombre de points (paramètre
font-size, valeur11– cf. W) ; - en ligne nº 11, la largeur de tabulation, exprimée en nombre de caractères espace (
tab-size, valeur2– cf. chap. C2‑X ).
L'emplacement du fichier de réglages utilisateur de Sublime Text dépend du système d'exploitation.
- Sous Linux :
/home/username/.config/sublime-text-3/Packages/User - Sous Windows :
C:\Users\username\AppData\Roaming\Sublime Text 3\User
En revanche, le codage des préférences est indépendant du système d'exploitation – c'est ce qu'on entend par portabilité (cf. supra ). On peut donc procéder par copier/coller de fichiers pour modifier d'un coup la totalité des préférences utilisateur.
Quant au paramétrage de la coloration syntaxique pour tel ou tel langage, il sera abordé ultérieurement (cf. chap. C2‑X ).
L'environnement de développement intégré Visual Studio Code

Visual Studio Code W est un éditeur de code suffisamment extensible pour constituer un véritable environnement intégré de développement, à la fois multi‑plateformes (Linux, Windows, MacOS) et multi‑langages.
Développé par Microsoft, c'est un logiciel libre et open‑source, distribué sous licence GNU GPL version 3 (cf. supra ). Sa première version date de 2015.
Il existe une application « clone » de VS Code nommée VS Codium qui, à l'instar de Chromium vis‑à‑vis de Google Chrome, a pour objectif d'en fournir toutes les fonctionnalités sans la télémétrie W.
Toutefois, même les dernières versions de VS Codium présentent plusieurs inconvénients. Notamment :
- elles souffrent de problèmes de stabilité (elles font parfois planter le système du poste de travail).
- elles incluent moins de fonctionnalités de remaniement du code que VS Code.
C'est pourquoi elles ne sont pas recommandées, d'autant plus que le niveau de télémétrie sous VS Code est ajustable, jusqu'à néant.
Caractéristiques remarquables
Outre sa gratuité et sa fiabilité, VS Code réunit de nombreuses qualités qui en font, depuis quelques années déjà, l'environnement de développement le plus populaire, tous publics confondus (cf. le Stack Overflow Developer Survey ).
- Fortement paramétrable, il peut offrir au codeur une interface « sur mesure » parfaitement adaptée à tel ou tel contexte de développement (web, embarqué, etc.). En particulier, la coloration syntaxique peut faire l'objet de règles très spécifiques selon le langage de programmation utilisé et les préférences du codeur, pour améliorer au maximum la lisibilité du code.
- Extrêmement modulaire, il est constitué d'un « noyau » assez réduit (donc rapide à charger) auquel on peut greffer de très nombreuses extensions que chaque codeur est libre de choisir en fonction de ses besoins (pour tel ou tel langage, framework, etc.).
À lui seul, le noyau intègre certaines fonctionnalités très appréciées par les codeurs professionnels, notamment :
- des outils puissant de remaniement du code source W (en anglais, refactoring), c'est‑à‑dire de remplacement d'éléments de code dans la totalité des fichiers source d'un projet ;
- l'intégration de Git, l'outil de gestion décentralisée de versions logicielles qui est incontournable pour le développement logiciel en équipes (cf. chap. C1‑I ) ;
- l'auto‑complétion intelligence – dénommée IntelliSense – pour les langages de la programmation web (HTML/CSS/JS) ;
Quant aux extensions, elles sont installables via un marché – en anglais, Marketplace – comme pour beaucoup de logiciels, sachant que la plupart sont gratuites.
Ces extensions permettent de prendre en charge de les langages les plus usuels, notamment C, C++, C#, Java, Python, PHP, Go… En règle générale, une seule extension ne suffit pas : chacune joue un rôle bien spécifique pour intégrer dans VS Code telle ou telle fonctionnalité attendue pour un langage donné : auto‑complétion intelligente, compilation, débogage, etc.
En contre‑partie de toutes ses qualités, VS Code est un IDE complexe qui nécessite une certaine expertise pour être convenablement paramétré en vue d'une exploitation efficace.
Bien plus puissant que Sublime Text (qui lui‑même est déjà bien évolué), VS Code n'est pas immédiatement exploitable juste après son installation pour la programmation en langages C/C++. Ce n'est donc pas un choix recommandé pour un codeur débutant.
Installation
L'installation de VS Code ne pose pas de difficulté, mais nécessite néanmoins d'effectuer quelques choix particuliers :
- Pour un poste de travail à système Linux, il est déconseillé jusqu'à nouvel ordre d'installer le paquet
flathubdisponible via certaines logithèques (dont celle de Linux Mint), car il s'agit d'une version non officielle qui s'exécute dans un conteneur et peut poser des problèmes ultérieurs dans le cadre d'une utilisation experte. Il est recommandé de télécharger le paquet adapté directement sur le site de VS Code – typiquement, le paquet.debpour les distributions Debian, Ubuntu, Mint. - retrouver le logiciel listé dans le menu
Démarreret ajouter son raccourci au tableau de bord (panneau). - vérifier la version de VS Code qui est installée via la commande :
code -v
Download (qui oriente vers une version mono‑utilisateur), mais choisir un installateur système (pour un usage multi‑utilisateurs) et une version 64 bits, donc typiquement un fichier exécutable dont le nom commence par VSCodeSetup-x64 suivi du numéro de version. C:\Program Files\Microsoft VS Code
Prise en main
Au premier lancement, VS Code ouvre automatiquement une fenêtre d'accueil, qu'on peut fermer pour prendre connaissance des éléments principaux de l'interface. Car en plus d'une très classique barre de menus, on y trouve plusieurs groupes de boutons très utiles (cf. la capture d'écran ci‑après).
- À gauche, on a une barre verticale de raccourcis (shortcut panel) pour afficher diverses informations dans le panneau latéral (fermé par défaut) ; ce dernier est donc très polyvalent et non pas seulement dévolu à l'exploration de fichiers comme sous Sublime Text.
- En haut à droite, on a des boutons de configuration de la fenêtre principale (layout customization) pour basculer l'affichage en mode multi/mono fenêtrage et notamment activer un terminal d'exécution.
De plus, comme Sublime Text , VS Code dispose d'une palette générale de commandes, activée par défaut par le raccourcis CtrlshiftP ou la touche F1. Fonctionnant en mode texte avec auto‑complétion dynamique, elle permet de sélectionner n'importe quelle commande existante dès la saisie des premières lettres de son appellation.
Pour plus de détails sur les diverses fonctionnalités de VS Code, on pourra consulter ce guide d'initiation très complet rédigé par Microsoft .
Accès aux paramètres de réglage
La gestion des paramètres de VS Code diffère de celle de Sublime Text. On y accède via fenêtre d'interface (cf. la capture d'écran ci‑dessous) ouverte via le menu File/Preferences/Settings (raccourci Ctrl,).
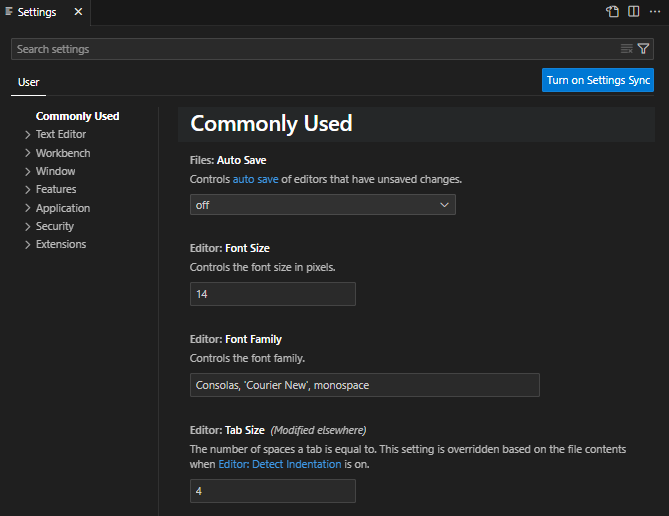
- Pour trouver facilement un paramètre (car il y en a énormément !), cette fenêtre intègre :
- en haut, une barre de recherche avec auto‑complétion ;
- à gauche, un panneau de navigation avec les différentes rubriques de classement des paramètres.
- Chaque paramètre est présenté avec son appellation, une brève description (avec éventuellement des liens hypertextes) et un champ pour choisir sa valeur.
Reset Setting accessible par un menu contextuel qui s'affiche en cliquant sur un bouton caché ⚙ situé à gauche du nom du paramètre (cf. la capture d'écran ci‑contre). 
De plus, il est possible d'éditer dans un fichier de préférences nommé settings.json (cf. supra ) tous les paramètres modifiés par l'utilisateur en cliquant sur le bouton de raccourci en haut à droite de la fenêtre (cf. la capture d'écran ci‑contre).
Si, dans la fenêtre d'interface, on modifie seulement le paramètre Tab Size (cf. supra ) en lui donnant la valeur 2, on obtient le fichier de préférences settings.json représenté sur la capture d'écran ci‑contre.
Comme pour Sublime Text, ce fichier de réglages utilisateur est portable. Il est placé dans un répertoire dont le chemin d'accès dépend du système d'exploitation.
- Sous Linux :
/home/username/.config/Code/User - Sous Windows :
C:\Users\username\AppData\Roaming\Code\User
Mais contrairement à Sublime Text, avec l'application VS Code, il n'est pas possible de visualiser les réglages par défaut sous la forme d'un fichier au format JSON.
Même s'ils apparaissent dans la fenêtre d'interface, certains paramètres spécifiques à des extensions peuvent être modifiés seulement via une ligne de code dans le fichier de préférences settings.json (cf. par exemple le choix de la chaîne de compilation par défaut pour les langages C/C++ expliqué, dans la section ci‑dessous).
Extension pour la prise en charge de C/C++
Comme il a été présenté supra , VS Code n'est pas un véritable IDE mais un éditeur de code extensible. Pour qu'il prenne en charge les langages C/C++, il faut donc :
- lui associer le chemin d'accès à une chaîne de compilation déjà installée sur le poste de travail ;
- lui apporter l'auto‑complétion intelligente via une extension spécialement développée pour.
C'est ce que détaille la procédure ci‑dessous. De façon complémentaire, on pourra consulter ce chapitre du guide rédigé par Microsoft spécifiquement pour l'extension C/C++ .

En ce qui concerne l'extension à installer, il est vivement recommandé de choisir celle dénommée simplement C/C++ qui est développée par Microsoft (cf. son icône ci‑contre). On la trouve en cliquant dans sur le bouton de raccourci vers les extensions (cf. supra ou taper CtrlShiftX) qui donne un accès direct au marché des extensions (Marketplace). Dans le panneau latéral gauche ainsi ouvert, il suffit de saisir « C » dans la barre de recherche. Elle apparaît alors en premier choix, il n'y a plus qu'à la sélectionner et cliquer sur le bouton bleu Install.
Un fois l'installation terminée, dans sa fenêtre d'accueil, il est proposé de choisir d'installer ou d'indiquer l'accès à la chaîne de compilation qui doit être utilisée par défaut pour les langages C/C++. Dans le cas où l'installation est déjà faite, le chemin d'accès aux exécutables de la chaîne de compilation dépend bien entendu du système d'exploitation ; au regard des choix précédents – installation de GCC, cf. supra – on saisit donc :
-
/usr/bin/gccsous Linux ; -
C:\Program Files\mingw64\bin\gcc.exesous Windows.
En examinant le fichier des préférences utilisateur settings.json, on trouve alors une ligne de code de la forme :
"C_Cpp.default.compilerPath": path
où path est le chemin détaillé ci‑dessus selon le système d'exploitation.
Remarque : au format JSON, dans le codage des chemins du système de fichiers de Windows, toute occurrence du séparateur « \ » doit être doublée, c'est‑à‑dire saisie \\ pour former ce qu'on appelle une séquence d'échappement (cf. chap. C2‑VII ).
Avec l'extension C/C++ installée et paramétrée, la compilation, l'exécution et même le débogage d'un programme sont autant de tâches pouvant être effectuées au sein de VS Code, qui constitue alors un véritable IDE. La procédure décrite ci‑dessous en donne un exemple minimal d'utilisation.
- Après avoir créé un répertoire de projet, on peut l'ouvrir via le menu
File/Open Folder. Cette commande affiche automatiquement la fenêtre d'accueil dans laquelle on trouve des liens de raccourcis utiles, notammentNew File…. - Lorsqu'on crée un nouveau fichier source nommé
hello.c, l'application VS Code reconnaît son extension et l'ouvre automatiquement avec la coloration syntaxique et l'auto‑complétion appropriées au langage C. On peut s'en rendre compte en saisissant le code ci‑dessous (à enregistrer après saisie) :
#include <stdio.h>
int main(void)
{
printf("Hello, World!\n");
return 0;
}

Run) associé à un menu déroulant. Ce menu permet de sélectionner la tâche de compilation et/ou d'exécution et de débogage du programme qui est lancée lorsqu'on clique sur le bouton. Run C/C++ File est lancée, elle renvoie automatiquement à la palette de commandes (cf. supra ) dans laquelle il suffit de cliquer sur le premier choix, spécifique à l'extension C/C++ (l'intitulé de la commande dépend du système) : C/C++: gcc build and debug active file
Cette commande lance une procédure complexe nécessitant quelques secondes d'exécution – mais heureusement transparente pour l'utilisateur. Elle comprend les étapes suivantes :
- La création dans le répertoire de projet d'un sous‑répertoire
.vscode; - La compilation du programme avec la création du fichier exécutable correspondant au fichier source, nommé
hellosous Linux,hello.exesous Windows ; - L'exécution du programme dans le terminal de commandes en lignes intégré à VS Code ;
tasks.json codant les paramètres de la compilation. TERMINAL du cadre bas de l'application en sélectionnant la tâche C/C++: gcc build active file dans le panneau latéral droit. TERMINAL de la fenêtre basse en sélectionnant la tâche cppdbg: hello dans le panneau latéral droit (la chaîne de caractères Hello, World! a été affichée conformément au code source). 
Run C/C++ File pour le fichier source actif, on constate qu'elle est plus rapide : elle ne passe plus par la palette de commande mais enchaîne directement la compilation et l'exécution du programme en mode débogage. Pour un fichier source codé en langage C++ enregistré avec une extension reconnue – typiquement, .cpp – la commande Run C/C++ File du menu contextuel est capable de proposer automatiquement en premier choix une commande dans la palette, avec le compilateur g++.
À travers cet exemple d'utilisation le plus réduit possible, on peut donc mesurer que l'éditeur VS Code est difficile à prendre en main par un débutant. On va voir ci‑après que les possibilités de paramétrages sont encore plus nombreuses et ramifiées qu'on pourrait l'imaginer et qu'il importe de ne pas confondre les différentes configurations qui s'y rapportent.
Paramétrage de la chaîne de compilation
Sous VS Code, le fichier tasks.json est, comme son extension l'indique, codé en langage JSON W. Spécifique au projet, il peut être modifié à volonté par le codeur pour adapter les paramètres de la chaîne de compilation à toutes sortes d'exigences : choix du niveau d'avertissements, du langage ou même de la norme (millésime), recours à des bibliothèques spéciales, etc.
Dans le fichier tasks.json, la tâche de génération du code exécutable créée par défaut par l'extension C/C++ présente le code suivant :
{
"type": "cppbuild",
"label": "C/C++: gcc générer le fichier actif",
"command": "/usr/bin/gcc",
"args": [
"-fdiagnostics-color=always",
"-g",
"${file}",
"-o",
"${fileDirname}/${fileBasenameNoExtension}"
],
"options": {
"cwd": "${fileDirname}"
},
"problemMatcher": [
"$gcc"
],
"group": {
"kind": "build",
"isDefault": true
},
"detail": "Tâche générée par le débogueur."
}
à propos duquel on peut apporter les précisions suivantes :
- À la ligne nº 4, la valeur
cppbuidde l'attributtypeest spécifique à l'extension C/C++. De plus, elle est définie comme la tâche par défaut du groupe de tâches du genrebuild(cf. les lignes nº 21 & 22). - À la ligne nº 5, la valeur de l'attribut
labelest le nom de la tâche ; c'est cette valeur qui permet d'identifier la tâche dans d'autres codages de configuration, par exemple pour définir un raccourci, imposer une contrainte d'antériorité, etc. - À la ligne nº 6, la valeur de l'attribut
commandest le chemin vers l'exécutable qui pilote la chaîne de compilation. Pour une compilation en C++, il suffit donc de remplacergccparg++. - À la ligne nº 6, la valeur de l'attribut
argsest la liste des arguments de la commande de compilation. Pour ajuster le niveau d'avertissement conformément aux usages recommandés en apprentissage de la programmation (cf. supra ), il suffit donc d'ajouter les items suivants :
"-Wall",
"-Wextra",
"-Werror",
options définit les options de la tâche (pas de la commande). Ici est défini le répertoire courant de travail (current working directory) dans lequel la commande est exécutée – sinon, c'est le répertoire racine qui est choisi par défaut. Configuration d'autres tâches
Sous VS Code, le fichier tasks.json permet, comme le pluriel de son nom le suggère, de définir plusieurs tâches spécifiques au projet. Et ces tâches peuvent être indépendantes ou éventuellement liées entre elles.
Par ailleurs, pour faciliter leur emploi, les tâches peuvent être associées à des raccourcis claviers définis dans le fichier keybindings.json (cf. infra ). On peut ainsi mettre en place des outils de compilation et/ou d'exécution plus souples que ce qui est mis en œuvre en cliquant sur le bouton ▷.
En particulier, il est utile pouvoir disposer d'une tâche de test du programme, c'est‑à‑dire d'exécution seule, sans regénération du code exécutable. Une telle tâche peut‑être codée comme ci‑dessous :
{
"type": "shell",
"label": "Run C/C++ File",
"command": "${fileDirname}/${fileBasenameNoExtension}",
"options": {
"cwd": "${fileDirname}"
},
"presentation": {
"reveal": "always",
"panel": "shared"
},
"group": {
"kind": "test",
"isDefault": true
},
"detail": "Specifically coded in tasks.json"
}
Dans ce code :
- À la ligne nº 30, la tâche est définie de type
shell, non spécifique à une extension, ce qui signifie qu'elle se déroule dans un terminal de commandes en ligne. - Aux lignes nº 36 à 39, la tâche est configurée de sorte que son processus d'exécution soit systématiquement visible et se déroule dans un onglet partagé, c'est‑à‑dire commun avec d'autres tâches.
test, c'est‑à‑dire d'exécution de code. On peut également coder une tâche qui permet d'enchaîner la génération et l'exécution, comme ci‑dessous :
{
"type": "shell",
"label": "C Compile and Run program",
"command": "${fileDirname}/${fileBasenameNoExtension}",
"options": {
"cwd": "${fileDirname}"
},
"dependsOn": [
"C/C++: gcc générer le fichier actif"
],
"dependsOrder": "sequence",
"presentation": {
"reveal": "always",
"panel": "shared"
},
"group": {
"kind": "test",
"isDefault": false
},
"detail": "Specifically coded in tasks.json"
}
Par rapport au code de la tâche Run C/C++ File donné supra, on peut observer deux différences :
- Les lignes nº 53 à 56 imposent la contrainte d'antériorité de la tâche de génération, qui sera donc systématiquement appelée avant ;
- Les lignes nº 61 à 64 précisent que la tâche est du genre
testmais n'est pas celle par défaut.
À l'heure actuelle (version 1.88.1, avril 2024), il semble que VS Code n'offre pas de possibilité à l'utilisateur de modifier globalement la tâche par défaut générée lors de la première compilation d'un projet. Toutes les configurations de la chaîne de compilation restent donc spécifiques et doivent être recodés pour chaque nouveau projet.
À cette lacune, un palliatif peut consister à réunir le code des tâches proposées supra dans un fichier modèle tasks.json. Dans la mesure où il constitué exclusivement de code générique – c'est‑à‑dire sans référence au moindre nom de fichier – il suffit de s'en servir pour remplacer celui produit automatiquement par l'extension C/C++ dans le répertoire .vscode de chaque projet.
Raccourcis claviers
Sous VS Code, on accède aux raccourcis claviers via le menu :
File/Preferences/Keyboard Shortcuts
ou encore via le bouton ⚙ de paramétrage (manage) situé en bas à gauche de la fenêtre de l'application.
Dans l'interface utilisateurs, ils se présentent sous la forme d'un tableau à quatre colonnes qui recense toutes les commandes de l'application, comme le montre la capture d'écran (partielle) ci‑dessous.
sachant que seule une petite partie de ces commandes font par défaut l'objet d'un raccourci.
Le nombre de commandes étant potentiellement très grands, on dispose d'une barre de recherche qui opère par comparaison du motif saisi (sous‑chaîne de caractères) avec tous les éléments de texte contenus dans le tableau (les motifs trouvés apparaissent instantanément en couleur). On peut donc faire une recherche par nom, par commande, par séquence de touches…

Après avoir sélectionné une entrée du tableau (ligne), on active son édition en cliquant sur le bouton (stylo) qui s'affiche à tout gauche de la ligne. On peut ainsi attribuer ou modifier le raccourci clavier qui est affecté à la commande, en précisant éventuellement les circonstances dans lesquelles le raccourci est utilisable (colonne When).
Pour une utilisation plus experte, on peut aussi éditer les raccourcis dans un fichier utilisateur au format JSON nommé keybindings.json. On peut y accéder soit en cliquant sur le bouton en haut à droite dans la barre d'onglet de l'application, soit via la palette de commande en saisissant :
Preferences: Open Keyboard Shortcuts (JSON)
sachant que le fichier lui‑même est placé dans un répertoire utilisateur. Sous Linux, il est typiquement accessible via le chemin :
home/user/.config/Code/User
Par défaut, ce fichier est vide, sa fonction étant de mémoriser toutes les modifications apportées par l'utilisateur par rapport aux raccourcis définis par l'application et ses extensions.
Dans le fichier keybindings.json, chaque raccourci est potentiellement codé par une règle à quatre attributs, les deux premiers étant obligatoires :
-
key, dont la valeur définit la séquence de touches ; -
command, dont la valeur définit la commande déclenchée ; -
arg, dont la valeur définit les arguments éventuels de la commande ; -
when, dont la valeur définit les circonstances éventuelles dans lesquels le raccourci peut être utilisé.
-, la règle code la suppression d'un raccourci préalablement défini. Par rapport au tableau de l'interface utilisateur, l'attribut arg apporte une puissance d'expression supplémentaire. Il permet notamment de cibler n'importe quelle tâche codée dans le fichier tasks.json.
Avec VS Code, pour faciliter l'emploi des tâches de compilation et d'exécution proposées supra , on peut coder les raccourcis suivants :
{
"key": "alt+t",
"command": "openInIntegratedTerminal"
},
{
"key": "ctrl+shift+t",
"command": "-workbench.action.reopenClosedEditor"
},
{
"key": "ctrl+shift+alt+t",
"command": "workbench.action.reopenClosedEditor"
},
{
"key": "ctrl+shift+t",
"command": "workbench.action.tasks.test",
"when": "editorLangId == 'c' || editorLangId == 'cpp'"
},
{
"key": "ctrl+shift+alt+b",
"command": "workbench.action.tasks.runTask",
"args": "C Compile and Run program",
"when": "editorLangId == 'c' || editorLangId == 'cpp'"
}
Dans ce code :
- La première règle (lignes nº 3 à 6) associe le raccourci AltT pour ouvrir un terminal sous le cadre d'édition (aucun raccourci pour cette commande n'étant associé par défaut dans l'application).
- La deuxième règle (lignes nº 7 à 10) supprime le raccourci CtrlShiftT affecté par défaut à l'action de ré‑ouvrir un onglet d'édition préalablement fermé ; ceci afin de pouvoir l'utiliser pour une autre action.
- La troisième règle (lignes nº 11 à 14) associe à cette commande le (nouveau) raccourci CtrlShiftAltT.
- La quatrième règle (lignes nº 15 à 19) associe à la tâche de test par défaut d'un programme le raccourci (maintenant disponible) CtrlShiftT (sachant qu'aucun raccourci pour cette commande n'était associé par défaut dans l'application).
- La cinquième règle (lignes nº 20 à 25) associe à la tâche de génération et test d'un programme le raccourci CtrlShiftAltB. Cette tâche spécifiquement codée par l'utilisateur (cf. supra ) n'étant pas une tâche par défaut, elle est ciblée par la commande générale de lancement d'une tâche (
workbench.action.tasks.runTask) en passant comme argument son nom (la valeur de son attributlabeldans le fichiertasks.json) .
when (cf. les lignes nº 18 & 24). Pour plus de détails sur les raccourcis, on pourra consulter cette page de référence de l'application VS Code .
Configuration de IntelliSense
La fonctionnalité dite IntelliSense mise en œuvre par l'extension C/C++ de VS Code n'apporte pas seulement l'auto‑complétion « intelligente » lors de la saisie du code source d'un programme. Elle affiche également des infobulles lorsque le pointeur de la souris survole certains éléments de code, notamment :
- les noms des fonctions – on obtient ainsi leur définition ;
- les noms des variables – on obtient ainsi leur type.
Mais pour que IntelliSense soit pleinement opérationnel, il peut être nécessaire de modifier sa configuration par défaut. Le nom de cette configuration est indiqué tout à droite dans la barre de notification, typiquement :
-
Linuxsur un poste de travail à système Linux ; -
WIN32sur un poste de travail à système Windows.
Cliquer sur ce nom renvoie dans la palette de commande où apparaît la possibilité de modifier cette configuration, soit via une fenêtre d'interface, soit par un fichier .json. Dans les deux cas, un fichier de configuration nommé c_cpp_properties.json est créé dans le sous‑répertoire local .vscode.
Comme pour les tâches de compilation avec le fichier tasks.json (cf. supra ), pour un même projet, il est possible de définir plusieurs configurations différentes d'IntelliSense via le fichier c_cpp_properties.json.
- On peut paramétrer une configuration en codant notamment le chemin vers compilateur utilisé, la norme du langage à appliquer, l'architecture de la machine‑cible, etc. (il est commode de recourir à la fenêtre d'interface pour voir toutes les possibilités).
- Pour sélectionner une configuration, il suffit de cliquer sur le nom de la configuration active qui est affiché dans la barre de notifications. La palette de commande propose alors la liste de toutes les configurations définies pour le projet.
- Comme pour les tâches (cf. la remarque B supra ), il ne semble pas possible à l'heure actuelle de modifier globalement la configuration par défaut d'IntelliSense. Tous les réglages codés dans le fichier
c_cpp_properties.jsonsont spécifiques et doivent être recodés à chaque nouveau projet. - Les réglages codés dans le fichier
c_cpp_properties.jsonsont indépendants de ceux codés dans le fichiertasks.json. Autrement dit, ils ne concernent que les fonctionnalités de IntelliSense et n'impactent pas les paramètres de la compilation. - Dans la plupart des cas, lorsqu'on débute en programmation, la génération d'un fichier
c_cpp_properties.jsondans le répertoire de projet n'est pas absolument pas indispensable pour compiler et exécuter un programme avec VS Code (seul le fichiertasks.jsonest incontournable).
Configuration du débogage
On a vu supra que lorsqu'on clique sur le bouton ▷ pour un fichier source actif déjà compilé, l'application VS Code lance successivement deux processus :
- la compilation du code source conformément aux indications codées dans le fichier
tasks.json; - l'exécution du programme par le biais du débogueur W.
Le processus d'exécution ainsi lancé est implicitement paramétré la configuration par défaut du débogueur, à ne pas confondre avec celle de la fonctionnalité IntelliSense.
Comme pour la fonctionnalité IntelliSense, il est possible de modifier cette configuration au niveau du répertoire de projet. Il suffit pour cela de cliquer sur le bouton ⚙ (Add Debug Configuration) situé à droite du bouton ▷.
Cliquer sur ce bouton renvoie dans la palette de commande avec la consigne de choisir une configuration de débogage. Il suffit de sélectionner le premier choix proposé, typiquement :
C/C++: gcc build and debug active file
et un fichier de paramétrage nommé launch.json est automatiquement créé dans le sous‑répertoire local .vscode.
Comme pour la fonctionnalité IntelliSense, pour un même projet, il est possible de définir plusieurs configurations différentes via le fichier launch.json. Et dans une configuration, on peut notamment changer le débogueur utilisé, définir des points d'arrêts et d'autres éléments relatifs au débogage W.
- Comme pour les tâches et la fonctionnalité IntelliSense (cf. les remarques des deux sections précédentes), il ne semble pas possible à l'heure actuelle de modifier globalement la configuration par défaut de débogage. Tous les réglages codés dans le fichier
launch.jsonsont spécifiques et doivent être recodés à chaque nouveau projet. - Les réglages codés dans le fichier
launch.jsonsont indépendants de ceux codés dans le fichiertasks.json. Autrement dit, ils n'ont pas d'influence sur le paramétrage de la compilation. - Dans la plupart des cas, lorsqu'on débute en programmation, la génération d'un fichier
launch.jsondans le répertoire de projet n'est pas absolument pas indispensable pour compiler et exécuter un programme avec VS Code. Seul le fichiertasks.jsonest incontournable.
Notion de workspace
On a vu supra que pour le codage des programmes simples (ce qui est le cas des exercices et travaux pratiques proposés dans ce module de formation), il est commode de placer directement dans un répertoire de projet tous les fichiers (source et exécutable).
Toutefois, pour des programmes plus complexes, il peut être nécessaire de répartir les fichiers dans divers répertoires qui eux‑mêmes ne sont pas placés directement dans un répertoire commun.
C'est là que le concept de Workspace (en français, espace de travail) proposé par VS Code trouve son intérêt : il permet de regrouper symboliquement plusieurs répertoires auxquels peuvent être associés un même paramétrage.
Les commandes relatives au concept de workspace sont regroupées dans le menu File, notamment :
-
Save Workspace As…pour créer un espace de travail dans le répertoire ouvert au moment de la commande ; -
Add Folder To Workspace…pour ajouter un répertoire à l'espace de travail ouvert moment de la commande ;
sachant qu'un workspace est défini par un fichier au format JSON mais d'extension .code-workspace. Dans ce fichier, on trouve codé :
- la liste des répertoires de l'espace de travail ;
- les réglages communs à l'espace de travail.
Il est tout à fait possible de ne définir aucun workspace en utilisant VS Code – c'est la pratique usuelle pour les programmes simples. Dans l'interface utilisateur, notamment pour les réglages, le terme Workspace fait alors référence au répertoire ouvert.
Notion d'implémentation – Choix de la norme du langage
Notions d'implémentation du langage
En programmation, on parle d'implémentation d'un langage pour désigner telle ou telle chaîne de compilation, dans une version précise, qui permet de produire du code exécutable pour une architecture de machine cible donnée – c'est‑à‑dire la machine sur laquelle le code doit s'exécuter.
Pour garantir une uniformité satisfaisante des résultats de compilation, les normes respectives des langages C et C++ imposent des spécifications impératives que les chaînes de compilation doivent respecter.
Toutefois, les normes accordent aussi certaines libertés aux compilateurs. Cela est nécessaire pour une bonne adaptation des programmes aux différentes architectures de machines, en particulier, pour le stockage en mémoire des données. En effet, il serait contre‑productif d'imposer les mêmes contraintes pour un PC à processeur 64 bits avec 16 Go de mémoire et une carte à microcontrôleur 8 bits avec seulement 2 ko de mémoire.
On dit alors que certains aspects du langage sont « dépendant de l'implémentation ». Il en découle qu'un code source peut donc être compilable sur une machine et pas sur une autre. Cette variabilité de compilation ne simplifie par l'apprentissage du langage, et tout débutant doit avoir en conscience pour se prémunir de certaines erreurs classiques.
Pour des raisons historiques de techniques d'encodage, la norme impose pour le type d'entier standard int une étendue de valeurs au moins comprise entre −32 767 et +32 767 seulement. Mais :


On peut se faire une idée de la très grande diversité des implémentations sur l'environnement en ligne Compiler Explorer godbolt.org, développé par Matt Godbolt. Il permet de tester la compilation (avec production du code d'assemblage) et l'exécution d'un même programme pour toutes sortes de combinaisons d'architectures de machines et de chaînes de compilation dans leur différentes versions (cf. la capture d'écran très partielle ci‑dessous).
Versions des normes dans la chaîne de compilation
On a vu supra que les normes respectives des langages C et C++ font l'objet de révisions périodiques. On peut également en retrouver la liste ici pour le C W et là pour le C++ W.
En règle générale, les chaînes de compilation sont mises à jour pour prendre en charge les évolutions des normes seulement plusieurs années après leur publication. Par exemple, en ce qui concerne GCC :
- même les versions 14.x distribuées à partir de 2024 mettent par défaut en œuvre seulement la norme C17 du langage C ;
- La norme C23 est optionnellement prise en charge, mais pas intégralement.
Pour sélectionner une norme particulière, avec la commande gcc, on emploie l'option -std= suivie d'une sous‑option de la forme gnu⦁⦁ ou c⦁⦁ (attention, en minuscules) selon que l'on souhaite respectivement disposer ou non des extensions GNU (cf. supra ).
Quant aux deux symboles ⦁⦁, ils codent le millésime de révision de la norme du langage C. Attention, ces deux symboles ne peuvent prendre que les valeurs 89 ou 90 (équivalentes), 99, 11, 17 ou 18 (équivalentes) et 2x (version expérimentale pour la norme C23 – laquelle n'est vraiment prise en charge qu'à partir de la version gcc-14 de la chaîne de compilation).
Il en va de même pour le langage C++ avec la commande g++ qui admet des sous‑options de la forme c++⦁⦁ avec comme valeurs possibles 98, 03, 11, 14, 17, 20 et 23 (le millésime C++26 n'est pas encore pris en charge).
- La commande :
gcc -std=c11…
g++ -std=gnu++17…
Avec l'IDE VS Code, il est donc très simple de choisir tel ou tel millésime de la norme du langage adopté par le compilateur pour d'un programme donné. Il suffit de coder une ligne d'option comme celles de l'exemple ci‑dessus dans le paramètre args des tâches de compilation et de génération définies dans le fichier tasks.json (cf. supra ).
De plus, pour un fonctionnement optimal d'IntelliSense, il est recommandé de coder la même valeur de millésime à l'argument cStandard dans le fichier c_cpp_properties.json (cf. supra ).
En revanche, avec la plupart des environnements de programmation en ligne, il n'est pas toujours facile de sélectionner telle ou tel millésime de la norme du langage.
Par exemple, sur OnlineGDB, on ne peut pas directement choisir la norme pour le langage C – alors que pour le C++, on a le choix entre les normes C++11 (choix par défaut), C++14, C++17 et C++23.
En revanche, il est toujours possible d'ajouter à la ligne de commande une option de la forme -std=c⦁⦁ via le bouton Extra Compiler Flafs dans le menu des paramètres ⚙ (cf. supra ).
Enfin, lors de l'exécution d'un programme, quel que soit l'environnement utilisé, il reste possible d'avoir une indication du millésime de la norme employée par la chaîne de compilation. Il suffit pour cela de coder dans le fichier source du programme une instruction qui affiche la valeur d'une variable d'environnement spécifique au langage :
- en langage C, c'est la variable
__STDC_VERSION__; - en langage C++, c'est la variable
__cplusplus.
Ces variables sont l'une et l'autre de type long int (cf. chap. C3‑II). Elles expriment dans le sens de lecture (de gauche à droite) une indication de l'année et le numéro du mois de la version de la norme. Toutefois, dans certains cas, cette indication peut prêter à confusion.
- Sous OnlineGDB, avec les réglages par défaut (dernier test effectué le 3 mai 2026), en remplaçant (copier/coller) l'instruction d'affichage initiale
printf("Hello World");: - l'instruction
printf("%ld\n", __STDC_VERSION__);affiche la valeur199901, ce qui signifie que le programme est compilé en langage C conformément à la norme C99 (janvier) ; - l'instruction
printf("%ld\n", __cplusplus);affiche la valeur201103, ce qui signifie que, par défaut, le programme est compilé en langage C++ conformément à la norme C++11 (mars). - Dans un terminal de commandes en lignes sur une machine Linux, en ayant installé les chaînes de compilation
gcc-14etg++14, le principe est le même. - L'instruction
printf("%ld\n", __STDC_VERSION__);affiche la valeur201710(norme C17) mais202000(!?) si le programme est compilé avec l'option-std=c23. Dans ce dernier cas, l'indication fait référence à une version expérimentale car, en toute rigueur, la norme C23 n'est pas encore totalement prise en charge, même par les versions les plus récentes degcc(alors qu'en fait, cette prise en charge est quasi‑complète). - L'instruction
printf("%ld\n", __cplusplus);affiche la valeur201703(norme C++17) et202302(norme C++23) si le programme est compilé avec l'option-std=c++23.
Les options « pedantic » de GCC
La commande gcc dispose d'options dites « pedantic » qui – avec un sens de l'humour un peu « second degré » – ont vocation d'aider le codeur à coder des programmes respectant strictement la norme du langage.
L'intérêt est de produire des programmes sources portables, c'est‑à-dire pouvant être compilés sur n'importe quelle implémentation, typiquement en renonçant à utiliser des extensions à la norme fournies par GCC (cf. supra ) puisque ces dernières ne sont pas disponibles dans toutes les implémentations.
- La plus connue est l'option d'avertissement
-Wpedantic, dont l'ancienne forme-pedanticest encore valide. Lorsqu'elle est invoquée, le compilateur émet un avertissement à chaque fois que le programme ne respecte pas strictement la norme spécifiée ou sélectionnée par défaut par la commande de compilation, même si ce programme est quand même compilable et correctement exécutable grâce aux extensions qu'il exploite. - Il y a aussi l'option
-pedantic-errorsqui convertit les avertissements de type « pedantic » en erreur de compilation, et ce faisant bloque la production du code exécutable – de la même manière que le fait l'option-Werrorpour tout avertissement en général (cf. supra ).
-Wpedantic pour être opérationnelle, mais elle est redondante avec l'invocation de -Werror. Les programmes déclenchant un avertissement de type « pedantic » font souvent appel à des concepts de codage avancés : pointeur générique, tableau de taille variable…
L'exemple académique proposé ci‑dessous – et enregistré dans un fichier nommé nestedSquare.c – consiste simplement en l'imbrication d'une fonction dans une autre (en anglais, nested functions) : la fonction square est codée à la ligne nº 3 au sein de la fonction principale main. Une telle pratique, bien que déconseillée de façon générale (cf. chap. C4‑I) et non conforme à la norme du langage C, est néanmoins autorisée par GCC. C'est donc une extension du langage C, qui par ailleurs n'est pas portée en C++.
int main(void)
{
float square(float x) {return x * x;} // nested function
return square(2);
}
- Compilé avec les options usuelles
-Wall -Wextra, dans un terminal de commandes sous Linux, ce programme ne déclenche aucun avertissement. Exécuté dans la foulée, il produit le résultat attendu :
gcc -Wall -Wextra nestedSquare.c -o nestedSquare && ./nestedSquareecho $?4
-Wpedantic, on obtient bien un avertissement tout à fait explicite, bien que le code machine généré reste parfaitement exécutable : gcc -Wpedantic nestedSquare.c -o nestedSquare && ./nestedSquarenestedSquare.c: In function ‘main’: nestedSquare.c:3:3: warning: ISO C forbids nested functions [-Wpedantic] 3 | float square(float x) {return x * x;} | ^~~~~echo $?0./nestedSquareecho $?4
-pedantic-errors, on obtient une erreur qui bloque la génération du fichier exécutable, comme l'explicite le code de retour 1 de la commande gcc : gcc -pedantic-errors nestedSquare.c -o nestedSquare && ./nestedSquarenestedSquare.c: In function ‘main’: nestedSquare.c:3:3: error: ISO C forbids nested functions [-Wpedantic] 3 | float square(float x) {return x * x;} | ^~~~~echo $?1