La couche transport a été brièvement décrite dans le chapitre R1‑IV portant sur l'étude générale des protocoles. Après avoir passé en revue toutes sortes de protocoles applicatifs qui, nécessairement, font appel à un protocole de transport, le moment est venu d'étudier en détail en quoi consiste un tel protocole.
Comparativement à la couche application à laquelle toute la partie R2 de ce module (8 chapitres) est consacrée, la couche transport apparaît nettement plus simple – et ce présent chapitre, à lui seuil, suffit à en décrire l'essentiel. En effet, la couche transport se résume principalement une alternative entre deux protocoles :
- UDP (user datagram protocol), maintes fois évoqué tant il est utilisé par les services réseaux – DNS, DHCP, NTP… – ainsi que les applications de streaming W et VoIP (cf. chap. R2‑VIII ) ;
- TCP (transmission control protocol), qui est le protocole employé pour la plupart des échanges de données massifs – HTTP (pages web), FTP (fichiers), SMTP et IMAP (courriels), etc.
Dans le modèle OSI, la couche transport peut être vue comme la plus basse des couches hautes, c'est‑à‑dire des couches qui sont prises en charge seulement par la machine émettrice (celle qui est à l'initiative de la communication) et la machine destinataire.
En général, les protocoles UDP et TCP sont mis en œuvre par des composants logiciels des systèmes d'exploitation respectifs des machines émettrices et destinataires. Néanmoins, on a vu (cf. TP R2‑4 ) qu'une simple carte à microcontrôleur – machine qui n'est pas dotée d'un système d'exploitation – peut aussi émettre et recevoir des datagrammes UDP, par exemple dans le rôle de client NTP, à condition d'être équipée d'une interface réseau .
Pour un technicien réseau, a fortiori dans le domaine de la cybersécurité, une connaissance technique des protocoles UDP et TCP fait partie de la culture générale indispensable. Comprendre leurs principes de fonctionnements, leurs avantages et inconvénients respectifs est en effet nécessaire pour pouvoir faire un choix dans le cadre du développement d'une nouvelle application réseau, en particulier sur des systèmes à microcontrôleur (domotique, IoT, etc.)
Ce chapitre a donc pour objectif d'apporter cette culture générale :
- On commencera par le protocole UDP, en raison de sa simplicité.
- On terminera par le protocole TCP, qui nécessite bien plus de développements qu'UDP en raison de sa complexité.
Le protocole UDP
Caractéristiques générales
Le protocole UDP W – pour user datagram protocol – est un protocole de transport pour données de petite taille. Sommairement spécifié en 1980 par la RFC 768 , il opère :
- sans segmentation – et donc sans contrôle de flux ;
- en mode non connecté et nativement en multicast – on peut donc l'employer en broadcast ;
- et sans contrôle de bonne réception des données pour l'émetteur, mais en laissant la possibilité aux destinataires d'effectuer un contrôle d'intégrité des données transmises.
Au regard des deux derniers points, on dit qu'UDP procède « au mieux » – c'est‑à‑dire en référence à l'expression anglaise best‑effort delivery W. On peut aussi également dire que c'est un protocole sans état W (stateless protocol).
Dans le cadre d'UDP, les PDU (protocol data units – cf. chap. R1‑IV ) sont appelés datagrammes.
Détaillons ces différents aspects.
- L'absence de segmentation et la petite taille des datagrammes s'expliquent par le fait que ce protocole est conçu pour les transmissions de données qui ne requièrent a priori qu'un seul datagramme ; par exemple, quelques adresses IP pour le protocole DHCP, quelques timestamp pour le protocole NTP, etc.
- L'absence de connexion entre les machines qui se transmettent des données via UDP fait qu'il n'y a aucune synchronisation entre elles.
- Lors de l'envoi d'un datagramme par la machine émettrice, la machine réceptrice n'est pas prévenue préalablement. Elle doit donc être en permanence à l'écoute des ports sur lesquels les datagrammes sont émis, sinon les datagrammes reçus sont ignorés.
- La réception d'un datagramme ne présume en rien du fait que d'autres datagrammes puissent suivre. Le processus de réception – comme d'ailleurs celui d'émission – est à répéter intégralement à chaque nouveau datagramme. Mais ce processus étant bref, cela ne constitue pas un inconvénient significatif.
- L'absence de contrôle de bonne réception fait que le protocole UDP est réputé non fiable : la machine émettrice acquiert la confirmation que son datagramme émis a été bien reçu par une machine destinataire seulement si cette dernière lui répond (éventuellement pour lui demander de renouveler une émission), mais ce n'est pas prévu dans le protocole UDP. Son principe est donc en quelque sorte : « pas de nouvelles, bonne nouvelles ! »
On peut être surpris qu'un protocole aussi central qu'UDP soit uniquement spécifié par la RFC 768. En effet, ayant le statut de standard de l'Internet, cette dernière :
- fait seulement 3 pages ;
- n'a fait l'objet d'aucun erratum ni d'aucune mise à jour par une RFC ultérieure.
Elle est néanmoins complétée par la RFC 8085 qui précise les bonnes pratiques d'utilisation du protocole UDP. Son but principal est d'apporter des recommandations techniques pour la maîtrise des congestions dans les réseaux liés à l'utilisation croissante d'UDP – notamment dû au développement des applications de streaming.
Format des datagrammes UDP
Le format des datagrammes du protocole UDP est volontairement minimaliste. Il se compose (cf. figure ci‑après) :
- d'un en‑tête (header ou PCI pour protocol control information – cf. chap. R1‑IV ) de 8 octets, composé de 4 champs de 2 octets chacun (16 bits) – soit 4 entiers non signés dont les valeurs sont comprises entre
0et65535, codés en binaire naturel ; - d'une charge utile (payload ou SDU pour service data unit) formée par le message de l'application qui fait appel au protocole UDP pour le transport ; elle a une taille variable mais limitée (cf. infra ).
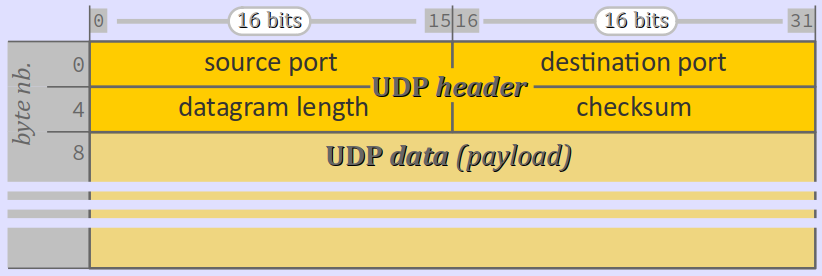
Détaillons maintenant les différents champs d'en‑tête (header's fields) d'un datagramme UDP.
- On a d'abord les numéros de port source et destinataire :
- le nº de port source spécifie aux machines réceptrices sur quel numéro de port elle doivent spécifiquement adresser un éventuel datagramme de réponse ; c'est un renseignement optionnel qui peut être codé à
0par défaut ; - le nº de port destinataire est impératif pour permettre aux machine réceptrices d'identifier l'application à laquelle s'adresse le datagramme qu'elles reçoivent ; sans cette information, le datagramme est ignoré.
- On a ensuite la longueur du datagramme (datagram length), qui est simplement son nombre d'octets – en‑tête incluse.
- On a enfin une somme de contrôle W (checksum) qui est calculée sur l'ensemble des mots binaires de 16 bits formant non seulement l'en‑tête et les données du datagramme, mais aussi sur la partie non‑optionnelle de l'en‑tête du PDU du protocole IP qui encapsule le datagramme – on parle de pseudo‑entête (cf. le schéma ci‑dessous pour un datagramme en IPv4, chap. R3‑II ).
- est facultatif en IPv4 – il suffit de renseigner la valeur 0 dans le champ de la somme de contrôle ; cette souplesse est intéressante lorsqu'un contrôle d'intégrité est déjà mis en œuvre par l'application qui fait appel à UDP ;
- est obligatoire en IPv6.
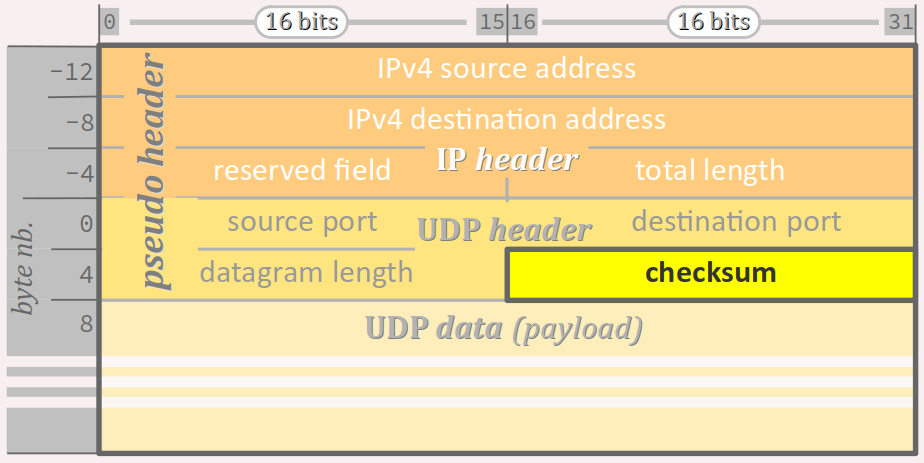
Le fait que la somme de contrôle d'un datagramme prenne en compte les adresses IP permet de procéder à une double vérification pour un temps de calcul à peine plus long.
Mais elle oblige à recalculer la somme de contrôle en cas d'usage d'un protocole de translation d'adresse – mécanisme qui permet aux paquets IP de passer dans un réseau privé à adresses non routables (cf. chap. R3‑II ).
Longueur des datagrammes UDP – notion de MTU
En théorie, la longueur totale d'un datagramme UDP (en‑tête incluse) est seulement limitée à 65 535 octets – donc, environ 65 ko – conformément au nombre maximal encodable dans le 3e champ de son en‑tête (datagram length – cf. supra ). C'est une taille « très confortable » au regard de la vocation du protocole UDP.
Mais en pratique, pour garantir l'absence de fragmentation du datagramme par le protocole IP (cf. chap. R3‑II ), cette longueur est fortement limitée. En effet, lorsqu'un datagramme entre dans un réseau IP via être un routeur‑passerelle, il est automatiquement fragmenté si sa longueur dépasse la valeur du MTU W – sigle qui signifie maximum transmission unit – imposée en sortie du routeur.
Le MTU est un paramètre qui dépend de la technologie de liaison employée. Usuellement, la longueur d'un datagramme est limitée à :
- 1500 octets sur les liaisons Ethernet ;
- 1468 octets sur les liaisons ADSL et Wi‑fi ;
soit environ 1,5 ko seulement.
Pour les applications de service – DNS en IPv4, DHCP, NTP… – cette longueur maximale est largement suffisante.
Mais pour du streaming où la vitesse est déterminante, une telle limite peut impacter l'efficacité des transmissions. Certains réseaux Ethernet réhaussent donc la limite jusqu'à 9000 octets. On parle alors de trames géantes W (jumbo frames).
Nomenclature des ports logiciels
D'après le format d'en‑tête des datagrammes UDP (cf. supra ), un numéro de port logiciel qui permet d'identifier l'application réseau source ou destinataire du datagramme est codé sur 16 bits. Il est donc nécessairement compris entre 0 et 65536 – et cette plage de valeurs possibles est aussi valable pour le protocole TCP.

Dans cette plage de valeurs possibles, les numéros inférieurs à 1023 (inclus) sont attribués par l'IANA (cf. chap. R1‑I ) aux applications les plus courantes. On parle de ports connus (en anglais, well‑known ports W) ou ports systèmes.
Quelques numéros de ports connus d'usage fréquent ont été listés au chapitre R1‑IV . Il est pertinent d'en récapituler la liste ici :
| Protocole(s) | Nº port(s) |
|---|---|
| FTP W (file transfer protocol) FTPS W (FTP over TLS) |
20 – 21 990 – 989 |
| Telnet W (terminal network) SSH W (secure shell) |
23 22 |
| DNS W (domain name system) | 53 |
| BOOTP W (bootstrap protocol) DHCP W (dynamic host configuration protocol) |
67 – 68 |
| HTTP W (hyper-text transfer protocol) HTTPS W (HTTP over TLS) |
80 443 |
| NTP W (network time protocol) | 123 |
| IMAP W (Internet message access protocol) IMAPS W (IMAP over TLS) SMTP W(simple mail transfer protocol) SMTPS W (SMTPS over TLS) |
143 993 25 465 |
| SNMP W (simple network management protocol) | 161 – 162 |
| SMB W (server message block) | 445 |
De façon beaucoup plus détaillée, une liste assez fournie des ports logiciels est consultable à ce lien W.
Attention ! En principe, un numéro de port connu ne doit pas être utilisé par aucune autre application que celle à laquelle il est attribué. D'ailleurs, une telle « usurpation » nécessite des droits d'administrateur pour être autorisée par le système d'exploitation de la machine, dans la mesure où elle présente un fort risque de conflit.
En revanche, on dispose de « souplesse » pour les autres ports.
- Ceux dont les numéros vont de
1024à49151sont également attribués par l'IANA mais à des applications plus spécialisées, d'usage moins courant. Ils peuvent donc être utilisés par d'autres applications avec, a priori, un moindre risque de conflit – mais néanmoins non nul. On parle de ports enregistrés (en anglais, registred ports W). - Ceux dont les numéros vont de
49152à65535ne sont pas attribués par l'IANA. Ils peuvent être utilisé a priori sans risque de conflit. On parle de ports dynamiques ou privés.
Sur une carte à microcontrôleur, le risque de conflit est très faible, dans la mesure où la carte ne peut mettre en œuvre qu'un nombre très réduit d'applications réseau . De plus, le codeur a en principe la maîtrise complète du programme utilisateur, donc des applications effectivement mises en œuvre.
Néanmoins, même dans ce contexte de mise en œuvre, simplement par soucis de lisibilité, on s'efforce d'adopter les mêmes conventions de choix de ports que sur les autres machines.
Intérêt du protocole UDP
Contrairement aux idées reçues que pourrait concevoir un débutant, les inconvénients notoires du protocole UDP – non connecté, non fiable, etc. – lui confèrent aussi deux avantages indéniables : la rapidité et la souplesse.
S'il s'agit de transmettre une donnée de petite taille, l'absence de connexion préalable – laquelle nécessite plusieurs échanges entre les applications émettrice et destinataire – ainsi que l'absence de contrôle de bonne réception, sont des stratégies tout à fait pertinentes en termes de rapidité d'exécution et de moindre impact sur le réseau. En effet, si l'application émettrice a émis une requête et attend une réponse, alors de deux choses l'une :
- ou bien une réponse arrive et cela signifie que le datagramme de requête est bien arrivé ;
- ou bien aucune réponse n'arrive et au delà d'un délai pré‑établi, l'application émettrice peut réitérer sa requête, exactement comme elle le ferait en cas d'échec dans le cadre d'un protocole sécurisé.
Par ailleurs, la possibilité de choisir une absence de contrôle d'intégrité permet de économiser le temps de calcul de la somme de contrôle, certes minime pour un seul datagramme, mais qui devient significatif pour un grand nombre de datagrammes dans le cadre d'une transmission de données en streaming.
Mise en œuvre sur une carte Arduino

Au chapitre R1‑III , on a présenté le module de bibliothèque Arduino EthernetA qui permet à une carte Arduino, lorsqu'elle est équipée d'un shield Ethernet comme celui en photo ci‑contre, de se connecter au réseau via une liaison Ethernet, en se dotant d'une configuration IPv4.
On a vu que ce module est composé de 15 fichiers sources et qu'il fait notamment appel à certains fichiers du noyau Arduino : Client.h, Server.h, IPAddress.h et IPAddress.cpp (cf. ce lien pour le framework des cartes à cœur AVR G).
Le module EthernetA du framework Arduino apporte tous les éléments de code – classes et méthodes - nécessaires pour envoyer et recevoir des datagrammes via le protocole UDP avec une carte reliée au réseau par une liaison Ethernet. De façon transparente pour le codeur, le module a recours au protocole IPv4 pour le routage des datagrammes (cf. infra ).
Avant tout, le fichier d'en‑tête Ethernet.h G déclare la classe EthernetUDP (lignes nº 152 à 209). Toutes les méthodes décrites ci‑après sont définies dans cette classe.
Cependant, il n'y a pas instanciation par défaut de cette classe, donc dans le fichier principal du programme utilisateur, il faut obligatoirement déclarer une instance – on dit aussi un objet – de cette classe pour pouvoir mettre en œuvre le protocole UDP. On code donc typiquement par une instruction comme :
EthernetUDP udp;
où l'identificateur udp désigne objet dont seront issues tous les appels de méthodes codés dans le programme.
Le code source de ces méthodes se trouve dans le fichier d'implémentation EthernetUdp.cpp consultable au lien suivant G.
Ensuite, il est nécessaire d'opérer un socket réseau – c'est‑à‑dire une tâche de fond s'exécutant en parallèle du programme pour recevoir et envoyer des données sur le réseau. Comme pour une liaison série, une telle tâche utilise un buffer de réception et un buffer d'émission (cf. chap. C3‑X C).
Pour employer un socket réseau, le codeur dispose des méthodes suivantes.
-
beginA mobilise un socket, sachant : - que cette méthode prend comme argument un numéro de port local (c'est‑à‑dire, pour la carte) – à choisir en fonction de l'application dont on veut transmettre les messages ;
- qu'elle retourne la valeur
1en cas de succès (socket disponible),0en cas d'échec. -
stopA libère le socket ; elle est sans argument et ne retourne aucune valeur.
Pour recevoir un datagramme UDP, on dispose notamment des méthodes suivantes (sachant que le code Arduino emploie le terme plus général « packet » et non pas « datagram »).
-
parsePacketA permet d'identifier un datagramme éventuellement présent dans le buffer de réception. -
readA permet de copier dans un tableau d'octet passé en premier argument (sous la forme d'un pointeur) n octets lus dans le buffer de réception – n étant passé en deuxième argument. - soit le dernier octet lu dans le buffer de réception – chaque octet lu étant supprimé du buffer ;
- soit la valeur
-1si le buffer est vide.
0 si aucun datagramme n'a été trouvé. Pour envoyer un datagramme UDP, on dispose notamment des méthodes suivantes.
-
beginPacketA compose l'en‑tête UDP et l'en‑tête IPv4 encapsulant la charge utile à venir. - Elle prend deux arguments : l'adresse IPv4 (de type
IPAddress) et le numéro de port (de typeuint16_t) du destinataire du datagramme. - Elle retourne la valeur
1en cas de succès,0en cas d'échec. -
writeA compose la charge utile du datagramme UDP dans le buffer d'émission, en recopiant depuis un tableau d'octet passé en premier argument (sous la forme d'un pointeur) n octets – n étant passé en deuxième argument (optionnel). -
endPacketA envoie le datagramme composé par les méthodes ci‑dessus. Elle n'a pas d'argument.
1 en cas de succès, 0 en cas d'échec. Le programme académique suivant permet de mettre en œuvre une messagerie instantanée (talk) par datagrammes UDP entre deux cartes Arduino chacune munie d'un shield Ethernet raccordé via un switch au même réseau local.
Chaque carte Arduino est en liaison USB avec un poste de travail pour permettre de utilisateurs de visualiser et saisir les messages dans le moniteur série de l'application Arduino IDE (cf. la figure ci‑contre où un seul poste est représenté car l'autre est symétrique).
La version présentée du programme est celle de la première carte (talker 1). Seules quelques modifications mineures de numérotation sont à apporter sur celle pour la deuxième carte (talker 2).
/* Talker 1 program */
#include <SPI.h>
#include <Ethernet.h>
const int SPI_SS_ETHERNET_PIN = 10;
byte mac[] = {0x90, 0xA2, 0xDA, 0x0D, 0x15, 0x43}; // talker 2 shield has another MAC
IPAddress local_ip (192, 168, 0, 101); // choose another IP on talker 2 program
IPAddress subnet (255, 255, 255, 0);
IPAddress gateway (192, 168, 0, 1);
IPAddress dns ( 8, 8, 8, 8);
EthernetUDP udp;
const uint16_t LOCAL_PORT = 5101; // swap port numbers on talker 2 program
const uint16_t TALKER_PORT = 5102;
IPAddress talker_ip (192, 168, 0, 102); // swap to 101 address on talker 2 program
void setup()
{
Ethernet.init(SPI_SS_ETHERNET_PIN);
delay(1000);
if (Ethernet.linkStatus() != LinkON) {
Serial.println("Link off! Check connectivity and reboot program...");
while (1);
}
Ethernet.begin(mac, local_ip, dns, gateway, subnet);
delay(1000);
Serial.begin(115200);
Serial.println();
Serial.flush();
Serial.println("Network connection successful:)");
Serial.print("IPv4 = "); Serial.println(Ethernet.localIP());
Serial.print("Gateway = "); Serial.println(Ethernet.gatewayIP());
Serial.print("DNS = "); Serial.println(Ethernet.dnsServerIP());
Serial.println("");
Serial.flush();
udp.begin(LOCAL_PORT);
}
void loop()
{
/* Read messages received form the other talker */
int nbOfbytesReceived = udp.parsePacket();
byte messageReceived[nbOfbytesReceived] = {0};
if (nbOfbytesReceived) {
if (udp.read(messageReceived, nbOfbytesReceived) == -1) {
Serial.println("Failed to read the message received :(");
}
else { // success :)
Serial.print("RCVD:\t ");
Serial.println(String((char*) messageReceived));
Serial.println();
}
}
/* Send messages typed by the user on the Serial Monitor */
String messageToSend("");
if (Serial.available()) {
messageToSend = Serial.readString();
if (!udp.beginPacket(talker_ip, TALKER_PORT)) {
Serial.println("Failed to create datagram header :(");
}
else { // success :)
if (!udp.write(messageToSend.c_str())) {
Serial.println("Failed to create datagram body :(");
}
else { // success :)
if (!udp.endPacket()) {
Serial.println("Failed to send datagram :( Check receiver IP");
}
else { // success :)
Serial.print("SEND:\t ");
Serial.println(messageToSend);
Serial.println();
}
}
}
}
}
Le programme commence par la déclaration des constantes et variables nécessaires à la connexion de la carte au réseau local : son adresse MAC et sa configuration IP statiques (lignes nº 7 à 11).
Ensuite sont déclarées les constantes et variables pour la mise en œuvre du protocole UDP (lignes nº 13 à 16) :
- l'objet
udp; - les numéros de ports logiciels choisis spécialement pour la messagerie instantanée (on aurait pu prendre n'importe quels autres numéros en dehors de la place des ports connus) ;
- l'adresse
IPde l'autre carte Arduino (celle du deuxième l'utilisateur de la messagerie, talker 2).
La fonction setup consiste principalement à initialiser la liaison Ethernet et à attribuer à la carte la configuration IP statique préalablement définie (cf. le chap. R1‑III pour plus de détails ).
Elle permet également d'appeler la méthode begin associée à l'objet udp pour mobiliser un socket réseau de la carte Arduino (ligne nº 43). Ainsi, les tâches relatives à l'envoi et à la réception de datagramme vont pouvoir s'exécuter en tâches de fond, en parallèle de l'exécution du programme utilisateur (cf. supra ).
Quant à la fonction loop, elle se divise en deux parties qui auraient chacune pu être codées dans une fonction séparée.
- La première partie (lignes nº 49 à 61) met en œuvre l'affichage des messages reçus sur la carte (cf. supra ).
- Avec la méthode
parsePacket, on commence par mémoriser le nombre d'octets reçus dans le buffer de réception de l'objetudp. Puis on déclare un tableau d'octets de la taille de ce nombre (lignes nº 50 & 51). - Ensuite, si ce nombre est non nul, on appelle la méthode
read, qui recopie le contenu du buffer de réception dans le tableau d'octet passé en argument. - Enfin, il ne reste plus qu'à coder l'affichage du message dans le moniteur série.
- La deuxième partie (lignes nº 63 à 85) met en œuvre l'envoi des messages saisis par l'utilisateur.
- Une fois qu'un tel message est détecté (via la méthode
Serial.available), on commence par le mémoriser dans la variablemessageToSendvia la méthodeSerial.readString(cf. chap. C3‑X C). - Ensuite, on appelle successivement les méthodes
beginPacket,writeetendPacketassociées à l'objetudp, conditionnées par des test de vérification de bonne exécution (cf. supra ). - Et pour finir, on procède à l'affichage du message sur le moniteur série afin d'en garder la trace.
Le protocole TCP
Caractéristiques générales
Le protocole TCP W – pour transmission control protocol – est un protocole de transport adapté aux données de grande taille (fichiers, courriels, etc.). Encore aujourd'hui principalement basé sur la RFC 793 de 1981, il opère :
- avec segmentation, associé à un contrôle de flux,
- en mode connecté, donc forcément en unicast,
- et avec contrôle de bonne réception des données par acquittement, associé à un contrôle d'intégrité.
autrement dit, de façon « diamétralement opposée » à UDP (cf. supra ). Pour éviter les confusions, dans le cadre de ce protocole, les PDU (protocol data units – cf. chap. R1‑IV ) sont appelés des paquets.
Le protocole TCP est beaucoup plus complexe qu'UDP. On se propose de donner d'abord un descriptif sommaire, afin de ne pas en compromettre la compréhension par une avalanche de détails.
- Une connexion est mise en place au début de la transmission. Elle consiste en un processus bilatéral :
- sur la machine émettrice, pour envoyer des paquets de données et recevoir leurs paquets d'acquittement respectifs ;
- sur la machine destinataire, pour recevoir les paquets de données et émettre leurs paquets d'acquittement respectifs ;
- La segmentation des données en segments s'accompagne bien entendu d'une numérotation de contrôle, afin que les octets des données puissent être ordonnés après réception par la machine destinataire – dans la mesure où aucune garantie n'existe quant l'ordre d'arrivée des paquets transportant les données (ils peuvent être routés différemment dans le réseau).
- Le contrôle de réception et d'intégrité est également bilatéral. Il consiste, pour chacune des deux machines :
- à indiquer quels numéros d'octets des données ont bien été correctement reçus ou acquittés ;
- à réitérer l'envoi de tout paquet perdu ou corrompu, qu'il s'agisse d'un paquet d'émission ou d'acquittement.
- Le contrôle de flux signifie que le rythme d'émission des paquets est ajusté en fonction de celui de réception des paquets d'acquittement.
Ci‑après, une sous‑section est respectivement consacrée à chacun de ces aspects pour apporter tous les détails nécessaires à leur bonne compréhension.
- Malgré ses 85 pages, la RFC 793 reste assez imprecise sur les détails de fonctionnement du protocole TCP, ce qui est compréhensible au regard de sa date d'édition très ancienne (1981). Et malheureusement, les explications complémentaires sont dispersées dans de nombreuses autres RFC, ce qui ne facile pas l'étude de ce protocole.
- Bien que les RFC soient assez rigoureuses en matière de terminologie, il peut exister dans le reste de la littérature certaines ambiguïtés entre les termes de paquet et de segment, qui sont essentiellement synonymes à une métonymie près (confusion contenant/contenu).
Format des paquets TCP
Un paquet du protocole TCP adopte une forme globale comparable à celle d'un datagramme UDP. On y trouve :
- un en‑tête (header ou PCI pour protocol control information – cf. chap. R1‑IV ) de 20 à 60 octets, composé de 8 champs obligatoires et d'autres optionnels, chacun de différentes largeurs ;
- une charge utile (payload ou SDU pour service data unit) qui constitue un segment des données de l'application qui fait appel au protocole TCP.
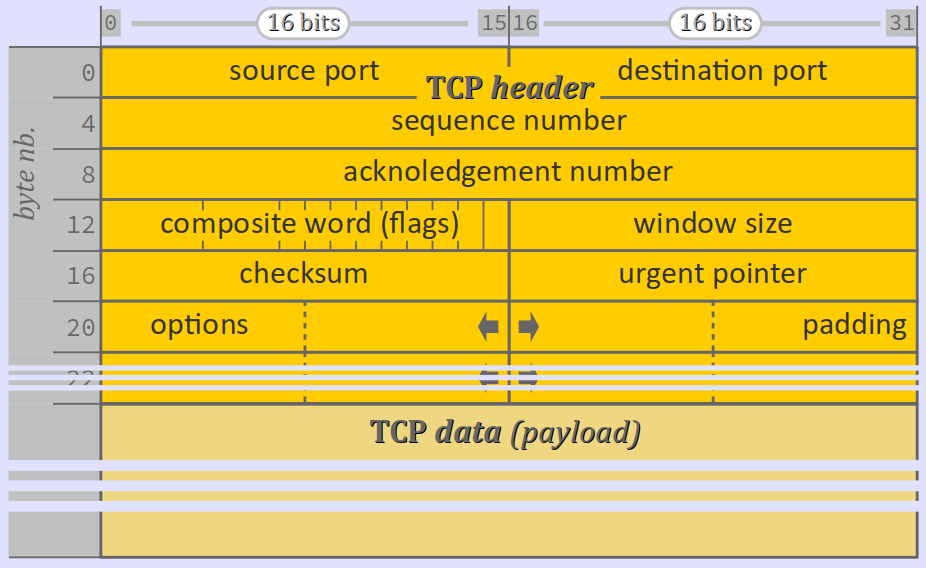
Détaillons maintenant les différents champs d'en‑tête (header's fields) d'un paquet TCP :
- On a d'abord les numéros de port source et destinataire, exactement comme pour un datagramme UDP (cf. supra ).
- On a ensuite le numéro de séquence du premier octet du segment dans la numérotation globale des données à envoyer. C'est un entier non signé encodé sur 32 bits (donc avec une valeur maximale d'environ 4 milliards), dont les débordements sont traités en arithmétique cyclique.
- Puis on a le numéro d'acquittement (acknowledgment number), qui est a priori le numéro de séquence du prochain octet de données attendu par la machine – qu'il s'agisse d'un paquet d'émission ou d'acquittement. C'est également un entier non signé encodé sur 32 bits, dont les débordements sont traités en arithmétique cyclique.
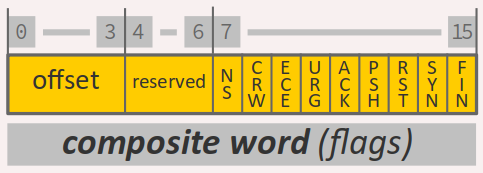
- Le mot composite est quant à lui codé sur 16 bits et comporte 11 champs dont 9 drapeaux W (bits de signalisation, en anglais flags).
- Le champ
offset(data offset), encodé sur 4 bits indique la taille de l'en‑tête du paquet, exprimée en nombre de mots de 32 bits. Autrement dit, c'est le nº du mot de 32 bits du paquet à partir duquel se trouve le premier octet de données. Ce décalage dépend donc de la longueur cumulée des champs d'options (cf. infra). - Le champ réservé est, comme son nom l'indique, réservé pour des développements futurs de la norme du protocole ; pour le moment, il doit être rempli de 0.
- Le champ des drapeaux encode 9 informations binaires.
- Les trois premiers bits sont utilisés pour la gestions des congestions – explicit congestion notification ou ECN :
- Le bit
NS– pour ECN nonce sum, c'est‑à‑dire une somme de bits aléatoires, encodée sur un seul bit – est encore d'usage expérimental ; il sert pour la protection contre la dissimulation (accidentelle ou malicieuse) des paquets signalés ECE (cf. le bit éponyme ci‑après). - Le bit
CWR– pour congestion window reduced – indique que la congestion a été prise en compte par l'émetteur. - Le bit
ECE– pour ECN echo – indique qu'une congestion est signalée par le protocole IP. - Le bit
URG– pour urgent – signale que la valeur du pointeur d'urgence (champ ultérieur – cf. infra ) est pertinente. - Le bit
ACK– pour acknowledgement – indique l'acquittement d'une connexion ; une fois que la transmission est en cours, ce bit signale que le numéro d'acquittement est valide (si le bit vaut 0, le numéro d'acquittement n'est pas pertinent et doit être ignoré). - Le bit
PSHindique que la fonction push est demandée. Elle permet d'accélérer la transmission des données à l'application sur la machine destinataire, sans attendre dans le buffer de réception. - Le bit
RST– pour reset – indique une demande de réinitialisation de la transmission en cours. - Le bit
SYN– pour synchronize – est utilisé durant l'établissement d'une connexion, laquelle consiste en la synchronisation des numéros de séquence entre les deux machines. - Le bit
FIN– pour finish – indique la fin de la transmission (dernier paquet). Il est également utilisé pour effectuer la terminaison de la connexion entre les machines émettrice et destinataire. - Ensuite, on a le champ qui code la taille de la fenêtre de transmission (windows size). Encodé sur 16 bits, elle indique le nombre d'octets qu'une machine destinataire peut traiter dans son buffer de réception. La valeur de ce champ est ajustée en temps réel au fur et à mesure de la transmission et participe ainsi au contrôle de flux (cf. infra ).
- Puis on a le champ de somme de contrôle (checksum), encodé sur 16 bits, qui utilise la même formule que celle du protocole UDP en intégrant l'en‑tête du protocole IP (cf. supra ).
- Puis on a le champ du pointeur d'urgence (urgent pointer) encodé sur 16 bits. Si le bit
URGvaut1(cf. supra ), le champ indique le numéro de séquence du segment qu'il est le plus urgent d'envoyer (ce champ est spécifié par la machine destinataire dans la perspective d'assembler les données). - Enfin, on a les champs d'options, qui sont facultatifs et qui peuvent prendre de 0 à 10 mots de 32 bits, chaque mot pouvant présenter 1 à 3 octets de remplissage garnis exclusivement de
0(padding).
Déroulement du protocole TCP
Le déroulement du protocole TCP comporte nominalement 3 phases :
- l'établissement de la connexion entre les machines émettrice et destinataire ;
- le transfert de données, durant lequel la connexion est maintenue ;
- la clôture de la connexion, qui nécessite également un échange protocolaire.
La connexion TCP se traduit par le démarrage, sur chacune des deux machines, d'un processus s'exécutant en tâche de fond du système d'exploitation – un socket réseau W – qui contrôle l'émission et la réception des paquets.
Cette connexion opère en circuit virtuel W car elle ne mobilise aucune liaison particulière entre les machines. Elle ne nécessite donc aucune indication de routage et laisse cette problématique entièrement à la charge du protocole IP – lequel doit être mis en œuvre sur tous les réseaux traversés et permet de faire éventuellement passer les paquets par différents chemins.
Établissement d'une connexion TCP
L'établissement d'une connexion en circuit virtuel entre la machine émettrice et la machine destinataire nécessite la transmission de trois paquets – en anglais, on parle de three‑way handshake W.
Au cours de cet échange protocolaire, les deux machines valident mutuellement leurs numéros de séquences respectifs en les mettant à jour dans l'en‑tête des paquets TCP, et en utilisant également les drapeaux SYN (synchronization) et ACK (acknowledgment) figurant dans le mot composite des paquets (cf. supra. ).
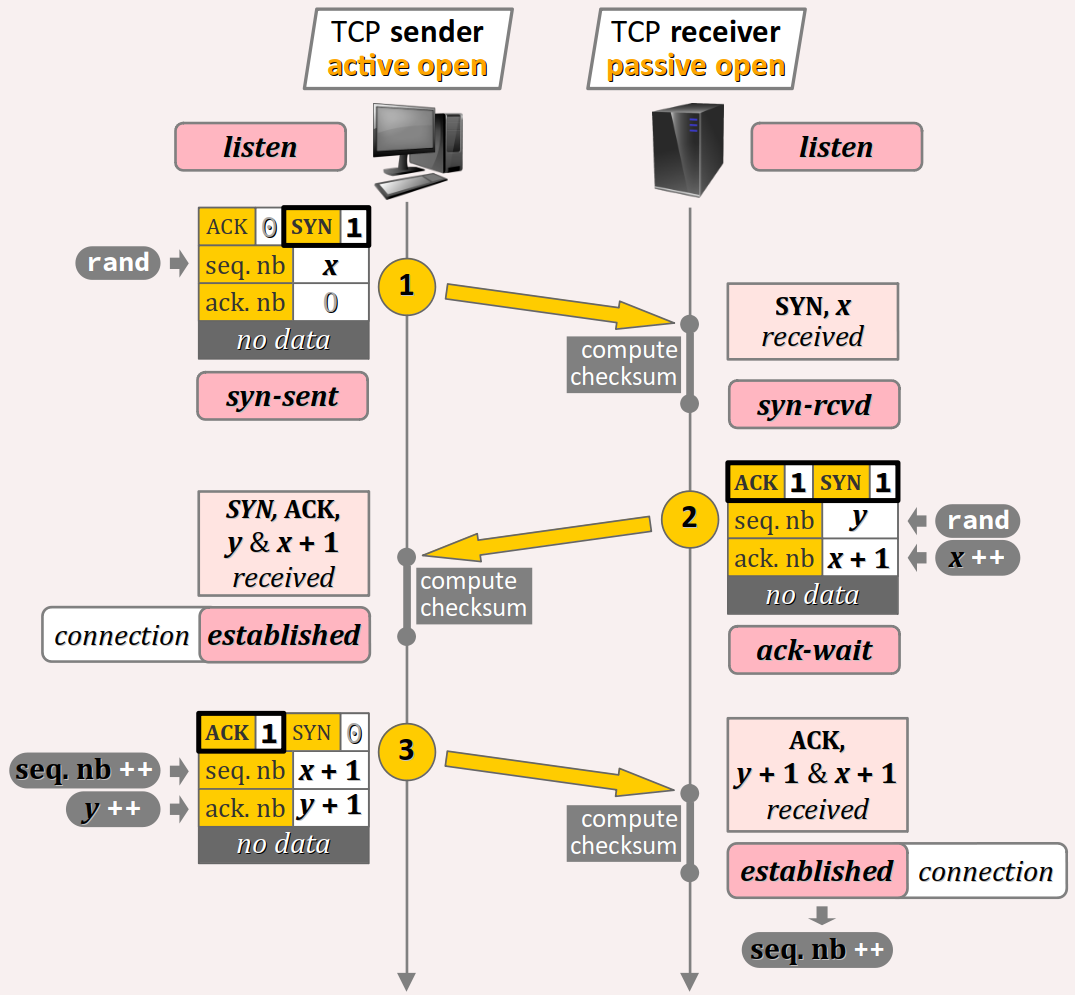
Sauf dysfonctionnement, le protocole se déroule comme dans l'exemple générique représenté sur la figure ci‑dessus :
- L'émetteur – typiquement, un poste de travail – envoie au destinataire – typiquement, un serveur – un paquet initial dont le bit
SYNest mis à1. De plus : - il génère son numéro de séquence par un nombre aléatoire, noté ici x ;
- son numéro d'acquittement est mis à 0 mais cette valeur est non pertinente car le bit
ACKest mis à0; - a priori, le paquet ne contient aucune donnée.
- Après réception et contrôle d'intégrité de ce paquet initial, le destinataire envoie à l'émetteur un paquet d'acquittement dont les bits
SYNetACKsont tous les deux mis à1. De plus : - le destinataire génère son propre numéro de séquence par un autre nombre aléatoire, noté ici y ;
- et il inscrit dans numéro d'acquittement la valeur x + 1, signifiant par là qu'il accuse bonne réception du numéro de séquence de l'émetteur ;
- a priori, le paquet ne contient aucune donnée.
- Après réception et contrôle d'intégrité de ce paquet d'acquittement, l'émetteur envoie un paquet de confirmation dont seul le bit
ACQest mis à1; - il inscrit dans son numéro de séquence la valeur x + 1 ;
- il inscrit dans numéro d'acquittement la valeur y + 1, signifiant par là qu'il accuse bonne réception du numéro de séquence du destinataire ;
- éventuellement, ce paquet pourrait être mis à profit pour envoyer des données.
Notons que ce paquet de confirmation fera lui‑même l'objet d'un acquittement par le destinataire, comme pour tous les envois par l'émetteur. Néanmoins, cet acquittement ne fait pas explicitement partie de la phase d'établissement de la connexion et l'émetteur n'a pas besoin d'attendre sa réception pour envoyer des données.
Pour une illustration avec un exemple réel, on pourra consulter cette page web , qui fournit un lien pour télécharger un fichier de capture de trames à ouvrir dans le logiciel Wireshark.
Transmission de données
Une fois que la connexion est établie, le protocole TCP cadence la transmission de données par une succession d'émission‑réception de paquets, chaque paquet contenant soit un segment des données à envoyer, soit une information d'acquittement pour un segment bien reçu, sachant qu'il n'y a pas forcément une stricte alternance entre les segments envoyés et leurs acquittements respectifs.
- Après chaque segment envoyé, l'émetteur incrémente son numéro de séquence du nombre d'octets que ce segment contient.
- Après chaque segment reçu et vérifié, le destinataire incrémente son numéro d'acquittement du nombre d'octets que ce segment contient.
Pour l'étude du déroulement du protocole TCP, il est plus commode de raisonner en termes de numérotation relative, c'est‑à‑dire en occultant les valeurs aléatoires x et y générées respectivement par l'émetteur et le destinataire pour former leurs numéros de séquence.
Ici, dans la continuité de l'exemple générique précédent, on se place dans le cas où, après l'établissement de la connexion, le serveur traite une requête HTTP (typiquement, une méthode GET – cf. chap. R2‑III ) envoyée juste avant par le poste de travail. Il a donc inversion des rôles initiaux car maintenant :
- le serveur joue le rôle d'émetteur – avec un numéro de séquence a ; il envoie régulièrement des segments de n octets ;
- le poste de travail joue le rôle de destinataire – avec un numéro de séquence b ; il répond au serveur par autant de paquets d'acquittement qui ne contiennent aucune donnée.
Et donc, sur la figure ci‑dessus, le serveur est représenté à gauche et le poste de travail à droite.
Remarque : après chaque envoi d'un paquet d'acquittement par le poste de travail, les deux machines ont leurs numéros de séquence et d'acquittement respectivement égaux.
Terminaison d'une connexion TCP
Quant à la terminaison d'une connexion TCP, elle se déroule selon un protocole similaire à celui d'établissement, mais en quatre étapes, avec cette fois l'utilisation des bits FIN et ACK pour identifier les paquets transmis (cf. la figure ci‑dessous).
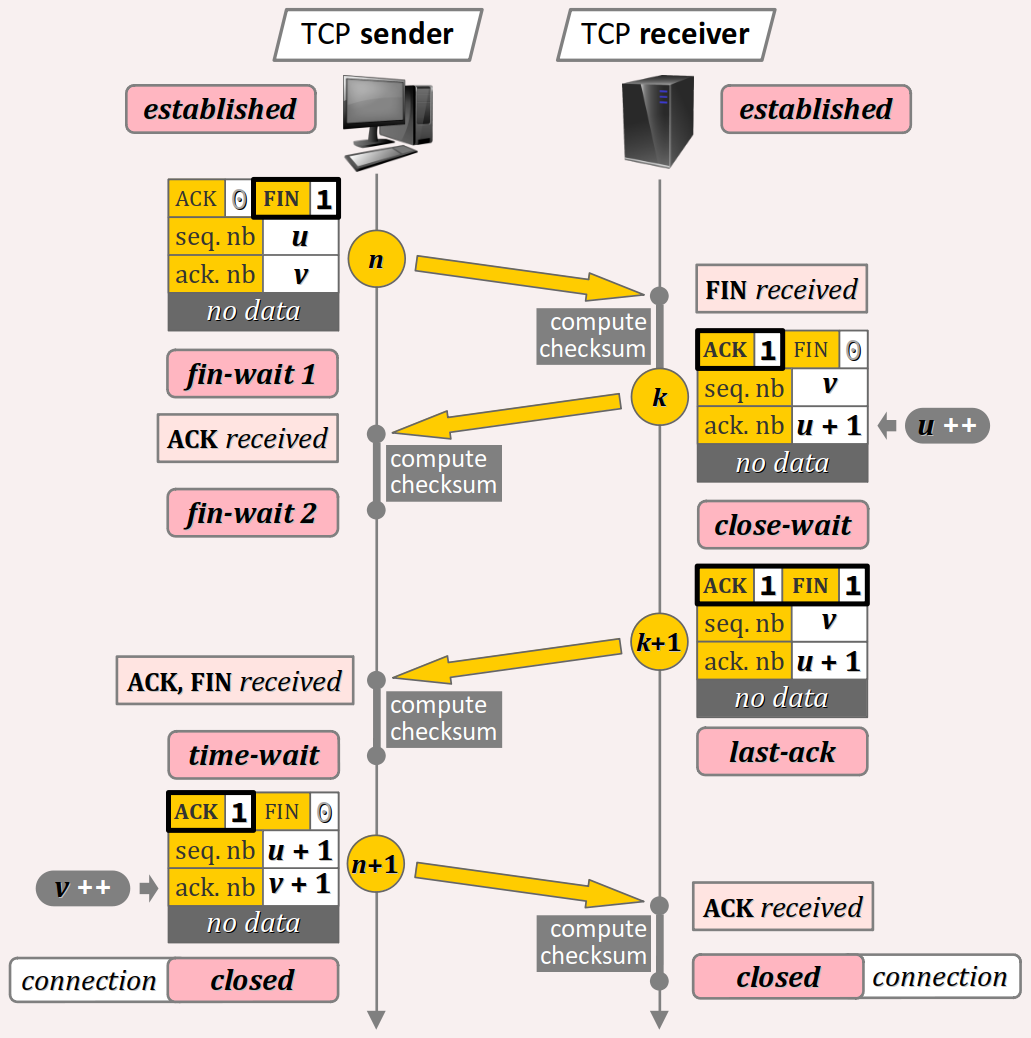
Là encore (cf. supra ), pour étudier cet aspect du protocole, il est plus commode de raisonner en termes de numérotation relative avec des numéros de séquences et d'acquittement du poste de travail notés respectivement u et v sur la figure ci‑dessus.
Le contrôle de réception et d'intégrité
Le protocole TCP met en œuvre un contrôle de bonne réception systématique de tous les paquets issus de la machine émettrice :
- tout paquet reçu par une machine destinataire déclenche immédiatement l'envoi par cette dernière d'un paquet d'acquittement ;
- ainsi, après écoulement du délai maximal supposé nécessaire à la transmission d'un paquet et de son acquittement – le timeout – toute non réception de ce dernier par la machine émettrice est interprété comme une perte, et déclenche automatiquement une nouvelle émission du paquet – procédure appelée ARQ (pour automatic repeat request W).

La valeur limite du délai d'acquittement (timeout) doit être judicieusement choisie :
- une valeur trop petite engendre de trop fréquentes réitération d'envoi des paquets supposés perdus alors qu'ils allaient arriver ; par « impatiente » la machine émettrice perd du temps en envois inutiles et contribue davantage à une éventuelle congestion du réseau.
- une valeur trop grande engendre du retard dans la réitération d'envoi de paquets réellement manquants ; or tant que tous les paquets n'ont pas été reçus, la donnée transmise ne peut pas être reconstituée sur une machine destinataire.
En pratique, le délai d'acquittement est un paramètre dynamique calculé en fonction de la fluidité réelle des communications entre les machines émettrice et destinataire. Cette fluidité est usuellement quantifié par le round-trip time W ou RTT – aussi dit ping time, car c'est le temps que met la machine émettrice à recevoir une réponse à un PDU qu'elle envoie par le protocole ICMP (cf. chap. R1‑IV ).
Typiquement, on affecte au timeout la valeur moyenne de RTT augmentée de 4 fois sa variance W – les paramètres statistiques (moyenne et variance) étant réactualisés en permanence W.
Le contrôle d'intégrité
Le contrôle de réception se double du contrôle d'intégrité de chaque paquet, mis en œuvre par le calcul d'une somme de contrôle qui, comme on l'a vu, utilise la même formule que ceux du protocole UDP (cf. supra ).
En revanche, la stratégie mise en œuvre en cas de paquet corrompu ne procède pas par ignorance comme dans le protocole UDP.
Tout paquet réputé corrompu déclenche l'émission par une machine destinataire d'un paquet de non‑acquittement, codé par le fait que son bit ACK est mis à 0. Cette procédure est meilleure que celle qui consisterait à ne rien faire dans la mesure où elle permet de signaler le problème à la machine émettrice le plus tôt possible, donc avant l'expiration du délai de non‑réception (timeout – cf. supra ).
Comme l'écoulement du timeout, la réception par la machine émettrice d'un paquet de non‑acquittement déclenche l'envoi réitéré du paquet corrompu (c'est là procédure ARQ – cf. supra ).
Les contrôles de bonne réception et d'intégrité garantissent au protocole TCP son excellente fiabilité.
La segmentation des données
On a vu supra que la transmission des données par le protocole TCP opère par une succession d'émission‑réception de paquets, chaque paquet issus de la machine émettrice contenant dans sa charge utile un segment des données à transmettre.
La segmentation des données à envoyer est opérée selon un nombre maximal d'octets fixé lors de l'établissement de la connexion.
- Cette information est transmise dans le champ d'option MSS W – pour maximum segment size – du premier paquet de connexion – dit paquet « SYN » – envoyé par la machine émettrice.
- Le champ MSS doit être confirmé par la machine destinataire en étant inscrit dans le « paquet SYN‑ACK » envoyé en réponse au cours du processus de connexion (cf supra ).
La valeur du champ MSS est optimisée pour éviter le plus possible la fragmentation des paquets au niveau du protocole IP, en se basant sur la limite déterminée par la technologie de liaison la plus contraignante sur laquelle les données transitent – limite appelée MTU (maximum transmission unit), déjà évoquée lors de l'étude du protocole UDP (cf. supra ).
En tenant compte de la taille de l'en‑tête du paquet TCP – soit 20 octets – et de celle du datagramme IPv4 qui l'encapsule (encore 20 octets), la formule retenue est MSS = MTU − 40.
Exemple : pour une liaison Ethernet, on a MSS = 1500 − 40 = 1460 octets.
Le contrôle de flux de TCP
Le contrôle de flux est une problématique générale des protocoles de communication pour la transmission de données volumineuses – typiquement, TCP, mais aussi HDLC (high‑level data link control W) ou encore PPP (point‑to‑point protocol ). Il consiste à réguler le débit d'emission des données au regard du débit de réception, au risque sinon de provoquer une congestion (cf. infra ).
Il existe différentes techniques de contrôle de flux, notamment les deux suivantes :
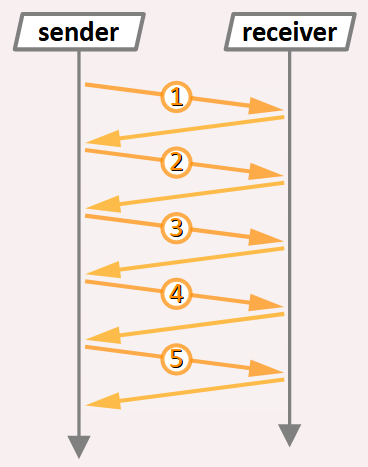
- La technique du stop‑and‑wait Y consiste à envoyer les paquets de données un par un, en attendant l'acquittement de chacun pour envoyer le suivante (cf. la figure ci‑contre).
- La technique de la sliding window Y – c'est‑à‑dire la fenêtre glissante – consiste à envoyer succesivement des paquets de données en décrémentant un compteur pour chaque octet envoyé, et sachant que :
- lorsque le compteur atteint la valeur 0, l'émetteur doit attendre ;
- le compteur incrémenté d'autant d'octets que ceux contenus dans les paquets acquittés ;

Pour assurer le contrôle de flux, le protocole TCP met en œuvre la technique de la fenêtre glissante.
La taille de la fenêtre est renseignée dans l'en‑tête de chaque paquet par le champ window size (cf. supra ).