Le world wide web W, c'est‑à‑dire le réseau des milliards de pages d'hypertexte – dites pages web W et accessibles à l'aide d'un logiciel navigateur – est la principale application (au sens général) de l'Internet. Comme beaucoup d'autres applications, elle est basée sur un modèle client‑serveur (cf. chap. R1‑I ).
À l'origine, les pages web étaient des documents statiques codés dans un langage à balises (HTML/CSS) et transmis du serveur au client par le protocole HTTP (cf. chap. R1‑IV ). Mais très vite, elles ont commencé à inclure des objets dynamiques : boutons, formulaires, animations audio et vidéo… – cf. ci‑contre ce logo au format animé gif de l'ancien navigateur Netscape (ici, converti au format mp4).
Aujourd'hui, les pages web peuvent mettre en œuvre des applications complexes – édition de documents bureautiques, logiciels de CAO, jeux 3D… Elles sont devenues un support incontournable des services de messagerie (web‑mail, chat…), des réseaux sociaux, du commerce en ligne, des médias d'information, des démarches administratives… Tout cela a été rendu possible grâce à :
- le développement de nouveaux langages de programmation (PHP, Java, JavaScript, SQL…) et une multitude de frameworks ;
- la « ramification » du modèle client‑serveur, non seulement du côté du client, mais surtout du côté du serveur, avec l'apparition d'architectures dite multi‑tiers W.
En effet, dans ce modèle client‑serveur W, comme illustré sur la figure ci‑dessous, on trouve le plus souvent :
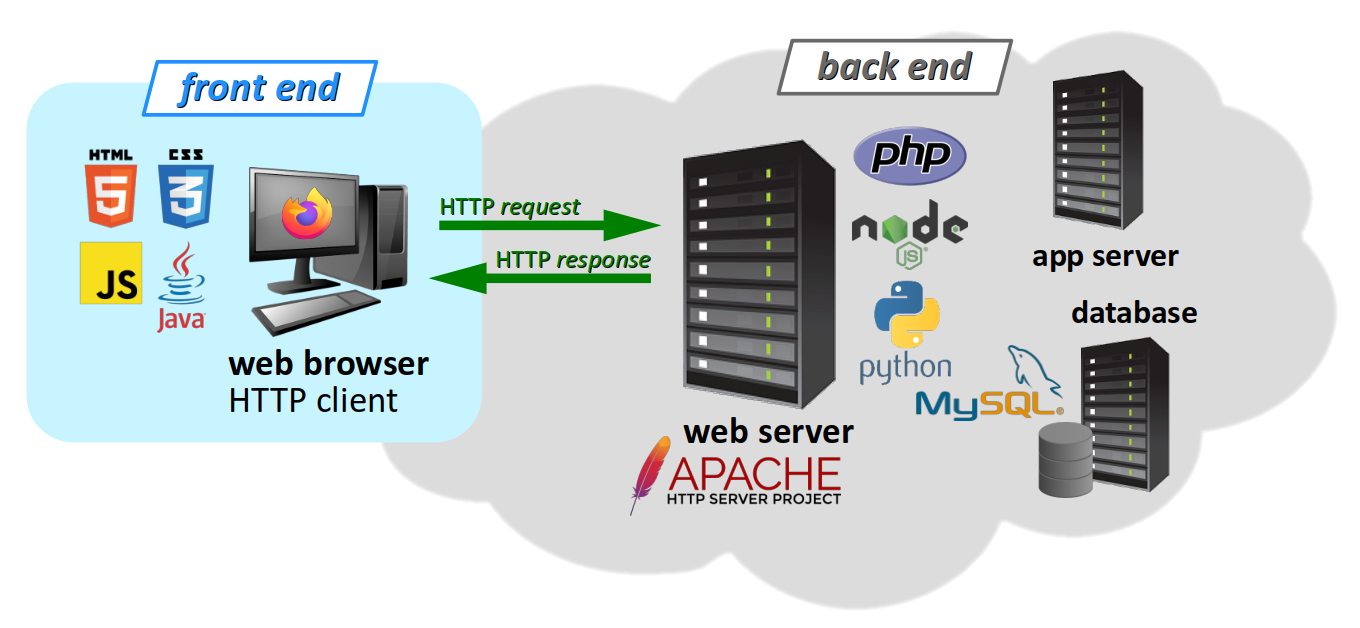
- du côté du client – ce qu'on appelle en anglais le front end – essentiellement un navigateur web – logiciel complexe qui effectue de nombreux traitements (client HTTP, interpréteur HTML/CSS/JS…) – et aussi, souvent, d'autres composants logiciels modulaires, appelés plugins (par exemple, un lecteur de fichiers
pdf) ; - du côté du serveur – ce qu'on appelle en anglais le back end –, un logiciel serveur web qui stocke les fichiers sources de la page web, et qui peut également accomplir des traitements très complexes sur le contenu des fichiers à transmettre aux clients.
- dans des bases de données, lesquelles sont souvent être hébergées sur d'autres serveurs ;
- dans des serveurs dédiés à des applications particulières (messagerie, vidéos, etc.).
À la lumière de cette brève description, on comprend qu'il serait déraisonnable pédagogiquement de vouloir décrire ici une telle diversité de technologies. Ce chapitre se donne donc l'objectif limité d'aborder seulement :
- l'architecture logicielle du côté du client et notamment le fonctionnement général d'un navigateur web ; d'un point de vue pratique, on présentera des caractéristiques et des fonctionnalités souvent méconnues du grand public, mais qui sont indispensables pour un informaticien (mémoire cache, console…) ;
- le protocole HTTP dans ses principes de fonctionnement et un premier niveau de détail de ses messages (requêtes et réponses).
Quant à la technologie du côté du serveur, bien qu'essentielles pour comprendre le fonctionnement du web, elle ne sera abordée qu'au chapitre suivant. Les impatients pourront néanmoins consulter cette vidéo Y qui en donne une bonne introduction.
Architecture web côté client (front end)
Le navigateur web – généralités

Du côté du client, l'architecture web est typiquement basée sur l'exécution d'un navigateur web W – en anglais web browser.
Il s'agit d'un logiciel complexe, qui intègre de nombreuses fonctionnalités.
Parmi ces fonctionnalités, on trouve principalement les suivantes :
- un client pour le protocole HTTP ;
- un moteur de rendu HTML pour interpréter le code HTML/CSS/JS des pages web chargées ;
- une interface utilisateur qui met en œuvre le dialogue homme‑machine et dont les éléments principaux sont bien sûr :
- la fenêtre d'affichage multi‑onglets des pages web chargées ;
- la barre d'adresse qui permet de saisir les URL (cf. chap. R2‑I ) pour accéder aux pages web ;
- un gestionnaire d'extensions et de plugins pour ajouter des fonctionnalités au navigateur ;
- un système de stockage de données persistantes – ce qu'on appelle usuellement la mémoire cache.
pdf, etc.), mais aussi pour filtrer d'éventuels éléments indésirables (bloqueur de publicité, etc.). Et bien entendu, le navigateur comporte un noyau logiciel pour coordonner tous ces composants, qu'on appelle parfois le moteur principal du navigateur.
Autrefois modeste, un navigateur est aujourd'hui un logiciel remarquable à bien des égards.
- Par la complexité des traitements qu'il met en œuvre et la rapidité qu'on attend de lui pour bénéficier d'un affichage fluide, un navigateur requiert d'importantes ressources matérielles (espace disque d'installation, mémoire vive et temps de processeur en fonctionnement).
- Fruit de recherches incessantes, un navigateur fait l'objet de mises à jours très fréquentes pour l'amélioration des performances et l'invention de nouvelles fonctionnalités. Ces dernières sont aussi parfois motivées par des questions urgentes de sécurité (découverte d'une faille) et doivent donc être appliquées sans tarder.
- En synergie avec le système d'exploitation auquel il est souvent associé (pensons par exemple au couple Android & Google Chrome), il permet d'imposer incidemment à l'utilisateur diverses options cachées de navigation – acceptation de cookies W non indispensables et autres dispositifs de télémétrie W – de surveiller son comportement et de collecter des données qui, à grande échelle, représentent un intérêt commercial significatif.
Évolution du marché des navigateurs
Le dernier point évoqué ci‑dessus explique en partie pourquoi les navigateurs sont tous des logiciels gratuits : les entreprises qui les développent peuvent rentabiliser leurs investissement en commercialisant des données qu'elles récoltent par télémétrie.
Toutefois, il ne faut pas perdre de vue qu'historiquement, le développement des navigateurs s'est d'abord déroulé dans le cadre d'un travail de recherche collaboratif, notamment au CERN W et au NCSA W). Après une transition dans un cadre entrepreneurial, avec la création de Netscape Navigator W (d'où vient d'ailleurs le terme « navigateur »), le fruit de ce travail a ensuite émulé dans le monde de l'open‑source gratuit, aboutissant notamment à la création de Mozilla Firefox W.



Cette alternative a permis, au début des années 2000, de tempérer le monopole du navigateur Internet Explorer W de Microsoft, installé d'office avec son système d'exploitation Windows ultra dominant sur le marché des ordinateurs personnels.

En revanche, l'existence de Firefox n'a pas réussi à limiter le même phénomène avec le navigateur Google Chrome W, indissociable du système d'exploitation Android qui domine le marché des smartphones et des tablettes. Avec la forte croissance des smartphones depuis les années 2010, Chrome a fini par conquérir près de 65 % des parts de marché des navigateurs.

Le seul challenger de cette quasi hégémonie est le constructeur Apple, qui a développé son propre navigateur Safari W, lequel représente aujourd'hui entre 15 % et 20 % du marché, parce qu'il constitue le navigateur par défaut pour les ordinateurs Macintosh et surtout les très « populaires » I‑Phones.
Aujourd'hui, dans les 20 % restant du marché, seul quatre navigateurs dépassent 1 % : Edge, Firefox, Opera et Samsung Internet W (cf. également l'animation ci‑contre, avec des statistiques un peu différentes). Pour continuer à suivre cette évolution, on peut par exemple consulter cette page web .

Le cas d'Internet Explorer est particulièrement instructif. En position de quasi‑monopole au début des années 2000, le navigateur n'occupe plus aujourd'hui qu'une position marginale, malgré un rebranding complet nommé Edge W.
D'ailleurs, fin 2018, l'entreprise Microsoft a abandonné le développement et l'exploitation de son propre moteur de rendu (EdgeHTML) pour adopter celui de Google Chrome (nommé Blink) !
Le moteur de rendu HTML
Peu connu du grand public, le moteur de rendu HTML W (en anglais, browser engine, ou layout engine, ou rendering engine) est le composant logiciel central d'un navigateur web. Son rôle principal est d'interpréter le code source d'un page web pour produire l'affichage dans la fenêtre principale du navigateur.
À l'instar du navigateur, le moteur de rendu HTML remplit de nombreuses fonctions pour afficher une page web, notamment celles listées ci‑dessous.
- Il interprète le code HTML W (hypertext markup language) pour afficher le contenu de la page web.
- forme implicitement ce qu'on appelle le DOM W ou document object model ;
- peut par ailleurs être réparti sur plusieurs fichiers pour coder de façon rationnelle différentes parties de la page (corps, panneau de navigation, etc.).
- Il obéit à des règles de présentation du contenu, codées dans des feuilles de styles en langage CSS W (cascading style sheets).
- Il exécute les scripts codés en langage JavaScript W inclus ou appelés dans le code HTML de la page web pour lui donner un comportement dynamique et interactif sans nécessiter son rechargement complet.




À titre d'illustration purement académique, le code HTML/CSS/JS ci‑dessous, enregistré dans un fichier nomme changeBackground.html, crée une page web très simple avec deux balises de liens dynamiques permettant respectivement de choisir entre deux couleurs d'arrière‑plan (blanc ou jaune).
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>Dynamic page client JS </title> </head> <body style="background: white"> <h1> Dynamic page example with client side JS </h1> <p> <a href="#" onclick="document.body.style.backgroundColor = 'white'">White</a> <!-- 2 no-break-spaces here --> <a href="#" onclick="document.body.style.backgroundColor = 'yellow'">Yellow</a> </p> </body> </html>
L'emploi du langage JavaScript apparaît dans les attributs onclick des balises <a> </a> codées aux lignes n° 11 & 13 : ils viennent modifier la propriété de style backgroundColor de l'objet body de la page.
Un moteur de rendu HTML peut également être utilisé dans d'autres application qui elles aussi requièrent l'affichage de contenus codés en HTML/CSS/JS.
C'est notamment le cas des logiciels clients de messagerie – Mozilla Thunderbird, Microsoft Outlook, etc. (cf. chap. R2‑VI ). Depuis longtemps, ils permettent d'intégrer dans les courriels de nombreux des éléments de mise en forme du texte, des hyperliens, etc.
Évolution des moteurs de rendu HTML
On a pu observer au cours des années 2000 une intéressante diversité de moteurs de rendu HTML. Cependant, on peut considérer que, depuis fin 2018, il n'en reste plus que trois à être employés dans les principaux navigateurs (cf. tableau ci‑dessous).
| Moteur de rendu HTML | Moteur JavaScript | Navigateurs ou autres applications |
|---|---|---|
| Blink W | V8 W | Chrome  , Chromium , Chromium  , Brave , Brave  , Opera , Opera  , Vivaldi , Vivaldi  , Edge , Edge  … … |
| WebKit W | JavaScriptCore W | Safari  … … |
| Gecko W | SpiderMonkey W | Firefox  , Thunderbird , Thunderbird  … … |
Spécificités du moteur JavaScript
Le moteur JavaScript occupe une place spécifique dans les fonctionnalités du moteur de rendu HTML, au point qu'il est souvent considéré comme une composante à part entière du navigateur lui‑même.
- Avec des scripts de plus en plus complexes et nombreux dans les pages web, les techniques d'interprétation du langage ont évolué et procèdent maintenant par compilation à la volée W (just‑in‑time compilation) de blocs d'instructions dans un langage intermédiaire appelé bytecode W (cf. également chap. C1‑I C). C'est pourquoi on parle de « moteur » et non pas d'« interpréteur ».
- De plus, le moteur JavaScript dit V8 de Blink est également exploité dans la plateforme Node.js W pour permettre l'utilisation du langage JavaScript dans un contexte général – notamment en ligne de commande – et non plus seulement au sein d'une page web.




Tendance du développement des pages web dynamiques
Dans la mesure du possible, en termes d'efficacité et de réactivité, il est préférable d'implémenter le fonctionnement dynamique d'une page web du côté du client W (on parle de client side scripting).

En effet, en plus de toutes les requêtes de chargement d'une page web, le serveur qui l'héberge doit aussi répondre à toutes les requêtes de comportements dynamiques qui sont codés de son côté. Le fait de coder ces comportements du côté du client permet de distribuer la charge de traitement et ainsi de soulager d'autant le serveur.
Néanmoins, certains traitements sont impossibles à implémenter du côté du client, notamment :
- l'agrégation de données issues de bases de données à accès restreint (données de compte utilisateur, catalogue de produits marchands, etc.) ;
- la manipulation de fichiers dans l'arborescence de la machine du client, et ce pour des raisons de sécurité évidentes (sinon il serait très simple d'installer un virus…).
Les extensions et plugins
Comme tous les gros logiciels, un navigateur adopte une architecture modulaire pour s'adapter au mieux aux besoins et aux ressources des utilisateurs.
Sur la base d'une installation nominale, on peut ajouter :
- des extensions W, c'est‑à‑dire des composants qui deviennent internes au navigateur (correcteur orthographique, bloqueur de publicité, etc.) ;
- des plugins W, c'est‑à‑dire des composants qui permettent d'exploiter au sein d'une page web des logiciels externes au navigateur (lecteur de fichiers
pdf, environnement Java, etc.).

En particulier, un plugin Java permet au navigateur d'interpréter dans une page web, de préférence dans une balise <objet>, un programme pré‑compilé en bytecode Java – on parle alors d'applet Java W.
Pour cela, le plugin Java donne accès à la l'environnement d'exécution JRE W (Java runtime environment) qui doit être préalablement installée sur la machine du client et s'exécuter en arrière‑plan. Cet environnement offre alors aux pages web des possibilités de fonctionnement dynamique sans limites de complexité.
Toutefois, depuis une dizaine d'année, les exigences en matière de sécurité ont amené à réduire drastiquement l'emploi de certains plugins, notamment :
- ActiveX W, un module de scripts permettant de manipuler des fichiers du côté client sur les systèmes d'exploitation Windows ; son développement est abandonné depuis 2015 ;


L'interface utilisateur
D'un navigateur à l'autre, les possibilités offertes par l'interface utilisateur peuvent être considérablement différentes.
Sur certains navigateurs, on peut notamment :
- spécifier des paramètres de connexion au réseau (serveur proxy, etc.) indépendamment de ceux renseignés au niveau du système d'exploitation de la machine hôte ; cela peut s'avérer très utile lorsqu'on ne dispose pas des droits d'administration ;
- choisir la politique de sécurité et de confidentialité (historique, cookies, mémoire cache, mots de passe…) ;
- examiner le code de la page dans une console, détailler les propriétés de chaque élément, lister des erreurs générées, observer les échanges de données sur le réseau – toutes ces possibilités étant très utiles pour le développement des pages web.
La mémoire cache
Comme pour les réponses d'un DNS (cf. chap. R2‑I ), il est efficace qu'un navigateur conserve en mémoire cache les dernières pages web chargées. Cela lui évite de devoir les recharger entièrement lorsque l'utilisateur ferme un onglet puis le ré‑ouvre peu de temps après, donc :
- cela rend la navigation plus rapide,
- plus généralement, cela diminue le flux de données qui transitent sur le réseau.
Toutefois, le stockage en mémoire cache peut obérer temporairement des modifications récentes dans le contenu d'une page, et ce sans qu'un clic sur le bouton  d'actualisation de la page suffisent pour y remédier. C'est en particulier le cas lorsque une modification de codage de la page est opérée dans un fichier JavaScript.
d'actualisation de la page suffisent pour y remédier. C'est en particulier le cas lorsque une modification de codage de la page est opérée dans un fichier JavaScript.
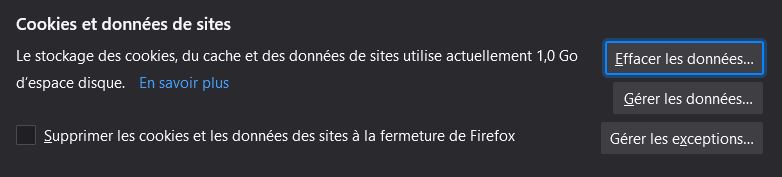
Dans ce cas, une solution consiste à vider le contenu de la mémoire cache de la page. Une telle manipulation est possible dans l'interface utilisateur (par exemple, sous Firefox, dans le menu Option/Vie privée et sécurité (cf. la capture d'écran ci‑contre) ou encore dansl'historique de navigation, en choisissant la commande Oublier ce site dans le menu contextuel.
Contrairement à ce que l'on pourrait naïvement penser, le code HTML/CSS/JS d'une page web affichée dans un navigateur n'est pas enregistré par ce dernier sous forme de fichiers .html, .css et .js, même si la page est statique. Ce code est directement stocké en mémoire vive pour être interprété avec le maximum de rapidité.
Lors de la fermeture de la page, la sauvegarde en mémoire cache de ses éléments est complexe. Elle tient compte du nombre de requêtes dont la page a fait l'objet pour calculer sa date d'expiration, car sauf situations particulières, l'usage intensif du navigateur sature rapidement la mémoire cache. En conséquence, toute sauvegarde d'une page se fait donc au détriment d'une autre.
Sur divers navigateurs (mais pas Chrome), on peut consulter le contenu détaillé de la mémoire cache en saisissant dans la barre de navigation l'URL about:cache (cf. la capture d'écran ci‑dessous avec Firefox).

On peut également aller constater la complexité de la structure de la mémoire cache en explorant le répertoire indiqué à la rubrique disk.
Autres clients web

Les navigateurs ne sont pas les seuls clients web qui existent. En fait, n'importe quel logiciel qui exécute des requêtes HTTP forme un client web.
Et notamment, c'est le cas de la plupart des applications web embarquées sur les appareils mobiles – smartphones, tablettes – disposant d'un connexion à l'Internet.
Ces applications web sont presque toujours codées en langage Java et exécutées sur l'environnement d'exécution JRE (cf. supra ). En effet, cela évite de devoir, pour chaque application, coder autant de versions de l'application qu'il existe de systèmes d'exploitation (Android, IOS, etc.). Il suffit de coder « une fois pour toute » le JRE pour chacun de ces systèmes, ce qui est beaucoup plus économique puisque le nombre de système se compte en unités alors que les applications se compte au moins en milliers.
Est donc un client web toute application qui fait appel à des données externes à la machine sur laquelle elle s'exécute, que ces données soient publiques (données météorologiques, horaires de trains…) ou privées (comptes clients de toute sorte, catalogues marchands…).

Et plus généralement, est également un client web tout logiciel installé sur une machine (poste de travail ou autre) qui fait appel à des services et/ou des données dématérialisées W (cloud computing).
En effet, pour exploiter ces données ou services externe, un logiciel va presque toujours utiliser des fonctions avancées du protocole HTTP (comme, par exemple, la méthode fetch en JavaScript ).
Le protocole HTTP
Généralités

Le protocole HTTP W – en anglais, hypertext transfer protocol – est le protocole applicatif (niveau 7 dans le modèle OSI – cf. chap. R1‑IV ) qui formalise les requêtes et les réponses entre un client (typiquement, un navigateur) et un serveur (typiquement, un serveur web).
Il utilise le port nº 80 de façon nominale (parfois aussi le port nº 8080) et le port nº 443 dans sa variante HTTPS sécurisée par le protocole TLS (cf. chap. R1‑IV ).
Comme pour tout protocole, il existe plusieurs versions de HTTP. Techniquement, une version y.x est notée :
- HTTP/y.x si x ≠ 0 – par exemple, HTTP/1.1
- HTTP/x dans les cas particuliers des versions 1.0, 2.0, etc. – par exemple , HTTP/2
De plus, on adopte la notation HTTP/1.x pour désigner l'ensemble des versions 1 (quel que soit le numéro de sous‑version x).
Principales caractéristiques du protocole HTTP
Les grandes qualités du protocole HTTP sont les suivantes.
- Il est modulaire, car il permet de charger une page par parties et non pas d'un seul bloc ;
- Il est extensible. En effet :
- il permet d'échanger toutes sortes de données – audio, vidéos, formulaires, et autres données numériques… – et non pas seulement du code HTML/CSS/JS ;
- il peut être utilisé par toutes sortes d'applications – player audio ou vidéo, client de messagerie, etc. – et et non pas seulement un navigateur web.
Jusqu'à sa version HTTP/2 incluse, le protocole HTTP(S) s'appuie sur le protocole de transport TCP (cf. chap. R1‑IV et R3‑I ). En effet :
- le fait d'opérer en mode connecté assure la disponibilité du serveur comme du client lors des échanges, et contribue in fine à une meilleure efficacité qu'en mode non connecté ;
- le découpage en paquets est évidemment justifié au regard du volume important des données à transmettre (la moindre page web ne peut pas tenir dans un datagramme UDP).
Sans conteste, la fiabilité du protocole TCP est bienvenue pour transporter les messages HTTP car, en matière de transmission de pages web, aucune erreur n'est acceptable à la réception des données.
Mais par ailleurs, HTTP est décrit comme étant un protocole sans état W – en anglais, stateless. En effet, une fois que la connexion établie entre le client et le serveur, les différentes transactions effectuées ne sont pas mémorisées dans le déroulement protocolaire. Le client peut donc envoyer ses requêtes au serveur en nombre quelconque et dans un ordre indifférent, sans déclencher d'erreur dès lors que les ressources demandées sont bien disponibles.
Cette stratégie de conception du protocole HTTP est motivée par la nécessité de permettre au serveur la prise en charge d'un grand nombre de client (mémoriser leurs requêtes pénaliserait forcément les temps de réponse).
Évolution des versions du protocole HTTP
Même si elle n'est pas la plus récente, la version HTTP/1.1 est encore encore utilisée pour le service non sécurisé des pages web – essentiellement statiques. Finalisée depuis juin 1999 par la RFC 2616 , elle présente plusieurs avancées par rapport à la version antérieure HTTP/1.0 (RFC 1945 ) :
- elle met en œuvre par défaut une connexion persistante entre le client et le serveur (valeur
Keep-alivede l'attributConnection), ce qui permet d'enchaîner les requêtes sans attendre les réponses (on parle alors de pipelining W) ; - elle permet la négociation du contenu, en spécifiant (dans des valeurs de la forme
Accept-) les langues et les formats de données préférés : encodage UTF‑8 ou autre (cf. C3‑IX C), types MIME (cf. chap. R1‑IV ), etc.
La version HTTP/2 W est définie depuis mai 2015 par la RFC 7540 . Aujourd'hui, c'est cette version qui est la plus largement adoptée car elle est facilite l'emploi du protocole de chiffrement TLS W dans ses normes les plus récentes (1.2 depuis 2008, 1.3 depuis 2018).
Rétro‑compatible avec HTTP/1.1, la version HTTP/2 présente plusieurs avantages, notamment :
- la segmentation de chaque message et l'encapsulation chaque segment dans une « trame » – en anglais, on emploie le mot frame, qu'il est préférable d'employer aussi français pour ne pas confondre avec la notion de trame du niveau 2 du modèle OSI (cf. chap. R1‑IV ) ;
- le codage binaire des frames, et non plus sous forme de caractères ; ainsi, pour un humain, il est impossible de déchiffrer les messages sans l'assistance d'un programme de décodage ;
- le multiplexage des frames, qui permet de s'affranchir du problème de Head‑of‑line blocking W.
Enfin, la version HTTP/3 vient d'être définie par la RFC 9114 de juin 2022. Cette nouvelle version apporte un changement majeur car elle s'appuie sur le protocole de transport QUIC W, lequel opère non pas par paquets TCP mais avec un multiplexage de connexions échangeant des datagrammes UDP.
Principe des messages HTTP – requêtes et réponses
Dans les versions 1.x, il n'existe que deux types de messages HTTP :
- les requêtes que le client adresse au serveur, typiquement pour demander le chargement de tout ou partie d'une page web, mais aussi pour lui transmettre des données (par exemple, le contenu d'un formulaire) ;
- les réponses que le serveur adresse au client pour satisfaire au mieux à ses requêtes, dans la mesure du possible.
En règle générale, une communication par le protocole HTTP est toujours initiée par la requête d'un client. Ce dernier est alors désigné par le terme user agent W.
Format général des messages HTTP 1.x
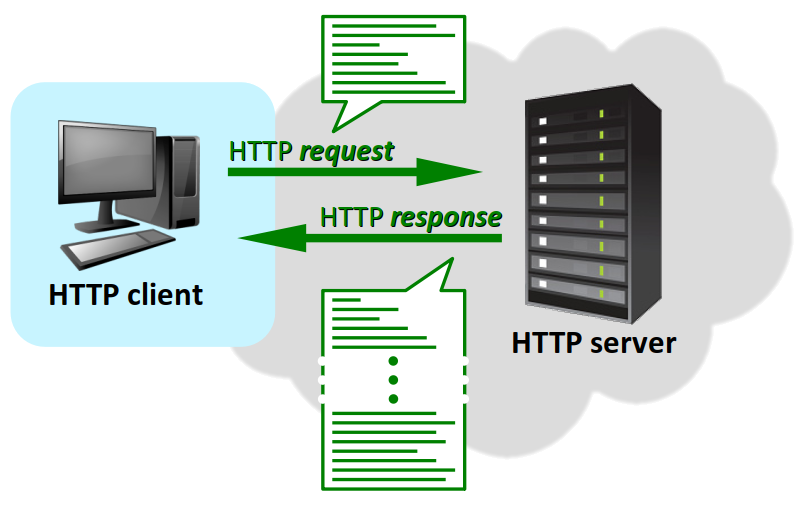
A contrario de ceux de la plupart des autres protocoles (DNS, DHCP, NTP, TCP, UDP, etc.), les messages du protocole HTTP n'adoptent pas un format unique qui serait décrit sur une échelle de 32 bits. Cela s'explique essentiellement par deux spécificités :
- la grande asymétrie que présentent :
- les requêtes, qui sont des messages le plus souvent très courts ;
- les réponses, qui sont des messages potentiellement très longs.
- le fait que les messages sont codés par des chaînes de caractères, et non pas par des mots binaires.
Formellement, un message HTTP/1.x est constitué d'une suite de lignes de textes, c'est‑à‑dire des chaînes de caractères chacune terminée par les deux séquences d'échappement \r\n, correspondant respectivement aux caractères de contrôle CR (carriage return) et LF (line feed ou new line) – cf. chap. C3‑VIII C.
Chaque type de message HTTP – requête ou réponse – possède un format particulier défini au regards des besoins spécifiques en termes d'informations à transmettre. Néanmoins, elles partagent le point commun de se diviser en deux ou trois parties.
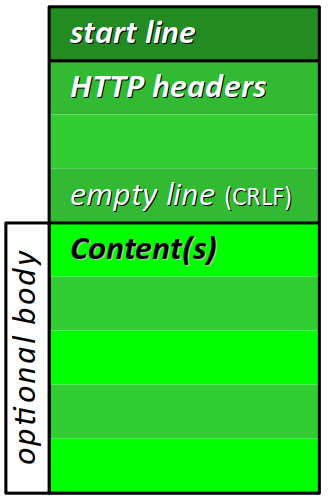
- La première partie se limite à une seule ligne dite ligne initiale (start line) ;
- La deuxième partie regroupe ce qu'on appelle les en‑têtes (headers). Ils forment une suite de lignes de champs (field lines), chacune codant une ou plusieurs valeurs pour le champ indiqué en début de ligne.
- La troisième partie, dite corps (body) du message, est optionnelle. Son format est « libre » et se divise éventuellement en plusieurs contenus (contents).
La ligne initiale comporte quelques éléments d'information importants, mais c'est surtout la partie des en‑têtes qui recèle les paramètres techniques essentiels et dont le codage est une affaire de spécialistes. Préférentiellement, ces deux premières parties doivent être composées exclusivement en caractères US-ASCII, c'est‑à‑dire en ASCII restreint codé sur 8 bits (cf. chap. C3‑VIII C).
Format d'une requête HTTP/1.x
À titre d'illustration préliminaire, observons la requête HTTP/1.1 reproduite ci‑dessous, issue d'une navigation avec Firefox sur la page d'accueil de ce module de formation, c'est‑à‑dire à l'URL :
http://www.lycee-ferry-versailles.fr/snir/
À l'aide du logiciel Wireshark, on obtient le contenu de la requête sous forme de chaînes de caractères :
GET /snir/ HTTP/1.1\r\n Host: www.lycee-ferry-versailles.fr\r\n User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:107.0) Gecko/20100101 Firefox/107.0\r\n Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8\r\n Accept-Language: fr,fr-FR;q=0.8,en-US;q=0.5,en;q=0.3\r\n Accept-Encoding: gzip, deflate\r\n Connection: keep-alive\r\n Upgrade-Insecure-Requests: 1\r\n \r\n
Elle est seulement constituée de deux parties seulement :
- une ligne initiale (mise en gras),
- une série de 8 en‑têtes,
que l'on va détailler ci‑après. Elle s'achève par une ligne vide (séquence \r\n).
Ligne initiale d'une requête HTTP
La ligne initiale d'une requête (request line) comporte trois informations :
La méthode est toujours choisie par le client parmi une dizaine de méthodes différentes. Les deux plus usuelles sont les suivantes.
- La méthode
GETpermet au client d'obtenir la représentation de la ressource ciblée – c'est‑à‑dire son code, qu'il s'agisse d'une page web, d'une image, etc. (et il revient ensuite au serveur de fournir ce code). - La méthode
POSTpermet au client d'envoyer des données qui viennent s'insérer dans la ressource ciblée (et il revient ensuite au serveur de les réceptionner).
Pour la requête proposée dans l'exemple supra , à l'examen de la request line :
GET /snir/ HTTP/1.1\r\n
on déduit qu'il s'agit d'une méthode GET dont la cible est visée par le chemin (sur le serveur hôte de la ressource) :
/snir/
via le protocole HTTP en version 1.1.
Par ailleurs, dans le cadre de développements web, on peut être amené à coder des instructions qui mettent en œuvre d'autres méthodes de requêtes HTTP, notamment les suivantes.
- La méthode
HEADpermet au client de n'obtenir que la ligne initiale et les en‑têtes – et donc, pas de corps – dans la réponse du serveur pour la ressource ciblée. - La méthode
PUTpermet au client d'envoyer des données au serveur, soit pour ajouter une nouvelle ressource, soit pour remplacer la ressource ciblée. - La méthode
DELETEpermet au client de supprimer sur le serveur la ressource ciblée.
Pour une présentation exhaustive des méthodes de requêtes HTTP, on peut consulter le site de la Fondation Mozilla (on trouve sur cette page web les hyperliens vers les RFC en vigueur correspondantes).
En‑têtes d'une requête HTTP
Les en‑têtes d'une requête (request headers) sont une suite de spécifications de valeur(s) pour paramétrer la requête.
Individuellement, chaque en‑tête spécifie un seul paramètre, appelé champ (field).
Certains champs sont essentiels pour spécifier la requête, alors que d'autres peuvent n'avoir qu'un rôle informatif.
Un en‑tête se code selon la forme syntaxique suivante :
identificateur de champ : chaîne de spécification
sachant que la chaîne de spécification est différente pour chaque champ et peut être assez complexe.
Pour connaître les différents champs d'en‑tête standards et usuels d'une requête HTTP ainsi que des exemples de codage, on peut consulter un tableau récapitulatif via ce lien W avec, pour chaque champ, un renvoi vers la RFC qui le spécifie.
Dans la requête proposée en exemple supra , on trouve ainsi en 4e en‑tête :
Accept-Language: fr,fr-FR;q=0.8,en-US;q=0.5,en;q=0.3\r\n
Il spécifie que :
- le client accepte les contenus en langue française (
fr,fr-FR), américaine (en-us) et anglaise (en) ; - avec une préférence pour la langue française qui se voit implicitement attribuer la valeur de qualité
q=0.8(un poids) plus élevé que celui attribué aux langues américaine (en-us) et anglaise (en), respectivementq=0.5etq=0.3(cf. ce lien. ).
Corps d'une requête HTTP
Le corps d'une requête HTTP est présent seulement si la méthode met en œuvre un envoi de données au serveur (typiquement, avec une méthode POST).
Les caractéristiques du contenu du corps – taille en octets, type de données, etc. – sont spécifiés dans divers en‑têtes de la requête.
Le corps d'une requête forme un texte au sens large.
- Il est potentiellement grand (même si cela est rare pour une requête). En théorie (selon la norme), il n'y a pas de limite de taille, mais en pratique le corps est limité par un paramétrage du client.
- Éventuellement, le corps se compose de plusieurs parties. Ce cas est spécifié dans un en‑tête par le champ
content-typequi prend une valeur de la formemultipart. - Le corps peut être encodé dans divers formats possibles, celui qui est choisi étant spécifié dans plusieurs en‑têtes.
- Le champ
content-typespécifie le type de données contenues (texte, image, etc.) et son encodage (HTLM, PNG, etc.). - Le champ
content-encodingspécifie l'algorithme de compression employé avant la transmission.
Content-length dont la valeur indique le nombre d'octets contenus. Format d'une réponse HTTP/1.x
À titre d'illustration préliminaire, observons la réponse HTTP/1.1 délivrée par le serveur hébergeant la ressource demandée par la requête donnée en exemple supra .
HTTP/1.1 200 OK\r\n Date: Wed, 30 Nov 2022 10:04:29 GMT\r\n Server: Apache/2.4.23 (Win64) PHP/5.6.25\r\n Last-Modified: Thu, 01 Sep 2022 19:42:12 GMT\r\n ETag: "5b7-5e7a2cf5699e2"\r\n Accept-Ranges: bytes\r\n Content-Length: 1463\r\n Keep-Alive: timeout=5, max=100\r\n Connection: Keep-Alive\r\n Content-Type: text/html\r\n \r\n <!DOCTYPE html>\r\n <html lang="fr">\r\n \r\n <head>\r\n \t<title> BTS SNIR - Sommaire </title>\r\n \t<meta charset="utf-8">\r\n \t<link rel="stylesheet" type="text/css" href="css/main.css">\r\n \t<link rel="icon" type="image/png" href="img/faviconSNIR.png">\r\n </head>\r\n [...]
Cette réponse est constituée de trois parties seulement :
- une ligne initiale (mise en gras),
- une série de 9 en‑têtes,
- le corps de la réponse, qui contient comme prévu le code HTML de la page web d'accueil de ce module de formation.
Il s'agit bien évidemment du code HTML d'une page web.
Ligne initiale d'une réponse HTTP
La ligne initiale d'une réponse (response line) comporte deux informations :
- la version employée, exactement comme dans la ligne initiale d'une requête ;
- le code numérique à trois chiffres de statut de la réponse, assorti du libellé explicitant la signification du code.
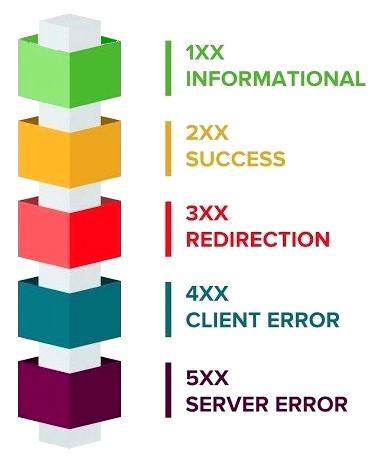
Grâce à sa valeur purement numérique, le code de statut permet de programmer facilement des tests, et des stratégies de requêtes alternatives en cas d'erreur ou de redirection.
Il existe une soixantaine de codes différents, classés en cinq catégories respectivement indiquées par le chiffre des centaines, conformément à la figure ci‑contre.
En particulier, le code 200 OK signifie que la requête a été traitée par le serveur avec succès (typiquement, la page web est chargée normalement).
Également connu, le code 404 NOT FOUND est classé dans la catégorie 4xx – client error parce qu'il découle le plus souvent d'une erreur dans l'URL spécifiée par le client – typiquement, un chemin mal orthographié ou ciblant une ressource non répertoriée sur un site existant.
En réalité, le code 404 est souvent employé par le serveur comme alibi pour ne pas révéler le vrai motif d'erreur.
Plus généralement, on peut trouver la liste exhaustive des codes de statuts aux liens suivants W .
En‑têtes d'une réponse HTTP
Comme dans une requête, les en‑têtes d'une réponse (response headers) sont une suite de spécifications de valeur(s) pour paramétrer la réponse – chaque en‑tête spécifiant un seul champ (field), avec parfois un rôle purement informatif.
Un en‑tête de réponse se code exactement selon la même forme syntaxique qu'une requête (cf. supra ).
En revanche, les identificateurs des champs et les valeurs qu'ils peuvent prendre sont spécifiques, on peut consulter le lien suivant pour connaître les champs d'en‑tête standards et usuels d'une réponse HTTP W.
Dans la réponse HTTP présentée supra , on trouve notamment l'en‑tête :
Content-Type: text/html; charset=UTF-8
Cet en‑tête informe le client que le corps (content) de la réponse envoyée par le serveur est constitué de texte ou de code HTML dont les caractères sont encodés au format UTF‑8.
Corps d'une réponse HTTP
Dans une réponse, le corps est en général présent, mais pas systématiquement.
Contrairement à une requête, ce n'est pas tant le type de méthode qui détermine la présence d'un corps dans le message, mais le statut de la réponse : en cas d'erreur, il n'y a en général pas de données à transmettre.
Comme pour une requête (cf. supra.), le corps d'une réponse forme un texte pouvant être codé dans tous types de format.
Dans la réponse HTTP présentée supra (cf. supra ), le corps est partiellement restitué (pour des raisons évidentes de place) :
<!DOCTYPE html>\r\n <html lang="fr">\r\n \r\n <head>\r\n \t<title> BTS SNIR - Sommaire </title>\r\n \t<meta charset="utf-8">\r\n \t<link rel="stylesheet" type="text/css" href="css/main.css">\r\n \t<link rel="icon" type="image/png" href="img/faviconSNIR.png">\r\n </head>\r\n [...]
Sans surprise, il est constitué comme prévu de texte codé en langage HTML.
Observation des messages dans la console d'un navigateur
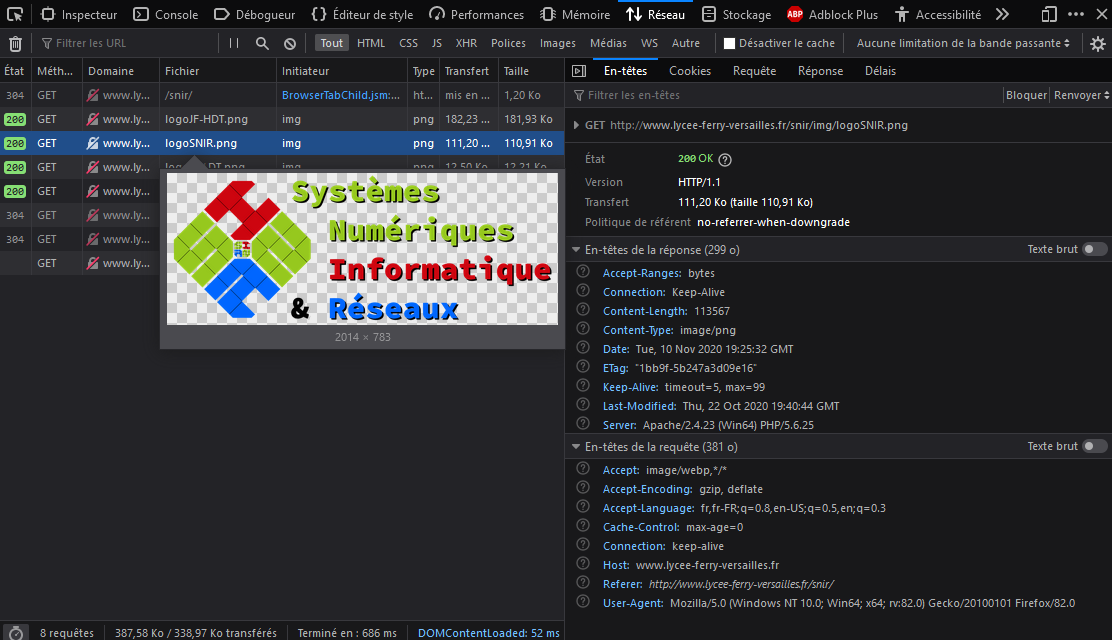
La console d'un navigateur (onglet ⇅Réseau sur Firefox) permet de lister et d'examiner le contenu des messages échangés entre le client et le serveur lors de l'accès à une page web.
En désactivant le cache (case à cocher dans la console), lors du chargement de la page d'accueil du site SNIR via l'URL suivante :
http://www.lycee-ferry-versailles.fr/snir/
on peut voir sur la capture d'écran ci‑dessous que l'ensemble des fichiers nécessaires (page web, feuille de style, images) sont obtenus avec succès (code 200) par la méthode GET.
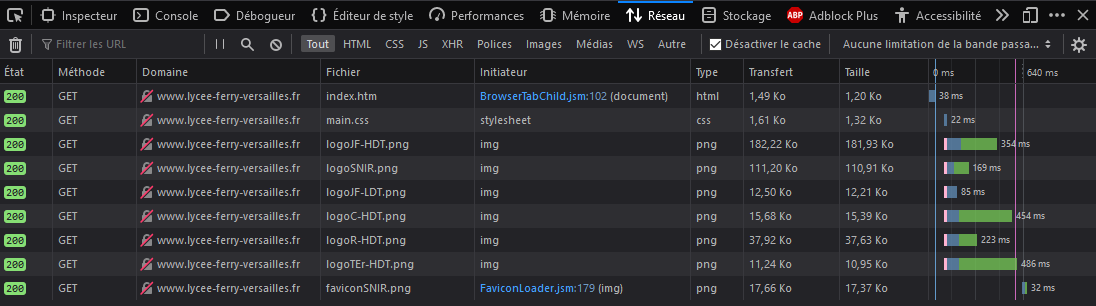
Tous ces appels de la méthode GET sont déclenchés lors de l'interprétation du code de la page par le traitement de balises HTML de type <img>, <link> ou autre…
Par ailleurs, en activant le cache et en réactualisant la page, on observe que certaines images sont obtenues avec le code 304 (libellé Not Modified). En effet, elles sont stockées dans la mémoire cache donc elles n'ont pas besoin d'être rechargées depuis le serveur.
Enfin, en cliquant sur la ligne d'un fichier d'image – ici, par exemple, logoSNIR.png – on peut voir ci‑dessous à droite le détail des en‑têtes de la réponse et de la requête.