
Dès la naissance du réseau Arpanet, il était évident que les utilisateurs apprécieraient d'employer des adresses littérales et non pas numériques pour transmettre des données. Un fichier d'annuaire centralisé des machines hôtes, nommé hosts.txt fut donc créé au Stanford Reseach Institute (SRI) W pour mettre en correspondance les noms des machines et leurs adresses IP respectives.
Mais rapidement, il fallu confier les incessantes mises à jour et diffusions de ce fichier à un département spécialisé, le Network Information Center. Et avec la croissance exponentielle du réseau – et donc des requêtes en consultation et modifications – comme en matière d'adresses IP (cf. chap. R1‑III ), toute solution centralisée était vouée à l'échec.

Aussi, dès 1983 (RFC 882 ) commence la mise en place d'un système distribué de serveurs de noms appelé domain name system ou DNS W. Contribueront notamment à sa conception Paul Mockapetris W, chercheur au SRI et Jonathan Postel W, professeur à l'UCS (University of Southern California) – respectivement à gauche et à droite sur la photo ci‑contre.

Aujourd'hui, le DNS de l'Internet constitue un véritable système informatique, complexe et très sollicité : presque toutes les applications web font appel à lui pour pouvoir fonctionner. Il est organisé en une myriade de zones d'autorité qui implémentent sa décentralisation.
Incontournable, le DNS a été évoquée dès le chapitre R1‑I . Pour un simple internaute, il peut sembler « transparent », tant son usage est simple (il suffit de saisir des noms de domaines pour accéder aux ressources). Mais pour un futur technicien réseau, il requiert un certain nombre de connaissances et de savoir‑faire indispensables. En effet :
- chaque organisme disposant d'un nom de domaine public formant une zone d'autorité est responsable de « son » DNS et doit l'administrer ;
- sur un réseau local privé, il n'est pas rare de mettre en place un DNS privé, qui opère de la même manière que celui de l'Internet.
Dans une perspective de découverte avancée, ce cours aborde :
- les principes généraux du DNS, et en particulier l'architecture pour le mettre en œuvre (serveurs de noms, résolveur, mémoire cache…) ;
- les noms de domaines – l'espace qu'ils forment, les règles syntaxiques qui les régissent, la notion d'alias, les enregistrements ;
- les URL (uniform resource locator) qui exploitent les noms de domaines pour cibler des ressources accessibles sur un réseau ;
- le fonctionnement opérationnel du DNS, et notamment ses aspects protocolaires ;
- et pour finir, quelques outils logiciels du DNS, notamment pour inspecter des enregistrements, mais aussi pour mettre en œuvre un résolveur ou un serveur de noms local.
Le DNS – principes généraux
Généralités

Un DNS W ou domain name system est un service réseau applicatif dont la fonction principale est de déterminer une ou plusieurs adresse(s) IP associée(s) à un nom de domaine dans un réseau informatique (public ou privé) géré par la pile de protocoles TCP/IP. Un tel système permet de mettre en œuvre un adressage littéral des ressources du réseau, ce qui facilite grandement leur accès aux utilisateurs.
Plutôt que de détermination d'adresse(s) IP, on parle de résolution de nom de domaine.
Par défaut, le sigle DNS fait référence au système de résolution global des noms de domaines de l'Internet. Ce dernier ne fournit que des adresses IP publiques.
Mais il est également possible de mettre en place un DNS dans un réseau privé. En effet, de même qu'il existe des adresses IP privées non routables sur l'Internet (cf. chap. R1‑III ), on peut définir des noms de domaines privés, c'est‑à‑dire qui ne peuvent pas être résolus par le DNS de l'Internet.
Le DNS fait l'objet de nombreuses RFC, les plus importantes étant :
- la RFC 1034 consacrée aux concepts et aux infrastructures du DNS – elle constitue en fait une introduction générale ;
- la RFC 1035 consacrée à l'implémentation et à la spécification du DNS – elle expose tous les détails techniques ;
- la RFC 9499 consacrée aux bonnes pratiques les plus récentes et qui, se faisant, reformule toute la terminologie du DNS.
Les serveurs de noms

Pour répondre dans les meilleurs délais aux milliards de requêtes quotidiennes en résolution de nom qu'il reçoit, le DNS fait appel à un grand nombre de serveurs – des machines exécutant un logiciel spécifique sur une base de donnée – appelés serveurs de noms W (name server).
Remarque : étant donnée leur fonction, on devrait parler plutôt de « serveurs d'adresses ».
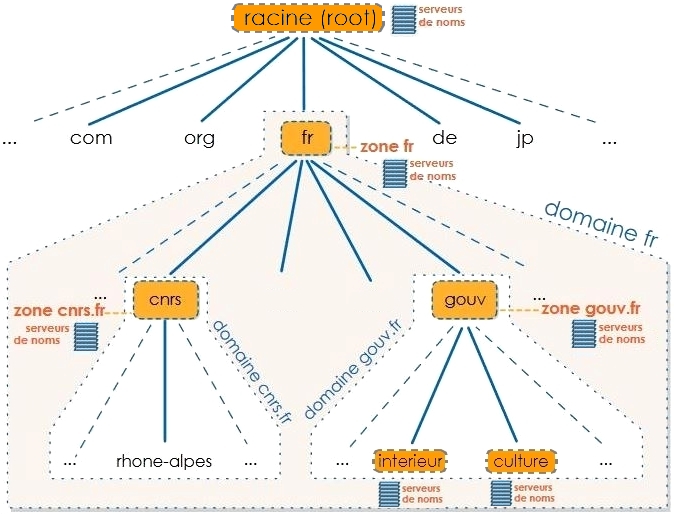
Les serveurs de noms forment une topologie en arbre qui est constituée d'une myriade de zones d'autorité hiérarchisées.
- Chaque zone d'autorité doit prendre en charge, de façon autonome, la résolution des noms du domaine qu'elle comprend – cette zone pouvant s'étendre sur plusieurs niveaux de sous‑domaines. On dit du ou des serveurs de noms qu'elle emploie qu'ils font autorité sur la zone (en anglais, on parle d'authoritative name servers).
- La hiérarchie des noms de domaines obéit au principe de délégation descendante, c'est‑à‑dire depuis la racine de l'arbre vers les feuilles.
- le serveur de la zone
frne fera que retourner l'adresse IP d'un serveur de noms de la zonegouv.fr; - qui lui‑même retournera l'adresse IP du serveur de noms faisant autorité sur la zone
culture.gouv.fr; - et c'est seulement ce dernier serveur de nom qui fournira l'adresse IP de la ressource demandée – typiquement celle du serveur web de la page d'index de ce domaine.
- La racine (unique) de l'arbre constituant l'ensemble de tous les noms de domaines publics forme une zone spéciale placée sous l'autorité de l'ICANN (cf. chap. R1‑I ). Ses serveurs de noms sont appelés les serveurs racine W du DNS (root name servers). Ils ne résolvent que les noms de domaines dits de premier niveau – tous individuellement constitués en zones distinctes, par exemple
org,com,fr, etc.
www.culture.gouv.fr : www.culture.gouv.fr, un serveur racine ne fera que retourner l'adresse IP d'un serveur de noms faisant autorité sur le domaine fr. - La topologie du DNS ne correspond pas du tout à celle du « réseau » Internet. En effet, cette topologie ne fait apparaître que les serveurs de noms et les ressources (serveurs de données ou autres) ayant une adresse publique. Elle ne révèle rien de la redondance des serveurs ni de l'existence des routeurs, ni même de la multiplicité des routes entre les machines en général.
- Les serveurs racine font l'objet de quelques phantasmes et idées reçues en termes de criticité, qu'il importe de relativiser .
- Certes, il n'y a que 13 adresses logiques de serveurs racine (cf. W) mais chacune redirige vers une multitude de serveurs physiques répliqués en redondance.
- Certes, 10 des 13 serveurs étaient historiquement situés sur le territoire des États‑Unis, mais une bonne part sont maintenant opérés par adressage anycast W, si bien que leurs serveurs physiques peuvent être – et sont – situés partout dans le monde.
- Certes, toute requête en résolution de nom passe en principe par un serveur racine, mais :
- comme il y a assez peu de domaines de premier niveau (de l'ordre de 1500 seulement en 2020), répondre à une requête ne nécessite qu'une recherche modeste dans la base de donnée d'un serveur racine ;
- l'emploi des mémoires caches dans les résolveurs (cf. infra ) diminue grandement le nombre de requêtes réellement soumises aux serveurs racine.
- Enfin, les attaques de grande ampleur sur les serveurs racine (cf. W) ont permis de constater que la qualité de service globale du DNS était assez peu affectée par ces attaques.
Notion d'enregistrement

Tout serveur de noms du DNS embarque une base de donnée qui contient principalement des enregistrements d'adresse – en anglais address record – de la forme :
Mais il existe d'autre types d'enregistrements, notamment les alias (cf. infra ). De façon générale, on parle d'enregistrement de ressource – en anglais resource record W (abrégé RR) – pour qualifier tout enregistrement dans la base de donnée d'un serveur de noms du DNS.
Dans la pratique, un enregistrement comporte d'autres informations techniques en plus des deux champs de la forme donnée ci‑dessus. Sa composition sera détaillée infra .
Les serveurs DNS dits résolveurs
Étant donné à l'hyper‑complexité de l'Internet, une requête en résolution de nom issue d'une application ne peut pas être adressée directement à un serveur racine, sinon ces derniers seraient beaucoup trop sollicités. Elle passe par un autre type de serveur du DNS appelé résolveur – donc, à ne pas confondre avec un serveur de nom.
Un résolveur DNS agit comme un intermédiaire : il joue le rôle de serveur pour la machine terminale et de client pour les serveurs de noms, en exécutant un algorithme de résolution de nom.
On verra infra qu'il dispose de sa propre base de donnée, appelée cache.
Un résolveur DNS assure un service crucial. En cas de dysfonctionnement, la navigation sur l'Internet devient quasi impossible : les hyperliens ne fonctionnant plus, il faudrait saisir les adresses IP des sites pour y accéder, ce qui est très laborieux.
C'est pourquoi, en règle générale, la configuration réseau de l'interface d'une machine comporte au moins deux adresses IP de résolveur DNS (cf. chap. R1‑III ). Elles déterminent respectivement ce qu'on appelle les résolveurs DNS primaire et secondaire, prévus pour coopérer dans un système de répartition de charge.
Choix d'un résolveur DNS public
On parle de résolveur DNS public lorsqu'un tel serveur est accessible via une adresse IP publique sans limitation de droit d'accès. Cette adresse est alors utilisable telle pour configurer n'importe quelle interface disposant d'un accès à l'Internet.
En règle générale, un adresse IP de résolveur DNS public donne accès à un pool de serveurs géré par un système de répartition de charge.
Par défaut, tout fournisseur d'accès à l'Internet met à disposition de ses abonnés (ou de tout autre internaute) deux adresses IP de résolveurs DNS publics, respectivement primaires et secondaires. Elles sont attribuées automatiquement aux interfaces des machines reliées à la box via son service DHCP.
Le FAI Free SAS donne les adresses IP publiques de résolveurs DNS suivantes :
- DNS primaire
212.27.40.240(IPv4) ou2a01:e0c:1:1599::22(IPv6) ; - DNS secondaire
212.27.40.241(IPv4) ou2a01:e0c:1:1599::23(IPv6).
Ce faisant, un fournisseur d'accès est en mesure de connaître toutes les requêtes en résolution de noms des internautes qui recourent à son service de résolveur DNS. Ces données ont une grande valeur commerciale, elles permettent de répondre aux attentes des organisations qui souhaite connaître les tendances d'actualité, l'évolution de la popularité de tel ou tel sujet, etc.
Par ailleurs, certains grands acteurs du web offrent également un service de résolveur DNS public avec des adresses IPv4 particulièrement faciles à mémoriser :
| Entreprise | DNS primaire | DNS secondaire |
|---|---|---|
8.8.8.8 2001:4860:4860::8888 |
8.8.4.4 2001:4860:4860::8844 |
|
| Cloudflare | 1.1.1.1 2606:4700:4700::1111 |
1.0.0.1 2606:4700:4700::1001 |
Plus généralement, on trouve une liste très complète, classée par pays, et en régulièrement actualisée des adresses de résolveurs DNS publics au lien suivant .
Mais au delà des considérations en termes de performance ou de confidentialité pour choisir tel ou tel service , les adresses IP remarquables données dans le tableau ci‑dessus sont utiles à connaître pour un technicien des réseaux. Elles constituent un bon choix par défaut lorsqu'on définit la configuration statique d'une interface ou les paramètres d'un serveur DHCP, et qu'on ne dispose pas encore d'un accès à l'Internet pour déterminer des adresses de résolveurs DNS.
Mode opératoire d'un résolveur DNS
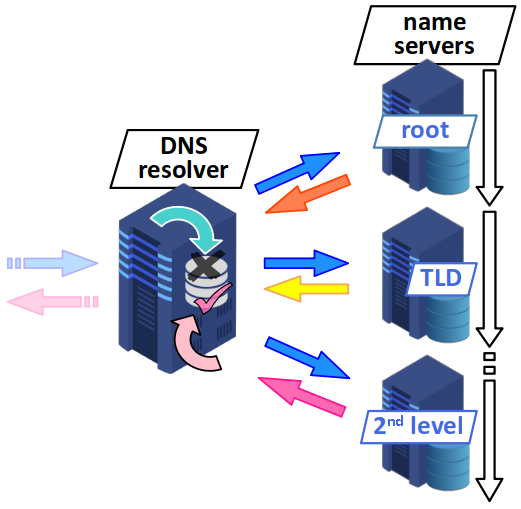
Même s'il est le plus souvent implémenté sur une machine dédiée (typiquement un serveur), un résolveur DNS est avant tout un logiciel qui met en œuvre algorithme de résolution de nom. Et ce dernier peut procéder de deux façons :
- Il peut opérer en mode récursif lorsqu'il propage la requête en interrogeant un autre résolveur qu'il connaît par défaut pour obtenir une réponse.
- Il peut aussi opérer en mode itératif lorsqu'il obtient de la part d'un serveur de noms non pas l'adresse IP du nom de domaine à résoudre mais celle d'un autre serveur de noms, qu'il doit alors solliciter, et ce jusqu'à obtenir une réponse.
- ce dernier ne connaissant pas l'adresse IP du nom de domaine complet recherché, il retourne celle du serveur de noms de premier niveau (TLD) ;
- le résolveur doit alors réitérer sa requête auprès de ce serveur de noms, qui lui‑même peut renvoyer celle d'un serveur de noms de 2e niveau, etc.
Mémoire cache d'un résolveur DNS
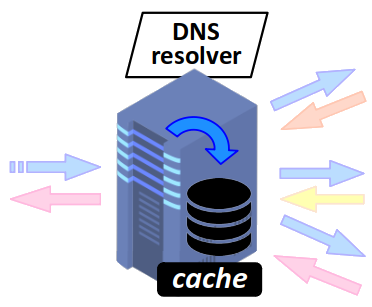
Comme de nombreux logiciels (système d'exploitation, navigateurs…), celui d'un résolveur DNS dispose aussi en mémoire cache W d'une base de donnée qui lui permet d'enregistrer temporairement les réponses qu'ils ont obtenues aux dernières requêtes.
Cette stratégie présente deux avantages :
- diminuer le temps de réponse aux applications qui sont à l'origine des requête ;
- diminuer le nombre de requêtes adressées aux serveurs de noms.
Mais elle pourrait avoir l'inconvénient d'aboutir à une réponse erronée lorsqu'elle n'est plus à jour. C'est pourquoi la durée de vie des enregistrements en mémoire cache doit être judicieusement choisie.
Durée de vie d'un enregistrement en mémoire cache

La durée de vie W – en anglais, time‑to‑live, abrégé TTL – d'un enregistrement en mémoire cache est un paramètre qui limite dans le temps la validité de l'enregistrement.
C'est un entier non signé encodé sur 32 bits qui exprime cette durée en secondes.
Le format d'encodage sur 32 bits permet théoriquement de définir une valeur de durée de vie jusqu'à 136 ans (environ 4,3 × 109 s). Mais en pratique :
- dans tous les cas, on ne dépasse pas 7 jours maximum (604 800 s) ;
- pour un domaine peu sollicité et doté d'un adressage stabilisé, par défaut, on peut prendre une valeur de 12 heures (43 200 s) ou 24 heures (86 400 s) ;
- sur un tel domaine, lorsque des changements d'adressage sont en cours, on aura tendance à choisir une valeur de l'ordre d'1 heure (3 600 s) ;
- les domaines très sollicités (moteurs de recherche, Wikipedia, etc.) qui ont recours à des dispositifs de répartition de charge W, on observe des valeurs beaucoup plus courtes, typiquement 5 minutes (300 s).
Contribution au DNS du système d'exploitation
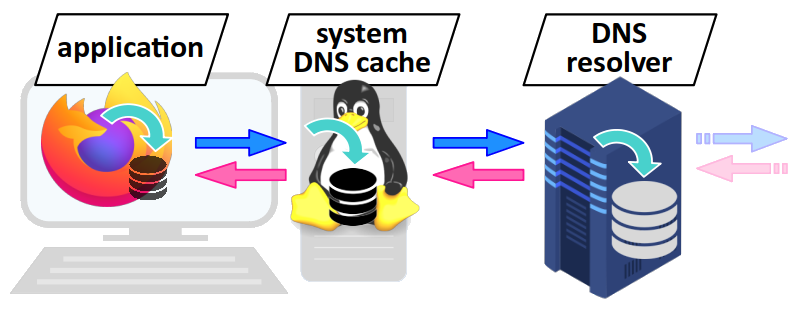
Sur une machine dotée d'un système d'exploitation (ordinateur, smartphone, serveur…), ce dernier contribuer au DNS de deux façons :
- par des enregistrements statiques – c'est‑à‑dire sans limite de durée de vie – inscrits dans un fichier nommé
hosts; - en conservant aussi dans une base de données en mémoire cache DNS les enregistrements les plus sollicités ; en principe, le système leur confère la même durée de vie que celle spécifiée dans l'enregistrement.


Tous ces dispositifs sont mis en œuvre par des bibliothèques logicielles qui permettent au système d'exploitation d'agir comme un résolveur strictement récursif. On parle de stub resolver, ou plus récemment de caching resolver pour tenir compte de l'usage d'une mémoire cache.
Ces composants logiciels permettent de considérablement accélérer le temps de réponse et diminuer la charge sur les résolveurs DNS publics. Et il faut savoir que lorsqu'une application sollicite le système pour accéder à une ressource par son nom de domaine :
- par défaut, et en l'absence de recours à un serveur proxy, c'est le fichier
hostsqui est consulté en premier ; si une adresse IP y est associé au nom à résoudre, c'est cette réponse et elle seule qui est retournée à l'application ; - dans la négative, c'est la mémoire cache DNS du système d'exploitation qui est ensuite consultée ; là encore, si une adresse IP correspondante y figure, elle est fournie à l'application requérante sans qu'aucun résolveur DNS ne soit sollicité.
Comme ces composants logiciels sont gérés par le système d'exploitation, un administrateur du poste peut les manipuler, contrairement à tout autre élément issu d'un résolveur public ou d'un serveur de noms. Ce qui donne quelques moyens rudimentaires pour orienter et filtrer les réponses aux requêtes en résolution de noms (cf. infra ).
Mémoire cache DNS du navigateur
Toujours dans l'objectif de diminuer le nombre de requêtes au DNS, tout navigateurs web (Firefox, Chrome, etc.) dispose également d'une base de donnée en mémoire cache DNS qui lui est propre.
En règle générale, la durée de vie des enregistrements mémorisés dans ce cache est beaucoup plus faible – typiquement, 2 minutes – que dans celui du système d'exploitation ou d'un résolveur.

Les noms de domaine
Notions de nom de domaine et de ressource enregistrée
Un nom de domaine W est une chaîne de caractères qui identifie littéralement un domaine enregistré ou une ressource enregistrée dans une zone d'autorité sur un réseau informatique.
Plus précisément :
- Un domaine enregistré est constitué d'un ensemble de machines répertorié par le DNS du réseau – chacune disposant d'une adresse IP susceptible d'être fournie lors une requête en résolution du nom de ce domaine traitée positivement par un serveur de nom de la zone d'autorité.
- Une ressource enregistrée est une machine répertoriée par le DNS du réseau, c'est‑à‑dire disposant d'une adresse IP et donnant accès à une ou plusieurs ressource du réseau (site web, etc.). On peut alors parler de nom d'hôte W (en anglais, hostname) au sens où cette machine est « hébergée » dans le réseau.
- Le nom de domaine
orgidentifie le domaine enregistré du réseau Internet constitué de toutes les machines ayant une adresse IP publique identifiable lors d'une requête en résolution traitée positivement par un serveur de nom faisant autorité sur la zoneorg. - Le nom de domaine
www.wikipedia.orgidentifie l'une des machine du réseau Internet ayant une adresse IP publique qui constitue la ressource enregistrée donnant accès à la page d'accueil du site web de l'encyclopédie en ligne Wikipedia.
Espace des noms de domaine
De droite à gauche, un nom de domaine est récursivement composé :
- d'identifiants de domaines (en anglais, on emploie le mot label) ;
- avec le séparateur
.qui joue le rôle d'opérateur de composition.
On appelle espace des noms de domaine l'ensemble formé de tous les noms de domaines enregistrés.
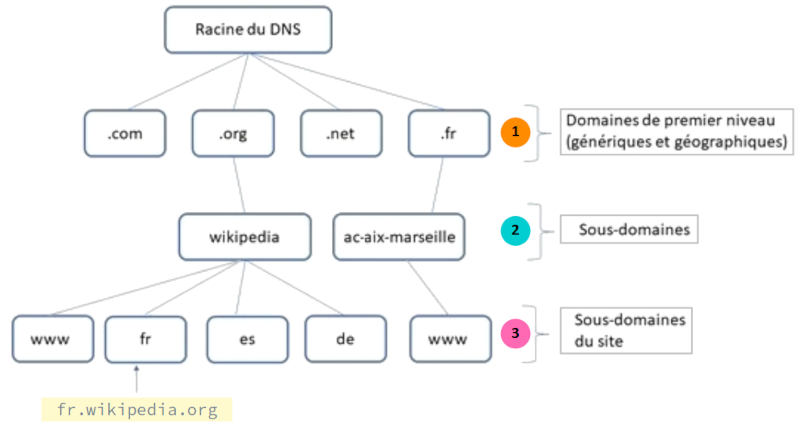
L'espace des noms de domaine (domain name space) forme un arbre :
- dont la racine est anonyme ; on la symbolise par un simple caractère
.sachant qu'il est le plus souvent omis lors des saisies ; - dont les nœuds de premier niveau W (top-level domain ou TLD) peuvent être :
- soit génériques (gTLD pour generic), c'est‑à‑dire chacun attribué à un domaine d'activité transversal, par exemple
orgpour les organisations à but non lucratif,compour le commerce, etc. ; - soit « géographiques » (ccTLD pour country code), c'est‑à‑dire chacun attribué à un pays ou un territoire, par exemple
frpour la France métropolitaine,mqpour l'île de la Martinique,ukpour le Royaume‑Uni, etc. - dont les nœuds de deuxième niveau W forment des sous‑domaines à l'intérieur du domaine de premier niveau dont ils sont issus ; ils sont attribués à des organisations de toutes sortes (entreprises, administrations, associations, etc.) ; par exemple,
wikipedia.orgdésigne le domaine qui réunit tous les sous‑domaines de l'encyclopédie en ligne ; - dont les feuilles désignent des ressources enregistrées hébergées dans un domaine particulier ; par exemple,
fr.wikipedia.orgdésigne la ou les machines qui donnent accès au site web de la page d'accueil en langue française de Wikipedia.
Le nombre de niveaux de sous‑domaine n'est en principe pas limité (sauf par des contraintes syntaxiques, cf. infra ). Par exemple, le nom de domaine :
www.lyc-ferry-versailles.ac-versailles.fr
comporte trois niveaux de sous‑domaines.
Toutefois, pour des enjeux de bonne lisibilité, il est recommandé de ne pas dépasser 2 niveaux et d'utiliser des identifiants les plus courts possibles (typiquement, ne pas dépasser 12 caractères). En effet, plus on ajoute de niveaux, plus les adresses sont difficiles à retenir, ce qui va à l'encontre de l'objectif principal de l'adressage littéral, qui est de faciliter l'accès aux ressources.
- Dans la littérature scientifique et technique, par convention implicite, les identifiants des TLD sont écrits avec un point initial (
.com,.org, etc.) car : - ils désignent rarement une ressource ; ils attendent donc une complétion, ce à quoi le point invite ;
- cela permet d'éviter les confusions avec un mot ou un sigle.
- Historiquement, les TLD génériques ont été créés pour les besoins des États‑Unis – là où le réseau Internet a été inventé.
- Certains gTLD, comme
govetmilrestent encore strictement réservés à leur usage initial (respectivement pour le gouvernement et l'armée américaine). C'est aussi le cas pratique deeduqui ne couvre que les établissements universitaires des États‑Unis. On dit que ces TLD sont parrainés W – en anglais, sponsored – au sens où il faut impérativement le soutien d'un « parrain » (un organisme décisionnaire dans un secteur d'activité spécifique) pour y enregistrer un sous‑domaine. - Les autres gTLD –
com,org,net,biz,info, etc. – sont en revanche ouverts à toutes les demandes d'enregistrement de noms de sous‑domaines à partir du moment où elles répondent à certaines exigences (par exemple, d'être émise par une organisation à but non lucratif pour obtenir une adresse dans le domaineorg). - Hors des deux catégories de TLD mentionnées supra (gTLD et ccTLD), il existe aussi un TLD spécial (catalogué infrastructure) :
arpaW (aujourd'hui tenant pour address and routing parameter area). Il est réservé pour des usages techniques.
com est un nom de domaine, mais pas .com à strictement parler. Nom de domaine pleinement qualifié
On dit d'un nom de domaine qu'il est pleinement qualifié W – fully qualified domain name, abrégé FQDN – s'il forme un chemin jusqu'à la racine incluse de l'arbre de l'espace de nom, marquée par un « . » final.
Ce point symbolisant la racine est nécessaire pour le bon déroulement des algorithmes de résolution de noms. Lorsqu'il est omis dans une requête en résolution de nom, il est en fait automatiquement rajouté par l'application ou le système d'exploitation.
Le nom de domaine www.wikipedia.org. avec son point final constitue un FQDN.
Notion d'alias
À tout nom de domaine enregistré, l'administrateur de sa zone d'autorité peut définir un ou plusieurs alias : ce sont d'autres noms qui identifient le même domaine.
Dans la base de donnée des serveurs de noms, tout alias est défini par un enregistrement d'un type différent de celui d'un nom de domaine enregistré. Techniquement appelé canonical name W, un tel enregistrement est de la forme :
L'enregistrement d'un alias d'un nom de domaine présente potentiellement plusieurs intérêts, en particulier :
- augmenter la visibilité d'un site par l'ajout de différents noms pour y accéder, notamment avec et sans le nom de sous‑domaine
www(cf. infra ) ; - assurer la transition d'hébergement d'un site qui soit robuste aux habitudes des internautes non informés de cette transition (l'ancien nom étant l'alias du nouveau nom durant toute la période de transition) ;
- simplifier l'espace des noms d'un sous‑domaine pour le rendre plus attractif, voire complètement différent du nom de domaine réellement utilisé.
www.lycee-ferry-versailles.fr est en fait un alias du nom de domaine enregistré lycee-ferry-versailles.fr qui est plus simple. www.neuf.fr est un alias de www.sfr.fr. En effet, l'opérateur 9 Télécom est un ancien FAI ayant fusionné avec SFR en 2008 W. www.education.gouv.fr est un alias du nom de domaine enregistré cs4.wpc.alphacdn.net. Ce domaine est géré par la société américaine Verizon Trademark Services LLC qui agit en qualité d'hébergeur web pour le Ministère de l'éducation nationale français. Bien évidemment, ce nom de domaine « technique » est trop complexe pour les internautes, c'est pourquoi il est doté d'un alias beaucoup plus lisible. - Tous les exemples ont été vérifiés en 2021 à l'aide de la commande
nslookup. Toutefois, le résultat obtenu est susceptible de varier au gré de changements d'enregistrement opérés depuis cette date. - L'enregistrement d'un alias n'est pas la seule technique pour associer plusieurs noms à un même domaine. Il existe aussi divers mécanismes de redirection d'URL (cf. infra ).
Règles syntaxiques des noms de domaine
Par défaut, un nom de domaine doit être composé exclusivement avec le jeu de caractères ASCII restreint (cf. chap. C3‑VIII C) et :
- sans distinction de casse (les majuscules sont automatiquement converties en minuscules) ;
- sans caractères spéciaux, excepté le trait d'union (hyphen, code ASCII
0x2d).
De plus, un nom de domaine doit respecter les limites suivantes :
- chaque identifiant (label) ne doit pas dépasser 63 caractères ;
- un nom complet ne doit pas dépasser 253 caractères.
Noms de domaines internationalisés

Cette possibilité est implémentée par le mécanisme appelé IDNA – pour internationalized domain names in applications – qui est formalisé par les RFC 5890 et 5891 et qui est aujourd'hui pris en charge par la plupart des navigateurs. Il consiste à transcoder en ASCII restreint les noms de domaines internationalisés par l'algorithme punycode W (RFC 3492 ) – qu'on ne détaillera pas ici. Afin qu'il n'y ait pas de confusion avec tout autre nom de domaine directement composé en ASCII, le préfixe xn-- est ajouté à chaque identifiant transcodé par cet algorithme.
Assez rare pour être signalé, le nom de domaine www.académie-française.fr peut être directement saisi dans la barre d'adresse d'un navigateur . Son transcodage punycode est :
www.xn--acadmie-franaise-npb1a.fr
Il est bien exclusivement composée dans le jeu ASCII restreint (pas de « é » ni de « ç ») et comporte le préfixe xn--.
Remarque : Ici, dans tous les cas, on aboutit au site www.academie-francaise.fr (nom de domaine sans « é » ni « ç ») par un mécanisme de redirection d'URL (cf. infra ) et d'alias (cf. supra ). On peut le vérifier facilement dans un terminal à l'aide de la commande host (cf. infra ) :
host www.académie-française.frwww.xn--acadmie-franaise-npb1a.fr is an alias for ulix2.sdv.fr. ulix2.sdv.fr has address 212.95.66.79host www.academie-francaise.frwww.academie-francaise.fr is an alias for ulix2.sdv.fr. ulix2.sdv.fr has address 212.95.66.79
On voit que les deux noms de domaines sont en fait l'alias d'un même nom de domaine technique .
Usage du sigle www
Dans les noms de domaine, le sigle www – pour world wide web – est conventionnellement employé pour désigner un sous‑domaine regroupant des pages web (de même, que le sigle ftp est usuellement réservé désigner le nom de domaine d'un serveur de fichier par le protocole du même nom).
Si cet usage facilite l'identification du contenu des noms de domaine, il n'est pourtant pas obligatoire. Aujourd'hui, pour diminuer les erreurs d'adressage, il est fréquent d'attribuer deux noms à un même domaine, avec et sans sous‑domaine www et de renvoyer l'un sur l'autre.
Si l'on saisit seulement le nom de domaine education.gouv.fr dans la barre d'adresse d'un navigateur, ce dernier aboutit automatiquement au nom de domaine www.education.gouv.fr par un mécanisme de redirection d'URL (cf. infra ).
Formalités d'enregistrement d'un nom de domaine
Tout enregistrement d'un nom de (sous‑)domaine est soumise à l'autorité de l'institution ou de l'organisme qui gère le domaine auquel ce (sous‑)domaine appartient.
Dans le cas des domaines de premier niveau, on parle de TLD manager.
Il faut savoir que :
- la racine et certains TLD génériques (
int,arpa) sont placés sous l'autorité historique de l'IANA W – Internet assigned numbers authority – qui est un département de l'ICANN (cf. chap. R1‑I ) ; - d'autres TLD génériques sont gérés par divers organismes, par exemple :
-
orgpar le PIR W – public interest registry – qui est une association américaine à but non lucratif ; -
compar VeriSign W, une société américaine qui gère également deux serveurs racine ; - les TLD géographiques sont le plus souvent placés sous l'autorité d'institutions des pays respectifs ou régions correspondant à ces domaines ; par exemple, le domaine
fr… est géré par l'AFNIC.
Plus généralement, on peut consulter la liste complète des TLD directement sur le site de l'IANA et ainsi connaître l'organisme gestionnaire de chacun – son TLD manager.
Bureaux d'enregistrement
Dans la pratique, les TLD managers n'ont pas les moyens de traiter les demandes d'enregistrement de noms de domaine.
Ils délèguent donc cette tâche à des entreprises ou associations appelées registraires ou bureaux d'enregistrement W (domain name registrar). Moyennant une contribution financière, un registraire agit comme intermédiaire commercial pour le compte des demandeurs d'enregistrement.
On retrouve ici le même principe que pour l'attribution des adresses IP (cf. chap. R1‑III ), les TLD managers jouant le rôle des RIR et les registraires celui des LIR.
- C'est donc le TLD manager qui détermine la politique d'enregistrement (conditions générales, limites tarifaires…).
- Quant au registraire, il se charge :
- d'instruire au demandeur les formalités administratives à accomplir ;
- de maintenir au niveau des serveurs de noms la base de donnée des enregistrements qu'il commercialise.
La liste des registraires d'un TLD est en général accessible le site web du TLD manager.
Sur le site de l'AFNIC (TLD manager des domaines fr, re, etc.) on trouve un formulaire de base de donnée qui permet de cibler la recherche d'un registraire en fonction des besoins, du pays, de la région…
D'autres outils sont également disponibles, en particulier pour savoir si un nom de sous‑domaine est déjà réservé.
L'hôte local
Le nom d'hôte localhost W – littéralement, l'hôte local – est un un TLD spécial réservé par l'IETF (RFC 2606 puis RFC 6761 ) pour désigner la machine locale sur laquelle sont exécutées des requêtes vers ce nom de domaine.
Ce nom de domaine est associé à l'adresse IP de rebouclage, c'est‑à‑dire 127.0.0.1 en IPv4 et ::1/128 en IPv6 (cf. chap. R1‑III ).
Cette association est en général enregistrée dans le fichier hosts du système d'exploitation (cf. supra et infra ).

Sur une machine hébergeant le logiciel serveur web Apache (cf. chap. R2‑IV et TP R2‑2 ), l'accès à la page web d'accueil du serveur peut se faire directement via l'URL :
http://localhost
Le TLD local
Le nom local W est aussi un TLD spécial réservé par l'IETF (RFC 6762 ) pour désigner les réseaux IP constitués par les machines reliées entre elles par lien local (cf. chap R1‑II ).
Sur le lien local, les machines peuvent être identifiées par leur nom d'hôte pour former des noms de domaine de deuxième niveau, c'est‑à‑dire de la forme :
nom d'hôte.local
Cette possibilité existe grâce au protocole mDNS, ou multicast DNS W, inventé par Apple et mis en œuvre sur la plupart des systèmes Linux ou semblables (macOS, IOS).

Si on raccorde dans un réseau local (typiquement, via un switch) une carte Raspberry Pi à laquelle on attribue le nom d'hôte rpi, alors on peut vérifier depuis un poste de travail la bonne connexion de la carte par la commande :
ping rpi.local
Les URL
Notion d'URL

Une URL W – pour uniform resource locator – est une chaîne de caractères qui indique l'accès à une ressource enregistrée dans un réseau informatique.
Elle est destinée à être saisie :
- dans la barre d'adresse d'un navigateurs web, ou plus généralement dans un champ de saisie spécifique de logiciel (par exemple, pour définir un hyperlien dans un document bureautique) ;
- comme valeur d'un attribut de balise du langage HTLM (par exemple, un attribut
hrefousrc) ; - comme argument d'une commande de système d'exploitation (par exemple, sous Linux,
wget,curl, etc.) ;
cette liste n'étant pas exhaustive.
Il existe de nombreux types d'URL. Les plus courants sont ceux qui donnent accès à :
- des serveurs de pages web, via le protocole http ;
- des serveurs de fichiers, via le protocole ftp ;
- des serveurs de messagerie, via le protocole smtp…
Mais on peut aussi spécifier l'accès à une ressource locale (un fichier) sur la même machine que celle qui héberge l'application dans laquelle l'URL est saisie.
En fait, la notion d'URL s'inscrit dans le concept plus vaste d'URI W – pour uniform ressource identifier – qui définit un format général pour identifier toutes les ressources sur les réseaux informatiques, et non pas seulement celles qui peuvent être accédées par un navigateur.
Forme d'une URL
Dans l'absolu, une URL se compose selon une forme syntaxique comportant jusqu'à 6 composantes, certaines étant optionnelles. Elles sont concaténées les unes à la suite des autres, comme ci‑dessous :
schéma :[//autorité ] [:nº port ] chemin [?requête ] [#fragment ]
Le détail de ces 6 composantes peut être trouvé sur cette page web W. La combinatoire de toutes leurs valeurs possibles est immense. Toutefois, pour un étudiant dans le domaine des réseaux, il est surtout important d'en retenir les usages les plus courants, qui seront exposés ci‑après dans cette section.
Par ailleurs, on voit dans l'écriture d'une URL, il existe des caractères réservés car ce sont des séparateurs syntaxiques. Ils sont les suivants :
! # $ & ' ( ) * + , / : ; = ? @ [ ]
et, évidemment, ils sont à ne pas utiliser pour un autre usage que celui qui leur est dévolu.
Pour une description encore plus exhaustive, on peut évidemment consulter la RFC 3986 qui est consacrée à la syntaxe générique des URI. Sa rédaction a été dirigée par Tim Berners‑Lee W, également principal inventeur du langage HTML.
Le nº port ne doit être spécifié que lorsqu'il n'est pas standard, ce qui est assez rare dans la pratique. C'est pourquoi cette composante est le plus souvent passée sous silence, mais on peut en trouver mention ici .
Le schéma about:
Peu connu du grand public, le schéma about: W permet d'afficher toutes sortes d'informations dans la fenêtre principale du navigateur. Il suffit de saisir à la suite du schéma le nom de la page d'information.
On peut trouver dans le lien supra la liste des noms de pages d'information qui sont valides dans tel ou tel navigateur.
Dans certains navigateurs (Chromium, Opera…), le schéma about: est automatiquement remplacé par un autre, équivalent – typiquement, chrome: ou opera:…
L'URL about:about affiche la liste de toutes les pages d'information disponibles sur le navigateur utilisé. Elles sont présentées sous forme d'hyperliens donc il suffit de cliquer sur leur nom pour y accéder.
Par exemple, avec le navigateur Firefox, on trouve dans cette liste le lien about:networking qui donne accès à de nombreuses informations relatives au réseau (liste des hôtes contactés pour des requêtes http, cache DNS, etc.)
URL d'une page web en libre accès
Pour accéder à une page web en libre accès sur un serveur, l'URL est de la forme :
http://nom d'hôte chemin
Dans cette forme :
- le nom d'hôte doit être le nom de domaine enregistré hébergé par une machine hôte du réseau, typiquement un serveur web (cf. supra ) ;
- le chemin définit le chemin d'accès au fichier sur la machine hôte dans l'arbre des répertoires web qu'elle héberge.
- la racine est conventionnellement un segment vide, autrement dit le chemin commence toujours par le caractère
/; - le dernier segment est le nom du fichier codant la page web ; par défaut, le nom doit être complet, c'est‑à‑dire codé avec son extension (mais il existe des solutions pour se passer de ce détail technique peu commode pour le grand public).
/ – et non pas \ – sachant que : Par ailleurs, l'accès à une page web via le protocole sécurisé https prend la même forme d'URL, sauf bien entendu pour le sigle du protocole.
- L'URL de la page d'accueil de ce module de formation est :
http://www.lycee-ferry-versailles.fr/snir/ModuleR/R_index.html - L'URL de la page de prévisions météorologiques du service public Météo France pour la ville de Versailles est :
https://meteofrance.com/previsions-meteo-france/versailles/78000
URL d'un segment de page web
Pour accéder à un segment de page web en libre accès sur un serveur, c'est‑à‑dire une section particulière de cette page, l'URL reprend la forme générale de celle d'une page web et y concatène un identificateur de fragment précédé par le préfixe # :
http://nom d'hôte chemin#fragment
Une telle URL permet d'accéder à la page web non pas à son début mais directement au segment qui commence là où est identifié le fragment.
L'identificateur du fragment doit être déclaré dans une et une seule balise du code html de la page web, comme valeur de son attribut id.
Dans la page web de l'encyclopédie Wikipedia consacrée au DNS figure une sous‑section qui détaille la notion de mise à jour dynamique. Ce segment de la page est directement accessible via l'URL W :
https://fr.wikipedia.org/wiki/Domain_Name_System#Mise_à_jour_dynamique
Dans le code html de la page, en examinant l'élément du titre de cette sous‑section (accessible dans le menu contextuel par clic‑droit, commande Inspecter), on peut vérifier que la balise <span> qui contient ce titre possède bien l'attribut id figurant en fin d'URL :
<h2> … <span id="Mise_à_jour_dynamique" class="mw-headline">Mise à jour dynamique</span>
URL de page web incluant une requête
Dans une URL, des éléments de requête W – en anglais, query string – permettent de passer des valeurs à des paramètres pour qu'une page web dynamique puisse opérer des traitements spécifiques.
La syntaxe d'une requête est celle d'une suite d'affectations, chacune de la forme champ=valeur . Ces affectations sont concaténées l'une après l'autre avec les séparateurs & ou ;.
D'autres éléments syntaxiques peuvent être employés, comme par exemple le symbole + qui se substitue au caractère espace, lequel est interdit. Pour plus de détails sur tous ces aspects, on pourra consulter ce lien W.
L'URL ci‑dessous :
https://www.youtube.com/watch?v=xhP_guPY1CM&t=182
cible la page web de YouTube qui commence une diffusion à la 182e seconde de la vidéo de vulgarisation sur le DNS citée supra en introduction de ce chapitre.
URL d'une page web locale
Sur un poste de travail, pour accéder à une page web stockée localement (ou même une image, un document .pdf, etc.), le schéma d'URL est file. Il doit être suivi du chemin absolu de la ressource dans l'arborescence du système de fichiers sur la machine.
L'URL ci‑dessous :
file:///F:/TRAVAIL/SOURCES/SNIR/SNIR_WEB/index.htm
cible la page d'accueil du site SNIR stockée sur le disque dur étiqueté F d'un PC (sous Windows). Le 3e caractère / après le schéma file symbolise la racine de l'arborescence du système de fichiers du PC.
Redirection d'URL
Une redirection d'URL W – en anglais, URL forwarding ou redirection – est un procédé qui permet d'accéder à une même ressource par plusieurs URL, et ce sans recourir à un enregistrement d'alias.
Les raisons d'employer une redirection d'URL sont les mêmes que celles pour l'enregistrement d'un alias évoquées supra : robustesse aux erreurs de saisie des utilisateurs, migration d'un site, simplification de noms, etc..
Mais une redirection d'URL offre plus de possibilités qu'un alias, puisqu'une URL ne se limite pas à un nom de domaine :
- elle précise le protocole, qui peut donc être changé – en particulier, pour basculer automatiquement de
httpàhttps; - elle cible aussi un chemin et peut inclure un fragment, une requête…
Il existe de nombreuses techniques et services de redirection d'URL, dont l'étude dépasse le cadre de ce chapitre. Pour en avoir un aperçu, on pourra consulter les liens suivants W .
Réduction d'URL
Une réduction – ou minimisation – d'URL W – en anglais, URL shortening – est une redirection qui utilise une URL très courte pour accéder à une ressource.
En général, on opère une réduction d'URL en concaténant :
- un nom de domaine abrégé ;
- une clef unique – la plus petite possible – générée à partir de l'URL initiale ou de la page web ciblée ;
le but étant de composer une URL suffisamment courte pour être facile à saisir (voire mémoriser).
L'URL de la vidéo de vulgarisation sur le DNS donnée en exemple supra :
https://www.youtube.com/watch?v=xhP_guPY1CM
fait l'objet de la réduction suivante :
https://youtu.be/xhP_guPY1CM
Ici, l'effet de la réduction n'est pas très spectaculaire parce que l'URL initiale est déjà très courte. Seul le nom de domaine de substitution youtu apporte une réelle réduction. Ce dernier étant enregistré dans le ccTLD .be de la Belgique, cela permet astucieusement de recomposer le nom de la marque YouTube.
Fonctionnement du DNS
Les enregistrements de ressources

Dans la base de donnée d'un serveur de nom, un enregistrement relatif à un nom de domaine est appelé resource record (abrégé RR). Conformément à la RFC 1035 , il est constitué d'une séquence de 6 champs de données :
De façon détaillée, et en rappel des explications précédentes :
- Le champ domain name est le nom de domaine pleinement qualifié – FQDN, cf. supra – qui est le sujet de l'enregistrement.
- Le champ TTL – ou time‑to‑live, cf. supra – exprime en secondes la durée de conservation de l'enregistrement dans la mémoire cache des résolveurs.
- Le champ class indique le domaine général d'emploi de l'enregistrement ; sauf exceptions historiques, la classe
IN— pour Internet – est la seule employée. - Le champ type indique la « nature » de la donnée enregistrée associée au nom de domaine. Il existe un très grand nombre de types (cf. cette liste W). Ceux les plus fréquemment employés sont :
-
Apour une adresse IPv4 etAAAApour une adresse IPv6 (4 lettres «A» car elle fait 4 fois la taille d'une adresse IPv4) ; -
NSpour le nom de domaine du serveur de nom (name server) ; -
CNAMEpour le nom de domaine d'un alias W (canonical name) ; -
SOApour les informations administratives de la zone d'autorité W (start of authority) ; -
MXpour un serveur de mail associés au nom de domaine W (mail exchange) – cf. chap. R2‑VII ). - Le champ RDlength (record data length) exprime la longueur en octets du champ variable Rdata. Purement technique, cette information n'est pas affichée par les commandes d'investigation sur les noms de domaine.
- Le champ Rdata (record data) contient la donnée au associée au nom de domaine, qui est l'objet de l'enregistrement. C'est donc lui qui contient l'information essentielle de l'enregistrement.
0x0001, 0x001C (28), 0x0002, 0x0005, 0x0006 et 0x000F codent respectivement les types A, AAAA, NS, CNAME, SOA et MX. Les valeurs 0xFF00 à 0xFFFE sont réservées pour un usage privé. A, le champ Rdata contient l'adresse IPv4 associée au nom de domaine qui est le sujet de l'enregistrement (champ domain name). Pour une présentation complète de ces différents champs et de leurs valeurs possibles, il est conseillé de consulter directement la page des paramètres DNS sur le site l'IANA où l'on trouve les informations les plus à jour.
Les requêtes DNS
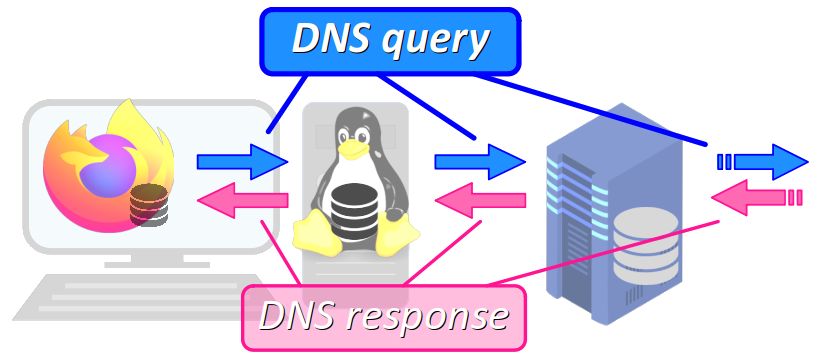
Toute résolution de nom de domaine qui ne trouve pas de réponse en mémoire cache (du navigateur, du système ou du résolveur) nécessite l'envoi d'une requête DNS – en anglais, DNS query.
Conformément à la RFC 1035 , une requête est essentiellement formulée par 3 champs :
De façon détaillée :
- Le champ domain name est nom de domaine pleinement qualifié – FQDN, cf. supra – qui est justement l'objet de la requête.
- Le champ Qclass indique le domaine général d'emploi de la donnée recherchée ; comme le champ Class des enregistrements (cf. supra ), sauf exceptions, seule la classe
IN– pour Internet – est aujourd'hui employée. - Le champ Qtype (query type) indique la « nature » de la donnée demandée. Il doit correspondre à un type d'enregistrement reconnu d'enregistrement de ressource (cf. supra ).
Les messages DNS
Les échanges de données du DNS – typiquement, entre un résolveur DNS et un serveur de noms – adoptent un format de message unique, aussi bien pour les requêtes que pour les réponses. En principe, la ou les questions formulées sont toujours rappelées dans un message de réponse.
Ce format est défini dans la RFC 1035 et synthétisé par le schéma ci‑dessous.

Ainsi, un message DNS :
- comporte toujours un en‑tête – header – de taille fixe 12 octets ;
- comporte ensuite 4 sections, certaines éventuellement vides, respectivement nommées question, answer, authority et additional information et présentées toujours dans cet ordre après l'en-tête ;
- peut contenir plusieurs questions et/ou plusieurs réponses, dont les nombres respectifs sont indiqués dans l'en‑tête, et qui adoptent les formats décrits précédemment (3 champs pour une question , 6 champs pour une réponse – cf. supra).
En règle générale, un message DNS est encapsulé dans un datagramme UDP.
Comme dans toute mise en œuvre de protocole, les messages DNS comportent divers éléments de codage techniques, en particulier :
- un numéro d'identification (nombre entier non signé encodé sur 2 octets) qui est généré aléatoirement par l'application requérante pour chaque nouvelle requête et qui est répliqué dans les réponses ; il permet vérifier sans ambiguïté la bonne correspondance de ces dernières à la requête ;
- un champ dit de drapeaux qui code sur 16 bits (2 octets) toutes sortes de détails, notamment :
- le bit
QR(query‑response) qui indique si le message est une requête (valeur0) ou une réponse (valeur1) ; - le champ
OpCode(operation code) qui code sur 4 bits le type de requête ou de réponse (valeur0s'il s'agit d'un message standard…) ; - le drapeau
AA(authoritative answer) qui indique (valeur1), dans le cas d'une réponse, si cette dernière est émise par un serveur de noms faisant autorité sur sa zone ; - le drapeau
TC(truncation) qui indique (valeur1), dans le cas d'une réponse, si cette dernière est tronquée car trop longue pour tenir dans un seul datagramme UDP ; - le drapeau
RD(recursion desired) qui indique (valeur1) s'il s'agit d'une requête en mode récursif (la valeur de ce drapeau est reproduite à l'identique dans les réponses) ; - le drapeau
RA(recursion available) qui indique (valeur1) s'il s'agit d'une réponse en mode récursif ; - le bit
Z, réservé pour un usage futur, en principe toujours mis à zéro ; - le drapeau
AD(authenticated data) qui indique (valeur1), dans le cas d'une réponse, si toutes les données (RR) contenues dans le message sont authentifiées ; - le drapeau
CD(checking disabled) qui indique (valeur1), dans le cas d'une requête, que les réponses non vérifiées sont acceptables ; - le champ
Rcode(response/error code) qui code le type d'erreur éventuellement détecté lors de la génération d'une réponse, la valeur0signifiant l'absence d'erreur.

AD et CD ne sont exploités que par des serveurs DNS sécurisés ; La connaissance de ces différents aspects est utile pour comprendre les résultats obtenus par des commandes en lignes d'investigation du DNS comme dig (cf. infra ). Pour plus de détails, on pourra notamment consulter les RFC 4035 et 6895 .
Les messages DNS ont principalement recours au protocole UDP (cf. chap. R1‑IV ) mais aussi au protocole TCP (même chap. ), en particulier lorsque les ressources demandées sont au format IPv6.
En effet, les datagrammes UDP ont une taille souvent trop limitée pour contenir toutes les adresses en réponse (rappelons qu'une adresse IPv6 est 4 fois plus longue qu'une adresse IPv4).
Outils logiciels du DNS
Inspection et réinitialisation du cache DNS du navigateur
En règle générale, le contenu de la mémoire cache DNS d'un navigateur (cf. supra ) est visualisable dans une page d'information accessible par le schéma about: (cf. supra ).
Dans cette page, on trouve un bouton qui permet de réinitialiser cette mémoire – on dit « vider le cache ».
Avec le navigateur Firefox, l'URL about:networking#dns liste détaillée tous les noms de domaines en mémoire cache DNS, comme par exemple ci‑dessous :
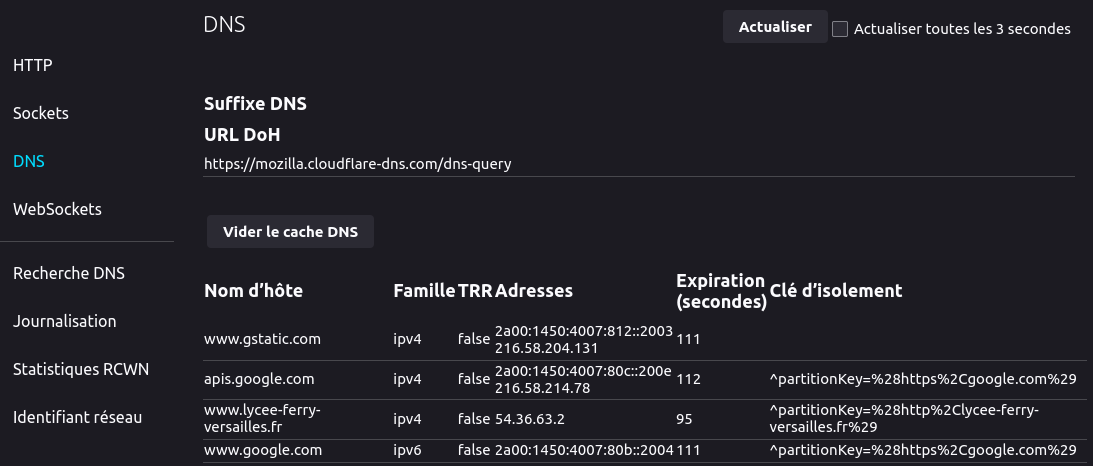
De plus, la page dispose de deux boutons :
- l'un pour actualiser la page ; on peut notamment constater en cliquant dessus que les durées d'expiration diminuent…
- l'autre pour vider le cache ; il faut cliquer sur le bouton
Actualiserpour vérifier que la mémoire est momentanément vide.
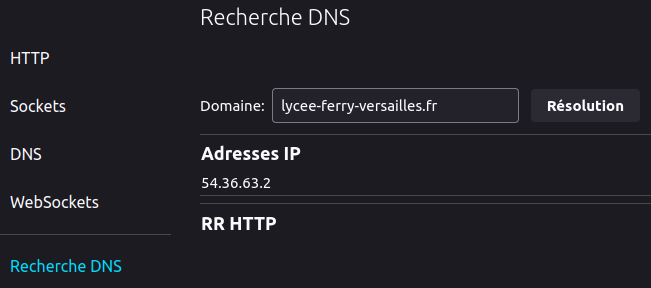
Par ailleurs, on trouve dans le panneau latéral de la page une rubrique Recherche DNS qui cible l'URL about:networking#dnslookuptool. On aboutit sur une page interactive qui permet d'effectuer des requêtes élémentaires en résolution de nom.
Dans l'exemple de la capture d'écran ci‑contre, une recherche DNS sur le nom de domaine lycee-ferry-versailles.fr qui héberge ce module de formation donne l'adresse IP du serveur qui l'héberge (54.36.63.2) et indique qu'il s'agit bien d'un resource record (RR).
Le fichier hosts du système d'exploitation
Héritage du passé, sur une machine à système d'exploitation (ordinateur, smartphone, etc.), le fichier hosts W est un fichier système de type texte (mais sans extension .txt) qui met en correspondance statique des adresses IP, des noms de domaines et éventuellement des alias de noms associés.
Par défaut, lors de toute requête en résolution de nom, il est consulté en premier, sauf si le système d'exploitation est paramétré pour recourir à un serveur proxy.
La localisation du fichier hosts dépend bien évidemment du système de fichiers de la machine. Typiquement, il est accessible dans le répertoire :
-
/etcsous Linux ; -
C:\System32\drivers\etc\sous Windows.
Dans tous les cas, pour le modifier, il faut les droits d'administration. Cette précaution est essentielle pour protéger la machine contre toutes sortes de détournements malveillants.
Le fichier hosts peut remplir principalement 2 fonctions :
- définir pour la machine des noms de domaines privés, notamment le nom de domaine générique
localhost; - implémenter un filtrage de noms de domaine indésirables.
Définition d'un nom de domaine privé
Toute définition d'un nom de domaine privé et d'éventuels alias consiste en l'écriture d'une ligne dans le fichier hosts de la forme :
adresse IP nom de domaine [ alias‑1 alias‑2 … ]
et ce aussi bien pour la norme – v4 ou v6 – de l'adresse IP.
En particulier, on trouve systématiquement par défaut dans le fichier hosts la définition du nom de domaine générique localhost, associée à l'adresse IPv4 de rebouclage (cf. chap. R1‑III ) :
127.0.0.1 localhost
Sur ce même principe, on peut donc définir, exclusivement pour la machine locale dont on modifie le fichier hosts, des noms de domaine privés, pour cibler n'importe quelle ressource (imprimante réseau, serveur…) ou domaine, public ou privé.
- Si, dans le fichier
hostsd'un ordinateur raccordé à une box de FAI dont l'adresse IP privée est192.168.0.254, on procède à l'ajout de la ligne suivante : - Si, dans le fichier
hostsd'un ordinateur raccordé à l'Internet, on procède à l'ajout de la ligne suivante :
192.168.0.254 box-fai
box-fai. Dans une fenêtre de terminal, on peut alors saisir la commande : ping box-faiPING box-fai (192.168.0.254) 56(84) bytes of data. 64 bytes from box-fai (192.168.0.254): icmp_seq=1 ttl=64 time=1.24 ms 64 bytes from box-fai (192.168.0.254): icmp_seq=2 ttl=64 time=1.07 ms 64 bytes from box-fai (192.168.0.254): icmp_seq=3 ttl=64 time=1.13 ms ^C --- box-fai ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2002ms rtt min/avg/max/mdev = 1.067/1.143/1.237/0.070 ms
ping. On peut également visualiser l'éventuelle page d'accueil de ce routeur en saisissant l'URL http://router dans la barre d'adresse d'un navigateur. 54.36.63.2 site-jf sjf
site-jf pour le site pédagogique du Lycée Jules Ferry de Versailles et un alias sjf. On peut alors accéder à la page d'accueil publique de la section SNIR en saisissant l'URL http://site-jf/snir/ ou encore http://sjf/snir/ dans la barre d'adresse d'un navigateur. hosts respectifs, ou dans un DNS privé mis en place sur ce réseau. Filtrage statique de noms de domaines indésirables
En détournant le principe de définition d'un nom de domaine privé, on peut mettre en place sur la machine un filtrage statique de noms de domaines : il suffit de leur associer une adresse IP de substitution différente de celle à laquelle ils sont normalement associés dans le DNS.
Cette technique rudimentaire permet de rendre difficile voire impossible l'accès à des ressources, que ces dernières soient publiques ou privées.
Typiquement, on peut utiliser comme adresse IP de substitution :
- l'adresse réservée nulle – en IPv4,
0.0.0.0ou tout simplement0(cf. chap. R1‑III ) ; - n'importe quelle adresse de rebouclage – notamment
127.0.0.1(cf. chap. R1‑III idem) ; - l'adresse associée à une page web d'explication ou d'avertissement, à condition d'avoir mis en place un serveur web sur la machine disposant de cette adresse IP (pas forcément l'hôte local).
- Une page web d'un site filtré par le fichier
hostpeut sembler rester temporairement accessible parce qu'elle est mémorisée dans la mémoire cache du navigateur (à ne pas confondre avec le cache DNS mentionné supra). Mais la navigation finit toujours par échouer pour un accès à une autre page non mémorisée du même site ou par rafraîchissement de la page après expiration de la durée de vie de l'enregistrement. - Pour que le filtrage d'une ressource soit pleinement effectif, il faut veiller à filtrer tous les noms de domaines donnant accès à cette ressource, en tenant compte des éventuels alias (cf. supra ) et des redirections d'URL (cf. supra ).
- De plus, il faut également s'assurer que les informations sur cette ressource contenues dans le cache du navigateur aient expiré (en rappelant qu'on peut forcer sa suppression immédiate, cf. infra ).
- Par ailleurs, même en filtrant tous les noms de domaines lui donnant accès, une ressource peut rester accessible via son adresse IP. Cette possibilité est relativement facile à exploiter si la ressource est accessible par page web statique – sachant qu'avec le protocole
https, une tentative d'accès à une ressource directement par son adresse IP risque d'échouer pour cause de certificat SSL non valide. - Enfin, s'il s'agit de filtrer des noms de domaines de sites malveillants ou de publicité en ligne, copier un grand nombre de lignes de substitution dans le fichier
hostsn'est pas très commode ni durablement efficace car ces noms de domaines indésirables se renouvellent constamment.
- Si, dans le fichier
hostsd'un ordinateur raccordé à l'Internet, on procède à l'ajout de la ligne suivante : - Si, dans le fichier
hostsd'un poste de travail raccordé à l'Internet, on on procède à l'ajout de la ligne suivante :
0 kogama.com www.kogama.com

0 lycee-ferry-versailles.fr www.lycee-ferry-versailles.fr
http://54.36.63.2/snir/
Investigation sur les noms de domaine
Depuis de nombreuses années, les systèmes d'exploitation des ordinateurs disposent d'outils en ligne de commande pour effectuer des requêtes au DNS et des demandes administratives (au sens général du terme) sur les noms de domaines.
Les outils les plus connus – tous gratuits et open‑source – sont les commandes host, dig, nslookup et whois.
Comme tous les outils en ligne de commande, ceux du DNS :
- possèdent de nombreuses options, qu'il est possible de découvrir en affichant les options d'aide ou de manuel en ligne (cf. chap. S1‑III S) ;
- peuvent aussi être utilisés dans des fichiers de script pour automatiser les recherches et optimiser l'exploitation de leurs résultats.
La présentation ci‑après de ces outils reste très superficielle. Des liens sont proposés pour en approfondir la pratique.
Ces commandes ne permettent pas de lister les sous‑domaines d'un nom de domaine, ni ses alias ou ses redirections.
En fait, cette limitation est souhaitable en termes de sécurité. En effet, la recherche d'une telle liste est un préalable pour mettre en œuvre une attaque sur un site. Pour plus de détails, on pourra consulter ce lien .
La commande host
La commande host W est un outil logiciel pour systèmes d'exploitation Unix et Linux, développé par l'ISC W (Internet systems consortium). Elle est en général pré‑installée, quelle que soit la distribution du système.
Par défaut, elle fournit des résultats de « premier niveau » sous forme synthétique, c'est‑à‑dire sans détails techniques.
- Une utilisation élémentaire typique de la commande
hostest la suivante : - Une utilisation plus experte de la commande
hostest, par exemple, la suivante :
host lycee-ferry-versailles.frlycee-ferry-versailles.fr has address 54.36.63.2 lycee-ferry-versailles.fr has address 54.36.63.2 lycee-ferry-versailles.fr mail is handled by 1 mx1.mail.ovh.net. lycee-ferry-versailles.fr mail is handled by 5 mx2.mail.ovh.net. lycee-ferry-versailles.fr mail is handled by 100 mx3.mail.ovh.net.
host www.lycee-ferry-versailles.frwww.lycee-ferry-versailles.fr is an alias for lycee-ferry-versailles.fr. lycee-ferry-versailles.fr has address 54.36.63.2 […]
host -a lycee-ferry-versailles.frTrying "lycee-ferry-versailles.fr" ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 12029 ;; flags: qr rd ra; QUERY: 1, ANSWER: 9, AUTHORITY: 0, ADDITIONAL: 0 ;; QUESTION SECTION: ;lycee-ferry-versailles.fr. IN ANY ;; ANSWER SECTION: lycee-ferry-versailles.fr. 3600 IN SOA dns110.ovh.net. tech.ovh.net. 2019072300 86400 3600 3600000 300 lycee-ferry-versailles.fr. 3600 IN NS ns110.ovh.net. lycee-ferry-versailles.fr. 3600 IN NS dns110.ovh.net. lycee-ferry-versailles.fr. 3600 IN MX 1 mx1.mail.ovh.net. lycee-ferry-versailles.fr. 3600 IN MX 100 mx3.mail.ovh.net. lycee-ferry-versailles.fr. 3600 IN MX 5 mx2.mail.ovh.net. lycee-ferry-versailles.fr. 3600 IN A 54.36.63.2 lycee-ferry-versailles.fr. 3600 IN TXT "google-site-verification=HUNDoeFN79g2pHtvhuMgpg1B5NCUNRMnhY5nZR72KVc" lycee-ferry-versailles.fr. 3600 IN TXT "v=spf1 include:mx.ovh.com ~all" Received 337 bytes from 8.8.8.8#53 in 59 ms
-a, on obtient davantage de résultats et surtout une présentation technique, très similaire à celle produite par la commande dig, que l'on va détailler ci‑après. La commande dig
La commande dig W – pour DNS information groper – est une composante de la suite logicielle multiplateforme BIND (cf. infra ). Elle est en général pré‑installée dans les distributions Linux.
Plus puissante que la commande host, elle fournit ses résultats avec une présentation technique conforme à la composition d'un message DNS exposée supra . Elle est donc bien adaptée pour une exploitation automatisée où de multiples requêtes sont mise en œuvre par un script et leurs résultats analysés et exportés dans un ou plusieurs fichiers.
Le nom de la commande dig est aussi choisi en référence au verbe anglais to dig qui signifie « creuser ».
- Une utilisation simple de la commande
digest par exemple la suivante : - les éléments d'en‑tête (
HEADER) du message DNS, à savoir le nº d'identification (id), les drapeaux (flags), le nombre de requêtes (QUERY), de réponses (ANSWER), etc. - des informations optionnelles relative à l'EDNS W (extension mechanisms for DNS) avec notamment la taille maximale possible du datagramme UDP ;
- le rappel des 3 champs de la requête (
QUESTION SECTION) – cf. supra ; - les 5 champs de la réponse (
ANSWER SECTION), avec bien entendu l'adresse IP (champ Rdata), mais aussi son typeA(IPv4) et sa TTL3600(1 h) ; - des informations additionnelles comme la date, l'heure et la durée de traitement de la requête, mais aussi l'adresse IP du serveur ayant répondu ; il s'agit d'un résolveur mettant en œuvre un algorithme récursif, ce que confirme l'en‑tête avec l'absence du drapeau
aa(autoritative answer) et la présence des drapeauxrdetra(recursion desired et recursion available). - Une utilisation une peu plus experte de la commande
digest la suivante : - les informations sur la zone d'autorité (
SOApour start of authority) ; - 2 noms de serveurs de noms du domaine (types
NSpour name server) ; - 3 noms de domaine des serveurs de courriels associés (types
MXpour mail exchanger). - Une utilisation encore plus experte de la commande
digest la suivante :
dig lycee-ferry-versailles.fr; <<>> DiG 9.16.1-Ubuntu <<>> lycee-ferry-versailles.fr ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 8386 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 1472 ;; QUESTION SECTION: ;lycee-ferry-versailles.fr. IN A ;; ANSWER SECTION: lycee-ferry-versailles.fr. 3600 IN A 54.36.63.2 ;; Query time: 39 msec ;; SERVER: 8.8.8.8#53(8.8.8.8) ;; WHEN: mar. oct. 19 13:34:45 CEST 2021 ;; MSG SIZE rcvd: 70
dig lycee-ferry-versailles.fr ANY; <<>> DiG 9.16.1-Ubuntu <<>> lycee-ferry-versailles.fr ANY ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 34941 ;; flags: qr rd ra; QUERY: 1, ANSWER: 9, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 1472 ;; QUESTION SECTION: ;lycee-ferry-versailles.fr. IN ANY ;; ANSWER SECTION: lycee-ferry-versailles.fr. 3600 IN SOA dns110.ovh.net. tech.ovh.net. 2019072300 86400 3600 3600000 300 lycee-ferry-versailles.fr. 3600 IN NS dns110.ovh.net. lycee-ferry-versailles.fr. 3600 IN NS ns110.ovh.net. lycee-ferry-versailles.fr. 3600 IN MX 5 mx2.mail.ovh.net. lycee-ferry-versailles.fr. 3600 IN MX 1 mx1.mail.ovh.net. lycee-ferry-versailles.fr. 3600 IN MX 100 mx3.mail.ovh.net. lycee-ferry-versailles.fr. 3600 IN A 54.36.63.2 lycee-ferry-versailles.fr. 3600 IN TXT "v=spf1 include:mx.ovh.com ~all" lycee-ferry-versailles.fr. 3600 IN TXT "google-site-verification=HUNDoeFN79g2pHtvhuMgpg1B5NCUNRMnhY5nZR72KVc" ;; Query time: 27 msec ;; SERVER: 8.8.8.8#53(8.8.8.8) ;; WHEN: mar. oct. 19 23:31:21 CEST 2021 ;; MSG SIZE rcvd: 348
ANY, on obtient en principe tous les enregistrements associés au nom de domaine lycee-ferry-versailles.fr, quels que soient leurs types. On obtient ainsi 9 réponses avec notamment, en plus de l'adresse IP attendue : dig @dns110.ovh.net lycee-ferry-versailles.fr;<<>> DiG 9.16.1-Ubuntu <<>> @dns110.ovh.net lycee-ferry-versailles.fr ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 13831 ;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;lycee-ferry-versailles.fr. IN A ;; ANSWER SECTION: lycee-ferry-versailles.fr. 3600 IN A 54.36.63.2 ;; Query time: 23 msec ;; SERVER: 2001:41d0:1:4a9a::1#53(dns110.ovh.net) (UDP) ;; WHEN: mer. oct. 20 00:08:44 CEST 2021 ;; MSG SIZE rcvd: 70
@ on a effectué une requête directement adressée au serveur de noms faisant autorité sur la zone (SOA), dont on a pu identifier le nom de domaine dns110.ovh.net lors de la requête précédente. Et on peut constater que le drapeau aa (autoritative answer) est bien présent, ce qui certifie que la réponse fait autorité. A que précédemment signifie que la ressource n'a pas changé récemment d'adresse IP, ce qui est presque toujours le cas. C'est pour cela qu'on peut le plus souvent se passer d'une telle démarche et faire confiance à la mémoire cache du résolveur. La commande nslookup
La commande nslookup W est l'outil logiciel le plus ancien de requêtes au DNS. Développé conjointement par l'ISC (Internet systems consortium) ainsi que les entreprises IBM (Industrial business machines) et Microsoft, il est multi‑plateforme et pré‑installé sur la plupart des systèmes d'exploitation.
Même si elle est parfois jugée comme étant redondante avec les autres outils sur les systèmes Linux, la commande nslookup possède des caractéristiques particulières qui rendent son utilisation « manuelle » très commode :
- elle possède un mode interactif, qui permet d'enchaîner rapidement des requêtes ;
- elle ne fait jamais appel à la mémoire cache du système d'exploitation, autrement dit elle interroge systématiquement l'un des résolveurs DNS définis dans la configuration de l'interface réseau ;
- elle adopte toujours une présentation conviviale des résultats pour l'utilisateur (user‑friendly display).
- Une utilisation simple de la commande
nslookupest par exemple la suivante : - On entre dans le mode interactif en saisissant seulement le nom de la commande
nslookupsans argument à la suite. Le prompt change et devient>en attente de saisies supplémentaires pour effectuer des requêtes successives. On peut alors simplement saisir un nom de domaine, fixer des paramètres ou les deux à la fois. Et on sort du mode interactif en saisissantexit. Divers exemples sont proposés ci‑dessous.
nslookup lycee-ferry-versailles.frServer: 212.27.40.241 Address: 212.27.40.241#53 Non-authoritative answer: Name: lycee-ferry-versailles.fr Address: 54.36.63.2
host mais moins qu'avec la commande dig. nslookupwww.lycee-ferry-versailles.frServer: 212.27.40.241 Address: 212.27.40.241#53 Non-authoritative answer: www.lycee-ferry-versailles.fr canonical name = lycee-ferry-versailles.fr. Name: lycee-ferry-versailles.fr Address: 54.36.63.2set querytype=ANYlycee-ferry-versailles.frServer: 8.8.8.8 Address: 8.8.8.8#53 Non-authoritative answer: lycee-ferry-versailles.fr origin = dns110.ovh.net mail addr = tech.ovh.net serial = 2019072300 refresh = 86400 retry = 3600 expire = 3600000 minimum = 300 lycee-ferry-versailles.fr nameserver = dns110.ovh.net. lycee-ferry-versailles.fr nameserver = ns110.ovh.net. lycee-ferry-versailles.fr mail exchanger = 5 mx2.mail.ovh.net. lycee-ferry-versailles.fr mail exchanger = 1 mx1.mail.ovh.net. lycee-ferry-versailles.fr mail exchanger = 100 mx3.mail.ovh.net. Name: lycee-ferry-versailles.fr Address: 54.36.63.2 lycee-ferry-versailles.fr text = "google-site-verification=HUNDoeFN79g2pHtvhuMgpg1B5NCUNRMnhY5nZR72KVc" lycee-ferry-versailles.fr text = "v=spf1 include:mx.ovh.com ~all" Authoritative answers can be found from:server dns110.ovh.netDefault server: dns110.ovh.net Address: 2001:41d0:1:4a9a::1#53 Default server: dns110.ovh.net Address: 213.251.188.154#53set querytype=Alycee-ferry-versailles.frServer: dns110.ovh.net Address: 2001:41d0:1:4a9a::1#53 Name: lycee-ferry-versailles.fr Address: 54.36.63.2exit
dig. Mais si l'on doit faire de nombreuses requêtes « à la main », la commande nslookup nécessite moins de saisies. La commande whois
La commande whois W offre un service d'informations administratives relatives aux noms de domaines à leurs adresses IP associées. Ces données sont publiées par les RIR (cf. chap. R1‑III ) ou les TLD manager (cf. supra ) sur des serveurs dédiés. Elles sont rendues accessibles via un protocole nommé également whois et spécifié par la RFC 3912 .
En règle générale, la commande whois n'est pas pré‑installée sur les systèmes d'exploitation des postes de travail. Pour pouvoir l'utiliser, il faut donc procéder à son installation, ce qui nécessite bien entendu de disposer des droits d'administration.
- Sur une machine à système Linux (distribution Ubuntu ou similaire), il suffit de saisir la commande :
sudo apt install whois -y
Une utilisation simple de la commande whois consiste à simplement la faire suivre d'un nom de domaine, comme dans l'exemple ci‑dessous :
whois lycee-ferry-versailles.fr%% %% This is the AFNIC Whois server. %% %% complete date format : YYYY-MM-DDThh:mm:ssZ %% short date format : DD/MM %% version : FRNIC-2.5 %% %% Rights restricted by copyright. %% See https://www.afnic.fr/en/products-and-services/services/whois/whois-special-notice/ %% %% Use '-h' option to obtain more information about this service. %% %% [2a01:0e0a:0441:fcb0:xxxx:xxxx:xxxx:xxxx REQUEST] >> -V Md5.5.6 lycee-ferry-versailles.fr %% %% RL Net [##########] - RL IP [#########.] %% domain: lycee-ferry-versailles.fr status: ACTIVE hold: NO holder-c: ANO00-FRNIC admin-c: LJF386-FRNIC tech-c: OVH5-FRNIC zone-c: NFC1-FRNIC nsl-id: NSL100842-FRNIC registrar: OVH Expiry Date: 2024-02-19T23:08:15Z created: 2009-10-19T13:55:35Z last-update: 2021-02-09T10:43:33Z source: FRNIC ns-list: NSL100842-FRNIC nserver: ns110.ovh.net nserver: dns110.ovh.net source: FRNIC registrar: OVH type: Isp Option 1 address: 2 Rue Kellermann address: 59100 ROUBAIX country: FR phone: +33 8 99 70 17 61 fax-no: +33 3 20 20 09 58 e-mail: support@ovh.net website: http://www.ovh.com anonymous: NO registered: 1999-10-21T12:00:00Z source: FRNIC nic-hdl: ANO00-FRNIC type: PERSON contact: Ano Nymous remarks: -------------- WARNING -------------- remarks: While the registrar knows him/her, remarks: this person chose to restrict access remarks: to his/her personal data. So PLEASE, remarks: don't send emails to Ano Nymous. This remarks: address is bogus and there is no hope remarks: of a reply. remarks: -------------- WARNING -------------- registrar: OVH changed: 2019-02-19T23:08:14Z anonymous@anonymous anonymous: YES obsoleted: NO eligstatus: ok eligdate: 2019-02-19T23:08:14Z reachstatus: not identified source: FRNIC nic-hdl: LJF386-FRNIC type: ORGANIZATION contact: Lycee Jules Ferry address: Lycee Jules Ferry address: 29 rue du Marechal Joffre address: 78000 Versailles country: FR phone: +33.139201160 e-mail: mtenzpkby0gg9fhym4i0@v.o-w-o.info registrar: OVH changed: 2021-02-09T10:43:29Z nic@nic.fr anonymous: NO obsoleted: NO eligstatus: not identified reachstatus: not identified source: FRNIC nic-hdl: OVH5-FRNIC type: ROLE contact: OVH NET address: OVH address: 140, quai du Sartel address: 59100 Roubaix country: FR phone: +33 8 99 70 17 61 e-mail: tech@ovh.net trouble: Information: http://www.ovh.fr trouble: Questions: mailto:tech@ovh.net trouble: Spam: mailto:abuse@ovh.net admin-c: OK217-FRNIC tech-c: OK217-FRNIC notify: tech@ovh.net registrar: OVH changed: 2006-10-11T08:41:58Z tech@ovh.net anonymous: NO obsoleted: NO eligstatus: not identified reachstatus: not identified source: FRNIC
Dans cette réponse très détaillée, on trouve quelques informations administratives – nom, adresse postale, adresse électronique, nº de téléphone – sur :
- l'organisme en charge du serveur ayant fourni la réponse – ici, l'AFNIC (cf. chap. R1‑I ) qui est le TLD manager du ccTLD
fr; - le détenteur du nom de domaine (
nic-hdlou network information centre handle) – ici, le lycée Jules Ferry de Versailles ; - le registraire (cf. supra ) auquel le détenteur du nom de domaine a fait appel – ici, la société OVH , qui est aussi le principal hébergeur web (cf. chap. R1‑I ) en France.
Même si les informations fournies via la commande whois sont a priori publiques, il peut sembler étonnant qu'elles soient si facilement disponibles.
À l'origine, le service whois a été conçu pour permettre aux techniciens du réseau de pouvoir joindre rapidement tout gestionnaire d'un nom de domaine en cas de dysfonctionnement.
Toutefois certains acteurs commerciaux ou associatifs peuvent ne pas souhaiter la divulgation de leurs coordonnées. Dans ce cas, les champs sont renseignés avec une mention générique de la forme REDACTED FOR PRIVACY.
Par ailleurs, les informations via la commande whois ne font l'objet d'aucune garantie d'authenticité : elles peuvent être erronés, et ce par obsolescence, inadvertance, voire mauvaise volonté.
Manipulation du cache DNS du système d'exploitation
On a vu supra que le système d'exploitation d'une machine contribue au DNS en jouant le rôle d'un résolveur récursif doté d'une importante mémoire cache.
Il est possible d'accéder en lecture et en écriture au cache DNS du système par des commandes spécifique saisies dans un terminal.
Pour plus de détails sur l'intérêt de ces manipulations, on peut consulter par exemple cet article .
Sur un PC Windows, il faut employer la commande ipconfig et les options suivantes :
-
/displaydnspour afficher le contenu du cache ; -
/flushdnspour effacer le contenu du cache ; -
/registerdnspour réenregistrer tous les noms de domaines en mémoire (donc, réinitialiser leur durée de vie).
Sur une machine Linux, les commandes dépendent du composant logiciel qui met en œuvre le cache DNS. Avec les distributions Ubuntu et ses dérivées – Mint, etc. – récentes, ce composant est systemd-resolve.