Si l'architecture web du côté client est relativement simple (une machine hébergeant un navigateur et quelques plugins – cf. chap. R2‑III ), il en va rarement de même du côté serveur. À moins que l'on souhaite mettre en œuvre un site web constitué seulement de pages statiques, on recourt aujourd'hui à une technologie logicielle complexe qui s'appuie sur au moins deux niveaux de service, chacun spécialisé dans sa fonction :
- l'élaboration de pages web en fonction des demandes du client – service dont le codage nécessite l'emploi un langage de script (php, Python, Javascript avec Node.js, etc.) voire même un langage compilé) ;
- le stockage des informations (en particulier celles des clients) dans une base de données – dont l'exploitation passe par l'emploi d'un langage de requêtes spécifique (typiquement, SQL).
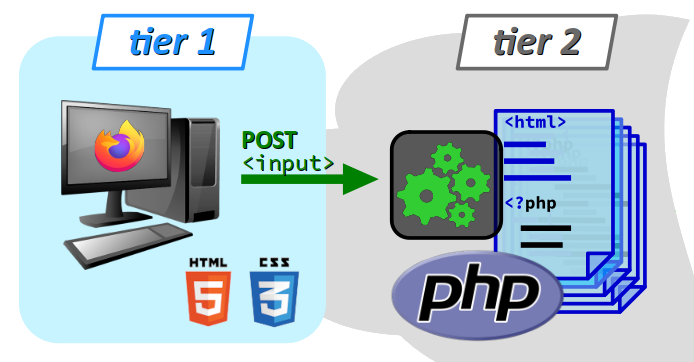
En comptant le client, on parle alors d'architecture 3 niveaux W, en anglais, architecture 3 tiers, qu'on utilise aussi en français par anglicisme (en effet, le terme anglais tier – sans « s » – est un faux‑ami, il se traduit par niveau en français, et non pas « tiers »).
Et encore, cette décomposition est insuffisante pour modéliser des applications web plus complexes – et néanmoins aujourd'hui très courantes – où peuvent intervenir notamment :
- des traitements spécifiques opérés par des logiciels « métiers » (business tier) qui mettent en œuvre des traitements informatiques spécialisés dans un domaine – par exemple, des calculs statistiques ;
- des niveaux intermédiaires de stockages de données ou d'équilibrage de la charge des requêtes sur un pool de serveurs (load balancer).
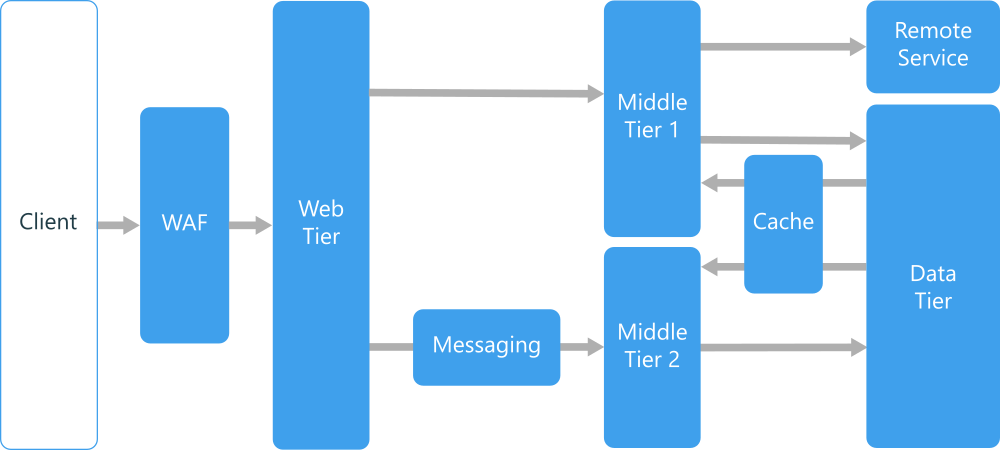
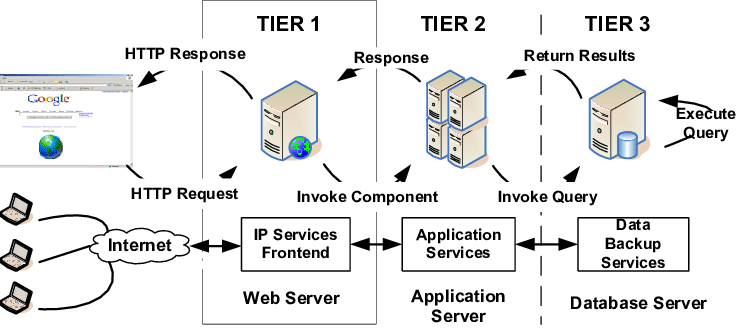
On parle alors d'architecture multi‑niveaux (en anglais, multitier) W, avec des schémas fonctionnels qui varient fortement d'une application à l'autre – cf. par exemple la figure ci‑dessus issue de la documentation Azure , la solution commerciale en cloud computing proposée par l'entreprise Microsoft.
Au regard de cette complexité technologique, ce chapitre se fixe pour objectif principal de donner une vue d'ensemble de l'architecture web du côté serveur.
- On commencera par l'architecture générale du côté serveur, en détaillant les solutions matérielles les plus usuelles pour les différents niveaux de services.
- On étudiera ensuite les technologies logicielles des serveurs web, notamment le système d'exploitation qu'ils requièrent, et bien entendu les solutions pour mettre en œuvre un serveur HTTP .
- Puis on abordera les principaux langages de backend et leurs frameworks associés, qui sont employés pour coder les sites web dynamiques. On se focalisera principalement sur les langages php et Javascript.
- On achèvera ce panorama technologique avec les bases de données, en se limitant aux SGBDR – systèmes de gestion de base de donnée relationnelle – qui sont de loin les plus utilisés.
- Enfin, on proposera un exemple académique d'application web reposant sur une architecture 3 niveaux. L'intégralité de son code source est fourni et expliqué, afin qu'il soit possible de l'expérimenter, tant dans le cadre d'une séance de travaux pratiques (cf. TP R2‑2 ) que sur un poste de travail équipé d'une pile AMP.
Sans exposer tous les aspects techniques de la programmation (ce qui nécessiterait un volume de cours beaucoup plus important), ce panorama est néanmoins utile à plus d'un titre pour un futur technicien en informatique. Il doit permettre :
- de « démystifier » le fonctionnement global d'une application web ;
- de découvrir les différents aspects du développement web du côté serveur et pouvoir choisir sur quelle technologie ou quel langage investir ses efforts d'apprentissage.
Car il est bien évident qu'il faudra plusieurs années de pratiques pour acquérir une bonne connaissance d'un langage de backend avec un framework associé, ou encore un système de gestion de bases de données.
À titre complémentaire de cette introduction, on pourra visionner la vidéo de vulgarisation disponible au lien suivant Y.
Architecture générale et matérielle
Architecture 3 niveaux
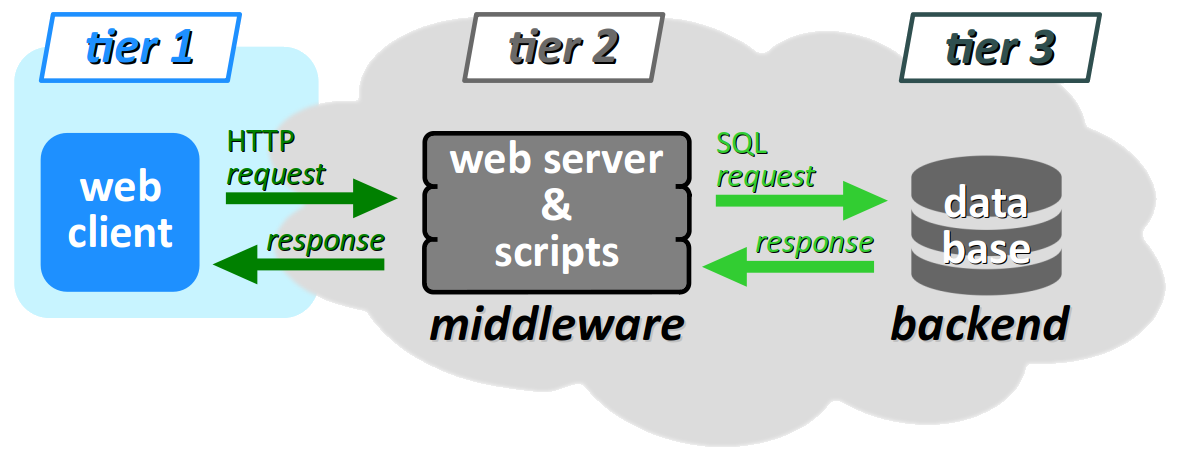
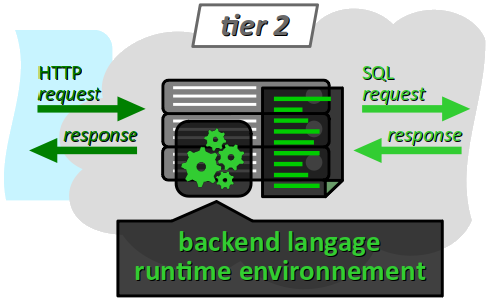
On parle d'architecture 3 niveaux (ou 3 tiers par anglicisme) W pour caractériser le schéma de principe d'une application web, dans lequel :
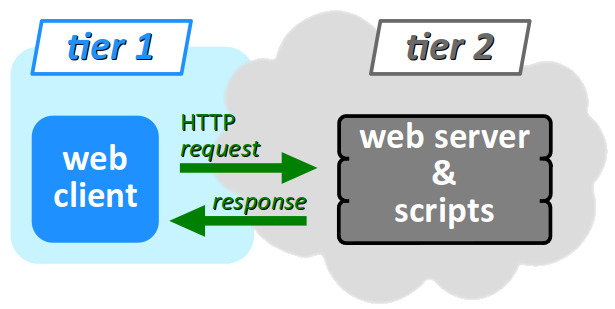
- un client web (logiciel navigateur ou autre) constitue le 1er niveau, à l'origine d'une requête HTTP d'accès à une ressource distante sur le web ;
- un serveur web constitue le 2e niveau, sur lequel s'exécute un voire plusieurs scripts pour coordonner les tâches du serveur afin de répondre aux requêtes du client, notamment préparer les ressources web demandées (c'est‑à‑dire collecter et assembler les données nécessaires), mais aussi enregistrer les données transmises par les clients ;
- une base base de données (BDD) constitue le 3e niveau, qui stocke et fournit les informations nécessaires à la préparation des ressources demandées par le client.
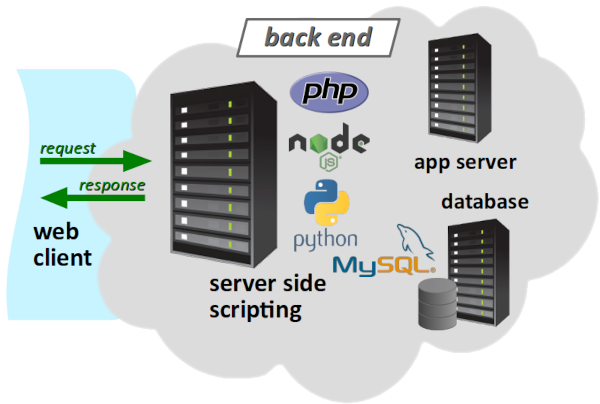
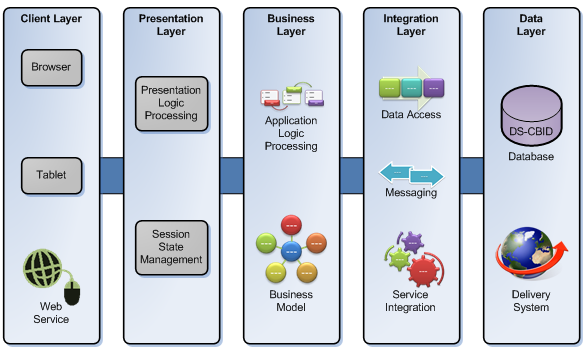
Pour le client web, les 2e et 3e niveaux ne sont pas discernables. Ils constituent ce qu'on appelle usuellement l'architecture côté serveur ou back end au sens général, par opposition au front end qui désigne l'architecture côté du client (cf. chap. R2‑III et W) et que l'on appelle aussi couche de présentation (presentation layer).
Mais dès lors qu'on étudie en détail l'architecture côté serveur, le vocabulaire technique s'enrichit :
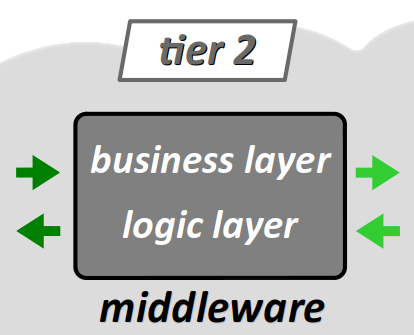
- Pour désigner le 2e niveau, on parle de couche logique (logic layer) ou encore de couche métier (business layer) middleware W en référence à sa position intermédiaire dans l'architecture globale.
- Pour désigner spécifiquement le 3e niveau, on parle de couche données (data layer) et on emploie aussi spécifiquement le terme back end (ou encore backend en un seul mot) au sens où, dans l'architecture, il s'agit du niveau le plus éloigné du client.
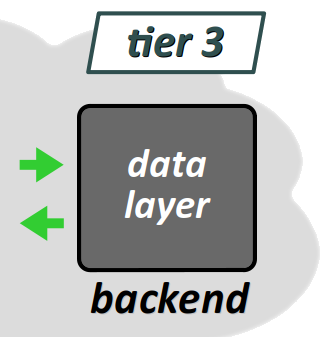
Par ailleurs, il est intentionnel que le schéma de principe de l'architecture représenté supra fasse le plus possible abstraction de toute structure matérielle. En effet, les 2e et 3e niveaux peuvent très bien :
- être réunis sur une même machine physique (et éventuellement avec recours à une machine virtuelle),
- ou encore déployés sur plus de deux machines, en particulier si l'application fait appel à plusieurs bases de données.
Plus généralement, l'architecture 3 niveaux schématisée ci‑dessus pour décrire une application web en général est une présentation simpliste d'une réalité diverse, dont la complexité est très variable selon l'application considérée.
- Dans les cas simples, le serveur web met simplement à disposition des fichiers de code HTML/CSS/JS et d'autres fichiers (images, etc.) que le navigateur du client se charge de demander pour afficher.
- Dans les cas complexes, par exemple lorsque le navigateur du client ouvre un fichier stocké sur le cloud avec un logiciel en ligne (par exemple, un logiciel professionnel de fabrication), pour préparer la page web à transmettre au client, le serveur web chargé de la coordination doit collecter :
- non seulement une multitude de données issues de différents domaines (compte client, données fournisseur, publicités…),
- mais aussi toutes les données pour exécuter le logiciel, lequel peut faire appel à divers autres composants logiciels (module de calculs, etc.)
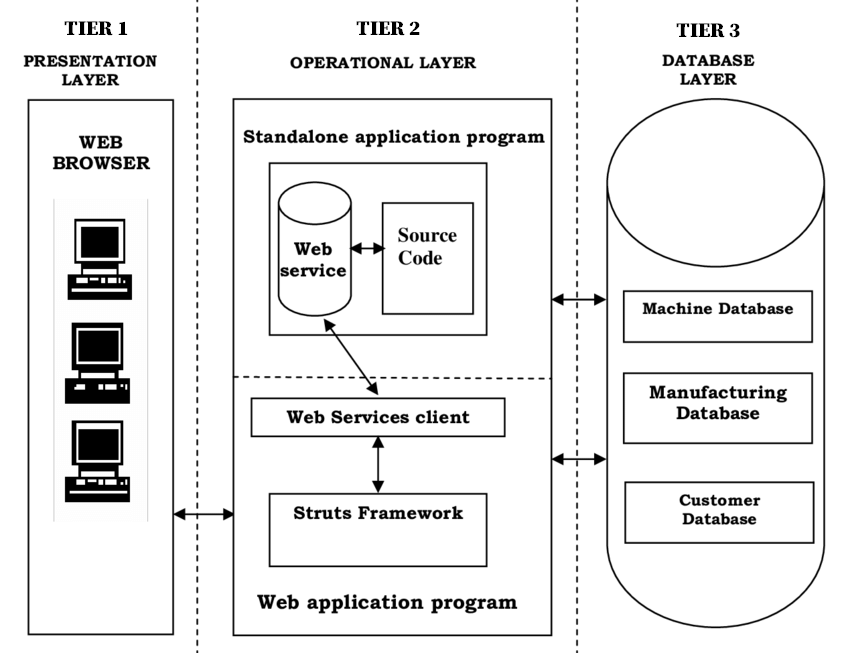
- Attention, le terme « middleware » W possède un sens originel plus spécifique en informatique. Il désigne un logiciel dont le rôle est d'assurer la communication entre des applications utilisant des standards d'entrées‑sorties hétérogènes – ces applications s'exécutant a priori (mais pas forcément) sur une même machine.
- L'architecture à trois niveaux – frontend, middleware, backend – est parfois présentée comme telle exclusivement du côté du serveur (cf. le schéma ci‑dessous extraite de cette publication de recherche ).
Si l'on compte la couche du côté du client, on peut aussi considérer qu'on a en fait une architecture à 4 niveaux.
Architecture à n niveaux
L'architecture d'un service web peut devenir encore plus complexe pour diverses raisons. Ainsi :
- pour des ressources très demandées, plusieurs serveurs en parallèle sont nécessaires dans chaque niveau ; afin de leur distribuer les requêtes, et aussi pour garantir la continuité de service en cas de panne de l'un d'entre eux, on installe un « étage » logiciel appelé répartiteur de charge W (load balancer) ; ce logiciel peut être hébergé sur une machine virtuelle ou réelle (un serveur spécifique dédié à cette tâche de répartition) ;
- la préparation de la ressource demandée peut nécessiter l'exécution d'un logiciel métier W (business software) qui constitue un niveau à lui tout seul (par exemple, un logiciel de comptabilité, de bureautique, de simulation, etc.) ;
- les bases de données peuvent être structurées sur plusieurs niveaux ou encore nécessiter un niveau intermédiaire pour l'intégration des données dans la ressource demandée ou dans le logiciel métier.
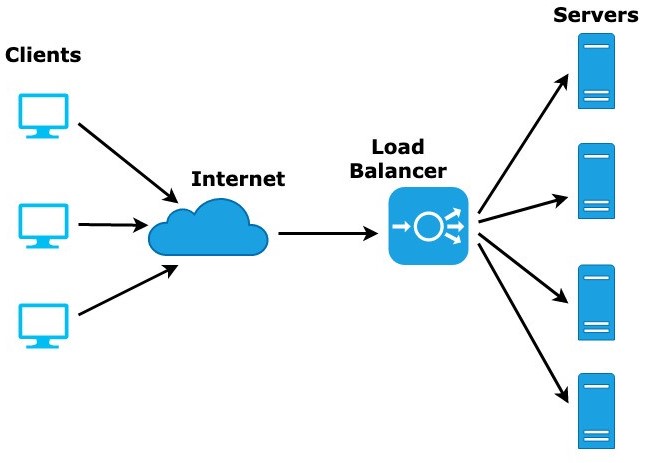
On parle alors d'architecture multi-niveaux ou à n niveaux W (en anglais, n-tier ou multitier architecture) – cf. la figure ci‑dessus.
Les machines serveurs web – généralités
Un serveur web W est une machine sur laquelle s'exécutent des applications capables de répondre à des requêtes du protocole HTTP pour mettre à disposition des ressources de type pages web.
Un serveur web peut être installé indifféremment dans un réseau public ou privé, et offrir un accès libre ou restreint, mais dans tous les cas, il doit surtout fonctionner sans interruption, et c'est cette particularité qui justifie l'adoption d'une technologie spécifique, différente de celle des postes de travail.
- Bien entendu, la continuité de service repose avant tout sur la fiabilité des composants matériels mis en œuvre. Mais elle dépend aussi de :
- certaines précautions de conception comme la modularité des unités de traitement et de stockage, et la redondance des modules ;
- certaines fonctionnalités, comme la possibilité de montage et démontage à chaud des modules, c'est‑à‑dire sans mise hors service du système.
- Par ailleurs, la continuité de service induit que la nécessité que la technologie employée soit économe en énergie – cet aspect devenant crucial avec l'augmentation du facteur d'échelle.
Il existe une grande variété de technologies de serveurs web pour répondre à toutes sortes de cahier des charges.
- Pour une application donnée, le choix de la technologie dépend essentiellement de la charge devant être supportée, c'est‑à‑dire le nombre de requêtes par unité de temps.
- Mais d'autres aspects comme l'encombrement ou les contraintes d'intégration peuvent intervenir dans des contextes particuliers, notamment pour les systèmes embarqués.
Serveurs web stationnaires usuels
La technologie matérielle des serveurs web stationnaires W se décline usuellement en trois types de solutions, chacune respectivement bien adaptée à certains environnements d'intégration. Toutes ces technologies partagent l'implication d'un nombre significatif d'unités de stockages pour héberger les pages web et autres données (images, fichiers pdf, mp3, etc.) dont le volume peut être très important.
- Le serveur tour reprend la technologie polyvalente des postes de travail fixes avec, dans un boîtier vertical ventilé, une alimentation, une carte‑mère et une ou plusieurs interfaces réseau. Facile à installer ou déplacer, le serveur peut être posé au sol ou sur n'importe quel support plan (table, meuble, etc.).
- Le serveur rack adopte une technologie modulaire à boîtier horizontal.
- Il possède une largeur standard pour permettre son empilement avec d'autres équipements dans une coffret ou une armoire de type baie.
- La hauteur du boîtier est également standard et se compte en unités (1U, 2U, etc.).
- Le serveur lame apporte une technologie ultra‑modulaire de cartes électroniques (cartes‑mères, interfaces réseau) et d'unités de stockages qui viennent s'insérer horizontalement ou verticalement dans un grand boîtier, lui‑même destiné à être monté dans une baie.



Serveurs web embarqués
La technologie matérielle des serveurs web embarqués W est évidemment beaucoup plus légère que celles des serveurs stationnaires. Précisons avant tout que le qualificatif « embarqué » ne signifie pas nécessairement qu'il s'agit d'un système mobile mais plutôt un système qui comprend un petit serveur web, lequel ne constitue pas la fonction première du système (typiquement, il peut s'agir d'une machine‑outil ou même d'un capteur autonome).
L'intérêt principal d'un serveur web embarqué est d'offrir à un système une IHM W (interface homme‑machine) à la fois conviviale et accessible à distance. Développée sous forme de pages web avec la technologie logicielle usuelle (HTML/CSS/JS…), cette interface peut permettre de consulter ou de commander le système à l'aide d'un terminal informatique équipé d'un navigateur, et pourvu qu'on dispose de part et d'autre d'une connexion réseau.
Il existe une très grande diversité des technologies de serveurs web embarqués. Les exemples donnés ci‑après ne constituent pas du tout une liste exhaustive.
- Un module réseau d'automate programmable industriel W (programmable logic controller ou PLC) comporte en général les composants nécessaires pour héberger des pages web. Ce module permet notamment d'assurer la supervision de l'automate (et donc du système qu'il commande) par un SCADA W (supervisory control and data acquisition), et ce via le protocole HTTP.
- Un nano‑ordinateur (carte Raspberry Pi ou autre) offre une solution économique, peu encombrante et polyvalente pour constituer un serveur web assez évolué.
- En effet, ce serveur peut être implémenté par un logiciel serveur HTTP classique (cf. infra ), s'exécutant sur un système d'exploitation en même temps que d'autres applications, notamment un logiciel de base de données. On peut donc mettre en place une architecture à 3 niveaux, voire plus.
- Si la capacité de stockage de la mémoire embarquée ne suffit pas, rien n'interdit de raccorder au nano‑ordinateur un disque dur externe.
- Un peu plus économique encore (financièrement et aussi énergétiquement), un carte à microcontrôleur (Arduino ou autre) équipée d'une interface réseau (module Ethernet, Wi‑Fi, etc.) permet également d'implémenter un serveur web, mais évidemment assez rudimentaire.
- Plus généralement, il existe toutes sortes de technologies de petit serveur web, qu'elles soient polyvalentes ou propriétaires, dans des domaines comme la domotique, la surveillance, et plus généralement l'Internet des objets W (Internet of things ou IoT).



Technologies logicielles des serveurs web
Architecture logicielle globale des serveurs web
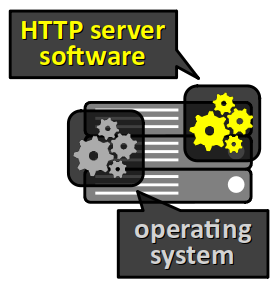
En règle générale, le système d'exploitation d'un serveur, même avec une conception spécifique, n'intègre pas de service par défaut pour répondre à des requêtes HTTP.
Pour qu'il devienne un server web, il faut préalablement installer et exécuter en tâche de fond un logiciel applicatif dédié qu'on appelle serveur HTTP (typiquement, Apache, NGINX ou autre…).
Par ailleurs, pour mettre en place une architecture à 3 niveaux, il faut aussi installer et exécuter en tâche de fond sur la machine d'autres logiciels.
- Il faut impérativement un environnement d'exécution de scripts W qui sont codés dans un langage de programmation généraliste dit de backend (php, JavaScript, Python, etc.).
- Il faut également installer un système de gestion de base de données W ou SGBD (en anglais, database management system ou DBMS), qui est le plus souvent installé et exécuté sur une machine serveur dédiée.
Comme pour toutes les technologies du web, il existe aujourd'hui une grande diversité des solutions logicielles pour implémenter les serveurs web. Sans que l'on puisse décréter que telle ou telle solution est meilleure qu'une autre, on peut néanmoins distinguer des tendances dans les usages à grande échelle, qui dessinent les technologies d'avenir et du passé. En avoir connaissance est utile à de futurs techniciens, pour investir judicieusement leurs efforts d'apprentissage. Toutes les sections suivantes du chapitre y sont consacrées.
Les systèmes d'exploitation des serveurs
Pour qu'une machine fasse fonction de serveur, on peut a priori s'appuyer sur n'importe quel système d'exploitation usuel, pour peu qu'il soit compatible avec l'architecture physique (processeur, mémoire, etc.) de la machine.
Toutefois, les versions « grand public » des systèmes Windows (Microsoft) et MacOS (Apple) ne disposent pas de mécanismes commodes pour la gestion des droits d'accès aux fichiers, gestion qui constitue un aspect primordial pour un serveur puisqu'il s'agit presque toujours d'une machine multi‑utilisateurs.


C'est pourquoi ces constructeurs proposent des versions spécifiques pour serveurs, respectivement Windows Server W et MacOs Server W. Comme les versions grand public, elles sont payantes, typiquement sur la base d'un abonnement annuel associé à un contrat d'assistance.

A contrario, toutes les distributions usuelles du système GNU/Linux W (et encore une fois, sous couvert de compatibilité matérielle) sont adaptées à une machine de type serveur parce qu'elles incluent une gestion des droits d'accès. Cette gestion est héritée du système Unix qui a été conçu dès le départ pour un contexte multi‑utilisateurs.
Parmi ces distributions, on en trouve W :
- une bonne partie – Debian, Fedora, Ubuntu, OpenSUSE… – qui sont gratuites et dites communautaires parce que développées et soutenues par une communauté d'utilisateurs qui peuvent apporter une aide significative à travers les forums de l'Internet ;
- les autres – Red Hat Enterprise Linux, Ubuntu Long Term Support, SUSE Linux Enterprise… – qui sont dites d'entreprise ; elles sont payantes mais elles incluent un contrat d'assistance.





Les distributions Linux communautaires restent dominantes dans l'univers des serveurs web du fait de leur gratuité.
Les logiciels serveurs HTTP
Un logiciel serveur HTTP est une application s'exécutant en tâche de fond sur une machine, typiquement pour que cette dernière constitue un serveur web.
La principale fonction de cette application est de générer les réponses aux requêtes émises par un client dans le cadre du protocole HTTP.
Dans la variété des logiciels serveurs HTTP, on trouve principalement, par ordre décroissant de fréquence d'emploi :
- Apache HTTP Server W et NGINX W qui sont l'un et l'autre libres de droits et open‑source.
- IIS W (Internet Information Services) qui est un logiciel propriétaire développé par Microsoft pour compléter ses systèmes d'exploitation Windows Server.



Avec une machine serveur à système d'exploitation Linux (cas le plus fréquent), l'installation en ligne de commande (sur la machine ou depuis une connexion distante de type ssh) d'un logiciel serveur HTTP ne pose pas de difficulté particulière, la procédure étant le plus souvent bien documentée – cf. par exemple ce lien pour l'installation du logiciel Apache sur une distribution Ubuntu et la mise en œuvre sur une carte Raspberry Pi au TP C2‑2 .
À titre de complément, on trouvera au lien suivant une vidéo (en anglais) qui explique les différentes fonctionnalités que peut mettre en œuvre un serveur NGINX Y. Y sont abordées notamment les notions de répartiteur de charge (load balancer) et de serveur mandataire (proxy).
Les piles virtuelles AMP pour le développement
Durant la phase de développement d'une application web (codage, mise au point…), il n'est pas nécessaire de disposer d'une véritable architecture 3 tiers. Sur un poste de travail, il est toujours possible de recourir à la virtualisation d'une telle architecture, intégrant toute la pile des composants logiciels nécessaires : serveur HTTP, langage de backend, SGBD.
Ces piles sont désignées de façon générique par le sigle AMP – en anglais, AMP stack, acronyme du triptyque Apache, MySQL et php (cf. une liste des piles les plus courantes au lien suivant W).
D'une pile AMP à une autre, certains composants logiciels peuvent être différents :
- en particulier, le logiciel de SGBD peut être MariaDB ou MongoDB et non pas MySQL ;
- de même, on peut avoir un langage de backend comme Perl ou Python inclus dans la pile en plus de php.
Lorsqu'une pile AMP s'exécute sur un poste de travail, elle opère une machine virtuelle sur l'hôte local pour jouer le rôle de serveur HTPP, d'environnement d'exécution d'un langage backend et d'un SGDB.
- Sur cette machine virtuelle, elle crée une arborescence de dossiers avec, typiquement, un dossier nommé
wwwdans lequel il est possible de déposer des fichiers de script pour implémenter une application web en développement. - Pour tester l'application, il suffit d'employer un navigateur avec une URL commençant par
localhost/.
Pile AMP pour les postes de travail Windows

Pour les postes de travail à système Windows, on peut par exemple installer le logiciel WampServer W, en téléchargeant son fichier d'installation (setup) à ce lien ) puis en l'exécutant une fois le téléchargement terminé.
Attention, cette installation nécessite quelques précautions préalables, en particulier la désactivation du serveur IIS (cf. supra ) qui est installé par défaut sur les systèmes Windows. Pour cela, il suffit de taper dans la barre de recherche du système l'expression :
Activer ou désactiver des fonctionnalités Windows
puis, après avoir cliqué sur ce raccourci, décocher l'option :
□ Instance principale web des Internet Information Services (IIS)
Après l'installation, il faut cliquer sur l'icône de l'application Wampserver apparue sur le bureau, qui se lance implicitement en tâche de fond. À droite dans la barre de tâche apparaît alors une icône avec le logo de l'application à droite — dit tray icon. Lorsque sa couleur verte, cela signifie que l'application est pleinement opérationnelle.
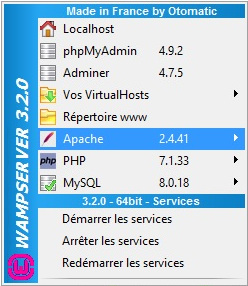
Ce tray icon donne un accès convivial à une cascade de menus pour :
- paramétrer les logiciels de la pile (Apache, php, MySQL et autres) ;
- alimenter les répertoires des fichiers, en particulier,
www directoryoù sont usuellement placés les fichiers des applications web (code HTML, php, etc.) ; - ouvrir la page d'accueil par défaut du serveur web (Localhost) dans le navigateur choisi par défaut.
Pile AMP pour les postes de travail Linux
Pour les postes de travail à système Linux, on peut bien sûr procéder à l'installation séparée des composants logiciels d'une pile AMP, en respectant un ordre précis.
On peut aussi installer un package intégré comme lamp‑server W, à condition qu'il soit adapté pour la distribution du système. Dans le cas d'une distribution de type Ubuntu – notamment Mint – on procède en ligne de commande simplement par :
sudo apt install lamp-server^ -y
- Une fois que l'installation est terminée, on peut vérifier que le serveur HTTP Apache s'exécute bien en tâche de fond :
systemctl status apache2
sudo systemctl, il peut être à tout moment arrêté (stop), démarré (start) ou redémarré (restart). xdg-open http://localhost
/var/www/html/
root. Sur le poste de travail, il doit donc être ouvert en tant que super‑utilisateur pour pouvoir être modifié. Pour éviter cette contrainte, il est évidemment possible d'en changer la propriété (et le groupe) de façon récursive (c'est‑à‑dire dans tout le sous‑arbre) par une commande de la forme : sudo chown -Ruser‑name:user‑name/var/www
Installation sur une machine de type serveur
L'installation d'un logiciel serveur HTTP sur une machine de type serveur ne présente pas de différences significatives avec celle d'une pile AMP dans le cas le plus usuel où on a une machine à système Linux et s'il s'agit du logiciel Apache. Pour les détails, on se reportera à la procédure décrite dans le sujet de travaux pratiques R2‑TP2 .
Cas particulier de la plateforme Node.js

La plateforme de développement Node.js (cf. infra ) qui met en œuvre un environnement d'exécution du langage JavaScript inclut aussi un composant logiciel serveur HTTP. Moyennant quelques lignes de code dans le fichier de script principal de l'application, il est ainsi possible, sur un poste de travail, de tester directement une application web codée en JavaScript côté serveur, même sans même avoir à recours à une pile AMP.
Les langages de backend et leurs frameworks
Généralités
Un langage de script backend est un langage de programmation qui permet de coordonner les tâches du serveur web pour répondre aux requêtes d'un client web, notamment :
- préparer les pages web en code HTML/CSS/JS à envoyer, à partir de fichiers existants ou composés sur mesure ;
- transmettre et collecter des données stockées dans diverses bases de données…
Pour être opérationnel, tout langage nécessite un environnement d'exécution installé et opérant en tâche de fond sur le serveur.
Là encore, il existe une grande variété de langages de script backend, chacun ayant des points forts et des points faibles. Le choix dépend du contexte (problématique générale, culture d'entreprise, tendance…). Son apprentissage demande à tout technicien un investissement de plusieurs années, qui ne doit pas être engagé à la légère.
Notion de framework
Avec la sophistication des applications web, le codage des scripts de backend devient rapidement complexe et lourd, aussi les communautés informatiques ont développé des frameworks W pour le développement web.
On désigne par ce terme anglais un ensemble structuré de bibliothèques de fonctions et d'autres éléments de code (types, constantes…) pour un langage donné.
Structuré pour une utilisation très modulaire, un framework de développement web comprend en général des fonctions puissantes pour créer des API W – application programming interfaces. Ces dernières doivent ensuite permettre de :
- récupérer les données des requêtes et générer les réponses pour le protocole HTTP ;
- générer des requêtes et récupérer les données des réponses en langage SQL vers une base de données ;
- transcoder des données entre différents formats (
csv,json,xml,html, etc.) ; - et bien d'autres actions…
Comme usuellement en programmation modulaire, une fonction dans un framework est présentée au codeur par son prototype (nom, arguments, valeur retournée — cf. chap. C4‑I C) et forme elle‑même une API (mais de moins haut niveau qu'une API développée à l'aide de cette fonction).
Pour une présentation plus détaillée des frameworks, on pourra consulter cette page web de la Fondation Mozilla .



Attention à ne pas confondre les frameworks avec ce qu'on appelle les CMS – ou content management system W – comme par exemple WordPress W, Drupal W, Joomla! W, etc.
Un CMS définit de nombreux éléments préformatés de mise en forme des pages web côté client. Il permet ainsi d'élaborer rapidement des sites web à partir de kits de conception personnalisables pour créer des forums, des blogs, des sites de commerce en ligne, etc.
Le langage php

Créé en 1994, le langage php W – hypertext preprocessor – est historiquement le premier et encore aujourd'hui de très loin le plus utilisé des langages de backend (environ 80 % des sites web l'utilisent).
Libre de droit et open‑source, l'environnement d'exécution de php se greffe très facilement à la plupart des logiciels serveur HTTP.

Comme bien d'autres, le langage php est un langage mixte interprété/compilé. Il est basé sur le logiciel Zend Engine W qui joue à la fois le rôle de compilateur en bytecode W et d'environnement d'exécution.
Avec une syntaxe et un typage inspirés du C, le langage php dispose :
- de tous les éléments de la programmation procédurale structurée (structures de contrôle, fonctions…) ;
- de la notion de classe, qui le rend apte à la programmation orientée objet ;
- d'un très grand nombre de bibliothèques de fonctions qui peuvent être incluses à volonté dans un fichier de code (comme en langage C) ; on peut ainsi mettre en œuvre une programmation modulaire.
Pour les débutants, le principal atout du langage php est de permettre l'insertion directe de code backend partout dans les fichiers HTML/CSS des pages web – grâce à la balise <?php ?>. Cela évite de devoir coder sous forme de chaînes de caractères le code HTML des pages web que le script est censé fournir ; il en résulte que certaines parties des fichiers php sont très semblables au code usuel qui implémente les pages web statiques.
Installation de l'environnement d'exécution de php
Rappelons que l'environnement d'exécution du langage php est inclus dans toute pile AMP. Sur un poste de travail, aucune installation supplémentaire n'est donc requise.
Pour une installation sur un serveur, on se reportera à la procédure décrite dans le sujet de travaux pratiques R2‑TP2 .
Exemple académique d'utilisation de php en backend

À titre d'illustration purement académique, le code php ci‑dessous, enregistré dans un fichier nommé changeBackground.php, crée une page web très simple avec deux balises de liens dynamiques permettant respectivement de choisir entre deux couleurs d'arrière‑plan (blanc ou jaune).
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Dynamic page PHP </title>
</head>
<?php
echo '<body style="background:' .
htmlspecialchars($_GET['bgcolor']) . '">';
?>
<h1> Dynamic page example with PHP (server side scripting) </h1>
<p>
<a href="./changeBackground.php?bgcolor=white">White</a>
<!-- 2 no-break-spaces here -->
<a href="./changeBackground.php?bgcolor=yellow">Yellow</a>
</p>
</body>
</html>
L'emploi du langage php apparaît seulement dans les lignes n° 8 à 11 qui codent une seule balise <?php ?> :
- Cette balise construit l'objet
bodyde la page sous la forme d'une chaîne de caractère par concaténation de 3 parties, sachant qu'en php, l'opérateur de concaténation est codé par le symbole.(point). - L'attribut de style CSS
backgroundde cet objet est introduit dans la 2e partie de la chaîne :
htmlspecialchars($_GET['bgcolor'])
via la conversion en chaîne de caractères de la valeur de variable spéciale$_GETà son index'bgcolor'.
$_GET permet de récupérer les valeurs des variables transmises dans les URL des requêtes adressées par le client au serveur. Avec seulement 22 lignes, ce code est presque aussi simple que celui proposé avec le langage JavaScript coté client (cf. chap. R2‑III ). Il peut être testé en plaçant son fichier directement dans le répertoire www d'une pile AMP et en ouvrant un navigateur avec l'URL :
localhost/changeBackground.php?bgcolor=white
Remarques.
- Dans la pratique, pour des fonctionnalités dynamiques simples comme ici, il ne fait aucun doute qu'on doit privilégier une solution côté client comme celle proposée avec JavaScript. Mais ici l'exemple est volontairement choisi pour sa simplicité, afin d'illustrer les mécanismes de communication entre le client et le serveur via des URL.
- Le code proposé ci‑dessus est certes efficace mais il manque de sûreté, puisqu'il injecte directement un champ d'URL dans le code HTML de la page web. Ainsi, il est possible de donner n'importe quelle couleur d'arrière‑plan à la page web, simplement en saisissant dans l'URL une valeur non attendue pour le champ
bgcolor, par exemple green :
localhost/changeBackground.php?bgcolor=green

background, typiquement :
<?php
if ($_GET['bgcolor'] == 'yellow')
echo "<body style='background: yellow'>";
else
echo "<body style='background: white'>";
?>
Frameworks du langage php
Parce qu'il est massivement employé depuis plus de 20 ans, le langage php peut aujourd'hui s'appuyer sur de nombreux frameworks pour le développement web – cf. la liste suivante W.





Parmi les plus populaires, on peut citer Laravel W, Symfony W, Zend Framework W (à ne pas confondre avec Zend Engine – cf. supra), CakePHP W, FuelPHP W…
Le langage JavaScript

Inventé en 1996, le langage JavaScript W est, on l'a vu, le principal langage de script pour le développement frontend (côté client) – cf. chap. R2‑III .
Mais depuis 2009, il peut aussi être employé pour le backend grâce à la plateforme Node.js W qui est libre de droit et open‑source :

Avec la plateforme Node.js, le langage JavaScript devient généraliste. Comme php :
- il adopte une syntaxe très similaire à celle des langages C/C++, en particulier pour les structures de contrôle et la ponctuation générale – avec néanmoins quelques subtiles différences ;
- multi‑paradigme, il est particulièrement bien adapté à la programmation orientée objet ; en particulier, il permet de décrire très facilement le DOM ou document object model d'une page web.
Employer JavaScript pour le codage coté serveur présente alors l'intérêt évident d'adopter le même langage de script que du coté client. Cela facilite le travail des codeurs qui, avec un seul langage, peuvent maîtriser l'ensemble de l'architecture d'une application. (On appelle développeur fullstack un codeur disposant de cette compétence.)
Installation de la plateforme Node.js
Dans le cadre du développement web sur un poste de travail, pour pouvoir tester localement des applications codées en JavaScript côté serveur, une procédure d'installation de la plateforme Node.js est préalablement nécessaire. En effet, elle n'est pas incluse dans les piles AMP.
De plus, cette installation peut être effectuée indépendamment de toute pile AMP.
- Avec un système Windows, on procède comme toujours en téléchargeant un installateur (setup) puis en suivant la procédure pas à pas. Cet installateur inclut le gestionnaire de paquet npm, qui n'a donc pas besoin d'être installé séparément.
- Avec un système Linux, on procède dans un terminal de commandes en fonction de la distribution (cf. cette page officielle ).
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.7/install.sh | bashnvm list-remote
nvm install v20.11.1
Une fois l'installation effectuée, quel que soit le système, on peut consulter les numéros de versions en saisissant dans un terminal la commande :
node -v && npm -v
On peut également vérifier que l'environnement d'exécution est opérationnel en saisissant la commande node. Le terminal devient alors un interpréteur de commandes JavaScript, comme le montre par exemple la sortie d'exécution ci‑dessous :
nodeWelcome to Node.js v16.13.1. Type ".help" for more information.console.log("Hello World!")Hello World!undefined(To exit, press Ctrl+C again or Ctrl+D or type .exit)
Exemple académique d'utilisation de JavaScript en backend
À titre d'illustration purement académique, et dans la continuité de l'exemple proposé pour le langage php (cf. supra ), le code JavaScript ci‑dessous, enregistrée dans un fichier nommé changeBackground.js, crée la même page web très simple avec deux balises de liens dynamiques permettant respectivement de choisir entre deux couleurs d'arrière‑plan (blanc ou jaune).
var http = require("http");
var url = require("url");
var querystring = require("querystring");
var callback = function(request, result)
{
result.writeHead(200, {"Content-Type": "text/html"});
var query = querystring.parse(url.parse(request.url).query);
result.write(
"<!DOCTYPE html>" +
"<html>" +
"<head>" +
"<meta charset='utf-8'>" +
"<title>Dynamic page server JS </title>" +
"</head>" +
"<body style='background:" + query['bgcolor'] +"'>" +
"<h1> Dynamic page example with server side JS </h1>" +
"<p><a href='./changeBackground.js?bgcolor=white'>White</a>" +
" " +
" <a href='./changeBackground.js?bgcolor=yellow'>Yellow</a></p>" +
"</body>" +
"</html>"
);
result.end();
}
var serveur = http.createServer(callback);
serveur.listen(8080); // port number
Avant de décrire en détail ce code, remarquons que sa structure est très différente de celle du code en langage php pour la même page web. Il consiste essentiellement en la définition, à partir de la ligne n° 5, d'une fonction de callback W, qui est destinée à être appelée à chaque fois que le serveur reçoit une requête HTTP – le rôle de cette fonction étant de générer la réponse HTTP (cf. chap. R2‑III ).
Voyons maintenant comment est codée cette fonction de callback :
- En ligne n° 7, l'appel de la méthode
writeHeadgénère la ligne initiale de la réponse HTTP, avec le code de statut200(succès) et le type de contenutext/htmldu corps de la réponse. - En ligne n° 8, l'appel de la méthode
parsepermet la récupération des données contenues dans la requête (composantes query) et leur sauvegarde dans une variable nomméequery, implicitement de type tableau. - En lignes n° 9 à 22, l'appel de la méthode
writegénère le code HTML de la page web sous la forme de concaténations successives de chaînes de caractères – opérations codées par le symbole+. - Dans la balise
<body></body>vient s'insérer la valeur de l'attribut de stylebackgroundde l'objetbodysous la forme du champbgcolorextrait de la variablequery(ligne n° 16). - Et comme dans le code en php, la valeur de ce champ
bgcolorapparaît dans la partie requête des URL codées pour les attributs href respectives des balises<a></a>(lignes n° 18 et 20).
Grâce aux lignes n° 27 et 28 du code ci‑dessus, on le peut tester même sans disposer d'un serveur web ni d'une pile AMP (mais à condition d'avoir installé sur le poste de travail la plateforme Node.js – cf. supra ). Il suffit alors simplement :
- de saisir dans un terminal de commandes en ligne :
node changeBackground.js
http://localhost:8080. De plus, en cas de modification du fichier de code .js, il est nécessaire de relancer la commande node (après une annulation par Ctrl-C) avant de recharger la page dans le navigateur.
Remarques.
- Là encore, pour des fonctionnalités dynamiques aussi simples, la solution avec JavaScript côté client proposée au chap. R2‑III est évidemment bien plus efficace. La motivation d'une solution côté serveur reste ici purement pédagogique.
- Comme pour la solution codée en php (cf. supra ), il est déconseillé d'injecter directement la valeur d'un champ d'URL dans le code HTML de la page (cf. ligne n° 16. Il est préférable d'opérer par une variable intermédiaire et une structure de contrôle en ajoutant sous la ligne n° 7 les deux lignes de code ci‑dessous :
var backgroundColor = "white"; if (query['bgcolor'] == "yellow") backgroundColor = "yellow";
"<body style='background:" + backgroundColor +"'>" +
Frameworks du langage JavaScript coté serveur
Rappelons que JavaScript est avant tout le principal langage de script pour le codage des pages web côté client, et ainsi en va‑t‑il de ses frameworks les plus populaires (Angular, React, etc.) – cf. chap. R2‑III .



Mais également, de nombreux frameworks ont également été développés pour JavaScript lorsqu'il est employé côté serveur. On peut en particulier citer Express.js W, Next.js W et Meteor W.
Les langages C/C++ (pour sites web embarqués)
Pour coder un site web embarqué sur une carte à microcontrôleur, il n'y a pas d'autre alternative que d'utiliser le langage de programmation du microcontrôleur – à savoir presque toujours C ou C++.
Ces langages ont été présentés en détail au chap. C1‑II C. Quelques points restent ici à souligner.
- C et C++ sont des langages généralistes. Ils permettent donc de coder n'importe quelle application, y compris une application web. Mais ils ne sont pas optimisés pour cela (surtout C) et dans la pratique, on privilégie plutôt d'autres langages (Python, Ruby, Perl, etc.). On trouve néanmoins quelques frameworks de développement web ont été créés pour C++.
- C et C++ sont des langages compilés, ce qui confère à leurs programme une grande rapidité d'exécution et ce dans un environnement minimal (aucune machine virtuelle n'est requise, ni interpréteur s'exécutant en tâche de fond).
Il s'agit encore d'une illustration purement académique, en continuité avec les exemples proposés supra pour php et JavaScript .
Le code C++ ci‑dessous, enregistré dans un fichier nommé changeBackground.ino est conçu pour être embarqué sur une carte Arduino équipé d'un shield Ethernet. Il en fait un serveur de la même page web très simple avec deux balises de liens dynamiques permettant respectivement de choisir entre deux couleurs d'arrière‑plan (blanc ou jaune).
#include <SPI.h>
#include <Ethernet.h>
const int SPI_ETHERNET_PIN = 10; // pin number on board
byte mac[] = {0x90, 0xA2, 0xDA, 0x0D, 0x15, 0x43};
EthernetServer server(80);
const char PAGE_HEAD[] = R"=====(
<!DOCTYPE html>
<html lang='fr'>
<head>
<meta charset='utf-8'>
<title>Dynamic page Arduino</title>
</head>
)=====";
const char PAGE_TAIL[] = R"=====(
<h1> Dynamic page example embedded on Arduino board </h1>
<p><a href='./?bgcolor=white'>White</a>
<!-- 2 non‑break spaces here as inter-margin -->
<a href='./?bgcolor=yellow'>Yellow</a></p>
</body>
</html>
)=====";
void setup()
{
Ethernet.init(SPI_ETHERNET_PIN);
Ethernet.begin(mac);
// Serial.begin(115200); // only for debug
}
void loop()
{
EthernetClient client = server.available();
if (client) {
String clientRequest = "";
while (client.connected() && client.available()) {
// read request characters 1 by 1
char c = client.read();
clientRequest += c;
// Serial.write(c); // only for debug
// only the first line of the request is needed
if (c == '\n') {
// send response to the client
client.println("HTTP/1.1 200 OK");
client.println("Content-Type: text/html");
client.println(); // blank line (\n\r)
// start of response body
client.println(PAGE_HEAD);
if (clientRequest.indexOf("bgcolor=yellow") > 0) {
client.print("<body style='background: yellow'>");
}
else {
client.print("<body style='background: white'>");
}
client.print(PAGE_TAIL);
// end of response body
delay(1); // give the web browser time to receive the data
client.stop();
break;
}
}
}
}
Évidemment, ce code C++ est beaucoup plus long que dans les exemples précédents, puisque le système embarqué doit tout prendre en charge (connexion au réseau, etc.) sans s'appuyer sur un système d'exploitation. Néanmoins, ce code reste d'une complexité raisonnable car il s'appuie sur le module de bibliothèque Arduino Ethernet.h avec de nombreuses fonctions de haut niveau prêtes à l'emploi. En particulier, la connexion Ethernet au réseau local en mode DHCP peut très facilement se coder, comme expliqué au chap. R2‑II .
Dans son principe, ce code C++ peut être comparé à celui composé en JavaScript, puisqu'il consiste essentiellement à générer des réponses HTTP aux requêtes d'un client.
Mais ici, le code HTML de la page web qui sera inséré dans le corps de la réponse est préalablement déclaré sous la forme de deux chaînes de caractères brutes (d'où le préfixe R pour raw – cf. chap. C5‑VI ). Elles apparaissent respectivement aux lignes n° 10 (PAGE_HEAD) et 19 (PAGE_TAIL). L'usage des chaînes brutes facilite l'édition du code, qui peut même être déporté dans des fichiers séparés et insérés dans le code via des directives d'inclusion.
Tout d'abord, le programme consiste à attendre la requête d'un client et à déclarer un objet nommé client de la classe EthernetClient en lui affectant le nombre d'octets disponibles en lecture retournés par la méthode available(ligne n° 39).
Ensuite, dans le cas d'une requête à traiter, le programme effectue les actions suivantes :
- Il mémorise dans une chaîne de caractère nommée
clientRequestles caractères de la première ligne de la requête (lignes n° 44 & 45). - Lorsque cette première ligne de la requête est mémorisée (caractère newline
'\n'détecté – cf. ligne n° 46), le programme génère une réponse en commençant par composer par appels successifs de la méthodeclient.println(distincte de celle l'objetSerial) : - la ligne initiale avec le code
200de succès (ligne n° 51) ; - l'en‑tête
Content-Typeavec la valeurtext/html(ligne n° 52) ; - la ligne vide séparant les en‑têtes du corps de la réponse (ligne n° 50) ;
- dans le corps de la réponse, le début de la page web mémorisé dans la chaîne de caractères brute
PAGE_HEAD(ligne n° 56). - Ensuite, le programme teste si la chaîne
clientRequestcomporte la sous‑chaîne"bgcolor=yellow"à l'aide de la la méthodeindexOfde la classeStringen C++ (ligne n° 57). - si tel est le cas, le programme ajoute dans le corps de la réponse l'objet
bodyavec l'attribut de stylebackground: yellow(ligne n° 58) ; - et sinon, il fait la même chose mais avec la valeur par défaut
background: white(ligne n° 61). - Pour finir, le programme termine le corps de la réponse avec la fin de la page web mémorisée dans la chaîne de caractères brute
PAGE_TAIL(ligne n° 63).
?bgcolor – est incluse dans la cible de la requête, donc sans la première ligne (1er en‑tête – cf. chap. R2‑III ). Pour tester ce programme, il suffit :
- bien évidemment, de téléverser le programme sur la carte raccordée au réseau local du poste de travail ;
- de scanner le réseau pour déterminer l'adresse IP allouée au shield Ethernet par le serveur DHCP local ;
- d'ouvrir la page web avec un navigateur en saisissant URL :
http://adresse IP du shield
Remarque. Dans le framework Arduino, on ne trouve pas de fonction puissante d'analyse du texte de la requête du client, comme parse en JavaScript, ni de variable structurée comme $_GET en php.
Autres langages de backend
Le langage Java

Inventé en 1995, Java W est un langage de programmation généraliste qui permet de pré‑compiler des programmes en bytecode s'exécutant via une machine virtuelle (Java runtime environment W ou JRE), le rendant potentiellement portable sur toute architecture pour laquelle une telle machine virtuelle est développée.
Utilisable dans les pages web côté client pour créer des applets (cf. chap. R2‑III ), le langage Java est donc aussi utilisable côté serveur, où l'on parle alors de servlets W.
Le langage Java est également directement utilisable dans des pages de code HTML par la technique des JavaServer Pages W.
Parmi les frameworks de Java W utilisés pour le backend, on peut citer Apache Struts W, Play W, Spring W, Hibernate W…

À l'origine, Java était un projet open source développé au sein de la société californienne Sun microsystems (constructeur de serveurs et de stations de travail, mais aussi développeur du système d'exploitation Unix Solaris).

Le langage C#

Inventé en 2001, C# W est un langage de programmation généraliste. Comme Java, il procède par pré‑compilation de composants dans un langage intermédiaire (CIL ou Common intermediate language W). Ce code est ensuite interprété dans un environnement d'exécution communément appelé la plate‑forme .NET W et basée sur les systèmes d'exploitation Windows.

Pour le développement web côté serveur, le codeur en langage C# peut s'appuyer sur un très gros framework nommé ASP.NET W. Il permet d'insérer des appels de code source C# dans un fichier de code HTML, notamment par l'intermédiaire de widgets W appelés Web controls.
Le langage Python

Inventé en 1991, Python W est un langage de programmation interprété et généraliste, placé sous licence libre. Universellement employé dans les systèmes d'exploitation (ordinateurs, smartphones), son interpréteur y est presque toujours déjà installé.
Apprécié pour sa syntaxe légère mais explicite, Python dispose d'un très grand nombre de bibliothèques spécialisées, notamment dans les domaines du calcul scientifique, de l'intelligence artificielle, du traitement massif des données (data science).
On peut aisément vérifier qu'un interpréteur Python 3 est installé sur une machine en saisissant dans un terminal de commandes en ligne :
-
which python3avec un système Linux ; -
where python3avec un système Windows.
Et pour l'anecdote, dans la marque Raspberry Pi, le terme « Pi » fait référence à Python interpreter.

De part sa popularité, Python est beaucoup utilisé pour le développement web côté serveur. Divers frameworks existent, parmi lesquels on peut notamment citer Django W.
Les bases de données
Généralités
Notion de base de donnée
La plupart des applications web manipulent un très grand nombre de données. C'est notamment le cas :
- de tout site commercial, qui fait appel à son « fichier » de clients enregistrés, son catalogue de produits, ses listes de promotion, etc. ;
- de tout site administratif (médical, fiscal, etc.) avec là encore des usagers enregistrés dont il faut mémoriser toutes les informations ;
- de tout site d'information (média en ligne) qui permet d'accéder à l'historique de ses publications…
Or ces données sont souvent utilisées par d'autres applications informatiques, typiquement des progiciels de gestion intégrés W. Elles ne peuvent donc pas être codées directement dans les fichiers des pages web. En effet :
- ce serait presque toujours techniquement infaisable en raison du trop grand nombre de données (il en résulterait des fichiers de code HTML immenses) ;
- cela reviendrait à les dupliquer par rapport à leur format d'origine, avec tous les problèmes de mise à jour que cela induirait ;
- cela rendrait leur accès particulièrement malcommode dans l'application web (avec notamment la difficulté à effectuer des tris dans un format qui n'est pas prévu pour cela).
Pour stocker des données en grand nombre, on emploie une structure informatique dédiée appelée base de données, en abrégé BDD W – en anglais, database, en abrégé DB. Dans une telle structure :
- les données – en anglais, data, qui est un pluriel – sont numérisées dans des fichiers sous un format binaire (et non pas sous forme de texte) ;
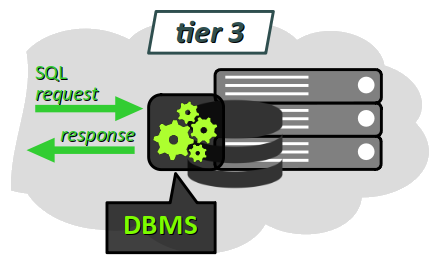
- l'accès aux données en lecture et écriture n'est possible que via une application spécifique, appelée système de gestion de base de données ou SGBD W – en anglais, database management system, abrégé DBMS.
Les formats binaires des fichiers de données incluent des systèmes d'indexation complexes qui optimisent les temps d'accès. Ils sont « incompréhensibles » pour un utilisateur, à l'instar du code exécutable d'un programme compilé. Ils ne doivent en aucun cas être accédés autrement que par le SGBD, au risque sinon de corrompre la base de données dans son ensemble.
Le SGBD est donc un logiciel incontournable tant pour la création que la manipulation d'une base de données. En contre‑partie, il apporte des fonctionnalités beaucoup plus performantes que celles que l'on pourrait mettre en œuvre avec de simples fichiers, même au format csv, json ou autre…. En particulier, on peut effectuer :
- des requêtes multi‑critères complexes, associées à des fonctions de tri ;
- des accès multi‑utilisateurs avec gestion des droits, systèmes de verrouillage sécurisant les opérations de lectures (éventuellement simultanées) et d'écriture, journalisation des transactions et reprise en cas d'écriture interrompue par une panne pour ne pas corrompre les données, etc.
Par ailleurs, il existe différents modèles de bases de données, car la question cruciale de la structuration des données se pose différemment selon les domaines (commercial, scientifique, administratif, géographique, etc.). Néanmoins, le modèle de loin le plus répandu est celui de la base de donnée relationnelle, étudié ci‑après. On parle alors de SGBDR pour désigner son logiciel de gestion.
Technologie matérielle
Comme le langage de backend, la mise en œuvre d'une base de donnée nécessite une machine de type serveur, avec ici la spécificité de requérir un grand volume de stockage (cf. chap. R2‑V ).
Lorsque cela est possible, il est plus simple d'installer la base de données sur la même machine que celle où s'exécute le serveur HTTP et le langage de backend. Mais il est tout à fait usuel d'employer une machine différente, éventuellement située sur un site distant. Il faut alors en paramétrer les accès.
L'univers des bases de données
Les bases de données constituent un domaine de l'informatique à la fois très vaste et très complexe. Avec l'essor du big data W, il n'a cessé de gagner en importance stratégique.
Le marché des SGBD est principalement dominé par l'entreprise californienne Oracle W qui distribue :
- Oracle Database W, logiciel propriétaire et payant destiné aux grandes entreprises et organisations ; il en existe aussi une version gratuite mais limitée en termes de volume (12 Go), dite express edition .
- MySQL W, logiciel initialement libre et open source, acquis par Oracle via le rachat de la société Sun microsystems (cf. supra ) ; il reste aujourd'hui disponible gratuitement.



Depuis son acquisition par Oracle, le principal créateur de MySQL, Mickael Widenius W, en a développé un fork W libre et open-source, appelé MariaDB W. Ce SGBDR est désormais adopté par défaut sur la plupart des systèmes Linux.
Par ailleurs, parmi les grands acteurs du marché, on peut également citer Microsoft et ses logiciels propriétaires :


Base de données relationnelle
Une base de donnée relationnelle W (en anglais, relational database) est une base de données dans laquelle les données sont structurées sous forme de tableaux à deux dimensions, qu'on appelle tables. Dans une table :
- chaque ligne est appelée un enregistrement (en anglais, record) dans la base,
- chaque colonne est appelée un attribut d'enregistrement (en anglais, attribute),
de sorte qu'un enregistrement met en relation toutes les valeurs des attributs – qu'on appelle aussi champs – enregistrées dans une même ligne (cf. la figure ci‑dessous).

Une base de données peut contenir plusieurs tables, et il est alors possible d'établir des relations entre les différentes tables (relations historiques, hiérarchiques, etc.).
Installation d'un SGBDR (MySQL ou MariaDB)
Rappelons qu'un SGBDR comme MySQL ou MariaDB est nécessairement inclus dans toute pile AMP. Sur un poste de travail doté d'une telle pile, aucune installation supplémentaire n'est donc requise.
Pour une installation sur un serveur, on se reportera à la procédure décrite dans le sujet de TP R2‑2 .
Sur une machine à système Linux, dans le cas des SGBDR comme MySQL ou MariaDB, les fichiers de stockage de données sont placés dans le répertoire :
/var/lib/mysql
et il faut les droits d'administration pour y accéder. Rappelons qu'il faut surtout ne pas tenter de modifier ces fichiers.
Notion de moteur de stockage
Dans une base de données relationnelle, toute table est définie avec un certain nombre de caractéristiques, typiquement son nom et son nombre d'attributs, mais aussi des aspects plus techniques comme son moteur de stockage W – encore appelé moteur de base de données (en anglais, storage engine ou database engine).
En règle générale, tout SGBDR intègre plusieurs moteurs de stockage – cf. la liste au lien suivant W. Le choix d'un moteur est une question très technique qui détermine les méthodes de stockage et d'accès aux données, avec à la clef divers niveaux de garanties d'intégrité et de sécurité de la base.
Sans entrer dans les détails, dans le cadre d'une pratique débutante, retenons simplement :
- qu'il est recommandé d'utiliser le même moteur de stockage pour toutes les tables de la base, sinon le SGBDR devra partager la mémoire qui lui est allouée entre les différents moteurs choisis ;
- qu'il est recommandé de privilégier un moteur dit transactionnel comme innoDB W – c'est d'ailleurs la solution par défaut dans MySQL – plutôt qu'un moteur « historique » comme MyISAM W.
Encodage des caractères – notion d'interclassement
Presque toujours, une base de données inclut des données de type chaîne de caractères ou texte. Se pose alors évidemment la question du choix de l'encodage des caractères (ASCII, UTF‑8 ou autre – cf. les chap. C3‑VIII C et C3‑IX C).
Par ailleurs, lors du traitement des requêtes, les recherches et les opérations de tri peuvent être grandement facilitées si les majuscules, les minuscules (la casse) et les variantes accentuées d'une même lettre ne sont pas différenciées. En effet, lorsqu'un utilisateur effectue une recherche sur un site, il ne saisit pas forcément ses mots‑clefs avec l'orthographe exacte (par exemple, « noel » au lieu de « Noël ») ; un algorithme de recherche sera apprécié s'il est quand même capable de trouver les ressources correspondantes. C'est ici qu'intervient la notion d'interclassement qui permet à l'administrateur de la base de choisir la souplesse requise.
Dans une base de donnée, l'interclassement (en anglais, collation) définit des relations de précédences et d'égalités entre les caractères dans un jeu de caractères. Implicitement, il spécifie l'encodage des caractères utilisés pour exprimer les champs de types chaînes de caractères ou texte dans la base.
L'interclassement peut être choisi différemment pour chaque table ou même pour chaque attribut.
Par défaut, pour des applications générales, il est vivement recommandé de choisir un interclassement indifférent à la casse (case insensitive) et basé sur le format UTF‑8 général, qui offre le catalogue Unicode dans son intégralité tout en optimisant l'espace mémoire utilisé (cf. chap. C3‑IX C).
Mais on peut être amené à faire d'autres choix dans des cas particuliers, si les champs de types chaînes de caractères sont composés dans un jeu de caractères plus restreint. De telles décisions deviennent d'autant plus pertinentes que la taille de la base de données augmente.
Caractéristiques des attributs d'une table
Dans une table de base de données, chaque attribut est défini par deux caractéristiques impératives : son nom et son type de valeurs – à savoir entier, décimal, chaîne de caractères, type énuméré… comme dans un langage de programmation.
De plus, pour des attributs de certains types, d'autres caractéristiques peuvent devoir être définies, notamment la taille dans le cas d'une chaîne de caractères (c'est‑à‑dire sa longueur maximale).
Pour chaque attribut d'une table, il est également possible de choisir un interclassement spécifique, d'imposer une valeur par défaut, d'autoriser ou non la valeur nulle, etc.
Notion de clef primaire
Dans une table de base de données, il peut arriver incidemment que deux enregistrements aient tous leurs champs respectivement identiques. Une telle situation peut évidemment engendrer des confusions désastreuses donc il est nécessaire de s'en prémunir.
À toute table, il est possible d'ajouter une clef primaire W (en anglais, primary key), c'est‑à‑dire un attribut d'identification, dont le SGBD garantit qu'il prendra une valeur différente pour chaque enregistrement.
Typiquement, il peut s'agir un nombre entier incrémenté à chaque nouvel enregistrement.
Exemple d'une table de base de donnée relationnelle
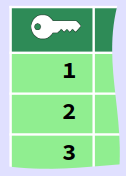
À titre académique, considérons une table permettant de stocker des couleurs définies par le code RGB W. Une telle table peut être structurée avec 5 colonnes :

- une colonne nommée
idpour la clef primaire sous la forme d'un entier non nul incrémenté à chaque nouvel enregistrement ; - une colonne nommée
colorNamepour le nom de couleur sous la forme d'une chaîne de caractères de longueur maximale 64 caractères (ce qui est largement suffisant) ; - trois colonnes nommées respectivement
redCode,greenCodeetblueCode, pour les codes des composantes RGB, sous la formes d'entiers non signés de taille 8 bits ;
Manipulation d'une base de donnée relationnelle – le langage SQL
Comme avec la plupart des structures informatiques, toute manipulation d'une base de données – création, suppression, enregistrement, consultation, etc. – peut être effectuée :
- soit dans un terminal de commandes en ligne, à l'aide d'un langage dédié, qu'il évidemment possible d'employer pour composer une série de commandes dans un fichier de script à exécuter d'une traite ;
- soit dans une interface fenêtrée, avec des champs de saisie à valider par clic sur tel ou tel bouton ;
Et bien entendu, une interface fenêtrée n'est jamais qu'une apparence conviviale qui opère elle‑même les commandes en ligne correspondant aux manipulation effectuées, pour rendre ce travail accessible à des utilisateurs non expérimentés en codage.
Pour manipuler les bases de données relationnelles, il existe un langage nommé SQL W – sigle qui signifie structured query language.
Créé en 1974 au sein de l'entreprise américaine IBM, il est régi par la norme ISO/CEI 9075 depuis 1987.
SQL est un langage de haut niveau pour coder des requêtes sur une base de données relationnelle. Il ne présuppose pas comment ces requêtes sont mises en œuvre.
Fondamentalement, il doit être considéré comme un langage interprété, un interpréteur étant intégré à tout SGBDR qui fournit ainsi une implémentation du langage SQL. Et dans la pratique, comme pour la plupart des langages interprétés, les instructions peuvent être compilées à la volée en bytecode avant d'être exécutées (cf. chap. C1‑I C).
La grande majorité des SGBDR emploie un langage qui respecte la norme de SQL et en constitue une extension, notamment pour permettre la programmation procédurale (cf. chap. C1‑I C). On peut ainsi coder des fonctions et procédures SQL et les regrouper en modules stockés dans le SGBDR. C'est notamment le cas du langage SQL/PSM W (pour persistent stored modules) qui est intégré aux logiciels de la famille MySQL.
Les composantes du langage SQL
Dans le langage SQL, on peut distinguer quatre composantes :
- Le data definition language W ou DDL est dédié à la manipulation des bases de données et des tables – création, modification, suppression, etc. – mais pas des données elles‑mêmes.
- Le data manipulation language W ou DML est dédié à la manipulation des données dans les tables – ajout d'un enregistrement, consultation ciblée, recherche, etc.
- Le data control language W ou DCL est dédié au contrôle d'accès aux données – autorisation, interdiction, verrouillage, etc.
- Le transaction control language W ou TCL est dédié au contrôle des transactions – validation, annulation, etc.
CREATE, ALTER, DROP, etc. SELECT, INSERT, UPDATE, DELETE, etc. GRANT, DENY, LOCK, etc. COMMIT, SAVEPOINT, ROLLBACK, etc. Paramétrage et lancement de l'environnement d'exécution d'un SGBDR
Pour pouvoir agir sur une base de donnée via des requêtes SQL, il est nécessaire de lancer l'environnement d'exécution du SGBDR. Une telle action s'apparente à une connexion avec une étape d'authentification par identifiant et mot de passe.
Préalablement, il est nécessaire de paramétrer le SGBDR pour définir l'utilisateur par défaut (typiquement, le compte root) et faire divers choix de sécurité.
Sous Linux, dans le cas des SGBDR comme MySQL ou MariaDB, le paramétrage peut être effectué par une commande spécifique prédéfinie qu'on peut exécuter dans un terminal de commande en ligne :
sudo mysql_secure_installation
Attention ! Sous MariaDB, le nom de la commande utilise des tirets courts - à la place des tirets bas _.
sudo mariadb-secure-installation
Pour plus de détails sur cette commande, on pourra consulter le sujet de TP R2‑2 .
Ensuite, en optant pour les choix usuels, il est possible de lancer l'environnement d'exécution du SGBDR avec le compte root et une authentification par mot de passe, en saisissant la commande :
sudo mysql -u root -p
Attention, il est possible que deux mots de passe soient successivement demandés :
- d'abord celui du compte Linux pour l'emploi de la commande
sudo; - ensuite celui du compte
rootdu SGBDR.
Il faut ne pas les confondre.
Remarque. Même en ayant installé MariaDB, on peut employer la commande historique mysql. En effet, elle est installée comme lien symbolique vers l'exécutable mariadb placé dans le même répertoire /usr/bin.
Si l'authentification est réussie, l'invite de commande change et devient :
mysql>
Règles de syntaxe et conventions de codage en langage SQL
Le codage des requêtes en langage SQL obéit à des règles de syntaxe dont certaines sont spécifiques à chaque implémentation. C'est notamment le cas des types de guillemets à employer pour délimiter les identificateurs choisis par le codeur.
Parmi ces règles, deux sont très utiles à connaître pour bien débuter avec des SGBDR comme MySQL ou MariaDB :
- Par défaut, le délimiteur de fin d'instruction est le symbole
;(comme dans de nombreux langages de programmation). - Tout identificateur de table ou de colonne doit être délimité par une paire de guillemets simples obliques
` `(en anglais, backtips ou backquotes ).
DELIMITER. Par ailleurs, il existe des conventions de codage qui sont très différentes de celles employées avec les langages de programmation usuels (C, Python, JavaScript, etc.).
Bien entendu, les conventions de codage ne doivent pas être confondues avec les règles de syntaxes, mais leur respect est néanmoins vivement recommandé, surtout dans le cadre d'un travail d'équipe.
En particulier, en langage SQL, il est d'usage de saisir tous les mots‑clefs du langage tout en majuscules. Quant aux identificateurs choisis par le codeur, ils peuvent adopter une typographie camelCase ou snake_case (cf. chap. C2‑X C) mais ne doivent évidemment pas être codés en tout en majuscules.
Exemple de création d'une base de donnée et d'une table avec MariaDB
Partons de l'exemple académique supra d'une table pour stocker des couleurs préférées définies par leur nom et leur code RGB. Le script SQL ci‑dessous code :
- la création d'une base de donnée nommée
userPref(pour préférences de l'utilisateur) ; - dans cette base de données, la création d'une table nommée
favoriteColors(pour couleurs préférées), comportant les cinq colonnes identifiées précédemment.
CREATE DATABASE IF NOT EXISTS `userPref`; USE `userPref`; CREATE TABLE IF NOT EXISTS `favoriteColors` ( `id` INT NOT NULL, `colorName` VARCHAR(64) NOT NULL, `redCode` TINYINT UNSIGNED, `greenCode` TINYINT UNSIGNED, `blueCode` TINYINT UNSIGNED ) AUTO_INCREMENT = 1; ALTER TABLE `favoriteColors` ADD PRIMARY KEY (`id`); ALTER TABLE `favoriteColors` MODIFY `id` INT NOT NULL AUTO_INCREMENT;
Sous un SGBDR comme MariaDB ou MySQL, ce script – enregistré dans un fichier tableCreation.sql – peut être exécuté par la commande :
mysql> source tableCreation.sql
à condition que ce fichier soit enregistré dans le répertoire courant d'exécution du terminal de commandes en ligne avant le lancement de l'environnement d'exécution du SGBDR – sinon, il faut saisir son chemin absolu ou son chemin relatif depuis le répertoire courant.
On obtient alors en sortie les messages d'acquittement du SGBDR pour les différentes requêtes SQL exécutées du script :
Query OK, 1 row affected (0,01 sec)
Database changed
Query OK, 0 rows affected (0,04 sec)
Query OK, 0 rows affected (0,08 sec)
Records: 0 Duplicates: 0 Warnings: 0
Query OK, 0 rows affected (0,07 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql>
Une fois que cette table est créée, il est possible d'insérer un nouvel enregistrement par une requête SQL. Par exemple, on peut enregistrer une couleur ayant pour nom mediumyellow et pour code RGB (255, 255, 128) – via la requête :
mysql> INSERT INTO `favoriteColors` (colorName, redCode, greenCode, blueCode) VALUES ("mediumyellow", 255, 255, 128);
Query OK, 1 row affected (0,01 sec)
L'interface d'administration phpMyAdmin

phpMyAdmin est une application web qui fournit une interface fenêtrée d'administration de bases de données, compatible avec les SGBDR MySQL et MariaDB. Elle est opérationnelle dans l'environnement d'un serveur web et du langage php.
L'application phpMyAdmin est intégrée à WampServer (logiciel d'émulation de pile AMP pour les systèmes Windows – cf. supra ).
En revanche, elle n'est pas incluse dans la plupart des piles AMP pour les systèmes Linux. Il faut donc procéder à son installation et pour cela, on pourra se reporter à la procédure décrite dans le sujet de TP R2‑2 .
Une fois l'installation achevée, l'accès à l'application est possible dans n'importe que navigateur via l'URL :
http://localhost/phpmyadmin
Page d'accueil
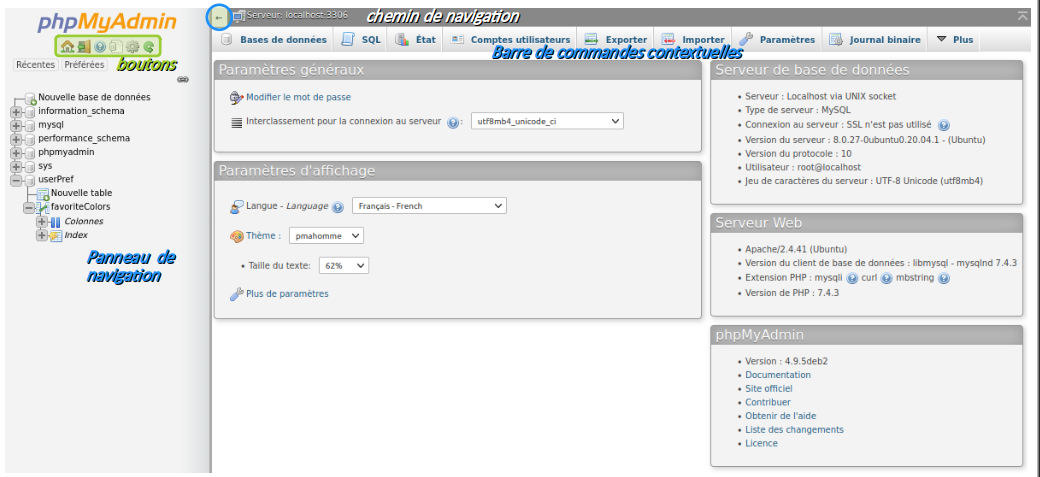
Après avoir renseigné et validé les identifiants de connexion au SGBDR (cf. supra ), on aboutit à la page d'accueil nommée index.php de phpMyAdmin dont la capture d'écran ci‑dessous donne un aperçu.
À partir de cette page, l'accès aux bases de données enregistrées avec le SGBDR peut se faire :
- soit via le panneau de navigation de navigation, qui se présente comme un explorateur dans une arborescence, où chaque identificateur affiché est un hyperlien ;
- soit via le premier bouton de la barre de commande.
userPref et sa table favoriteColors créées précédemment ) ; Lorsqu'on sélectionne une base ou une table, l'interface affiche dans le bandeau gris supérieur le chemin dans l'arborescence.

Par ailleurs, on trouve en haut du panneau de navigation – juste en dessous du logo de l'application – des boutons de raccourcis, respectivement :
- de retour à la page d'accueil ;
- de déconnexion ;
- d'accès aux pages de documentation interne et externe ;
- de paramétrage du panneau de navigation ;
- de rafraîchissement du panneau de navigation.
Page de manipulation d'une table
Dans le panneau de navigation, lorsqu'on clique sur l'hyperlien d'une table, le navigateur ouvre une page de manipulation dont la capture d'écran ci‑dessous donne un aperçu.
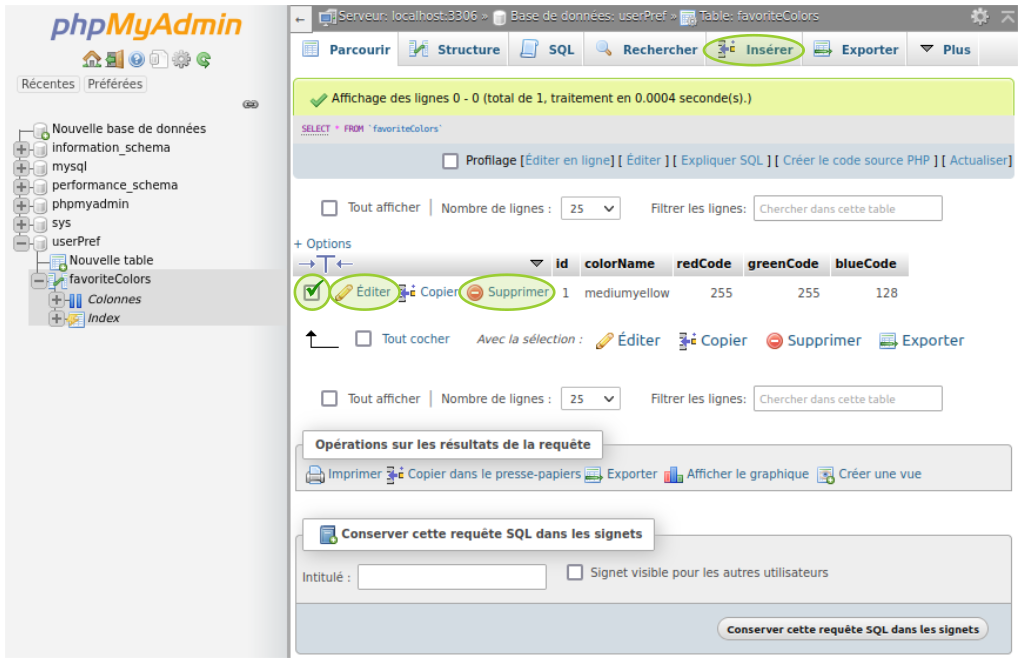
Dans cet exemple, on retrouve la couleur mediumyellow enregistrée précédemment. On peut maintenant :
- sélectionner un enregistrement (voire plusieurs) en cliquant sur sa case‑à‑cocher ; puis on peut :
- modifier individuellement cet enregistrement en cliquant sur le bouton
Éditersitué dans sa ligne ; - effacer individuellement cet enregistrement en cliquant sur le bouton
Supprimersitué dans sa ligne ; - ajouter à la table un nouvel enregistrement en cliquant sur le bouton
Insérersitué dans la barre de commandes.
En règle générale, lors de l'exécution d'une requête, l'interface bascule dans l'onglet SQL et affiche en haut de la page (sous une bulle de notification jaune), son codage en langage SQL.

Et sous cet affichage, on trouve des hyperliens pour éditer ce code ou même le transcoder en langage php.
Exemple d'application web avec une architecture 3 niveaux
Présentation
Dans le prolongement de l'exemple académique d'une base de données mémorisant les couleurs préférées d'un utilisateur (cf. supra ), on décrit ci‑après le code d'une page web dynamique d'interface client pour manipuler cette base de donnée (cf. la capture d'écran ci‑dessous).
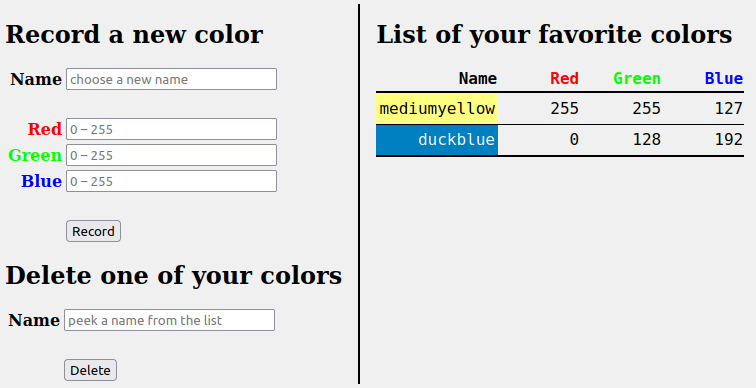
Cette page web doit permettre à un utilisateur de gérer des couleurs enregistrées dans la base de données :
- enregistrer une nouvelle couleur,
- supprimer une couleur enregistrée,
- visualiser la liste de toutes les couleurs enregistrées,
et ceci sans recourir à l'application phpMyAdmin. En effet, cette dernière est réservée à l'administrateur de la base de donnée, elle ne peut en aucun cas jouer le rôle d'interface usuelle pour un client.
Bien qu'assez simple, une telle application constitue un exemple nettement plus complexe que celui de la page web dont dont on pouvait simplement changer la couleur d'arrière plan (cf. supra ). Elle fait appel à de la programmation orientée objet – avec notamment des PDO W – et, pour une bonne factorisation du code, elle nécessite le recours à une programmation multi‑fichiers.
Installation sur une pile AMP
Comme toute application web, elle peut être testée sur un poste de travail muni d'une pile AMP. Tous les fichiers de l'application sont à placer dans le même répertoire, nommé par exemple example3tier, lui‑même à placer dans le répertoire www du émulé par la pile AMP – typiquement, /var/www/html sur une machine à système Linux (cf. supra ).
Ces fichiers sont téléchargeables en exécutant le script ci‑dessous dans un terminal de commandes en lignes (pour plus de détails, consulter le sujet de TP R2‑2 ) :
cd /var/www/html && mkdir example3tier && cd example3tier/wget -r --no-parent -nH -l1 --cut-dirs=6 --reject="index.html*","example3tier*" --no-check-certificate -- https://www.lycee-ferry-versailles.fr/snir/moduleR/prog/R2tp2_serveurs/example3tierfor f in *.txt; do mv -- "$f" "${f%.txt}.php"; done
Dans le répertoire de l'application, il faut également exécuter avec MariaDB le fichier source tableCreation.sql de création de la base de donnée userPref et de la table favoriteColors (cf. supra ).
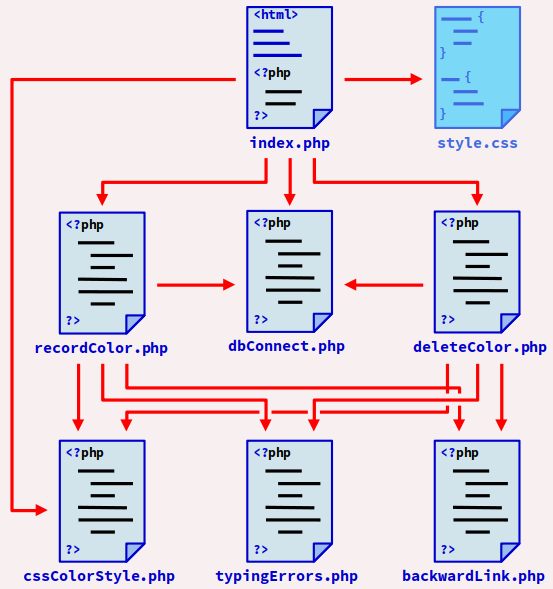
Synoptique du code de l'application
Le code de l'application est réparti sur 8 fichiers source :
- le fichier principal
index.phpet son fichier de style associéstyle.css; - le fichier de script
dbConnect.phpqui gère la connexion à la base de donnée ; - les fichiers de script
recordColor.phpetdeleteColor.phpqui gèrent respectivement l'ajout et la suppression d'une couleur dans la base de donnée ; - trois autres fichiers de script qui gèrent des aspects secondaires :
-
typingErrors.phppour gérer les éventuelles erreurs de saisies de l'utilisateur ; -
cssColorStyle.phppour générer le code CSS du nom d'une couleur affiché sur la page web ; -
backwardLink.phppour factoriser le code HTML de la balise de retour à la page principale, car ce code est utilisé à plusieurs reprises dans le programme.
La figure ci‑dessous représente les relations de dépendances entre ces différents fichiers :
Pour ne pas surcharger inutilement l'exposé, certains aspects ne seront pas détaillés, notamment le fichier style.css. Toutefois, ce fichier peut être consulté après téléchargement.
Code de la page principale
Le fichier principal de l'application web est nommée index.php. Cela permet le chargement automatique de la page par le navigateur lorsqu'on saisit l'URL ciblant le répertoire où sont stockés tous les fichiers :
http://localhost/example3tier
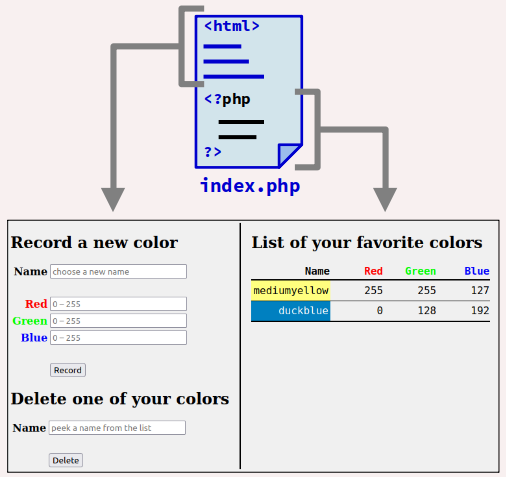
Le code de cette page se décompose en deux parties :
- une première partie, entièrement composée en HTML/CSS qui affiche successivement sur la colonne de gauche les formulaires d'enregistrement d'une nouvelle couleur et de suppression d'une couleur enregistrée ;
- une deuxième partie, essentiellement constituée d'un script php qui affiche sur la colonne de droite la liste des couleurs enregistrées dans la base de donnée.
Code de la première partie (HTML)
La balise <body></body> de la page principale est essentiellement constituée de deux balises <form></form> pour afficher les formulaires d'enregistrement et de suppression d'une couleur. Chacune de ces balises <form></form> contient elle‑même :
- diverses balises
<input>de champs de saisie de type : -
textpour le nom de la couleur à enregistrer ou supprimer -
intpour les composantes du code RGB de la couleur à enregistrer ; - une balise
<input>de typesubmit, se présentant comme un bouton qui permet de déclencher une requête HTTP – de méthodePOSTdans les deux cas – et l'exécution du script d'action en langage php dont le chemin est déterminé par l'attributactionde la balise<form></form>. Il s'agit respectivement des fichiers : -
recordColor.phppour le formulaire d'enregistrement (ligne n° 14) ; -
deleteColor.phppour le formulaire de suppression (ligne n° 42).
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title> 3‑tier example </title>
<link href="./style.css" rel="stylesheet">
</head>
<body>
<div style="display: inline-flex;">
<div class="forms">
<h1> Record a new color </h1>
<form method="post" action="recordColor.php">
<table class="forms">
<tr>
<th> <strong>Name</strong> </th>
<td> <input type="text" name="colorName" placeholder="choose a new name"> </td>
</tr>
<tr><th> </th></tr>
<tr>
<th> <strong style="color: red">Red</strong> </th>
<td> <input type="int" name="redCode" placeholder="0 – 255"> </td>
</tr>
<tr>
<th> <strong style="color: lime">Green</strong> </th>
<td> <input type="int" name="greenCode" placeholder="0 – 255"> </td>
</tr>
<tr>
<th> <strong style="color: blue">Blue</strong> </th>
<td> <input type="int" name="blueCode" placeholder="0 – 255"> </td>
</tr>
<tr><th> </th></tr>
<tr>
<th> </th>
<td> <input type="submit" value="Record"> </td>
</tr>
</table>
</form>
<h1> Delete one of your colors </h1>
<form method="post" action="deleteColor.php">
<table class="forms">
<tr>
<th> <strong>Name</strong> </th>
<td> <input type="text" name="colorName" placeholder="peek a name from the list"> </td>
</tr>
<tr><th> </th></tr>
<tr>
<th> </th>
<td> <input type="submit" value="Delete"> </td>
</tr>
</table>
</form>
</div><!-- forms -->
Code de la deuxième partie (php)
Hormis son titre codé par une balise <h1> (ligne n° 57), la deuxième partie de la page web (colonne de droite) est entièrement dynamique et implémentée par du code en langage php.
<div class="list">
<h1> List of your favorite colors </h1>
<?php
$conn = require 'dbConnect.php';
$stmt = $conn->prepare("SELECT * FROM `favoriteColors`");
$stmt -> execute();
$result = $stmt->fetchAll(PDO::FETCH_ASSOC);
if (!$result) {
echo "<p> No color is recorded in the database. </p>";
}
else {
echo
"<table class='list'>" .
" <tr>" .
" <th> <strong>Name</strong> </th>" .
" <th> <strong style='color: red' >Red</strong> </th>" .
" <th> <strong style='color: lime'>Green</strong> </th>" .
" <th> <strong style='color: blue'>Blue</strong> </th>" .
" </tr>";
require('cssColorStyle.php');
foreach ($result as $color) {
$rgbCode = [
"red" => $color["redCode"],
"green" => $color["greenCode"],
"blue" => $color["blueCode"]
];
echo
"<tr>" .
" <td style='" . colorStyle($rgbCode) . "'>" . $color["colorName"] . "</td>" .
" <td>" . $color["redCode"] . "</td>" .
" <td>" . $color["greenCode"] . "</td>" .
" <td>" . $color["blueCode"] . "</td>" .
"</tr>";
}
echo "</table>";
}
?>
</div><!-- list -->
</body>
</html>

La balise <?php ?> commence à la ligne n° 60 par une requête de connexion à la base de données où sont enregistrées les couleurs. Le script de cette requête est exporté dans un fichier séparé nommé dbConnect.php (ligne n° 61). Ce dernier contient des mécanismes de gestion des erreurs de connexion, il sera détaillé infra .
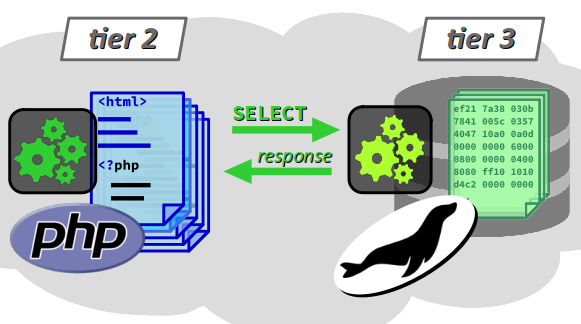
Une fois que la connexion est établie, on procède à une requête SQL de sélection de toutes les lignes (SELECT *) de la table favoriteColors (lignes n° 62).
La réponse du SGBDR à cette requête est stockée dans la variable nommée $result qui est implicitement de type tableau (lignes n° 64).
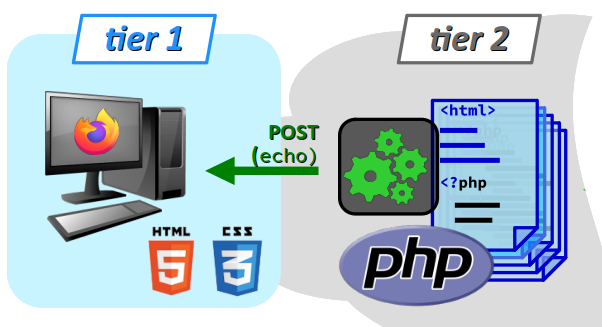
Le reste du code consiste en la génération de code HTML/CSS pour l'affichage de la liste des couleurs sous la forme d'une table, à l'aide de la fonction echo.
Code des scripts d'action
Script d'enregistrement d'une nouvelle couleur

Rappelons que, dans le code de la page principale index.php, le script d'enregistrement d'une couleur, stocké dans le fichier recordColor.php, est appelé par un clic sur le bouton Record. Ce clic engendre également une requête HTTP (méthode POST) qui contient dans son corps les données saisies par l'utilisateur dans les quatre formulaires inclus dans la balise <form></form> du bouton.
<?php
if ($_SERVER["REQUEST_METHOD"] == "POST") {
$colorName = $_POST["colorName"];
$rgbCode = [
"red" => $_POST["redCode"],
"green" => $_POST["greenCode"],
"blue" => $_POST["blueCode"]
];
require('typingErrors.php');
if (!colorNameError($colorName) && !rgbCodeError($rgbCode)) {
$conn = require 'dbConnect.php';
$stmt = $conn->prepare("SELECT * FROM `favoriteColors` WHERE `colorName` = :colorName;");
$stmt -> execute([
':colorName' => $colorName,
]);
$result = $stmt->fetch(PDO::FETCH_ASSOC);
require('cssColorStyle.php');
if ($result) {
$rgbCode = [
"red" => $result["redCode"],
"green" => $result["greenCode"],
"blue" => $result["blueCode"]
];
echo "<p> Sorry, a color named <strong style='" . colorStyle($rgbCode) . "'><em>" . $colorName . "</em></strong> is <strong>already recorded</strong> among your favorites. </p>";
require('backwardLink.php');
}
else {
$stmt = $conn->prepare("INSERT INTO favoriteColors (colorName, redCode, greenCode, blueCode) VALUES(:colorName, :redCode, :greenCode, :blueCode);");
$stmt -> execute([
':colorName' => $colorName,
':redCode' => $rgbCode["red"],
':greenCode' => $rgbCode["green"],
':blueCode' => $rgbCode["blue"]
]);
echo "<p style='" . colorStyle($rgbCode) . "'> Success! The color <strong><em>" . $colorName . "</em></strong> has been <strong>recorded</strong> among your favorites. </p>";
require('backwardLink.php');
}
$conn = null;
}
}
?>
Ce script commence par la récupération des données saisies – le nom de la couleur et les trois composantes de son code RGB – en les stockant dans deux variables nommées $colorName et $rgbCode (cf. les lignes n° 3 à 8). Précisons que cette deuxième variable est un tableau de 3 entiers indexés respectivement par les étiquettes "red", "green" et "blue".

Il est alors fait appel à un script de gestion des erreurs de saisie que l'utilisateur pourrait commettre, qui est codé dans le fichier typeErrors.php (cf. la ligne n° 10). Ce script définit les fonctions colorNameError et rgbCodeError qui sont appelées juste après (à la ligne n° 11) pour tester d'éventuelles erreurs. Il sera détaillé infra .
Et c'est seulement en l'absence d'erreur de saisie que s'effectue une requête SQL de type SELECT * à la base de donnée (cf. la ligne n° 12), exactement comme dans la deuxième partie de la page principale (cf. supra ). Le but de cette requête est de vérifier si le nom saisi pour la couleur à ajouter ne figure pas déjà dans les enregistrement de la table favoriteColors (cf. les lignes n° 13 à 17).
Le script se poursuit donc selon le résultat de cette recherche :
- dans l'affirmative, le script affiche dans une balise
<p></p>un message d'erreur, avec une invite à revenir à la page principale (lignes n° 20 à 28), codée dans le fichierbackwardLink.php; - dans la négative, le script exécute une requête d'insertion dans la base de donnée de la nouvelle couleur, avec à la clef un message pour informer l'utilisateur du succès de l'opération et une invite à revenir à la page principale (lignes n° 29 à 40).

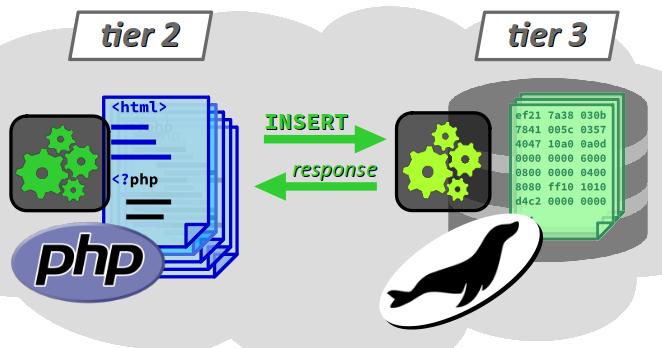

Dans les deux cas, l'affichage de la couleur en arrière plan du texte est rendu convivial grâce au script de composition du style CSS (exporté dans le fichier cssColorStyle.php, cf. infra ).
Script de suppression d'une couleur
Rappelons que dans le code de la page principale index.php appelle le script d'effacement d'une couleur, stocké dans le fichier deleteColor.php, par un clic sur le bouton Delete. Ce clic engendre également une requête HTTP (méthode POST) qui contient dans son corps le nom de la couleur saisie par l'utilisateur dans le seul formulaire inclus dans la balise <form></form> du bouton.
<?php
if ($_SERVER["REQUEST_METHOD"] == "POST") {
$colorName = $_POST["colorName"];
require('typingErrors.php');
if (!colorNameError($colorName)) {
$conn = require 'dbConnect.php';
$stmt = $conn->prepare("SELECT * FROM `favoriteColors` WHERE `colorName` = :colorName;");
$stmt -> execute([
':colorName' => $colorName,
]);
$result = $stmt->fetch(PDO::FETCH_ASSOC);
if (!$result) {
echo "<p> Sorry, the color <strong><em>" . $colorName . "</em></strong> is <strong>not recorded</strong> among your favorites. </p>";
require('backwardLink.php');
}
else {
$rgbCode = [
"red" => $result["redCode"],
"green" => $result["greenCode"],
"blue" => $result["blueCode"]
];
$stmt = $conn->prepare("DELETE FROM favoriteColors WHERE `colorName` = :colorName;");
$stmt -> execute([
':colorName' => $colorName
]);
require('cssColorStyle.php');
echo "<p style='" . colorStyle($rgbCode) . "'> Success! The color <strong><em>" . $colorName . "</em></strong> has been <strong>deleted</strong> from your favorites. </p>";
require('backwardLink.php');
}
$conn = null;
}
}
?>
Ce script procède dans la même logique que le script d'enregistrement, auquel on se reportera pour les détails :
- récupération des données de saisie (cf. la ligne n° 3) ;
- gestion des erreurs de saisie éventuelles (cf. la ligne n° 5) ;
- connexion à la base de données (cf. la ligne n° 7) ;
- recherche du nom de la couleur saisi pour vérifier s'il figure dans la base de données (cf. les lignes n° 8 à n° 12), puis :
- dans la négative, affichage d'un message d'erreur (cf. les lignes n° 14 à n° 17) ;
- dans l'affirmative, exécution de la requête SQL de suppression
DELETEavec affichage d'un message de succès (cf. les lignes n° 18 à n° 33).
Code des script secondaires
Tous ces scripts sont déportés dans des fichiers séparés car ils sont utilisés par les trois scripts étudiés supra. Cela permet une bonne factorisation du code.
Script de connexion à la base de données
Le script de connexion est stocké dans le fichier dbConnect.php. Il commence par renseigner les identifiants de connexion dans les variables $dbhost, $dbuser, etc. (cf. les lignes n° 2 à n° 5).
Attention ! Si la chaîne de caractères définissant le mot de passe (valeur de la variable $dbpasswd) comporte un caractère spécial comme $, ce dernier doit être codé par une séquence d'échappement, comme \$.
<?php
$dbhost = "localhost";
$dbuser = "user-name";
$dbpasswd = "********";
$dbname = "userPref";
function connect($host, $db, $user, $passwd) {
$dsn = "mysql:host=$host;dbname=$db;charset=UTF8";
try {
$options = [PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION];
return new PDO($dsn, $user, $passwd, $options);
}
catch (PDOException $e) {
echo "<p> Connection error: " . $e->getMessage() . "</p>";
die();
}
}
return connect($dbhost, $dbname, $dbuser, $dbpasswd);
?>
Ensuite, il définit la fonction connect (cf. les lignes n° 7 à n° 17) qui met en œuvre la connexion via le bloc try et avec une gestion des exceptions codée dans le bloc catch .
Enfin, il retourne un appel de cette fonction avec comme arguments effectifs les identifiants de connexion mémorisés (cf. la ligne n° 19).
Script de gestion des erreurs de saisie
Le script de gestion des erreurs de saisie est stocké dans le fichier typingErrors.php. Il définit juste deux fonctions : colorNameError et rgbCodeError.
<?php
function colorNameError($colorName) {
if (!isset($colorName) || $colorName[0] == ' ') {
echo "<p> Type <strong>a name</strong> for your color. </p>";
echo "<p> Click on the <strong>backward button ←<strong> of your browser. </p>";
return true;
}
return false;
}
function rgbCodeError($rgbCode) {
$typingError = false;
foreach ($rgbCode as $color => $code) {
if (!isset($code) || $code > 255 || $code < 0) {
$typingError = true;
$textColor = $color;
if ($color == "green") $textColor = "lime";
echo "<p> Error! Type the <strong style=color:" . $textColor . ">" . $color . " code</strong> from <strong>0 to 255.</strong> </p>";
echo "<p> Click on the <strong>backward button ←</strong> of your browser. </p>";
}
}
return $typingError;
}
?>
- La fonction
colorNameErrorvérifie si son argument formel$colorName(cf. la ligne n° 3) : - n'est pas défini – cela signifie l'utilisateur n'a pas saisi ce champ avant de cliquer sur le bouton Record ou Delete ;
- ou commence par le caractère « espace » – car cela peut occasionner le risque d'avoir une chaîne de caractère constituée seulement d'espaces, donc invisible ;
- La fonction
rgbCodeErrorvérifie son argument formel$rgbCode(cf. la ligne n° 13). Il s'agit d'un tableau dont chaque élément peut éventuellement être : - non défini – cela signifie que l'utilisateur n'a pas saisi son champ avant de cliquer sur le bouton Record ;
- non compris entre 0 et 255 – une telle valeur saisie ne pouvant constituer une composante de code RGB d'une couleur.
<p></p> un message d'erreur (cf. la ligne n° 4)puis dans une autre dans une balise <p></p> une invitation de renvoi à la page d'accueil (ligne n° 5). Elle retourne finalement la valeur booléenne true (ligne n° 63); dans le script appelant qui reçoit cette valeur, cela empêche toute requête à la base de donnée et oblige l'utilisateur à modifier la saisie. false (cf. la ligne n° 8). <p></p> un message d'erreur où le nom du champ ayant fait l'objet d'une erreur de saisie est affiché dans sa couleur : red, green ou blue (cf. la ligne n° 18). Elle affiche également une invitation de renvoi à la page d'accueil (ligne n° 19). Script de composition du style CSS de couleur
Le script de composition du style CSS est stocké dans le fichier cssColorStyle.php.
Il définit juste la fonction colorStyle dont l'argument formel $rgbCode est implicitement un tableau de 3 entiers indexés respectivement par les étiquettes "red", "green" et "blue".
<?php
function colorStyle ($rgbCode) {
$backgndHexcode = sprintf("#%02x%02x%02x", $rgbCode["red"], $rgbCode["green"], $rgbCode["blue"]);
$foregndHexcode = "#000000"; // black text (default)
if (($rgbCode["red"] + $rgbCode["green"] + $rgbCode["blue"]) < 128 * 3) {
$foregndHexcode = "#ffffff"; // white text if background is too dark
}
return "background: " . $backgndHexcode . "; " .
"color: " . $foregndHexcode . "; " .
"padding: 0.2em";
}
?>
Cette fonction commence par préparer la couleur d'arrière‑plan. Via la fonction sprintf (analogue à celle du langage C – cf. chap. C5‑VI C), elle transcode dans une variable $backgndHexcode les valeurs exprimées en base 10 dans le tableau $rgbCode en une chaîne de caractères formant un code de couleur hexadécimal à 6 digits, préfixé par le caractère #, conformément à la syntaxe du langage CSS (cf. la ligne n° 3).
Ensuite, elle détermine la couleur de texte (donc, au premier plan) dans une variable $foregndHexcode :
- en prenant par défaut la valeur
"#000000"– donc le noir (cf. la ligne n° 4) ; - mais en la changeant en
"#ffffff"– donc le blanc – si la couleur d'arrière plan codée dans les éléments de$rgbCodeest sombre (cf. les lignes n° 5 & 6). Sinon, le texte en noir serait alors difficile à distinguer de l'arrière plan.
Pour finir, la fonction retourne une chaîne de caractère qui concatène le style d'affichage en langage CSS à appliquer au texte des messages avec les codes de couleurs précédemment déterminés. Ce style sera injecté dans le code HTML/CSS des messages généré par les scripts appelants, via la fonction echo (cf. les lignes n° 8 à 10).
Script du lien de retour à la page principale
Stocké dans un fichier nommé backwardLink.php, ce script très simple code juste un lien HTML de retour à la page principale avec une balise <a></a>. Le lien s'ajoute sur la page qui appelle ce script par la fonction echo.
<?php echo "<p> <a href='./index.php'> Back to home </a></p>"; ?>