Les services de messagerie font partie des applications les plus anciennes et les plus utilisées de l'Internet, et il en existe une grande diversité.
- Principalement, on a le service de courrier électronique ou courriel W, en anglais, e‑mail, abréviation de electronic mail, dont la francisation mel – pour « message électronique » – n'a pas vraiment réussi à concurrencer l'anglicisme direct.
- chez les fournisseurs de service, des machines dédiées pour le traitement et le stockage des courriels ;
- des logiciels dédiés, qu'on appelle clients et serveurs de messagerie ;
- des protocoles de communications spécifiques dans la couche application, à savoir essentiellement :
- SMTP (simple mail transfer protocol) pour l'envoi de courriels ;
- IMAP (Internet message access protocol) pour la réception et sauvegarde des courriels.
- Très largement utilisés également, mais d'usage moins formel, on trouve les services de messagerie instantanée W – en anglais, instant messaging abrégée IM. Plus anciens qu'on pourrait le penser (ils sont l'héritage de la commande talk W du système d'exploitation Unix), ces services reposent sur des architectures matérielles et logicielles différentes de celles du courriel. Ils ne seront pas abordés dans ce chapitre mais évoqués à nouveau au chapitre R2‑VIII dans le cadre de la notion de messsagerie unifiée.


Comme le web, le courriel est une application opérant sur les réseaux, massivement utilisée par le grand public, mais dont la complexité est souvent méconnue. Cette complexité s'est accentuée ces dix dernières années avec l'essor de la mobilité (ordinateurs portables, smartphones…) qui a multiplié le nombre de clients par utilisateur et fait émerger le besoin pour chaque utilisateur de « dématérialiser » le stockage des courriels.
Pour un technicien en informatique, une bonne connaissance des services de messagerie est indispensable Dans cet objectif général, ce chapitre développe dans l'ordre les points suivants :
- Il débute par une présentation générale qui apporte les éléments nécessaires pour effectuer des tâches simples comme paramétrer un logiciel client de messagerie.
- Il développe ensuite une description détaillée de l'architecture matérielle des services de messagerie, et les principaux protocoles d'émission et de réception des courriels.
- Il aborde enfin la problématique de l'encodage des courriels, qui est l'occasion de découvrir le standard MIME et différentes techniques transcodage – quoted‑printable, base64 – complémentaires avec celles étudiées dans le module de programmation (standard Unicode).
Ces aspects plus approfondis sont essentiels :
- non seulement pour la mise en place (installation et configuration) d'un serveur de messagerie dans un contexte professionnel élargi ;
- mais aussi pour le codage de scripts visant à automatiser des tâches de gestion des courriels (envois automatiques, gestion des indésirables, etc.) ;
- et enfin dans la perspective d'acquisition de la culture technique prérequise en matière de cybersécurité – les services de messagerie constituant un maillon crucial de la communication au sein des organisations, quelle que soit leur taille.
Généralités
Architecture simplifiée
Le service de courriel est basé sur un double modèle client‑serveur :
- l'un pour l'expéditeur
- un autre pour chaque destinataire d'un courriel.
Pour comprendre le principe de cette architecture, représentée de façon simplifiée sur la figure ci‑dessous (avec divers acteurs de l'Internet choisis à titre d'exemple), suivons les étapes de transmission d'un courriel depuis son expéditeur jusqu'à un destinataire unique. On ne tient pas compte ici des potentiels scénarios d'erreur : destinataire inconnus, compte supprimé, etc.
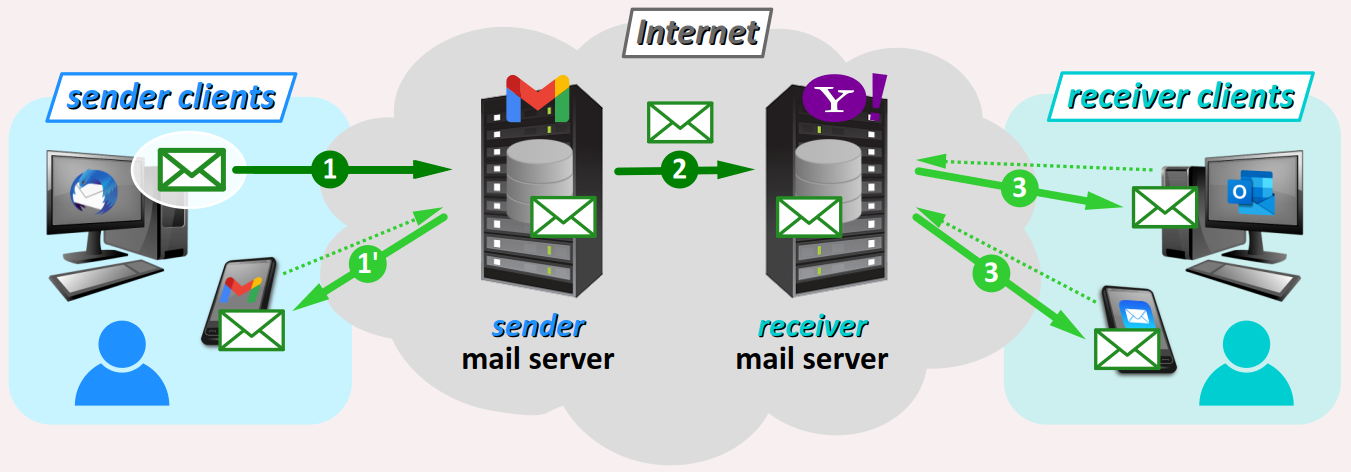
- Agissant comme client, un hôte de l'expéditeur (PC, smartphone…) transmet un courriel jusqu'au serveur de courriel auprès duquel il a souscrit à un compte de messagerie. Ce courriel est alors stocké dans une base de données, précisément dans le dossier
Envoyésde l'expéditeur. - Le serveur de courriel du compte de messagerie de l'expéditeur transmet ensuite le courriel au serveur de courriel auprès duquel le destinataire a souscrit son compte de messagerie.
- Agissant comme clients, les hôtes du destinataire font régulièrement des requêtes auprès du serveur de courriel pour savoir s'il y a des courriels à lui transmettre. C'est seulement alors que chacun reçoit le courriel envoyé par l'expéditeur.
Envoyés sur cet hôte. Attention ! Dans le processus décrit ci‑dessus, les étapes se déroulent évidemment dans l'ordre déterminé par leur numérotation 1‑2‑3. En revanche, il n'est pas possible de déterminer a priori l'ordre de délivrance du courriel aux différents clients (par exemple, l'étape 1' peut intervenir après l'étape 3).
Le choix de cette architecture se justifie par deux aspects déterminants.
- Elle ne requiert aucune synchronisation entre les machines hôtes respectives de l'expéditeur et du destinataire. Ces deux machines jouent toujours le rôle de client et n'ont donc aucun impératif de continuité de fonctionnement pour garantir le bon fonctionnement du service.
- Le choix d'un serveur de messagerie électronique – qui, lui, assure la continuité de service – peut être différent entre le destinataire et l'expéditeur. Autrement dit, l'envoi de courriels n'est pas limité aux clients d'un même serveur de messagerie.
Notion de fournisseur de messagerie
Un peu comme avec la notion de FAI pour l'accès au web (cf. chap. R1‑I ), on parle de fournisseur de messagerie électronique W – en anglais, email service provider ou ESP – pour désigner un organisme qui gère des serveurs de service de courriel pour des utilisateurs.
Dans la pratique, le choix d'un service de messagerie dépend principalement du statut social du client.
- Un particulier opte en général pour son FAI (Free, Orange, etc.), ou encore un grand acteur du web (Google, Yahoo, etc.).
- Une petite structure – entreprise ou autre organisme – qui fait appel à un hébergeur de données (OVH, Ikoula, etc.) peut négocier auprès de ce dernier la prise en charge de son serveur de courriel, avec à la clef la possibilité de disposer d'un nombre suffisant d'adresses et d'un nom de domaine personnalisé.
- Une grande structure ayant du personnel suffisamment qualifié peut avoir économiquement et techniquement intérêt à mettre en place son propre serveur de messagerie. Ce dernier n'est alors pas situé dans l'Internet comme sur la figure supra, mais dans un réseau local de l'entreprise ou de l'organisme, sur des serveurs accessibles depuis l'extérieur (en DMZ – cf. chap. R1‑II ).
La « démocratisation » des nano‑ordinateurs (Raspberry Pi, Odroid, etc…) permet aujourd'hui à une petite structure de mettre en place à moindre coût (acquisition de la carte et d'un disque dur, très faible consommation électrique de l'appareil) un serveur de messagerie interne.
Notion de compte et d'adresse de messagerie
Pour pouvoir utiliser le service de messagerie électronique sur l'Internet, il faut souscrire un compte de messagerie auprès d'un fournisseur de messagerie. Ce compte est constitué :
- d'une adresse électronique unique, rattachée à un nom de domaine hébergeant un serveur de messagerie ;
- d'un espace de stockage réservé sur un serveur du fournisseur de messagerie pour mémoriser et rendre en permanence accessibles à l'utilisateur ses courriels entrants, sortants et autres (brouillons, archives, poubelle…).
L'adresse électronique W d'un compte de messagerie est une chaîne de caractères composée de la forme :
partie locale @ nom de domaine
de telle sorte que la combinaison des deux chaînes de caractères de part et d'autre du symbole @ (prononcé usuellement « at » à par anglicisme) soit unique.
Lors de la souscription d'un compte de messagerie, le fournisseur de messagerie refuse automatiquement la création du compte si l'adresse est déjà répertoriée comme utilisée dans ses bases de données.
Le service de messagerie datant des premiers développement de l'Internet, les adresses ont dès le départ été composées exclusivement dans le jeu de caractères ASCII restreint (cf. chap. C3‑VIII C).
De plus, la partie locale obéit à des règles syntaxiques supplémentaires, formelles ou d'usage :
- le caractère
.usuellement employé comme séparateur ne doit être ni initial, ni final, ni réitéré à suite (la sous‑chaîne..est interdite) ; - usuellement, aucune distinction de casse n'est opérée, et il est d'usage d'écrire les adresses exclusivement en lettres minuscules ;
- les symboles employés comme préfixe ou séparateurs dans les URL sont à éviter (par exemple,
/ ? # &etc. – cf. chap. R2‑I ), même si aucune règle n'interdit formellement leur emploi.

Néanmoins, depuis 2012, il est possible de composer la partie locale d'une adresse dans le jeu de caractère Unicode en utilisant le format d'encodage UTF‑8 (cf. chap. C3‑IX C), notamment grâce à l'extension SMTPUTF8 du protocole de courriels sortants SMTP. Cette possibilité, appelée EIA – pour email address internationalization W – est appréciée dans les pays dont la langue ne s'écrit pas du tout en caractères latins – Chine, Japon, Ukraine, etc. Elle est davantage détaillée infra .
Quant au nom de domaine, rappelons qu'il peut être composé avec des caractères du catalogue Unicode grâce au mécanisme IDNA (internationalized domain names in applications) via un transcodage par l'algorithme Punycode (cf. chap. R2‑I ).
Par ailleurs, la partie locale n'est soumise à aucune contrainte d'identification de l'utilisateur. Autrement dit, on peut choisir n'importe quel nom, tant qu'il n'est pas déjà utilisé pour un autre compte sur le même domaine.
En revanche, pour une adresse professionnelle, il est recommandé d'adopter le format usuel :
nom . prénom
éventuellement suivi d'un numéro en cas d'homonymie. Cette convention facilite l'identification d'un expéditeur par son destinataire. De même, cela facilite les tentatives d'un expéditeur d'adresser un courriel à un destinataire dont il n'a pas l'adresse mais dont il connaît le nom et l'organisme pour lequel il travaille.
Solutions matérielles et logicielles
Clients de messagerie

Du côté de l'utilisateur, le service de messagerie électronique peut être mis en œuvre sur n'importe quel type de machine terminale, notamment un poste de travail, un smartphone, une tablette… Sur ces machines, de façon générale, il existe deux grandes solutions logicielles.
- On peut employer un logiciel client de messagerie W, c'est‑à‑dire une application dédiée à ce service qui s'exécute directement sur une machine hôte (par exemple, Microsoft Outlook, Mozilla Thunderbird…). On parle de client lourd.
- On peut aussi opérer par l'intermédiaire d'une messagerie web W (en anglais, webmail), c'est‑à‑dire une page web dynamique s'exécutant sur n'importe quel logiciel navigateur qui constitue une application web dédiée à ce service, mise à disposition du client par son fournisseur (par exemple, Gmail, Mail.one…). On parle alors de client léger.




La distinction entre les notions de client lourd et léger s'explique par le fait dans pour cette deuxième solution, il n'y a pas de transfert des courriels – ni entrant, ni sortants – entre la machine hôte de l'utilisateur et son serveur de messagerie. En effet, en règle générale, l'application webmail s'exécute sur une machine voisine de celle(s) qui héberge(nt) les autres des composants logiciels nécessaires au service de messagerie (serveurs d'échange, de stockage) – avec à la clef des temps de transferts réduits au minimum.

Il est également possible d'embarquer un client de messagerie « minimal » sur une architecture matérielle très réduite, comme une box domotique (cf. chap. R3‑V ), une caméra IP, ou même une carte à microcontrôleur, dès lors que cette dernière dispose d'un accès au réseau (Ethernet, Wi‑Fi…). Cela permet notamment d'envoyer des courriels d'alerte ou d'information
La solution logicielle est alors également réduite, puisque ces machines n'ont pas d'interface d'homme‑machine ; leur fonctionnalité se limite à l'envoi de courriels (pas de réception). L'installation se fait via un plugin à paramétrer ou une bibliothèque de fonctions à exploiter dans le programme utilisateur.
Serveurs de messagerie

Dans la très grande majorité des cas, un serveur de messagerie est implémenté sur une machine de type serveur, comme pour le web, sans spécificité particulière. D'ailleurs, dans les petites configurations, le service de messagerie et le service web sont souvent hébergés sur la même machine (ou seulement séparés par virtualisation). On se reportera donc au chapitre R2‑IV pour consulter les détails sur ces aspects matériels.
Quant aux solutions à grande échelle, notamment celles choisies par les fournisseurs de messagerie, elles privilégient :
- les SSD comme solutions de stockage pour diminuer les temps d'accès, et impérativement avec des technologies de redondance (cf. chap. R2‑V ) ;
- suffisamment de RAM pour supporter toutes les mises en cache des listes de courriels et les fichiers volumineux de filtrage de spam ;
- des connectivités à très haut débit comme la technologie fibre channels (cf. chap. R2‑V ).
En revanche, la partie logicielle est évidemment complètement spécifique et c'est cela qu'on entend lorsque l'on parle de serveur de messagerie W. Peu connus du grand public, ces applications sont principalement développées pour s'exécuter sous Linux ou équivalents (Unix, BSD). Basées sur des standards ouverts, elles sont le plus souvent open source et libre de droits. Elles forment une pile logicielle dont chaque composant est dédié soit à un protocole, un agent ou une fonctionnalité spécifique : anti‑span, anti‑virus, etc.
Parmi les logiciels serveurs de messagerie les plus populaires, on peut notamment citer les suivants.
- On a les serveurs de courriels sortants ou agents de transfert (MTA – cf. infra ) comme Postfix W (licence publique IBM et Eclipse), Exim W (licence publique GPL) ou encore SendMail W.
- On a les serveurs de courriels entrants IMAP/POP3 comme Dovecot W (licences publiques MIT et GPL – 78 % des parts de marché) ou Cyrus W (licence publique Carnegie Mellon University).







Protocoles de messagerie électronique

Quelles que soient les solutions logicielles retenues, la transmission de courriels fait appel à des protocoles de communication applicatifs (appartenant à la couche nº 7 du modèle OSI) de type client‑serveur :
- SMTP W (simple mail transfer protocol) pour les courriels sortants – c'est‑à‑dire émis par le client ;
- POP W (post office protocol) ou IMAP W (Internet message access protocol) pour les courriels entrants – c'est‑à‑dire reçus par le client.
La connaissance de ces sigles est indispensable pour savoir paramétrer correctement un client de messagerie.
Pour les courriels entrants, le protocole IMAP, plus récent que POP, est devenu le choix privilégié par les usagers (et le choix par défaut des clients de messagerie), en raison de la synchronisation qu'il met en œuvre entre les différents hôtes clients pour un même compte de messagerie. Avec ce protocole, toutes les actions sur les courriels du compte de messagerie (envoi, suppression, création de dossiers, classement, etc.) depuis un client sont répercutées à l'ensemble des autres clients. Il en résulte que :
- cela facilite la gestion du compte ; en particulier, il n'est pas nécessaire de supprimer un message périmé ou indésirable sur chacun des clients ;
- mais cela diminue la robustesse aux erreurs – par exemple, après avoir vider la corbeille sur l'un de ses clients de messagerie, un usager ne peut plus récupérer son contenu sur un autre client.
La synchronisation des clients d'un même compte de messagerie opérée par le protocole IMAP procède de la manière suivante :
- Les courriels entrants sont conservés sur le serveur. Lorsqu'un client y accède, il en reçoit une copie dans sa boîte de réception. De cette manière, l'accès au message reste possible :
- sur le client en mode hors connexion ;
- sur les autres clients dès lors qu'ils se connectent au serveur, sachant que le message est alors marqué comme « lu » (sous couvert des délais de synchronisation).
- Chez un client, le déplacement d'un courriel de la boîte de réception vers la corbeille ou tout autre dossier synchronisé – spam, etc. – est transmise au serveur, qui répercute aussi cette commande chez les autres clients. Ainsi, il n'est pas nécessaire de répéter ce genre opération pour chaque client. Idem pour le vidage de la corbeille.
Ports logiciels utilisés
Les protocoles de messagerie utilisent théoriquement des ports standards : le nº 25 pour SMTP et le nº 143 pour IMAP – cf. chap. R1‑IV . Mais dans la pratique, dès lors que l'on fait appel à un système de chiffrement (SSL/TLS par exemple) ou qu'on utilise diverses possibilités offertes par un client de messagerie, d'autres numéros de port sont requis, avec en général :
- le nº 587 (chiffrement en mode explicite) ou le nº 465 (chiffrement en mode implicite) pour SMTPS (cf. infra );
- le nº 993 pour IMAPS (chiffrement en mode implicite) (cf. infra ).
Ces valeurs sont utiles à connaître pour configurer un client de messagerie, même si de plus en plus, elle sont automatiquement renseignées par les logiciels grand‑public (Thunderbird, Outlook, etc.) dans leur interface fenêtrée de configuration.
Sauf exception, le port nº 25 est tout simplement bloqué par les FAI pour empêcher la submersion des comptes de messagerie (et donc des serveurs…) par du spam W. Aujourd'hui, il n'est utilisé qu'entre les relais SMTP où le flux de courriels est déjà expurgé d'une grande partie du spam.
Constitution d'un courriel
Un courriel est un objet potentiellement complexe. Il est toujours divisé en deux sections.
- La première section est l'en‑tête (header), qui est un texte constitué une suite de champs, chacun codé de la forme :
nom: valeur
Certains champs –From:(expéditeur),To:(destinataires),Subject:(sujet) – ont leurs valeurs respectives spécifiées par l'utilisateur lors de la composition du courriel ; les autres champs –Date:,Message-ID:, etc. (il y en a beaucoup !) – sont automatiquement déterminés par le client ou les serveurs de messagerie participant à son transfert. - La deuxième section est le corps (body), qui forme le contenu du message à proprement parler et qui peut inclure toutes sortes de données (texte avec ou sans mise en forme, images, vidéos, etc.).
Sur un client de messagerie ou une page webmail, les noms des champs sont souvent traduits et explicités dans la langue de l'interface utilisateur. Néanmoins, on les trouve parfois dans leur format original, en particulier les deux suivants :
- Le champ
cc:, qui signifie carbon copy pour faire référence au procédé ancien de duplication d'un document W, permet de mettre un ou plusieurs destinataires en copie – au sens où ils ne sont pas considérés comme faisant partie des destinataires directs du courriel. - Le champ
bcc:, qui signifie blind carbon copy (en français, « aveugle »), permet la transmission d'une copie du courriel à des destinataires invisibles par les autres destinataires (d'où le sigle françaiscci:pour copie carbone invisible).
Remarque. Lorsqu'un courriel est adressé seulement à des destinataires en copie cachée (donc, invisibles), le terme undisclosed recipients (en français, « destinataires confidentiels ») apparaît à la réception dans le champ destinataire. C'est un procédé commode pour les listes de diffusion réunissant des publics qui n'ont pas à connaître mutuellement leurs adresses.
Architecture détaillée et protocoles
Schéma de principe et composants logiciels
Pour des motifs évidents de pédagogie, le schéma de principe du service de courriel présenté supra n'est pas détaillé. Mais pour un futur technicien réseau, il est nécessaire de connaître et situer les différents processus à l'œuvre – des composants logiciels s'exécutant en tâche de fond.
Sur la figure ci‑dessous, l'architecture n'est détaillée que pour un seul utilisateur et son fournisseur de service de messagerie (ESP – email service provider). Il faut imaginer une architecture potentiellement symétrique chez un autre utilisateur, l'un comme l'autre pouvant jouer le rôle d'expéditeur et de destinataire.
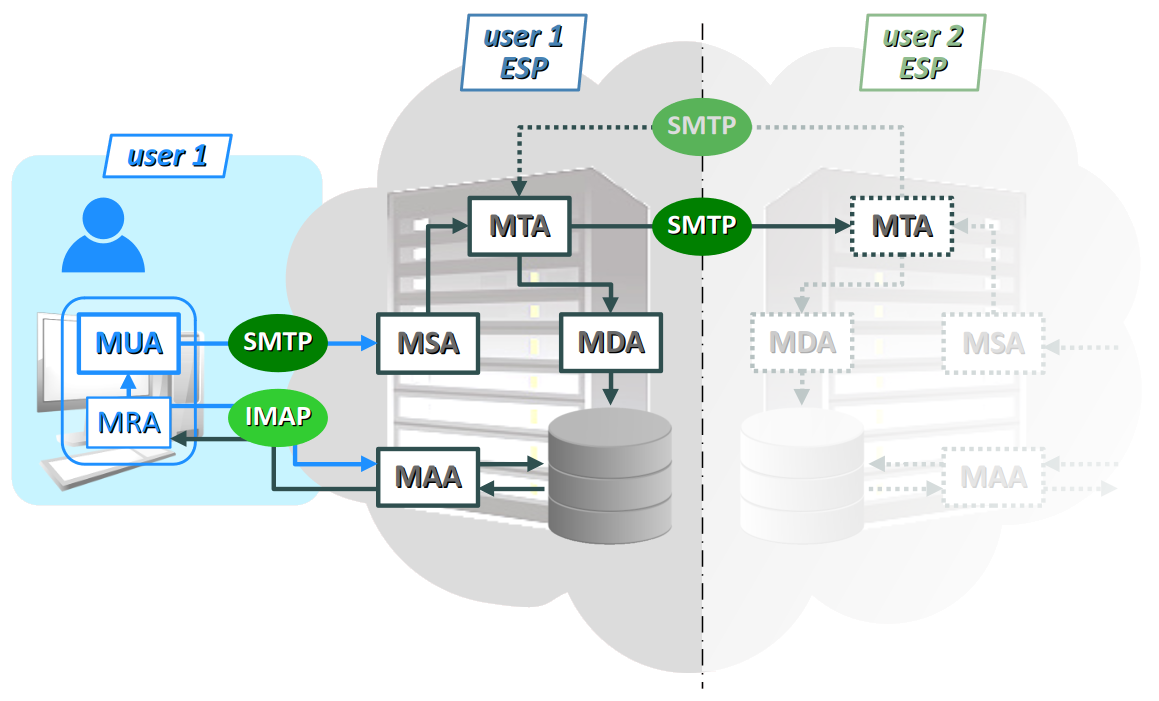
La complexité de cette architecture découle de plusieurs facteurs :
- les gigantesques volumes de données que représentent aujourd'hui les courriels des utilisateurs stockés sur les serveurs, du fait des protocoles synchronisés majoritairement utilisés ;
- la nécessité pour les fournisseurs de services de mettre en œuvre des dispositifs de filtrage pour diminuer l'impact des spams W sur le trafic et les données stockées sur l'Internet.
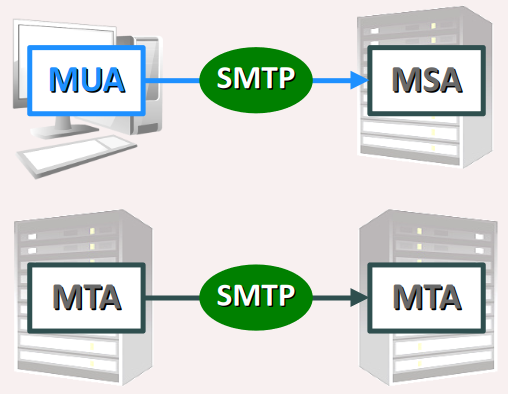
Les composants logiciels intervenant dans le service de courriels sont désignés par des sigles de trois lettres, commençant tous par « M » pour mail ou message, et se terminant tous par « A » pour agent.
- Un MUA W ou mail user agent désigne aussi bien un logiciel client de messagerie qu'une page de messagerie web. Hébergée sur une machine hôte d'un réseau local, ce composant agit comme client pour le protocoles SMTP. C'est également lui qui assure l'encodage, le transcodage et de décodage des courriels conformément au standard MIME (cf. infra ).
- Un MRA W ou mail retrieval agent est un composant intermédiaire pour la récupération des courriels d'un utilisateur depuis le serveur de son fournisseur de messagerie. Il agit donc comme client pour les protocoles IMAP ou POP3. Il est intégré dans la même application que le MUA (client de messagerie ou messagerie web).
- Un MSA W ou mail submission agent, exécuté sur un serveur, joue le rôle d'intermédiaire entre le MUA et le MTA du fournisseur de service de messagerie du client expéditeur.
- Un MTA W ou mail transfer agent, très souvent intégré à la même application que celle qui exécute le MSA, a pour rôle de router les courriels entrants et sortants à destination des autres serveurs de messagerie.
- Un MDA W ou mail delivery agent est charger d'alimenter la base de données des courriels des utilisateur, entrants comme sortants.
- Un MAA ou mail access agent est un composant exécuté sur serveur qui sert à accéder à la base de données des courriels pour répondre aux requêtes de consultation et de manipulation émises par les MRA des clients de messagerie.
Enregistrement des serveurs de messagerie
Comme tout nom de domaine de l'Internet, le nom de domaine d'un service de messagerie (cf. supra ) doit :
En fait, conformément à la RFC 1035 , les noms de domaine des comptes de messagerie font l'objet d'enregistrements DNS spécifiques, de type MX W – pour mail exchanger – dont le champ Rdata se décompose en :
- preference – également appelé priority – à savoir un entier positif d'autant plus petit que la préférence à accorder au serveur enregistré dans le champ host est grande (c'est donc un nombre qu'on peut lire comme une distance, à minimiser).
- exchange – également appelé host – à savoir un nom de domaine de serveur de messagerie faisant l'objet d'un enregistrement DNS (RR) de type
AouAAAA(pas de typeCNAME, conformément à la RFC 1035 ).
Avoir plusieurs enregistrements MX pour un même nom de domaine de service de messagerie est une pratique très courante qui permet de garantir la continuité de service avec une redondance de serveurs. Si un serveur est en panne, un autre est enregistré pour prendre le relais et recevoir les courriels envoyés via le protocole SMTP.
Le domaine ac-versailles.fr des adresses professionnels du personnel de l'Académie de Versailles fait l'objet de 2 enregistrements MX, comme le montre la réponse obtenue à la commande dig (cf. chap. R2‑I ), partiellement reproduite ci‑dessous :
dig ac-versailles.fr MX[…] ;; ANSWER SECTION: ac-versailles.fr. 300 IN MX 10 msg-a85.education.gouv.fr. ac-versailles.fr. 300 IN MX 20 msg-b85.education.gouv.fr. […]
Les deux noms de domaines msg-a85.education.gouv.fr et msg-b85.education.gouv.fr figurant comme valeurs du champ exchange correspondent respectivement aux serveurs de messagerie principal (preference 10) et secondaire (preference 20) de l'Académie. On peut facilement vérifier qu'ils sont eux‑mêmes des noms de domaine enretistrés, grâce à la commande host :
host msg-a85.education.gouv.frmsg-a85.education.gouv.fr has address 194.254.206.85host msg-b85.education.gouv.frmsg-b85.education.gouv.fr has address 193.54.151.85
Le protocole de courriels sortants SMTP

Le protocole SMTP W (simple mail transfer protocol) est un protocole applicatif pour l'émission de courriels. Il est utilisé par pratiquement tous les logiciels clients de messagerie (plus précisément, leur MUA), ainsi que par les agents relais SMTP des serveurs d'échanges de courriels (MSA, MTA, MDA – cf. supra ).
Développé au début des années 1980 (RFC 821 ), le protocole SMTP est maintenant basé sur la RFC 5321 publiée en 2008. Parce que les courriels sont potentiellement volumineux et que leur intégrité est cruciale, il recourt au protocole de transport TCP (cf. les chap. R1‑V et R3‑I ) qui est le mieux adapté – comme pour la transmission de fichiers via FTP, de pages web via HTTP, etc.
Rappel (cf. supra ). Le protocole SMTP utilise par défaut le port nº 25 (mais aujourd'hui, exclusivement entre serveurs) et, dans sa version sécurisée par chiffrement TLS, ou bien le port nº 587 (en mode explicite), ou bien le nº 465 (en mode implicite).
Outre le recours à TCP, le protocole SMTP présente plusieurs similitudes avec le protocole HTTP :
- Il opère selon un modèle client‑serveur :
- typiquement entre le MUA (mail user agent) d'un client de messagerie et le MSA (mail submission agent) d'un serveur de messagerie ;
- mais aussi entre les MTA (mail tranfer agents) respectifs de deux serveurs de messagerie, l'un jouant le rôle de client (le serveur du compte de messagerie expéditeur), l'autre celui de serveur (le serveur du compte de messagerie destinataire).
- Il opère en mode texte au sens où, à la manière du protocole HTTP 1.1 (cf. chap. R2‑III ), il met en œuvre un flux d'échanges de lignes de caractères (chacune de longueur limitée, terminée par un saut de ligne
\r\n) et non pas des messages formatés et codés en tableaux d'octets comme avec les protocoles DHCP, NTP, TCP, etc. - Il utilise des codes numériques pour les réponses du serveur, comme résumés sur le figure ci‑contre (cf. par exemple ces pages web pour plus de détails W ).
-
250pour requested mail action okay (OK) ; -
354pour start mail input (go ahead) ; -
452pour requested action not taken: insufficient system storage ; -
550pour requested action not taken: mailbox unavailable ;

\r\n.\r\n pour marquer la fin de la transmission. 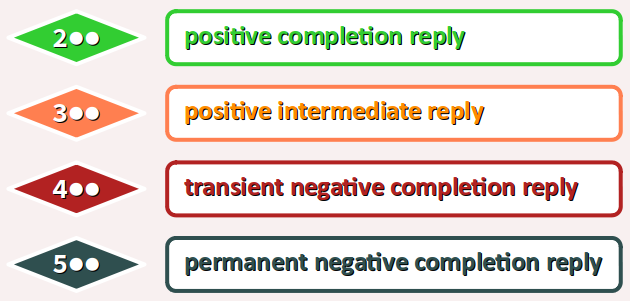
Mais par ailleurs, le protocole SMTP présente plusieurs spécificités. En particulier, c'est un protocole à états – en anglais, stateful – et orienté connexion (indépendamment de la connexion établie préalablement via le protocole TCP).
- On parle de session SMTP pour désigner la succession d'échanges de données entre le client et le serveur pour l'envoi d'un courriel.
- Une session met en œuvre un nombre a priori indéterminé de transactions SMTP, chacune consistant en une séquence de requêtes/réponses formant un flot de ligne de textes échangées entre le client et le serveur, qu'on peut voir comme des « messages SMTP ».
- On parle préférentiellement de commande pour désigner une requête du client, dont les plus usuelles sont celles décrites ci‑dessous :
-
HELO(avec un seul «L» pour respecter un format de commande à 4 lettres) suivi de l'adresse IP ou du nom de domaine du client (qui, rappelons‑le, peut être un serveur) ; -
MAILsuivi de l'adresse de courriel de l'émetteur (FROM) – cet argument étant appelé le return path du courriel ; -
RCPTsuivi de l'adresse de courriel de destinataire (TO) – cet argument étant appelé un forward path du courriel (il faut réitérer cette commande pour chaque destinataire, qu'il soit direct ou en copie) ; -
DATApour ensuite envoyer les données, c'est‑à‑dire le courriel lui‑même (en‑tête et corps), ainsi que le signal de fin de transmission (la séquence\r\n.\r\n) -
QUITpour terminer la session SMTP (lorsque le client n'a plus aucun message à envoyer).
503 Bad sequence of commands
C'est notamment en ce sens que SMTP est un processus à états.
Remarques.
- Les commandes
MAIL FROMetRCPT TOassociées à leurs arguments respectifs (adresses d'emission et de destination) constituent ce qu'on appelle l'enveloppe d'un courriel sortant pris en charge par le protocole SMTP, à l'image de ce qui est usuellement inscrit sur l'enveloppe d'un courrier traditionnel. - Pour éviter tout possibilité d'interprétation erronée du signal de fin de transmission par une éventuelle ligne de texte formée d'un seul caractère «
.» contenue dans un courriel (formant, avec le saut de ligne précédent, une séquence\r\n.\r\n), le protocole SMTP met en œuvre une technique dite de dot‑stuffing : lors de l'émission des données (commandeDATA), toute ligne de texte commençant par le caractère «.» se voit ajouter un «.» initial supplémentaire, qui est évidemment supprimé à la réception.

Mode étendu (ESMTP)
Conformément à la RFC 2821 , un client peut initier le protocole SMTP en mode étendu noté ESMTP (pour extended SMTP) en employant, à la place de HELO, la commande EHLO (pour « extended HELO »).
Le mode étendu permet au client d'utiliser un jeu étendu de commandes et d'attributs. Pour cela, le serveur répond en indiquant ses capacités et extensions, typiquement 8BITMIME (cf. infra ), SMTPUTF8 (cf. infra ), PIPELINING, etc.
Parmi les commandes spécifiques du mode étendu, on peut citer notamment :
-
SIZEpour demander au serveur d'indiquer la taille maximale des messages qu'il accepte (cf. la RFC 1870 ) ; -
AUTHpour indiquer au client, en réponse à une commandeEHLO, les méthodes d'authentification qu'il prend en charge ; cette commande permet aussi au client d'initier une procédure d'authentification (cf. la RFC 4954 ) ; -
STARTTLS(une des rares commandes de plus de 4 lettres) pour indiquer au client, en réponse à une commandeEHLO, que le serveur prend en charge le protocole de chiffrement TLS en mode explicite (cf. chap. R1‑IV ) ; -
VRFYpour vérifier la validité d'une adresse auprès du serveur ; - etc.

Pour plus de détails, outre les RFC, on pourra consulter cette page web consacrée aux commandes du protocole SMTP
Exemple de scénario SMTP
On expérimente ici l'envoi d'un courriel par le MUA (mail user agent) d'un client de messagerie comme Thunderbird dont le compte utilisé est ouvert chez un fournisseur de service comme Google Mail. Ce courriel est donc pris en charge par le MSA (mail submission agent) d'un serveur SMTP du fournisseur. Les deux agents sont représentées respectivement à gauche et à droite sur la figure ci‑dessous.
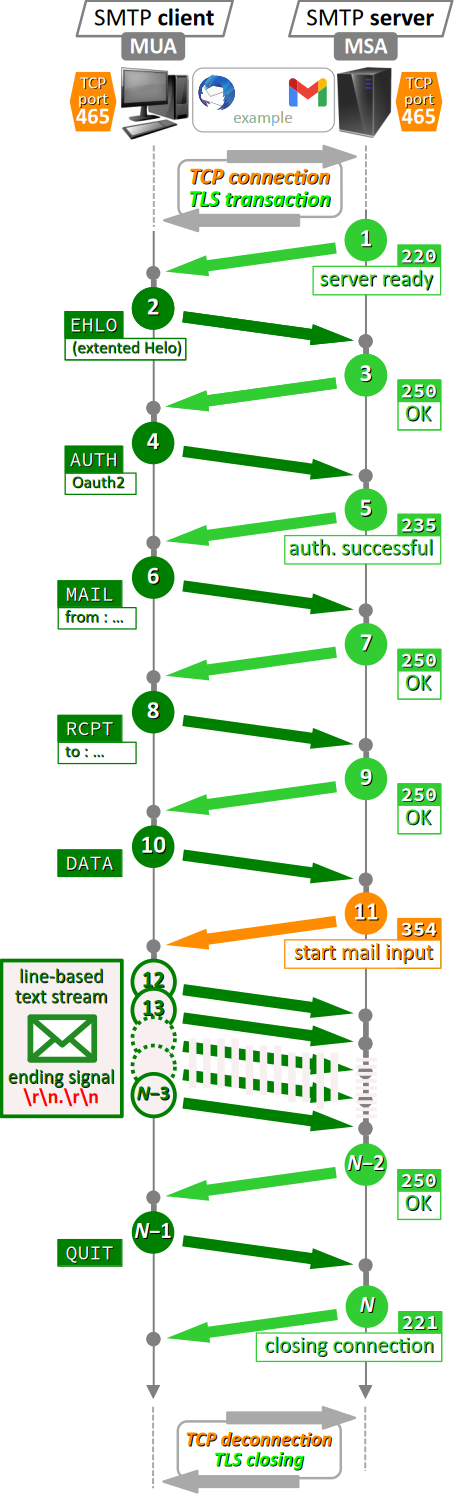
- Le fournisseur de service impose le protocole de chiffrement TLS en mode implicite donc :
- tous les messages sont transportés par le protocole TCP sur le port nº 465 ;
- l'échange de message est précédé par la phase de connexion TCP (three‑way handshake – cf. chap. R3‑I ) et l'initialisation de la session TLS W.
- Contrairement à l'intuition qu'on pourrait avoir, le premier message SMTP est envoyé par le serveur pour indiquer au client qu'il est prêt (server ready, code
220). - Le client envoie alors successivement les commandes suivantes :
-
EHLOpour initialiser le protocole avec le jeu étendu de commande ; -
AUTHpour s'authentifier en tant que détenteur du compte de messagerie utilisé ; - En cas de réponse positive à l'authentification (authentication successful, code
235), le protocole se poursuit avec la constitution de l'enveloppe du courriel (cf. supra ) : - La commande
MAIL (from)détermine l'adresse d'expéditeur, car plusieurs adresses différentes sont parfois associées au même compte de messagerie. Cette adresse définit aussi ce qu'on appelle le return‑path, c'est‑à‑dire l'adresse utilisée pour un éventuel accusé de réception ou encore une notification de non‑délivrance. - La commande
RCPT (to)détermine l'adresse de réception c'est‑à‑dire de destination du courriel. - En cas de réponses positives (OK, code
250) du serveur aux commandes précédentes, le client peut alors envoyer la commandeDATApour signaler qu'il s'apprête à transmettre le courriel lui‑même. Le serveur répond alors par un message start mail input, code354pour signifier qu'il est prêt. - Le courriel (en‑tête, corps et pièces jointes) est donc envoyé comme un flux de lignes de texte terminé par la séquence de fin de transmission
\r\n.\r\n. Mais, si le volume des données dépasse la MTU du lien local (maximum transmission unit, environ 1500 octets – cf. chap. R3‑I ), le flux apparaît alors fragmenté en plusieurs paquets du fait de sa prise en charge par le protocole de transport TCP. - Après la réponse positive (OK, code
250) du serveur, consécutive à la bonne et complète exécution de la commandeDATA, le client peut procéder à l'envoi d'un autre courriel (s'il y en a un dans la file d'attente du client de messagerie) ou sinon signifier la fin d'envoi par la commandeQUIT, que le serveur confirme normalement par un message closing connection, code221.
250), ce dernier indique dans la foulée ses capacités et les extensions qu'il prend en charge, ce qui permet par la suite au client d'adapter le transcodage du courriel conformément au standard MIME (cf. infra ) ; 
OAUth2 W formaté en json et encodé en base64 (cf. infra ), qui met en œuvre une délégation d'autorisation.


Parce qu'il est systématiquement sécurisé par TLS, les messages du protocole SMTP sont chiffrés. Pour pouvoir les capturer avec Wireshark (cf. chap. R1‑IV ), il est nécessaire d'employer une procédure spécifique, qui est la suivante pour un poste de travail sous Linux.
- Dans un terminal de commandes en ligne, créer un répertoire personnel de l'utilisateur pour stocker les journaux (log files) du protocole TLS, et dans ce répertoire, créer un fichier de log dédié à l'application Thunderbird :

mkdir -p ~/tlstouch ~/tls/thunderbird_keys.log
SSLKEYLOGFILE le chemin vers le fichier de log précédemment créé, puis lancer en tâche de fond l'application Thinderbird depuis le terminal (et non pas depuis le bureau) pour qu'elle bénéficie de ce paramétrage : export SSLKEYLOGFILE=~/tls/thunderbird_keys.logthunderbird &
Edit/Preferences/Protocoles/TLS
et dans la fenêtre de paramétrage ainsi ouverte, renseigner le champ :
(Pre)-Master-Secret log filename
en lui affectant le chemin d'accès au fichier de log précédemment créé, c'est‑à‑dire :
~/tls/thunderbird_keys.log
-
smtppour l'affichage ; -
tcp port 465pour la capture.
Il suffit alors de lancer la capture puis d'envoyer un courriel pour voir s'afficher dans Wireshark les paquets SMTP échangés entre le client de messagerie Thunderbird et le serveur du fournisseur de service, comme par exemple ceux listés sur la figure ci‑dessous, qui correspondent au scénario décrit supra.
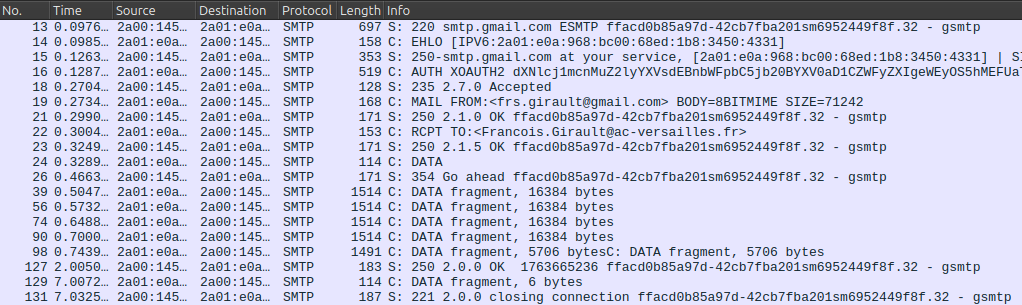
Notons enfin que, dans ce listing de capture, certains aspects peuvent n'être pas immédiatement explicites. Par exemple, il faut explorer avec Wireshark les détails du paquet 129 pour s'apercevoir qu'il contient en fait la commande QUIT (ce n'est pas à proprement parler un « DATA fragment »).
Enfin, une fois que l'expérience est terminée, il est recommandé d'écraser le fichier de log avec une commande spéciale qui rend sa récupération impossible même avec des moyens avancés. Typiquement, on peut y parvenir en saisissant la commande :
shred -u ~/tls/thunderbird_keys.log
Le protocole de courriels entrants IMAP

Le protocole IMAP W (Internet message access protocol) est un protocole applicatif pour la réception de courriels, utilisé exclusivement par les clients lourds de messagerie. Contrairement au protocole POP (post office protocol, maintenant relativement désuet), il permet la synchronisation entre plusieurs clients du même compte de messagerie.
Inventé en 1986, le protocole IMAP a connu considérablement évolué dans les années 1990. Il est aujourd'hui implémenté dans sa version 4. Il essentiellement spécifié par :
- la RFC 3501 de 2003 (v4rev1) qui est, aujourd'hui encore, un standard largement répandu ;
- d'autres RFC qui apportent des extensions importantes comme
IDLE(mode attente, RFC 2177 ),UNSELECT(RFC 3691 ) ou encoreUIDPLUS(RFC 4315 ) ; - la RFC 9051 de 2021 (v4rev2) qui est rétrocompatible avec la v4rev1, qui intègre la plupart de ses extensions et qui apporte une syntaxe moderne.
Pour les mêmes raisons que SMTP, IMAP recourt au protocole de transport TCP pour la transmission des données.
Rappel (cf. supra ). Le protocole IMAP utilise par défaut le port nº 143, et le port nº 993 dans sa version sécurisée par TLS en mode implicite (IMAPS). Quant à la sécurisation en mode explicite, elle est mise en œuvre sur le port nº 143 à l'aide de la commande STARTTLS (cf. infra ).
Le protocole IMAP présente un certain nombre de points communs avec SMTP :
- C'est bien évidemment un protocole client‑serveur, entre le MRA (mail retriever agent) d'un client de messagerie et le MAA (mail access agent) d'un serveur de messagerie.
- Il opère aussi en mode texte avec des requêtes à base de commandes (usuellement présentées en majuscules) du client et des réponses du serveur formatées en lignes, séparées les unes des autres par des séquences
\r\n(sauts de ligne). - Et c'est aussi un protocole à états (stateful ) tel que les commandes invoquées par le client doivent respecter un certain ordre d'exécution.
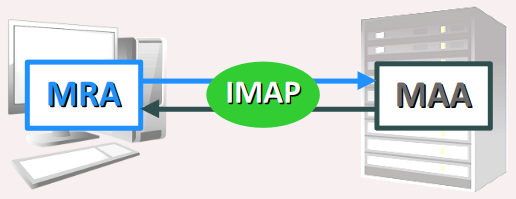
Mais par ailleurs, le protocole IMAP présente des différences significatives avec SMPT, notamment les suivantes.
- On a d'une part une finalité opposée puisqu'il s'agit pour le client, non pas d'expédier mais de recevoir des courriels, sachant que leur réception sur le serveur sont des événements inopinés. Les états d'une session du protocole IMAP sont donc dédiés, non pas à cadencer des étapes d'une transaction, mais à mémoriser le contexte du client au gré des commandes qu'il envoie au serveur (par exemple, la boîte au lettre sélectionnée, le mode attente, etc.).
- Techniquement, il n'y a pas de codification numériques des réponses du serveur mais des mots‑clefs comme
OK(succès),NO(échec),BAD(erreur). - Les requêtes du client font l'objet d'une identification par étiquettes auxquelles les réponses du serveur se référent pour faciliter le débogage éventuel du processus (car ces réponses peuvent parvenir au client dans un ordre différent de celui des requêtes).
- Enfin, bien plus qu'en SMTP, tout serveur IMAP est en interaction fréquente avec la base de données dans laquelle sont organisés les courriels des clients. Pour optimiser les commandes de recherche et de manipulation, le protocole IMAP introduit les concepts suivants :
- Les courriels sont dotés de drapeaux (en anglais, flags – cf. chap. C3‑III ) pour signaler leur état, par exemple :
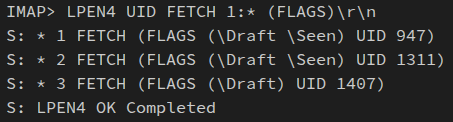
\Recentpour « récent »,\Seenpour « vu », etc. Sauf exception, ils sont accessibles en lecture et écriture par le client. - Dans une boîte aux lettres, tout courriel est identifié par son numéro de séquence, c'est‑à‑dire un entier qui exprime son ordre d'arrivée par valeurs croissantes (le plus récent portant donc le numéro de séquence le plus élevé) – cf. la capture d'écran ci‑contre d'une commande IMAP pour lister tous les courriels dans le dossier « Brouillons » préalablement sélectionné.
NDKF0, NDKF1, NDKF2, etc. *, synonyme de réponse non achevée, et terminée par une ligne de validation qui commence par l'étiquette de la requête et qui indique le statut de la réponse, par exemple : NDKF0 OK completed
ou encore :
NDKF0 BAD Missing required argument

\HasChildren pour « a un ou des dossiers » ou \Noselect pour « non sélectionnable ». Sauf exception, les attributs de boîtes aux lettres sont accessibles en lecture seule par le client (la modification d'un attribut de relève du fonctionnement interne du serveur). 1) se traduit naturellement par le prédicat =true, mais le contraire – à savoir, l'absence (valeur binaire 0) – peut s'interpréter par deux prédicats possibles : =false ou =unknown. 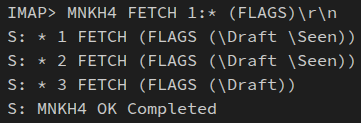
Commandes du protocole IMAP
Par rapport à SMTP, le protocole IMAP fournit au client une plus grande variété de commandes, que l'on peut classer de la manière qui suit (la liste n'étant pas exhaustive, afin de ne pas alourdir inutilement l'exposé).

Ces commandes peuvent être testées dans un terminal grâce à un programme de client IMAP codé en langage Python, dont les fichiers sources sont téléchargeable au lien suivant .
C'est précisément ce programme qui est exploité dans les exemples proposés ci‑après, en interaction avec le serveur IMAP d'un compte de messagerie académique.
- Session, authentification :
-
CAPABILITYdemande les caractéristiques du serveur. -
IMAP4rev1qui donne la version du protocole pris en charge ; -
ACLqui précise que le serveur prend en charge les listes de contrôle d'accès (access control list) avec la gestion des droits d'accès aux dossiers de classement des courriels ; -
QUOTAqui indique que le serveur prend en charge l'extension QUOTA (cf. la RFC 9208 ) permettant à l'utilisateur de demander les informations de capacité de stockage de son compte (espace occupé/libre) ; - etc.
-
STARTTLSdemande au serveur d'engager une client négociation pour ouvrir une session du protocole de chiffrement TLS (c'est le mode explicite). Le client ne doit alors invoquer aucune commande tant que la négociation n'est pas achevée (autrement dit, que la réponse du serveur n'est pas complète). -
LOGINdemander au serveur une connexion du client.user‑namepassword -
AUTHENTICATEpermet de définir la méthode d'authentification à laquelle le client veut recourir auprès du serveur (cf. la RFC 2222 sur SASL – simple authentication and security layer).method -
LOGOUTdemander au serveur la déconnexion du client. - Gestion des boîtes aux lettres (dossiers Courrier entrant, Brouillons, etc.) :
-
LISTdemande au serveur de lister les boîtes aux lettres du compte de messagerie du client, sachant que :referencemailbox - l'argument reference spécifie le point de départ de la liste dans l'arborescence des boîtes aux lettres du compte ;
- l'argument mailbox complète le critère de listage avec des métacaractères (wildcards ).
-
SELECTdemande au serveur de sélectionner une boîte aux lettres, typiquement pour y rendre les courriels accessibles.mailbox -
CREATE,DELETEetRENAMEsont trois commandes qui toutes prennent un seul argumentmailboxet qui respectivement demandent au serveur de créer, supprimer ou renommer une boîte aux lettres. - Gestion des courriels :
-
SEARCHpour rechercher des courriels selon divers critères ; -
FETCHpour afficher les données (en‑tête, corps, pièces jointes) contenues dans un ou plusieurs courriels donnés ; -
STOREpour modifier les drapeaux d'un ou plusieurs courriels ; -
COPYpour copier un ou plusieurs courriels dans une autre boîte aux lettres que celle sélectionnée ; -
EXPUNGE(sans argument) pour définitivement effacer tous les courriels qui portent le drapeau\Deleteddans la boîte aux lettres sélectionnée. - d'abord d'afficher certains en‑têtes (expéditeur, sujet, date) du dernier courriel reçu (le plus récent, donc dernier dans la liste de la boîte aux lettres sélectionnée) – commande qui porte l'étiquette
CHKP10; - puis de déplacer ce courriel du dossier Courrier entrant dans le dossier Corbeille – 3 commandes qui portent respectivement les étiquettes
CHKP11àCHKP13. - Mode d'attente :
- soit réitérant la commande
SELECT; - soit en invoquant la commande
NOOP(no operation, sans argument ni état requis). - maintient la connexion TCP et l'authentification du client (pas de
server close) ; - engage le serveur à ce qu'ilsignale tout changement dans la boîte aux lettres sélectionnée ;
- après le message de continuation
+ idlingenvoyé par le serveur, le terminal affiche le prompt de saisie utilisateur jusqu'à l'arrivée du nouveau courriel ; - à l'arrivée du nouveau courriel, le serveur envoie successivement les trois lignes
* 2265 EXISTSpuis* 1 RECENTpuis2265 FETCH (FLAGS (\Recent Junk)). - pouvoir spécifier les événements que le serveur doit rapporter ;
- opérer aussi sans sélectionner une boîte aux lettres particulière, donc accéder à tous les événements sur le compte de messagerie : courriels normaux, spam, etc.
Voici la réponse du serveur messagerie.ac-versailles.fr soumis à une commande CAPABILITY du client IMAP (cf. supra ) :
CHKP6 CAPABILITY\r\n
S: * CAPABILITY IMAP4 IMAP4rev1 ACL RIGHTS=tekx QUOTA LITERAL+ NAMESPACE UIDPLUS CHILDREN BINARY UNSELECT SORT CATENATE URLAUTH LANGUAGE ESEARCH ESORT THREAD=ORDEREDSUBJECT THREAD=REFERENCES CONDSTORE ENABLE QRESYNC CONTEXT=SEARCH CONTEXT=SORT WITHIN SASL-IR SEARCHRES METADATA ID XSENDER X-SUN-SORT ANNOTATE-EXPERIMENT-1 X-UNAUTHENTICATE X-SUN-IMAP XUM1 IDLE
S: CHKP6 OK Completed
On peut voir que ce serveur opère la version 4 rev1 et qu'il bénéficie de nombreuses extensions.
CAPABILITY avant de procéder à une demande de connexion (chiffrée) par la commande LOGIN. Dans la continuité de l'exemple précédent, voici la réponse du serveur messagerie.ac-versailles.fr soumis à une commande LIST du client IMAP (cf. supra ), pour afficher toutes les boîtes aux lettres du compte (recours au métacaractère *) :
CHKP8 LIST "" "*"\r\n
S: * LIST (\NoInferiors) "/" INBOX
S: * LIST (\HasChildren) "/" Archives
S: * LIST (\HasNoChildren) "/" Archives/2025
S: * LIST (\HasNoChildren) "/" Drafts
S: * LIST (\HasNoChildren) "/" Junk
S: * LIST (\HasNoChildren) "/" Sent
S: * LIST (\HasNoChildren) "/" Trash
S: CHKP8 OK Completed
On retrouve les 6 boîtes aux lettres usuelles d'un compte de messagerie électronique académique : Courrier entrant, Archives, Brouillons, Envoyés, Indésirables, Corbeille.
Dans la continuité des exemples précédents, voici la réponse du serveur messagerie.ac-versailles.fr soumis à une commande SELECT inbox du client IMAP (cf. supra ) :
CHKP9 SELECT inbox\r\n
S: * FLAGS (\Answered \Flagged \Draft \Deleted \Seen NonJunk $Forwarded $MDNSent Junk $label1)
S: * OK [PERMANENTFLAGS (\Answered \Flagged \Draft \Deleted \Seen NonJunk $Forwarded $MDNSent Junk $label1 \*)]
S: * 2265 EXISTS
S: * 1 RECENT
S: * OK [UIDVALIDITY 1292247461]
S: * OK [UIDNEXT 17148]
S: CHKP9 OK [READ-WRITE] Completed
On peut voir que la boîte aux lettres Courrier entrant contient 2266 courriels, et parmi eux, un nouveau (recent)
EXPUNGE, toutes ces commandes prennent plusieurs arguments qui obéissent à une syntaxe complexe qu'il ne serait pas opportun de détailler ici. Au besoin, on se reportera à la RFC de la version du protocole pris en charge par le serveur du compte de messagerie avec lequel on souhaite interagir (cf. supra ). Dans la continuité des exemples précédents d'interraction du client IMAP (cf. supra ) avec le serveur messagerie.ac-versailles.fr, voici une succession de commandes qui permettent :
CHKP10 FETCH 2265 (FLAGS BODY.PEEK[HEADER.FIELDS (FROM SUBJECT DATE)])\r\n S: * 2265 FETCH (FLAGS (\Seen NonJunk) BODY[HEADER.FIELDS (FROM SUBJECT DATE)] {184} S: From: =?UTF-8?Q?R=C3=A9gion =C3=8Ele-de-France?= <noreply@monlycee.net> S: Subject: =?UTF-8?Q?monlycee.net:_R=C3=A9ception_d'un_message?= S: Date: Tue, 23 Dec 2025 23:34:51 +0100 (CET) S: ) S: CHKP10 OK Completed CHKP11 COPY 2265 "Trash"\r\n S: CHKP11 OK [COPYUID 1292247462 17147 11333] Completed CHKP12 STORE 2265 +FLAGS (\Deleted)\r\n S: * 2265 FETCH (FLAGS (\Deleted \Seen)) S: CHKP12 OK Completed CHKP13 EXPUNGE\r\n S: * 2265 EXPUNGE S: * 2264 EXISTS S: * 0 RECENT S: CHKP13 OK Completed
Remarque : certains serveurs plus modernes prennent en charge la commande MOVE qui permet au client d'effectuer directement l'opération ci‑dessus. C'est une extension du protocole IMAP, définie par la RFC 6851 .
inbox). Cela qui se fait typiquement : IDLE, développée comme une extension à la version 4 du protocole IMAP (RFC 2177 ). Après sélection d'une boîtes aux lettres, cette commande (sans argument) : DONE (sans argument). Dans la continuité des exemples précédents d'interraction du client IMAP (cf. supra ) avec le serveur messagerie.ac-versailles.fr, voici un scénario où le client, toujours dans l'état Selected invoque les commandes IDLE et DONE, entre lesquelles un nouveau courriel entrant arrive sur le serveur.
CHKP14 IDLE\r\n S: + idling S: * 2265 EXISTS S: * 1 RECENT S: * 2265 FETCH (FLAGS (\Recent Junk)) DONE\r\n S: CHKP14 OK Completed
Dans ce scénario :
Le scénario s'achève alors avec le traitement de la commande DONE envoyée par le client.
NOTIFY, définie également comme une extension (RFC 5465 ). En comparaison avec IDLE, elle présente plusieurs avantages, notamment : CAPABILITY). Machine à états du protocole IMAP
Pour avoir une représentation globale des scénarios possibles du protocole IMAP, il est usuel de recourir à sa modélisation par une machine à états finis W (finite state machine). Une telle modélisation est proposée dans la RFC 3501 et reproduite ci‑dessous.

Cette modélisation est assez simple, elle ne distingue 4 états possibles, dont deux – client authenticated et mailbox selected – sont les plus fonctionnels en termes de possibilités de requêtes du client. Les deux autres états sont, en principe, transitoires.
Encodage des courriels
Problématique

Comme une page web, un courriel est n'est pas seulement constitué de texte, il peut inclure aussi des images ou d'autres fichiers joints de toutes sortes de formats – et même d'autres courriels (avec leurs éventuelles pièces jointes).
Pour les éléments de texte, comme dans le web, il est impératif de pouvoir prendre en charge l'ensemble du jeu de caractères Unicode. La tendance est donc à la généralisation de l'encodage des caractères en UTF‑8 (cf. chap. C3‑IX C) par les clients de messagerie. En effet, ce format est celui qui engendre un surcoût moyen minimal en termes de taille mémoire.
Mais la question cruciale est aussi la conception du protocole SMTP ainsi que la capacité des serveurs à pouvoir transférer et stocker des données dans n'importe quel format d'encodage, et pas seulement les éléments de texte. La réponse à cette contrainte est essentiellement apportée par le standard de transcodage MIME (cf. infra ).
En fait, l'encodage des courriels reste une question épineuse car le protocole SMTP a été initialement conçu (au début des années 1980) pour transmettre uniquement des données de type text :
- formatées en lignes de longueur limitée (998 caractères maximum, sachant que la valeur recommandée est de 76 caractères), terminées par chacune par la séquence
\r\n; - encodées dans le jeu ASCII restreint (c'est‑à‑dire des octets dont la valeur reste comprise entre
0et127, donc laissant le bit de haut rang toujours à0).
Et en particulier, encore aujourd'hui, l'encodage des en‑têtes des courriels (cf. supra ) reste particulièrement contraint :
- les noms des champs doivent être composés exclusivement dans le jeu de caractères ASCII restreint (plus précisément, avec des caractères imprimables et sans espace).
- Quant aux valeurs des champs, elles peuvent être composées dans le jeu de caractères Unicode, avec deux solutions pour leur prise en charge :
Le standard MIME
Le standard MIME W – pour multipurpose Internet mail extensions – est une norme de classification de données et de choix de techniques de transcodage mise en œuvre par les clients de messagerie (MUA) au sein de la couche application, lors de l'émission et de la réception des courriels. Introduite dès 1992, cette norme rend possible la prise en charge via le protocole SMTP des courriels comportant des données encodés dans des formats autres que l'ASCII : texte en caractères larges (UTF‑8 ou autre), images, code exécutable, etc.
Par la suite, le standard MIME a également été adopté pour distinguer les types de données dans d'autres contextes que les services de messagerie, notamment au sein du protocole HTTP et, dans une moindre mesure, pour l'administration des systèmes d'exploitation Linux.
Le standard MIME est assez complexe. Dès son introduction, il a été spécifié par pas moins de cinq RFC : 2045 , 2046 , 2047 , 2048 et 2049 . À l'exception de la 2048 qui est obsolète et remplacée par les RFC 4289 et RFC 6838 , toutes les RFC originales restent en vigueur, même si elles sont complétées par d'autres plus récentes.
Comme l'indique le terme « multipurpose », le standard MIME est une norme polyvalente, dans l'objectif d'être :
- rétro‑compatible avec les systèmes d'échange de courriels existant, en particulier avec les contraintes inhérentes au protocole SMTP (restriction à l'encodage en octets 7 bits – cf. supra ) ;
- efficace en adaptant la technique de transcodage aux différents types de données pouvant être incorporés dans un courriel (texte, image, etc.).

Sur la machine émettrice, la mise en œuvre du standard MIME par le MUA (cf. supra ) consiste, avant le passage d'un courriel à la couche Présentation :
- à définir par des champs d'en‑têtes spécifiques et délimiter par ajout de frontières (en anglais, boundaries) les types de données contenus dans le courriel ;
- à choisir et effectuer, pour chaque type de données, une technique de transcodage adaptée ;
sachant que, comme pour tout protocole applicatif, sur la machine destinataire, le processus réciproque est appliqué par le MUA (toujours au sein de la couche application) pour reconstituer la forme originelle du courriel (par transcodage inverse).
Les champs d'en‑tête spécifiques (cf. supra sur la notion de champ d'en‑tête) au standard MIME sont notamment les suivants.
- Le champ
MIME-Versionprécise la version du standard utilisé. C'est un champ purement formel car, encore aujourd'hui, c'est la version1.0introduite dès 1992 qui est utilisée, et aucune nouvelle version n'est en préparation (ce qui n'empêche pas des évolutions du standard lui‑même). - Le champ
Content-Typeindique le type de données contenues dans le corps du courriel ou d'une de ses parties s'il s'agit d'un courriel dit multipart. Il est basé sur les 11 types de médias recensés par l'Iana (cf. la RFC 2046 ), auquel il ajoute toujours une précision de format après le séparateur/. Il peut notamment prendre les valeurs principales suivantes : -
text/plainpour un corps (ou une partie) constitué d'un texte non formaté (le terme anglais plain signifie « simple » en français) ; autrement dit, il s'agit d'une chaîne de caractères plus ou moins longue, à interpréter telle quelle par les clients de messagerie émetteur et destinataire(s) ; -
text/htmlpour un corps (ou une partie) constitué d'un texte formaté en langage HTML ; il se présente également comme une chaîne de caractères, mais destinée à être interprétée par le moteur de rendu (cf. chap. R2‑III ) du client de messagerie ; -
multipart/mixedpour un corps structuré en plusieurs parties encodées dans différents formats, typiquement un courriel avec des pièces jointes diverses ; -
multipart/alternativepour un corps structuré en plusieurs parties, chacune présentant le même contenu d'une façon spécifique (par exemple,text/html&text/plain), pour laisser au MUA du destinataire plusieurs possibilités d'affichage ; -
application/pdfpour une pièce jointe constituée d'un document au formatpdf; - etc.
- Le champ
Content-Transfert-Encodingindique quant à lui le format d'encodage du contenu pour permettre le transfert du courriel par SMTP. On peut notamment avoir les formats suivants : -
7bitest le format indiqué si aucun transcodage n'est nécessaire, parce que le contenu est de typetextet codé comme chaîne de caractères exclusivement pris dans le jeu ASCII restreint (cf. chap. C3‑VIII C) ; -
quoted-printable(cf. infra ) est un format obtenu par un transcodage d'un contenu de type texte où, pour faire simple, seuls les caractères hors du jeu ASCII restreint sont transformés en séquences d'échappement composées dans ce jeu. D'autant plus efficace que ces caractères sont rares, cette technique n'est alors pas trop coûteuse en mémoire et conserve alors une bonne lisibilité du texte. -
base64(cf. infra ) est un format qui est en principe applicable à tout format de données (y compris du texte), mais utilisé surtout pour les contenus non textuels (images, code exécutable, etc.). Il est obtenu par un transcodage des octets du contenu dans un code à 64 symboles pris dans le jeu ASCII restreint. -
8bitest le format indiqué si aucun transcodage n'est nécessaire, même avec du texte composé avec des caractères hors du jeu ASCII restreint, dès lors que le client et le serveur disposent de l'extension8BITMIME. C'est l'approche moderne de plus en plus souvent adoptée.
Content-Type permet d'apporter davantage de précision sur le formatage des données, chacune séparée de la précédente par un caractère ;. Par exemple, pour un contenu de type text, il indique l'encodage des caractères, typiquement : Content-type: text/html; charset=utf-8.
Lorsqu'un courriel est structuré en plusieurs parties, le standard MIME opère la séparation de la partie antérieure par la création d'une frontière – en anglais, boundary. Chaque frontière se présente sous la forme d'une chaîne de caractères commençant par :
--------------
suivi d'un identificateur alphanumérique spécifique du courriel, généré aléatoirement.
Chaque partie fait alors l'objet de son propre descriptif, notamment par les champs d'en‑têtes Content-type et Content-Transfert-Encoding.
Transcodage en quoted‑printable
Quoted‑printable W (RFC 2045, section 6.7 ) est un format d'encodage obtenu par une technique de transcodage qui transforme n'importe quelle chaîne de caractères initiale quel que soit son format d'encodage – ASCII étendu, UTF‑8, UTF‑16, etc. – en une chaîne de caractères transcodée, qui elle, est composée exclusivement de caractères imprimables, blancs et de sauts de ligne, tous encodés dans le jeu ASCII restreint.
Rappelons que dans ce jeu (cf. chap. C3‑VIII ) :
- les caractères blancs sont la tabulation horizontale (HT,
0x09) et l'espace ordinaire (SP,0x20) ; - les caractères imprimables sont les lettres (majuscules, minuscules), les chiffres, et divers signes de ponctuation et symboles, leurs codes allant de
0x21à0x7E.
Enfin, un sauts de ligne est une séquence CR LF ou CR (carriage return – 0x0D) et LF (line feed – 0x0A) sont deux caractères de contrôle.
Attention ! Le transcodage en quoted-printable ne procède pas par caractères mais par octets, ceci pour en simplifier l'algorithme et s'adapter à toutes sortes de formats. À quelques exceptions près détaillées plus loin, le principe est le suivant :

- Tous les octets qui coïncident avec les valeurs des caractères imprimables et blancs et des caractères du saut de ligne dans le jeu ASCII restreint – ne sont pas transcodés ;
- A contrario, tous les autres octets sont transcodés pour prendre des valeurs dans cette plage, sur la base de leur encodage.
Il en résulte une chaîne de caractère transcodée totalement adaptée au protocole SMTP et dont la lisibilité par un utilisateur est conservée autant que possible dès lors que le format d'encodage de la chaîne initiale est rétro‑compatible avec le code ASCII, à savoir les formats ASCII étendus (cf. chap. C3‑VIII ) et l'UTF‑8 .
En revanche, on a une perte de lisibilité totale pour les formats UTF‑16 et UTF‑32.
Également, le transcodage en quoted‑printable impose une longueur maximale de ligne de 76 octets, en ajoutant si nécessaire des sauts de ligne (séquences CR LF) dans la chaîne transcodée.
Plus précisément, le principe du transcodage en quoted‑printable est le suivant : tout octet à transcoder est remplacé par une séquence d'échappement préfixée par le caractère « = » (code ASCII 0x3D) suivi des lettres majuscules de A à F et chiffres de 0 à 9 formant sa valeur hexadécimale dans le format d'encodage de la chaîne initiale – ces caractères étant tous imprimables ou blancs dans le jeu ASCII restreint.
- À titre académique, on considère le cas d'une chaîne de caractère initiale encodée dans différents formats possibles, contenant le caractère « î » (point de code U+00EE). Le tableau ci‑dessous récapitule le trancodage en quoted‑printable de ce caractère selon les différents formats listés de la chaîne.
-
printfpour former la chaîne de caractères initiale, avec éventuellement des séquences d'échappement pour coder des caractères de contrôle ((cf. chap. C3‑VIII ) ; -
iconvpour convertir le format d'encodage de la chaîne de caractère initiale dans celui à expérimenter ; -
qprintpour transcoder la chaîne en quoted‑printable (cette commande s'installe directement via le gestionnaire de paquetsapt). - Pour bien saisir l'impact sur la lisibilité du transcodage en quoted‑printable en fonction du format d'encodage de la chaîne initiale, comparons les résultats obtenus, toujours par expérimentation dans un terminal en langage Bash :
- dans le premier cas (à partir de l'UTF‑8), la chaîne transcodée est encore assez compacte et à peu près lisible ;
- dans le deuxième cas (à partir de l'UTF‑16), la chaîne transcodée est beaucoup plus longue et difficilement lisible ;
| format initial | Latin-9 | UTF‑8 | UTF‑16BE | UTF‑32BE |
|---|---|---|---|---|
| quoted–printable | =EE |
=C3=AE |
=00=EE |
=00=00=00=EE |
| (pipe W), on enchaîne les commandes : printf "î" | iconv -f UTF-8 -t Latin-9 | qprint -e=EE=printf "î" | qprint -e # (already in UTF-8)=C3=AE=printf "î" | iconv -f UTF-8 -t UTF-16BE | qprint -e=00=EE=printf "î" | iconv -f UTF-8 -t UTF-32BE | qprint -e=00=00=00=EE=
= en fin de ligne ne fait pas explicitement partie du transcodage (il est ajouté pour la gestion des sauts de lignes – cf. infra ). printf "chaîne de caractères" | qprint -e # (already in UTF-8)cha=C3=AEne de caract=C3=A8resprintf "chaîne de caractères" | iconv -f UTF-8 -t UTF-16BE | qprint -e=00c=00h=00a=00=EE=00n=00e=00 =00d=00e=00 =00c=00a=00r=00a=00c=00t=00= =E8=00r=00e=00s=
Les cas d'exceptions au principe général d'encodage en quoted‑printable sont les suivants :
- Dans la chaîne initiale, toute occurrence d'un octet de valeur
0x3D, qui correspond au caractère «=» dans le jeu ASCII restreint, parce qu'il est utilisé comme préfixe de transcodage (cf. supra ), est systématiquement transcodé en=3D. - Dans la chaîne initiale, toute occurrence d'un octet de valeur
0x09ou0x20qui correspondent aux caractères blancs (HT et SP) dans le jeu ASCII restreint, s'il est placé juste avant un saut de ligne (séquence CR LF) est systématiquement transcodé.
Comme dans les exemples précédents, on procède par expérimentation dans un terminal de commandes en langage Bash avec une chaîne de caractères initiale encodée par défaut UTF‑8, contenant notamment :
- une occurrence du caractère «
=», lequel est encodé par un seul octet de valeur0x3D; - une occurrence du caractère HT, lequel encodé par un seul octet de valeur
0x09(cette tabulation est codé dans la chaîne initiale par la séquence d'échappement\tpour mieux la visualiser) ; - une occurrence du caractère SP, lequel encodé par un seul octet de valeur
0x20, avec la particularité d'être placé juste avant un saut de ligne (le saut de ligne étant lui‑même codé dans la chaîne par les séquences d'échappement\r\n).
printf "E = mc²\tAlbert Einstein \r\n" | qprint -eE =3D mc=C2=B2 Albert Einstein=20
Et, comme attendu, on observe que :
- le caractère «
=» est transcodé en=3D; - le caractère HT n'est pas transcodé puisqu'il n'est placé juste avant un saut de ligne – il apparaît ici comme un seul espace mais on peut révéler sa vraie valeur par copier-coller dans un terminal ;
- le caractère SP final (juste avant
\r\n) est transcodé en=20(alors que toutes les autres occurrences de ce caractère ne le sont pas).
Le surcoût en volume mémoire du transcodage en quoted‑printable dépend du nombre d'octets à transcoder dans la chaîne initiale, mais pour chacun, il est quand même conséquent puisqu'il génère 3 octets.
- Il reste donc acceptable pour du texte composé en UTF‑8 avec une majorité de caractères issus du jeu ASCII restreint ;
- En revanche, il est très pénalisant dès que le texte comporte trop de caractères hors du jeu ASCII restreint (typiquement, dans un lphabet cyrillique, grec, arable, etc.) ou si le texte est encodé en UTF‑16 ou en UTF‑32. Là, le volume mémoire est multiplié par 3 (sans même considérer les sauts de ligne additionnels).
Transcodage en base64
Base64 W (RFC 2045, section 6.8 et RFC 4648 ) est un format d'encodage obtenu par une technique de transcodage qui transforme n'importe quelle suite d'octets quoi qu'ils représentent – texte, image, audio, code exécutable ou autre – UTF‑8, UTF‑16, etc. – en une chaîne de caractères est composée exclusivement parmi 64 + 1 caractères imprimables du jeu ASCII restreint.
- Les 64 caractères format la base de transcodage sont, dans l'ordre, les 52 lettres (majuscules et minuscules), les 10 chiffres et 2 symboles, par défaut
+et/. - Le symbole
=est également utilisé comme caractère de bourrage (padding) pour pouvoir terminer le processus de transcodage dans tous les cas de figure.
Le principe de transcodage en base64 est le suivant :
- On attribue de façon biunivoque un code binaire sur 6 bits à chacun des 64 caractères de la base, en procédant dans l'ordre (
0b000000pourAà0b1111111pour/). Sachant que 26 = 64, toutes les codes sont attribués). - On transcode chaque groupe de 3 octets consécutifs – soit 3 × 8 = 24 bits – en un groupe de 4 caractères de la base – soit 4 × 6 = 24 bits également.
En définitive, cette chaîne de caractères base64 est encodée en ASCII sur 4 × 8 = 32 bits, comme l'illustre la figure ci‑dessous.

Il en résulte un surcoût mémoire systématique de 33 %, ni plus ni moins (les caractères de bourrage exposés ci‑après sont négligeables). Cette technique de transcodage est donc bien plus efficace que quote‑printable (cf. supra ), même pour les données de type texte si elles sont encodées dans les formats suivants :
- UFT‑16 ou UTF‑32 ;
- UFT‑8 avec des caractères composés dans un alphabet non latin (grec, cyrillique, arabe…) ou, plus généralement, avec trop de caractères hors du jeu ASCII restreint.
Et dans tous les cas, l'absence de lisibilité ne peut tenir lieux de contre‑argument car ce défaut vaut aussi en quoted‑printable.
Pour clore cet exposé, une particularité subsiste (sachant qu'elle n'a aucun impact significatif sur les considérations précédentes) : le nombre d'octets à transcoder n'est pas nécessairement un multiple de 3.
- S'il reste 1 octets (8 bits) à transcoder, on procède à l'ajout de 4 bits de valeur
0pour former un ensemble de 12 bits (2 × 6), soit 2 caractères base64. - S'il reste 2 octets (16 bits) à transcoder, on procède à l'ajout de 2 bits de valeur
0pour former un ensemble de 18 bits (3 × 6), soit 3 caractères base64.
= pour compléter le groupe de 4 caractères. = pour former compléter le groupe de 4 caractères. C'est ce qu'illustrent respectivement les figures de gauche et de droite ci‑dessous.

Remarque. Les caractères de bourrage sont indispensables pour pouvoir, lors du transcodage inverse (à la réception du courriel), supprimer les bits 0 ajoutés.
Gestion des sauts de ligne
La RFC 5322 (2008) consacrée au format des courriels précise que, pour des raisons historiques, (cf. les remarques infra ) ces derniers doivent être constitués de lignes de 998 caractères maximum, avec une valeur recommandée de 76 caractères seulement, saut de ligne CR LF exclu. Et ce quelle que soit la partie du courriel (en‑tête, corps) considérée.
Pour se conformer à ces contraintes le standard de transcodage MIME met en œuvre diverses techniques d'insertion de sauts de lignes « souples » – en anglais, soft linebreaks, selon le format de transfert utilisé (7bit, quoted‑printable ou base64 – cf. supra ).
Dans un contenu de type 7bit ou 8bit, les sauts de ligne originaux – c'est‑à‑dire ceux inclus dans le contenu initial – sont sémantiques (ils sont intentionnellement composés par l'auteur du courriel). Si des sauts de lignes additionnels sont insérés tels quels, il est impossible de les distinguer des sauts de lignes originaux lors du transcodage inverse (à la réception du courriel). Longtemps, cela a gâché la présentation des courriels reçus.
Pour éviter ces artefacts, le standard MIME propose l'option format=flowed qui, lorsqu'elle est activée, consiste à :
- dans le texte initial, supprimer tous les espaces (SP) précédents un saut de ligne – en effet, ces espaces n'ont a priori aucune pertinence sémantique ;
- puis insérer à chaque fois que nécessaire (pour respecter la contrainte de longueur de ligne recommandée), de préférence après un espace (SP) – donc, sans couper un mot – un saut de ligne CR LF, ce qui forme une séquence SP CR LF qu'on qualifie de saut de ligne « souple » ;
À la réception du courriel, il est alors trivial d'éliminer les sauts de ligne « souples » sans toucher aux sauts de ligne originaux, et ainsi retrouver la forme originale du texte.
Avec un client de messagerie (Thunderbird 140.7.1 sous Linux Mint), on compose un courriel d'essai dont le corps est constitué des cinq premières phrases de la version populaire du Lorem ispum W, dans lequel on a ajouté exprès un saut de ligne précédé d'un espace (c'est‑à‑dire une séquence SP CR LF). Il s'agit donc d'un texte de deux lignes composé exclusivement dans le jeu ASCII restreint, et pour mieux visualiser ses caractères blancs, il été copié dans un éditeur de code (cf. la capture d'écran ci‑dessous) :

Voici maintenant ce que l'on peut observer en utilisant la même technique que dans l'exemple supra pour analyser le déroulement du protocole SMTP avec Wireshark.
[…] Content-Type: text/plain; charset=UTF-8; format=flowed\r\n Content-Transfer-Encoding: 7bit\r\n \r\n Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed non risus. \r\n Suspendisse lectus tortor, dignissim sit amet, adipiscing nec, ultricies \r\n sed, dolor.\r\n Cras elementum ultrices diam. Maecenas ligula massa, varius a, semper \r\n congue, euismod non, mi.\r\n
Comme attendu, dans l'unique paquet DATA fragment généré par le MUA dans le cadre du protocole SMTP, on constate les points suivants.
- Le corps du courriel est bien identifié comme du texte simple (
text/plain), et il est pris en charge avec l'optionformat=flowed. - Par rapport au texte initial, 3 sauts de ligne « souples » (séquences SP CR LF – c'est‑à‑dire
\r\n) ont été automatiquement formés sans coupure de mot, pour obtenir des lignes de longueur toujours inférieure à 76 caractères. - Quant à la séquences SP CR LF (
\r\n) qui était présente dans le texte initial, elle a vu son espace supprimé, pour devenir simplement CR LF (\r\n) et ainsi ne pas être confondue avec un saut de ligne « souple » à la réception du courriel. - Enfin, le dernier saut de ligne à la fin du texte est ajouté pour signaler la fin de la transmission, en étant suivi d'un dernier message SMTP réduit à la seule séquence . CR LF (
.\r\n), pour former ensemble la séquence CR LF . CR LF (\r\n.\r\n– cf. supra ).
7bit. Ainsi, lors de la réception du courriel, le texte apparaît (presque) exactement comme lors de sa composition, sous la forme de deux lignes de texte, expurgées de tous les sauts de ligne « souples ». Seul l'espace supprimé est définitivement perdu – mais ce n'est pas un problème car il ne présentait a priori aucun intérêt.
Dans un contenu de type quoted‑printable, on est confronté à la même problématique qu'avec du contenu 7bit ou 8bit : le texte initial peut a priori contenir des sauts de lignes sémantiques qui ne doivent pas être confondus avec les sauts de lignes « souples » insérés pour respecter la contrainte de longueur maximale de ligne.
Le standard MIME préconise une technique similaire pour contourner cette difficulté : les sauts de ligne « souples » sont insérés comme des séquences = CR LF . Grâce au préfixe =, elles ne peuvent pas être confondues avec les simples séquences CR LF codant les sauts de ligne sémantiques contenus dans le texte initial.
À l'aide des mêmes commandes (printf et qprint) que dans les exemples supra , observons le transcodage en quoted‑printable d'une chaîne de 253 caractères « Lorem ipsum […] », contenant par ailleurs un saut de ligne intentionnel (sémantique) codé par la séquence d'échappement \r\n après le mot « dolor ».
printf "Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed non risus. Suspendisse lectus tortor, dignissim sit amet, adipiscing nec, ultricies sed, dolor.\r\nCras elementum ultrices diam. Maecenas ligula massa, varius a, semper congue, euismod non, mi." | qprint -eLorem ipsum dolor sit amet, consectetur adipiscing elit. Sed non risus= . Suspendisse lectus tortor, dignissim sit amet, adipiscing nec, ultri= cies sed, dolor. Cras elementum ultrices diam. Maecenas ligula massa, varius a, semper = congue, euismod non, mi.=
Dans chaîne transcodée, les sauts de ligne n'apparaissent pas sous la forme d'une séquence d'échappement mais ils sont exécutés. Elle se présente donc sur 5 lignes et contient 4 saut de lignes « souples », chacun repérable par son préfixe = en toute fin de ligne.
Par ailleurs, le saut de ligne intentionnel après le mot dolor est bien préservé : il n'est pas précédé par le préfixe =, ce n'est pas un saut de ligne « souple ».
Dans un contenu de type base64, il n'y a aucune problématique des sauts de ligne car :
- les caractères CR et LF ne sont pas dans base de transcodage ;
- la chaîne transcodée est juste une suite d'octets, sans séparateur ; le concept de mot n'y existe pas.
Des sauts de ligne ordinaires peuvent donc être insérés à intervalles réguliers pour garantir le respect de la contrainte de longueur de ligne. À la réception du courriel, ils sont tous supprimés avant transcodage inverse sans risque de confusion avec quoi que ce soit du contenu initial transmis.
Les raisons historiques de limitation de la longueur des lignes des courriels sont les suivantes :
- Implémentés en langage C, les programmes qui mettent en œuvre les protocoles de communication manipulant des fichiers de texte opèrent ligne par ligne. Typiquement, ils appellent une fonction comme
fgetsC qui copie la ligne en cours de traitement dans un buffer de type tableau de caractères dont le nombre d'éléments est déterminé par une constante. La valeur maximale1000(998si l'on exclut les deux caractères requis par le saut de ligne) s'est imposée parce que jugée : - suffisamment grande pour l'efficacité de l'algorithme (surtout à une époque où la taille de mémoire vive des processeurs était très limitée) et les limites de taille des paquets dans les réseaux (MTU – cf. chap. R3‑I ),
- facile à mémoriser et commode pour compter le nombre de caractères traités au fur et à mesure de l'exécution du programme.
- Par ailleurs, il faut se souvenir qu'aux début du déploiement des réseaux informatiques (années 1980), les postes de travail sont des terminaux dont les moniteurs ont une largeur de 80 caractères (cf. par exemple le modèle VT100 de DEC, en photo ci‑contre W). L'idée qui a prévalu était donc la suivante : quite à découper en lignes le texte d'un courriel, autant le faire directement à la longueur optimale pour l'affichage (avec une petite marge) – d'où la valeur recommandée de
76caractères.

Exemple de démonstration de MIME
On donne ci‑après le contenu brut d'un courriel de démonstration :
- dont le sujet est «
Démonstration MIME» (il contient une lettre accentuée, donc hors du jeu ASCII restreint) ; - dont le corps est le texte «
Courriel écrit en français.» (sans formatage) ; - qui inclut deux pièces jointes :
- une image au format
.png; - un autre courriel, portant le sujet «
essai ASCII» et contenant le texte «Hello, World.» (exclusivement composé en ASCII restreint) ;
sachant que le client de messagerie utilisé (Mozzilla Thunderbird) encode par défaut le courriel en UTF‑8. Ce contenu est obtenu via la commande Afficher la source accessible via le bouton contextuel Autres.
En plus des éléments en vert ci‑dessus, pour bien visualiser les aspects essentiels de l'encodage MIME :
- les frontières de découpage du courriel en différentes parties MIME ont été coloriés en
rouge; - dans chaque partie, les valeurs des champs d'en‑tête MIME ont été coloriés en
bleu; - Les passages sans intérêt on été coupés et remplacés par le symbole
[…]et les adresses IP ont été masquées.
Return-path: <Francois.Girault@ac-versailles.fr> Received: from smtpout2.ac-versailles.fr ([XXX.XXX.XXX.XXX]) by storel.in.ac-versailles.fr (Oracle Communications Messaging Server 7.0.5.38.0 64bit (built Nov 28 2016)) with ESMTP id <0QKN00IKTPDCFH70@storel.in.ac-versailles.fr> for francois.girault@ac-versailles.fr; Tue, 01 Dec 2020 11:34:24 +0100 (CET) Original-recipient: rfc822;francois.girault@ac-versailles.fr Received: from localhost (localhost [127.0.0.1]) by smtpout2.ac-versailles.fr (Postfix) with ESMTP id AFDDEE80C48 for <francois.girault@ac-versailles.fr>; Tue, 1 Dec 2020 11:34:24 +0100 (CET) […] X-Virus-Scanned: Debian amavisd-new at smtpout2.in.ac-versailles.fr X-Spam-Flag: NO X-Spam-Score: -2.9 X-Spam-Level: X-Spam-Status: No, score=-2.9 tagged_above=-999 required=6.2 tests=[ALL_TRUSTED=-1, BAYES_00=-1.9] autolearn=ham autolearn_force=no Received: from smtpout2.ac-versailles.fr ([127.0.0.1]) by localhost (smtpout2.in.ac-versailles.fr [127.0.0.1]) (amavisd-new, port 10024) with ESMTP id gp-J4VDQ_-f5 for <francois.girault@ac-versailles.fr>; Tue, 1 Dec 2020 11:34:24 +0100 (CET) Received: from [192.168.0.12] (unknown [XXX.XXX.XXX.XXX]) by smtpout2.ac-versailles.fr (Postfix) with ESMTPA id 5EC26E80BFC for <francois.girault@ac-versailles.fr>; Tue, 1 Dec 2020 11:34:24 +0100 (CET) To: =?UTF-8?Q?fran=c3=a7ois_Girault?= <Francois.Girault@ac-versailles.fr> From: =?UTF-8?Q?Fran=c3=a7ois_Girault?= <Francois.Girault@ac-versailles.fr> Subject: =?UTF-8?Q?D=c3=a9monstration_MIME?= Message-id: <7f27afdb-ef6c-d2b9-e370-e03ae3382a50@ac-versailles.fr> Date: Tue, 01 Dec 2020 11:33:31 +0100 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Thunderbird/78.5.0 MIME-version: 1.0 Content-type: multipart/mixed; boundary=------------471AF95E97E742D31C117386 Content-language: fr This is a multi-part message in MIME format. --------------471AF95E97E742D31C117386 Content-Type: text/plain; charset=utf-8; format=flowed Content-Transfer-Encoding: quoted-printable Courriel =C3=A9crit en fran=C3=A7ais. --------------471AF95E97E742D31C117386 Content-Type: image/png; name="iconShowPanel.png" Content-Transfer-Encoding: base64 Content-Disposition: attachment; filename="iconShowPanel.png" iVBORw0KGgoAAAANSUhEUgAAAQUAAAD0CAYAAACSLzOZAAAACXBIWXMAAA7DAAAOwwHHb6hk AAAGqUlEQVR42u3bsWoUQQAG4Nv1wBSKQioRRIQ0FnZiI/gSahEkT2BlZRM8Gysfw8YTrGyC […] AhCgIFBo9wACFAQKix5AgIJAYdEDCPlkfPobVx7cr3/fvnX55Gdlwq/zzG/azVJ9vXT92iBQ aDCo17c2gZBJirp2MBCRs//5ICJQEBGBgohAQUSgICKdcgSNq7rwTTL0BAAAAABJRU5ErkJg gg== --------------471AF95E97E742D31C117386 Content-Type: message/rfc822; name="essai ASCII.eml" Content-Transfer-Encoding: 7bit Content-Disposition: attachment; filename="essai ASCII.eml" Return-path: <Francois.Girault@ac-versailles.fr> Received: from smtpout1.ac-versailles.fr ([XXX.XXX.XXX.XXX]) by storel.in.ac-versailles.fr (Oracle Communications Messaging Server 7.0.5.38.0 64bit (built Nov 28 2016)) with ESMTP id <0QKN00IZ5P9TFH60@storel.in.ac-versailles.fr> for francois.girault@ac-versailles.fr; Tue, 01 Dec 2020 11:32:17 +0100 (CET) Original-recipient: rfc822;francois.girault@ac-versailles.fr […] X-Virus-Scanned: Debian amavisd-new at smtpout1.in.ac-versailles.fr X-Spam-Flag: NO X-Spam-Score: -0.999 X-Spam-Level: X-Spam-Status: No, score=-0.999 tagged_above=-999 required=6.2 tests=[ALL_TRUSTED=-1, TVD_SPACE_RATIO=0.001] autolearn=ham autolearn_force=no Received: from [192.168.0.12] (unknown [XXX.XXX.XXX.XXX]) by smtpout1.ac-versailles.fr (Postfix) with ESMTPA id 60F1532100E for <francois.girault@ac-versailles.fr>; Tue, 1 Dec 2020 11:32:17 +0100 (CET) To: =?UTF-8?Q?fran=c3=a7ois_Girault?= <Francois.Girault@ac-versailles.fr> From: =?UTF-8?Q?Fran=c3=a7ois_Girault?= <Francois.Girault@ac-versailles.fr> Subject: essai ASCII Message-id: <ab4f72a4-760b-6b3b-4c24-0bc2223a4e16@ac-versailles.fr> Date: Tue, 01 Dec 2020 11:31:24 +0100 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Thunderbird/78.5.0 MIME-version: 1.0 Content-type: text/plain; charset=utf-8; format=flowed Content-transfer-encoding: 7bit Content-language: fr Hello, World. --------------471AF95E97E742D31C117386--
L'extension SMTPUTF8
L'extension SMTPUTF8 (SMTP extension for internationalized email W) a été développée expérimentalement à la fin des années 2000 (RFC 5336) puis augmentée et spécifiée par la RFC 6531 W en 2012.
Elle permet de composer avec des chaînes de caractères encodés en UTF‑8 (cf. chap. C3‑IX C) :
- la partie locale des adresses de messagerie ;
- les valeurs des champs des en‑têtes des courriels.
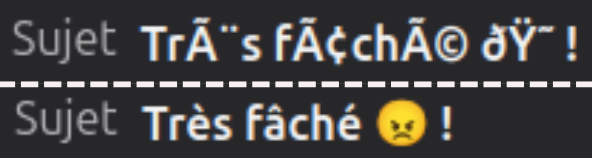
Il arrive encore qu'un courriel parvienne à son destinataire avec des problèmes d'encodage des lettres accentuées – typiquement, le classique « é » à la place du « é » – dans le champ sujet alors que le corps du texte est correctement affiché (cf. l'exercice 4 de la feuille C3 C pour simuler ce dysfonctionnement dans un terminal de commande en lignes). Il suffit pour cela qu'il ait été composé en UTF‑8 mais acheminé via un serveur qui ne prend pas en charge le protocole SMTPUTF8 ; ce qui est, heureusement, de moins en moins fréquent.